Gestion des erreurs et optimisation#
Un programme Solana qui fonctionne n’est pas necessairement un programme pret pour la production. Entre le prototype qui passe les tests et le programme deploye sur le mainnet, il existe un ecart considerable que seules une gestion rigoureuse des erreurs et une optimisation methodique permettent de combler. Les erreurs mal gerees produisent des messages incomprehensibles pour les utilisateurs ; les transactions non optimisees echouent faute de compute units ou depassent la taille maximale autorisee.
Ce chapitre aborde deux dimensions complementaires du developpement avance sur Solana. La premiere concerne la gestion des erreurs : comment definir des codes d’erreur personnalises avec Anchor, comment ces erreurs se propagent depuis le runtime jusqu’au client, et comment les intercepter dans les tests. La seconde dimension est l’optimisation, declinee en trois axes : les compute units (le budget de calcul), la memoire (la taille des comptes et la deserialisation), et les transactions (leur taille et leur composition).
L’objectif est de donner au lecteur les outils conceptuels et pratiques pour passer d’un programme fonctionnel a un programme robuste, economique et capable de supporter la charge d’un environnement de production. Chaque optimisation sera presentee avec son contexte d’application : optimiser sans mesurer, c’est naviguer sans boussole.
Erreurs personnalisees avec Anchor#
Le systeme d’erreurs de Solana est hierarchique : le runtime definit des codes de base, chaque programme du SPL possede ses propres codes, et les programmes utilisateur ajoutent leur couche. Anchor unifie cette gestion avec la macro #[error_code].
Définition 145 (La macro #[error_code])
La macro #[error_code] d’Anchor permet de definir un enum d’erreurs personnalisees pour un programme Solana. Chaque variante de l’enum represente une condition d’erreur specifique, accompagnee d’un message lisible via l’attribut #[msg("...")].
A la compilation, Anchor assigne a chaque variante un code numerique unique en commencant a 6000. Le premier variant recoit le code 6000, le deuxieme 6001, et ainsi de suite. Ces codes sont inclus dans l’IDL du programme, ce qui permet aux clients TypeScript de decoder automatiquement les erreurs recues.
L’utilisation de #[error_code] presente trois avantages :
Lisibilite : chaque erreur a un nom semantique et un message explicatif.
Stabilite : les codes sont deterministes et documentes dans l’IDL.
Interoperabilite : les clients TypeScript, les explorateurs de blocs et les outils de monitoring peuvent decoder les erreurs sans connaitre le code source.
Voici un exemple complet d’enum d’erreurs pour un programme de coffre-fort (vault) qui gere des depots et des retraits.
use anchor_lang::prelude::*;
#[error_code]
pub enum VaultError {
#[msg("Le montant du depot doit etre superieur a zero.")]
DepositAmountZero, // 6000
#[msg("Le montant du retrait depasse le solde disponible.")]
InsufficientBalance, // 6001
#[msg("Le coffre-fort est temporairement suspendu.")]
VaultPaused, // 6002
#[msg("Seul l'administrateur peut effectuer cette operation.")]
UnauthorizedAdmin, // 6003
#[msg("Le coffre-fort a atteint sa capacite maximale.")]
VaultCapacityExceeded, // 6004
#[msg("Le delai de verrouillage n'est pas encore expire.")]
LockPeriodNotExpired, // 6005
#[msg("Le montant depasse la limite par transaction.")]
TransactionLimitExceeded, // 6006
}
Ces erreurs s’utilisent dans le corps des instructions avec la macro require! ou avec le pattern err! :
pub fn withdraw(ctx: Context<Withdraw>, amount: u64) -> Result<()> {
let vault = &mut ctx.accounts.vault;
require!(!vault.paused, VaultError::VaultPaused);
require!(amount > 0, VaultError::DepositAmountZero);
require!(
vault.balance >= amount,
VaultError::InsufficientBalance
);
require!(
amount <= vault.max_per_tx,
VaultError::TransactionLimitExceeded
);
vault.balance -= amount;
// ... logique de transfert ...
Ok(())
}
Remarque 111 (Propagation des erreurs et rollback)
Lorsqu’un programme retourne une erreur, le mecanisme de propagation suit un chemin precis :
Le programme retourne un code d’erreur via
Result::Err.Le runtime Solana intercepte cette erreur et annule toutes les modifications apportees aux comptes pendant l’instruction (rollback atomique).
Le client recoit un objet contenant le code d’erreur numerique et le message associe.
Aucune donnee on-chain n’est modifiee : c’est la propriete d’atomicite des transactions Solana. Ce comportement est garanti meme si l’erreur survient apres plusieurs ecritures dans des comptes differents — le runtime restaure l’etat precedent dans sa totalite.
Remarque 112 (Plages de codes d’erreur)
Les codes d’erreur sur Solana sont organises en plages distinctes :
0 a 99 : erreurs systeme du runtime Solana (compte inexistant, signataire manquant, budget depasse, etc.).
100 a 999 : erreurs des programmes SPL (Token, Associated Token Account, etc.). Par exemple, le programme SPL Token utilise les codes 0 a 17 dans son propre espace.
300 a 399 : erreurs internes d’Anchor (contraintes
has_one,mut,seeds, etc.). Par exemple,ConstraintHasOneest le code 2001 dans l’espace Anchor (qui commence a 2000).6000+ : erreurs personnalisees du programme utilisateur, definies via
#[error_code].
Cette separation permet de diagnostiquer immediatement l’origine d’une erreur a partir de son code numerique. Un code superieur ou egal a 6000 provient toujours de la logique metier du programme.
Exemple 49 (Intercepter les erreurs dans les tests TypeScript)
Pour verifier qu’une instruction echoue avec le bon code d’erreur, on utilise un bloc try/catch dans les tests TypeScript Anchor :
import * as anchor from "@coral-xyz/anchor";
import { Program } from "@coral-xyz/anchor";
import { Vault } from "../target/types/vault";
import { assert } from "chai";
it("refuse un retrait superieur au solde", async () => {
try {
await program.methods
.withdraw(new anchor.BN(1_000_000))
.accounts({
vault: vaultPda,
owner: owner.publicKey,
systemProgram: anchor.web3.SystemProgram.programId,
})
.signers([owner])
.rpc();
assert.fail("La transaction aurait du echouer");
} catch (err) {
// Verifier le code d'erreur Anchor
assert.equal(err.error.errorCode.code, "InsufficientBalance");
assert.equal(err.error.errorCode.number, 6001);
assert.include(
err.error.errorMessage,
"Le montant du retrait depasse le solde disponible"
);
}
});
it("refuse un depot de zero", async () => {
try {
await program.methods
.deposit(new anchor.BN(0))
.accounts({
vault: vaultPda,
depositor: depositor.publicKey,
systemProgram: anchor.web3.SystemProgram.programId,
})
.signers([depositor])
.rpc();
assert.fail("La transaction aurait du echouer");
} catch (err) {
assert.equal(err.error.errorCode.code, "DepositAmountZero");
assert.equal(err.error.errorCode.number, 6000);
}
});
L’objet err.error expose trois champs utiles : errorCode.code (le nom de la variante), errorCode.number (le code numerique), et errorMessage (le message defini dans #[msg("...")]). Ce trio permet des assertions precises dans les tests.
Gestion des compute units#
Chaque instruction Solana s’execute dans un cadre budgetaire strict. Comprendre et gerer les compute units est essentiel pour eviter les echecs de transaction en production.
Définition 146 (Compute unit (CU))
La compute unit (CU) est l’unite de mesure du cout de calcul sur Solana. Chaque operation effectuee par un programme — acces memoire, operation arithmetique, appel systeme, ecriture de log — consomme un nombre determine de CU.
Le budget par defaut est de 200 000 CU par instruction. Une transaction peut contenir plusieurs instructions, avec un plafond global de 1 400 000 CU par transaction. Si une instruction depasse son budget, le runtime Solana l’interrompt immediatement et annule toutes les modifications (rollback).
Ce budget sert deux objectifs :
Protection contre les boucles infinies : un programme qui boucle epuise son budget et echoue proprement.
Tarification equitable : les validateurs facturent les transactions en fonction des CU consommees, via le mecanisme de priority fees.
Les operations qui consomment le plus de CU sont les suivantes :
Logging (
msg!) : environ 100 CU par appel, plus le cout de formatage des arguments.Appels systeme (syscalls) :
sol_log,sol_create_program_address,sol_invoke_signed— chacun avec un cout fixe.Allocation memoire : l’allocateur de tas (heap) de Solana consomme des CU proportionnellement a la taille allouee.
Deserialisation des comptes : Borsh deserialise l’integralite du compte a chaque acces, ce qui est couteux pour les grands comptes.
Cross-Program Invocation (CPI) : chaque CPI a un cout de base d’environ 1000 CU, plus le cout de l’instruction invoquee.
Pour ajuster le budget de CU, on ajoute des instructions speciales du programme Compute Budget a la transaction :
# Dans une transaction TypeScript, ajouter avant les autres instructions :
# 1. Definir la limite de CU pour la transaction
# (remplace le defaut de 200 000 par instruction)
ComputeBudgetProgram.setComputeUnitLimit({
units: 400_000
})
# 2. Definir le prix par CU (priority fee)
# En micro-lamports par CU
ComputeBudgetProgram.setComputeUnitPrice({
microLamports: 50_000
})
Voici l’equivalent en TypeScript :
import {
ComputeBudgetProgram,
Transaction,
} from "@solana/web3.js";
const tx = new Transaction();
// Augmenter le budget a 400 000 CU
tx.add(
ComputeBudgetProgram.setComputeUnitLimit({
units: 400_000,
})
);
// Priority fee : 50 000 micro-lamports par CU
tx.add(
ComputeBudgetProgram.setComputeUnitPrice({
microLamports: 50_000,
})
);
// Ajouter l'instruction principale
tx.add(mainInstruction);

Remarque 113 (Profilage avec solana logs)
Pour mesurer la consommation reelle de CU d’une instruction, on utilise la commande solana logs qui affiche, pour chaque instruction executee, le nombre de CU consommees :
Program 9xQ3...4vR7 invoke [1]
Program log: Instruction: Withdraw
Program 9xQ3...4vR7 consumed 15234 of 200000 compute units
Program 9xQ3...4vR7 success
La ligne consumed X of Y compute units est la source de verite pour le profilage. En comparant cette valeur avant et apres une modification, on peut mesurer l’impact exact de chaque optimisation.
On peut egalement utiliser solana confirm -v <SIGNATURE> pour obtenir le detail des CU d’une transaction deja confirmee, ou l’option simulateTransaction du SDK TypeScript qui retourne les CU consommees sans envoyer la transaction au reseau.
Remarque 114 (Le budget de 200 000 CU et ses limites)
Le budget par defaut de 200 000 CU par instruction est genereux pour la plupart des operations simples. Un transfert SOL consomme environ 2 100 CU, une initialisation Anchor environ 20 000 CU. Meme un programme moderement complexe reste souvent sous les 50 000 CU.
Cependant, certaines operations depassent largement ce budget :
Les operations DeFi complexes (swap avec plusieurs pools, liquidations) peuvent atteindre 300 000 a 800 000 CU.
Les programmes avec de nombreux CPI en chaine accumulent les couts de base de chaque invocation.
Les comptes volumineux (plusieurs KB de donnees) coutent cher a deserialiser.
Dans ces cas, il faut augmenter le budget via SetComputeUnitLimit. Inversement, pour les operations simples, reduire le budget en dessous de 200 000 CU peut ameliorer la priorite de la transaction (le prix par CU etant calcule sur le budget demande, pas consomme).
Optimisation memoire#
La memoire on-chain a un cout direct : chaque octet stocke dans un compte requiert des lamports pour l’exemption de loyer. Optimiser la taille des structures est donc un investissement rentable, surtout pour les programmes qui creent de nombreux comptes.
Le premier levier est l”ordre des champs dans les structures. Borsh serialise les champs dans l’ordre de declaration sans padding, ce qui differe du comportement du compilateur C. Toutefois, pour les comptes en zero-copy (qui utilisent #[repr(C)]), l’ordre des champs impacte directement la taille a cause du padding d’alignement.
// AVANT : ordre naif, avec padding (en repr(C))
// Taille = 1 + 7(pad) + 8 + 1 + 3(pad) + 4 + 32 = 56 octets
#[repr(C)]
pub struct OrderNaif {
pub is_active: bool, // 1 octet + 7 padding
pub amount: u64, // 8 octets
pub category: u8, // 1 octet + 3 padding
pub count: u32, // 4 octets
pub owner: Pubkey, // 32 octets
}
// APRES : champs ordonnes par alignement decroissant
// Taille = 32 + 8 + 4 + 1 + 1 + 2(pad) = 48 octets
#[repr(C)]
pub struct OrderOptimise {
pub owner: Pubkey, // 32 octets (align 1, mais le plus grand)
pub amount: u64, // 8 octets
pub count: u32, // 4 octets
pub category: u8, // 1 octet
pub is_active: bool, // 1 octet + 2 padding
}
La regle est simple : ordonner les champs du plus grand au plus petit minimise le padding insere par le compilateur pour respecter les contraintes d’alignement.
Définition 147 (Deserialisation zero-copy)
La deserialisation zero-copy est une technique qui mappe directement les donnees brutes d’un compte Solana sur une structure Rust, sans copier ni transformer les octets. En Anchor, elle s’active avec la contrainte #[account(zero_copy)] sur la structure et zero_copy dans les contraintes de compte.
Avec la deserialisation standard (Borsh), les donnees sont lues octet par octet et reconstruites en memoire. Pour un compte de 10 KB, cela signifie copier 10 KB et consommer des CU proportionnellement. Avec zero-copy, le programme accede directement au buffer du compte via un pointeur, ce qui reduit la consommation de CU a presque zero pour la « deserialisation ».
Zero-copy est recommande pour les comptes depassant environ 10 KB, ou la difference de cout en CU devient significative.
Voici un exemple de definition de compte zero-copy pour un carnet d’ordres (order book) :
use anchor_lang::prelude::*;
use bytemuck::{Pod, Zeroable};
// La structure doit utiliser #[repr(C)] pour un layout memoire predictible
// et implementer Pod + Zeroable (via bytemuck)
#[account(zero_copy)]
#[repr(C)]
pub struct OrderBook {
pub authority: Pubkey, // 32 octets
pub base_mint: Pubkey, // 32 octets
pub quote_mint: Pubkey, // 32 octets
pub order_count: u64, // 8 octets
pub orders: [Order; 256], // 256 * 48 = 12 288 octets
}
#[derive(Copy, Clone, Pod, Zeroable)]
#[repr(C)]
pub struct Order {
pub owner: Pubkey, // 32 octets
pub price: u64, // 8 octets
pub quantity: u64, // 8 octets
}
// Utilisation dans les contraintes de compte :
#[derive(Accounts)]
pub struct PlaceOrder<'info> {
#[account(mut)]
pub order_book: AccountLoader<'info, OrderBook>,
pub trader: Signer<'info>,
}
Remarque 115 (Contraintes du zero-copy)
La deserialisation zero-copy impose des contraintes strictes sur la structure des donnees :
Types a taille fixe uniquement : pas de
String, pas deVec<T>, pas deOption<T>. Seuls les types dont la taille est connue a la compilation sont autorises.#[repr(C)]obligatoire : le layout memoire doit etre predictible et stable. Le layout par defaut de Rust (#[repr(Rust)]) ne garantit pas l’ordre des champs.Traits
PodetZeroable: chaque champ doit implementer ces traits du cratebytemuck, ce qui garantit que la structure peut etre interpretee comme une simple sequence d’octets.AccountLoaderau lieu deAccount: dans les structuresAccounts, on utiliseAccountLoader<'info, T>au lieu deAccount<'info, T>. L’acces aux donnees se fait via.load()(lecture seule) ou.load_mut()(lecture-ecriture).
Ces contraintes rendent zero-copy inadapte aux structures dynamiques, mais ideal pour les tableaux de taille fixe comme les carnets d’ordres, les pools de liquidite ou les registres de validateurs.
Définition 148 (Table des tailles Borsh)
La serialisation Borsh encode chaque type avec une taille fixe ou un prefixe de longueur. La connaissance precise de ces tailles est indispensable pour calculer le parametre space lors de l’initialisation d’un compte Anchor. Les tailles ci-dessous incluent les prefixes de longueur pour les types dynamiques mais excluent le discriminateur de 8 octets qu’Anchor ajoute en tete de chaque compte.
Type |
Taille (octets) |
Notes |
|---|---|---|
|
1 |
0 ou 1 |
|
1 |
|
|
2 |
Little-endian |
|
4 |
Little-endian |
|
8 |
Little-endian |
|
16 |
Little-endian |
|
4 |
IEEE 754 |
|
8 |
IEEE 754 |
|
32 |
32 octets bruts |
|
N |
Tableau de taille fixe |
|
4 + len |
Prefixe |
|
4 + n * sizeof(T) |
Prefixe |
|
1 + sizeof(T) |
1 octet discriminant + donnee |
|
1 + max(variantes) |
1 octet discriminant + plus grande variante |
Optimisation des transactions#
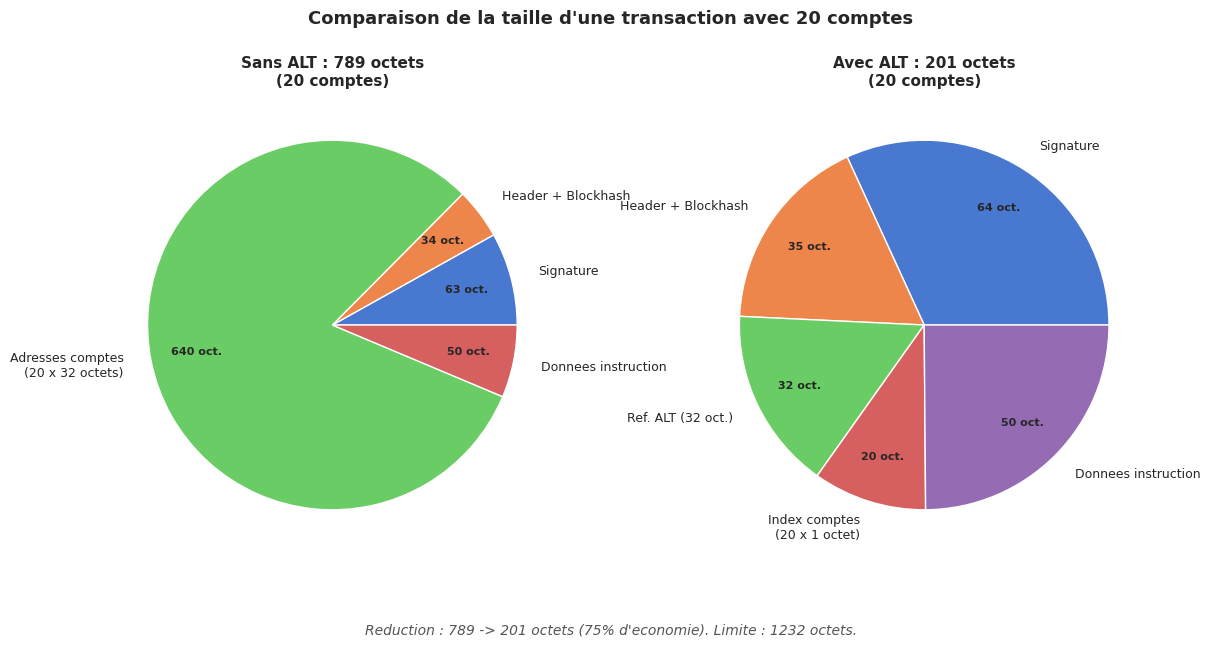
La taille d’une transaction Solana est limitee a 1232 octets. Cette contrainte, heritee du protocole UDP sous-jacent, impose une gestion attentive de la composition des transactions.
Définition 149 (Address Lookup Tables (ALT))
Les Address Lookup Tables (ALT) sont des comptes on-chain qui stockent une liste d’adresses frequemment utilisees. Au lieu d’inclure chaque adresse complete (32 octets) dans la transaction, on peut referencer une adresse par son index dans la table (1 octet).
Une ALT peut contenir jusqu’a 256 adresses. Elle est creee par l’instruction CreateLookupTable du programme Address Lookup Table, puis peuplee avec ExtendLookupTable. Chaque adresse ajoutee ne devient utilisable qu’apres une periode de warm-up d’un slot.
L’economie est considerable : pour 20 comptes, on passe de 640 octets (20 * 32) a 20 octets (20 * 1) plus la reference a la table elle-meme (32 octets), soit une reduction de plus de 90%.
Définition 150 (Transactions versionnees)
Les transactions versionnees (format v0) sont le format de transaction qui prend en charge les Address Lookup Tables. Le format legacy (pre-v0) ne peut pas utiliser les ALT.
Une transaction v0 contient un champ addressTableLookups qui reference une ou plusieurs ALT et specifie quels index utiliser pour les comptes en lecture seule et en ecriture. Le runtime Solana resout ces index en adresses completes au moment de l’execution.
Depuis la generalisation des transactions v0 sur le mainnet, tous les SDKs modernes (web3.js v2, Anchor) les supportent nativement.
Remarque 116 (Batching d’instructions)
Le batching consiste a combiner plusieurs instructions en une seule transaction. Chaque transaction a un cout fixe incompressible : au moins une signature (64 octets), un header (3 octets) et un blockhash (32 octets). Regrouper trois instructions en une transaction est donc plus economique que d’envoyer trois transactions separees.
De plus, les instructions au sein d’une meme transaction partagent les references de comptes : si deux instructions utilisent le meme compte, son adresse n’apparait qu’une seule fois dans la liste des comptes de la transaction. Ce partage reduit la taille totale et maximise l’utilisation de l’espace disponible.
Le batching est particulierement utile pour les operations en lot : distribuer des tokens a plusieurs destinataires, mettre a jour plusieurs comptes simultanement, ou enchainer une creation de compte et son initialisation.
Pour les instructions qui acceptent un nombre variable de comptes, Anchor fournit le mecanisme remaining_accounts :
use anchor_lang::prelude::*;
pub fn process_batch(ctx: Context<ProcessBatch>) -> Result<()> {
// remaining_accounts contient une liste variable de comptes
// non declares dans la structure Accounts
let accounts = &ctx.remaining_accounts;
for account_info in accounts.iter() {
// Verification manuelle obligatoire : remaining_accounts
// ne beneficie d'aucune validation automatique
require!(
account_info.owner == ctx.program_id,
VaultError::UnauthorizedAdmin
);
// Deserialiser manuellement
let mut data = account_info.try_borrow_mut_data()?;
// ... traitement ...
}
msg!("Traite {} comptes", accounts.len());
Ok(())
}
#[derive(Accounts)]
pub struct ProcessBatch<'info> {
#[account(mut)]
pub authority: Signer<'info>,
// Les comptes supplementaires sont passes via remaining_accounts
}
Remarque 117 (Limite de taille des transactions)
La taille maximale d’une transaction Solana est de 1232 octets. Cette limite inclut les signatures (64 octets chacune), le header (3 octets), le blockhash recent (32 octets), les adresses de comptes (32 octets chacune) et les donnees d’instructions.
Sans ALT, une transaction avec une seule signature peut contenir environ 35 comptes (1232 - 64 - 3 - 32 - overhead d’instructions) / 32. Avec une ALT, chaque compte supplementaire ne coute qu’un octet d’index, ce qui permet de referencer potentiellement des centaines de comptes.
En pratique, meme avec les ALT, le budget de CU reste le facteur limitant pour les transactions complexes. La taille en octets et le budget de CU sont deux contraintes independantes qui doivent etre satisfaites simultanement.
Patterns avances#
Au-dela des techniques d’optimisation specifiques, certains patterns architecturaux permettent d’ecrire des programmes plus flexibles et plus economiques.
L”initialisation paresseuse (lazy initialization) consiste a ne pas allouer la totalite de l’espace d’un compte des sa creation. On commence avec un espace minimal, puis on utilise la contrainte realloc d’Anchor pour agrandir le compte au fur et a mesure que les donnees s’accumulent.
Définition 151 (Initialisation paresseuse avec realloc)
L”initialisation paresseuse est un pattern qui differe l’allocation memoire au moment ou elle est reellement necessaire. Au lieu d’allouer la taille maximale d’un compte a la creation (ce qui immobilise des lamports pour le loyer), on alloue un minimum et on agrandit avec realloc a chaque ajout de donnees.
Ce pattern est pertinent lorsque :
La taille maximale est grande mais rarement atteinte (ex : un vecteur de 1000 elements dont la majorite des utilisateurs n’en utilisent que 10).
Le cout initial de creation doit etre minimise (meilleure UX pour les nouveaux utilisateurs).
Les donnees sont ajoutees incrementalement au fil du temps.
Le compromis est que chaque reallocation consomme des CU supplementaires et necessite le passage du system_program dans l’instruction.
Définition 152 (Comptes conditionnels)
Les comptes conditionnels permettent de rendre certains comptes optionnels dans une instruction Anchor. En declarant un champ avec le type Option<Account<'info, T>>, le compte peut etre present ou absent dans la transaction. Anchor deserialise le compte s’il est fourni, ou assigne None si l’adresse du programme systeme est passee a sa place.
Ce pattern est utile lorsque le comportement d’une instruction varie selon le contexte : prelever des frais uniquement si un collecteur est configure, crediter un referrer uniquement s’il existe, ou interagir avec un programme externe uniquement si le compte correspondant est fourni.
use anchor_lang::prelude::*;
#[derive(Accounts)]
pub struct TransferWithOptionalFee<'info> {
#[account(mut)]
pub sender: Signer<'info>,
#[account(mut)]
/// CHECK: validated in instruction body
pub recipient: AccountInfo<'info>,
// Le compte de frais est optionnel :
// present si le protocole preleve des frais, absent sinon
#[account(mut)]
pub fee_collector: Option<Account<'info, FeeCollector>>,
// Le compte de referral est egalement optionnel
#[account(mut)]
pub referrer: Option<Account<'info, ReferrerAccount>>,
pub system_program: Program<'info, System>,
}
pub fn transfer_with_optional_fee(
ctx: Context<TransferWithOptionalFee>,
amount: u64,
) -> Result<()> {
let mut net_amount = amount;
// Si un collecteur de frais est present, prelever les frais
if let Some(fee_collector) = &mut ctx.accounts.fee_collector {
let fee = amount
.checked_mul(fee_collector.fee_bps as u64)
.unwrap()
.checked_div(10_000)
.unwrap();
fee_collector.total_collected += fee;
net_amount -= fee;
}
// Si un referrer est present, crediter le bonus
if let Some(referrer) = &mut ctx.accounts.referrer {
referrer.referral_count += 1;
}
// Effectuer le transfert du montant net
// ... logique de transfert ...
msg!("Transfert de {} lamports (net: {})", amount, net_amount);
Ok(())
}
Remarque 118 (Quand optimiser ?)
La celebre maxime de Donald Knuth — « premature optimization is the root of all evil » — s’applique pleinement au developpement Solana. Voici une approche methodique :
Ecrire d’abord un programme correct. La securite et l’exactitude priment sur la performance. Un programme rapide mais vulnerable est pire qu’un programme lent mais sur.
Mesurer avant d’optimiser. Utiliser
solana logset la simulation de transactions pour identifier les goulots d’etranglement reels. Souvent, le probleme n’est pas ou l’on croit.Optimiser le goulot d’etranglement. Concentrer l’effort sur les 20% du code responsables de 80% de la consommation de CU.
Verifier l’impact. Apres chaque optimisation, mesurer a nouveau pour confirmer le gain. Une optimisation qui ne produit pas de gain mesurable est du bruit.
Les optimisations les plus rentables, par ordre d’impact decroissant, sont generalement :
Reduire le nombre de CPI (chacun coute ~1000 CU de base).
Utiliser zero-copy pour les grands comptes (>10 KB).
Supprimer les
msg!()de production.Ordonner les champs des structures
#[repr(C)]par alignement.Utiliser les ALT pour les transactions avec de nombreux comptes.
Resume#
Concept |
Description |
|---|---|
|
Macro Anchor pour definir des erreurs personnalisees avec codes numeriques (a partir de 6000) et messages |
Propagation des erreurs |
Programme retourne erreur, runtime annule les modifications, client recoit code + message |
Plages de codes |
0-99 (systeme), 100-999 (SPL), 2000+ (Anchor interne), 6000+ (programme utilisateur) |
Compute unit (CU) |
Unite de cout de calcul ; 200 000 CU/instruction par defaut, 1 400 000 CU/transaction max |
SetComputeUnitLimit |
Instruction pour ajuster le budget de CU d’une transaction |
SetComputeUnitPrice |
Instruction pour definir le prix par CU (priority fees) |
Zero-copy |
|
Layout compact |
Ordonner les champs par alignement decroissant pour minimiser le padding en |
Tailles Borsh |
bool=1, u8=1, u16=2, u32=4, u64=8, u128=16, Pubkey=32, String=4+len, Vec=4+n*sizeof(T) |
Address Lookup Tables |
Tables on-chain stockant des adresses ; reference par index (1 octet) au lieu de 32 octets |
Transactions versionnees |
Format v0 supportant les ALT ; requis pour utiliser les lookup tables |
Taille max transaction |
1232 octets ; ~35 comptes sans ALT, centaines avec ALT |
remaining_accounts |
Comptes non declares, passes dynamiquement ; aucune validation automatique |
Initialisation paresseuse |
Allouer un minimum a la creation, agrandir avec |
Comptes conditionnels |
|
Quand optimiser |
Mesurer d’abord, optimiser le goulot d’etranglement, verifier le gain |
Le chapitre suivant explorera les cross-program invocations (CPI) avancees et la composabilite des programmes Solana, en montrant comment construire des protocoles complexes a partir de briques elementaires.