Introduction et installation#
Qu’est-ce que le contrôle de version ?#
Le contrôle de version (ou version control) est la pratique qui consiste à enregistrer les modifications successives apportées à un ensemble de fichiers au cours du temps, de sorte que l’on puisse retrouver, comparer ou restaurer n’importe quelle version antérieure. Sans un tel système, la gestion d’un projet logiciel repose sur des copies manuelles de dossiers — projet_v1, projet_v2_final, projet_v2_final_VRAI — méthode fragile, opaque et source de pertes de données. Le contrôle de version résout ce problème en offrant un historique structuré, traçable et partageable de chaque changement effectué.
L’idée n’est pas nouvelle. Dès les années 1980, RCS (Revision Control System) permettait de versionner des fichiers individuels en stockant les différences (deltas) entre révisions successives. Dans les années 1990, CVS (Concurrent Versions System) puis SVN (Apache Subversion) ont étendu cette approche à des projets entiers, avec un serveur central hébergeant l’historique complet. Mais c’est en 2005 que Linus Torvalds, insatisfait des outils existants pour gérer le noyau Linux, a créé Git : un système distribué, rapide et conçu pour les projets à grande échelle. Aujourd’hui, Git est devenu le standard de facto, utilisé aussi bien par les développeurs individuels que par les plus grandes entreprises du monde.
Systèmes centralisés vs distribués#
Définition 1 (Système de contrôle de version centralisé)
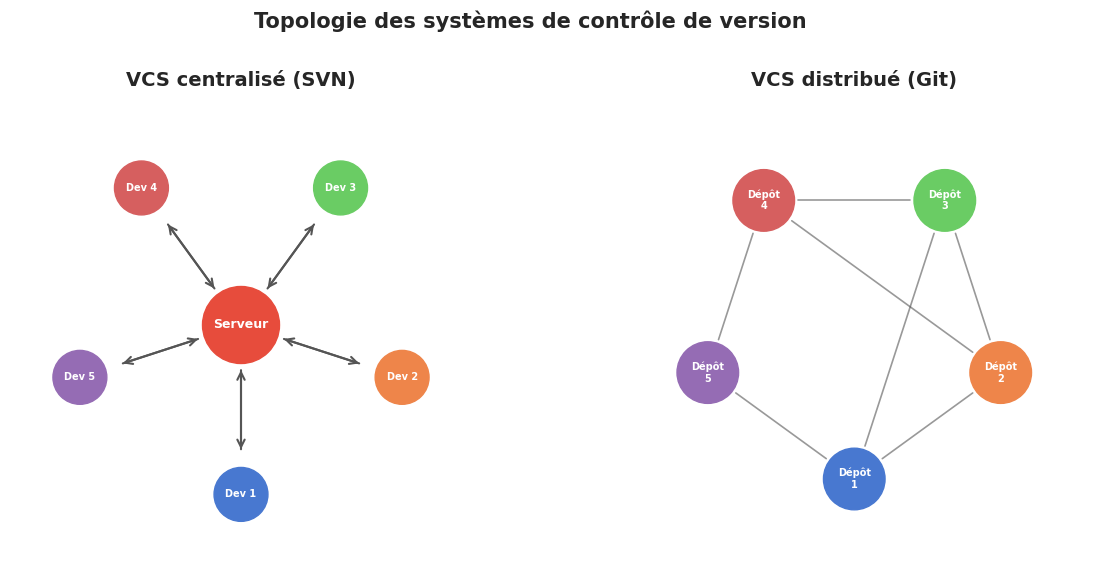
Un VCS centralisé (comme CVS ou SVN) repose sur un serveur unique qui contient l’historique complet du projet. Chaque développeur possède une copie de travail (working copy) correspondant à une seule révision. Toutes les opérations d’historique — consulter un ancien commit, créer une branche, fusionner — nécessitent une connexion réseau au serveur central.
Définition 2 (Système de contrôle de version distribué)
Un VCS distribué (comme Git ou Mercurial) donne à chaque développeur un clone complet du dépôt, incluant l’intégralité de l’historique. Chaque clone est un dépôt à part entière : on peut consulter l’historique, créer des branches, effectuer des commits et des fusions entièrement hors ligne. La synchronisation entre dépôts se fait par échange de commits (push, pull, fetch).
Remarque 1
Le modèle distribué apporte plusieurs avantages décisifs :
Travail hors ligne. Puisque chaque clone contient tout l’historique, on peut travailler sans connexion réseau. Les commits, branches et fusions sont des opérations locales, donc quasi instantanées.
Vitesse. Les opérations courantes (log, diff, blame) ne transitent pas par le réseau. Git est conçu pour être rapide même sur des dépôts contenant des centaines de milliers de fichiers.
Redondance naturelle. Chaque clone est une sauvegarde complète. Si le serveur principal tombe en panne, n’importe quel clone peut servir de base pour reconstruire le dépôt.
Workflows flexibles. On peut organiser la collaboration de multiples façons : un dépôt central de référence, un modèle dictateur-lieutenants, ou un réseau pair-à-pair.
Installation et configuration#
Git est disponible sur tous les systèmes d’exploitation courants. Voici les commandes d’installation selon votre plateforme.
Exemple 1 (Installation de Git)
Sur Linux (Debian/Ubuntu) :
sudo apt update && sudo apt install git
Sur macOS (via Homebrew) :
brew install git
Sur Windows, le plus simple est de télécharger l’installateur depuis git-scm.com ou d’utiliser winget :
winget install Git.Git
Après l’installation, on vérifie que Git est bien disponible :
%%bash
git --version
git version 2.47.3
Configuration initiale#
Avant de commencer à travailler avec Git, il est indispensable de configurer son identité. Ces informations seront associées à chaque commit que vous créerez.
%%bash
# Configurer son identité (à adapter avec vos informations)
git config --global user.name "Votre Nom"
git config --global user.email "votre.email@exemple.com"
# Définir l'éditeur par défaut (nano, vim, code, etc.)
git config --global core.editor "nano"
# Renommer la branche par défaut en 'main' (convention moderne)
git config --global init.defaultBranch main
# Vérifier la configuration
git config --global --list
user.name=Votre Nom
user.email=votre.email@exemple.com
user.signingkey=BCC71367447BCDEB
color.ui=aut
o
core.editor=nano
alias.unstage=reset HEAD --
alias.last=log -1 HEAD
alias.one=log --pretty=oneline
filesystem.N/A|13|/dev/sda4.timestampresolution=20000 nanoseconds
filesystem.N/A|13|/dev/sda4.minra
cythreshold=5090 microseconds
filter.lfs.required=true
filter.lfs.clean=git-lfs clean -- %f
filter.l
fs.smudge=git-lfs smudge -- %f
filter.lfs.process=git-lfs filter-process
commit.gpgsign=true
init.de
faultbranch=main
Remarque 2
Git applique sa configuration selon trois niveaux de portée, du plus général au plus spécifique :
--system: s’applique à tous les utilisateurs de la machine. Le fichier se trouve généralement dans/etc/gitconfig.--global: s’applique à tous les dépôts de l’utilisateur courant. Le fichier est~/.gitconfig(ou~/.config/git/config).--local: s’applique uniquement au dépôt courant. Le fichier est.git/configdans le dépôt.
Un paramètre défini à un niveau plus spécifique écrase celui du niveau plus général. Ainsi, on peut définir un email professionnel en --global et le remplacer par un email personnel dans un dépôt particulier via --local.
Les trois zones de Git#
La compréhension des trois zones de Git est fondamentale. C’est le modèle mental qui sous-tend toutes les opérations que nous verrons dans les chapitres suivants.
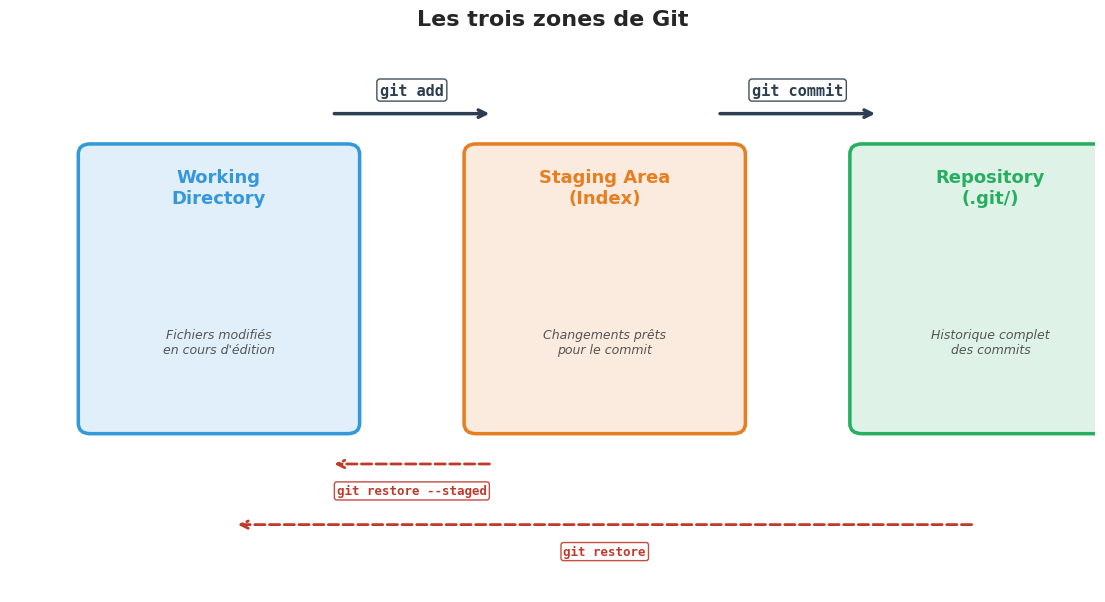
Définition 3 (Répertoire de travail (Working Directory))
Le répertoire de travail est le dossier visible sur le système de fichiers où l’on modifie les fichiers du projet. C’est l’état « en cours » du projet : les fichiers que l’on édite, crée ou supprime. Git compare en permanence cet état avec la dernière version enregistrée pour détecter les modifications.
Définition 4 (Zone de transit (Staging Area ou Index))
La zone de transit (ou index) est un espace intermédiaire qui contient les modifications que l’on souhaite inclure dans le prochain commit. On y ajoute des changements avec git add. C’est une « zone de préparation » : elle permet de sélectionner précisément quels changements seront enregistrés, sans être obligé de tout committer d’un coup.
Définition 5 (Dépôt (Repository))
Le dépôt (le répertoire .git/) contient l’historique complet du projet : tous les commits, branches, tags et métadonnées. Lorsqu’on exécute git commit, les changements présents dans la zone de transit sont enregistrés de façon permanente dans le dépôt sous forme d’un objet commit, identifié par un hash SHA-1 unique.
Remarque 3
La zone de transit est ce qui rend Git véritablement unique par rapport aux autres VCS. Elle permet de construire un commit de façon incrémentale et sélective. Par exemple, si l’on a modifié dix fichiers, on peut n’en ajouter que trois à la zone de transit et créer un commit cohérent portant uniquement sur ces trois fichiers. Les sept autres modifications restent dans le répertoire de travail, prêtes pour un commit ultérieur. Cette granularité fine encourage les commits atomiques : chaque commit ne contient qu’un seul changement logique, ce qui rend l’historique lisible et les retours en arrière précis.
Exemple 2 (Cycle de travail élémentaire)
Un cycle de travail typique avec Git suit ces étapes :
Modifier des fichiers dans le répertoire de travail.
Indexer les modifications souhaitées avec
git add fichier.py(passage dans la zone de transit).Enregistrer un instantané avec
git commit -m "Description du changement"(passage dans le dépôt).
Pour revenir en arrière :
git restore fichier.pyannule les modifications du répertoire de travail (revient à la version du dernier commit).git restore --staged fichier.pyretire un fichier de la zone de transit sans toucher au répertoire de travail.
Résumé#
Dans ce chapitre, nous avons posé les fondations nécessaires à la compréhension de Git :
Le contrôle de version est une pratique essentielle qui permet de conserver un historique structuré et traçable de chaque modification apportée à un projet.
Git est un système distribué : chaque clone contient l’intégralité de l’historique, ce qui permet le travail hors ligne, la rapidité des opérations et une redondance naturelle — contrairement aux systèmes centralisés comme SVN où tout repose sur un serveur unique.
L”installation de Git est simple sur toutes les plateformes, et la configuration initiale (
user.name,user.email,core.editor,init.defaultBranch) doit être effectuée avant de commencer à travailler.Git repose sur trois zones : le répertoire de travail (fichiers en cours d’édition), la zone de transit (modifications sélectionnées pour le prochain commit) et le dépôt (historique permanent). La zone de transit est la clé de la flexibilité de Git : elle permet de construire des commits précis et atomiques.
Dans le chapitre suivant, nous mettrons ces concepts en pratique en créant notre premier dépôt et en effectuant nos premières opérations : git init, git add, git commit, git status et git log.