Pull requests et revue de code#
Les pull requests sont la pierre angulaire du développement collaboratif moderne. Elles formalisent le processus par lequel un développeur propose d’intégrer ses modifications dans une branche partagée, en offrant un cadre structuré pour la discussion, la revue de code et la validation automatisée. Avant l’adoption généralisée des pull requests, les contributions étaient souvent envoyées par e-mail sous forme de patches, ou intégrées directement par un mainteneur de confiance sans revue systématique. L’essor des plateformes comme GitHub (2008) et GitLab (2011) a démocratisé ce mécanisme et en a fait une pratique standard.
Au-delà du simple mécanisme de fusion, les pull requests incarnent une philosophie de développement : chaque modification mérite d’être lue, discutée et validée avant d’atteindre la branche principale. Elles combinent revue humaine et vérifications automatisées (tests, linting, sécurité) pour garantir la qualité du code. Ce chapitre examine en détail leur anatomie, leur cycle de vie, les bonnes pratiques de revue, l’intégration continue et les différentes stratégies de fusion.
Anatomie d’une pull request#
Définition 40 (Pull request (PR))
Une pull request (abrégée PR) est une demande formelle de fusion d’une branche source vers une branche cible. Elle comprend un titre, une description, un ensemble de commits, un diff agrégé, une liste de relecteurs assignés, des étiquettes (labels), des vérifications automatisées (CI) et un fil de discussion. La PR sert à la fois de proposition technique et de support de communication entre les membres de l’équipe.
Une pull request se compose de plusieurs éléments qui, ensemble, fournissent tout le contexte nécessaire à la prise de décision :
Titre : résumé concis du changement en une ligne (par exemple : Ajouter la validation des emails à l’inscription).
Description : explication détaillée du quoi, du pourquoi et du comment tester. C’est le document de référence pour les relecteurs.
Diff : l’ensemble des modifications apportées, fichier par fichier, ligne par ligne. C’est le coeur technique de la PR.
Commits : la liste ordonnée des commits composant la PR. Chaque commit raconte une étape logique du développement.
Relecteurs (reviewers) : les personnes assignées pour examiner le code et donner leur approbation ou demander des modifications.
Étiquettes (labels) : des tags catégorisant la PR (bug, feature, documentation, breaking change, etc.).
Vérifications CI (checks) : les résultats des pipelines d’intégration continue déclenchés automatiquement.
Commentaires : les discussions en ligne, les suggestions de code et les fils de conversation attachés à des lignes spécifiques du diff.
Remarque 40
GitHub appelle ce mécanisme Pull Request, tandis que GitLab utilise le terme Merge Request (MR). Malgré cette différence terminologique, le concept est rigoureusement identique : une demande de fusion accompagnée d’un processus de revue. Bitbucket utilise également le terme Pull Request. Dans ce chapitre, nous employons le terme « pull request » ou « PR » par convention, mais tout ce qui est dit s’applique de manière équivalente aux merge requests de GitLab.
Cycle de vie visuel d’une PR#
Le diagramme suivant illustre les étapes successives par lesquelles passe une pull request, de la création de la branche jusqu’à sa suppression après fusion.
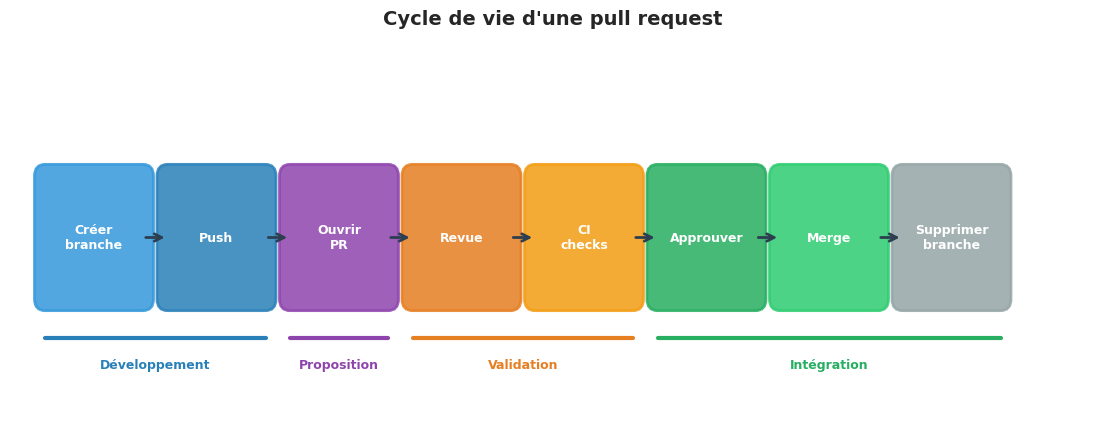
Le cycle de vie d’une PR#
Ouverture de la PR#
L’ouverture d’une pull request intervient une fois que le développeur a poussé sa branche de travail vers le dépôt distant. Il choisit alors la branche cible (généralement main ou develop), rédige un titre et une description, puis assigne des relecteurs. La qualité de la description est cruciale : c’est elle qui permet aux relecteurs de comprendre le contexte sans avoir à deviner l’intention derrière chaque ligne de code.
Une bonne description répond à trois questions fondamentales :
Quoi : quel changement est apporté ?
Pourquoi : quel problème résout-il, ou quelle fonctionnalité introduit-il ?
Comment tester : quelles étapes suivre pour vérifier que le changement fonctionne correctement ?
Revue de code#
La phase de revue est le coeur du processus. Les relecteurs examinent le diff, posent des questions, suggèrent des améliorations et identifient les éventuels problèmes. Sur GitHub comme sur GitLab, les commentaires peuvent être attachés à des lignes spécifiques du code, ce qui permet des discussions ciblées. Un relecteur peut émettre trois types de verdict :
Commentaire (Comment) : une remarque sans verdict formel, pour poser une question ou faire une suggestion mineure.
Approbation (Approve) : le relecteur estime que le code est prêt à être fusionné.
Demande de modifications (Request changes) : le relecteur identifie des problèmes qui doivent être corrigés avant la fusion.
Mise à jour de la PR#
Lorsque des modifications sont demandées, l’auteur apporte les corrections sur sa branche et pousse de nouveaux commits. La pull request se met à jour automatiquement : les nouveaux commits apparaissent dans le diff, et les vérifications CI se relancent. Il est courant de traverser plusieurs cycles revue-correction avant d’atteindre l’approbation.
Fusion#
Une fois que la PR est approuvée par le nombre requis de relecteurs et que toutes les vérifications CI sont au vert, la PR peut être fusionnée. Selon la stratégie de fusion choisie (voir la section dédiée plus bas), les commits de la branche sont intégrés dans la branche cible. La branche source est ensuite généralement supprimée pour garder le dépôt propre.
Exemple 12 (Modèle de description de PR)
Un bon modèle de description pour une pull request pourrait suivre cette structure :
Titre : Ajouter la validation des adresses email à l’inscription
Description :
What (Quoi) : Ajout d’une validation côté serveur pour les adresses email lors de l’inscription. Le validateur vérifie le format RFC 5322, la présence d’un enregistrement MX pour le domaine et rejette les adresses jetables.
Why (Pourquoi) : Issue #42 — Actuellement, les utilisateurs peuvent s’inscrire avec des adresses email invalides ou jetables, ce qui fausse nos métriques et empêche la communication avec les utilisateurs.
How to test (Comment tester) :
Lancer le serveur de développement avec
make dev.Tenter de s’inscrire avec une adresse invalide (ex.
test@invalid) — doit échouer.Tenter de s’inscrire avec une adresse jetable (ex.
test@yopmail.com) — doit échouer.S’inscrire avec une adresse valide — doit réussir.
Screenshots : (le cas échéant, captures d’écran de l’interface)
Bonnes pratiques de revue de code#
La revue de code est un exercice délicat qui demande autant de compétences humaines que techniques. Les pratiques suivantes, pour l’auteur comme pour le relecteur, permettent de rendre le processus efficace et bienveillant.
Pour l’auteur#
Garder les PRs petites et ciblées. Une PR ne devrait traiter qu’un seul sujet : une fonctionnalité, un correctif ou un refactoring. Une PR de 50 lignes sera relue en 10 minutes avec attention ; une PR de 2000 lignes sera survolée en 30 minutes avec résignation. Si un changement est trop volumineux, il est préférable de le découper en plusieurs PRs successives.
Rédiger une description claire. Comme vu précédemment, la description est le premier document que le relecteur lira. Elle doit être suffisamment détaillée pour qu’un collègue absent pendant une semaine comprenne le changement sans poser de questions.
Se relire avant de demander une revue. Avant d’assigner des relecteurs, l’auteur devrait parcourir son propre diff comme s’il le découvrait pour la première fois. Cette auto-revue permet de corriger les oublis évidents (fichiers de debug, commentaires temporaires, imports inutilisés) et d’anticiper les questions des relecteurs.
Répondre à tous les commentaires. Chaque commentaire mérite une réponse, même si c’est un simple « Corrigé dans le commit abc1234 » ou « Bonne remarque, j’ai créé une issue #99 pour traiter cela dans une prochaine PR ». Ignorer un commentaire donne l’impression que le retour n’est pas valorisé.
Pour le relecteur#
Être constructif, pas critique. La revue porte sur le code, pas sur la personne. Préférer « Que penses-tu de renommer cette variable pour plus de clarté ? » à « Ce nom est mauvais ». Les formulations interrogatives et les suggestions sont plus productives que les injonctions.
Se concentrer sur la logique, les bugs et la sécurité. Le style de formatage (indentation, espaces, longueur des lignes) devrait être géré par des outils automatisés (linters, formatters). Le relecteur humain apporte de la valeur sur ce que les machines ne savent pas (encore) bien faire : la cohérence architecturale, la gestion des cas limites, les failles de sécurité et la maintenabilité à long terme.
Approuver ou demander des modifications explicitement. Un simple commentaire « LGTM » (looks good to me) sans approbation formelle laisse la PR dans un état ambigu. Utiliser le mécanisme d’approbation de la plateforme pour que l’état de la PR soit clair pour tout le monde.
Remarque 41
La revue de code est une opportunité d’apprentissage bidirectionnelle. Un développeur junior apprend en relisant le code d’un senior — il découvre des patterns, des techniques et des conventions qu’il n’aurait pas rencontrés autrement. Inversement, un senior qui soumet son code à la revue d’un junior bénéficie d’un regard neuf : les questions « naïves » révèlent souvent des zones de complexité accidentelle ou un manque de documentation. Les meilleures équipes cultivent cette dynamique où tout le monde relit et se fait relire, indépendamment du niveau d’expérience.
Intégration continue (CI/CD)#
Définition 41 (Intégration continue (CI))
L”intégration continue (Continuous Integration, CI) est une pratique de développement logiciel dans laquelle chaque modification de code déclenche automatiquement un pipeline de vérifications : compilation, exécution des tests, analyse statique, vérification du formatage, scan de sécurité. L’objectif est de détecter les problèmes le plus tôt possible, avant qu’ils n’atteignent la branche principale. La CI est indissociable du processus de pull request : elle fournit un verdict objectif et reproductible sur la qualité du code proposé.
Les outils de CI les plus répandus sont :
GitHub Actions : intégré nativement à GitHub, configuré via des fichiers YAML dans
.github/workflows/.GitLab CI/CD : intégré à GitLab, configuré via un fichier
.gitlab-ci.ymlà la racine du dépôt.Jenkins : serveur CI/CD auto-hébergé, historiquement très utilisé en entreprise.
CircleCI, Travis CI, Azure Pipelines : autres solutions populaires, chacune avec ses particularités.
Un pipeline CI typique pour une pull request comprend les étapes suivantes :
Linting : vérification du style et de la syntaxe (ex.
flake8pour Python,eslintpour JavaScript).Tests unitaires : exécution de la suite de tests pour détecter les régressions.
Build : compilation ou construction du projet pour vérifier que le code est valide.
Scan de sécurité : détection de dépendances vulnérables ou de patterns dangereux dans le code.
Remarque 42
Une CI au vert est un prérequis non négociable pour la fusion. Ne jamais fusionner une PR dont le pipeline est en échec (une « PR rouge »), même si l’erreur semble sans rapport avec les modifications. Un test qui échoue signale soit une régression introduite par la PR, soit un test instable (flaky test) qu’il faut corriger. Dans les deux cas, fusionner en ignorant l’échec normalise le fait de travailler avec un pipeline cassé, ce qui érode progressivement la confiance dans la CI et finit par la rendre inutile.
Exemple 13 (Workflow GitHub Actions minimal)
Voici un exemple de fichier .github/workflows/ci.yml définissant un pipeline CI basique pour un projet Python :
```yaml name: CI
on: pull_request: branches: [main] push: branches: [main]
jobs: test: runs-on: ubuntu-latest steps: - uses: actions/checkout@v4
- name: Installer Python
uses: actions/setup-python@v5
with:
python-version: "3.12"
- name: Installer les dépendances
run: pip install -r requirements.txt
- name: Linting
run: flake8 src/
- name: Tests
run: pytest tests/ -v
```
Ce workflow se déclenche à chaque push ou pull request ciblant la branche main. Il installe les dépendances, vérifie le style avec flake8 et exécute les tests avec pytest. Si l’une de ces étapes échoue, le pipeline est marqué en échec et la PR affiche un indicateur rouge.
Stratégies de fusion des PRs#
Lorsqu’une PR est prête à être fusionnée, la plateforme propose généralement trois stratégies. Chacune produit un historique différent et convient à des situations distinctes.
Définition 42 (Merge commit (fusion classique))
La stratégie merge commit crée un commit de fusion qui possède deux parents : le dernier commit de la branche cible et le dernier commit de la branche source. L’intégralité de l’historique de la branche est préservée dans le graphe de commits. C’est l’équivalent de git merge --no-ff.
Définition 43 (Squash and merge)
La stratégie squash and merge compresse tous les commits de la branche source en un seul commit, qui est ajouté directement sur la branche cible. L’historique détaillé de la branche (commits intermédiaires, fixups, corrections de typos) disparaît au profit d’un unique commit propre et résumé.
Définition 44 (Rebase and merge)
La stratégie rebase and merge rejoue les commits de la branche source un par un au sommet de la branche cible, comme si le développement avait été effectué directement sur celle-ci. Chaque commit conserve son message et son contenu, mais reçoit un nouveau hash. Le résultat est un historique linéaire sans commit de fusion.
Le choix entre ces trois stratégies dépend du contexte :
Stratégie |
Historique |
Quand l’utiliser |
|---|---|---|
Merge commit |
Graphe complet avec branches visibles |
Quand l’historique de la branche a une valeur documentaire (ex. feature complexe avec étapes significatives) |
Squash and merge |
Un seul commit propre sur la branche cible |
Quand la branche contient de nombreux commits de travail en cours (WIP, fixup, « oups ») qui n’apportent rien à l’historique |
Rebase and merge |
Linéaire, chaque commit logique préservé |
Quand on souhaite un historique linéaire tout en conservant les commits individuels (chacun représentant un changement logique distinct) |
Remarque 43
La plupart des équipes choisissent une seule stratégie de fusion et s’y tiennent pour l’ensemble du projet. Cette cohérence simplifie la lecture de l’historique et évite les surprises lors de git log ou git bisect. Le choix le plus courant dans l’industrie est le squash and merge, car il produit un historique principal propre (un commit = une PR = un changement logique) tout en conservant l’historique détaillé dans l’interface de la plateforme. Les projets open source de grande envergure (comme le noyau Linux) préfèrent souvent le merge commit pour préserver la traçabilité complète.
Pour illustrer visuellement la différence entre ces trois stratégies, le diagramme suivant montre l’état de l’historique après fusion d’une branche feature contenant trois commits (C, D, E) dans main qui a continué à avancer (commit F).
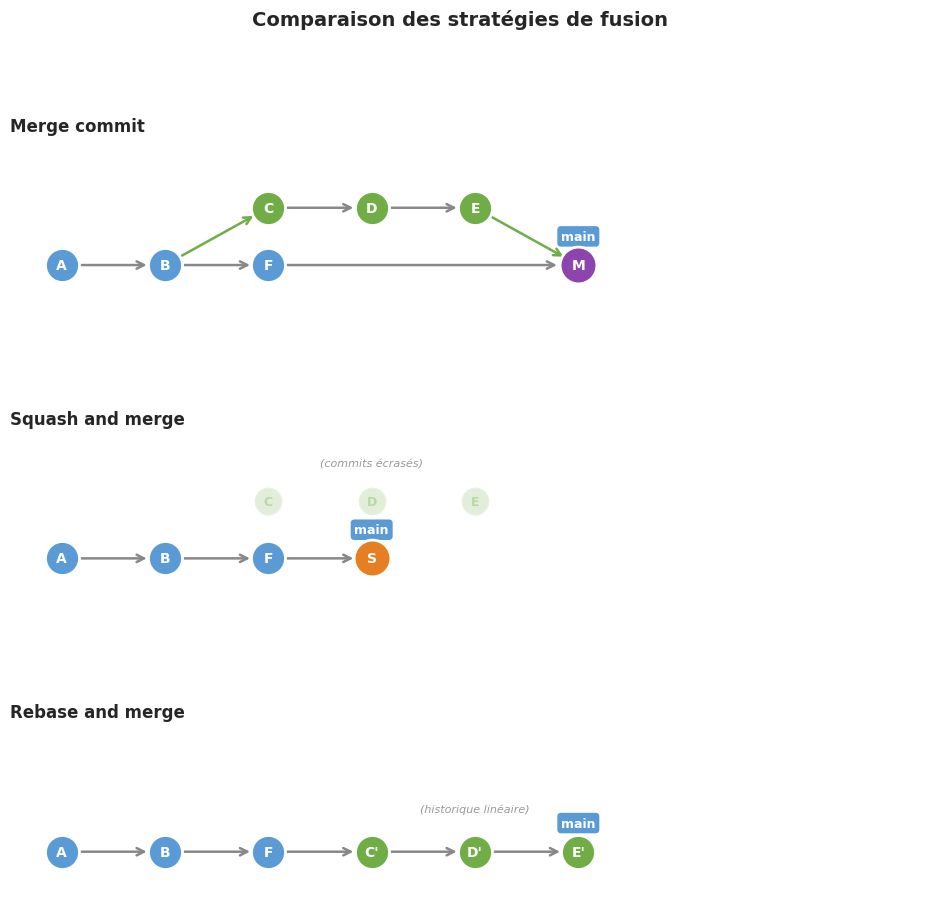
Résumé#
Ce chapitre a couvert le processus complet des pull requests et de la revue de code. Voici les points essentiels à retenir :
Une pull request est une demande formelle de fusion accompagnée d’un cadre de revue, de discussion et de validation automatisée. Elle se compose d’un titre, d’une description, d’un diff, de commits, de relecteurs, d’étiquettes et de vérifications CI.
Le cycle de vie d’une PR suit une progression claire : création de branche, push, ouverture de la PR, revue, corrections, approbation, fusion, suppression de la branche.
Pour l”auteur, les bonnes pratiques sont de garder les PRs petites, de rédiger des descriptions claires, de se relire avant de demander une revue et de répondre à tous les commentaires.
Pour le relecteur, il convient d’être constructif, de se concentrer sur la logique et la sécurité plutôt que le style, et d’utiliser les mécanismes formels d’approbation.
L”intégration continue (CI) automatise les vérifications (linting, tests, build, sécurité) et constitue un prérequis indispensable avant toute fusion.
Les trois stratégies de fusion — merge commit, squash and merge, rebase and merge — produisent des historiques différents. Le choix dépend du contexte, mais la cohérence au sein d’une équipe est primordiale.