Du Transformer au LLM#
Le chapitre 23 du volume Apprentissage automatique a introduit l’architecture Transformer : auto-attention multi-têtes, encodage positionnel, blocs encodeur-décodeur. Ce mécanisme, concu initialement pour la traduction automatiquée, s’est révélé être une brique de base extraordinairement polyvalente. Mais l’histoire ne s’arrête pas là. Entre 2018 et 2025, une série de découvertes empiriques a montré que l’augmentation simultanée de la taille des modèles, du volume de données et de la puissance de calcul faisait émerger des capacités qualitativement nouvelles, imprévisibles à petite échelle.
Ce passage à l’échelle — le scaling — constitue le fil conducteur de ce premier chapitre. Comprendre pourquoi un Transformer de 175 milliards de paramètres (GPT-3) se comporte différemment d’un Transformer de 117 millions (GPT-2), alors que l’architecture est essentiellement la même, est la question fondatrice du domaine des grands modèles de langage (Large Language Models, LLM). Les lois d’échelle (scaling laws) fournissent un cadre quantitatif pour y répondre, tandis que le débat sur l’émergence des capacités interroge la nature même de ce que ces modèles « apprennent ».
Ce chapitre pose les fondations conceptuelles du livre. Nous partirons de l’architecture Transformer pour expliquer ce qui change lorsqu’on augmente l’échelle de plusieurs ordres de grandeur. Nous formaliserons les lois de puissance qui relient performance, paramètres, données et calcul. Nous examinerons les principales familles de modèles et les benchmarks utilisés pour les évaluer. L’objectif est de donner au lecteur une carte mentale solide avant d’entrer dans les détails techniques des chapitres suivants.
Du Transformer au LLM : le passage à l’échelle#
L’architecture Transformer originale de Vaswani et al. (2017) comptait environ 65 millions de paramètres et était entrainée sur un corpus de traduction de quelques millions de paires de phrases. En l’espace de six ans, les modèles fondés sur cette même architecture ont vu leur taille multipliée par un facteur \(10\,000\) et leur corpus d’entrainement par un facteur comparable. Ce changement d’échelle n’est pas simplement quantitatif : il a engendre des comportements qualitativement différents.
Définition 1 (Grand modèle de langage (LLM))
Un grand modèle de langage (Large Language Model, LLM) est un modèle de langage neuronal fondé sur l’architecture Transformer (généralement dans sa variante décodeur seul), pré-entrainé sur un corpus textuel massif (typiquement des centaines de milliards à plusieurs milliers de milliards de tokens) par modélisation auto-regressive du langage. Les LLM se distinguent des modèles de langage antérieurs par leur taille (de l’ordre de \(10^{10}\) a \(10^{12}\) paramètres) et par les capacités émergentes que cette échelle leur confère, notamment le raisonnement en contexte (in-context learning), le suivi d’instructions et la génération de texte cohérent sur de longues séquences.
Définition 2 (Pré-entrainement)
Le pré-entrainement (pretraining) est la phase initiale d’entrainement d’un LLM, au cours de laquelle le modèle apprend è predire le token suivant è partir des tokens précédents sur un corpus textuel massif et non annoté. L’objectif est la maximisation de la log-vraisemblance auto-regressive :
Cette phase, extrêmement coûteuse en calcul (de l’ordre de \(10^{23}\) a \(10^{25}\) FLOPs pour les plus grands modèles), produit un modèle de base (base model) qui capture la structure statistique du langage et encode une vaste quantité de connaissances factuelles.
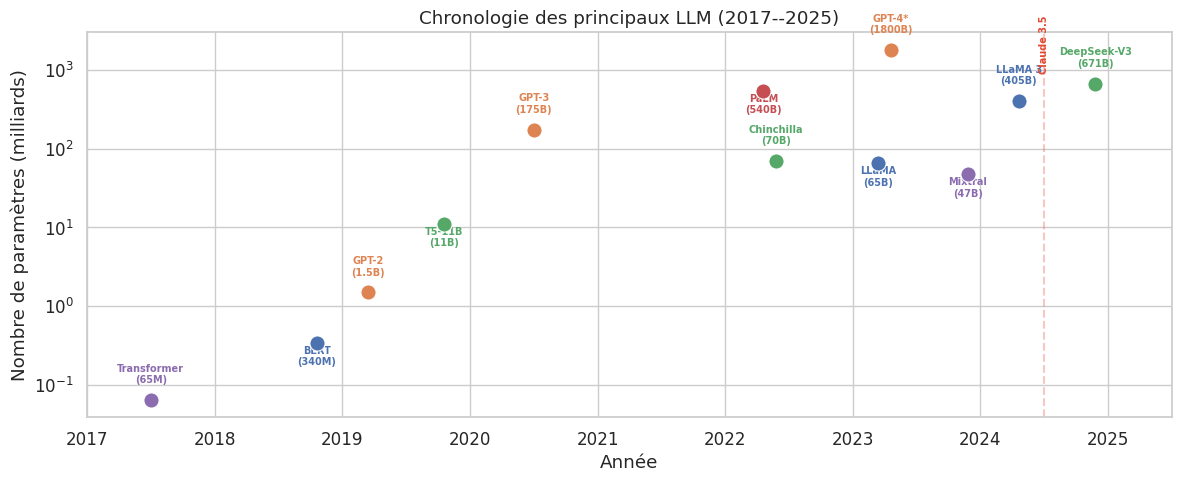
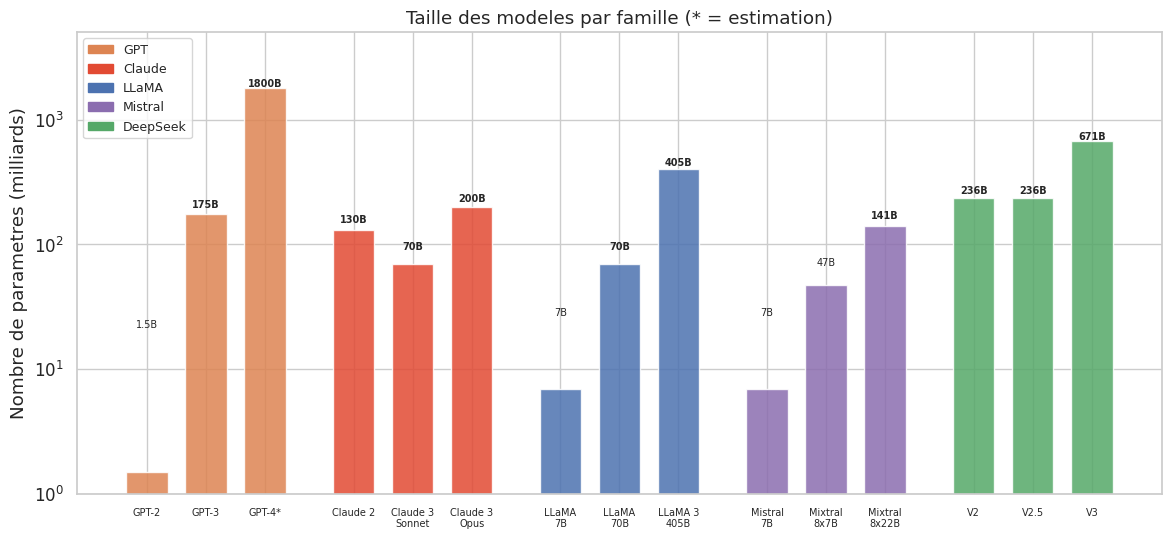
Le mécanisme central est simple : on empile davantage de blocs Transformer (profondeur), on augmente la dimension cachée \(d_{\text{model}}\) (largeur), et on entraine sur plus de texte pendant plus longtemps. Le nombre de paramètres d’un Transformer décodeur seul scale approximativement comme \(N \approx 12 \, L \, d_{\text{model}}^2\), où \(L\) est le nombre de couches. Passer de \(d_{\text{model}} = 768\) et \(L = 12\) (BERT-base, 110M paramètres) a \(d_{\text{model}} = 12\,288\) et \(L = 96\) (GPT-3, 175B paramètres) represente un facteur \(\times 1\,600\) en nombre de paramètres.
Remarque 1 (Budget de calcul)
Le coût d’entrainement d’un LLM est dominé par les multiplications matricielles dans les couches d’attention et les couches feed-forward. Pour un modèle de \(N\) paramètres entrainé sur \(D\) tokens, le nombre d’opérations en virgule flottante est approximativement \(C \approx 6ND\) (en comptant le passage avant et le passage arrière). Ainsi, entrainer GPT-3 (\(N = 175 \times 10^9\), \(D \approx 300 \times 10^9\) tokens) a necessité environ \(C \approx 3{,}14 \times 10^{23}\) FLOPs, soit plusieurs semaines sur des milliers de GPU.
Exemple 1 (Ordres de grandeur)
Pour fixer les idées, voici quelques ordres de grandeur représentatifs :
Modèle |
Année |
Paramètres |
Tokens d’entrainement |
Compute (FLOPs) |
|---|---|---|---|---|
Transformer original |
2017 |
65M |
~100M |
~\(10^{18}\) |
BERT-base |
2018 |
110M |
~3,3B |
~\(10^{19}\) |
GPT-2 |
2019 |
1,5B |
~10B |
~\(10^{20}\) |
GPT-3 |
2020 |
175B |
300B |
~\(3 \times 10^{23}\) |
Chinchilla |
2022 |
70B |
1,4T |
~\(5 \times 10^{23}\) |
LLaMA 2 |
2023 |
70B |
2T |
~\(10^{24}\) |
GPT-4 |
2023 |
~1,8T (estimé) |
~13T (estimé) |
~\(10^{25}\) |
On constate que la taille des modèles et des corpus a augmenté de manière exponentielle, avec un doublement tous les 6 a 12 mois — un rythme bien plus rapide que la loi de Moore.
Lois d’échelle (Scaling Laws)#
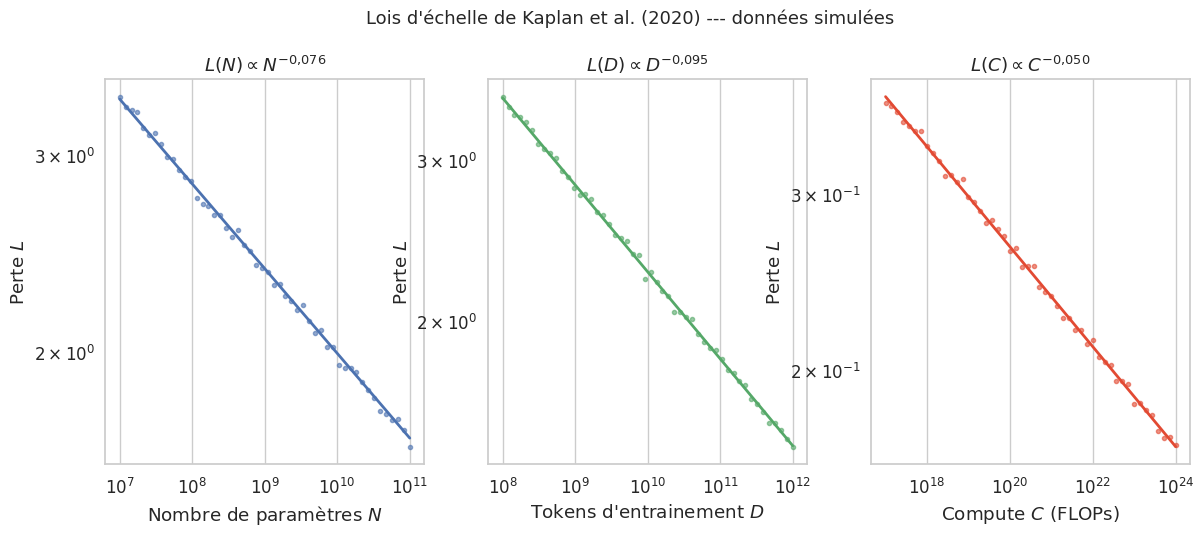
L’une des découvertes les plus importantes de la recherche sur les LLM est que la performance des modèles de langage suit des lois de puissance (power laws) remarquablement regulières lorsqu’on augmente la taille du modèle, le volume de données ou le budget de calcul. Ces relations empiriques, appelées lois d’échelle (scaling laws), permettent de prédire la performance d’un modèle avant même de l’entrainer.
Définition 3 (Lois d’échelle (Scaling Laws))
Les lois d’échelle (scaling laws) des modèles de langage sont des relations empiriques de type loi de puissance reliant la perte du modèle (entropie croisée sur un ensemble de test) à trois facteurs :
Le nombre de paramètres \(N\) : \(L(N) = \left(\frac{N_c}{N}\right)^{\alpha_N}\), avec \(\alpha_N \approx 0{,}076\)
Le volume de données \(D\) (en tokens) : \(L(D) = \left(\frac{D_c}{D}\right)^{\alpha_D}\), avec \(\alpha_D \approx 0{,}095\)
Le budget de calcul \(C\) (en FLOPs) : \(L(C) = \left(\frac{C_c}{C}\right)^{\alpha_C}\), avec \(\alpha_C \approx 0{,}050\)
ou \(N_c\), \(D_c\), \(C_c\) sont des constantes et \(\alpha_N\), \(\alpha_D\), \(\alpha_C\) sont les exposants de la loi de puissance. Ces relations sont observées sur plusieurs ordres de grandeur et semblent indépendantes de détails architecturaux (nombre de couches vs largeur, type de tokenisation, etc.).
Propriété 1 (Loi de puissance et linéarité en log-log)
Une loi de puissance \(L(x) = a \, x^{-\alpha}\) se traduit par une relation linéaire en échelle logarithmique :
C’est cette linéarité en graphe log-log qui rend les lois d’échelle si frappantes et si utiles : en mesurant la perte pour quelques valeurs de \(x\) (paramètres, données ou compute), on peut extrapoler à des échelles bien plus grandes par simple régression linéaire. La pente de la droite donne directement l’exposant \(\alpha\), qui mesure la « rentabilité » de l’augmentation de l’échelle.
L’optimum de Chinchilla#
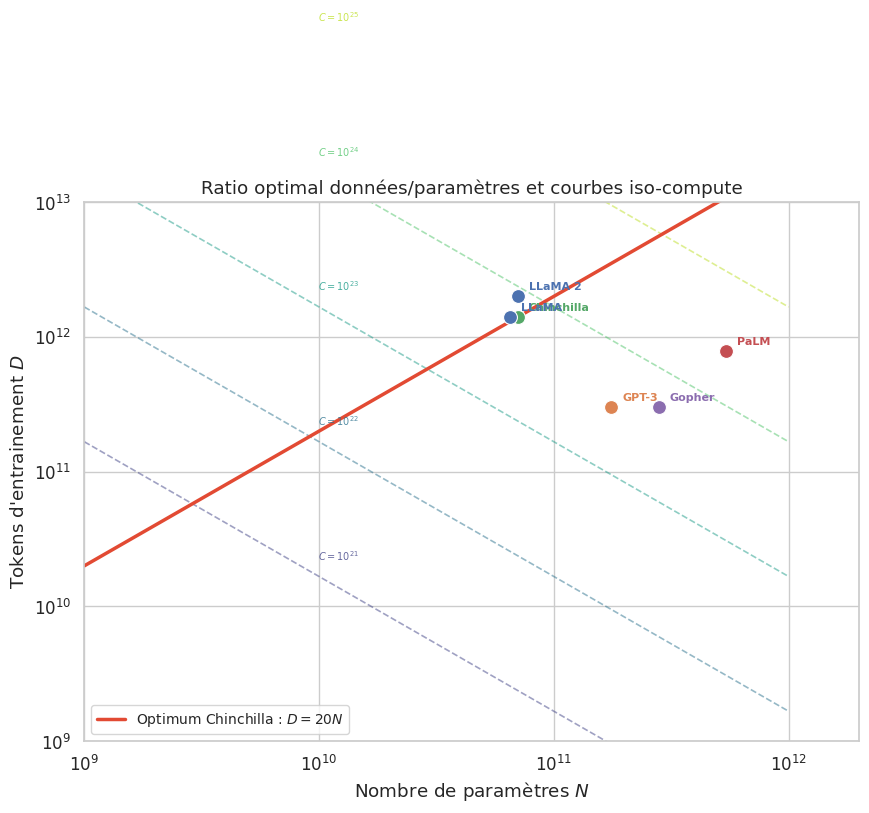
Les travaux de Kaplan et al. (2020) suggéraient que, pour un budget de calcul fixe, il valait mieux investir dans un modèle plus grand entrainé sur relativement peu de données. Hoffmann et al. (2022), dans l’article dit « Chinchilla », ont contesté cette conclusion en montrant que les modèles existants étaient significativement sous-entrainés : pour un budget de calcul optimal, le nombre de paramètres et le nombre de tokens doivent croitre au même rythme.
Définition 4 (Loi de Chinchilla (ratio optimal))
Le résultat central de Hoffmann et al. (2022) est que, pour un budget de calcul \(C\) donné, la perte minimale est atteinte lorsque le nombre de paramètres \(N\) et le nombre de tokens \(D\) sont choisis de manière proportionnelle :
Autrement dit, un modèle de \(N\) paramètres devrait être entrainé sur environ \(20N\) tokens pour exploiter optimalement le budget de calcul. Cette relation implique que \(N_{\text{opt}} \propto C^{0{,}5}\) et \(D_{\text{opt}} \propto C^{0{,}5}\) : paramètres et données doivent croître à parts égales avec le compute.
Remarque 2 (Chinchilla vs Kaplan)
La différence entre les recommandations de Kaplan et celles de Chinchilla est considérable en pratique. Kaplan suggérait d’allouer la majeure partie du budget à la taille du modèle (\(N \propto C^{0{,}73}\)), tandis que Chinchilla montre que l’allocation optimale est \(N \propto C^{0{,}5}\). Concrètement, GPT-3 (175B parametres, 300B tokens) était largement sous-entrainé selon le critère de Chinchilla : il aurait fallu environ \(20 \times 175B = 3{,}5T\) tokens. Le modèle Chinchilla (70B parametres, 1,4T tokens) atteint des performances comparables a Gopher (280B parametres, 300B tokens) avec quatre fois moins de paramètres, simplement en équilibrant le ratio données/paramètres.
Emergence de capacités#
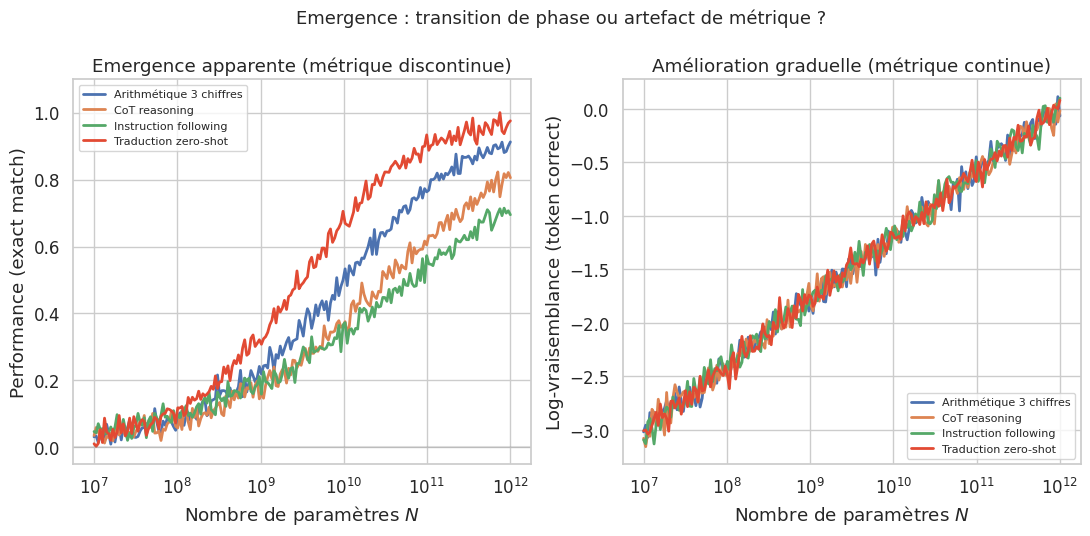
L’un des phénomènes les plus débattus dans la recherche sur les LLM est l”émergence de capacités à grande échelle. Certaines tâches semblent impossibles pour des modèles de petite taille, puis deviennent soudainement réalisables lorsque le modèle dépasse un seuil critique de paramètres ou de compute.
Définition 5 (Capacités émergentes)
Une capacité émergente (emergent ability) d’un LLM est une capacité qui est absente dans les modèles de petite taille mais qui apparait dans les modèles de grande taille. Plus formellement, Wei et al. (2022) définissent une capacité comme émergente si sa performance est proche du hasard pour des modèles en dessous d’un certain seuil d’échelle, puis augmente brusquement au-dela de ce seuil. Cette transition evoque les transitions de phase en physique statistique, ou un changement quantitatif (la température) engendre un changement qualitatif (le passage de l’état liquide à l’état gazeux).
Exemple 2 (Exemples de capacités émergentes)
Parmi les capacités fréquemment citées comme émergentes :
Raisonnement en chaine de pensée (Chain-of-Thought, CoT) : la capacité à décomposer un problème en étapes intermediaires n’apparait de manière fiable qu’au-delà d’environ \(10^{11}\) paramètres (Wei et al., 2022). Les petits modèles ne bénéficient pas du prompt « Réflechissons étape par étape ».
Apprentissage en contexte (in-context learning) : la capacité à réaliser une tâche à partir de quelques exemples dans le prompt, sans mise à jour des poids. Ce comportement, documenté par Brown et al. (2020) pour GPT-3, est quasi absent dans GPT-2.
Suivi d’instructions (instruction following) : la capacité à comprendre et exécuter des instructions en langue naturelle, qui émerge après un alignement par RLHF sur des modèles suffisamment grands.
Arithmétique multi-chiffres : la multiplication de nombres à 3+ chiffres échoue à petite echelle puis réussit de manière fiable au-delà d’un seuil de taille.
Remarque 3 (Modèle de fondation)
Le terme modèle de fondation (foundation model), introduit par Bommasani et al. (2021), désigne un modèle pré-entrainé à grande échelle sur des données larges et non spécifiques, qui peut ensuite être adapté à une varieté de tâches en aval. Les LLM sont les exemples les plus emblématiques de modèles de fondation, mais le concept s’étend aux modèles multimodaux (texte + image), aux modèles de code et aux modèles scientifiques. Le terme souligne que ces modèles servent de « fondation » a un écosystème entier d’applications, et que leurs biais et limitations se propagent à toutes les utilisations en aval.
Le débat sur la réalité de l’émergence reste ouvert. Schaeffer et al. (2023) ont montré que l’émergence apparente peut être un artefact du choix de la métrique : lorsqu’on remplace une métrique discontinue (exact match) par une metrique continue (log-vraisemblance du token correct), la transition brusque disparait au profit d’une amélioration graduelle. Néanmoins, même si l’émergence « au sens strict » est contestée, il reste indéniable que les grands modèles manifestent des capacités absentes chez les petits — la question est de savoir si cette transition est réellement abrupte ou simplement graduelle et amplifiée par le choix de métrique.
Familles de modèles#
Le paysage des LLM est structuré autour de quelques grandes familles, distinguées par leur architecture (encodeur, décodeur, ou les deux), leur régime d’accès (ouvert ou fermé) et leur stratégie d’échelle (dense ou par mélange d’experts).
Architecture : encodeur, décodeur, encodeur-décodeur#
Le Transformer original comportait un encodeur et un décodeur, mais les LLM modernes utilisent majoritairement le décodeur seul (decoder-only). Ce choix est motivé par sa simplicité et son adéquation à la génération auto-régressive.
Encodeur seul : BERT, RoBERTa. L’attention est bidirectionnelle. Adapté à la classification, l’extraction d’entités, etc. Ces modèles ne sont généralement pas classés parmi les LLM au sens strict.
Décodeur seul : GPT, Claude, LLaMA, Mistral. L’attention est causale (masque triangulaire). C’est l’architecture dominante pour les LLM génératifs.
Encodeur-decodeur : T5, BART, UL2. L’encodeur utilise une attention bidirectionnelle, le décodeur une attention causale. Adapté aux tâches de transformation texte-a-texte.
Dense vs Mixture of Experts (MoE)#
Définition 6 (Mélange d’experts (MoE))
Une architecture Mixture of Experts (MoE) remplace les couches feed-forward denses du Transformer par un ensemble de \(E\) sous-réseaux « experts », parmi lesquels seuls \(k \ll E\) sont actives pour chaque token. Un réseau de routage (gating network) détermine quels experts sont actifs :
L’avantage est que le nombre total de paramètres est très grand (capacité du modèle), mais le coût de calcul par token ne dépend que de \(k\) experts actifs. Ainsi, Mixtral 8x7B possède 47B de paramètres totaux mais n’en active qu’environ 13B par token, offrant un compromis favorable entre capacité et efficacité.
Remarque 4 (Dense vs MoE)
Les modèles denses activent tous leurs paramètres pour chaque token, ce qui rend le coût de calcul proportionnel a \(N\). Les modèles MoE décorrellent la taille du modèle du coût de calcul : un MoE de 1 000B de paramètres totaux peut avoir un coût d’inférence comparable à un modèle dense de 100B. C’est cette propriété qui a motivé le développement de modèles comme Switch Transformer (Google, 2021), Mixtral (Mistral AI, 2023) et DeepSeek-V3 (2024). Le principal defi des MoE est l’équilibrage de la charge (load balancing) : il faut éviter que certains experts soient systématiquement sous-utilisés tandis que d’autres sont surchargés.
Principales familles#
Exemple 3 (Familles de modèles)
Famille |
Organisation |
Architecture |
Accès |
Tailles notables |
|---|---|---|---|---|
GPT |
OpenAI |
Décodeur dense |
Fermé (API) |
GPT-3 (175B), GPT-4 (~1,8T MoE*) |
Claude |
Anthropic |
Décodeur dense |
Fermé (API) |
Claude 3 Opus, Claude 3.5 Sonnet |
LLaMA |
Meta |
Décodeur dense |
Ouvert (poids) |
LLaMA 2 (7/13/70B), LLaMA 3 (8/70/405B) |
Mistral |
Mistral AI |
Décodeur dense + MoE |
Ouvert (poids) |
Mistral 7B, Mixtral 8x7B, Mixtral 8x22B |
Gemini |
Décodeur dense (MoE*) |
Fermé (API) |
Gemini 1.5 Pro, Gemini Ultra |
|
DeepSeek |
DeepSeek |
Décodeur MoE |
Ouvert (poids) |
DeepSeek-V2 (236B), DeepSeek-V3 (671B) |
Qwen |
Alibaba |
Décodeur dense + MoE |
Ouvert (poids) |
Qwen 2.5 (7/72B), Qwen-MoE |
*Les détails architecturaux exacts de GPT-4 et Gemini ne sont pas publiés ; les valeurs sont des estimations de la communauté.
Remarque 5 (Modèles ouverts vs fermés)
La distinction entre modèles ouverts (open-weight) et fermés (closed) est structurante pour le domaine. Les modèles ouverts (LLaMA, Mistral, DeepSeek) publient leurs poids et permettent l’inspection, le fine-tuning et le déploiement local. Les modèles fermés (GPT-4, Claude, Gemini) ne sont accessibles que via des API et leurs détails internes sont confidentiels. Cette tension entre ouverture et contrôle a des implications majeures pour la reproductibilité scientifique, la sécurité et l’innovation. On notera que « open-weight » n’est pas synonyme de « open-source » : les poids sont publiés mais les données d’entrainement et le code restent souvent propriétaires.
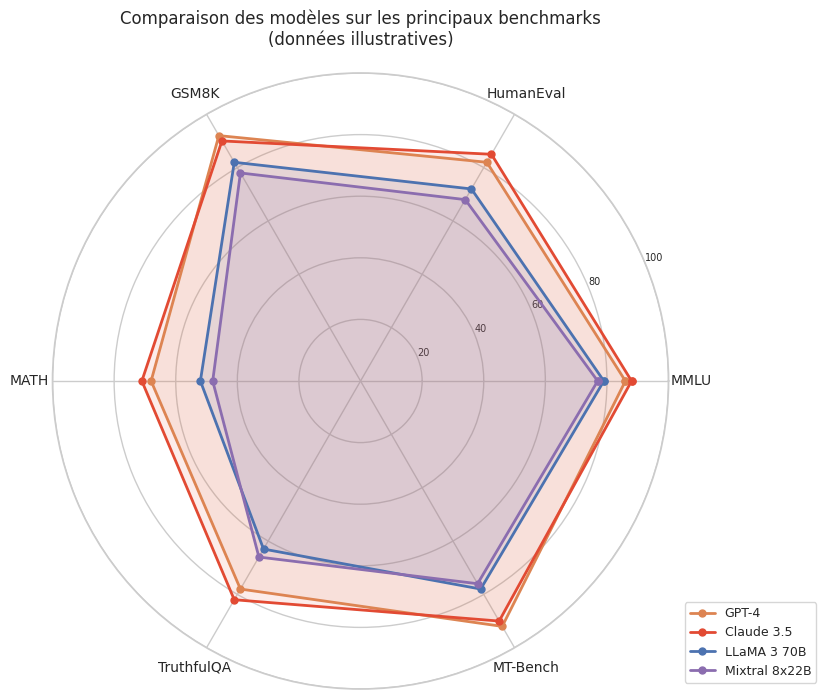
Benchmarks et évaluation#
L’évaluation des LLM est un problème ouvert et fondamental. A mesure que les modèles progressent, les benchmarks existants saturent et de nouveaux sont créés, dans une dynamique de « course aux armements » entre capacités des modèles et difficulté des évaluations.
Définition 7 (Benchmark)
Un benchmark est un ensemble de tâches standardisées, accompagne d’un protocole d’évaluation et d’une métrique, utilisé pour mesurer et comparer les performances des modèles. Un bon benchmark doit être discriminant (séparer les modèles de niveaux différents), reproductible (protocole fixé et données publiques), représentatif (couvrir des capacités pertinentes) et résistant à la contamination (les données de test ne doivent pas se retrouver dans les données d’entrainement).
Exemple 4 (Principaux benchmarks pour LLM)
Benchmark |
Domaine |
Metrique |
Description |
|---|---|---|---|
MMLU |
Connaissances générales |
Accuracy (QCM) |
57 matières, du lycée au doctorat |
HumanEval |
Code |
pass@k |
Génération de fonctions Python |
GSM8K |
Mathématiques (primaire) |
Exact match |
Problèmes de maths a 2-8 étapes |
MATH |
Mathématiques (avancé) |
Exact match |
Problèmes de compétitions mathématiques |
TruthfulQA |
Véracité |
BLEURT / juge |
Résistance aux idees reçues fausses |
MT-Bench |
Conversation |
Score LLM-juge |
Evaluation multi-tour par un LLM juge |
Chatbot Arena |
Général |
Elo (votes humains) |
Comparaisons par paires par des utilisateurs |
GPQA |
Sciences (expert) |
Accuracy (QCM) |
Questions de niveau doctorat en sciences |
ARC-AGI |
Raisonnement abstrait |
Exact match |
Analogies visuelles de type QI |
Chaque benchmark éclaire une facette différente des capacités du modèle. Aucun benchmark unique ne suffit à capturer la « qualité » globale d’un LLM.
Remarque 6 (Contamination des données)
La contamination des données (data contamination) est un problème majeur pour l’évaluation des LLM. Comme les corpus d’entrainement contiennent une part substantielle du web, il est possible — voire probable — que des questions et réponses de benchmarks s’y trouvent. Un modèle qui a « vu » les réponses pendant l’entrainement obtiendra un score artificiellement élevé. Ce problème est aggravé par l’opacité des corpus d’entrainement des modèles fermés. Des stratégies d’atténuation existent (déduplication, canary strings, benchmarks dynamiques comme Chatbot Arena), mais aucune n’est parfaite. La contamination est l’une des raisons pour lesquelles les classements sur les benchmarks statiques doivent être interprétés avec prudence.
Un autre phénomène préoccupant est la saturation des benchmarks. MMLU, longtemps considéré comme un objectif ambitieux, est désormais approché ou dépassé par les meilleurs modèles (>90% de precision). GSM8K, conçu pour être difficile en 2021, est aujourd’hui résolu à plus de 95% par GPT-4 et Claude 3.5. Cette saturation nécessite la création continue de benchmarks plus difficiles (GPQA, ARC-AGI, Frontier Math) et alimente le debat sur ce que les scores mesurent réellement.
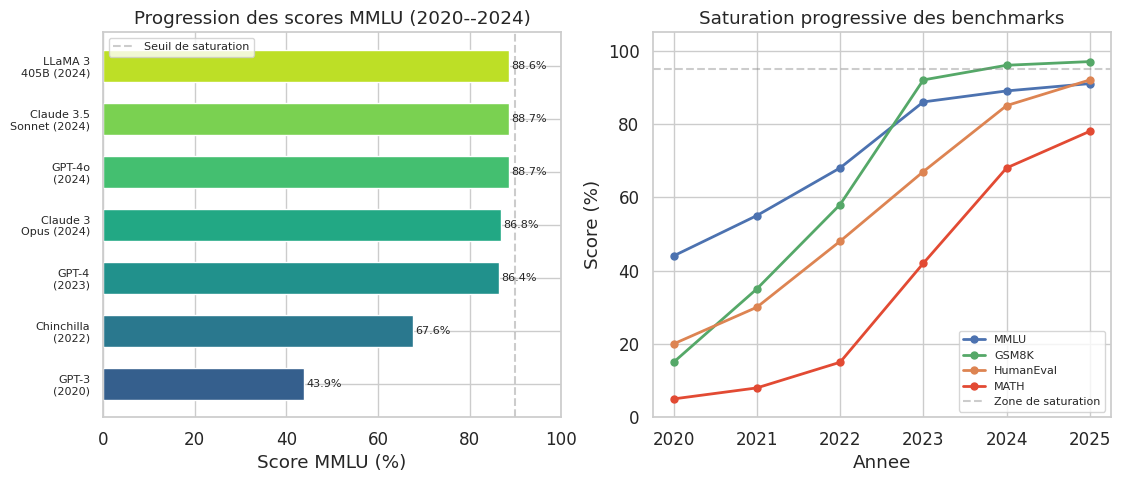
Résumé#
Ce chapitre a tracé le chemin qui mène de l’architecture Transformer (chapitre 23 du volume précédent) aux grands modèles de langage qui définissent l’état de l’art actuel.
Un LLM est un Transformer décodeur seul de grande taille (\(\geq 10^{10}\) paramètres), pré-entrainé par modélisation auto-régressive du langage sur un corpus massif. L’architecture reste fondamentalement celle de Vaswani et al. (2017) ; c’est l”échelle qui change tout.
Les lois d’échelle de Kaplan et al. (2020) montrent que la perte suit des lois de puissance en fonction du nombre de paramètres (\(L \propto N^{-0{,}076}\)), du volume de données (\(L \propto D^{-0{,}095}\)) et du budget de calcul (\(L \propto C^{-0{,}050}\)). Ces relations, linéaires en échelle log-log, permettent de prédire la performance à grande échelle.
La loi de Chinchilla (Hoffmann et al., 2022) établit que le ratio optimal est \(D \approx 20N\) : un modèle doit être entrainé sur environ 20 tokens par paramètre. Ce résultat a montré que GPT-3 était sous-entrainé et a réorienté les stratégies d’entrainement vers un meilleur équilibre données/paramètres.
Les capacités émergentes — raisonnement en chaine de pensée, apprentissage en contexte, suivi d’instructions — apparaissent au-delà de certains seuils d’échelle. Le débat sur la realité de l’émergence (transition de phase vs artefact de métrique) reste ouvert mais stimulant.
Le paysage des LLM est structuré autour de grandes familles (GPT, Claude, LLaMA, Mistral, Gemini, DeepSeek), distinguées par leur architecture (décodeur dense vs MoE), leur régime d’accès (ouvert vs fermé) et leur stratégie d’échelle.
L”évaluation des LLM repose sur une batterie de benchmarks (MMLU, HumanEval, GSM8K, MATH, TruthfulQA, MT-Bench, Chatbot Arena) dont aucun ne capture à lui seul la qualité globale d’un modèle. Les problèmes de contamination des données et de saturation des benchmarks imposent une interprétation prudente des classements.
Le coût d’entrainement, approximativement \(C \approx 6ND\) FLOPs, est un facteur déterminant qui structure la recherche : seules quelques organisations disposent des ressources nécessaires pour entrainer les plus grands modèles, ce qui souleve des questions d’accès, de reproductibilité et de concentration du pouvoir technologique.