Mémoire conversationnelle#
Les grands modèles de langage (LLM) sont par nature sans état : chaque appel à l’API constitue une transaction indépendante, sans aucun souvenir des échanges précédents. Cette propriété, héritée de l’architecture Transformer sous-jacente, pose un défi fondamental dès lors que l’on souhaite construire des systèmes conversationnels cohérents sur la durée. Comment un assistant peut-il se souvenir de ce que l’utilisateur a dit cinq, dix ou cent tours de conversation plus tôt ?
La mémoire conversationnelle désigne l’ensemble des mécanismes qui permettent de maintenir un contexte au fil d’une intéraction multi-tours avec un LLM. Ces mécanismes vont du plus simple — stocker l’intégralité des messages — au plus sophistiqué — résumer, compresser, extraire des entités et persister des informations dans des bases de données externes. Le choix d’une stratégie de mémoire est un compromis entre fidélité (ne rien perdre d’important), efficacité (minimiser la consommation de tokens) et pertinence (ne fournir au modèle que les informations utiles à la requête courante).
Ce chapitre explore les principales stratégies de mémoire conversationnelle, depuis le tampon brut jusqu’aux architectures hiérarchiques à long terme. Pour chaque approche, nous formalisons le fonctionnement, analysons les compromis et fournissons une implémentation Python exécutable. Nous terminons par une comparaison empirique sur une conversation simulée de trente tours.
Le problème de la mémoire dans les LLM#
Un LLM de type Transformer traite une séquence de tokens en entrée et produit une séquence en sortie. A chaque appel, le modèle reçoit la totalité du contexte nécessaire dans le prompt : il n’a pas d’état interne persistant entre deux appels. Si l’on souhaite qu’un LLM « se souvienne » d’un échange précédent, il faut explicitement inclure cet échange dans le prompt de l’appel suivant.
Définition 45 (Mémoire conversationnelle)
La mémoire conversationnelle est un mécanisme logiciel qui gère l’historique des messages échangés entre un utilisateur et un LLM, et qui construit le contexte fourni au modèle à chaque nouveau tour de conversation. Formellement, soit \(\mathcal{H}_t = \{(r_1, a_1), \ldots, (r_t, a_t)\}\) la séquence des \(t\) paires (requête, réponse) échangées. La mémoire est une fonction
qui transforme l’historique complet en un contexte \(\mathcal{C}_t\) de taille bornée, fourni au modèle pour générer la réponse \(a_{t+1}\).
La contrainte fondamentale est la fenêtre de contexte du modèle. Chaque LLM possède une longueur maximale \(L\) (en tokens) pour la séquence d’entrée. Même lorsque la fenêtre est très large (128k ou 1M tokens), inclure un historique volumineux a des conséquences directes :
Coût : la facturation des API est proportionnelle au nombre de tokens en entrée.
Latence : le temps d’inférence croit avec la longueur du contexte (complexité quadratique de l’attention).
Dégradation : la qualité des réponses se dégrade pour les contextes très longs, en particulier pour les informations situées au milieu de la fenêtre (lost in the middle).
Remarque 55
La fenêtre de contexte d’un LLM est analogue à la mémoire de travail en psychologie cognitive : elle est limitée en capacité et nécessite des stratégies actives de gestion pour être utilisée efficacement. Tout comme un humain ne peut pas retenir simultanément des centaines d’informations, un LLM ne peut pas traiter un contexte arbitrairement long sans perte de performance. Les stratégies de mémoire conversationnelle sont l’équivalent computationnel des stratégies mnémotechniques humaines.
Définition 46 (Taux de compression mémorielle)
Le taux de compression d’une stratégie de mémoire \(M\) au tour \(t\) est défini par :
Pour la mémoire tampon, \(\rho_t = 1\) (aucune compression). Pour une fenêtre de taille \(K\), \(\rho_t = \min(1,\, K/t)\). Un bon mécanisme de mémoire minimise \(\rho_t\) tout en maximisant la rétention d’information pertinente.
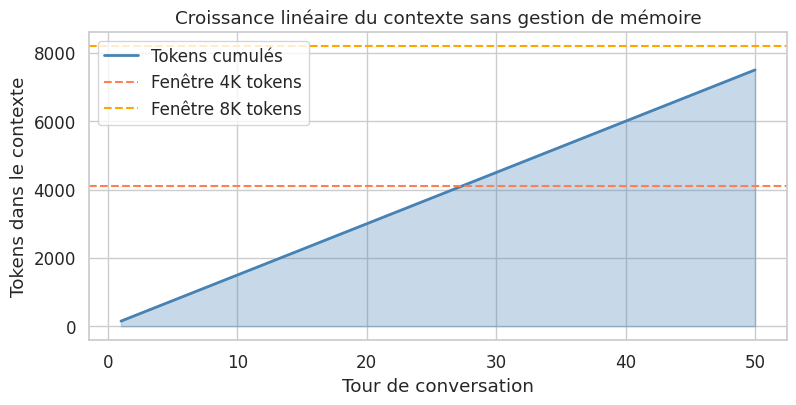
Le graphique illustre le problème : sans gestion de mémoire, le nombre de tokens croit linéairement. Après environ 27 tours (à 150 tokens par tour), on dépasse la fenêtre de 4096 tokens.
Mémoire tampon (buffer memory)#
La stratégie la plus naive consiste a conserver l’integralité des messages échangés et à les injecter tels quels dans le prompt.
Définition 47 (Mémoire tampon)
La mémoire tampon (buffer memory) stocke l’historique complet sans transformation. Le contexte fourni au modèle est la concatenation de tous les messages :
où \(\oplus\) designe la concaténation et \(\|\) le séparateur entre requête et réponse. La taille du contexte est \(|\mathcal{C}_t| = \sum_{i=1}^{t} (|r_i| + |a_i|)\), qui croit linéairement avec \(t\).
Cette approche a le mérite de la fidélité totale : aucune information n’est perdue. Cependant, lorsque \(|\mathcal{C}_t| > L\), il faut tronquer les messages les plus anciens.
Exemple 36 (Implémentation d’une mémoire tampon)
La classe ConversationBufferMemory stocke les messages et retourne un contexte tronqué par l’avant si la limite de tokens est atteinte :
memory = ConversationBufferMemory(max_tokens=4096)
memory.add_message("user", "Bonjour, je suis Alice.")
memory.add_message("assistant", "Bonjour Alice !")
context = memory.get_context() # tout l'historique, tronque si > 4096 tokens
Messages : 6 | Tokens : 95
[user] Bonjour, je m'appelle Alice et je travaille chez Acme Corp.
[assistant] Bonjour Alice ! Ravi de vous rencontrer. Comment puis-je vous aider ?
[user] Je cherche des informations sur le machine learning.
[assistant] Le machine learning est un sous-domaine de l'IA qui permet aux systèmes d'apprendre.
[user] Quels sont les principaux types d'apprentissage ?
[assistant] On distingue l'apprentissage supervisé, non supervisé et par renforcement.
Fenêtre glissante (sliding window)#
Pour éviter la croissance indéfinie du contexte, une approche courante consiste a ne conserver que les \(K\) derniers tours de conversation.
Définition 48 (Mémoire à fenêtre glissante)
La mémoire à fenêtre glissante (sliding window memory) conserve uniquement les \(K\) derniers echanges :
La taille du contexte est bornée : \(|\mathcal{C}_t| \leq K \cdot \bar{s}\) ou \(\bar{s}\) est la taille moyenne d’un échange.
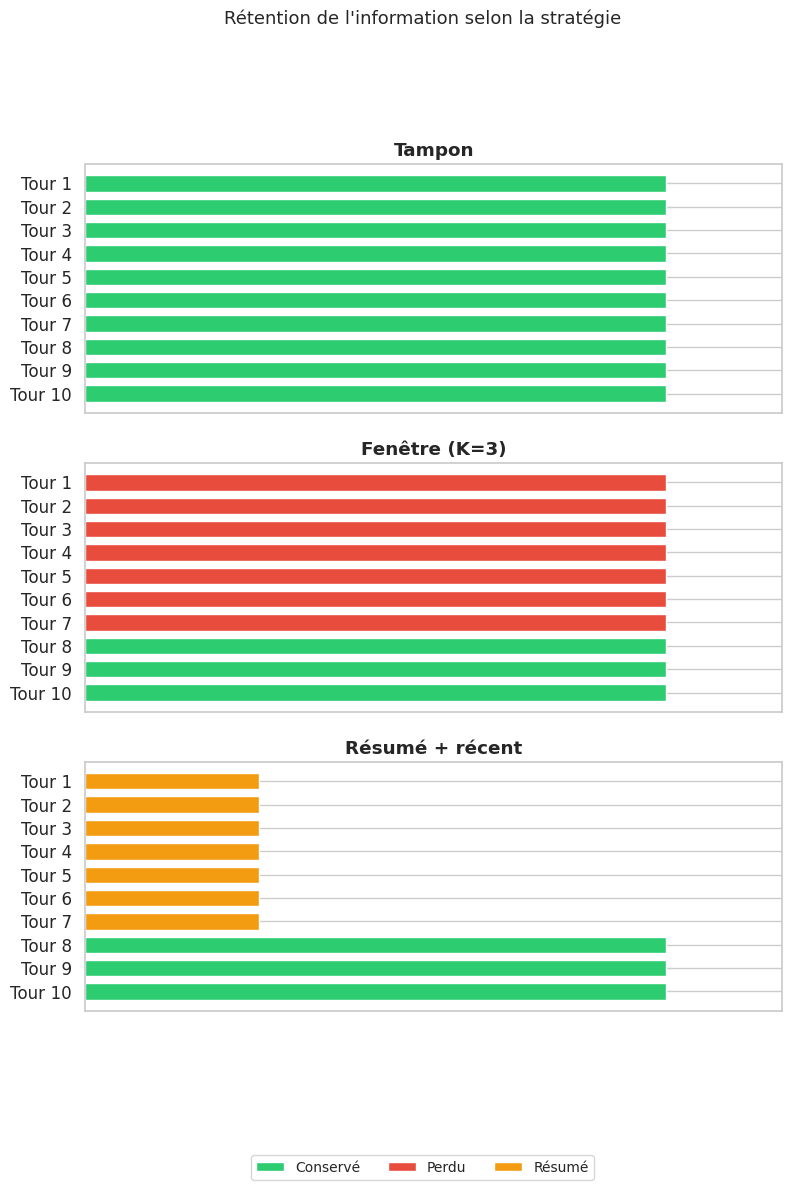
L’avantage principal est la prévisibilité : la consommation de tokens est bornée indépendamment de la longueur de la conversation. En revanche, toute information mentionnée avant les \(K\) derniers tours est définitivement perdue.
Remarque 56
La perte d’information dans la fenêtre glissante est abrupte : un message est soit entièrement présent, soit entièrement absent du contexte. Cela pose problème lorsque des informations critiques (nom de l’utilisateur, sujet initial) ont été mentionnées dans les premiers tours. Le modèle « oublie » soudainement ces informations, ce qui peut produire des réponses incohérentes.
Remarque 57
Le choix de la taille de fenêtre \(K\) dépend du domaine d’application. Pour un chatbot de support technique, \(K = 5\) a \(10\) suffit souvent car chaque question est relativement indépendante. Pour un tuteur pédagogique ou un assistant de rédaction, \(K\) doit être plus grand car la cohérence sur la durée est essentielle. En pratique, on ajuste \(K\) en fonction du budget de tokens disponible : \(K \leq \lfloor L / \bar{s} \rfloor\) où \(L\) est la taille de la fenêtre de contexte et \(\bar{s}\) la taille moyenne d’un échange.
Messages totaux : 6 | Dans la fenêtre : 4 | Perdus : 2
Contexte (K=2) :
[user] Je cherche des informations sur le machine learning.
[assistant] Le machine learning est un sous-domaine de l'IA qui permet aux systèmes d'apprendre.
[user] Quels sont les principaux types d'apprentissage ?
[assistant] On distingue l'apprentissage supervisé, non supervisé et par renforcement.
Le nom « Alice » et l’entreprise « Acme Corp » ont disparu du contexte : le modèle ne pourrait plus y faire référence.
Résumé de conversation (summary memory)#
Une strategie plus intelligente consiste à résumer les anciens messages plutôt que de les supprimer. On conserve une version compressée de l’historique combinée aux messages récents.
Définition 49 (Mémoire par résumé)
La mémoire par résumé (summary memory) maintient deux composantes :
Un résumé courant \(S_t\) qui condense les échanges anciens.
Un tampon récent \(B_t\) contenant les \(K\) derniers messages non résumés.
Le contexte est \(\mathcal{C}_t = S_t \oplus B_t\). Périodiquement, les messages anciens du tampon sont résumés :
où \(\text{LLM}(\cdot)\) désigne un appel au modèle pour générer le résumé.
Remarque 58
Le résumé réalise une compression avec perte. Un échange de 500 tokens peut être résumé en 50, mais certaines nuances sont inévitablement perdues. L’efficacité dépend de la qualité du LLM utilise pour le résumé. Un bon résumé préserve les faits clés, les décisions prises et les préférences exprimées, tout en éliminant les formules de politesse et les répétitions.
Exemple 37 (Chaine de résumé)
En production, le résumé est généré par un appel LLM avec un prompt tel que :
Résumez la conversation suivante de manière concise.
Préservez : noms, décisions, préférences, questions en suspens.
Conversation : {messages_anciens}
Résumé existant : {resume_precedent}
Nouveau résumé :
Le résumé est stocké et utilisé comme préfixe du contexte dans les appels suivants.
Résumé : Résumé : Bonjour, je m'appelle Alice et je travaille chez Acme Corp.... ; Bonjour Alice ! Ravi de vous rencontrer. Comment puis-je vou...
Tampon : 4 messages | Tokens : 98
[résumé] Résumé : Bonjour, je m'appelle Alice et je travaille chez Acme Corp.... ; Bonjour Alice ! Ravi de vous rencontrer. Comment puis-je vou...
[user] Je cherche des informations sur le machine learning.
[assistant] Le machine learning est un sous-domaine de l'IA qui permet aux systèmes d'apprendre.
[user] Quels sont les principaux types d'apprentissage ?
[assistant] On distingue l'apprentissage supervisé, non supervisé et par renforcement.
Compression de contexte#
Au-delà du résumé simple, des techniques plus sophistiquées permettent de comprimer le contexte de manière structurée, en extrayant des informations spécifiques plutôt qu’en produisant un résumé narratif.
Définition 50 (Compression de contexte)
La compression de contexte (context compression) désigne une famille de techniques qui transforment l’historique conversationnel en une représentation plus compacte :
Extraction d’entités : identifier et stocker les entités clés (noms, lieux, concepts) et leurs attributs.
Suivi d’entités (entity tracking) : maintenir un registre des entités et de leur état courant.
Résumé hiérarchique : résumer à plusieurs niveaux de granularité (session, thème, fait).
Compression par embeddings : représenter les messages anciens par leurs vecteurs et sélectionner les passages pertinents par similarité sémantique.
Remarque 59
Le suivi d’entités est particulièrement utile dans les conversations ou l’utilisateur mentionne des personnes, des projets ou des concepts specifiques dont les attributs évoluent. Par exemple, si l’utilisateur dit « mon budget est passé de 10k à 50k » au tour 15, un suivi d’entités mettra à jour l’attribut budget sans conserver l’intégralité du tour 15 dans le contexte. Cela permet une compression structurée qui préserve les informations factuelles tout en réduisant le nombre de tokens.
Entités extraites :
personnes: ['Corp', 'Alice', 'Acme', 'Bonjour']
organisations: ['Corp', 'Alice', 'Acme', 'Bonjour']
sujets: ['machine learning']
[entités] {'personnes': ['Corp', 'Alice', 'Acme', 'Bonjour'], 'organisations': ['Corp', 'Alice', 'Acme', 'Bonjour'], 'sujets': ['machine learning']}
[user] Je cherche des informations sur le machine learning.
[assistant] Le machine learning est un sous-domaine de l'IA qui permet aux systèmes d'apprendre.
[user] Quels sont les principaux types d'apprentissage ?
[assistant] On distingue l'apprentissage supervisé, non supervisé et par renforcement.
Mémoire à long terme et hiérarchique#
Les stratégies précédentes opèrent au sein d’une session unique. Dans de nombreuses applications (assistants personnels, support client, tuteurs intelligents), il faut persister des informations entre les sessions, ce qui nécessite une mémoire à long terme.
Exemple 38 (Mémoire hiérarchique)
Une architecture de mémoire hiérarchique organise l’information à trois niveaux :
Mémoire de travail : les \(K\) derniers messages (fenêtre glissante).
Mémoire épisodique : les résumés des sessions précédentes, stockés dans une base vectorielle et récupérés par similarité sémantique.
Mémoire sémantique : les faits stables extraits (entités, préférences), stockés dans une base structurée.
Requête utilisateur
│
▼
┌─────────────────┐
│ Mémoire de │ ◄── derniers K messages
│ travail │
└────────┬────────┘
│
▼
┌─────────────────┐
│ Mémoire │ ◄── recherche par similarité
│ épisodique │ dans la base vectorielle
└────────┬────────┘
│
▼
┌─────────────────┐
│ Mémoire │ ◄── lookup dans la base
│ sémantique │ structurée (entités)
└────────┬────────┘
│
▼
Contexte enrichi → LLM → Réponse
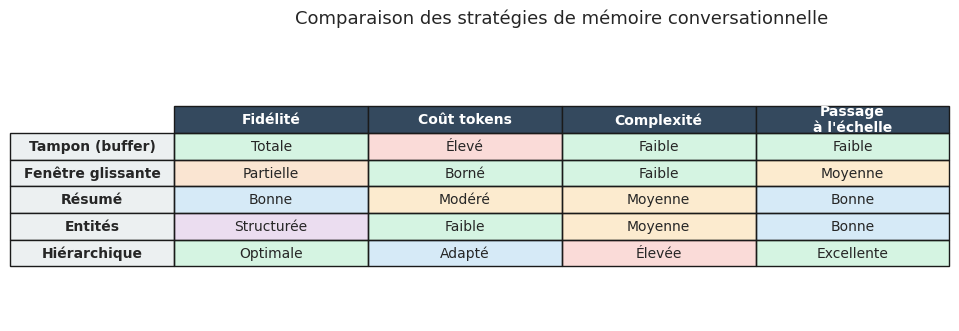
Propriété 13 (Compromis des stratégies de mémoire)
Les stratégies de mémoire présentent des compromis selon quatre axes :
Fidélité : proportion d’information originale préservée dans le contexte.
Coût en tokens : nombre de tokens consommés par tour (coût financier et latence).
Complexité d’implementation : difficulté technique de mise en oeuvre.
Passage à l’échelle : capacité à gérer des centaines de tours ou des interactions multi-sessions.
Aucune stratégie ne domine les autres sur tous les axes. Le tampon est maximal en fidélité mais minimal en passage à l’échelle. La fenêtre glissante est simple et bornée mais perd de l’information. Le résumé offre un bon compromis mais introduit du bruit. La mémoire hiérarchique est la plus complete mais aussi la plus complexe.
Remarque 60
La mémoire épisodique par base vectorielle offre un avantage unique : elle permet de retrouver des informations anciennes sans les conserver en permanence dans le contexte. Au lieu de fournir un résumé global potentiellement hors sujet, on récupère spécifiquement les passages pertinents pour la requête courante. Cette approche, à l’intersection de la mémoire conversationnelle et du RAG (chapitre suivant), est particulièrement efficace pour les conversations longues et thématiquement variées.
Implémentation et patterns#
En pratique, les systèmes de production combinent plusieurs stratégies pour obtenir le meilleur compromis. Cette section presente les patterns les plus courants.
Mémoire hybride (resume + tampon recent)#
Le pattern le plus répandu consiste à combiner un résumé progressif des anciens messages avec un tampon des messages récents. Ce schéma est utilisé par défaut dans des frameworks comme LangChain ou LlamaIndex.
Mémoire avec RAG#
Un pattern avancé consiste à indexer l’historique dans une base vectorielle et à récupérer par similarité les passages pertinents pour la requête courante. Plutôt que de fournir l’intégralité de l’historique ou un résumé statique, on recherche dans l’historique les messages pertinents. Cette approche, à l’intersection de la mémoire et du RAG (chapitre suivant), est particulièrement efficace pour les conversations longues.
Exemple 39 (Pattern memoire + RAG)
L’intégration de la mémoire avec le RAG suit un schéma en trois étapes :
Indexation : à chaque nouveau message, on calcule son embedding et on l’insère dans la base vectorielle.
Retrieval : à chaque requête, on récupère les \(k\) messages les plus proches sémantiquement.
Augmentation : le contexte fourni au LLM combine les messages récupérés et le tampon recent.
# Schéma conceptuel (en production : FAISS, Chroma, Pinecone...)
embedding = model.encode(new_message)
vector_store.add(embedding, metadata={"content": new_message, "turn": t})
relevant = vector_store.search(query_embedding, top_k=5)
context = format_context(summary, relevant, recent_messages)
Gestion de la mémoire en production#
En environnement de production, la gestion de la mémoire doit prendre en compte des contraintes supplémentaires :
Persistance : les sessions doivent être sauvegardées (base de données, Redis) pour survivre aux redémarrages.
Multi-utilisateurs : chaque utilisateur doit avoir son propre espace mémoire isolé.
TTL : les conversations anciennes doivent être archivées selon les politiques de rétention.
Sécurité : les données conversationnelles contiennent potentiellement des informations sensibles.
Remarque 61
En production, le choix de la stratégie de mémoire est souvent dicté par des contraintes non techniques : budget API, exigences réglementaires (RGPD, droit à l’oubli), politique de rétention des données. Un système déployé en Europe doit par exemple permettre la suppression complête de l’historique d’un utilisateur sur demande, ce qui impose une architecture de mémoire oè chaque session est identifiable et supprimable indépendamment.
============================================================
Tampon — 749 tokens
============================================================
[user] Je m'appelle Marie et je travaille chez TechCorp sur un projet d'IA.
[assistant] Réponse détaillée au tour 1 avec des recommandations adaptées.
[user] Notre projet concerne la détection de frau...
============================================================
Fenêtre (K=5) — 110 tokens
============================================================
[user] Question de suivi numéro 26.
[assistant] Réponse détaillée au tour 26 avec des recommandations adaptées.
[user] Question de suivi numéro 27.
[assistant] Réponse détaillée au tour 27 avec des re...
============================================================
Résumé — 674 tokens
============================================================
[résumé] Résumé : Je m'appelle Marie et je travaille chez TechCorp sur un proj... ; Réponse détaillée au tour 1 avec des recommandations adaptée... | Notre projet concerne la détection de fraude dans ...
============================================================
Hybride — 674 tokens
============================================================
[résumé] Résumé : Je m'appelle Marie et je travaille chez TechCorp sur un proj... ; Réponse détaillée au tour 1 avec des recommandations adaptée... | Notre projet concerne la détection de fraude dans ...
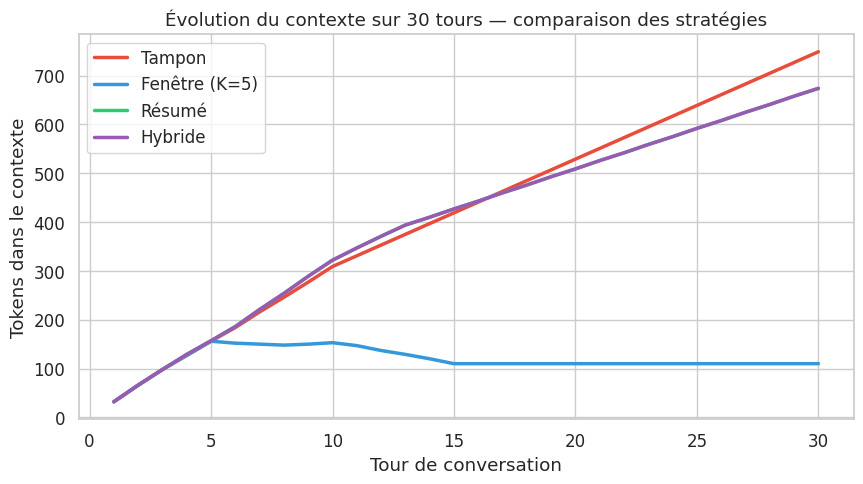
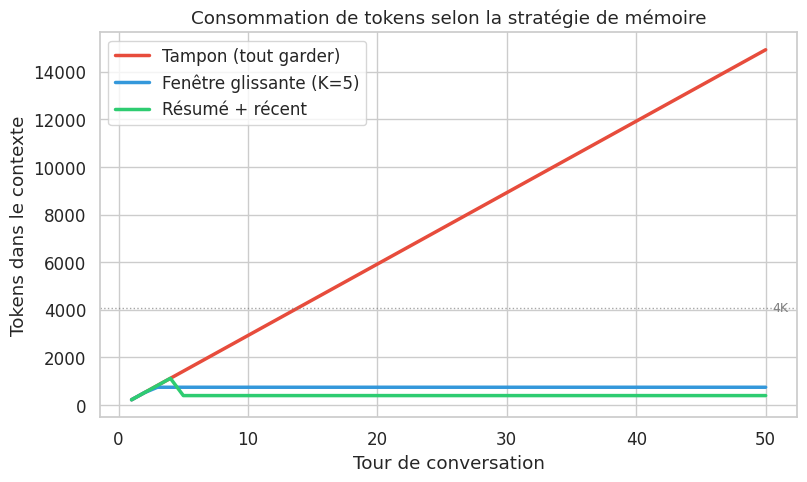
Le graphique confirme les propriétés théoriques : le tampon diverge, la fenêtre glissante et les approches par résumé restent bornées. La mémoire hybride offre un bon compromis entre coût en tokens et rétention d’information.
Résumé#
Ce chapitre a présenté les principales stratégies de mémoire conversationnelle pour les LLM :
Les LLM sont sans état : chaque appel est indépendant, et la fenêtre de contexte constitue la seule « mémoire de travail » du modèle. Sans mécanisme explicite, le contexte croit linéairement et dépasse la capacité du modèle.
La mémoire tampon conserve l’intégralité des messages. Elle offre une fidelité maximale mais une consommation de tokens non bornée, inadaptée aux longues conversations.
La fenêtre glissante conserve les \(K\) derniers tours. Elle borne la consommation de tokens mais introduit une perte d’information abrupte pour tout ce qui précède la fenêtre.
La mémoire par résumé compresse les anciens messages en un résumé narratif combiné avec un tampon récent. La compression est efficace mais avec perte.
La compression de contexte englobe des techniques structurées (extraction d’entités, suivi d’entités, résumé hiérarchique) qui préservent l’information sous une forme compacte et interrogeable.
La mémoire à long terme persiste entre les sessions via des bases de données, des stores vectoriels (mémoire épisodique) et des stores structurés (mémoire sémantique).
Les patterns de production combinent plusieurs stratégies : mémoire hybride (résumé + tampon récent), mémoire avec RAG pour la récupération sémantique, et gestion des contraintes opérationnelles (persistance, multi-utilisateurs, sécurité).
Le choix d’une stratégie est un compromis entre fidélité, coût en tokens, complexité et passage à l’échelle. Les systèmes les plus performants utilisent une architecture hiérarchique combinant mémoire de travail, mémoire épisodique et mémoire sémantique.