RAG : Retrieval-Augmented Generation#
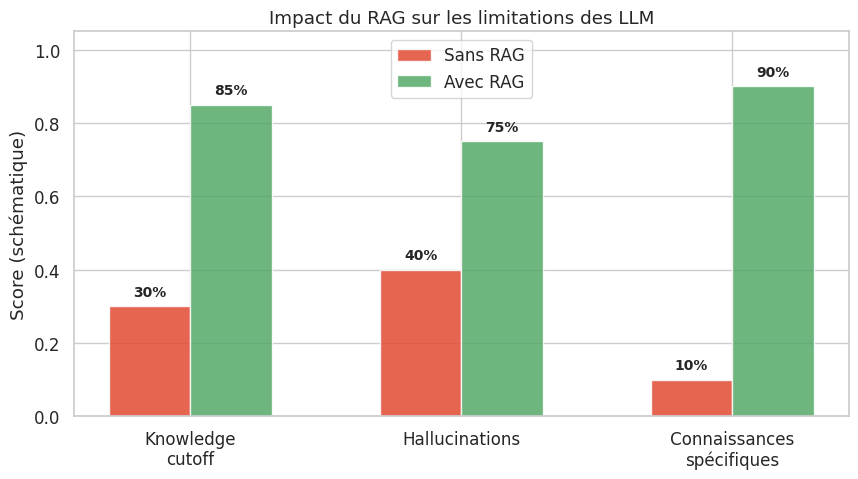
Les grands modèles de langage possèdent une connaissance paramétrique impressionnante, acquise durant leur pré-entraînement sur des corpus massifs. Cependant, cette connaissance est figée à la date de la dernière mise à jour des données d’entraînement (knowledge cutoff), elle ne couvre pas les documents internes d’une organisation, et elle peut produire des réponses plausibles mais factuellement incorrectes — les hallucinations. Le paradigme RAG (Retrieval-Augmented Generation), introduit par Lewis et al. en 2020, propose une solution élégante : plutôt que de compter uniquement sur la mémoire paramétrique du modèle, on ancre la génération dans des documents externes récupérés dynamiquement au moment de la requête.
Ce chapitre présente le pipeline RAG complet, depuis le découpage des documents en fragments (chunking) jusqu’à la génération augmentée par la récupération, en passant par les embeddings vectoriels et la recherche de similarité avec FAISS. Nous verrons comment chaque composant influence la qualité finale de la réponse et comment évaluer un système RAG de manière rigoureuse.
Le RAG s’inscrit naturellement dans la suite du chapitre 9 sur la mémoire conversationnelle : alors que la mémoire gère le contexte d’une conversation, le RAG permet au modèle d’accéder à une base de connaissances externe potentiellement très vaste. Combinés, ces deux mécanismes donnent au LLM une capacité de raisonnement ancré dans des faits vérifiables.
Pourquoi le RAG ?#
Les LLM, aussi puissants soient-ils, souffrent de trois limitations fondamentales qui motivent l’adoption du RAG.
Définition 51 (Retrieval-Augmented Generation (RAG))
Le Retrieval-Augmented Generation (RAG) est un paradigme d’augmentation des LLM qui combine un module de récupération (retriever) et un module de génération (generator). Étant donné une requête \(q\), le système :
Récupère un ensemble de \(k\) passages pertinents \(\{d_1, \ldots, d_k\}\) depuis une base de connaissances externe \(\mathcal{D}\).
Augmente le prompt en concaténant les passages récupérés au contexte de la requête.
Génère une réponse \(y\) conditionnée par la requête et les passages :
où \(p(d_i \mid q)\) est la pertinence estimée du passage \(d_i\) pour la requête \(q\).
Knowledge cutoff. Un LLM entraîné jusqu’en janvier 2024 ne sait rien des événements postérieurs. Toute question portant sur des faits récents — une nouvelle réglementation, un article scientifique publié le mois dernier — recevra une réponse obsolète ou inventée. Le RAG résout ce problème en permettant l’ajout de documents à jour sans ré-entraîner le modèle.
Hallucinations. Les LLM génèrent du texte en maximisant la vraisemblance token par token. Rien ne garantit la véracité factuelle de la sortie. Le RAG réduit les hallucinations en fournissant des passages sources que le modèle peut citer ou paraphraser.
Remarque 62
Le RAG ne supprime pas les hallucinations, mais les réduit significativement. Le modèle peut toujours ignorer le contexte fourni ou en faire une synthèse incorrecte. C’est pourquoi l”évaluation de la fidélité (faithfulness) — la cohérence de la réponse avec les passages récupérés — est une métrique centrale des systèmes RAG. En pratique, des instructions explicites dans le prompt (« Réponds uniquement à partir du contexte fourni ») améliorent la fidélité.
Connaissances spécifiques à un domaine. Une entreprise possède des documents internes — procédures, contrats, documentations techniques — qui n’ont jamais été vus par le LLM durant son entraînement. Le RAG permet d’exploiter ces connaissances privées sans fine-tuning, en les indexant dans une base vectorielle.
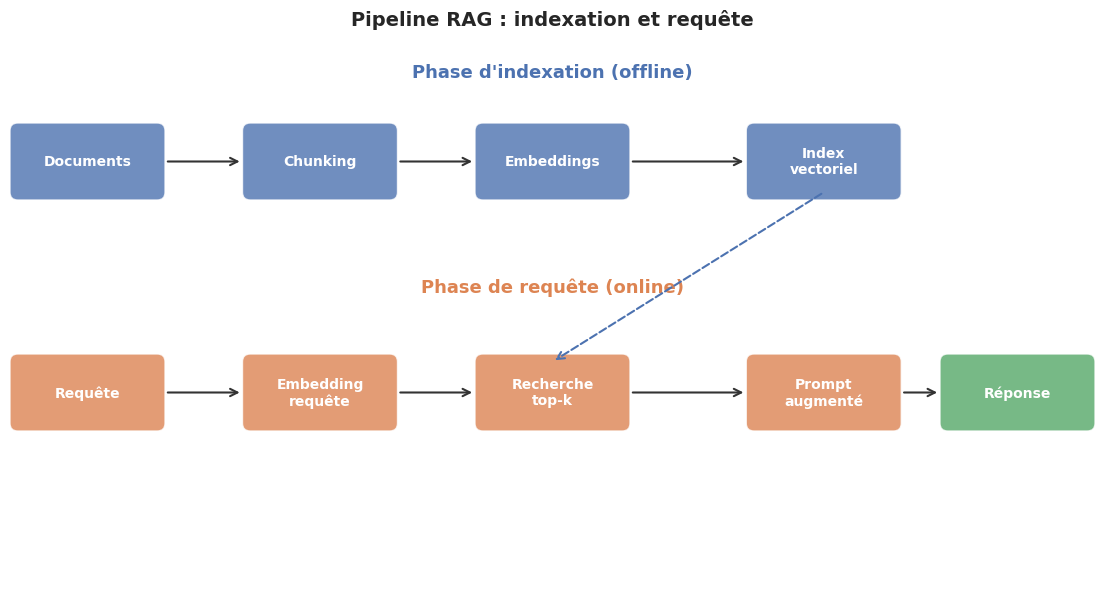
Pipeline RAG : vue d’ensemble#
Le pipeline RAG se décompose en deux phases distinctes : une phase d”indexation (offline) et une phase de requête (online).
Phase d’indexation. Les documents sont découpés en fragments (chunks), chaque fragment est transformé en un vecteur dense par un modèle d’embeddings, et ces vecteurs sont stockés dans un index vectoriel (par exemple FAISS).
Phase de requête. La question de l’utilisateur est encodée par le même modèle d’embeddings, les \(k\) fragments les plus similaires sont récupérés par recherche de similarité, ces fragments sont insérés dans le prompt, et le LLM génère la réponse.
Exemple 40 (Pipeline RAG de bout en bout)
Supposons une base de connaissances contenant 500 articles techniques. Le pipeline RAG procède comme suit :
Chunking : chaque article est découpé en fragments de 512 tokens avec un recouvrement de 64 tokens, produisant environ 3 000 chunks.
Embedding : chaque chunk est encodé par
all-MiniLM-L6-v2en un vecteur de dimension 384.Indexation : les 3 000 vecteurs sont ajoutés à un index FAISS
IndexFlatIP(\(\sim\) 4,5 Mo).Requête : la question est encodée en un vecteur de dimension 384.
Récupération : les 5 chunks les plus similaires sont récupérés (top-5).
Génération : le LLM reçoit le prompt augmenté et génère une réponse fidèle aux passages récupérés.
Chunking de documents#
Le chunking est l’opération qui découpe un document en fragments de taille gérable pour l’embedding et la récupération. Des chunks trop grands diluent l’information pertinente ; des chunks trop petits perdent le contexte nécessaire à la compréhension.
Définition 52 (Chunking)
Le chunking (fragmentation) est le processus de découpage d’un document textuel \(D = (t_1, t_2, \ldots, t_N)\) de \(N\) tokens en une séquence de fragments \(\{c_1, c_2, \ldots, c_M\}\), où chaque chunk \(c_i\) contient un sous-ensemble contigu de tokens de \(D\). Les hyperparamètres principaux sont :
La taille du chunk \(s\) : nombre de tokens (ou caractères) par fragment.
Le recouvrement (overlap) \(o\) : nombre de tokens partagés entre deux chunks consécutifs, avec \(0 \leq o < s\).
Le nombre de chunks résultant : \(M = \left\lceil \frac{N - o}{s - o} \right\rceil\).
Remarque 63
Le choix de la taille du chunk est un compromis fondamental :
Chunks petits (128–256 tokens) : plus précis pour la récupération (un chunk = une idée), mais risquent de perdre le contexte.
Chunks grands (512–1024 tokens) : conservent plus de contexte, mais diluent la pertinence.
En pratique, des chunks de 256 à 512 tokens avec un recouvrement de 10 à 20 % offrent un bon compromis pour la plupart des cas d’usage.
Remarque 64
Le recouvrement (overlap) entre chunks consécutifs assure qu’une phrase coupée à la frontière de deux chunks reste présente dans au moins l’un des deux. Sans recouvrement, une information clé située à la jonction pourrait n’apparaître de manière cohérente dans aucun fragment. Un recouvrement de 10 à 20 % de la taille du chunk est un bon point de départ.
Texte original : 1223 caractères
Nombre de chunks : 9 (taille 200, recouvrement 50)
--- Chunk 0 (200 car.) ---
Le Retrieval-Augmented Generation (RAG) est un paradigme qui combine la récupéra...
--- Chunk 1 (200 car.) ---
langage. L'idée centrale est simple : plutôt que de compter uniquement sur la mé...
--- Chunk 2 (200 car.) ---
s externes récupérés dynamiquement. Le pipeline RAG se compose de deux phases. L...
--- Chunk 3 (200 car.) ---
les encoder en vecteurs denses, puis à les stocker dans un index vectoriel. La ...
--- Chunk 4 (200 car.) ---
gments les plus similaires, et les insère dans le prompt du LLM pour générer une...
--- Chunk 5 (200 car.) ---
r la recherche de similarité efficace dans des espaces vectoriels de grande dime...
--- Chunk 6 (200 car.) ---
is entre vitesse et précision. L'index le plus simple, IndexFlatL2, effectue une...
--- Chunk 7 (173 car.) ---
entre le vecteur requête et tous les vecteurs de la base. Pour des bases plus g...
--- Chunk 8 (23 car.) ---
vitesse considérables.
Chunking récursif et sémantique#
Le chunking récursif tente de respecter les frontières naturelles du document : d’abord par paragraphe, puis par phrase, puis par mot, en recourant à des délimiteurs de plus en plus fins si un fragment dépasse la taille cible.
Chunking récursif : 8 chunks
[0] (157 car.) Le Retrieval-Augmented Generation (RAG) est un paradigme qui...
[1] (175 car.) L'idée centrale est simple : plutôt que de compter uniquemen...
[2] (189 car.) Le pipeline RAG se compose de deux phases. La phase d'indexa...
[3] (168 car.) La phase de requête encode la question de l'utilisateur, réc...
[4] (138 car.) FAISS est une bibliothèque développée par Meta AI pour la re...
[5] (92 car.) Elle offre plusieurs types d'index adaptés à différents comp...
[6] (176 car.) L'index le plus simple, IndexFlatL2, effectue une recherche ...
[7] (114 car.) Pour des bases plus grandes, des index approximatifs comme I...
Exemple 41 (Comparaison des stratégies de chunking)
Stratégie |
Taille cible |
Recouvrement |
Nombre de chunks |
Préserve la structure |
|---|---|---|---|---|
Fixe |
200 |
50 |
7 |
Non |
Récursive |
200 |
— |
5–6 |
Oui (paragraphes) |
Sémantique |
variable |
— |
4–8 |
Oui (thématique) |
Le chunking sémantique regroupe les phrases par similarité d’embeddings : on calcule l’embedding de chaque phrase, puis on fusionne les phrases consécutives tant que la similarité cosinus entre elles dépasse un seuil \(\tau\). Cette approche produit des chunks de taille variable mais thématiquement cohérents.
Embeddings et indexation vectorielle#
Une fois les documents découpés en chunks, chaque fragment doit être transformé en un vecteur dense qui capture son sens sémantique. Ces vecteurs sont ensuite stockés dans un index vectoriel permettant la recherche rapide des passages les plus pertinents.
Définition 53 (Base de vecteurs (vector store))
Une base de vecteurs (vector store) est une structure de données qui stocke des vecteurs denses \(\mathbf{v}_1, \ldots, \mathbf{v}_N \in \mathbb{R}^d\) et permet la recherche efficace des \(k\) plus proches voisins d’un vecteur requête \(\mathbf{q} \in \mathbb{R}^d\) selon une métrique de distance :
Distance euclidienne (\(L_2\)) : \(d(\mathbf{q}, \mathbf{v}_i) = \|\mathbf{q} - \mathbf{v}_i\|_2\)
Produit scalaire (inner product) : \(\text{IP}(\mathbf{q}, \mathbf{v}_i) = \mathbf{q}^\top \mathbf{v}_i\)
Similarité cosinus : \(\cos(\mathbf{q}, \mathbf{v}_i) = \frac{\mathbf{q}^\top \mathbf{v}_i}{\|\mathbf{q}\| \, \|\mathbf{v}_i\|}\)
Pour des vecteurs normalisés (\(\|\mathbf{v}\| = 1\)), le produit scalaire est équivalent à la similarité cosinus.
Remarque 65
Le choix du modèle d’embeddings est crucial pour la qualité du RAG :
all-MiniLM-L6-v2 : léger (80 Mo), dimension 384, bon pour le prototypage.
all-mpnet-base-v2 : plus lourd (420 Mo), dimension 768, meilleur sur les benchmarks STS.
Modèles multilingues (e.g.,
multilingual-e5-large) : nécessaires pour des corpus non anglophones.Modèles spécialisés : un fine-tuning du modèle d’embeddings sur des données du domaine améliore significativement la récupération.
# Chargement du modèle d'embeddings (~80 Mo)
model = SentenceTransformer('all-MiniLM-L6-v2')
print(f"Modèle : all-MiniLM-L6-v2")
print(f"Dimension des embeddings : {model.get_sentence_embedding_dimension()}")
BertModel LOAD REPORT from: sentence-transformers/all-MiniLM-L6-v2
Key | Status | |
------------------------+------------+--+-
embeddings.position_ids | UNEXPECTED | |
Notes:
- UNEXPECTED :can be ignored when loading from different task/architecture; not ok if you expect identical arch.
Modèle : all-MiniLM-L6-v2
Dimension des embeddings : 384
Nombre total de chunks : 20
Sources : ['RAG', 'FAISS', 'Embeddings', 'LLM', 'Évaluation']
Matrice d'embeddings : (20, 384)
Norme du premier vecteur : 1.0000 (normalisé)
FAISS : recherche de similarité efficace#
FAISS (Facebook AI Similarity Search) est une bibliothèque développée par Meta AI Research pour la recherche de similarité efficace dans des espaces vectoriels de grande dimension.
Définition 54 (FAISS)
FAISS est une bibliothèque de recherche de similarité vectorielle qui implémente plusieurs structures d’index :
IndexFlatL2 : recherche exacte par distance euclidienne (force brute). Complexité \(O(Nd)\) par requête.
IndexFlatIP : recherche exacte par produit scalaire. Pour des vecteurs normalisés, équivalent à la similarité cosinus.
IndexIVFFlat : recherche approximative par partitionnement de Voronoï. L’espace est divisé en \(n_{\text{cells}}\) cellules ; seules les \(n_{\text{probe}}\) cellules les plus proches sont explorées.
IndexHNSWFlat : recherche approximative par graphe Hierarchical Navigable Small World. Excellent compromis vitesse/précision pour les grandes bases.
Les index sont construits sur des vecteurs de dimension \(d\) en float32, soit \(4d\) octets par vecteur.
Définition 55 (Recherche de similarité (similarity search))
La recherche de similarité consiste, étant donné un vecteur requête \(\mathbf{q} \in \mathbb{R}^d\) et une base de \(N\) vecteurs \(\{\mathbf{v}_1, \ldots, \mathbf{v}_N\}\), à trouver les \(k\) vecteurs les plus proches de \(\mathbf{q}\) :
Le résultat est un ensemble d’indices \(I = (i_1, \ldots, i_k)\) et de distances \(D = (d_1, \ldots, d_k)\), triés par distance croissante (ou similarité décroissante).
Index : IndexFlatIP, dim 384, 20 vecteurs
Mémoire estimée : 30.0 Ko
Exemple 42 (Création et interrogation d’un index FAISS)
La création et l’interrogation d’un index FAISS se font en trois lignes :
Créer l’index :
index = faiss.IndexFlatIP(d)pour un index exact par produit scalaire en dimension \(d\).Ajouter les vecteurs :
index.add(vectors)oùvectorsest un tableau NumPyfloat32de forme \((N, d)\).Chercher :
D, I = index.search(query, k)retourne les distances \(D\) et indices \(I\) des \(k\) plus proches voisins.
Pour \(N = 10\,000\) vecteurs en dimension \(d = 384\), l’index occupe environ 15 Mo et une recherche exacte prend quelques millisecondes.
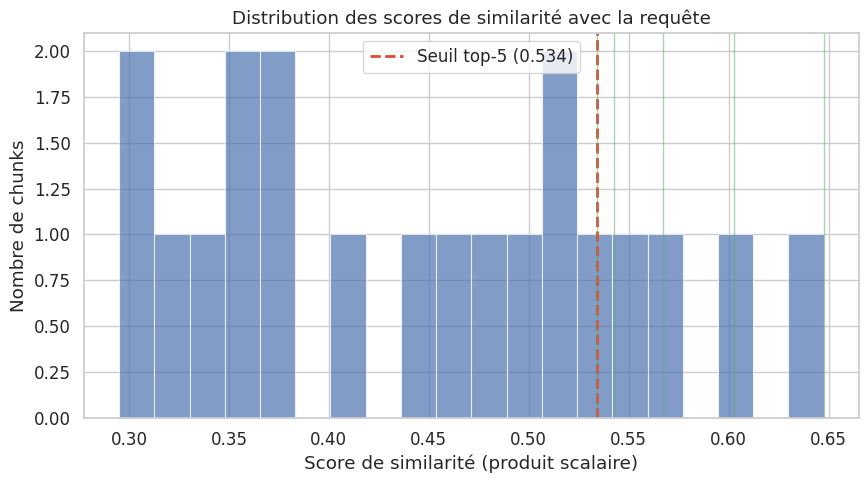
Requête : "Comment fonctionne la recherche de similarité dans un système RAG ?"
Top-5 résultats :
--------------------------------------------------------------------------------
[1] (score: 0.6475) [Évaluation] RAGAS est un framework d'évaluation automatique pour les systèmes RAG.
[2] (score: 0.6025) [RAG] Le RAG permet d'utiliser des connaissances privées sans fine-tuning.
[3] (score: 0.5673) [Embeddings] La similarité cosinus mesure la proximité sémantique entre deux vecteurs.
[4] (score: 0.5426) [RAG] Le RAG combine récupération d'information et génération de texte par un LLM.
[5] (score: 0.5342) [RAG] Le pipeline RAG comprend une phase d'indexation et une phase de requête.
Propriété 14 (Complexité des index FAISS)
Pour \(N\) vecteurs en dimension \(d\) et une requête top-\(k\) :
Index |
Complexité temporelle |
Complexité mémoire |
Exactitude |
|---|---|---|---|
|
\(O(Nd)\) |
\(O(Nd)\) |
Exacte |
|
\(O\!\left(\frac{n_p}{n_c} \cdot Nd\right)\) |
\(O(Nd + n_c d)\) |
Approximative |
|
\(O(ef \cdot \log N \cdot d)\) |
\(O(Nd + NM)\) |
Approximative |
Pour de petites bases (\(N < 50\,000\)), IndexFlatIP est suffisant. Au-delà, les index approximatifs offrent des gains de vitesse de 10 à 100x avec une perte de rappel inférieure à 5 %.
Remarque 66
En pratique, les systèmes RAG combinent la recherche vectorielle avec un filtrage par métadonnées : date du document, source, catégorie, langue. Ce filtrage peut être appliqué avant la recherche (pre-filtering) ou après (post-filtering). Les bases de vecteurs dédiées (Pinecone, Weaviate, Qdrant, ChromaDB) offrent ce filtrage nativement, tandis qu’avec FAISS il faut le gérer manuellement.
Génération augmentée par la récupération#
La dernière étape du pipeline RAG consiste à injecter les chunks récupérés dans le prompt du LLM pour générer une réponse fidèle au contexte fourni. La formulation du prompt est déterminante pour la qualité et la fidélité de la réponse.
Exemple 43 (Template de prompt RAG)
Un template de prompt RAG typique :
Tu es un assistant qui répond aux questions en te basant
uniquement sur le contexte fourni. Si l'information n'est
pas dans le contexte, dis-le explicitement.
Contexte :
[1] {chunk_1}
[2] {chunk_2}
...
[k] {chunk_k}
Question : {query}
Réponds de manière concise en citant les sources pertinentes
entre crochets (ex: [1], [3]).
Ce template impose trois contraintes cruciales :
Fidélité : « uniquement sur le contexte fourni ».
Transparence : « Si l’information n’est pas dans le contexte, dis-le ».
Traçabilité : « en citant les sources pertinentes entre crochets ».
=== Prompt RAG ===
Tu es un assistant qui répond aux questions en te basant uniquement sur le contexte fourni. Si l'information n'est pas dans le contexte, dis-le explicitement.
Contexte :
[1] RAGAS est un framework d'évaluation automatique pour les systèmes RAG.
[2] Le RAG permet d'utiliser des connaissances privées sans fine-tuning.
[3] La similarité cosinus mesure la proximité sémantique entre deux vecteurs.
[4] Le RAG combine récupération d'information et génération de texte par un LLM.
[5] Le pipeline RAG comprend une phase d'indexation et une phase de requête.
Question : Comment fonctionne la recherche de similarité dans un système RAG ?
Réponds de manière concise en citant les sources entre crochets.
Classe RAGPipeline complète#
Combinons l’ensemble des composants — chunking, embedding, indexation et récupération — dans une classe unifiée.
BertModel LOAD REPORT from: sentence-transformers/all-MiniLM-L6-v2
Key | Status | |
------------------------+------------+--+-
embeddings.position_ids | UNEXPECTED | |
Notes:
- UNEXPECTED :can be ignored when loading from different task/architecture; not ok if you expect identical arch.
Indexés : 1 docs → 9 chunks → index FAISS (9 vecteurs, dim 384)
Question : Quels types d'index propose FAISS ?
[1] (score: 0.4858) r la recherche de similarité efficace dans des espaces vectoriels de grande dime...
[2] (score: 0.4793) is entre vitesse et précision. L'index le plus simple, IndexFlatL2, effectue une...
[3] (score: 0.4409) entre le vecteur requête et tous les vecteurs de la base. Pour des bases plus g...
Évaluation du RAG#
L’évaluation d’un système RAG doit mesurer la qualité à la fois de la récupération et de la génération. Le framework RAGAS (Retrieval-Augmented Generation Assessment) propose un ensemble de métriques standardisées.
Définition 56 (Évaluation RAG)
L”évaluation d’un système RAG porte sur quatre dimensions complémentaires :
Fidélité (faithfulness) : la réponse est-elle cohérente avec les passages récupérés ? Proportion d’affirmations soutenues par le contexte.
Pertinence de la réponse (answer relevance) : la réponse répond-elle effectivement à la question posée ?
Rappel contextuel (context recall) : les passages récupérés contiennent-ils toutes les informations nécessaires ? \(\text{recall} = \frac{|\text{faits pertinents récupérés}|}{|\text{faits pertinents totaux}|}\).
Précision contextuelle (context precision) : les passages récupérés sont-ils tous pertinents ? \(\text{precision} = \frac{|\text{passages pertinents}|}{|\text{passages récupérés}|}\).
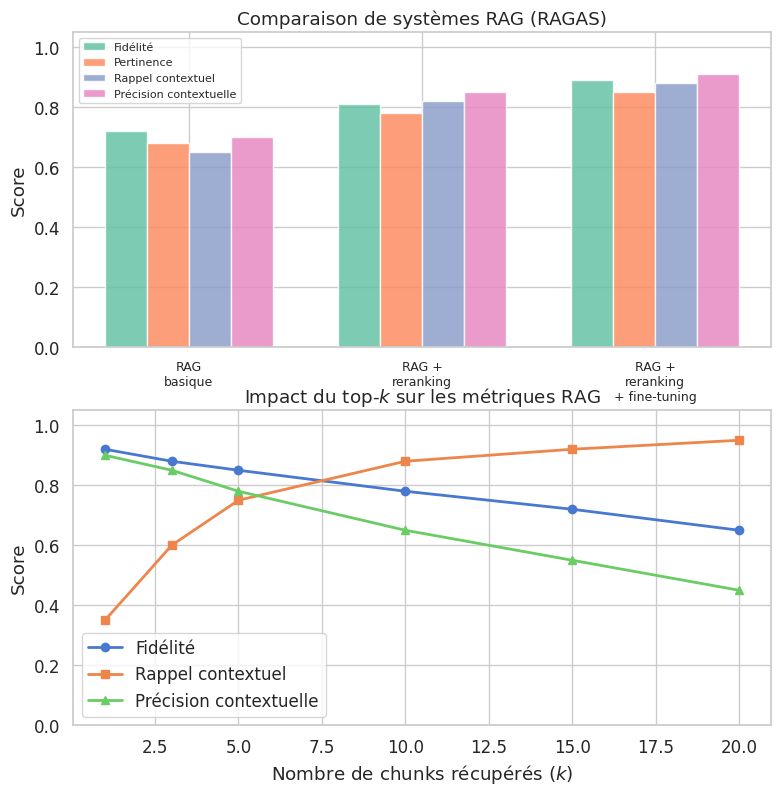
Le graphique de droite illustre un compromis fondamental : augmenter \(k\) améliore le rappel (plus de chances de récupérer tous les faits pertinents), mais dégrade la précision (davantage de bruit) et la fidélité (le modèle peut être distrait par des passages non pertinents).
Résumé#
Ce chapitre a présenté le paradigme RAG (Retrieval-Augmented Generation), qui ancre la génération des LLM dans des connaissances externes pour surmonter les limites de la mémoire paramétrique.
Le RAG résout trois problèmes fondamentaux des LLM : le knowledge cutoff (connaissances figées), les hallucinations (réponses factuellement incorrectes) et l’absence de connaissances spécifiques à un domaine.
Le pipeline RAG se compose de deux phases : l’indexation (offline : chunking, embedding, stockage vectoriel) et la requête (online : embedding de la question, récupération top-\(k\), génération augmentée).
Le chunking découpe les documents en fragments exploitables. Le choix de la taille et du recouvrement est un compromis entre précision de la récupération et préservation du contexte. Les chunks de 256 à 512 tokens avec 10–20 % de recouvrement constituent un bon point de départ.
Les sentence embeddings (MiniLM, MPNet) transforment les chunks en vecteurs denses capturant la sémantique. La normalisation des vecteurs permet d’utiliser le produit scalaire comme mesure de similarité cosinus.
FAISS offre une recherche de similarité efficace avec différents types d’index : exact (
IndexFlatIP/L2) pour les petites bases, approximatif (IVF,HNSW) pour les grandes bases. La complexité passe de \(O(Nd)\) en exact à \(O(\log N \cdot d)\) avec HNSW.Le prompt RAG structure la génération en imposant la fidélité au contexte récupéré, la transparence sur les limites de la connaissance disponible et la traçabilité par citation des sources.
L”évaluation RAG (framework RAGAS) mesure quatre dimensions : fidélité, pertinence de la réponse, rappel contextuel et précision contextuelle. Le choix du nombre de chunks \(k\) est un compromis entre rappel et précision.
Le chapitre suivant étendra ces concepts au RAG avancé : re-ranking, chunking sémantique, RAG hybride (dense + sparse), et l’intégration de graphes de connaissances pour un raisonnement structuré.