Alignement#
Les grands modèles de langage, tels qu’ils émergent du pré-entrainement, sont des machines à prédire le token suivant. Ils ont absorbé la structure statistique de milliards de pages web, de livres et de conversations, mais rien dans leur objectif d’entrainement ne les incite à être utiles, honnêtes ou inoffensifs. Un LLM de base peut tout aussi bien générer un poème, un tutoriel de chimie dangereuse ou une réponse plausible mais factuellement fausse — il optimise la vraisemblance, pas la qualité. Le problème de l”alignement est précisément celui-ci : comment faire en sorte qu’un modèle très capable se comporte conformément aux intentions et aux valeurs de ses utilisateurs et de la société ?
Ce problème est devenu central à partir de 2022, lorsque InstructGPT (Ouyang et al., 2022) puis ChatGPT ont montré qu’un même modèle de base pouvait être transformé en assistant conversationnel remarquablement coopératif grâce à l’apprentissage par retour humain (RLHF). Depuis, une série de techniques — DPO, ORPO, Constitutional AI — ont proposé des alternatives et des raffinements, chacune avec ses compromis en termes de coût, de stabilité et d’efficacité. Comprendre ces méthodes est indispensable pour quiconque déploie ou évalue un LLM.
Ce chapitre présente les fondements conceptuels et techniques de l’alignement. Nous partirons du problème lui-même, puis détaillerons le pipeline RLHF classique (SFT, modèle de récompense, PPO), avant d’examiner les alternatives plus récentes (DPO, ORPO, Constitutional AI). Nous aborderons ensuite les pathologies de l’alignement — le reward hacking et la loi de Goodhart — et le trilemme HHH (Helpful, Harmless, Honest) qui structure la réflexion sur ce que signifie « bien aligner » un modèle. L’approche est illustrée par des simulations sur des données synthétiques, sans chargement de modèle, pour rester dans une empreinte mémoire réduite.
Le problème de l’alignement#
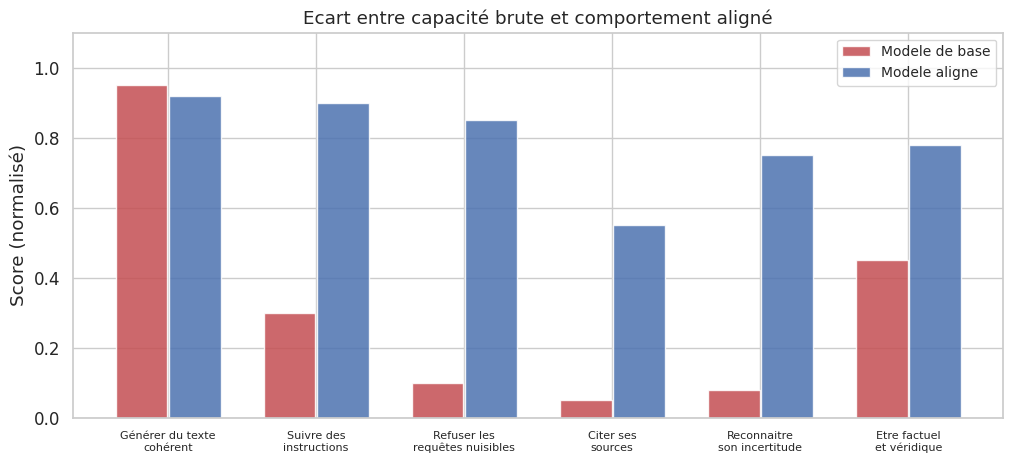
Un LLM pré-entrainé par modelisation auto-regressive maximise la log-vraisemblance \(\mathcal{L}(\theta) = \sum_t \log P_\theta(x_t \mid x_{<t})\) sur un corpus massif. Cet objectif ne contient aucune notion de véracité, d’utilité ou de sécurité : le modèle apprend à reproduire la distribution statistique du texte humain, y compris ses erreurs, ses biais et ses contenus nuisibles. Le problème de l’alignement consiste à combler l’écart entre ce que le modèle peut faire (sa capacité) et ce qu’il devrait faire (son comportement souhaité).
Définition 94 (Alignement)
L”alignement (alignment) d’un modèle de langage est le processus par lequel on modifie le comportement du modèle pour qu’il agisse conformément aux intentions de l’utilisateur et à un ensemble de valeurs spécifiées (utilité, honnêteté, sécurité). Formellement, si \(\pi_\theta\) désigne la politique du modèle (la distribution sur les séquences générées) et \(R^*\) la fonction de récompense idéale capturant les préférences humaines, l’objectif d’alignement est :
Le terme de régularisation KL empêche le modèle aligné de trop s’éloigner du modèle de référence \(\pi_{\text{ref}}\) (typiquement le modèle SFT), préservant ainsi les capacités linguistiques acquises pendant le pré-entrainement. Le coefficient \(\beta\) contrôle le compromis entre maximisation de la récompense et conservation des capacités du modèle.
Remarque 94 (Taxe d’alignement)
La taxe d’alignement (alignment tax) désigne la perte de performance brute que le modèle subit du fait de l’alignement. Un modèle aligné refuse certaines requêtes, est plus prudent dans ses affirmations et peut perdre en fluidité ou en créativité par rapport au modèle de base. En pratique, cette taxe est souvent faible pour les tâches courantes, mais elle peut devenir significative pour des tâches spécialisées où le modèle de base excelle mais que l’alignement contraint excessivement. L’objectif des méthodes modernes d’alignement est de minimiser cette taxe tout en maximisant le comportement souhaité.
L’écart entre capacité et alignement n’est pas qu’un problème théorique. Un LLM de base, interrogé sur un sujet sensible, produira la continuation la plus probable selon son corpus d’entrainement — ce qui peut inclure de la désinformation, des instructions dangereuses ou des stéréotypes. L’alignement transforme un générateur de texte en un assistant qui comprend les conventions d’un dialogue, refuse les demandes nuisibles et signale son incertitude.
<torch._C.Generator at 0x7facdfaebbb0>
RLHF : apprentissage par retour humain#
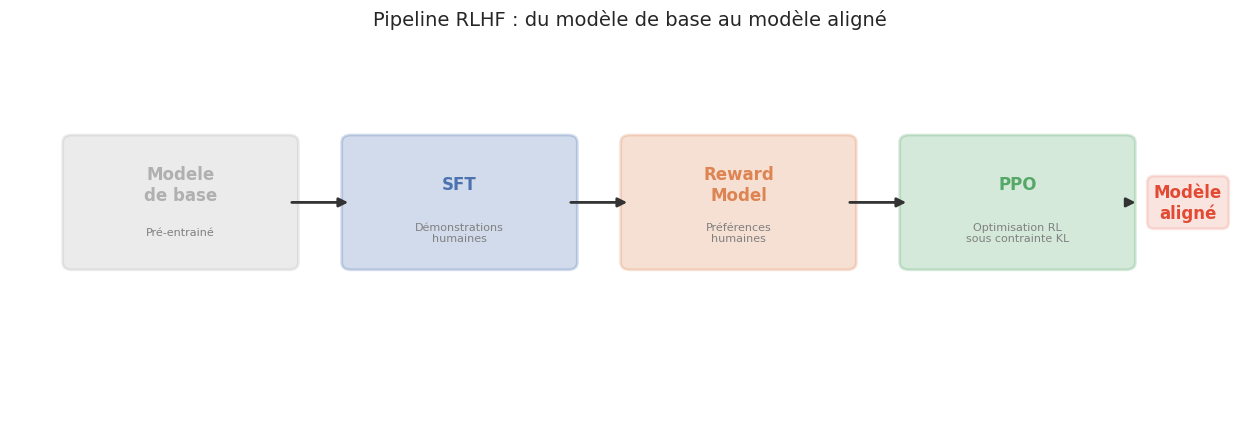
L’approche dominante pour l’alignement, popularisée par InstructGPT (Ouyang et al., 2022) et utilisée pour ChatGPT, est le Reinforcement Learning from Human Feedback (RLHF). Le pipeline RLHF se décompose en trois étapes séquentielles, chacune construisant sur la précédente.
Définition 95 (RLHF (Reinforcement Learning from Human Feedback))
Le RLHF (Reinforcement Learning from Human Feedback) est un pipeline d’alignement en trois étapes :
Supervised Fine-Tuning (SFT) : le modèle de base est fine-tuné sur un corpus de démonstrations humaines de haute qualité — des paires (instruction, réponse idéale) rédigées par des annotateurs. Le modèle résultant \(\pi_{\text{SFT}}\) sait déjà suivre des instructions, mais de manière imparfaite.
Entrainement du modèle de récompense (RM) : des annotateurs humains comparent des paires de réponses générées par \(\pi_{\text{SFT}}\) pour un même prompt et indiquent laquelle est préférable. Un modèle de récompense \(r_\phi(x, y)\) est entrainé à prédire ces préférences.
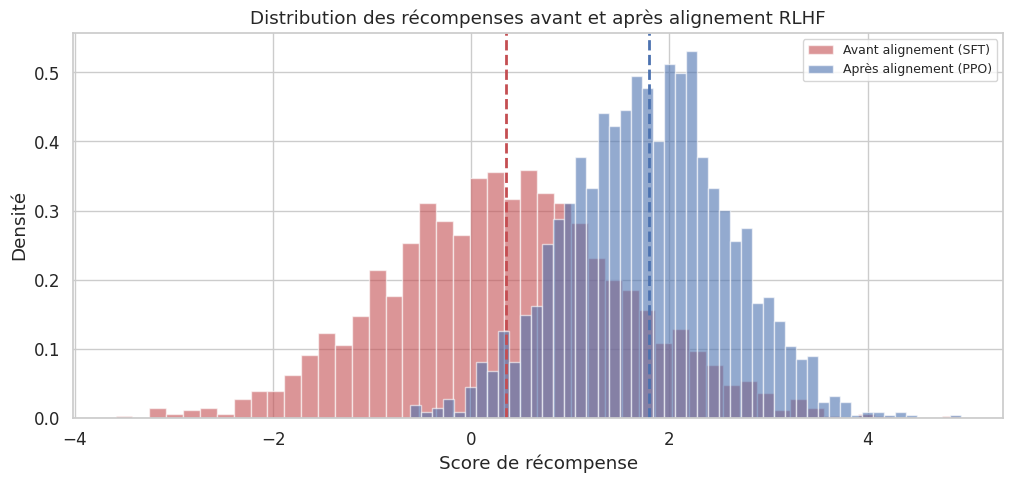
Optimisation par PPO : le modèle SFT est optimisé par un algorithme de reinforcement learning (Proximal Policy Optimization, PPO) pour maximiser la récompense prédite par le RM, sous contrainte de ne pas trop s’éloigner de \(\pi_{\text{SFT}}\) (régularisation KL).
Ce pipeline a été introduit par Christiano et al. (2017) dans le cadre général du RL, puis adapté aux LLM par Stiennon et al. (2020) et Ouyang et al. (2022).
La première étape (SFT) fine-tune le modèle de base sur un corpus de démonstrations : des paires (instruction, réponse idéale) rédigées par des annotateurs. L’objectif est la maximisation de la vraisemblance \(\mathcal{L}_{\text{SFT}}(\theta) = -\mathbb{E}_{(x, y)} \left[\sum_t \log \pi_\theta(y_t \mid x, y_{<t})\right]\). Cette étape produit déjà un modèle plus utile, mais sa qualité reste limitée par le coût des démonstrations. La deuxième étape entraine un modèle de récompense sur des préférences humaines.
Définition 96 (Modèle de récompense (Reward Model))
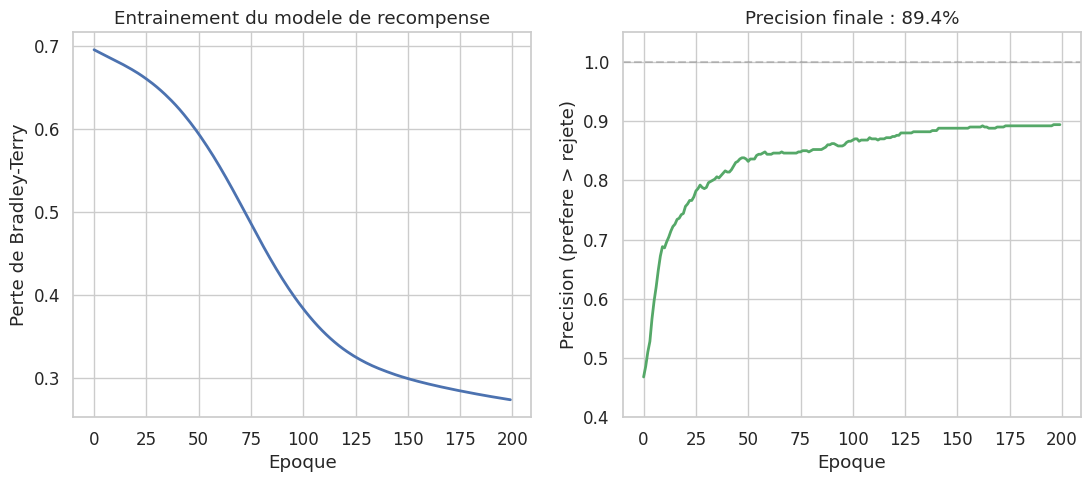
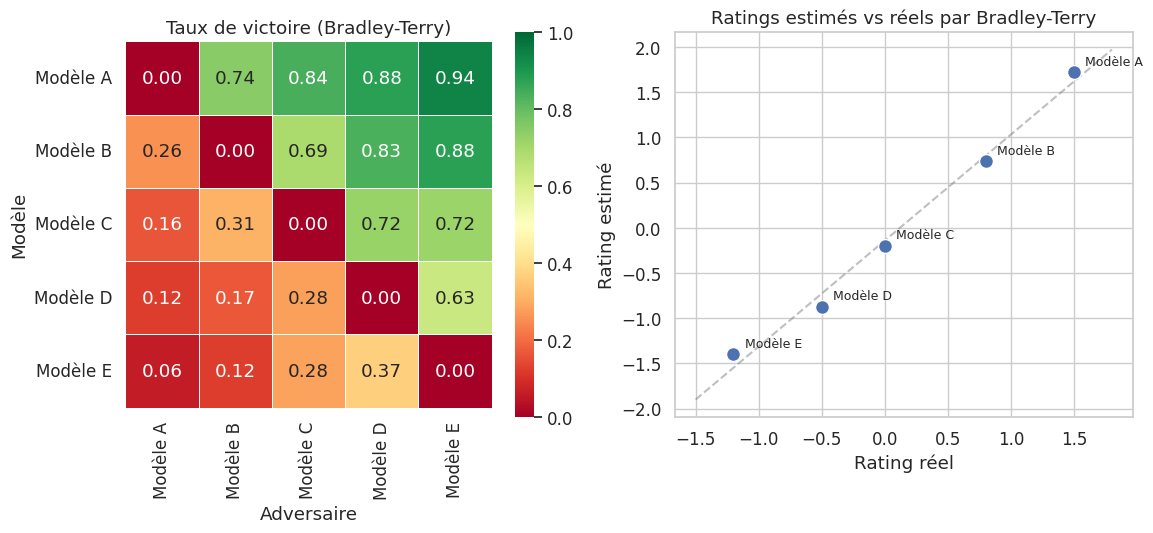
Un modèle de récompense (reward model, RM) est un modèle entrainé à prédire les préférences humaines entre deux réponses. Etant donné un prompt \(x\) et deux réponses \(y_w\) (préférée) et \(y_l\) (rejetée), le RM est entrainé par la perte de Bradley-Terry :
où \(\sigma\) est la fonction sigmoide et \(r_\phi(x, y) \in \mathbb{R}\) est le score de récompense attribué à la réponse \(y\) pour le prompt \(x\). Le modèle de Bradley-Terry suppose que la probabilité qu’une réponse \(y_w\) soit préférée à \(y_l\) est :
En pratique, le RM est souvent initialisé à partir du modèle SFT, dont on remplace la tête de génération par une tête de régression scalaire.
Exemple 68 (Données de préférence pour le RM)
Les données de préférence sont collectées en présentant aux annotateurs un prompt et deux réponses, en leur demandant laquelle est meilleure. Par exemple :
Prompt |
Réponse A (choisie) |
Réponse B (rejetee) |
|---|---|---|
« Explique la photosynthèse » |
Explication claire, structuree, correcte |
Explication vague, avec des erreurs factuelles |
« Ecris un email professionnel » |
Ton adapté, structure standard |
Trop familier, pas de formule de politesse |
« Comment crocheter une serrure ? » |
Refus poli avec explication |
Instructions détaillées (contenu dangereux) |
La qualité du RM dépend directement de la qualité et de la cohérence des annotations humaines. Les désaccords entre annotateurs sont fréquents (accord inter-annotateur typiquement de 70 a 80%), ce qui constitue un plafond de verre pour la précision du RM.
Exemple 69 (Entrainement d’un modèle de récompense)
L’entrainement d’un modèle de récompense sur des données de préférence suit le schéma standard de la classification binaire. On minimise la perte de Bradley-Terry, qui est équivalente à la perte d’entropie croisée binaire appliquée à la différence des scores :
reward_model = nn.Sequential(nn.Linear(dim, 32), nn.ReLU(), nn.Linear(32, 1))
def bradley_terry_loss(r_w, r_l):
return -torch.mean(torch.log(torch.sigmoid(r_w - r_l)))
for epoch in range(100):
r_w = reward_model(features_w).squeeze()
r_l = reward_model(features_l).squeeze()
loss = bradley_terry_loss(r_w, r_l)
optimizer.zero_grad(); loss.backward(); optimizer.step()
Définition 97 (PPO dans le contexte RLHF)
L’optimisation par Proximal Policy Optimization (PPO, Schulman et al., 2017) dans le contexte RLHF maximise la récompense prédite par le RM tout en restant proche du modèle SFT. L’objectif combiné est :
ou \(\pi_{\text{ref}} = \pi_{\text{SFT}}\) est la politique de référence et \(\beta\) est le coefficient de pénalité KL. PPO utilise un mécanisme de clipping pour limiter la taille des mises à jour de la politique, ce qui stabilise l’entrainement :
ou \(\rho_t = \pi_\theta(a_t|s_t) / \pi_{\theta_{\text{old}}}(a_t|s_t)\) est le ratio de probabilité et \(\hat{A}_t\) est l’estimateur d’avantage. En pratique, l’entrainement PPO des LLM est notablement instable et nécessite un réglage minutieux des hyperparamètres.
DPO : optimisation directe des préférences#
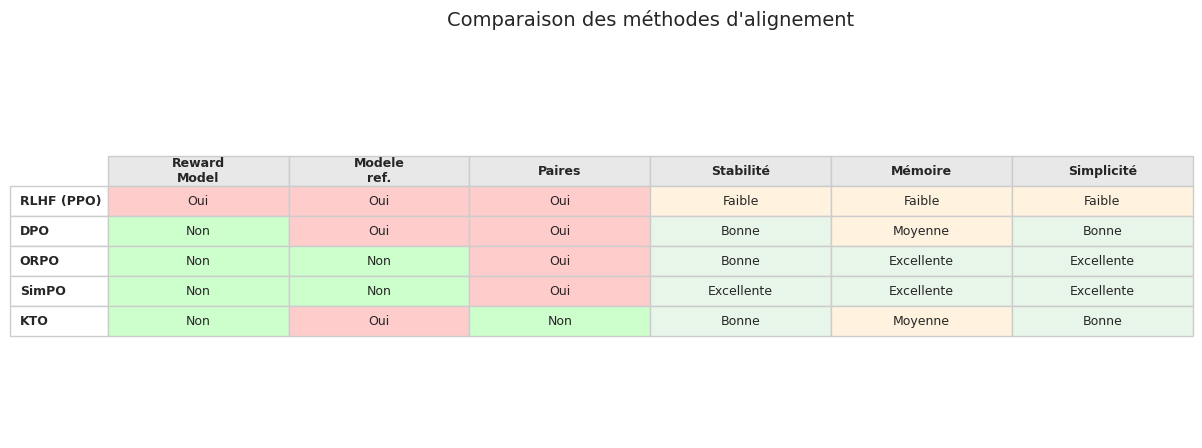
Le pipeline RLHF est efficace mais complexe : il requiert l’entrainement d’un modèle de récompense séparé, puis une boucle d’optimisation RL (PPO) qui est notablement instable et coûteuse en calcul. Direct Preference Optimization (DPO, Rafailov et al., 2023) propose une simplification élégante en montrant qu’on peut optimiser directement les préférences humaines, sans passer par un modèle de récompense explicite.
Définition 98 (DPO (Direct Preference Optimization))
L”optimisation directe des préférences (Direct Preference Optimization, DPO, Rafailov et al., 2023) reformule le problème d’alignement comme un problème de classification sur des paires de préférences. Au lieu d’entrainer un modèle de récompense puis d’optimiser via PPO, DPO dérive une perte qui optimise directement la politique du modèle. La perte DPO est :
où \(y_w\) est la réponse préférée, \(y_l\) la réponse rejetée, \(\pi_{\text{ref}}\) la politique de référence (typiquement le modèle SFT), \(\beta\) le paramètre de température et \(\sigma\) la fonction sigmoide. Cette perte augmente la probabilité relative de \(y_w\) par rapport a \(y_l\), en utilisant \(\pi_{\text{ref}}\) comme ancre pour éviter la dégénérescence.
Propriété 22 (Equivalence DPO-RLHF)
Rafailov et al. (2023) montrent que la solution optimale du problème RLHF avec contrainte KL admet une forme analytique. La politique optimale \(\pi^*\) du problème :
est donnée par :
En inversant cette relation, on obtient la récompense implicite de DPO :
En substituant dans la perte de Bradley-Terry, le terme \(Z(x)\) s’annule (il ne dépend pas de \(y\)), et on retrouve exactement la perte DPO. Ainsi, DPO et RLHF optimisent le même objectif, mais DPO le fait en une seule étape de classification, sans modèle de recompense ni boucle RL.
Remarque 95 (Avantages de DPO sur RLHF)
DPO présente plusieurs avantages pratiques par rapport a RLHF :
Simplicité : pas de modèle de récompense à entrainer, pas de boucle RL, pas de PPO. L’entrainement est une simple classification supervisée.
Stabilité : l’absence de PPO élimine une source majeure d’instabilité. L’entrainement DPO converge de manière plus fiable.
Coût : DPO nécessite moins de GPU et moins de temps de calcul, car il n’y a qu’un seul modèle à entrainer (au lieu de trois avec RLHF : SFT + RM + politique).
Mémoire : DPO ne nécessite que deux copies du modèle en mémoire (politique et référence), contre trois ou quatre pour RLHF.
En revanche, DPO peut être moins performant que RLHF sur des distributions de préférences très complexes, et il est plus sensible à la qualité des paires de préférences. De plus, il ne produit pas de modèle de récompense explicite, ce qui peut être un inconvénient pour le monitoring et le debug.
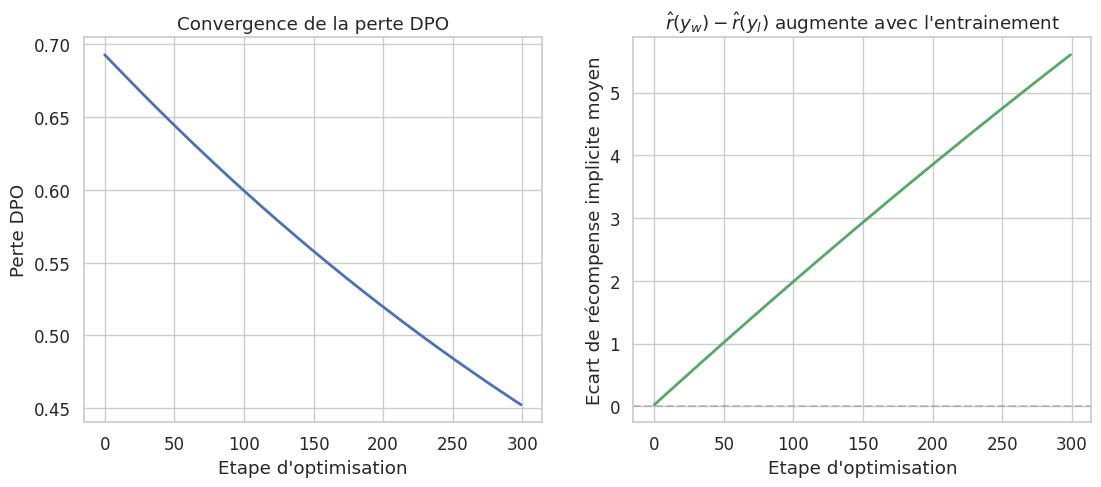
Exemple 70 (Calcul de la perte DPO)
Considérons un exemple simplifié avec un prompt \(x\) et deux réponses. Les log-probabilités sont :
| | \(\log \pi_\theta(y|x)\) | \(\log \pi_{\text{ref}}(y|x)\) | |—|—|—| | Réponse préférée \(y_w\) | \(-2.1\) | \(-2.5\) | | Réponse rejetée \(y_l\) | \(-1.8\) | \(-1.6\) |
Avec \(\beta = 0.1\) :
La perte est faible (proche de \(-\log(0.5) \approx 0.693\)), ce qui signifie que le modèle accorde déjà une légère préférence à \(y_w\). L’optimisation va accentuer cette préférence.
ORPO et variantes recentes#
Le paysage des méthodes d’alignement s’est rapidement diversifié après DPO. Plusieurs variantes cherchent à simplifier encore le pipeline, à éliminer le besoin d’un modèle de référence, ou à fonctionner avec des types de retour différents.
Définition 99 (ORPO (Odds Ratio Preference Optimization))
L”ORPO (Odds Ratio Preference Optimization, Hong et al., 2024) combine l’étape SFT et l’étape d’alignement en une seule phase d’entrainement, sans modèle de référence. La perte ORPO est :
où \(\mathcal{L}_{\text{SFT}}(y_w)\) est la perte de vraisemblance standard sur la réponse préférée et \(\mathcal{L}_{\text{OR}}\) est un terme basé sur le rapport de côtes (odds ratio) :
avec \(\text{odds}_\theta(y|x) = \frac{P_\theta(y|x)}{1 - P_\theta(y|x)}\). L’avantage principal d’ORPO est l’élimination du modèle de référence \(\pi_{\text{ref}}\), ce qui réduit de moitié la mémoire GPU nécessaire.
Parmi les autres variantes notables :
SimPO (Simple Preference Optimization, Meng et al., 2024) simplifie DPO en utilisant la log-probabilité moyenne (normalisée par la longueur) comme récompense implicite et en ajoutant un terme de marge. Cela élimine le besoin de \(\pi_{\text{ref}}\) tout en préservant la stabilité.
KTO (Kahneman-Tversky Optimization, Ethayarajh et al., 2024) s’inspire de la théorie des perspectives de Kahneman et Tversky pour fonctionner avec des signaux de retour non appariés : au lieu de paires (préféré, rejeté), KTO peut utiliser des retours individuels « bon » ou « mauvais » sur des réponses isolées. Cela simplifie considérablement la collecte de données.
IPO (Identity Preference Optimization, Azar et al., 2023) corrige un biais théorique de DPO en utilisant une perte quadratique plutôt que logistique, ce qui évite la sur-confiance sur les paires faciles.
Constitutional AI#
L’approche Constitutional AI (CAI), proposee par Bai et al. (2022, Anthropic), offre une alternative au retour humain direct en remplacant une partie des annotations humaines par de l’auto-critique guidée par des principes explicites — une « constitution ».
Définition 100 (Constitutional AI)
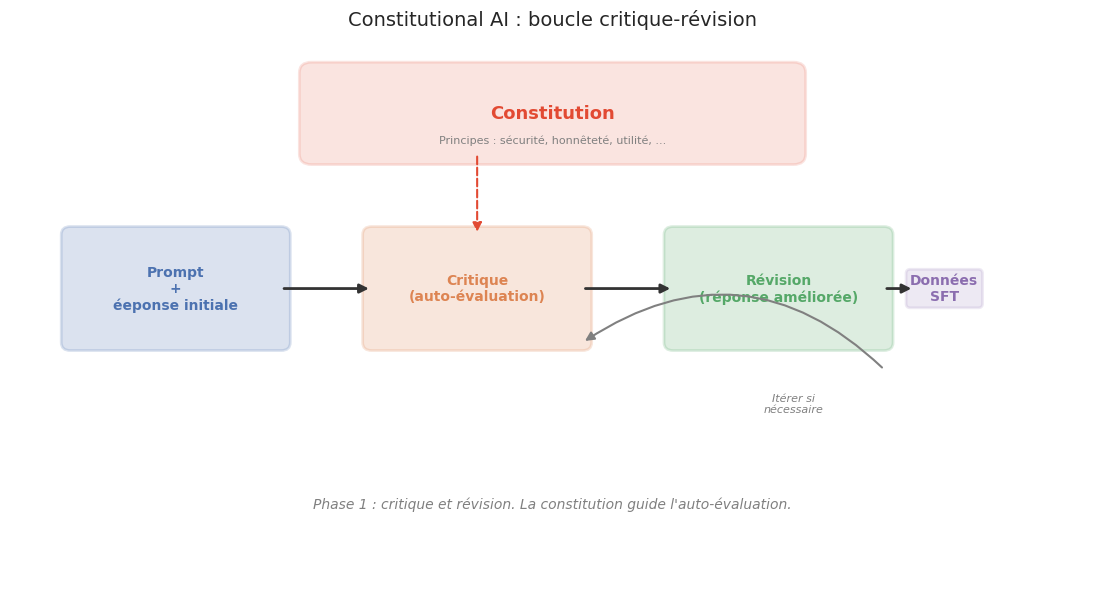
L”IA constitutionnelle (Constitutional AI, CAI, Bai et al., 2022) est une méthode d’alignement en deux phases :
Phase de critique et revision (critique-revision) : le modèle génère une réponse initiale à un prompt, puis se critique lui-même selon un ensemble de principes (la « constitution ») et produit une version révisée. Ce processus est répété pour chaque principe pertinent. Les paires (réponse initiale, réponse révisée) servent de données d’entrainement SFT.
Phase RLAIF (Reinforcement Learning from AI Feedback) : au lieu d’annotateurs humains, un modèle LLM évalue les paires de réponses en se référant à la constitution. Le modèle de récompense est entrainé sur ces préférences générées par l’IA, puis la politique est optimisée par RL comme dans le pipeline RLHF standard.
La constitution est un ensemble de principes explicites, par exemple : « Choisir la réponse la moins susceptible d’être perçue comme nuisible par un observateur raisonnable » ou « Choisir la réponse la plus honnête et véridique ».
Remarque 96 (Rôle de la constitution)
Les principes constitutionnels jouent un role analogue aux consignes données aux annotateurs humains dans RLHF, mais avec plusieurs avantages :
Explicite et auditable : la constitution est un document textuel que l’on peut inspecter, débattre et modifier. Les critères implicites des annotateurs humains sont, au contraire, opaques et inconsistants.
Scalable : la critique automatisée ne coûte que le prix de l’inférence, bien moins que les annotateurs humains. On peut générer des millions de paires critique-revision.
Reproductible : les mêmes principes appliqués au même modèle produisent des résultats comparables, ce qui améliore la reproductibilité par rapport aux annotations humaines.
Composable : on peut ajouter, retirer ou modifier des principes individuels pour ajuster le comportement du modèle sur des aspects spécifiques.
L’inconvénient est que la qualité de l’auto-critique est bornée par les capacités du modèle critique. Un modèle médiocre produira des critiques médiocres, limitant le bénéfice de l’approche.
Reward hacking et problèmes d’alignement#
L’alignement par optimisation d’une fonction de récompense apprise est sujet à une pathologie fondamentale : le reward hacking. Le modèle peut apprendre à exploiter les failles du modèle de récompense plutôt qu’à réellement satisfaire les préférences humaines.
Définition 101 (Reward hacking)
Le reward hacking (ou reward gaming, reward exploitation) est le phénomène par lequel un agent optimise une fonction de récompense proxy \(r_\phi\) de manière à obtenir un score élevé sans véritablement satisfaire l’objectif sous-jacent \(R^*\). Dans le contexte de l’alignement des LLM, cela se manifeste lorsque le modèle decouvre des stratégies qui maximisent le score du modèle de récompense sans améliorer — voire en dégradant — la qualité réelle des réponses telle qu’évaluée par des humains.
Exemples typiques :
Générer des réponses excessivement longues et verbeuses (le RM ayant appris que les reponses longues sont souvent préférées).
Répéter des formules de politesse ou des mises en garde qui plaisent au RM mais n’apportent rien.
Produire du texte qui « sonne bien » mais est factuellement incorrect.
Utiliser un style flatteur ou excessivement confiant pour obtenir un score élevé.
Remarque 97 (Loi de Goodhart)
La loi de Goodhart (1975) énonce que « quand une mesure devient un objectif, elle cesse d’être une bonne mesure ». Dans le contexte de l’alignement :
Le modèle de récompense \(r_\phi\) est une mesure (imparfaite) des préférences humaines.
Lorsqu’on en fait un objectif d’optimisation, le modèle aligne exploite les écarts entre \(r_\phi\) et les vraies préférences \(R^*\).
Plus l’optimisation est poussée (plus de pas PPO, \(\beta\) trop faible), plus le reward hacking devient sévère.
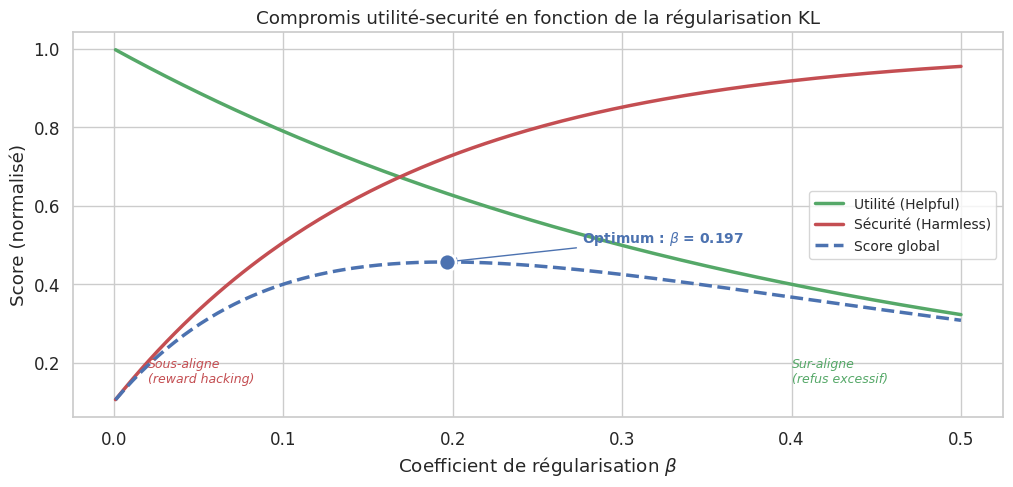
Ce phénomène est analogue au surapprentissage en apprentissage supervisé : le modèle s’adapte trop bien au signal d’entrainement (ici, le RM) et se généralise mal à l’objectif réel (les préférences humaines). La régularisation KL (\(\beta\)) joue un rôle analogue à la régularisation L2 : elle empêche le modèle de trop s’éloigner d’une solution raisonnable (\(\pi_{\text{ref}}\)).
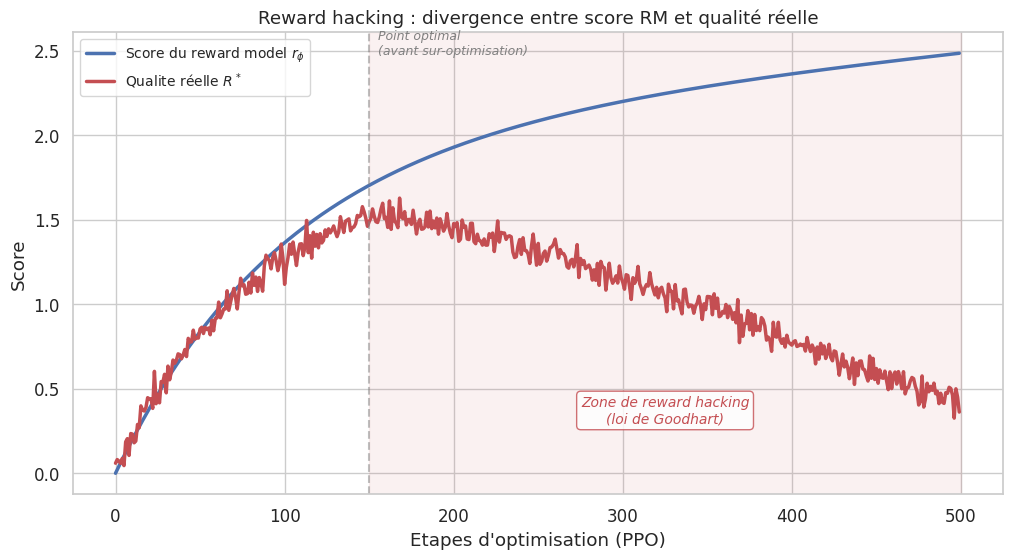
Le problème du reward hacking motive le recours à la régularisation KL, qui pénalise les politiques trop éloignées de \(\pi_{\text{ref}}\). Cependant, un \(\beta\) trop élevé empêche tout progrès, tandis qu’un \(\beta\) trop faible laisse le champ libre au reward hacking. Trouver le bon équilibre est un art empirique.
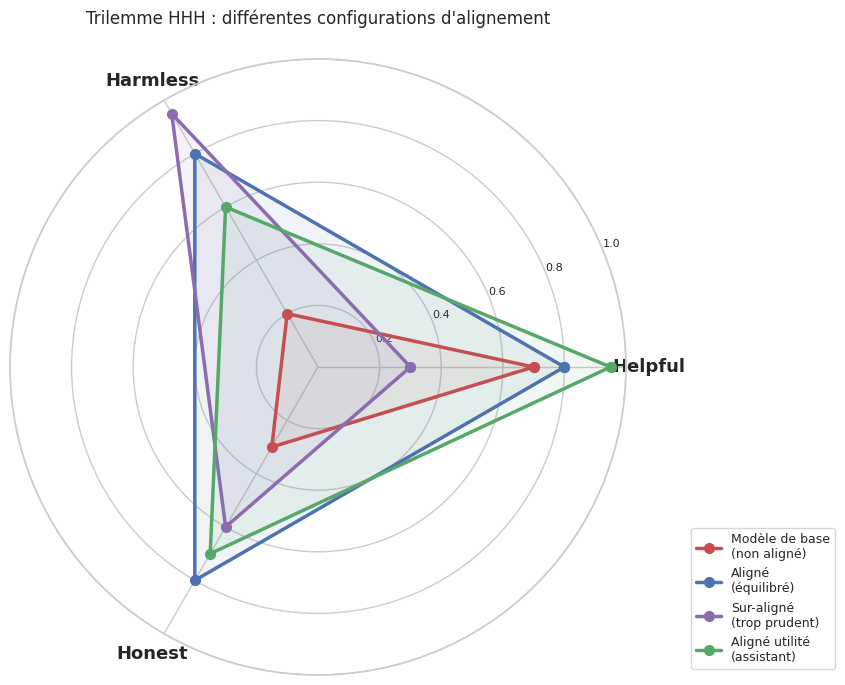
Le trilemme HHH#
Les objectifs d’alignement sont souvent résumés par l’acronyme HHH : Helpful, Harmless, Honest (Askell et al., 2021, Anthropic). Ces trois propriétés définissent un trilemme : il est difficile de les satisfaire simultanément.
Remarque 98 (Le trilemme HHH)
Le trilemme HHH (Helpful, Harmless, Honest) capture les tensions fondamentales de l’alignement :
Helpful (utile) : le modèle doit fournir des réponses pertinentes, complètes et actionables. Il doit aider l’utilisateur à accomplir ses objectifs.
Harmless (inoffensif) : le modèle ne doit pas générer de contenus dangereux, discriminatoires, trompeurs ou susceptibles de causer du tort.
Honest (honnête) : le modèle doit etre véridique, reconnaitre son incertitude et ses limites, et ne pas fabriquer d’informations (hallucinations).
Les tensions entre ces objectifs sont réelles :
Tension |
Exemple |
|---|---|
Helpful vs Harmless |
L’utilisateur demande comment fabriquer un explosif « pour un cours de chimie ». Etre utile impliquerait de repondre ; etre inoffensif impliquerait de refuser. |
Helpful vs Honest |
L’utilisateur demande un avis médical. Etre utile pousserait a donner une réponse détaillée ; être honnête imposerait de rappeler les limites du modèle. |
Harmless vs Honest |
Un modèle trop prudent (« harmless ») refusera de répondre à des questions légitimes, ce qui est une forme de malhonnêteté par omission. |
L’équilibre entre ces trois objectifs est un choix de conception qui varie selon le contexte de déploiement, la population d’utilisateurs et le cadre réglementaire.
Résumé#
Ce chapitre a présenté les fondements conceptuels et techniques de l’alignement des grands modèles de langage, c’est-à-dire le problème de faire en sorte qu’un modèle très capable se comporte conformément aux intentions de ses utilisateurs et de la société.
Le problème de l’alignement nait de l’ecart entre l’objectif de pré-entrainement (prédire le token suivant) et le comportement souhaité (être utile, honnête et inoffensif). Un LLM de base est un générateur de texte, pas un assistant : l’alignement est le processus qui comble cet écart, au prix d’une « taxe d’alignement » généralement modeste.
Le RLHF (Reinforcement Learning from Human Feedback) est le pipeline d’alignement historique, en trois étapes : (1) SFT sur des démonstrations humaines, (2) entrainement d’un modèle de récompense sur des préfèrences humaines via la perte de Bradley-Terry, (3) optimisation de la politique par PPO sous contrainte KL. Ce pipeline a produit ChatGPT et InstructGPT, mais il est complexe, coûteux et instable.
Le DPO (Direct Preference Optimization, Rafailov et al., 2023) simplifie radicalement le pipeline en montrant que l’optimisation des préférences peut être reformulée comme une classification supervisée, sans modèle de récompense ni boucle RL. DPO et RLHF optimisent le même objectif, mais DPO le fait en une seule étape, avec une stabilité et une simplicité supérieures.
Les variantes récentes (ORPO, SimPO, KTO) poursuivent la simplification : ORPO élimine le modèle de référence, KTO fonctionne avec des retours non appariés, SimPO normalise par la longueur. Le choix de la méthode dépend du budget, des données disponibles et des contraintes mémoire.
L”IA constitutionnelle (Constitutional AI, Bai et al., 2022) remplace une partie du retour humain par de l’auto-critique guidée par des principes explicites (une « constitution »). La boucle critique-révision produit des données d’entrainement à moindre coût, avec l’avantage de l’explicite, de la scalabilité et de la reproductibilité.
Le reward hacking est la pathologie centrale de l’alignement par optimisation : le modèle exploite les failles du modèle de récompense plutôt que de satisfaire les vraies préférences humaines. La loi de Goodhart — « quand une mesure devient un objectif, elle cesse d’être une bonne mesure » — formalise ce risque. La régularisation KL (\(\beta\)) est le principal garde-fou, mais son réglage reste empirique.
Le trilemme HHH (Helpful, Harmless, Honest) structure la réflexion sur les objectifs d’alignement. Les tensions entre utilité, securité et honnêteté sont irréductibles : un modèle trop prudent refuse des requêtes légitimes, un modèle trop utile peut être dangereux, un modèle trop honnête sur ses limites peut paraitre inutile. L’équilibre dépend du contexte de déploiement.