Frontières et perspectives#
Ce dernier chapitre dresse un panorama des frontières actuelles de l’intelligence artificielle et des grands modèles de langage. Apres avoir traversé, tout au long de ce livre, les fondations architecturales, le prompting, le raisonnement, la mémoire, les agents, l’alignement et le fine-tuning, il est temps de lever les yeux vers l’horizon. Les progrès des deux dernières années ont été fulgurants : des agents autonomes capables de coder pendant des heures, des modèles qui « réfléchissent » plus longtemps pour mieux raisonner, des architectures qui pourraient supplanter le Transformer. Ces avancées posent des questions techniques, mais aussi économiques, sociétales et philosophiques.
L’objectif de ce chapitre est triple. D’abord, présenter les directions de recherche les plus actives : agents de longue durée, scaling de l’inférence, architectures alternatives au Transformer. Ensuite, aborder les grands débats qui structurent le domaine : la question de l’AGI, les implications sociétales et la concentration du pouvoir technologique. Enfin, proposer au lecteur une feuille de route concrète pour devenir expert en IA, en synthétisant les compétences et les ressources nécessaires.
Ce chapitre est délibérement tourné vers l’avenir, et certaines de ses affirmations seront inévitablement datées. C’est la nature même d’un domaine qui évolue à une vitesse sans précédent. L’important n’est pas de prédire exactement ce qui arrivera, mais de fournir les cadres conceptuels qui permettent de comprendre et d’évaluer les développements futurs.
Agents autonomes de longue durée#
Les chapitres 12 a 15 ont presenté les agents LLM : des systèmes qui utilisent un modèle de langage comme « cerveau » pour planifier, utiliser des outils et accomplir des tâches complexes. Mais la plupart des exemples étaient des agents a horizon court : quelques étapes, quelques minutes d’exécution. La frontière actuelle est celle des agents à horizon long, capables de travailler de manière autonome pendant des heures, voire des jours, sur des tâches complexes et ouvertes.
Définition 121 (Agent autonome de longue durée)
Un agent autonome de longue durée (long-horizon autonomous agent) est un système fondé sur un LLM qui exécute une tâche complexe de manière autonome sur un horizon temporel étendu (dizaines de minutes à plusieurs heures), en enchainant de nombreuses étapes de planification, d’exécution et de correction. Formellement, l’agent réalise une trajectoire \((a_1, o_1, a_2, o_2, \ldots, a_T, o_T)\) ou \(T\) est grand (typiquement \(T > 50\)), chaque action \(a_t\) étant conditionnée par l’historique complet \((a_1, o_1, \ldots, a_{t-1}, o_{t-1})\) et l’objectif initial \(g\). Les défis spécifiques aux agents de longue durée incluent l”accumulation d’erreurs, la gestion du contexte (dépassement de la fenêtre) et la planification sur de nombreuses étapes.
Exemple 81 (Agents de longue durée : exemples concrets)
Plusieurs agents de longue durée ont marqué l’année 2024-2025 :
Devin (Cognition, 2024) : agent d’ingénierie logicielle capable de résoudre des issues GitHub de bout en bout. Evalué sur SWE-bench, il planifie une approche, édite des fichiers, exécute des tests et itère jusqu’à la résolution. Son horizon typique est de 30 à 120 minutes par tâche.
Claude Code (Anthropic, 2025) : agent de programmation en ligne de commande qui peut naviguer dans un codebase, comprendre l’architecture, implémenter des fonctionnalités et exécuter des tests. Il maintient un contexte de travail sur des sessions prolongées.
Agents de recherche autonome (AutoGPT, OpenDevin, SWE-Agent) : systèmes qui décomposent un objectif de recherche en sous-tâches, collectent de l’information, synthétisent des resultats et itèrent. Leur fiabilité reste limitée sur les horizons très longs.
Objectif : "Corriger le bug #1234 dans le dépôt X"
Agent (etape 1) : Cloner le dépôt, lire l'issue
Agent (etape 12) : Identifier le fichier source concerné
Agent (etape 25) : Implémenter le correctif
Agent (etape 38) : Ecrire des tests unitaires
Agent (etape 45) : Exécuter la suite de tests
Agent (etape 52) : Corriger un test qui échoue
Agent (etape 60) : Valider et soumettre le patch
La difficulté principale est que chaque étape peut introduire une erreur qui se propage aux étapes suivantes.
Remarque 120
Le coût d’un agent de longue durée est considérable. Un agent qui travaille pendant une heure sur une tâche de programmation peut consommer plusieurs millions de tokens en entrée et en sortie, soit un coût de l’ordre de 10 a 50 dollars par tache pour les modèles les plus capables. Ce coût est à mettre en perspective avec le salaire horaire d’un développeur, mais il impose une contrainte économique forte : les agents de longue durée ne sont viables que si leur taux de réussite est suffisamment élevé pour justifier l’investissement. Le compromis coût/fiabilité est l’un des principaux freins au déploiement généralisé de ces systèmes.
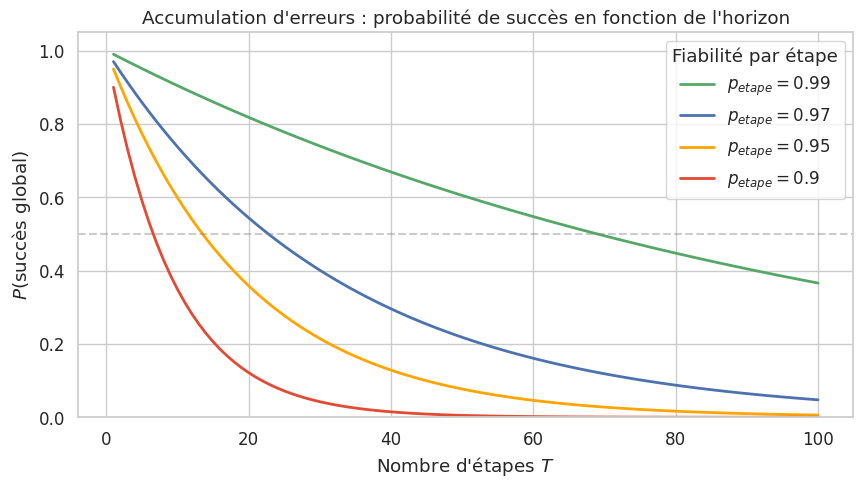
Même avec une fiabilité de 97% par étape, un agent qui doit enchainer 100 étapes n’a qu’environ 5% de chances de réussir sans aucune erreur. C’est pourquoi les agents de longue durée intègrent des mécanismes de vérification, de backtracking et de replannification : plutot que de viser la perfection a chaque étape, ils détectent et corrigent leurs erreurs en cours de route.
Scaling de l’inférence (test-time compute)#
Les lois d’échelle du chapitre 1 portaient sur l”entrainement : plus de paramètres, plus de données, plus de compute produisent de meilleurs modèles. Mais une révolution conceptuelle récente consiste à appliquer le même principe a l”inférence : plutôt que d’augmenter le compute à l’entrainement, on augmente le compute au moment de la prédiction. C’est l’idée du test-time compute.
Définition 122 (Test-time compute (scaling de l’inférence))
Le test-time compute (ou inference-time scaling) désigne l’approche consistant à allouer davantage de ressources de calcul au moment de l’inférence pour améliorer la qualité des réponses. Au lieu d’un unique passage à travers le modèle (forward pass), le système effectue plusieurs étapes de raisonnement interne, explore différentes pistes et vérifie ses conclusions avant de produire la réponse finale. Formellement, si un modèle standard calcule \(y = f_\theta(x)\) en un seul passage, un modèle avec test-time compute calcule :
où \(C_{\text{test}}\) est le budget de calcul alloué à l’inférence. La performance \(P\) croit avec \(C_{\text{test}}\) selon une loi de la forme :
où \(\alpha_{\text{test}}\) est l’exposant de scaling de l’inférence.
L’approche a été popularisée par OpenAI avec les modèles o1 (2024) et o3 (2025), qui utilisent un mécanisme de « raisonnement interne » (chain-of-thought interne) avant de produire leur réponse. Le modèle « pense » plus longtemps sur les problèmes difficiles, générant parfois des dizaines de milliers de tokens de raisonnement intermédiaire invisibles pour l’utilisateur.
Exemple 82 (Raisonnement o1 sur un problème mathematique)
Sur un problème de mathématiques de compétition (AIME), le modèle o1 peut générer un raisonnement interne de plusieurs milliers de tokens :
[Raisonnement interne - non visible par l'utilisateur]
Analysons le problème... Il s'agit de trouver le nombre de
solutions entières de l'équation x^2 + y^2 = 100.
Approche 1 : Enumération directe. Pour x de 0 a 10, on
cherche si 100 - x^2 est un carré parfait...
x=0 : 100 = 10^2 -> oui
x=6 : 64 -> 8^2 -> oui
x=8 : 36 -> 6^2 -> oui
x=10 : 0 -> 0^2 -> oui
En comptant les symétries (signes de x et y)...
Attendons, verifions : (0,10), (6,8), (8,6), (10,0)
et leurs symétries par changement de signe.
[... plusieurs centaines de tokens de verification ...]
Total : 12 solutions.
Le temps de calcul est 10 à 100 fois supérieur à un modèle standard, mais la précision sur les problèmes mathématiques difficiles est considérablement améliorée.
Remarque 121
L’approche « think harder » (dépenser plus de compute à l’inférence) est complémentaire de l’approche « think faster » (entrainer un modèle plus performant). La première est flexible — on peut ajuster le budget de calcul en fonction de la difficulté du problème — mais coûteuse à chaque utilisation. La seconde est coûteuse une seule fois (à l’entrainement) mais ne permet pas d’adaptation dynamique. Le futur sera probablement une combinaison des deux : des modèles bien entrainés qui savent aussi « réfléchir plus longtemps » quand c’est nécessaire.
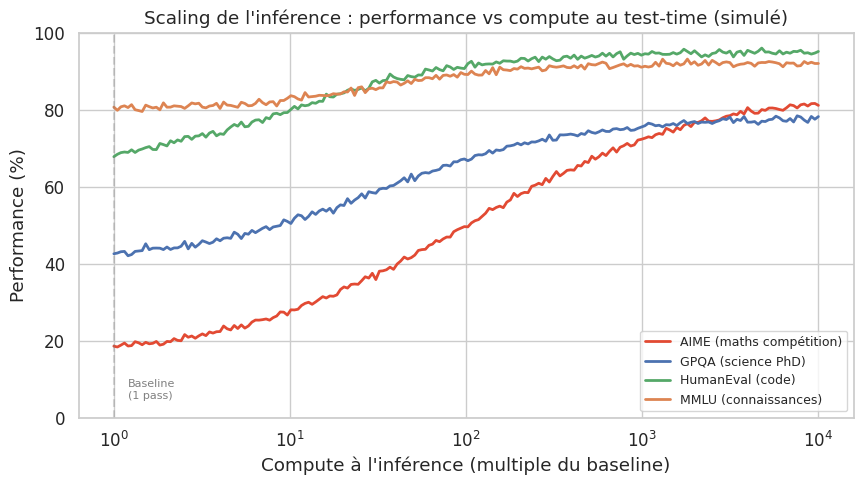
On observe que le gain du test-time compute est particulièrement marqué sur les tâches de raisonnement (mathématiques, science) où le modèle standard échoue faute de pouvoir « réflechir ». Sur les taches de connaissances factuelles (MMLU), le gain est plus modeste car la réponse est déjà « dans » les poids du modèle.
Au-delà du Transformer : nouvelles architectures#
Depuis 2017, le Transformer domine le paysage de l’IA. Mais sa complexité quadratique en \(O(T^2)\) par rapport à la longueur de la séquence \(T\) pose un problème fondamental pour les contextes très longs. Plusieurs architectures alternatives ont émergé, fondées sur des modèles à espace d’états (State Space Models, SSM).
Définition 123 (Modèle à espace d’états (SSM))
Un modele à espace d’états (State Space Model, SSM) est un modèle séquentiel inspiré de la théorie du contrôle, défini par les équations :
où \(x_t \in \mathbb{R}^d\) est l’entrée au temps \(t\), \(h_t \in \mathbb{R}^n\) est l’état caché, \(y_t \in \mathbb{R}^d\) est la sortie, et \(\bar{A}, \bar{B}, C, D\) sont des matrices de paramètres (discrétisées à partir d’un système continu). L’avantage fondamental est que le traitement d’une séquence de longueur \(T\) est en \(O(T)\) (récurrence) ou en \(O(T \log T)\) (convolution), contre \(O(T^2)\) pour l’auto-attention du Transformer.
Exemple 83 (Architectures SSM notables)
Plusieurs architectures SSM ont été proposées :
S4 (Gu et al., 2022) : le modèle fondateur, qui montre que les SSM correctement paramétrisés peuvent rivaliser avec les Transformers sur les séquences longues. Utilise une initialisation HiPPO (High-order Polynomial Projection Operator) pour capturer les dépendances à long terme.
Mamba (Gu & Dao, 2023) : une évolution majeure qui introduit la selectivité — les matrices \(\bar{B}\) et \(C\) dépendent de l’entrée \(x_t\), permettant au modèle de filtrer l’information pertinente de manière adaptative. Mamba atteint des performances comparables aux Transformers de même taille sur le langage.
RWKV (Peng et al., 2023) : une architecture hybride qui combine des idées des RNN et de l’attention, avec une complexité linéaire. Positionnée comme une alternative open-source au Transformer.
Jamba (AI21 Labs, 2024) : un modèle hybride qui alterne des couches Mamba et des couches d’attention Transformer, combinant la complexité linéaire des SSM pour les séquences longues et la puissance expressive de l’attention pour les patterns locaux.
Transformer : Attention(Q, K, V) -> O(T^2 * d)
Mamba : SSM selectif -> O(T * d * n)
Jamba : Alternance des deux -> compromis
Propriété 28 (Complexité comparee SSM vs Transformer)
Pour une séquence de longueur \(T\) et une dimension \(d\) du modèle :
Transformer (auto-attention) : complexité en temps et en mémoire \(O(T^2 \cdot d)\). Le terme \(T^2\) provient du produit \(Q K^T\) qui compare chaque position à toutes les autres.
SSM (récurrence) : complexité en temps \(O(T \cdot d \cdot n)\) ou \(n\) est la dimension de l’état caché (typiquement \(n \ll T\)). La mémoire est \(O(d \cdot n)\) en mode récurrent (constante par rapport a \(T\)).
SSM (convolution) : complexité en temps \(O(T \log T \cdot d)\) par FFT. Plus rapide que la récurrence pour l’entrainement en parallèle.
Pour \(T = 100\,000\) et \(n = 64\), le ratio de complexité est de l’ordre de \(T / n \approx 1\,500\), soit un gain de trois ordres de grandeur en faveur des SSM.
Remarque 122
Malgré leurs avantages théoriques, les SSM n’ont pas (encore) remplacé les Transformers. Plusieurs raisons expliquent cette résistance. D’abord, l’écosystème d’optimisation (FlashAttention, vLLM, TensorRT) est massivement optimisé pour les Transformers. Ensuite, les SSM peinent encore à égaler les Transformers sur les tâches qui nécessitent une attention fine à des éléments distants dans le contexte (retrieval, copie exacte). Enfin, les architectures hybrides comme Jamba suggèrent que l’avenir n’est peut-être pas le remplacement du Transformer, mais sa complémentation par des couches SSM pour les séquences longues. La question « les SSM remplaceront-ils les Transformers ? » est probablement mal posée : la réponse sera plutôt un mélange des deux paradigmes.
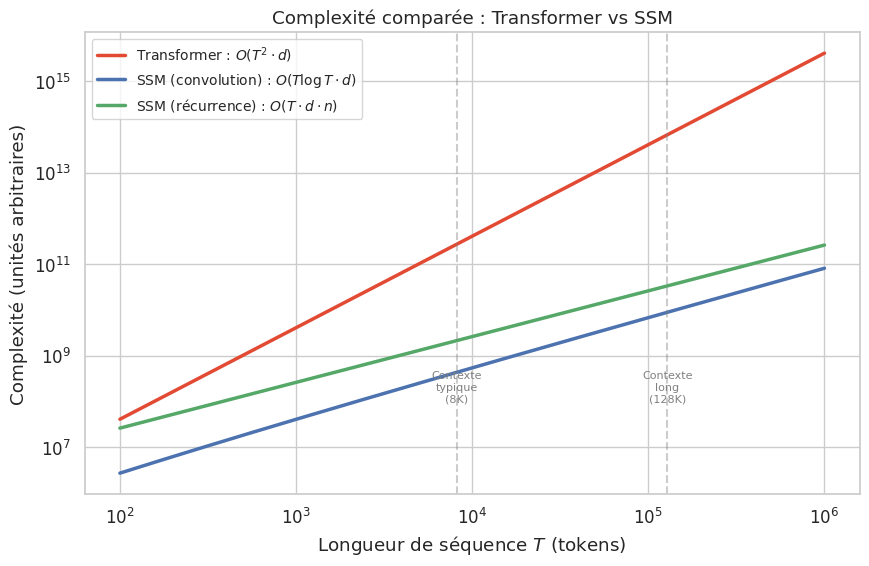
L’écart de complexité devient colossal pour les contextes longs : a \(T = 128\,000\) tokens, le Transformer est environ \(2\,000\) fois plus coûteux que le SSM en mode récurrent. C’est pourquoi les architectures SSM sont particulièrement prometteuses pour les applications qui nécessitent de traiter des documents entiers, des bases de code complètes ou des conversations très longues.
Le débat sur l’AGI#
Aucune discussion sur les frontières de l’IA ne peut éviter la question la plus controversée du domaine : sommes-nous proches de l”intelligence artificielle générale (AGI) ? Le débat est vif, les positions sont tranchées, et les définitions mêmes font l’objet de désaccords profonds.
Définition 124 (Intelligence artificielle générale (AGI))
L”intelligence artificielle générale (Artificial General Intelligence, AGI) désigne un système d’IA hypothétique capable d’accomplir toute tâche intellectuelle qu’un être humain peut réaliser, avec un niveau de compétence au moins égal. Contrairement à l’IA étroite (narrow AI), spécialisée dans un domaine, l’AGI possèderait des capacités de généralisation, d’apprentissage, de raisonnement et d’adaptation comparables à celles de l’intelligence humaine. Il n’existe pas de définition formelle consensuelle de l’AGI ; les critères varient selon les auteurs :
Critère de Turing : tromper un humain dans une conversation.
Critère economique (OpenAI) : un système capable de remplacer un travailleur intellectuel médian.
Critère de généralisation : performance de niveau humain sur un ensemble arbitraire de tâches nouvelles.
Critère d’autonomie : capacité à fixer ses propres objectifs et à apprendre de manière autonome.
Remarque 123
Les estimations de la timeline vers l’AGI varient énormément selon les experts et les définitions retenues :
Optimistes (certains chercheurs d’OpenAI, Google DeepMind) : l’AGI pourrait être atteinte d’ici 2027-2030, en extrapolant les courbes actuelles de progrès.
Pessimistes (Yann LeCun, Gary Marcus) : les architectures actuelles (Transformers, LLM) sont fondamentalement limitées et ne mèneront pas à l’AGI. Des percées conceptuelles majeures (raisonnement causal, modélisation du monde) sont nécessaires.
Position intermédiaire : les LLM actuels possèdent des capacités impressionnantes mais pas les propriétés fondamentales de l’intelligence générale (planification à long terme, compréhension causale, ancrage physique). L’AGI nécessitera probablement des innovations significatives au-delà du paradigme actuel.
Ce débat est sain et nécessaire, mais il est souvent pollué par des définitions mouvantes et des intérêts commerciaux.
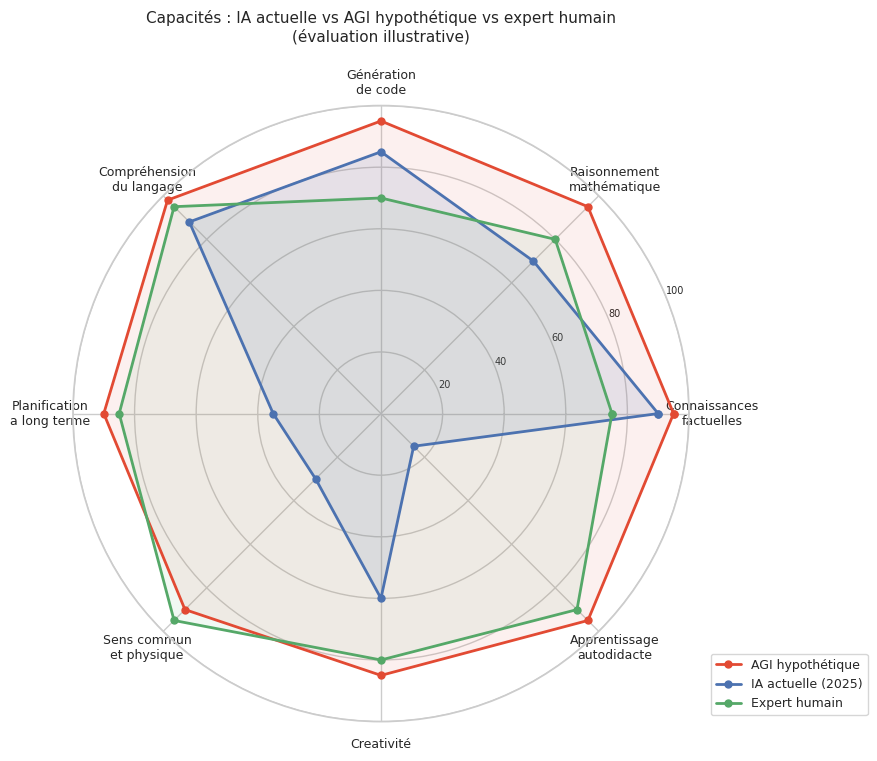
Ce radar illustre un point crucial : l’IA actuelle excelle dans certaines dimensions (connaissances, code, langage) mais reste très en-deçà du niveau humain sur d’autres (planification à long terme, sens commun physique, apprentissage autodidacte). L’AGI n’est pas simplement « un meilleur LLM » — elle nécessiterait des progrès fondamentaux dans les dimensions où l’IA actuelle est la plus faible.
Implications sociétales et économiques#
Les avancées en IA ne sont pas confinées au laboratoire. Elles transforment déjà le marché du travail, l’éducation, les industries créatives et la distribution du pouvoir économique. Ces implications sont trop importantes pour être laissées aux seuls technologues.
Remarque 124
Impact sur l’emploi. L’automatisation par l’IA ne suit pas le schéma classique de l’automatisation industrielle (remplacement des tâches manuelles et répétitives). Les LLM touchent en priorité les tâches intellectuelles : rédaction, analyse, programmation, conseil. Selon les études (Goldman Sachs, 2023 ; McKinsey, 2024), entre 15% et 30% des heures de travail dans les économies avancées pourraient être automatisées par l’IA générative. Mais l’histoire montre que l’automatisation crée aussi de nouveaux emplois — la question est de savoir si la transition sera assez rapide et équitable.
Education. L’IA générative bouleverse l’enseignement à tous les niveaux. Les étudiants peuvent utiliser les LLM pour générer des dissertations, résoudre des exercices ou coder des programmes. Cela pose des questions fondamentales sur l’évaluation, la fraude et la nature même de l’apprentissage. Mais c’est aussi une opportunité : les LLM peuvent servir de tuteurs personnalisés, disponibles 24h/24, capables d’adapter leur pédagogie au niveau de l’élève.
Industries créatives. La génération de texte, d’images (DALL-E, Midjourney, Stable Diffusion), de musique et de vidéo par l’IA soulève des questions de propriété intellectuelle, de rémunération des artistes dont les oeuvres ont servi à l’entrainement, et de dévaluation du travail creatif. Le débat juridique est en cours et loin d’être tranché.
Concentration du pouvoir. L’entrainement des plus grands modèles nécessite des investissements de l’ordre de centaines de millions de dollars, ce qui concentre la capacité de production d’IA entre les mains de quelques entreprises (OpenAI, Google, Anthropic, Meta). Cette concentration soulève des questions de gouvernance, de dépendance technologique et d’équité d’accès.
Devenir expert IA : feuille de route#
Ce livre a couvert un vaste territoire, des Transformers aux agents multi-agents, du prompt engineering à l’alignement. Mais que faut-il maitriser pour devenir un expert en IA ? Cette section propose une feuille de route structurée autour de six axes de compétence.
Remarque 125
Le profil d’un expert en IA avancée combine des compétences techniques (mathématiques, programmation, ML), des compétences spécifiques aux LLM (prompting, RAG, agents, fine-tuning), une sensibilité à l”éthique et à la sécurité, et une expertise de domaine qui permet d’appliquer l’IA à des problèmes concrets. L’erreur la plus fréquente est de se concentrer uniquement sur l’aspect technique en négligeant la dimension éthique et la compréhension du domaine d’application. Un expert en IA qui ne comprend pas les implications de ses systèmes n’est pas un expert complet.
Exemple 84 (Compétences clés pour l’expertise IA)
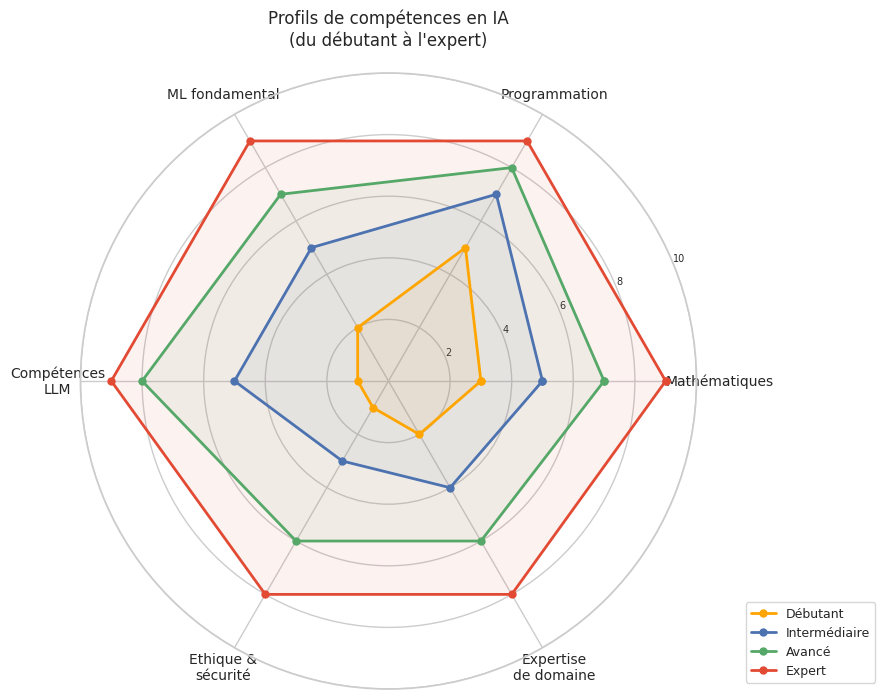
Les six axes de compétence de l’expert IA :
Mathématiques : algèbre linéaire, probabilités, optimisation, théorie de l’information. Ce sont les fondements sans lesquels on ne peut pas comprendre pourquoi les choses fonctionnent.
Programmation : Python, librairies ML (PyTorch, JAX), outils de déploiement (Docker, FastAPI), gestion de versions (git). La capacité à implémenter et expérimenter est essentielle.
ML fondamental : apprentissage supervisé/non supervisé, réseaux de neurones, Transformers, techniques d’optimisation (Adam, learning rate scheduling). Les bases du volume Apprentissage automatique.
Compétences LLM : prompt engineering, RAG, agents, fine-tuning, évaluation, alignement. Le contenu de ce livre.
Ethique et sécurité : biais, red-teaming, alignement, déploiement responsable, gouvernance. Les chapitres 16 à 19 de ce livre.
Expertise de domaine : compréhension du domaine d’application (santé, finance, droit, education, ingénierie) pour identifier les vrais problèmes et évaluer les solutions.
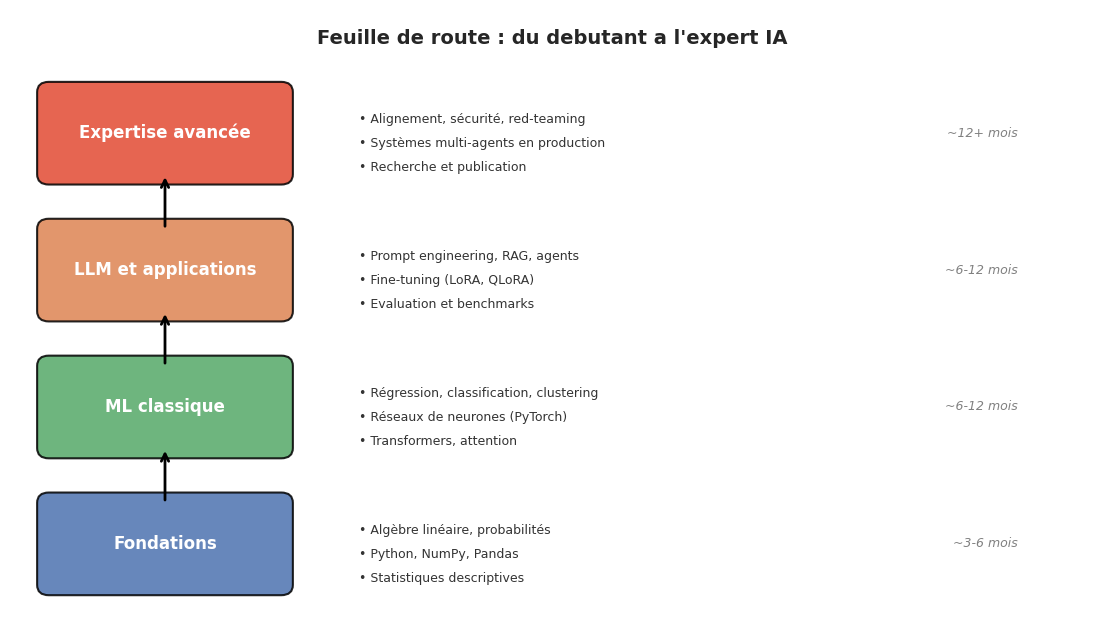
Débutant -> ML fondamental + Python
Intermédiaire -> LLM specifique + RAG + agents
Avancé -> Fine-tuning + éthique + domaine
Expert -> Recherche + publication + systèmes en production
Résumé#
Ce chapitre final a exploré les frontières de l’IA et ses perspectives d’avenir. Mais il est aussi l’occasion de prendre du recul sur l’ensemble du livre, depuis le chapitre 1 jusqu’ici. Retenons les points essentiels de ce chapitre, puis refermons le livre par une vue d’ensemble.
Les agents autonomes de longue durée (Devin, Claude Code, agents de recherche) représentent une frontière majeure. Le défi principal est l’accumulation d’erreurs : même avec 97% de fiabilité par étape, un agent de 100 étapes échoue 95 fois sur 100 sans mécanismes de correction. Les stratégies de vérification et de replannification sont essentielles.
Le scaling de l’inférence (test-time compute), popularisé par OpenAI o1/o3, ouvre un nouveau paradigme : au lieu d’entrainer un modèle plus gros, on le fait « réfléchir plus longtemps ». La performance suit une loi de scaling en \(P \propto C_{\text{test}}^{\alpha}\), avec des gains particulièrement marqués sur les tâches de raisonnement.
Les modèles à espace d’états (Mamba, S4, RWKV) offrent une complexité en \(O(T)\) contre \(O(T^2)\) pour les Transformers. Les architectures hybrides (Jamba) combinent les avantages des deux paradigmes. Le Transformer ne sera probablement pas « remplacé » mais complément par ces nouvelles architectures.
Le débat sur l”AGI révèle des désaccords profonds sur les définitions, les timelines et les voies d’accès. L’IA actuelle excelle sur les connaissances et le langage, mais reste faible sur la planification à long terme, le sens commun physique et l’apprentissage autonome.
Les implications sociétales de l’IA sont massives : transformation de l’emploi (15-30% des heures de travail potentiellement automatisées), bouleversement de l’education, questionnements dans les industries créatives, et concentration du pouvoir technologique entre quelques acteurs.
Devenir expert en IA nécessite six axes de compétence : mathématiques, programmation, ML fondamental, compétences LLM spécifiques, éthique et sécurité, expertise de domaine. La feuille de route va des fondations (algèbre linéaire, Python) à l’expertise avancée (recherche, systèmes en production).
Ce livre a parcouru un chemin ambitieux : du Transformer et de ses mécanismes d’attention (chapitre 1) à la tokenisation (chapitre 2), l’inférence (chapitre 3), les API (chapitre 4), le prompt engineering (chapitre 5), le raisonnement (chapitres 6-7), l’évaluation (chapitre 8), la mémoire (chapitre 9), le RAG (chapitres 10-11), les agents (chapitres 12-15), l’alignement et la sécurité (chapitres 16-19), le fine-tuning (chapitre 20), la multimodalite (chapitre 21), et enfin ces perspectives (chapitre 22). Le fil conducteur est qu’un LLM n’est pas un simple générateur de texte : c’est un composant central autour duquel on construit des systèmes — systèmes de raisonnement, de mémoire, d’action, d’alignement. Comprendre ces systèmes, les construire et les déployer de manière responsable : c’est le défi, et le privilège, de la génération actuelle de praticiens de l’IA.
Remarque 126
Ce livre s’achève, mais le domaine qu’il décrit évolue à une vitesse sans précédent. Certains des modèles, benchmarks et architectures cités dans ces pages seront probablement dépassés au moment où vous les lirez. C’est normal, et c’est même souhaitable : cela signifie que le domaine progresse. Ce qui ne change pas, ce sont les fondements — l’algèbre linéaire derrière l’attention, la théorie de l’information derrière la tokenisation, les principes d’alignement, la rigueur de l’évaluation. Ces fondements, que nous avons tenté de présenter avec soin, resteront pertinents bien après que les modèles spécifiques auront été remplacés. C’est sur eux qu’il faut construire.