Chain-of-Thought et raisonnement linéaire#
Les grands modèles de langage sont capables de performances remarquables sur de nombreuses tâches linguistiques, mais ils échouent souvent dès qu’un raisonnement en plusieurs étapes est requis. Demander à un LLM de résoudre un problème arithmétique, de suivre une chaine logique ou de planifier une séquence d’actions révèle une fragilité fondamentale : le modèle produit une réponse en un seul passage (forward pass), sans mécanisme explicite de réflexion intermédiaire. Cette limitation a motivé une série de travaux fondateurs sur le prompting structure, dont le Chain-of-Thought (CoT) est la pierre angulaire.
Le Chain-of-Thought prompting, introduit par Wei et al. en 2022, repose sur une idée simple mais puissante : au lieu de demander directement la réponse, on incite le modèle à expliciter ses étapes de raisonnement. Cette technique, déclinée en variantes zero-shot, few-shot et auto-consistante, a transformé la façon dont on utilise les LLM pour des tâches complexes. Elle constitue le point de départ d’une famille de méthodes de raisonnement que nous explorerons dans les chapitres suivants.
Ce chapitre présente le problème du raisonnement dans les LLM, formalise le Chain-of-Thought prompting et ses variantes (zero-shot CoT, self-consistency), explore les mécanismes de vérification et d’auto-critique, et discute les limites du raisonnement linéaire. Toutes les illustrations reposent sur des données simulées, sans chargement de modèle.
Le problème du raisonnement dans les LLM#
Un LLM génère du texte token par token, chaque prédiction étant conditionnée par le contexte précédent. Ce processus autoregressif est remarquablement efficace pour la complétion de texte, la traduction ou le résumé, mais il n’inclut aucun mécanisme explicite de raisonnement délibéré. La réponse est produite en un unique passage à travers le réseau, sans possibilité de « revenir en arrière » ou de « réfléchir plus longtemps ».
Remarque 32
Les modes d’échec typiques des LLM face au raisonnement multi-étapes sont les suivants :
Réponse directe incorrecte : le modèle saute directement à une réponse plausible mais fausse, sans décomposer le problème.
Erreur de propagation : une erreur dans une étape intermédiaire invalide tout le raisonnement subséquent.
Raccourci heuristique : le modèle utilise des corrélations superficielles (mots-clés, format) plutôt qu’un raisonnement authentique.
Incohérence logique : les étapes semblent raisonnables individuellement mais sont logiquement incompatibles entre elles.
Ces échecs sont particulièrement visibles sur les tâches arithmétiques, le raisonnement par contraintes et les problèmes de logique formelle.
Considérons un exemple concret. Face à la question « Roger a 5 balles de tennis. Il achète 2 boites de 3 balles. Combien de balles a-t-il maintenant ? », un LLM sans guidage peut repondre directement « 11 » (correct) ou « 10 » (incorrect, en oubliant les balles initiales). La difficulté augmente exponentiellement avec le nombre d’étapes.
Définition 30 (Trace de raisonnement)
Une trace de raisonnement (reasoning trace) est une séquence d’énoncés intermédiaires \((r_1, r_2, \ldots, r_k)\) qui relient une question \(q\) à une réponse \(a\). Chaque énoncé \(r_i\) constitue une étape logique qui s’appuie sur les informations de \(q\) et des étapes précédentes \((r_1, \ldots, r_{i-1})\). Formellement, on écrit :
La qualité d’une trace de raisonnement dépend de sa cohérence (chaque étape découle logiquement de la précédente), de sa complétude (aucune étape cruciale n’est omise) et de sa fidélité (la trace reflète le processus réel qui a conduit à la réponse).
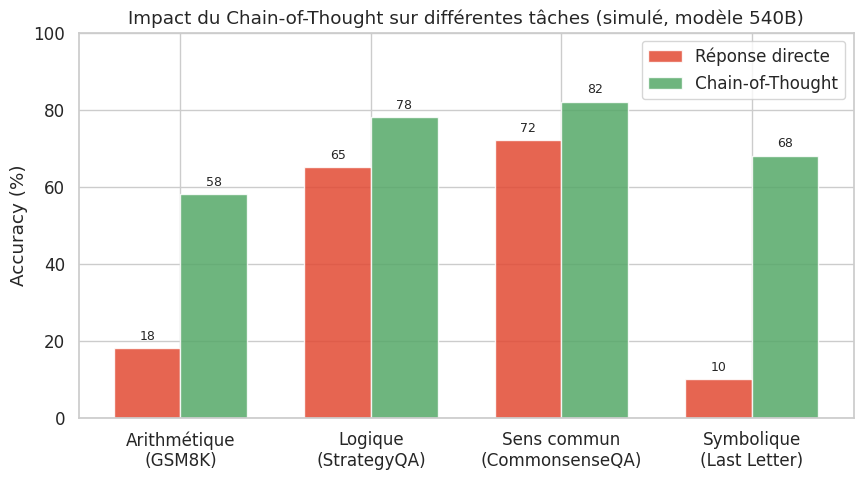
L’écart de performance est frappant : sur les tâches arithmétiques, le gain dépasse 40 points de pourcentage. Ce résultat empirique motive l’étude formelle du Chain-of-Thought.
Chain-of-Thought prompting#
Le Chain-of-Thought prompting (Wei et al., 2022) est une technique de prompting few-shot dans laquelle les exemples fournis au modèle incluent non seulement la question et la réponse, mais aussi les étapes de raisonnement intermédiaires. Le modèle apprend par analogie à reproduire ce schéma de raisonnement explicite.
Définition 31 (Chain-of-Thought prompting)
Le Chain-of-Thought (CoT) prompting consiste à fournir au modèle des exemples de la forme \((q_i, r_i, a_i)\) ou \(q_i\) est une question, \(r_i\) une trace de raisonnement et \(a_i\) la réponse finale. En voyant ces démonstrations, le modèle est incité à générer sa propre trace de raisonnement avant de produire la réponse. Le prompt prend la forme :
Le modèle produit alors \((\hat{r}_{\text{test}}, \hat{a}_{\text{test}})\), c’est-à-dire une trace de raisonnement suivie de la réponse.
Exemple 23 (CoT sur un problème arithmétique (style GSM8K))
Voici un prompt CoT few-shot typique. L’exemple de démonstration guide le modèle à décomposer le raisonnement :
Question : Un magasin vend des cahiers à 3 euros pièce. Marie achète
4 cahiers et paie avec un billet de 20 euros. Combien lui rend-on ?
Raisonnement : Marie achète 4 cahiers à 3 euros piece.
Le coût total est 4 x 3 = 12 euros.
Elle paie avec 20 euros.
On lui rend 20 - 12 = 8 euros.
Réponse : 8 euros.
---
Question : Roger a 5 balles de tennis. Il achète 2 boites de 3 balles
chacune. Combien de balles a-t-il maintenant ?
Raisonnement :
Le modele complete alors :
Roger a initialement 5 balles.
Il achète 2 boites de 3 balles, soit 2 x 3 = 6 balles supplémentaires.
Au total, il a 5 + 6 = 11 balles.
Réponse : 11 balles.
Remarque 33
Le Chain-of-Thought est un phénomène émergent : il n’apparait qu’à partir d’une certaine taille de modèle. Les expériences de Wei et al. montrent que les modèles de moins de ~10 milliards de paramètres ne beneficient pas significativement du CoT, et produisent souvent des traces de raisonnement incohérentes. Ce seuil d’émergence suggère que le CoT exploite des capacités de raisonnement qui ne se développent que dans les grands modèles, probablement liées à la quantité de texte structure (démonstrations mathématiques, tutoriels, solutions pas-a-pas) présent dans les données d’entrainement.
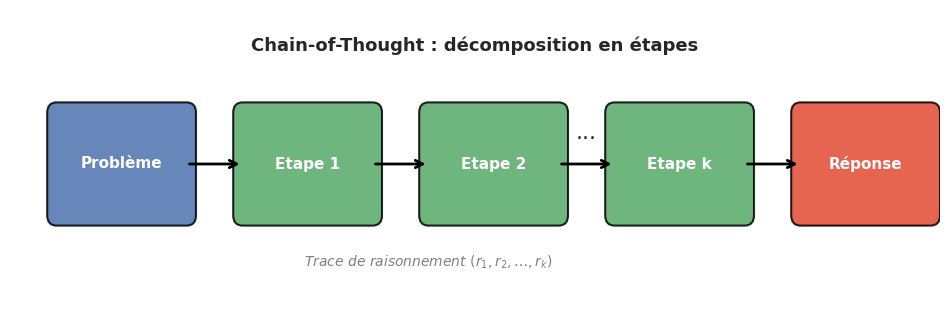
Le succès du CoT repose sur deux mécanismes complémentaires. D’abord, les étapes intermédiaires fournissent un échafaudage computationnel : chaque étape réduit la complexité du sous-problème restant. Ensuite, la trace de raisonnement reste dans le contexte du modèle, ce qui permet aux étapes suivantes de s’appuyer sur les resultats intermédiaires calculés précédemment.
Zero-shot Chain-of-Thought#
Si le CoT few-shot nécessite de concevoir des exemples de raisonnement pour chaque tâche, une approche plus simple existe : le zero-shot CoT (Kojima et al., 2022). Il suffit d’ajouter une instruction comme « Pensons étape par étape » à la fin du prompt, sans aucun exemple de démonstration.
Définition 32 (Zero-shot Chain-of-Thought)
Le zero-shot Chain-of-Thought consiste à ajouter une instruction générique de raisonnement au prompt, sans fournir d’exemple :
Le modele génère alors spontanément une trace de raisonnement avant de fournir sa réponse. Les formulations courantes incluent :
« Let’s think step by step » / « Pensons étape par étape »
« Let’s work this out in a step by step way to be sure we have the right answer »
« Let’s break this down »
Le zero-shot CoT est un cas particulier remarquable car il montre que les capacités de raisonnement sont latentes dans le modèle et peuvent être activées par une simple instruction, sans démonstration explicite.
Exemple 24 (Démonstration du zero-shot CoT)
Sans CoT :
Question : Si un train roule à 120 km/h et doit parcourir 450 km,
combien de temps met-il ?
Réponse : 4 heures.
Avec zero-shot CoT :
Question : Si un train roule a 120 km/h et doit parcourir 450 km,
combien de temps met-il ? Pensons etape par etape.
Le train roule a 120 km/h.
La distance a parcourir est de 450 km.
Le temps = distance / vitesse = 450 / 120 = 3.75 heures.
Convertissons : 0.75 heure = 45 minutes.
Le train met donc 3 heures et 45 minutes.
Réponse : 3 heures et 45 minutes.
La réponse directe (4 heures) est une approximation incorrecte. Le zero-shot CoT force le modèle à effectuer le calcul explicitement, ce qui produit la réponse exacte.
Remarque 34
Il est important de distinguer raisonnement et planification. Le Chain-of-Thought est une forme de raisonnement linéaire : chaque étape découle séquentiellement de la précédente. La planification, en revanche, implique d’anticiper plusieurs étapes à l’avance, d’évaluer différentes branches et de choisir une stratégie globale. Un LLM avec CoT peut résoudre « 2 + 3 = 5, puis 5 x 4 = 20 » (raisonnement linéaire), mais a du mal à choisir entre plusieurs approches pour résoudre un problème complexe (planification). Cette distinction motivera les méthodes de raisonnement arborescent du chapitre suivant.
Self-consistency#
Le Chain-of-Thought, même lorsqu’il améliore les performances, reste stochastique : un même prompt peut produire différentes traces de raisonnement selon l’échantillonnage. Certaines traces sont correctes, d’autres non. La self-consistency (Wang et al., 2022) exploite cette variabilité en échantillonnant plusieurs traces et en sélectionnant la réponse majoritaire.
Définition 33 (Self-consistency (auto-cohérence))
La self-consistency est une stratégie de décodage qui :
Echantillonne \(N\) traces de raisonnement indépendantes \((r_1, a_1), (r_2, a_2), \ldots, (r_N, a_N)\) à partir du même prompt, en utilisant un échantillonnage stochastique (température \(T > 0\)).
Extrait la réponse finale \(a_i\) de chaque trace.
Selectionne la réponse par vote majoritaire :
L’intuition est que les chemins de raisonnement corrects convergent vers la bonne réponse, tandis que les erreurs sont dispersées de manière aléatoire. Le vote majoritaire filtre donc les erreurs stochastiques.
Propriété 7 (Effet du nombre de chemins sur la precision)
Soit \(p\) la probabilité qu’un chemin de raisonnement individuel produise la bonne réponse, avec \(p > 0.5\). Avec \(N\) chemins indépendants et un vote majoritaire, la probabilité de réponse correcte est :
Par le théorème central limite, lorsque \(N \to \infty\), cette probabilité tend vers 1 des que \(p > 0.5\). En pratique, \(N\) entre 5 et 40 suffit pour obtenir un gain significatif. Le coût est linéaire en \(N\) (chaque chemin nécessite un appel au modèle), ce qui impose un compromis precision-cout.
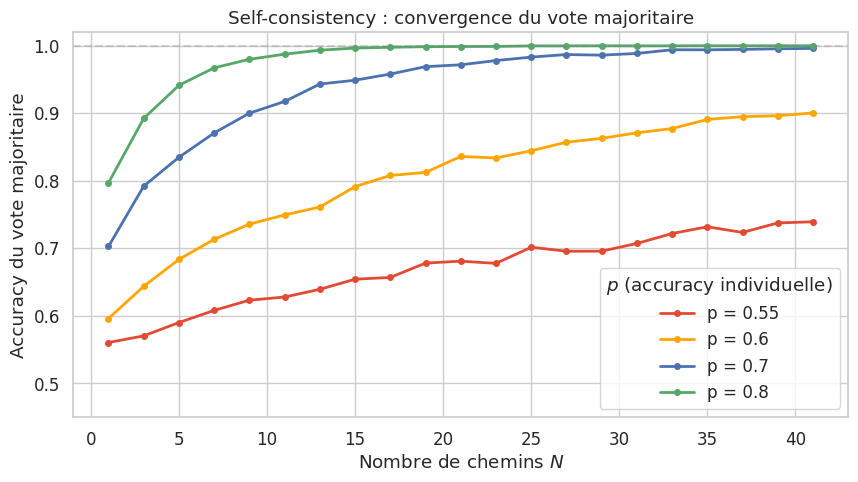
Exemple 25 (Vote majoritaire sur un problème arithmétique)
On echantillonne \(N = 5\) traces de raisonnement pour la question « 23 x 17 = ? » :
Trace 1 : 23 x 17 = 23 x 10 + 23 x 7 = 230 + 161 = 391 -> 391
Trace 2 : 23 x 17 = 20 x 17 + 3 x 17 = 340 + 51 = 391 -> 391
Trace 3 : 23 x 17 = 23 x 20 - 23 x 3 = 460 - 69 = 391 -> 391
Trace 4 : 23 x 17 = 400 - 9 = 389 -> 389 (erreur)
Trace 5 : 23 x 17 ~ 20 x 17 = 340 + 51 = 391 -> 391
Vote : 391 (4 voix) vs 389 (1 voix). Reponse finale : 391. La trace 4 contenait une erreur de calcul, mais le vote majoritaire l’a corrigee.
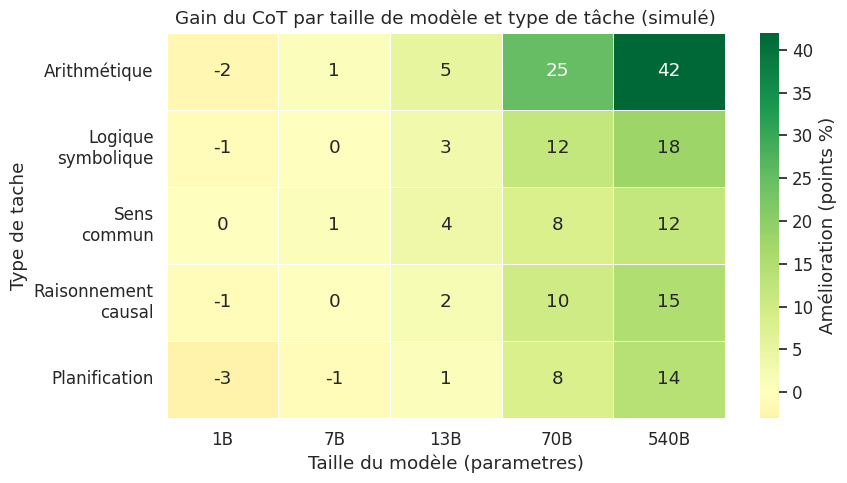
Ce heatmap illustre un résultat cle : le CoT est scale-dependent. Les petits modèles (\(\leq\) 7B) ne bénéficient pas du CoT, et peuvent même voir leurs performances dégradées. Le gain ne devient substantiel qu’au-delà de ~13B paramètres et s’amplifie avec la taille du modèle.
Vérification et auto-critique#
Au-delà du vote majoritaire, une approche complémentaire consiste à demander au modèle de vérifier et critiquer son propre raisonnement. Cette stratégie, parfois appelée self-refinement ou self-verification, crée une boucle itérative ou le modèle revient sur sa trace de raisonnement pour détecter et corriger les erreurs.
Le processus de vérification peut prendre plusieurs formes. La vérification directe consiste à demander au modèle de relire sa trace et de confirmer ou infirmer chaque étape. La vérification par reformulation demande au modèle de résoudre le problème d’une manière différente et de comparer les résultats. La critique structurée fournit un cadre explicite (par exemple : « Vérifie les calculs, la logique, et la cohérence avec l’énoncé ») pour guider l’analyse.
Exemple 26 (Boucle d’auto-vérification)
Etape 1 : génération initiale
Question : Un réservoir contient 200 litres d'eau. On en retire 35%
puis on ajoute 40 litres. Quel est le volume final ?
Raisonnement : 35% de 200 = 70 litres retirés.
200 - 70 = 130 litres restants.
130 + 40 = 170 litres.
Réponse : 170 litres.
Etape 2 : vérification
Vérifions chaque étape du raisonnement précédent :
1. 35% de 200 = 0.35 x 200 = 70 -> Correct.
2. 200 - 70 = 130 -> Correct.
3. 130 + 40 = 170 -> Correct.
Toutes les étapes sont valides.
Réponse confirmée : 170 litres.
Dans cet exemple, la vérification confirme la réponse. Mais dans les cas où une erreur est détectée, l’étape 3 consisterait a regénérer le raisonnement en corrigeant l’erreur identifiée.
Remarque 35
La fidelité (faithfulness) du raisonnement est une question ouverte et cruciale. Lorsqu’un LLM produit une trace de raisonnement, celle-ci reflète-t-elle réellement le processus computationnel interne du modèle, ou s’agit-il d’une rationalisation post-hoc — une explication plausible construite après que la réponse a déjà été « décidée » par le modèle ? Des travaux récents (Turpin et al., 2023 ; Lanham et al., 2023) suggèrent que les traces CoT ne sont pas toujours fidèles : le modèle peut arriver à la bonne réponse par un raccourci interne tout en produisant un raisonnement explicite qui ne correspond pas à son processus réel. L’auto-vérification hérite de cette limitation : si le raisonnement initial est une rationalisation, la vérification porte sur un artefact, pas sur le veritable processus de décision.
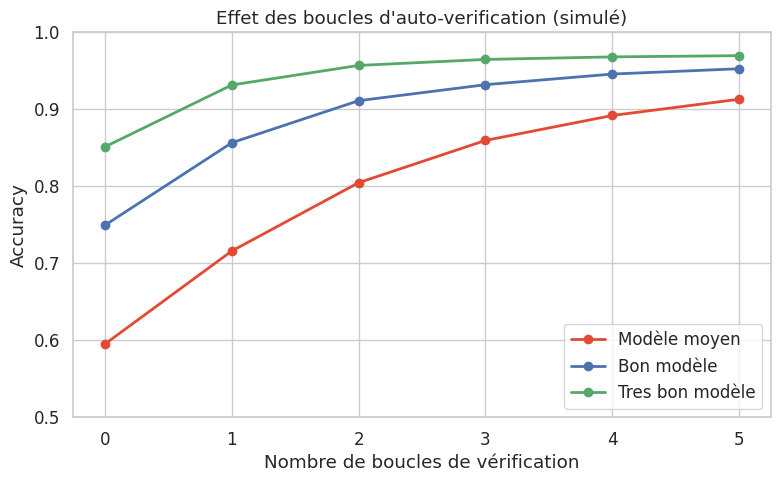
On observe que les boucles de vérification améliorent l’accuracy, mais avec des rendements décroissants. Au-delà de 2 à 3 itérations, le gain devient négligeable, et le risque de dégrader une réponse correcte (en « corrigeant » un raisonnement qui était juste) introduit un léger recul. Ce phénomène est lié au fait que le modèle utilisé pour vérifier est le même que celui qui a produit l’erreur initiale.
Limites du raisonnement linéaire#
Malgré ses succès, le Chain-of-Thought présente des limitations fondamentales qui motivent les approches plus sophistiquées du chapitre suivant.
Infidelité du raisonnement. Comme discuté dans la remarque Remarque 35, les traces CoT ne reflètent pas nécessairement le processus interne du modèle. Le modèle peut produire un raisonnement correct pour de mauvaises raisons (par exemple, en reconnaissant le pattern de la réponse dans ses données d’entrainement), ou un raisonnement incorrect qui aboutit néanmoins à la bonne réponse par compensation d’erreurs.
Propagation d’erreurs. Le raisonnement linéaire est fragile : une erreur dans une étape intermédiaire invalide toutes les étapes suivantes. Contrairement au vote majoritaire (self-consistency), qui opère au niveau des réponses finales, il n’existe pas de mécanisme de correction au sein d’une chaine unique. La probabilité d’obtenir un raisonnement entièrement correct décroit exponentiellement avec le nombre d’étapes \(k\) :
où \(p < 1\) est la probabilité de réussite à chaque étape.
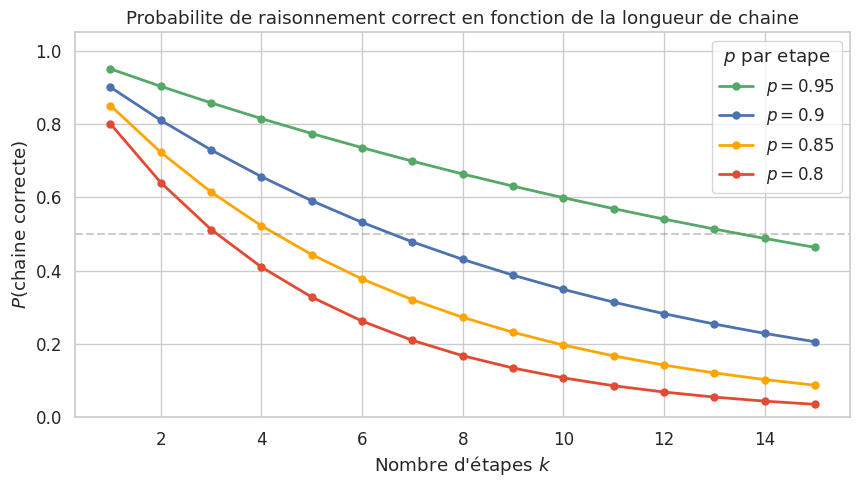
Même avec une précision par étape de 95%, la probabilité de réussite d’une chaine de 15 étapes tombe à \(0.95^{15} \approx 0.46\). Ce résultat souligne la nécessite de mécanismes de correction ou d’exploration, comme les approches arborescentes.
Dépendance à la taille du modèle. Comme illustré par le heatmap précédent, le CoT est un phénomène émergent qui ne bénéficie qu’aux grands modèles. Pour les modèles de taille modeste (\(< 10\text{B}\)), le CoT peut même dégrader les performances en incitant le modèle à produire des étapes incohérentes qui polluent la génération finale.
Remarque 36
Le caractère linéaire du CoT constitue sa limitation la plus fondamentale. Face a un problème qui admet plusieurs approches possibles, le CoT s’engage dans une seule direction et ne peut pas revenir en arrière si cette direction s’avère improductive. La self-consistency atténúe ce problème en explorant plusieurs chemins indépendants, mais chaque chemin reste linéaire. Les méthodes de raisonnement arborescent — Tree-of-Thought (Yao et al., 2023), Graph-of-Thought (Besta et al., 2023) — addressent cette limitation en introduisant une exploration structurée de l’espace des raisonnements, avec des mécanismes de backtracking et d’évaluation intermédiaire. Nous les étudierons au chapitre suivant.
Nombre d'étapes : 3
Etape 1 : Le prix unitaire est de 3 euros.
Etape 2 : Marie achète 4 cahiers, donc le coût total est 4 x 3 = 12 euros.
Etape 3 : Elle paie avec 20 euros, on lui rend 20 - 12 = 8 euros.
Réponse finale : 8 euros.
Résumé#
Ce chapitre a présenté le Chain-of-Thought et ses variantes, qui constituent les fondations du raisonnement dans les LLM. Retenons les points essentiels :
Les LLM échouent sur le raisonnement multi-étapes lorsqu’on leur demande une réponse directe, car le processus autorégressif ne dispose d’aucun mécanisme de réflexion intermédiaire explicite.
Le Chain-of-Thought prompting (Wei et al., 2022) améliore drastiquement les performances en fournissant des exemples de raisonnement étape par étape dans le prompt few-shot. Le modèle apprend à expliciter sa démarche avant de conclure.
Le zero-shot CoT (Kojima et al., 2022) montre qu’une simple instruction — « Pensons étape par étape » — suffit à activer les capacités de raisonnement latentes du modèle, sans aucun exemple.
La self-consistency (Wang et al., 2022) réduit la variance du CoT en échantillonnant \(N\) traces de raisonnement et en sélectionnant la réponse par vote majoritaire. La précision du vote croit avec \(N\) et converge vers 1 dès que la précision individuelle dépasse 50%.
Les boucles d”auto-vérification permettent au modèle de critiquer et corriger son propre raisonnement, avec des gains décroissants au-delà de 2 à 3 itérations.
Le CoT est un phénomène émergent qui ne bénéficie qu’aux grands modèles (\(\gtrsim 10\text{B}\) parametres). Il est de plus linéaire (pas de backtracking), fragile (propagation d’erreurs exponentielle) et potentiellement infidèle (rationalisation post-hoc).
Ces limitations motivent les approches de raisonnement arborescent (Tree-of-Thought, Graph-of-Thought) et de raisonnement avec outils que nous étudierons dans le chapitre suivant.