Agents LLM#
Ce chapitre ouvre la Partie IV de cet ouvrage, consacrée aux agents et systèmes multi-agents. Jusqu’ici, nous avons utilisé les LLM comme des systèmes réactifs : un prompt entre, une réponse sort. Les agents LLM franchissent un seuil conceptuel majeur en transformant le modèle de langage en moteur de raisonnement au sein d’une boucle autonome capable de percevoir son environnement, de prendre des décisions et d’agir sur le monde extérieur.
L’idée d’agent autonome n’est pas nouvelle — elle traverse l’intelligence artificielle depuis ses origines, des agents rationnels de Russell et Norvig aux systèmes multi-agents de Wooldridge. Ce qui change avec les LLM, c’est la généralité du raisonnement : un seul modèle peut comprendre des instructions en langage naturel, décomposer un problème complexe en sous-tâches, sélectionner des outils appropriés et synthétiser les résultats, le tout sans programmation explicite de chaque cas.
Ce chapitre pose les fondements : nous définirons rigoureusement ce qu’est un agent LLM, formaliserons sa boucle de fonctionnement, introduirons les mécanismes de tool use, de planification et de mémoire, puis construirons un agent complet en Python. Les chapitres suivants aborderont les frameworks existants, les architectures multi-agents et les applications pratiques.
Qu’est-ce qu’un agent LLM ?#
Un agent LLM est un système qui utilise un grand modèle de langage comme noyau décisionnel pour accomplir des tâches de manière autonome. Contrairement à un simple appel de modèle, l’agent interagit avec son environnement en boucle : il observe, raisonne, agit, puis observe le résultat de son action pour décider de la suite.
Définition 63 (Agent LLM)
Un agent LLM est un système \(\mathcal{A} = (\mathcal{M}, \mathcal{T}, \mathcal{E}, \pi)\) où :
\(\mathcal{M}\) est un grand modèle de langage servant de moteur de raisonnement,
\(\mathcal{T} = \{t_1, \ldots, t_n\}\) est un ensemble d”outils (fonctions exécutables),
\(\mathcal{E}\) est un environnement avec lequel l’agent interagit,
\(\pi : \mathcal{O}^* \to \mathcal{T} \cup \{\texttt{stop}\}\) est une politique dérivée de \(\mathcal{M}\) qui, étant donnée l’historique des observations \(o_1, \ldots, o_k \in \mathcal{O}^*\), sélectionne le prochain outil à invoquer ou décide de terminer.
L’agent opère en boucle jusqu’à ce que la politique émette \(\texttt{stop}\) ou qu’une condition d’arrêt externe soit atteinte.
La distinction clé avec une chaîne (chain) ou un pipeline est le caractère dynamique de la prise de décision. Dans un pipeline, la séquence d’étapes est fixée à l’avance par le développeur. Dans un agent, c’est le LLM lui-même qui décide, à chaque itération, quelle action entreprendre.
Remarque 70 (Agent vs chaîne)
La distinction entre un agent et une chaîne repose sur la source du contrôle de flux :
Chaîne/Pipeline : le développeur encode la séquence \(t_1 \to t_2 \to \cdots \to t_n\). Le LLM exécute chaque étape mais ne choisit pas l’ordre.
Agent : le LLM décide dynamiquement à chaque pas quelle action entreprendre. La séquence n’est pas prédéterminée.
# Pipeline : séquence fixe
resultat = traduire(resumer(extraire(document)))
# Agent : décision dynamique à chaque étape
while not terminé:
action = llm.decider(observations)
resultat = executer(action)
observations.append(resultat)
En pratique, il existe un spectre entre ces deux extrêmes : certaines architectures (comme les routers) offrent un contrôle de flux partiel au LLM.
Remarque 71 (Spectre d’autonomie)
Les systèmes basés sur les LLM s’étalent sur un spectre d’autonomie croissante :
Appel unique : un prompt, une réponse (zéro autonomie).
Chaîne : séquence fixe d’appels (autonomie nulle, composition fixe).
Routeur : le LLM choisit parmi un ensemble fini de branches (autonomie limitée).
Agent réactif : boucle perception-action, le LLM décide à chaque pas (autonomie modérée).
Agent planificateur : l’agent décompose un objectif en sous-tâches avant d’agir (autonomie élevée).
Système multi-agents : plusieurs agents collaborent ou se coordonnent (autonomie distribuée).
Plus l’autonomie augmente, plus les capacités croissent — mais aussi les risques d’erreur, de boucle infinie ou de comportement inattendu.

La boucle perception-action#
Le fonctionnement d’un agent repose sur une boucle itérative qui alterne raisonnement et interaction avec l’environnement. Cette boucle est l’analogue, pour les agents LLM, de la boucle perception-action des agents classiques en IA.
Définition 64 (Boucle perception-action)
La boucle perception-action d’un agent LLM se décompose en quatre phases répétées :
Percevoir : l’agent reçoit une observation \(o_t\) de l’environnement (résultat de l’action précédente, ou requête initiale de l’utilisateur).
Raisonner (think) : le LLM analyse l’historique \((o_1, a_1, \ldots, o_t)\) et produit un raisonnement interne \(r_t\) (souvent en chain-of-thought).
Agir (act) : le LLM sélectionne une action \(a_t \in \mathcal{T} \cup \{\texttt{stop}\}\) sur la base de \(r_t\).
Observer : l’environnement exécute \(a_t\) et renvoie \(o_{t+1}\).
L’agent s’arrête lorsque \(a_t = \texttt{stop}\) ou après un nombre maximal d’itérations \(T_{\max}\).
Ce cycle reprend le paradigme classique des agents rationnels tel que formalisé par Russell et Norvig. La différence fondamentale est que le raisonnement est effectué par un LLM en langage naturel plutôt que par un algorithme de recherche symbolique ou une politique apprise par renforcement.
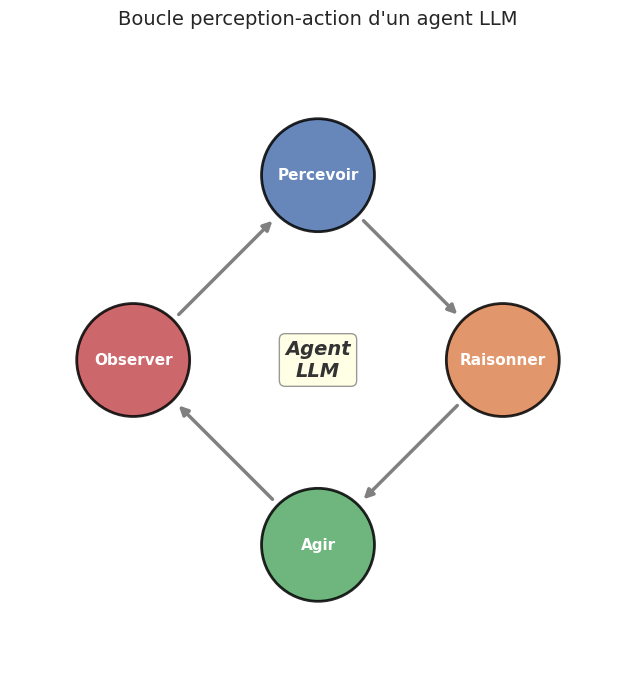
Le paradigme ReAct (Yao et al., 2023) formalise cette boucle en alternant explicitement des étapes de Reasoning (pensée) et d”Action dans le prompt du modèle. Chaque itération produit une trace de la forme : Thought (raisonnement en langage naturel), Action (outil à invoquer avec ses paramètres), Observation (résultat retourné par l’outil). Cette structuration améliore la traçabilité et la fiabilité de l’agent.
Tool use et function calling#
Les outils (tools) sont le mécanisme par lequel un agent LLM interagit avec le monde extérieur. Un outil est une fonction que l’agent peut invoquer pour obtenir de l’information ou produire un effet. Le tool use (ou function calling) est la capacité du LLM à identifier qu’un outil est nécessaire, à sélectionner le bon outil et à formuler correctement ses arguments.
Définition 65 (Définition d’outil)
Un outil (tool) pour un agent LLM est un triplet \(t = (\texttt{name}, \texttt{desc}, f)\) où :
\(\texttt{name} \in \Sigma^*\) est un identifiant unique,
\(\texttt{desc} \in \Sigma^*\) est une description en langage naturel de la fonctionnalité (utilisée par le LLM pour décider quand invoquer l’outil),
\(f : \mathcal{P} \to \mathcal{R}\) est une fonction exécutable qui, étant donné des paramètres \(p \in \mathcal{P}\) (typiquement décrits par un schéma JSON), renvoie un résultat \(r \in \mathcal{R}\).
La spécification de l’outil comprend en outre un schéma JSON décrivant les paramètres attendus, leurs types et contraintes.
Exemple 47 (Schéma JSON d’un outil)
Un outil de recherche web pourrait être spécifié ainsi :
{
"name": "web_search",
"description": "Recherche des informations sur le web. Utile pour trouver des faits récents, des données actualisées ou des informations que le modèle ne connaît pas.",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "La requête de recherche"
},
"num_results": {
"type": "integer",
"description": "Nombre de résultats à retourner",
"default": 5
}
},
"required": ["query"]
}
}
Le LLM reçoit cette spécification dans son contexte et génère un appel structuré lorsqu’il juge l’outil pertinent.
=== Test des outils ===
Résultat : 117.5
Météo Paris : 8°C, couvert, vent 15 km/h
Prix moyen : 0.2516 €/kWh en 2025 (tarif réglementé).
Exemple 48 (Agent calculatrice)
Un agent calculatrice illustre le mécanisme de base du tool use. L’utilisateur pose une question en langage naturel ; l’agent identifie qu’un calcul est nécessaire, formule l’expression, invoque l’outil et intègre le résultat dans sa réponse :
Utilisateur : Combien coûte le chauffage d'un appartement de 50 m²
pendant 30 jours à 0.25 €/kWh si la consommation est
de 120 kWh/mois ?
Agent (think): Je dois calculer 120 * 0.25 pour obtenir le coût mensuel.
Agent (act) : calculatrice(expression="120 * 0.25")
Observation : Résultat : 30.0
Agent (think): Le coût est de 30 €. Je peux répondre.
Agent (act) : stop
Réponse : Le chauffage coûte 30,00 € par mois.
Remarque 72 (Ancrage et fiabilité)
Le tool use joue un rôle d”ancrage (grounding) : en permettant à l’agent d’accéder à des sources de données externes (calculatrice, bases de données, API), on réduit les hallucinations et on augmente la fiabilité factuelle. Un agent bien conçu préfère invoquer un outil plutôt que de « deviner » un fait ou un calcul.
Cet ancrage est particulièrement important pour :
Les données numériques : les LLM font fréquemment des erreurs de calcul.
Les informations temporelles : les connaissances du modèle ont une date de coupure.
Les faits vérifiables : noms, dates, statistiques.
Planification et décomposition de tâches#
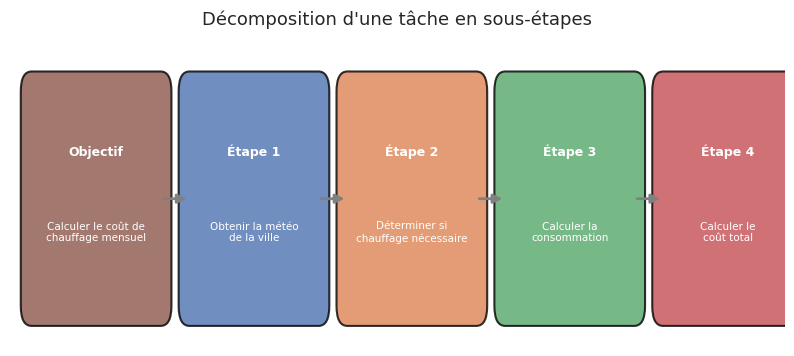
Face à une tâche complexe, un agent efficace ne se lance pas directement dans l’exécution : il planifie. La planification consiste à décomposer un objectif de haut niveau en sous-tâches séquentielles ou parallèles, puis à les exécuter méthodiquement.
Définition 66 (Décomposition de tâches)
La décomposition de tâches (task decomposition) est le processus par lequel un agent transforme un objectif \(G\) en une séquence ordonnée de sous-objectifs \((g_1, g_2, \ldots, g_m)\) tels que :
Chaque \(g_i\) est réalisable par un ou quelques appels d’outils.
Les dépendances entre sous-objectifs sont respectées : si \(g_j\) dépend du résultat de \(g_i\), alors \(i < j\).
L’achèvement de tous les sous-objectifs implique l’achèvement de \(G\).
La décomposition peut être statique (planification complète avant exécution) ou dynamique (re-planification après chaque étape).
Deux grandes stratégies de planification se distinguent :
Planification descendante (top-down). L’agent commence par formuler un plan global, puis le raffine en sous-étapes de plus en plus concrètes. Cette approche est souvent réalisée par un prompt dédié demandant au LLM de « lister les étapes nécessaires avant de commencer ».
Raffinement itératif. L’agent exécute une première étape, observe le résultat, puis décide de l’étape suivante. Le plan émerge pas à pas. Cette approche est plus robuste face à l’incertitude mais peut manquer de cohérence globale.
Exemple 49 (Prompt de planification)
Un prompt typique pour la planification descendante :
Tu es un assistant qui décompose les tâches complexes en étapes.
Objectif : Analyser les ventes du trimestre et préparer un rapport.
Décompose cet objectif en sous-tâches numérotées, en précisant
pour chaque sous-tâche quel outil utiliser :
1. [recherche_db] Extraire les données de ventes Q4
2. [calculatrice] Calculer les totaux par catégorie
3. [calculatrice] Calculer les variations vs Q3
4. [generateur_graphiques] Créer les visualisations
5. [redaction] Rédiger le résumé exécutif
Cette décomposition explicite permet à l’agent de suivre un plan structuré et de vérifier l’achèvement de chaque étape.
Remarque 73 (Récupération d’erreur)
Un agent robuste doit gérer les erreurs lors de l’exécution. Lorsqu’un outil échoue ou retourne un résultat inattendu, l’agent peut :
Réessayer avec des paramètres corrigés.
Choisir un outil alternatif (par exemple, passer de la recherche web à la base de données locale).
Re-planifier en adaptant le plan restant.
Escalader en demandant une clarification à l’utilisateur.
La gestion d’erreur est un marqueur essentiel de la maturité d’un système d’agents : un agent naïf s’arrête au premier échec, tandis qu’un agent robuste adapte sa stratégie.
Mémoire de l’agent#
Un agent efficace ne se limite pas au contexte immédiat : il exploite différentes formes de mémoire pour maintenir la cohérence à travers ses étapes d’exécution et, potentiellement, entre sessions.
Définition 67 (Mémoire de l’agent)
La mémoire d’un agent LLM se décline en trois types, par analogie avec la psychologie cognitive :
Mémoire de travail (working memory) : le contexte courant du LLM, incluant le prompt système, l’historique de la conversation et les observations récentes. Elle est limitée par la fenêtre de contexte du modèle.
Mémoire épisodique (episodic memory) : le stockage des expériences passées sous forme de paires (situation, action, résultat). Permet à l’agent de ne pas répéter les mêmes erreurs et d’exploiter des solutions déjà trouvées.
Mémoire sémantique (semantic memory) : une base de connaissances persistante (souvent implémentée via un système RAG) dans laquelle l’agent peut chercher des faits, des procédures ou des documents.
En pratique, la mémoire de travail est implémentée par le contexte de la conversation (la suite de messages). La mémoire épisodique peut être un simple journal (log) des actions passées, stocké dans un fichier ou une base de données. La mémoire sémantique correspond au mécanisme de RAG étudié aux chapitres 10 et 11.
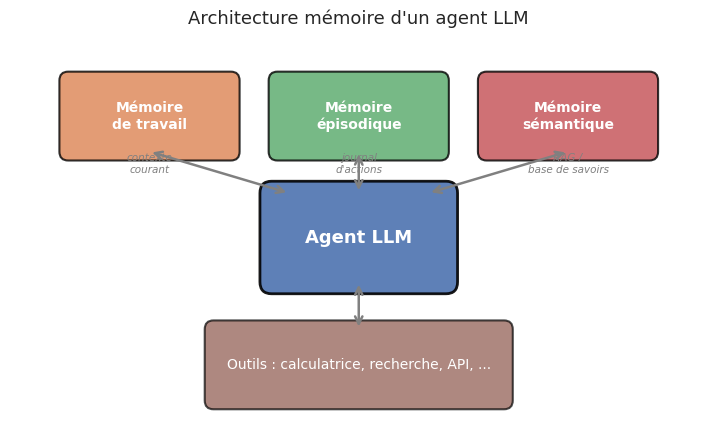
La gestion de la mémoire de travail est un défi central : lorsque l’historique dépasse la fenêtre de contexte, il faut résumer ou élaguer les observations anciennes. Différentes stratégies existent : résumé glissant (sliding summary), suppression des observations les moins pertinentes, ou compression via un modèle auxiliaire. Ce problème rejoint directement les techniques de mémoire conversationnelle étudiées au chapitre 9.
Implémentation d’un agent simple#
Nous allons maintenant construire un agent complet en Python. Pour rester indépendant de tout service externe, nous utilisons un LLM simulé (mock) qui retourne des réponses prédéfinies en fonction de mots-clés détectés dans le contexte.
MockLLM initialisé.
Question : Quelle est la météo à Paris ? Si c'est froid (< 15°C), calcule le coût de chauffage mensuel.
============================================================
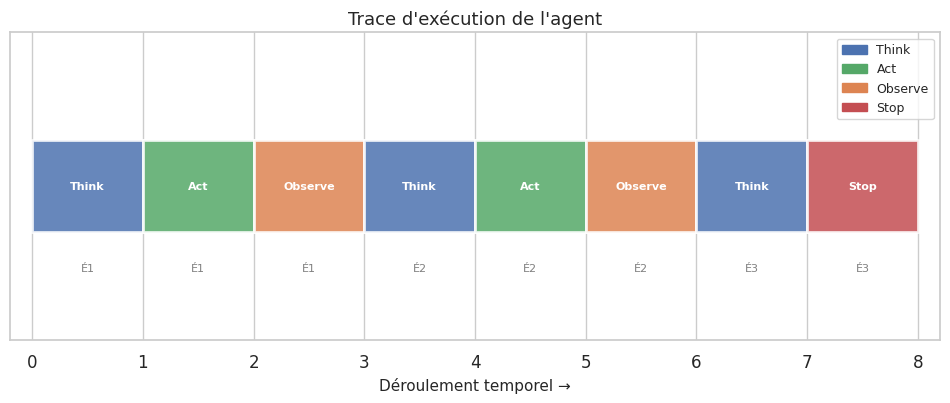
=== Trace d'exécution ===
Étape 1 [THINK ] : L'utilisateur demande la météo. Je dois utiliser l'outil meteo.
Étape 1 [ACT ] : meteo({'ville': 'Paris'})
Étape 1 [OBSERVE] : Météo Paris : 8°C, couvert, vent 15 km/h
Étape 2 [THINK ] : Il fait 8°C, c'est froid. Je dois calculer le coût de chauffage. Consommation estimée : 150 kWh/mois, prix : 0.25 €/kWh.
Étape 2 [ACT ] : calculatrice({'expression': '150 * 0.25'})
Étape 2 [OBSERVE] : Résultat : 37.5
Étape 3 [THINK ] : J'ai toutes les informations. La météo à Paris est 8°C (froid), le chauffage coûterait environ 37.50 €/mois.
Étape 3 [STOP ] : Tâche terminée.
============================================================
Réponse finale : J'ai toutes les informations. La météo à Paris est 8°C (froid), le chauffage coûterait environ 37.50 €/mois.
Propriété 16 (Complexité d’un agent)
La complexité d’un agent LLM peut se caractériser selon plusieurs axes :
Complexité en appels LLM : \(O(T)\) où \(T\) est le nombre d’étapes de la boucle. Chaque étape nécessite au moins un appel au modèle.
Complexité en tokens : croissante à chaque étape car l’historique s’allonge. Au pas \(t\), le contexte contient \(O(t \cdot \bar{L})\) tokens où \(\bar{L}\) est la longueur moyenne d’une observation.
Fiabilité : décroît avec \(T\). Si chaque étape a une probabilité de succès \(p\), la probabilité de succès global est \(p^T\), ce qui décroît exponentiellement.
Il existe donc un compromis fondamental entre la complexité des tâches réalisables (qui requiert plus d’étapes) et la fiabilité (qui diminue avec le nombre d’étapes).
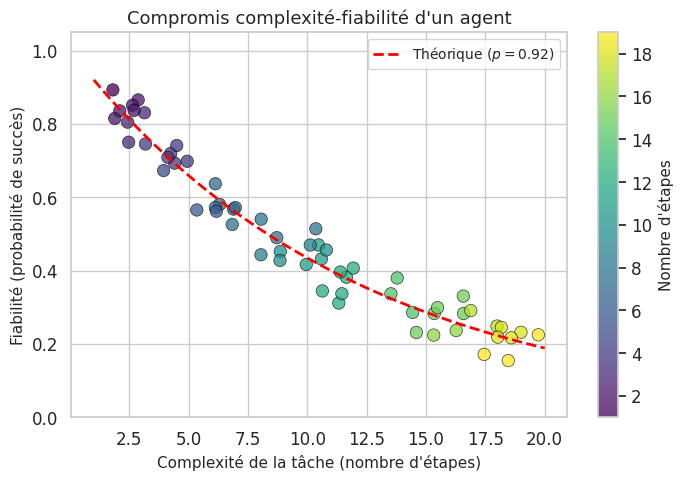
Ce graphique illustre un phénomène bien connu des praticiens : les agents fonctionnent remarquablement bien sur des tâches en 2 à 5 étapes, mais deviennent fragiles au-delà de 10 étapes. C’est pourquoi la décomposition en sous-tâches et la conception d’outils fiables sont des priorités d’ingénierie.
Résumé#
Ce chapitre a posé les fondations de l’architecture agent dans le contexte des grands modèles de langage.
Un agent LLM est un système autonome qui utilise un modèle de langage comme moteur de raisonnement pour percevoir, décider et agir dans une boucle itérative, contrairement aux chaînes dont le flux est prédéterminé.
La boucle perception-action formalise le fonctionnement de l’agent en quatre phases cycliques : percevoir une observation, raisonner via le LLM, sélectionner et exécuter une action, puis observer le résultat. Le paradigme ReAct structure cette boucle explicitement.
Le tool use permet à l’agent d’interagir avec le monde extérieur via des outils (fonctions exécutables), définis par un nom, une description et un schéma de paramètres JSON. Ce mécanisme d’ancrage réduit les hallucinations et étend les capacités du modèle.
La planification transforme un objectif complexe en sous-tâches ordonnées. Les stratégies descendante (plan global puis raffinement) et itérative (étape par étape) offrent des compromis différents entre cohérence et adaptabilité.
La mémoire de l’agent se décline en mémoire de travail (contexte courant), épisodique (journal des actions passées) et sémantique (base de connaissances). La gestion de la fenêtre de contexte est un défi central.
La fiabilité d’un agent décroît exponentiellement avec le nombre d’étapes, ce qui impose un compromis fondamental entre ambition des tâches et robustesse de l’exécution. Des outils fiables, une bonne décomposition et une gestion d’erreurs sont essentiels.
L’implémentation d’un agent repose sur une architecture relativement simple — une classe avec des méthodes
think,actetobserve— mais les défis pratiques (gestion du contexte, robustesse, sécurité) font toute la complexité des systèmes de production, comme nous le verrons dans les chapitres suivants.