RAG avancé et graphes de connaissances#
Le chapitre précédent a introduit le paradigme RAG (Retrieval-Augmented Generation) : enrichir le contexte d’un LLM avec des documents retrouvés dans une base vectorielle. Cette approche de base — encoder les chunks, retrouver les \(k\) plus proches voisins, les injecter dans le prompt — fonctionne remarquablement bien pour des questions simples et des corpus homogènes. Cependant, elle atteint rapidement ses limites face à des requêtes complexes, des corpus volumineux ou des questions nécessitant un raisonnement multi-étapes.
Ce chapitre explore les techniques avancées qui dépassent le RAG naif. Nous étudierons le re-ranking avec des cross-encoders pour améliorer la précision de la récupération, la recherche hybride combinant approches dense et sparse, le Self-RAG qui donne au modèle le contrôle sur le processus de récupération, les graphes de connaissances pour le raisonnement structuré, et enfin l”indexation hiérarchique pour les requêtes complexes.
Ces techniques ne sont pas mutuellement exclusives : les systèmes RAG les plus performants en production combinent plusieurs de ces approches dans des pipelines sophistiqués. L’objectif est de construire une intuition solide sur les forces et faiblesses de chaque méthode, ainsi que sur les contextes où elles apportent un gain réel.
Limites du RAG naive#
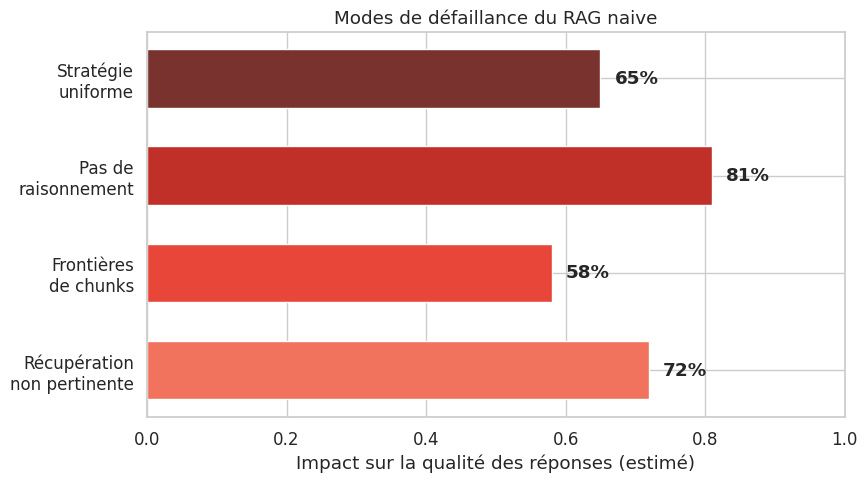
Avant d’introduire des solutions avancées, il est essentiel de comprendre pourquoi le RAG naive échoue. Le premier problème est la récupération non pertinente : la similarité cosinus dans l’espace d’embeddings ne garantit pas la pertinence sémantique. Deux phrases proches vectoriellement peuvent ne pas répondre è la même question.
Le deuxième problème concerne les frontières de chunks. Le découpage en chunks de taille fixé peut séparer des informations qui doivent être lues ensemble — un tableau dont l’en-tête et les données se retrouvent dans des chunks différents devient inutilisable.
Le troisième problème est l”absence de raisonnement sur les documents récupérés. Le RAG naive injecte les chunks sans les analyser ni les croiser. Enfin, la stratégie uniforme applique le même mécanisme de recherche quelle que soit la complexité de la requête : une question factuelle et une question analytique reçoivent le même traitement.
Re-ranking avec cross-encoders#
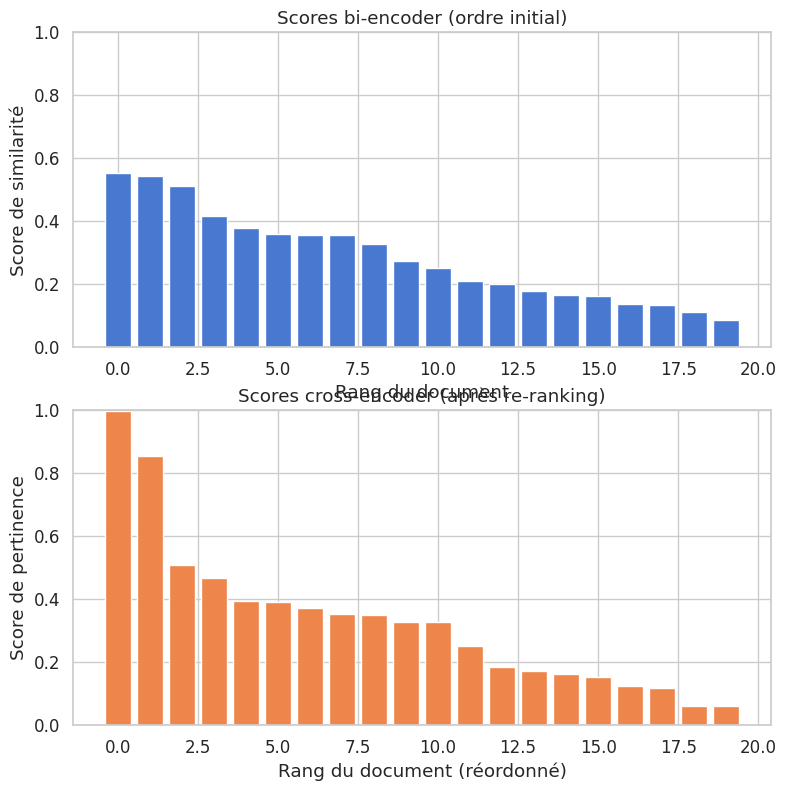
La solution la plus directe au problème de la récupération non pertinente est d’introduire une étape de re-ranking après la récupération initiale. L’idée est simple : utiliser un premier modèle rapide pour récupérer un ensemble large de candidats, puis un second modèle plus précis pour les réordonner.
Définition 57 (Re-ranking)
Le re-ranking (ou reordonnancement) est une étape de post-traitement dans un pipeline de récupération d’information. Etant donné une requête \(q\) et un ensemble de \(N\) documents candidats \(\{d_1, \ldots, d_N\}\) retrouvés par un premier modèle, un modèle de re-ranking attribue un score de pertinence \(s(q, d_i)\) à chaque paire \((q, d_i)\) et réordonne les documents selon ces scores. Seuls les \(k \ll N\) documents les mieux classés sont transmis au LLM.
La distinction clé est entre les bi-encoders et les cross-encoders.
Définition 58 (Cross-encoder)
Un cross-encoder est un modèle qui prend en entrée la concaténation de la requête et du document \([q ; d_i]\) et produit un score de pertinence \(s(q, d_i) \in [0, 1]\). Contrairement au bi-encoder qui encode \(q\) et \(d_i\) indépendamment, le cross-encoder permet une intéraction croisée (cross-attention) entre tous les tokens de \(q\) et de \(d_i\) à chaque couche du Transformer :
où \(\sigma\) est la fonction sigmoide.
Remarque 67 (Bi-encoder vs cross-encoder)
Le bi-encoder encode la requête et chaque document séparément en vecteurs \(\mathbf{e}_q\) et \(\mathbf{e}_d\), puis calcule leur similarité (cosinus, produit scalaire). Il est rapide car les embeddings des documents peuvent être pré-calculés. Le cross-encoder est plus précis car il modélise les intéractions fines entre requête et document, mais il est \(O(N)\) en temps d’inférence. En pratique, on combine les deux :
# Pipeline typique : bi-encoder (recall) + cross-encoder (précision)
# Etape 1 : bi-encoder retrouve top-100 candidats (rapide)
# Etape 2 : cross-encoder re-rank les 100 candidats (précis)
# Etape 3 : top-5 envoyés au LLM
Cette architecture à deux étages est parfois appelée retrieve-and-rerank.
Recherche hybride : dense + sparse#
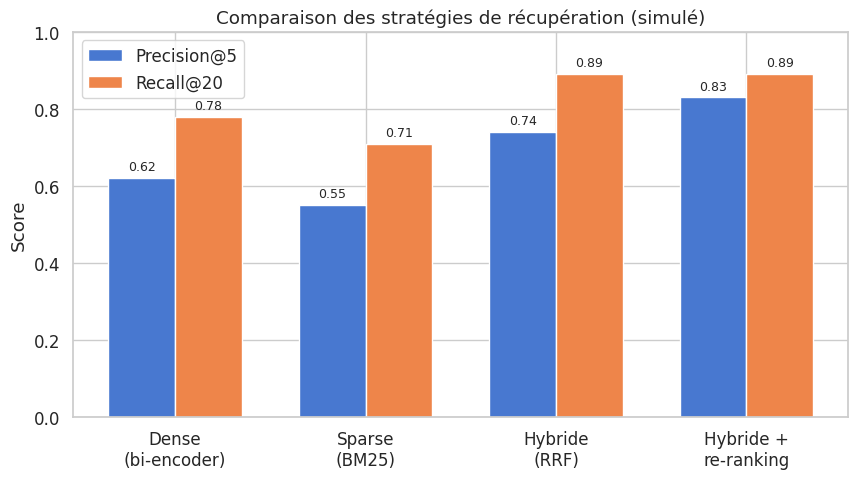
La recherche vectorielle dense excelle pour capturer la similarité sémantique, mais elle peut manquer des correspondances lexicales exactes. Inversement, les méthodes sparse comme BM25 capturent les correspondances de mots-clés mais ignorent la sémantique. La recherche hybride combine les deux.
Définition 59 (BM25)
BM25 (Best Matching 25) est une fonction de pondération issue de la famille TF-IDF. Pour une requête \(q = (t_1, \ldots, t_m)\) et un document \(d\), le score est :
où \(f(t_i, d)\) est la fréquence du terme \(t_i\) dans \(d\), \(|d|\) la longueur du document, \(\text{avgdl}\) la longueur moyenne du corpus, \(k_1 \approx 1{,}5\) et \(b \approx 0{,}75\). Le facteur IDF est :
Définition 60 (Recherche hybride)
La recherche hybride (hybrid search) combine les résultats d’un moteur dense (embeddings vectoriels) et d’un moteur sparse (BM25) pour produire un classement unifié. Les scores des deux systèmes, sur des échelles différentes, ne peuvent pas être additionnés directement. On utilise une méthode de fusion de rangs pour les combiner.
Requête : 'recherche hybride dense sparse'
Top-5 BM25 :
1. [score=6.865] La recherche hybride combine dense et sparse
2. [score=0.970] Le retrieval augmented generation combine recherche et génération
3. [score=0.834] BM25 est une méthode de recherche basée sur les mots clés
4. [score=0.000] Les embeddings vectoriels capturent la sémantique des phrases
5. [score=0.000] Les graphes de connaissances représentent des relations entre entités
La méthode la plus populaire pour combiner les classements est la Reciprocal Rank Fusion (RRF).
Remarque 68 (Reciprocal Rank Fusion)
La Reciprocal Rank Fusion (RRF), proposée par Cormack et al. (2009), est une méthode de fusion qui ne nécessite aucune calibration des scores. Elle repose uniquement sur les rangs des documents dans chaque classement, ce qui la rend robuste aux différences d’échelles. La constante \(k\) (typiquement \(k = 60\)) amortit l’influence des documents très bien classés dans un seul système :
# Plus k est grand, plus les rangs élevés sont attenués
# k = 60 est la valeur standard de la littérature
RRF produit des résultats comparables aux méthodes de fusion apprise (learned fusion) tout en étant beaucoup plus simple à implémenter.
Propriété 15 (Formule RRF)
Soit \(\mathcal{R} = \{r_1, r_2, \ldots, r_R\}\) un ensemble de \(R\) classements et \(\text{rank}_r(d)\) le rang du document \(d\) dans le classement \(r\). Le score RRF du document \(d\) est :
ou \(k\) est une constante (typiquement \(k = 60\)). Le classement final est obtenu en triant les documents par score RRF décroissant. Si un document n’apparait pas dans un classement \(r\), on lui attribue un rang \(\infty\) (contribution nulle).
Dense : [2, 0, 6, 4, 1]
Sparse : [6, 2, 3, 0, 7]
Fusionné (RRF) : [2, 6, 0, 3, 4]
Doc 2 : RRF = 0.03252
Doc 6 : RRF = 0.03227
Doc 0 : RRF = 0.03175
Doc 3 : RRF = 0.03102
Doc 4 : RRF = 0.03078
Exemple 44 (Pipeline de recherche hybride)
Un pipeline de recherche hybride typique suit les étapes suivantes :
Indexation : chaque document est indexé dans un index vectoriel (FAISS, Pinecone) et un index inverse (Elasticsearch, BM25).
Récupération parallèle : les deux systèmes retournent leurs top-\(N\) candidats (\(N \approx 100\)).
Fusion : les classements sont fusionnés via RRF.
Re-ranking (optionnel) : un cross-encoder réordonne les top-\(M\) documents fusionnés.
Génération : les top-\(k\) documents sont injectés dans le prompt du LLM.
def hybrid_rag(query, top_n=100, top_k=5):
dense_results = vector_store.search(query, top_n)
sparse_results = bm25_index.search(query, top_n)
fused = reciprocal_rank_fusion([dense_results, sparse_results])
reranked = cross_encoder.rerank(query, fused[:20])
context = "\n".join(doc.text for doc, _ in reranked[:top_k])
return llm.generate(query, context)
Self-RAG et RAG adaptatif#
Les approches précédentes améliorent la qualité de la récupération, mais elles ne remettent pas en question le schéma : pour toute requête, on récupère des documents et on les injecte. Or, certaines questions ne nécessitent aucune récupération, tandis que d’autres en necessitent plusieurs étapes. Le Self-RAG et le RAG adaptatif donnent au modèle le contrôle sur ce processus.
Définition 61 (Self-RAG)
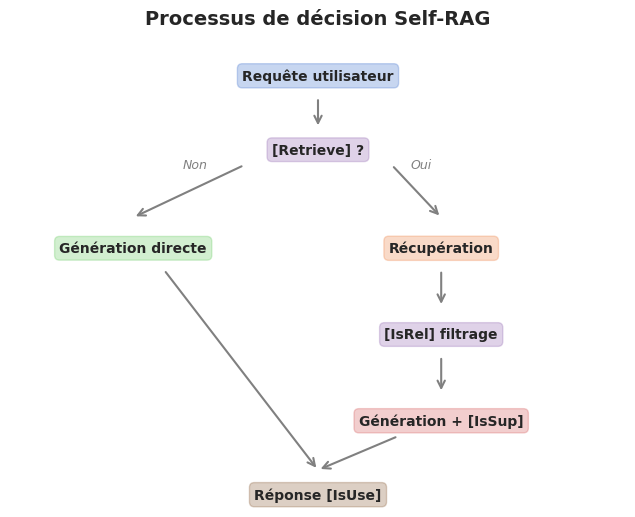
Le Self-RAG (Self-Reflective Retrieval-Augmented Generation), propose par Asai et al. (2023), est un framework dans lequel le LLM génère des tokens de réflexion (reflection tokens) contrôlant la récupération et la génération :
Décider s’il faut récupérer des documents (token
[Retrieve]: oui / non).Evaluer la pertinence de chaque document récupéré (token
[IsRel]: pertinent / non pertinent).Vérifier si la génération est soutenue par le document (token
[IsSup]: totalement / partiellement / pas du tout).Juger l’utilité globale de la reponse (token
[IsUse]: utile / pas utile).
Le modèle est entrainé par distillation à partir d’un modèle critique qui annote les données avec ces tokens de réflexion.
Exemple 45 (Boucle Self-RAG)
Déroulement d’une requête dans un système Self-RAG :
Requête : « Quelle est la population de Lyon ? »
Le modèle génère
[Retrieve] = oui(connaissance paramétrique potentiellement obsolète).Le système récupère 5 documents.
Pour chaque document,
[IsRel]est évalué. Seuls 3 sont jugés pertinents.Le modèle génère une réponse candidate par document pertinent.
Pour chaque réponse,
[IsSup]et[IsUse]sont evalués.La réponse avec les meilleurs scores est sélectionnée.
def self_rag(query):
need_retrieval = model.predict_retrieve(query)
if not need_retrieval:
return model.generate(query)
docs = retriever.search(query, top_k=5)
relevant_docs = [d for d in docs if model.predict_relevance(query, d)]
candidates = []
for doc in relevant_docs:
response = model.generate(query, context=doc)
support = model.predict_support(response, doc)
utility = model.predict_utility(response, query)
candidates.append((response, support, utility))
return max(candidates, key=lambda x: x[1] + x[2])[0]
Le RAG adaptatif généralise cette idée en introduisant un routeur qui sélectionne la stratégie de récupération selon la complexité de la requête. Une question factuelle simple peut être traitée par une recherche directe, tandis qu’une question complexe est routée vers un pipeline agentic avec décomposition.
Graphes de connaissances#
Les approches précédentes traitent les documents comme des blocs de texte plat. Les graphes de connaissances (knowledge graphs) introduisent une représentation structurée de l’information qui permet un raisonnement explicite sur les relations entre entités.
Définition 62 (Graphe de connaissances)
Un graphe de connaissances (knowledge graph, KG) est un graphe orienté \(G = (V, E)\) où :
\(V\) est l’ensemble des entités (noeuds) : concepts, personnes, lieux, etc.
\(E \subseteq V \times \mathcal{R} \times V\) est l’ensemble des triplets \((s, r, o)\), où \(s\) est le sujet, \(r \in \mathcal{R}\) la relation, et \(o\) l’objet.
Chaque triplet encode un fait : \((Paris, \text{est\_capitale\_de}, France)\). Les grands KG incluent Wikidata (\(\sim\)100M entités), Freebase et DBpedia.
Exemple 46 (Triplets d’un graphe de connaissances)
Exemples de triplets :
Sujet |
Relation |
Objet |
|---|---|---|
BERT |
est_un |
Modèle de langage |
BERT |
cree_par |
|
GPT-4 |
est_un |
Modèle de langage |
GPT-4 |
cree_par |
OpenAI |
Modèle de langage |
utilise |
Transformer |
A partir de ce graphe, on peut répondre à des questions multi-sauts comme « Quelles entreprises ont créé des modèles de langage ? » en traversant : Modèle de langage <-- est_un -- {BERT, GPT-4} -- cree_par --> {Google, OpenAI}.
Remarque 69 (GraphRAG)
GraphRAG (Microsoft, 2024) construit automatiquement un KG à partir d’un corpus, puis l’utilise pour améliorer la récupération et le raisonnement :
Extraction : un LLM extrait les triplets \((s, r, o)\) de chaque chunk.
Résolution d’entités : les mentions différentes d’une même entité sont fusionnées.
Détection de communautés : l’algorithme de Leiden identifie des groupes d’entités fortement connectées.
Résumés : un LLM génère un résumé par communauté.
triples = llm.extract_triples(chunks)
graph = build_knowledge_graph(triples)
communities = leiden_algorithm(graph)
summaries = [llm.summarize(c) for c in communities]
GraphRAG excelle pour les questions globales (« Quels sont les thèmes principaux du corpus ? ») la ou le RAG naive, qui ne récupère que quelques chunks locaux, échoue.
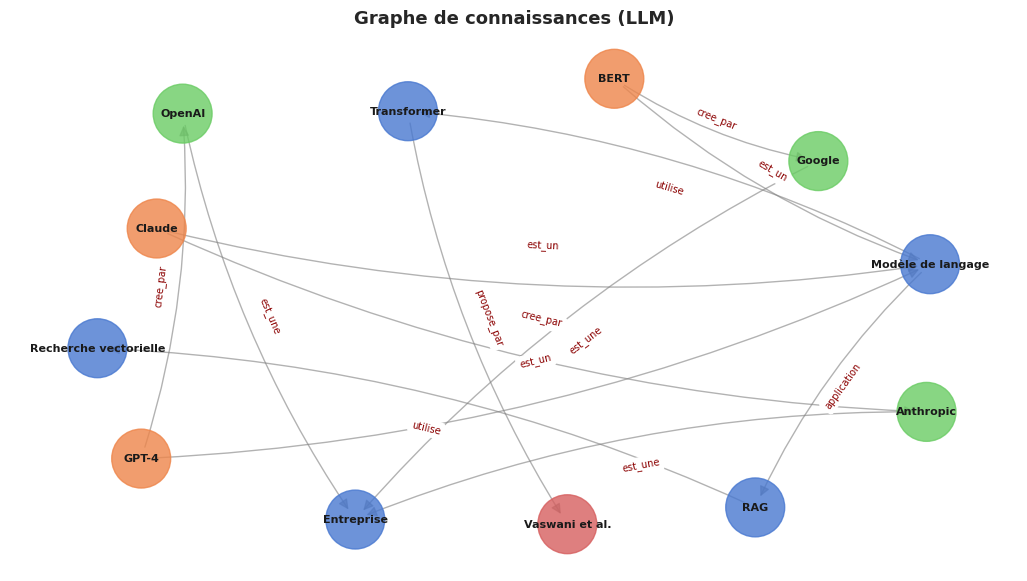
Le raisonnement multi-sauts (multi-hop) sur un graphe de connaissances permet de répondre à des questions nécessitant de traverser plusieurs arêtes. Par exemple, pour « Qui a proposé l’architecture utilisée par le modèle créé par Anthropic ? », le système doit identifier que Claude utilise le Transformer (via est_un \(\to\) utilise), puis que le Transformer a été proposé par Vaswani et al. Ce type de raisonnement est extrêmement difficile pour un RAG naive.
Indexation hiérarchique et multi-étapes#
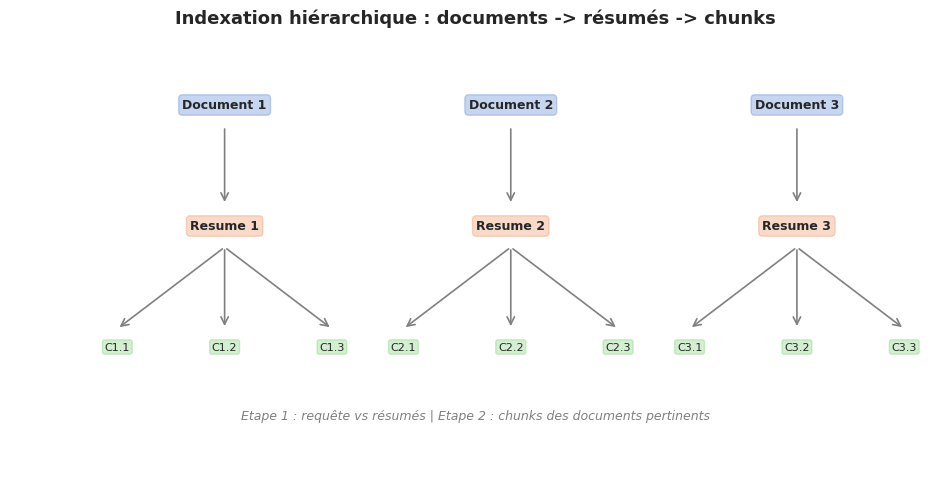
Les documents complexes possèdent une structure naturelle — chapitres, sections, paragraphes — que le RAG naive ignore. L”indexation hiérarchique exploite cette structure en construisant un index à deux niveaux : des résumés au premier niveau pour la récupération grossière, et des chunks au second pour la récupération fine.
Les résumés capturent le thème global d’un document (utile pour les requêtes exploratoires), tandis que les chunks capturent les détails spécifiques (utile pour les questions précises). En combinant les deux, le système traite une gamme plus large de requêtes.
La récupération multi-étapes va plus loin en décomposant une requête complexe en sous-requêtes. Chaque sous-requête récupère des documents spécifiques, et les résultats sont synthétisés pour construire la réponse finale. Cette approche est particulièrement utile pour les questions nécessitant un raisonnement conditionnel ou un croisement d’informations.
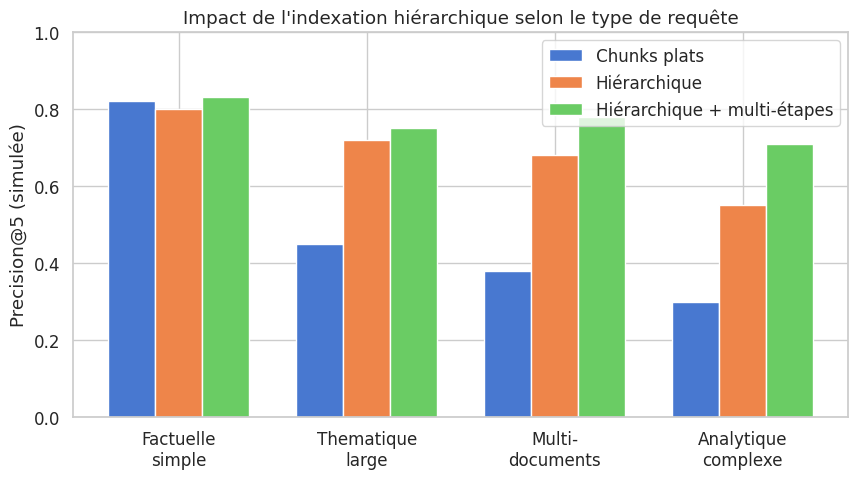
La récupération multi-étapes s’intègre naturellement avec les systèmes agentiques (chapitres 12–15). Un agent LLM peut décomposer une requête complexe, formuler des sous-requêtes, évaluer les résultats intermédiaires, et itérer jusqu’à obtenir une réponse satisfaisante. Cette convergence entre RAG avancé et agents est l’une des tendances les plus prometteuses du domaine.
Résumé#
Ce chapitre a présenté les techniques avancées qui dépassent le RAG naive pour construire des systèmes de récuperation et de génération plus performants.
Le RAG naive souffre de plusieurs modes de défaillance : récupération non pertinente, frontières de chunks, absence de raisonnement sur les documents récupérés, et stratégie uniforme indépendante de la complexité de la requête.
Le re-ranking avec des cross-encoders introduit une étape de précision après la récupération initiale par bi-encoder. Le cross-encoder modélise les intéractions croisées entre requête et document, offrant une précision supérieure au coût d’une latence accrue.
La recherche hybride combine récupération dense (similarité sémantique) et sparse (BM25, correspondance lexicale). La Reciprocal Rank Fusion (RRF), avec \(\text{RRF}(d) = \sum_r \frac{1}{k + \text{rank}_r(d)}\), fusionne les classements sans calibration.
Le Self-RAG (Asai et al., 2023) donné au modèle le contrôle sur le processus de récupération via des tokens de réflexion (
[Retrieve],[IsRel],[IsSup],[IsUse]). Le RAG adaptatif route les requêtes vers des stratégies différentes selon leur complexité.Les graphes de connaissances représentent l’information sous forme de triplets \((s, r, o)\) et permettent un raisonnement multi-sauts. GraphRAG (Microsoft) automatise la construction de KG à partir de documents et utilise la détection de communautés pour générer des résumés thématiques.
L”indexation hiérarchique exploite la structure naturelle des documents (résumés pour la récupération grossière, chunks pour la récupération fine). La récupération multi-étapes décompose les requêtes complexes en sous-requêtes, convergeant avec les approches agentiques.
Ces techniques sont complémentaires et les systèmes les plus performants en production les combinent dans des pipelines sophistiqués. Le choix de la bonne combinaison dépend du corpus, du type de requêtes, des contraintes de latence et du budget computationnel.