Inférence et génération#
Les chapitres précédents ont présenté l’architecture Transformer et le mécanisme de tokenisation qui transforme le texte brut en séquences d’identifiants numériques. Mais comment un LLM produit-il effectivement du texte ? La réponse tient en un mécanisme étonnamment simple dans son principe : le modèle prédit le prochain token en fonction de tous les tokens précédents, puis répète cette opération indéfiniment. Ce processus, appelé décodage autorégressif, est le moteur fondamental de toute génération de texte par un LLM.
Pourtant, la simplicité du principe masque une richesse de choix algorithmiques. À chaque pas de génération, le modèle produit une distribution de probabilité sur l’ensemble du vocabulaire — typiquement des dizaines de milliers de tokens. Comment choisir le prochain token dans cette distribution ? Faut-il toujours sélectionner le plus probable, ou introduire de l’aléatoire ? Comment contrôler le degré de « créativité » du modèle ? Ces questions ont donné naissance à une famille de stratégies de décodage — température, top-\(k\), nucleus sampling, beam search — dont le choix influence profondément la qualité, la diversité et la cohérence du texte généré.
Ce chapitre explore l’ensemble du pipeline de génération. Nous commencerons par formaliser le décodage autorégressif, puis examinerons les optimisations qui rendent l’inférence praticable à grande échelle (KV-cache), avant de détailler chaque stratégie de décodage avec des implémentations exécutables. Nous utiliserons GPT-2 (124M paramètres, ~500 Mo) comme modèle de démonstration, suffisamment léger pour s’exécuter sur une machine avec 8 Go de RAM.
Paramètres : 124M
Vocabulaire : 50257 tokens
Décodage autorégressif#
Le décodage autorégressif est le mécanisme par lequel un LLM génère du texte token par token. À chaque étape, le modèle prend en entrée la séquence de tokens produite jusqu’à présent et calcule une distribution de probabilité sur le token suivant.
Définition 14 (Décodage autorégressif)
Un modèle de langage autorégressif factorise la probabilité d’une séquence \(\mathbf{x} = (x_1, x_2, \ldots, x_T)\) comme un produit de probabilités conditionnelles :
À chaque pas \(t\), le modèle calcule un vecteur de logits \(\mathbf{z}_t \in \mathbb{R}^{|V|}\) (un score par token du vocabulaire \(V\)), puis convertit ces logits en probabilités via la fonction softmax :
La boucle de génération procède ainsi :
Encoder le prompt initial \((x_1, \ldots, x_n)\).
Calculer les logits \(\mathbf{z}_{n+1}\).
Sélectionner le token \(x_{n+1}\) selon une stratégie de décodage.
Ajouter \(x_{n+1}\) à la séquence et répéter depuis l’étape 2.
S’arrêter lorsqu’un token de fin (
<eos>) est généré ou qu’une longueur maximale est atteinte.
La factorisation autorégressive est une conséquence directe de la règle de la chaîne en théorie des probabilités. Elle ne fait aucune hypothèse d’indépendance : chaque token dépend de tous les tokens précédents. C’est le masque causal dans l’attention du Transformer qui garantit cette propriété — le token à la position \(t\) ne peut « voir » que les positions \(1, \ldots, t-1\).
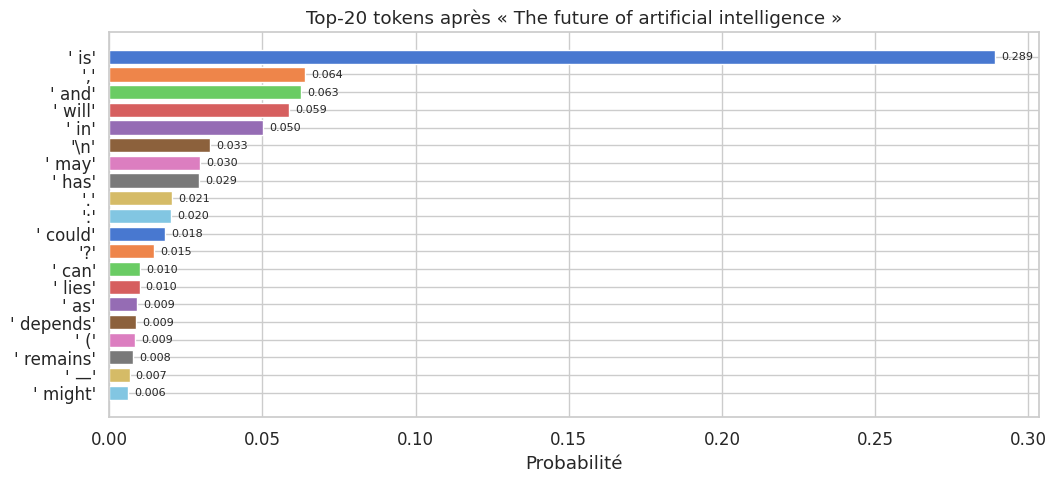
Remarque 12
La stratégie la plus simple est le décodage glouton (greedy decoding) : à chaque pas, on sélectionne le token de probabilité maximale \(x_t = \arg\max_v P(v \mid x_{<t})\). Cette approche est déterministe et rapide, mais elle produit souvent des textes répétitifs et peu naturels. Le décodage glouton ne garantit pas non plus de trouver la séquence globalement la plus probable, car il optimise localement à chaque pas sans considérer les conséquences à long terme.
KV-cache et optimisation de l’inférence#
Définition 15 (KV-cache)
Le KV-cache (Key-Value cache) est une technique d’optimisation qui évite de recalculer les matrices de clés (\(K\)) et de valeurs (\(V\)) pour les tokens déjà traités lors de la génération autorégressive. À chaque nouveau pas de génération :
On calcule \(Q_t\), \(K_t\), \(V_t\) uniquement pour le nouveau token \(x_t\).
On concatène \(K_t\) et \(V_t\) aux matrices \(K_{<t}\) et \(V_{<t}\) stockées en mémoire.
On calcule l’attention entre \(Q_t\) (un seul vecteur) et le cache \([K_{<t}; K_t]\), \([V_{<t}; V_t]\) complet.
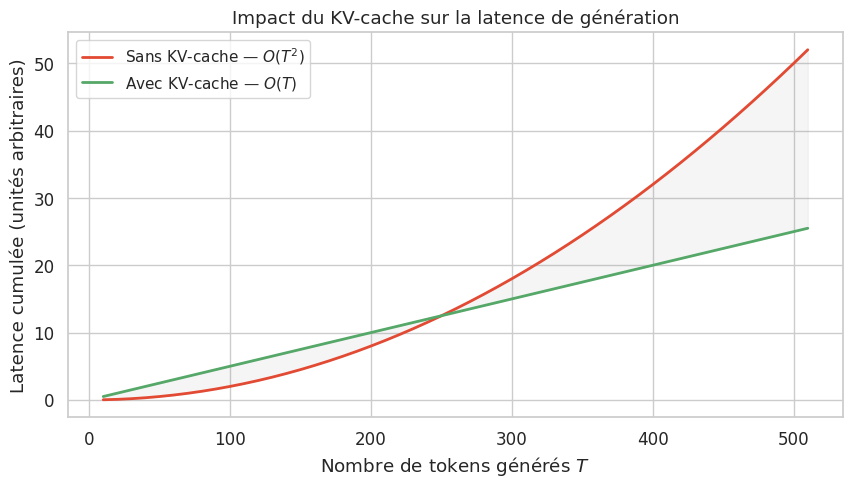
Sans KV-cache, chaque pas de génération nécessite de recalculer l’attention sur toute la séquence, soit une complexité de \(O(t \cdot d)\) par pas et \(O(T^2 \cdot d)\) au total pour \(T\) tokens. Avec le KV-cache, chaque pas coûte \(O(t \cdot d)\) mais on ne recalcule que pour le dernier token, réduisant le coût total à \(O(T \cdot d)\) au prix d’un stockage mémoire supplémentaire.
L’inférence autorégressive naïve — sans KV-cache — est extrêmement inefficace. À chaque pas \(t\), le Transformer doit réaliser une passe complète sur les \(t\) tokens de la séquence, recalculant les projections QKV et les produits d’attention pour tous les tokens, y compris ceux déjà traités aux pas précédents. Le coût total pour générer \(T\) tokens est donc \(O(T^2)\) en nombre d’opérations d’attention.
Remarque 13
La taille mémoire du KV-cache croît linéairement avec la longueur de séquence. Pour un modèle à \(L\) couches, \(H\) têtes d’attention et une dimension par tête \(d_h\), le cache stocke deux tenseurs (K et V) par couche et par tête :
Pour GPT-2 small (\(L=12\), \(H=12\), \(d_h=64\), dtype=float32) avec \(T = 1024\) tokens :
Pour des modèles plus grands (70B+ paramètres) avec des contextes longs (128k tokens), le KV-cache peut occuper plusieurs dizaines de Go, devenant le principal goulot d’étranglement mémoire de l’inférence.
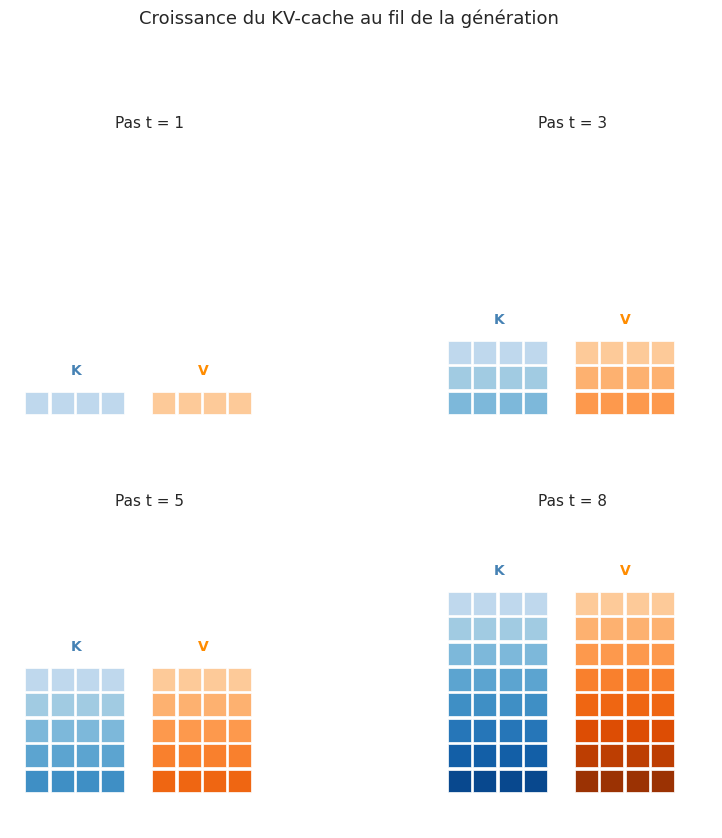
Remarque 14
Il est important de distinguer latence et débit (throughput) en inférence LLM. La latence est le temps pour générer une séquence complète (critique pour les applications interactives). Le débit est le nombre de tokens générés par seconde sur l’ensemble des requêtes (critique pour les systèmes à fort trafic). Le KV-cache améliore la latence par requête mais augmente la consommation mémoire, ce qui peut réduire le nombre de requêtes traitables en parallèle et donc le débit global. Ce compromis mémoire-calcul est central dans l’optimisation des systèmes de serving LLM.
Remarque 15
Le décodage spéculatif (speculative decoding) est une technique récente pour accélérer l’inférence. Un petit modèle « brouillon » (draft model) génère rapidement \(k\) tokens candidats, puis le grand modèle vérifie ces propositions en une seule passe forward (parallèle). Les tokens acceptés sont conservés ; le processus reprend au premier token rejeté. Cette approche peut accélérer la génération de 2 à 3 fois sans changer la distribution de sortie, à condition que le modèle brouillon soit suffisamment aligné avec le grand modèle.
Température et softmax#
La température est le paramètre le plus fondamental pour contrôler le comportement de la génération. Elle modifie la « netteté » de la distribution de probabilité sur le vocabulaire.
Définition 16 (Température)
La température \(T > 0\) est un scalaire qui divise les logits avant l’application du softmax. Pour un vecteur de logits \(\mathbf{z} \in \mathbb{R}^{|V|}\), la distribution modifiée par la température est :
Trois régimes se distinguent :
\(T \to 0\) : la distribution converge vers un Dirac sur le token de logit maximal (décodage glouton).
\(T = 1\) : la distribution originale du modèle est préservée.
\(T \to +\infty\) : la distribution converge vers une loi uniforme sur le vocabulaire.
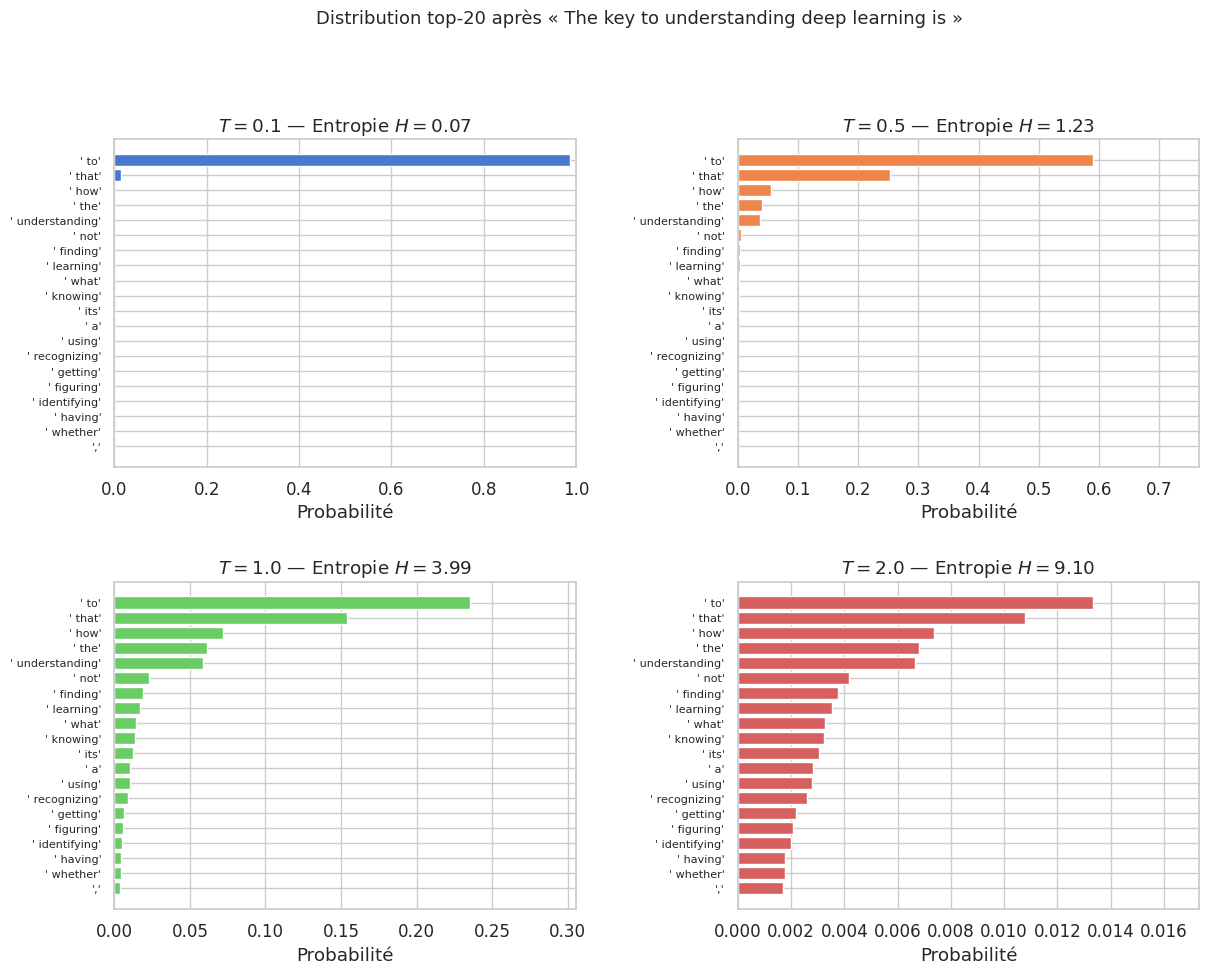
Propriété 3 (Température et entropie)
L”entropie \(H\) de la distribution de sortie est une fonction croissante de la température \(T\) :
Quand \(T \to 0\), \(H \to 0\) (certitude maximale, un seul token a toute la masse).
Quand \(T \to +\infty\), \(H \to \log |V|\) (entropie maximale, distribution uniforme).
À \(T = 1\), l’entropie reflète l’incertitude « naturelle » du modèle.
Une température élevée augmente la diversité mais réduit la cohérence ; une température basse produit des textes prévisibles mais potentiellement répétitifs.
Prompt : « Artificial intelligence will »
============================================================
T = 0.3 :
Artificial intelligence will be able to learn from the past, and will be able to learn from the future.
The technology will be able to learn from the past, and will be able to learn from the future. The technology will be able to learn from the
T = 0.7 :
Artificial intelligence will be used to work with the algorithms to solve problems that are already in the human brain.
"We're seeing a huge shift in the way we think about the world," says Griffin Parkman, head of global analytics at Deloitte.
T = 1.0 :
Artificial intelligence will continue to expand to create new theories and more tools to solve real problems like terrorism and disease we can't even get to. For now, ACRI's American Bureau of Public Affairs believes AI and AI cost $20B as a result of his PhD
T = 1.5 :
Artificial intelligence will materialise worldwide a furnace containing theories operating more underground parts than ever before: once again talking weirder farewell for 2010)." >>>>>> It ACRI Thomas Conglees Sal Meielve Dal Griffin Park Alexandria cost cmempp North car sm--- hist
Exemple 9 (Effet de la température sur la génération)
Avec le même prompt « Artificial intelligence will » et la même graine aléatoire :
\(T = 0.3\) : texte très conservateur, choix lexicaux prévisibles, phrases grammaticalement correctes mais peu originales. Le modèle reste « proche du centre » de sa distribution.
\(T = 0.7\) : bon compromis entre cohérence et diversité. C’est une valeur couramment utilisée en pratique pour les tâches créatives.
\(T = 1.0\) : distribution originale du modèle. Diversité accrue, mais apparition possible d’associations de mots inattendues.
\(T = 1.5\) : haute température. Le texte devient plus erratique, avec des transitions thématiques brusques et des formulations peu naturelles.
En pratique :
# Tâches factuelles (résumé, traduction) : T basse
model.generate(..., temperature=0.2)
# Tâches créatives (écriture, brainstorming) : T modérée
model.generate(..., temperature=0.7)
Stratégies de sampling : top-\(k\) et nucleus (top-\(p\))#
La température contrôle la forme globale de la distribution, mais elle ne résout pas un problème fondamental : même avec une température raisonnable, la longue traîne du vocabulaire contient des milliers de tokens à probabilité très faible mais non nulle. Occasionnellement, l’un de ces tokens improbables est échantillonné, produisant une rupture de cohérence dans le texte. Les stratégies de filtrage permettent d’éliminer cette longue traîne.
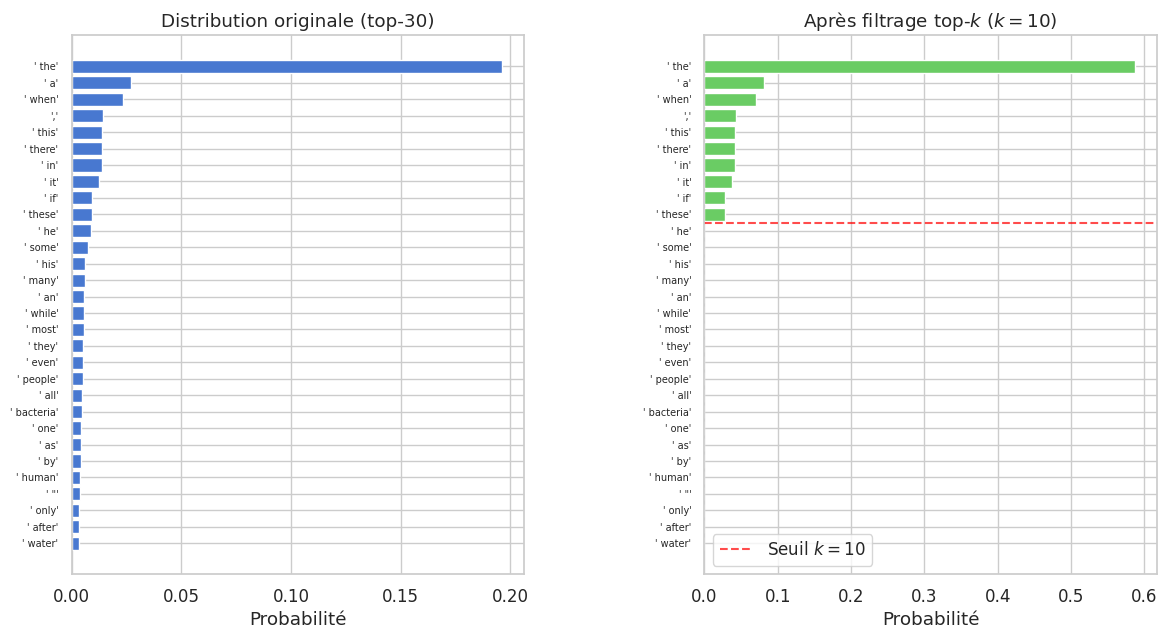
Définition 17 (Filtrage top-\(k\))
Le filtrage top-\(k\) restreint l’échantillonnage aux \(k\) tokens de plus haute probabilité. Formellement, soit \(V_k\) l’ensemble des \(k\) tokens de plus grands logits. La distribution filtrée est :
Valeurs typiques : \(k \in [10, 50]\). Le défaut historique est \(k = 50\).
Définition 18 (Filtrage nucleus (top-\(p\)))
Le filtrage nucleus (top-\(p\) sampling), introduit par Holtzman et al. (2020), sélectionne dynamiquement le plus petit ensemble de tokens \(V_p\) dont la probabilité cumulée dépasse un seuil \(p\) :
où les tokens sont triés par probabilité décroissante. La distribution est ensuite renormalisée sur \(V_p\).
L’avantage par rapport au top-\(k\) est l”adaptabilité : lorsque le modèle est confiant (distribution piquée), peu de tokens sont retenus ; lorsqu’il hésite (distribution plate), davantage de tokens sont considérés. Valeur typique : \(p \in [0.9, 0.95]\).
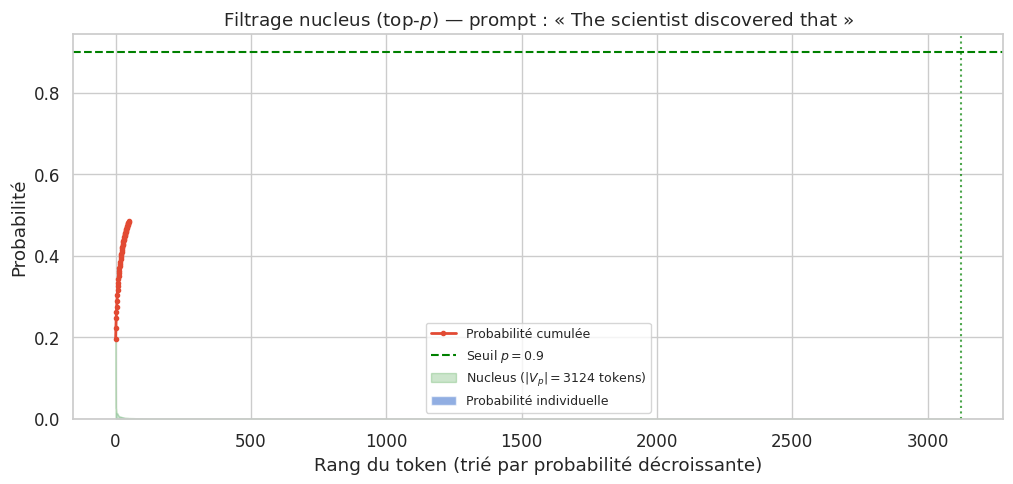
Tokens retenus par top-p = 0.9 : 3124
Exemple 10 (Top-\(k\) vs top-\(p\) : comportement adaptatif)
Considérons deux situations :
Cas 1 — Distribution piquée (le modèle est confiant) :
Le token le plus probable a \(p_1 = 0.85\).
Top-\(k\) (\(k=50\)) : retient 50 tokens, dont 49 sont quasi inutiles.
Top-\(p\) (\(p=0.9\)) : retient seulement 2–3 tokens, éliminant le bruit.
Cas 2 — Distribution plate (le modèle hésite) :
Les 30 premiers tokens ont chacun \(\approx 0.03\).
Top-\(k\) (\(k=10\)) : ne retient que 10 tokens, soit \(\approx 30\%\) de la masse.
Top-\(p\) (\(p=0.9\)) : retient \(\approx 30\) tokens, préservant la diversité.
# Top-p s'adapte automatiquement à la confiance du modèle
output = model.generate(
input_ids,
do_sample=True,
top_p=0.92, # nucleus sampling
temperature=0.8, # combiné avec une température modérée
max_new_tokens=50,
)
En pratique, top-\(p\) et top-\(k\) sont souvent combinés : on applique d’abord le filtrage top-\(k\), puis le filtrage top-\(p\) sur les tokens restants.
Remarque 16
Les systèmes de production modernes combinent généralement température, top-\(p\) et pénalité de répétition en un pipeline de post-traitement des logits. L’ordre d’application est : (1) pénalité de répétition sur les logits bruts, (2) division par la température, (3) filtrage top-\(k\), (4) filtrage top-\(p\), (5) échantillonnage. L’API d’OpenAI, par exemple, expose temperature et top_p comme paramètres principaux et recommande de ne modifier qu’un seul à la fois pour un contrôle prévisible.
Beam search et ses variantes#
Les stratégies de sampling introduisent de l’aléatoire pour favoriser la diversité. Le beam search adopte l’approche opposée : il explore systématiquement plusieurs hypothèses en parallèle pour trouver les séquences les plus probables.
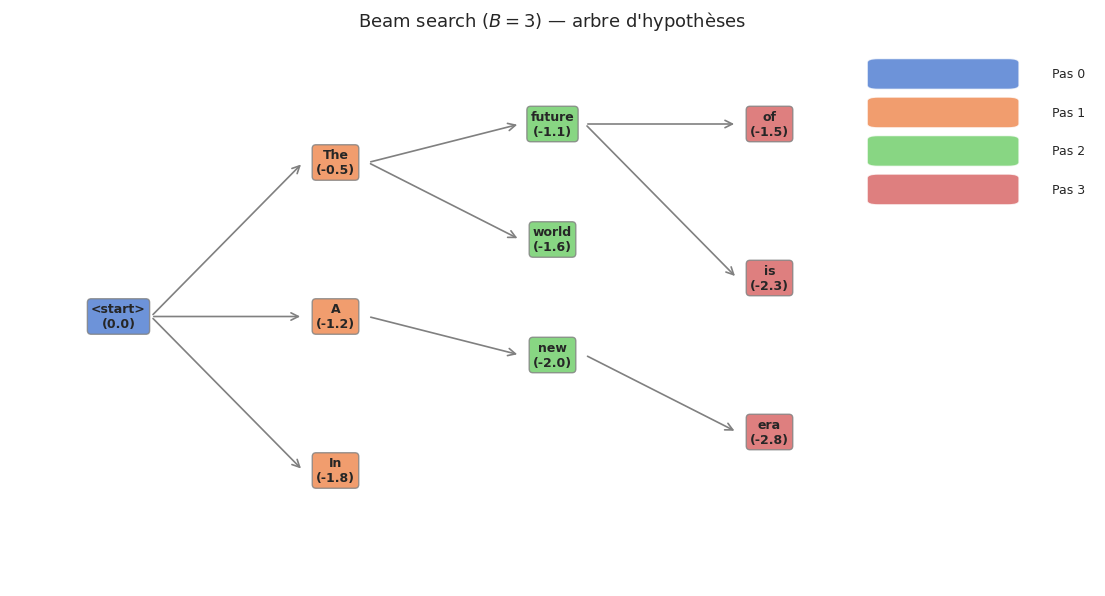
Définition 19 (Beam search)
Le beam search (recherche en faisceau) maintient à chaque pas de génération un ensemble de \(B\) hypothèses (séquences partielles), appelées le beam. À chaque pas \(t\) :
Pour chaque hypothèse dans le beam, calculer les probabilités de tous les tokens suivants possibles.
Former l’ensemble des \(B \times |V|\) extensions candidates.
Ne conserver que les \(B\) extensions de plus haute log-probabilité cumulée :
Appliquer optionnellement une pénalité de longueur pour éviter de favoriser les séquences courtes :
où \(\alpha \in [0.6, 1.0]\) est un hyperparamètre. Avec \(\alpha = 0\), pas de pénalité ; \(\alpha = 1\) correspond à la moyenne des log-probabilités.
Le paramètre \(B\) (largeur du beam) contrôle le compromis entre qualité de la recherche et coût computationnel. Avec \(B = 1\), le beam search se réduit au décodage glouton.
Propriété 4 (Complexité du beam search)
Le beam search de largeur \(B\) sur une séquence de \(T\) tokens avec un vocabulaire de taille \(|V|\) a une complexité temporelle de \(O(B \times T \times |V|)\) et une complexité mémoire de \(O(B \times T)\) pour stocker les hypothèses. En pratique, \(B\) est petit (\(B \in [2, 10]\)) et le surcoût par rapport au décodage glouton reste modéré. Au-delà de \(B \approx 10\), le gain en qualité devient marginal tandis que le coût augmente linéairement.
Remarque 17
Le beam search et le décodage glouton souffrent d’un problème de répétition : le modèle tend à produire des boucles où la même phrase ou le même motif se répète indéfiniment. Plusieurs mécanismes atténuent ce problème :
Pénalité de répétition (repetition penalty) : diviser les logits des tokens déjà générés par un facteur \(\theta > 1\).
Pénalité de n-grammes : interdire la génération de n-grammes déjà présents dans le texte (typiquement \(n = 3\) ou \(4\)).
Beam search diversifié (diverse beam search) : ajouter un terme de pénalité encourageant les différents beams à explorer des régions distinctes de l’espace des séquences.
Prompt : « The most important discovery in science »
=================================================================
[Greedy]
The most important discovery in science is that the universe is not a single, singular, singular, singular, singular, singular, singular, singular, singular, singular, singular, singular, singular, singular, singular, singular, singular, singular, singular, singular, singular, singular
[Sampling (T=0.8)]
The most important discovery in science is that the same molecular activity in neurons will manifest in different tissues. In order to understand these mechanisms it is necessary to act on the inside of neurons. In particular, several types of neurons have been shown to be activated as a response to certain molecular
[Top-k (k=40)]
The most important discovery in science is that the same molecular activity in neurons will affect our physiology. The activity of neurons in the brain can influence our cognitive abilities. The brain has many activities and its activity can be altered by different medications. We are able to change our physiology in different
[Top-p (p=0.92)]
The most important discovery in science is that the same molecular machinery in neurons will work in different tissues. In order for the same kind of machine to work in the same body of cells, it needs to be able to break down the genetic material. This means, for example, that
[Beam search (B=5)]
The most important discovery in science is that there is no such thing as a 'good' or 'bad' way of looking at the universe.
In fact, there is no such thing as a 'good' or 'bad' way of looking at the universe.
Exemple 11 (Trace d’un beam search)
Considérons un beam search avec \(B = 2\) sur le prompt « The cat ». À chaque pas, le modèle évalue toutes les extensions possibles et ne conserve que les \(B\) meilleures.
Pas 1 — Extensions de « The cat » :
Candidat |
Log-prob cumulée |
|---|---|
« The cat sat » |
\(-0.8\) |
« The cat is » |
\(-1.0\) |
~~« The cat the »~~ |
~~\(-3.2\)~~ |
Beam retenu : {« The cat sat », « The cat is »}
Pas 2 — Extensions des deux hypothèses :
Candidat |
Log-prob cumulée |
|---|---|
« The cat sat on » |
\(-1.3\) |
« The cat is a » |
\(-1.5\) |
~~« The cat sat the »~~ |
~~\(-2.9\)~~ |
~~« The cat is the »~~ |
~~\(-2.1\)~~ |
Beam retenu : {« The cat sat on », « The cat is a »}
Le beam search explore ainsi un espace de séquences beaucoup plus large que le décodage glouton, sans le coût prohibitif d’une recherche exhaustive.
Comparaison des stratégies#
Le choix de la stratégie de décodage dépend de la tâche, du modèle et des contraintes opérationnelles. Le tableau suivant résume les caractéristiques de chaque approche.
Stratégie |
Déterministe ? |
Qualité |
Diversité |
Coût relatif |
Cas d’usage typique |
|---|---|---|---|---|---|
Greedy |
Oui |
Moyenne |
Nulle |
\(1\times\) |
Prototypage rapide |
Sampling (\(T\)) |
Non |
Variable |
Haute |
\(1\times\) |
Écriture créative |
Top-\(k\) |
Non |
Bonne |
Modérée |
\(1\times\) |
Génération généraliste |
Top-\(p\) (nucleus) |
Non |
Bonne |
Modérée-haute |
\(1\times\) |
Dialogue, rédaction |
Beam search (\(B\)) |
Oui |
Haute |
Faible |
\(B\times\) |
Traduction, résumé |
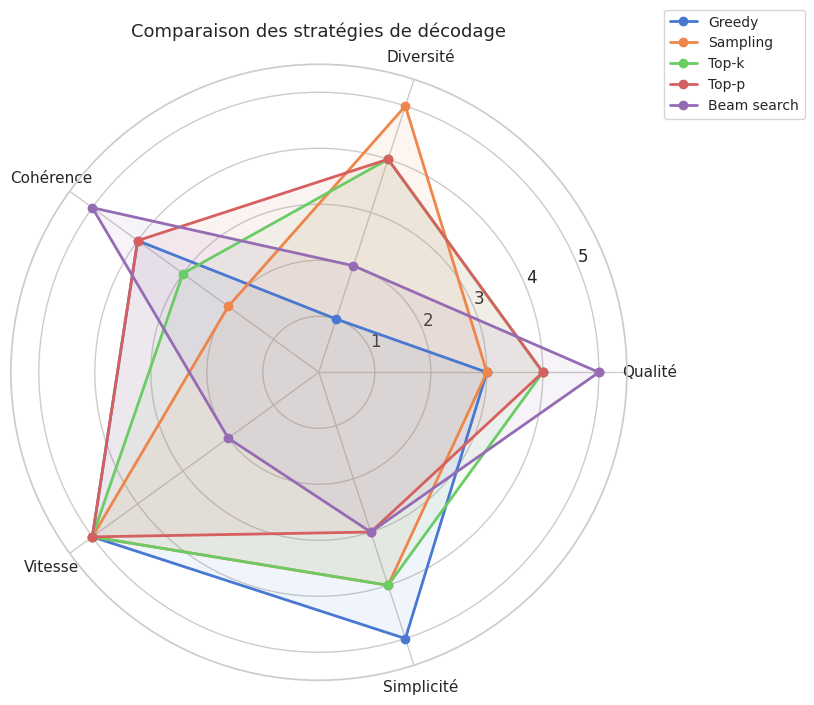
Le décodage glouton est le plus rapide et le plus simple, mais il sacrifie toute diversité et tend à produire des textes répétitifs. Le sampling avec température offre un contrôle direct sur la diversité, mais sans filtrage, la longue traîne du vocabulaire peut produire des incohérences. Le top-\(k\) est un filtre simple et efficace, mais son seuil fixe ne s’adapte pas à la confiance variable du modèle. Le top-\(p\) (nucleus) résout cette limitation par un seuil adaptatif — c’est la stratégie la plus utilisée dans les systèmes de production modernes (ChatGPT, Claude, etc.), souvent combinée avec une température modérée. Le beam search maximise la probabilité de la séquence complète, ce qui le rend préférable pour les tâches structurées (traduction, résumé) où la qualité prévaut sur la créativité, mais son coût est proportionnel à la largeur \(B\).
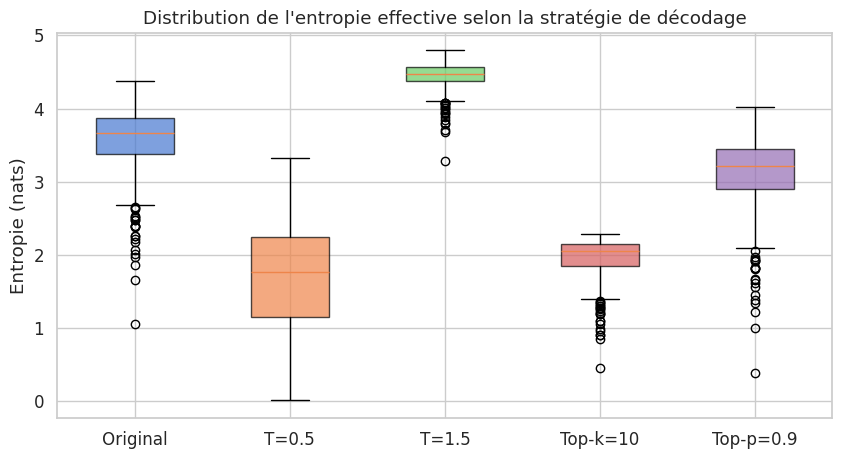
Résumé#
Ce chapitre a présenté le pipeline complet de génération de texte par un LLM, depuis le mécanisme autorégressif fondamental jusqu’aux stratégies de décodage sophistiquées.
Remarque 18
Points clés à retenir :
Le décodage autorégressif génère du texte token par token, chaque token étant conditionné sur tous les précédents : \(P(x_t \mid x_{<t})\). La boucle de génération itère jusqu’à un token de fin ou une longueur maximale.
Le KV-cache est une optimisation essentielle qui réduit la complexité de l’inférence de \(O(T^2)\) à \(O(T)\) en stockant les matrices de clés et valeurs déjà calculées, au prix d’une consommation mémoire linéaire en la longueur de séquence.
La température contrôle la netteté de la distribution softmax : \(T \to 0\) produit un décodage glouton (déterministe), \(T \to +\infty\) une distribution uniforme (aléatoire). L’entropie est une fonction croissante de \(T\).
Le filtrage top-\(k\) restreint l’échantillonnage aux \(k\) tokens les plus probables, éliminant la longue traîne mais avec un seuil fixe inadapté à la confiance variable du modèle.
Le filtrage nucleus (top-\(p\)) sélectionne dynamiquement le plus petit ensemble de tokens dont la probabilité cumulée dépasse \(p\), offrant un seuil adaptatif supérieur au top-\(k\).
Le beam search explore \(B\) hypothèses en parallèle pour maximiser la probabilité de la séquence complète, avec un compromis qualité-coût proportionnel à la largeur du beam.
En pratique, les systèmes modernes combinent typiquement température, top-\(p\) et pénalité de répétition. Le beam search reste préféré pour les tâches structurées (traduction, résumé).
Le chapitre suivant aborde l”utilisation des API de LLM, où ces paramètres de génération sont directement exposés à l’utilisateur.