Agents en pratique#
Les chapitres précédents ont introduit les agents LLM, les frameworks qui les structurent et les architectures multi-agents. Il reste une question décisive : comment ces systèmes se comportent-ils dans le monde réel ? Passer d’un prototype de démonstration à un agent fiable en production exige bien plus qu’un prompt astucieux et un appel à un modèle de langage. Il faut concevoir des boucles de rétroaction, instrumenter chaque étape, gérer les erreurs inévitables et, surtout, savoir quand l’humain doit reprendre la main.
Ce chapitre adopte une perspective résolument pratique. Nous examinons d’abord les cas d’usage où les agents LLM apportent une valeur démontrée, puis nous construisons pas à pas deux agents concrets — un agent de recherche d’information et un agent d’analyse de code. Nous formalisons ensuite le patron human-in-the-loop, indispensable pour toute application à enjeux, et les techniques de débogage et d’observabilité qui permettent de comprendre ce qu’un agent fait réellement.
La dernière section consolide les patterns de robustesse nécessaires en production : stratégies de reprise sur erreur, contrôle des coûts, garde-fous sur les actions autorisées. L’objectif est de fournir un guide opérationnel pour quiconque envisage de déployer un agent LLM au-delà du stade expérimental.
Cas d’usage réels#
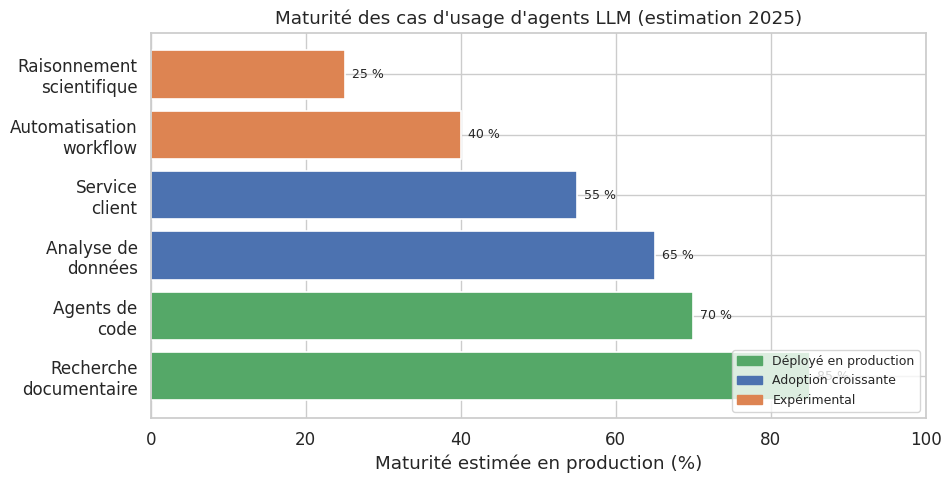
L’enthousiasme autour des agents LLM ne doit pas masquer une réalité : tous les cas d’usage ne sont pas mûrs. Certains domaines bénéficient déjà d’agents déployés en production ; d’autres restent au stade de la recherche.
Assistants de recherche. Les agents de recherche documentaire sont parmi les plus aboutis. Ils combinent la formulation de requêtes, l’extraction d’information depuis des sources hétérogènes et la synthèse avec citations. Des systèmes comme Perplexity AI ou les deep research de GPT illustrent cette catégorie. La valeur ajoutée est claire : un humain passerait des heures à faire ce qu’un agent réalise en minutes, avec un suivi des sources.
Agents de code. Les agents comme Devin (Cognition), Cursor Agent ou Claude Code représentent une avancée significative. Ils lisent du code, identifient des problèmes, proposent des corrections et exécutent des tests. Leur force réside dans la boucle écrire-exécuter-corriger qui mime le workflow d’un développeur. Les limites actuelles concernent les bases de code très volumineuses et les décisions architecturales de haut niveau.
Agents d’analyse de données. Ces agents reçoivent une question en langage naturel, génèrent du code d’analyse (pandas, SQL), l’exécutent, interprètent les résultats et produisent des visualisations. Ils excellent sur les requêtes exploratoires bien délimitées, mais peinent sur les analyses nécessitant une compréhension métier profonde.
Service client. Les agents conversationnels de support technique gèrent les demandes de premier niveau : diagnostic de problème, navigation dans la documentation, escalade vers un humain si nécessaire. Le taux de résolution autonome atteint 40–60 % dans les déploiements matures, avec un gain de temps considérable pour les équipes humaines.
Remarque 81
Un agent LLM est pertinent lorsque trois conditions sont réunies : (1) la tâche nécessite plusieurs étapes avec des décisions intermédiaires, (2) l’espace d’action est contraint et bien défini (outils limités, format de sortie structuré), et (3) le coût d’une erreur est gérable (vérification possible, rollback, supervision humaine). Si la tâche est simple et déterministe, un programme classique suffit. Si le coût d’une erreur est catastrophique et qu’aucune vérification n’est possible, un agent autonome n’est pas le bon choix.
Agent de recherche d’information#
Un agent de recherche suit un cycle multi-étapes : formulation de requête, recherche, extraction, synthèse et vérification. Chaque étape peut échouer ou nécessiter une itération, ce qui justifie l’architecture agentique plutôt qu’un simple appel de modèle.
Définition 77 (Agent de recherche)
Un agent de recherche d’information est un système qui, à partir d’une question en langage naturel, exécute de manière autonome un cycle itératif :
Décomposition : transformer la question en sous-questions ciblées.
Recherche : interroger une ou plusieurs sources (web, base de données, API).
Extraction : identifier les passages pertinents dans les résultats.
Synthèse : combiner les extraits en une réponse cohérente avec citations.
Vérification : confronter la synthèse aux sources pour détecter les incohérences.
Le processus est itératif : si la vérification révèle des lacunes, l’agent reformule ses requêtes et recommence.
Exemple 57 (Simulation d’un agent de recherche)
L’exemple suivant simule un agent de recherche en Python pur. Les outils de recherche et d’extraction sont remplacés par des fonctions fictives, mais la structure de contrôle — boucle de décision, accumulation de contexte, vérification — est fidèle aux implémentations réelles.
=== Résultat de l'agent de recherche ===
Réponse : Synthèse pour 'Transformer architecture and scaling laws': The Transformer architecture relies entirely on attention mec...
Sources : ['Vaswani et al., 2017', 'Devlin et al., 2019']
Confiance : 0.87
Trace (1 itérations) :
Itération 1 — 1 requêtes, confiance=0.87, sources=2
Remarque 82
Un anti-pattern fréquent dans les agents de recherche est la boucle de reformulation sans fin : l’agent reformule indéfiniment ses requêtes sans jamais atteindre le seuil de confiance. Trois garde-fous sont essentiels : (1) un nombre maximal d’itérations, (2) une détection de requêtes redondantes (si la reformulation est identique à une requête précédente, s’arrêter), et (3) une réponse dégradée mais honnête lorsque le seuil n’est pas atteint (« voici ce que j’ai trouvé, mais ma confiance est limitée »).
Agent d’analyse de code#
L’analyse automatisée de code est l’un des domaines où les agents LLM montrent le plus de potentiel. Un agent de code review suit un cycle structuré : lire le code, identifier les problèmes, proposer des corrections et, si possible, valider les corrections par exécution de tests.
Exemple 58 (Agent de revue de code)
L’exemple ci-dessous simule un agent d’analyse de code qui examine une fonction Python, identifie des problèmes potentiels et propose des corrections. En production, le LLM remplacerait les règles codées en dur, mais le patron d’orchestration reste le même.
============================================================
Rapport d'analyse — 4 problème(s) détecté(s)
============================================================
L 1 [ERREUR] Argument mutable par défaut — risque de partage d'état.
Original : def process_data(items, cache=[]):
Suggestion: Utiliser None comme défaut, initialiser dans le corps.
L 6 [AVERT] Clause except nue — capturer Exception explicitement.
Original : except:
Suggestion: except Exception as e:
L 1 [INFO] Fonction sans docstring.
Original : def process_data(items, cache=[]):
Suggestion: Ajouter une docstring.
L 10 [INFO] Fonction sans docstring.
Original : def transform(x):
Suggestion: Ajouter une docstring.
Exemple 59 (Agent d’analyse de données)
Un agent d’analyse de données suit le cycle : comprendre la question en langage naturel, générer du code d’analyse (pandas, matplotlib), exécuter le code, interpréter les résultats. En production, le code généré est exécuté dans un bac à sable isolé (sandbox) pour des raisons de sécurité. L’agent peut itérer si le code échoue ou si les résultats semblent incohérents.
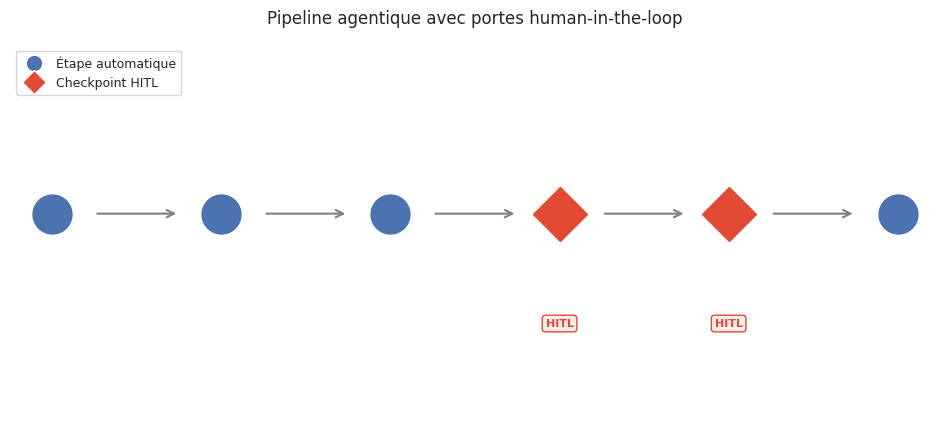
Human-in-the-loop#
L’autonomie totale d’un agent est rarement souhaitable. Dans la plupart des déploiements réels, l’humain reste dans la boucle — soit comme validateur à des points de contrôle, soit comme recours en cas d’incertitude. Le patron human-in-the-loop (HITL) formalise ces interactions.
Définition 78 (Human-in-the-loop)
Le patron human-in-the-loop (HITL) désigne une architecture dans laquelle un agent autonome soumet certaines décisions à la validation d’un opérateur humain avant de les exécuter. Les points de contrôle (checkpoints) sont définis selon trois critères :
Irréversibilité : toute action non annulable (envoi d’email, modification de base de données, paiement) requiert une approbation.
Incertitude : lorsque la confiance du modèle est inférieure à un seuil, l’agent demande confirmation.
Politique d’escalade : certaines catégories d’actions sont systématiquement soumises à validation indépendamment de la confiance.
Le HITL n’est pas un aveu de faiblesse de l’agent ; c’est un choix d’ingénierie qui optimise le compromis entre vitesse d’exécution et fiabilité.
Exemple 60 (Workflow HITL avec points de contrôle)
L’exemple suivant implémente une machine à états simple avec des points de contrôle HITL. Chaque transition peut être automatique ou nécessiter une approbation, selon la politique configurée.
Pipeline arrêté : 'execute' rejeté par l'humain.
=== Trace du workflow HITL ===
init -> research [ auto] auto | Recherche d'information sur le sujet
research -> draft [ auto] auto | Rédaction du brouillon
draft -> review [CHECKPOINT] approuvé | Contenu prêt pour validation humaine
review -> execute [CHECKPOINT] rejeté | Publication du contenu
Propriété 19 (Compromis fiabilité-autonomie)
Il existe un compromis fondamental entre fiabilité et autonomie dans un système agentique. Soit \(A\) le degré d’autonomie (fraction de décisions prises sans validation humaine) et \(R\) la fiabilité (probabilité qu’une action soit correcte). En général :
où \(R_0\) est la fiabilité avec supervision totale, et \(\alpha, \beta > 0\) sont des paramètres dépendant de la qualité du modèle et de la complexité de la tâche. L’objectif est de trouver le point \(A^*\) qui maximise l’utilité :
où \(\gamma\) est la valeur de la vitesse d’exécution et \(C_{\text{erreur}}\) le coût d’une erreur. Plus le coût d’erreur est élevé, plus \(A^*\) est faible (davantage de supervision humaine).
Debugging et observabilité#
Un agent LLM est un système opaque par nature : ses décisions dépendent du modèle, du contexte accumulé et d’interactions stochastiques avec des outils externes. Sans instrumentation, diagnostiquer un comportement incorrect est quasiment impossible.
Définition 79 (Observabilité d’un agent)
L”observabilité d’un agent est la capacité à reconstituer, a posteriori, la séquence complète de ses décisions, actions et résultats. Elle repose sur trois piliers :
Logs structurés : chaque étape est enregistrée avec un horodatage, l’action choisie, les arguments, le résultat et les métriques (tokens consommés, latence).
Traces : les logs sont chaînés en une trace identifiable par un identifiant unique de session, permettant de suivre le raisonnement de bout en bout.
Métriques agrégées : taux de succès, nombre moyen d’itérations, coût par requête, distribution des types d’erreurs.
Des outils comme LangSmith, Arize Phoenix ou Weights & Biases Traces fournissent des interfaces visuelles pour explorer ces données. Le principe reste le même : capturer chaque décision de l’agent dans un format structuré et requêtable.
Exemple 61 (Logger de traces structuré)
Le logger ci-dessous capture chaque action de l’agent dans un format JSON structuré. En production, ces traces sont envoyées vers un système de stockage centralisé (Elasticsearch, BigQuery, etc.) pour analyse ultérieure.
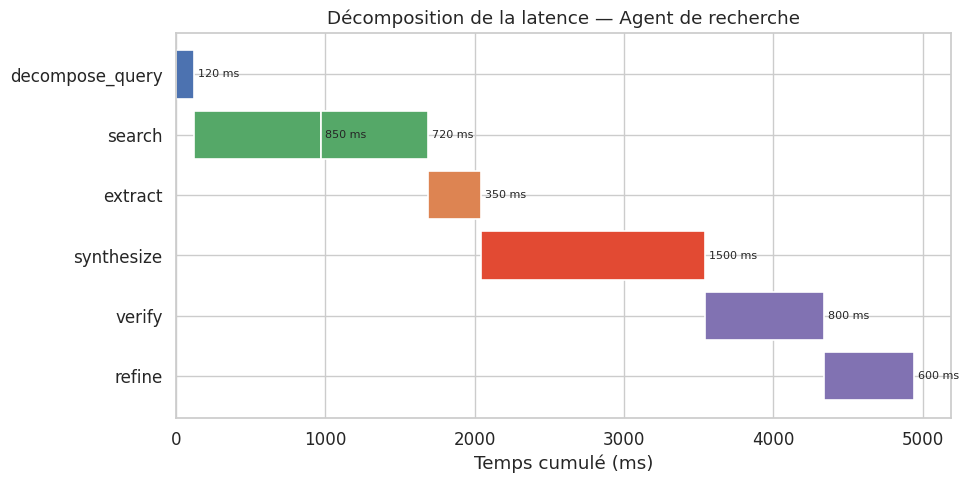
=== Trace de l'agent ===
Étape 1 | decompose_query | tokens= 150 | success
Étape 2 | search | tokens= 0 | success
Étape 3 | search | tokens= 0 | success
Étape 4 | extract | tokens= 800 | success
Étape 5 | synthesize | tokens= 1200 | success
Étape 6 | verify | tokens= 600 | success
Étape 7 | refine | tokens= 400 | success
=== Résumé ===
session_id: agent-research-042
total_steps: 7
total_tokens: 3150
total_time_s: 0.0709
errors: 0
Robustesse et patterns de production#
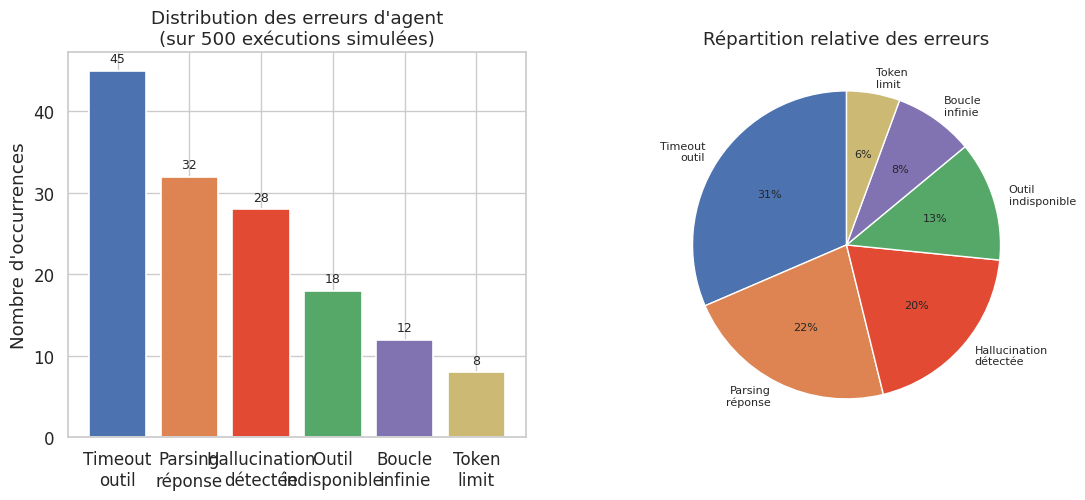
Un agent déployé en production fait face à des pannes réseau, des timeouts d’API, des réponses malformées et des boucles non terminantes. Les patterns de robustesse sont empruntés à l’ingénierie logicielle distribuée et adaptés au contexte agentique.
Remarque 83
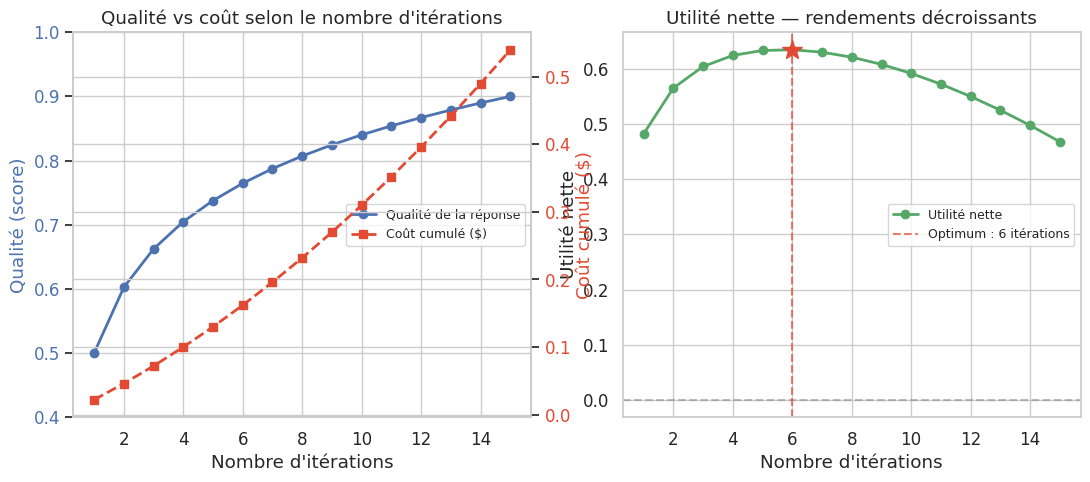
Le contrôle des coûts est un enjeu critique. Un agent mal configuré peut consommer des milliers de tokens par requête, avec un coût qui croît linéairement (voire super-linéairement si le contexte s’allonge à chaque itération). Trois leviers de contrôle sont essentiels :
Limite d’itérations : fixer un nombre maximal de boucles agent (typiquement 5–15).
Budget de tokens : fixer un plafond total de tokens par session (entrée + sortie).
Coût marginal décroissant : si les dernières itérations n’améliorent plus significativement le résultat, s’arrêter tôt (early stopping).
Remarque 84
Les garde-fous (guardrails) limitent l’espace d’action de l’agent pour prévenir les comportements indésirables. Ils opèrent à plusieurs niveaux :
Filtrage des actions : liste blanche d’outils autorisés, validation des arguments avant exécution.
Filtrage des sorties : détection de contenu toxique, d’informations personnelles ou de code malveillant.
Sandboxing : exécution du code généré dans un environnement isolé (conteneur, VM, WebAssembly).
Exemple de garde-fou en pseudo-code :
ALLOWED_TOOLS = {"search", "calculate", "read_file"}
def validate_action(action, args):
if action not in ALLOWED_TOOLS:
raise ForbiddenActionError(f"Outil {action} non autorisé")
if action == "read_file" and ".." in args["path"]:
raise ForbiddenActionError("Traversée de répertoire interdite")
return True
En production, ces garde-fous sont implémentés comme des middleware dans le pipeline d’exécution de l’agent.
Définition 80 (Stratégie de reprise (fallback))
Une stratégie de reprise (fallback strategy) définit le comportement de l’agent lorsqu’une action échoue. Les patterns classiques sont :
Retry avec backoff exponentiel : retenter l’action après un délai croissant (\(\Delta t_k = \Delta t_0 \cdot 2^k\) pour la \(k\)-ième tentative).
Fallback vers un modèle alternatif : si le modèle principal est indisponible, basculer vers un modèle plus petit ou plus rapide.
Dégradation gracieuse : retourner un résultat partiel plutôt qu’aucun résultat.
Circuit breaker : après \(n\) échecs consécutifs, désactiver temporairement l’outil défaillant.
En pseudo-code :
def execute_with_fallback(action, max_retries=3):
for attempt in range(max_retries):
try:
return action()
except TransientError:
time.sleep(BASE_DELAY * 2 ** attempt)
except PermanentError:
return fallback_action()
return graceful_degradation()
Le choix de la stratégie dépend du type d’erreur : les erreurs transitoires (timeout, rate limit) justifient un retry ; les erreurs permanentes (outil supprimé, permission refusée) nécessitent un fallback immédiat.
Sessions réussies : 20/20 (100%)
Nombre moyen de tentatives : 2.3
Détail des 5 premières sessions :
Session 0 : F -> S (2 tentatives)
Session 1 : S (1 tentatives)
Session 2 : S (1 tentatives)
Session 3 : F -> F -> F -> S (4 tentatives)
Session 4 : S (1 tentatives)
Résumé#
Ce chapitre a abordé les aspects pratiques du déploiement d’agents LLM, depuis les cas d’usage concrets jusqu’aux patterns de robustesse en production.
Les cas d’usage mûrs pour les agents LLM incluent la recherche documentaire, l’analyse de code, l’analyse de données et le service client. Le critère de pertinence repose sur trois conditions : tâche multi-étapes, espace d’action contraint et coût d’erreur gérable.
Un agent de recherche d’information suit un cycle itératif — formulation de requête, recherche, extraction, synthèse, vérification — avec des critères d’arrêt explicites (seuil de confiance, nombre maximal d’itérations) et une attribution systématique des sources.
Un agent d’analyse de code combine la lecture de code, la détection de problèmes par règles et par LLM, la proposition de corrections et la validation par exécution de tests. Le patron d’orchestration est similaire à celui de la recherche.
Le patron human-in-the-loop insère des points de contrôle humains aux transitions critiques : actions irréversibles, décisions à faible confiance, catégories soumises à une politique d’escalade. Il optimise le compromis entre autonomie et fiabilité.
L”observabilité repose sur des logs structurés, des traces chaînées par session et des métriques agrégées. Elle est indispensable pour le diagnostic des comportements incorrects et l’amélioration continue du système.
Les patterns de robustesse empruntés à l’ingénierie distribuée — retry avec backoff, fallback vers des modèles alternatifs, dégradation gracieuse, circuit breaker — assurent la résilience face aux pannes inévitables des composants externes.
Le contrôle des coûts passe par des limites d’itérations, des budgets de tokens et une détection des rendements décroissants. Un agent non borné est un risque financier autant qu’un risque technique.
Remarque 85
L’erreur la plus fréquente dans le déploiement d’agents LLM est de sous-estimer la complexité opérationnelle. Un agent qui fonctionne dans un notebook de démonstration n’est pas un agent prêt pour la production. La différence réside dans l’instrumentation (traces, métriques), la gestion des erreurs (retry, fallback), le contrôle des coûts (budgets, limites) et la supervision humaine (HITL, escalade). Ces quatre piliers transforment un prototype fragile en un système fiable.