Tokenisation et embeddings#
Le chapitre précédent a introduit l’architecture Transformer et les grands modèles de langage (LLM). Cependant, avant qu’un texte puisse être traité par un Transformer, il doit être converti en une séquence de nombres entiers — les token IDs — puis projeté dans un espace vectoriel continu via une matrice d’embeddings. Cette double transformation conditionne profondément les capacités et les limites de tout LLM : le choix du tokenizer détermine combien de tokens sont nécessaires pour représenter un texte, quels mots rares peuvent être gérés, et quelles langues sont favorisées ou pénalisées.
Le chapitre 24 du volume Apprentissage automatique a introduit les bases de la tokenisation et les embeddings statiques (Word2Vec, GloVe). Le présent chapitre approfondit ces concepts dans le contexte spécifique des LLM : algorithmes de tokenisation subword (BPE byte-level, WordPiece, SentencePiece), vocabulaires et tokens spéciaux des modèles modernes, distinction entre embeddings statiques et contextuels, et sentence embeddings pour représenter des phrases entières dans un espace vectoriel.
L’approche est pratique : nous utiliserons le tokenizer de GPT-2 (vocabulaire d’environ 1 Mo, aucun poids de modèle) et le modèle de sentence embeddings all-MiniLM-L6-v2 (environ 80 Mo) pour illustrer ces concepts par du code exécutable. L’empreinte mémoire totale reste bien inferieure à 1 Go.
Rappel et approfondissement : tokenisation subword#
La tokenisation par mots souffre d’un vocabulaire trop large et de l’impossibilité de traiter les mots hors vocabulaire (OOV), tandis que la tokenisation par caractères produit des séquences trop longues. La tokenisation par sous-mots (subword tokenization) est le compromis adopté par tous les LLM modernes : les mots fréquents restent intacts, les mots rares sont décomposés en sous-unités connues.
Définition 8 (Byte Pair Encoding au niveau des octets)
Le Byte Pair Encoding (BPE) au niveau des octets (byte-level BPE), tel qu’utilisé par GPT-2 et GPT-3, opère directement sur les octets bruts du texte encode en UTF-8, plutôt que sur des caractères Unicode. L’algorithme procède comme suit :
Initialisation : le vocabulaire de base contient les 256 valeurs d’octets possibles (0x00 a 0xFF).
Comptage des paires : pour chaque paire de tokens adjacents dans le corpus d’entrainement, compter le nombre d’occurrences.
Fusion : fusionner la paire la plus fréquente en un nouveau token et l’ajouter au vocabulaire.
Iteration : répéter les étapes 2-3 jusqu’à atteindre la taille de vocabulaire desirée \(|\mathcal{V}|\).
Le résultat est un vocabulaire de \(|\mathcal{V}|\) tokens, composé des 256 octets initiaux plus \(|\mathcal{V}| - 256\) tokens issus des fusions. Tout texte peut être tokenisé sans token inconnu, puisque le niveau de repli est l’octet individuel.
L’avantage du BPE byte-level est sa couverture universelle : il peut représenter n’importe quel texte dans n’importe quelle langue, y compris les emojis et les scripts rares, ce qui en fait le choix dominant pour les LLM multilingues.
Définition 9 (SentencePiece et le modèle unigram)
SentencePiece (Kudo et Richardson, 2018) est un framework de tokenisation qui traite le texte comme une séquence brute de caractères Unicode, sans pré-tokenisation par espaces. Il prend en charge deux algorithmes :
BPE : identique è l’algorithme décrit ci-dessus, mais applique directement sur la chaine brute.
Modèle unigram : part d’un vocabulaire initial très large et retire itérativement les tokens dont la suppression minimise la perte sur le corpus. La probabilité d’une segmentation \(\mathbf{x} = (x_1, \ldots, x_M)\) est :
ou \(p(x_i)\) est la probabilité unigram du token \(x_i\), estimée par maximum de vraisemblance. La segmentation optimale est trouvée par l’algorithme de Viterbi.
SentencePiece est utilisé par T5, LLaMA, Mistral et de nombreux modèles multilingues. L’espace est traité comme un caractère ordinaire (souvent noté _), ce qui rend la tokenisation entièrement réversible.
Remarque 7
Le BPE byte-level et SentencePiece diffèrent dans leur traitement des espaces et de la pré-tokenisation. Le BPE de GPT-2 applique d’abord une pré-tokenisation par regex qui sépare les mots, les nombres et la ponctuation, puis applique BPE sur chaque segment. SentencePiece, en revanche, traite le texte brut sans aucune pré-segmentation, ce qui le rend plus naturel pour les langues sans espaces (chinois, japonais, thai). Cette différence explique pourquoi les modèles basés sur SentencePiece tendent à avoir une meilleure couverture multilingue.
WordPiece, utilisé par BERT, est similaire a BPE mais sélectionne les fusions qui maximisent la vraisemblance d’un modèle de langue unigram plutôt que la simple fréquence de paires. La distinction principale réside dans la convention de notation : WordPiece marque les sous-mots en continuation par un préfixe ##, tandis que BPE et SentencePiece marquent le début de mot par un caractère spécial (_).
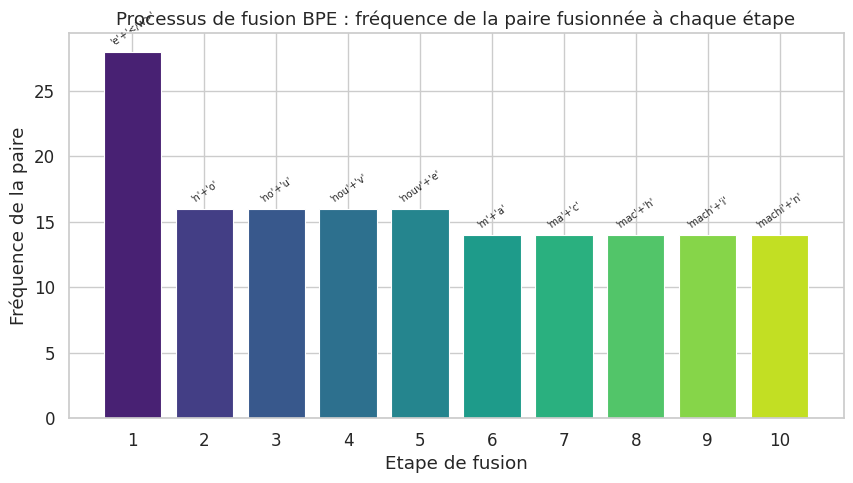
Fusions BPE (10 premières) :
--------------------------------------------------
Etape 1 : 'e' + '</w>' -> 'e</w>' (frequence : 28)
Etape 2 : 'n' + 'o' -> 'no' (frequence : 16)
Etape 3 : 'no' + 'u' -> 'nou' (frequence : 16)
Etape 4 : 'nou' + 'v' -> 'nouv' (frequence : 16)
Etape 5 : 'nouv' + 'e' -> 'nouve' (frequence : 16)
Etape 6 : 'm' + 'a' -> 'ma' (frequence : 14)
Etape 7 : 'ma' + 'c' -> 'mac' (frequence : 14)
Etape 8 : 'mac' + 'h' -> 'mach' (frequence : 14)
Etape 9 : 'mach' + 'i' -> 'machi' (frequence : 14)
Etape 10 : 'machi' + 'n' -> 'machin' (frequence : 14)
Tokenizers des LLM modernes#
Les LLM modernes utilisent tous une tokenisation subword, mais diffèrent par la taille de leur vocabulaire, le choix de l’algorithme et les tokens spéciaux.
Remarque 8
La taille du vocabulaire \(|\mathcal{V}|\) est un compromis fondamental :
Vocabulaire petit (\(|\mathcal{V}| \approx 32\,000\), LLaMA) : les mots sont souvent décomposés en plusieurs tokens, ce qui allonge les séquences et augmente le coût en attention (\(O(T^2)\)). En revanche, la matrice d’embeddings \(E \in \mathbb{R}^{|\mathcal{V}| \times d}\) est plus compacte.
Vocabulaire grand (\(|\mathcal{V}| \approx 100\,000\), Claude) : les mots courants dans de nombreuses langues sont représentés par un seul token, ce qui raccourcit les séquences. La matrice d’embeddings est plus volumineuse, mais le gain en longueur de séquence compense largement.
Modèle |
\(\lvert\mathcal{V}\rvert\) |
Algorithme |
Note |
|---|---|---|---|
GPT-2, GPT-3 |
50 257 |
BPE byte-level |
256 octets + 50 000 fusions + 1 token special |
BERT |
30 522 |
WordPiece |
Vocabulaire anglais-centrique |
LLaMA 2 |
32 000 |
SentencePiece (BPE) |
Optimisé pour l’anglais |
LLaMA 3 |
128 000 |
SentencePiece (BPE) |
Vocabulaire multilingue élargi |
Claude |
~100 000 |
BPE byte-level |
Bon équilibre multilingue |
Mistral |
32 000 |
SentencePiece (BPE) |
Similaire à LLaMA 2 |
Taille du vocabulaire GPT-2 : 50,257 tokens
=== Français (25 tokens) ===
Texte : L'apprentissage automatique transforme notre compréhension de l'intelligence artificielle.
Tokens : ['L', "'", 'app', 'rent', 'iss', 'age', 'Ġautom', 'at', 'ique', 'Ġtransform', 'e', 'Ġnot', 're', 'Ġcompr', 'é', 'hens', 'ion', 'Ġde', 'Ġl', "'", 'intelligence', 'Ġartific', 'iel', 'le', '.']
IDs : [43, 6, 1324, 1156, 747, 496, 3557, 265, 2350, 6121, 68, 407, 260, 12084, 2634, 5135, 295, 390, 300, 6, 32683, 29829, 8207, 293, 13]
=== Anglais (9 tokens) ===
Texte : Machine learning transforms our understanding of artificial intelligence.
Tokens : ['Machine', 'Ġlearning', 'Ġtransforms', 'Ġour', 'Ġunderstanding', 'Ġof', 'Ġartificial', 'Ġintelligence', '.']
IDs : [37573, 4673, 31408, 674, 4547, 286, 11666, 4430, 13]
Ratio français/anglais : 2.78x
Remarque 9
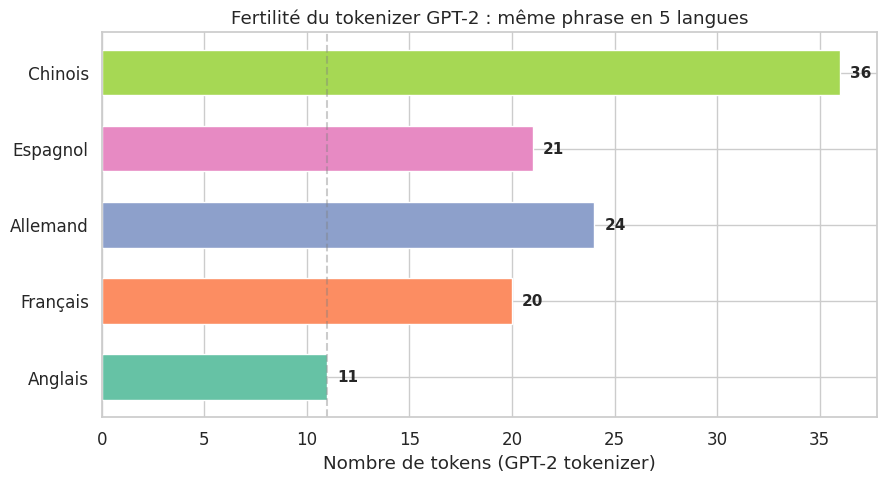
La fertilité (fertility) d’un tokenizer est le nombre moyen de tokens produits par mot. Elle varie considérablement selon la langue : un tokenizer entrainé principalement sur de l’anglais produit typiquement 1.0 à 1.3 tokens par mot en anglais, mais 1.5 à 2.5 tokens par mot en francais, et 3 à 5 tokens par caractère en chinois ou en arabe. Cette asymétrie a des conséquences directes :
Coût : à nombre de tokens facturés identique, un texte français ou chinois coûte plus cher à traiter.
Fenêtre de contexte : le même texte occupe plus de tokens, laissant moins de place pour le contexte.
Qualité : un mot fragmenté en de nombreux sous-tokens est plus difficile à traiter pour le modèle.
Anglais : 11 tokens
Français : 20 tokens
Allemand : 24 tokens
Espagnol : 21 tokens
Chinois : 36 tokens
Exemple 5 (Tokens spéciaux dans les LLM)
Les LLM utilisent des tokens spéciaux qui ne correspondent pas à du texte mais servent à structurer l’entrée et la sortie :
Token |
Rôle |
Modèles |
|---|---|---|
|
Début de séquence (Beginning of Sequence) |
LLaMA, Mistral |
|
Fin de séquence (End of Sequence) |
GPT-2, LLaMA |
|
Remplissage pour aligner les longueurs dans un batch |
BERT, T5 |
|
Token inconnu (rare avec BPE byte-level) |
BERT |
|
Classification et séparation de segments |
BERT |
`< |
endoftext |
>` |
`< |
system |
> |
Exemple avec GPT-2 :
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
texte = "Bonjour le monde"
ids = tokenizer.encode(texte)
# Décoder token par token
for tid in ids:
print(f" ID {tid:6d} -> '{tokenizer.decode([tid])}'")
Token EOS : '<|endoftext|>' (ID: 50256)
Token BOS : '<|endoftext|>' (ID: 50256)
Texte : 'Bonjour le monde' -> IDs : [20682, 73, 454, 443, 285, 14378]
ID 20682 -> 'Bon'
ID 73 -> 'j'
ID 454 -> 'our'
ID 443 -> ' le'
ID 285 -> ' m'
ID 14378 -> 'onde'
Exemple 6 (Tokenisation GPT-2 en détail)
Le tokenizer de GPT-2 utilise un BPE byte-level avec un vocabulaire de 50 257 tokens. Voici comment il segmente différents types de texte :
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# Mot courant en anglais : un seul token
tokenizer.tokenize("hello") # ['hello']
# Mot français avec accent : potentiellement fragmenté
tokenizer.tokenize("reussite") # ['re', 'uss', 'ite']
# Mot rare : fortement decoupé
tokenizer.tokenize("anticonstitutionnellement")
# ['ant', 'icon', 'stit', 'ution', 'n', 'ellement']
Le préfixe G (lettre G avec un espace avant) dans l’affichage des tokens GPT-2 représente un espace. Cela reflète le fait que GPT-2 encode les espaces comme faisant partie du token suivant.
Du token à l’embedding contextuel#
Une fois le texte tokenisé en une séquence d’identifiants \((t_1, \ldots, t_T)\), chaque token est projeté dans un espace vectoriel continu par une matrice d’embeddings \(E \in \mathbb{R}^{|\mathcal{V}| \times d}\). Le vecteur initial \(\mathbf{e}_i = E[t_i]\) est un embedding statique, identique quel que soit le contexte.
Définition 10 (Embedding contextuel)
Un embedding contextuel est une représentation vectorielle d’un token qui dépend de l’ensemble de la séquence dans laquelle il apparait. Formellement, étant donné une séquence de tokens \((t_1, \ldots, t_T)\) et un modèle Transformer à \(L\) couches, l’embedding contextuel du token \(t_i\) à la couche \(l\) est :
avec \(\mathbf{h}_i^{(0)} = E[t_i] + PE_i\) (embedding statique + encodage positionnel). Chaque couche Transformer raffine la représentation en intégrant l’information contextuelle via le mécanisme d’auto-attention. Le même mot « avocat » recevra des représentations différentes dans :
« L”avocat plaide devant le tribunal. » (profession)
« L”avocat est mûr, je vais faire du guacamole. » (fruit)
Contrairement aux embeddings statiques (Word2Vec, GloVe) ou \(\mathbf{v}_{\text{avocat}}\) est un vecteur unique, les embeddings contextuels produisent \(\mathbf{h}_{\text{avocat}}^{(L)}\) différent selon le contexte.
Les embeddings statiques capturent le sens moyen d’un mot sur l’ensemble du corpus, tandis que les embeddings contextuels capturent le sens spécifique dans chaque contexte d’utilisation. Cette distinction est l’une des avancées fondamentales des modèles modernes.
Remarque 10
Pour obtenir une représentation unique d’une séquence entière (une phrase, un paragraphe) à partir des embeddings contextuels des tokens individuels, on utilise une stratégie de pooling :
CLS pooling : prendre le vecteur du token spécial
[CLS]placé en début de séquence (approche de BERT). Ce token est entrainé pour agréger l’information de toute la séquence via l’auto-attention.Mean pooling : calculer la moyenne des embeddings de tous les tokens : \(\mathbf{h}_{\text{phrase}} = \frac{1}{T} \sum_{i=1}^{T} \mathbf{h}_i^{(L)}\). Souvent supérieur au CLS pooling pour les sentence embeddings.
Max pooling : prendre le maximum élément par élément : \((\mathbf{h}_{\text{phrase}})_j = \max_i (\mathbf{h}_i^{(L)})_j\).
Le mean pooling est aujourd’hui la stratégie dominante pour les sentence embeddings, car elle donne un poids égal à tous les tokens de la séquence.
Propriété 2 (Structure de l’espace d’embeddings)
L’espace des embeddings contextuels possède des propriétés géométriques remarquables :
Anisotropie : les embeddings des LLM tendent à occuper un cône étroit dans \(\mathbb{R}^d\), ce qui signifie que la similarité cosinus moyenne entre deux tokens quelconques est souvent élevée (\(\sim 0.5\) a \(0.8\)). Cela peut fausser les recherches par similarité si l’on n’applique pas de normalisation.
Clustering sémantique : les tokens sémantiquement proches forment des clusters. Les couches profondes du Transformer produisent des représentations ou la structure sémantique est plus marquée que les structures syntaxiques.
Linearité des relations : comme pour Word2Vec, certaines relations sémantiques se traduisent par des directions linéaires dans l’espace contextuel.
Sentence embeddings et sentence-transformers#
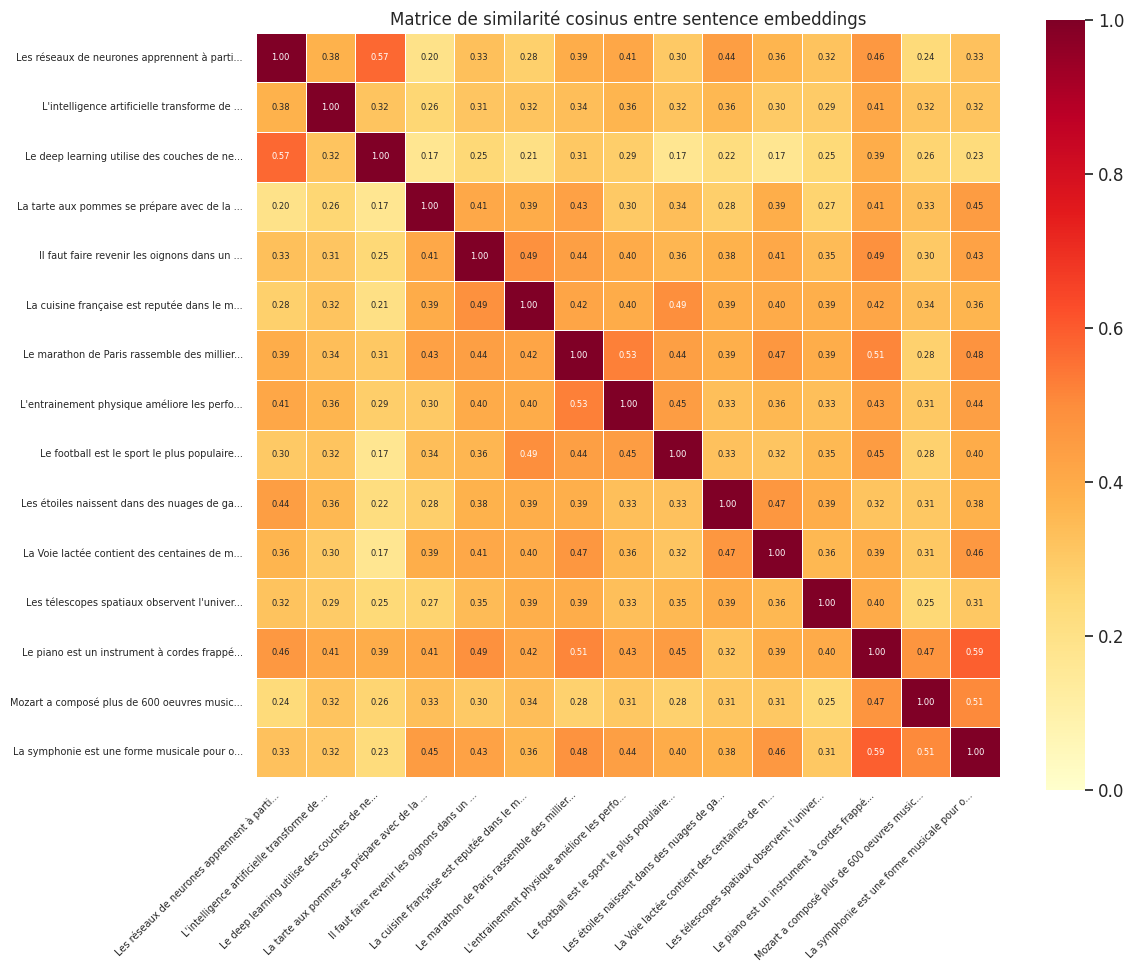
Les embeddings contextuels produits par BERT ou GPT ne sont pas directement utilisables pour comparer des phrases. Le pooling naif des représentations de BERT donne des sentence embeddings de mauvaise qualité : les cosinus entre phrases quelconques sont presque tous dans \([0.6, 1.0]\), rendant la discrimination impossible.
Définition 11 (Sentence embedding)
Un sentence embedding est un vecteur \(\mathbf{s} \in \mathbb{R}^d\) représentant le sens d’une phrase entière dans un espace vectoriel ou la proximité géométrique correspond à la similarité sémantique :
Deux paraphrases ont une similarité proche de 1, deux phrases sans rapport une similarité proche de 0, et des phrases partiellement liées une similarité intermediaire.
Définition 12 (Similarité cosinus)
La similarité cosinus entre deux vecteurs \(\mathbf{a}, \mathbf{b} \in \mathbb{R}^d\) est définie par :
Elle mesure l’angle entre les deux vecteurs, indépendamment de leur norme : \(\cos(\mathbf{a}, \mathbf{b}) \in [-1, 1]\). Une valeur de 1 indique des vecteurs colinéaires (sémantiquement identiques), 0 des vecteurs orthogonaux (sans lien), et \(-1\) des vecteurs opposés. La similarité cosinus est préférée à la distance euclidienne pour les embeddings de haute dimension, car elle est invariante par mise à l’échelle.
Définition 13 (Apprentissage contrastif)
L”apprentissage contrastif (contrastive learning) est le paradigme d’entrainement des sentence embeddings. Le modèle apprend à rapprocher les représentations de phrases similaires (positives) et à éloigner celles de phrases dissimilaires (négatives). La perte typique (Multiple Negatives Ranking Loss) est :
ou \(\mathbf{s}_i^+\) est l’embedding de la phrase positive, \(\tau\) la température, et les autres phrases du batch servent de négatifs. Sentence-BERT (Reimers et Gurevych, 2019) a été le premier modèle à appliquer cette approche à BERT.
Remarque 11
Les sentence embeddings modernes utilisent souvent la technique Matryoshka Representation Learning (MRL), qui entraine le modèle de sorte que les \(k\) premières dimensions de l’embedding (pour tout \(k \leq d\)) soient elles-mêmes un embedding valide de qualité degradée. Cela permet d’adapter dynamiquement la dimension de stockage au budget mémoire. Le modèle all-MiniLM-L6-v2 ne supporte pas MRL, mais des modèles plus récents comme nomic-embed-text-v1.5 l’intègrent.
BertModel LOAD REPORT from: sentence-transformers/all-MiniLM-L6-v2
Key | Status | |
------------------------+------------+--+-
embeddings.position_ids | UNEXPECTED | |
Notes:
- UNEXPECTED :can be ignored when loading from different task/architecture; not ok if you expect identical arch.
Modèle chargé : all-MiniLM-L6-v2
Dimension des embeddings : 384
Forme de la matrice d'embeddings : (15, 384)
-> 15 phrases x 384 dimensions
Exemple 7 (Recherche sémantique par similarité cosinus)
La recherche sémantique consiste à trouver les documents les plus proches d’une requête dans l’espace des embeddings. Contrairement à la recherche lexicale (TF-IDF, BM25), elle ne dépend pas de la présence des mêmes mots dans la requête et le document :
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('all-MiniLM-L6-v2')
corpus = ["Les réseaux de neurones...", "La tarte aux pommes...", ...]
corpus_embeddings = model.encode(corpus)
query = "Comment fonctionne l'apprentissage profond ?"
query_embedding = model.encode(query)
# Trouver les phrases les plus similaires
scores = util.cos_sim(query_embedding, corpus_embeddings)[0]
top_k = scores.argsort(descending=True)[:3]
La requête « Comment fonctionne l’apprentissage profond ? » trouvera les phrases sur les réseaux de neurones et le deep learning, même si elle ne contient aucun de ces mots exacts.
Requête : "Comment fonctionne l'apprentissage profond ?"
1. [0.439] L'entrainement physique améliore les performances sportives.
2. [0.433] Les réseaux de neurones apprennent à partir de données.
3. [0.409] Le marathon de Paris rassemble des milliers de coureurs.
Requête : "Quelle est la recette du gâteau au chocolat ?"
1. [0.536] La Voie lactée contient des centaines de milliards d'étoiles.
2. [0.514] La cuisine française est reputée dans le monde entier.
3. [0.502] Le marathon de Paris rassemble des milliers de coureurs.
Requête : "Combien y a-t-il de planètes dans notre galaxie ?"
1. [0.515] La Voie lactée contient des centaines de milliards d'étoiles.
2. [0.485] Le marathon de Paris rassemble des milliers de coureurs.
3. [0.473] Les télescopes spatiaux observent l'univers lointain.
Visualisation des espaces vectoriels#
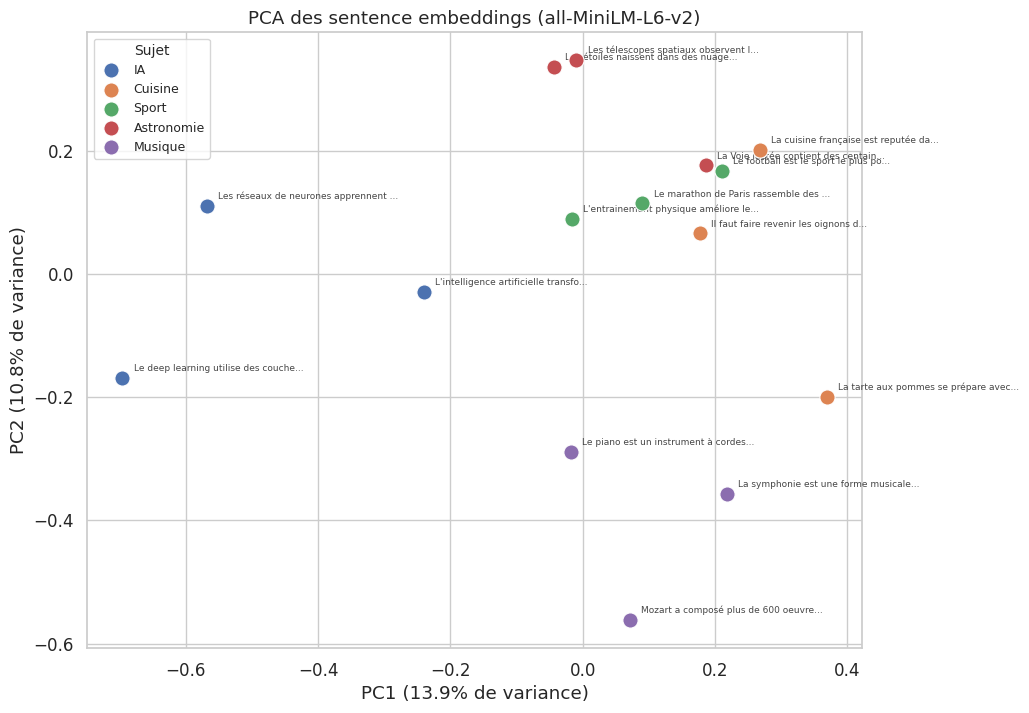
La visualisation des embeddings en deux dimensions permet de vérifier que l’espace vectoriel capture la structure sémantique attendue. Les techniques de réduction de dimensionnalité les plus utilisées sont la PCA (linéaire, préservant les distances globales) et t-SNE ou UMAP (non linéaires, préservant les structures locales).
Exemple 8 (Clustering de sentence embeddings)
Les sentence embeddings peuvent être utilisés directement comme entrée d’un algorithme de clustering (K-Means, DBSCAN, clustering hiérarchique). Cela permet de découvrir automatiquement les thèmes présents dans un corpus, sans aucune annotation manuelle. La qualité du clustering dépend directement de la qualité des embeddings : un bon modèle de sentence embeddings produira des clusters bien separés qui correspondent aux sujets réels.
from sklearn.cluster import KMeans
# Clustering automatique des phrases
kmeans = KMeans(n_clusters=5, random_state=42, n_init=10)
clusters = kmeans.fit_predict(embeddings)
# Chaque cluster correspond approximativement à un sujet
for c in range(5):
print(f"\nCluster {c} :")
for i, phrase in enumerate(phrases):
if clusters[i] == c:
print(f" - {phrase}")
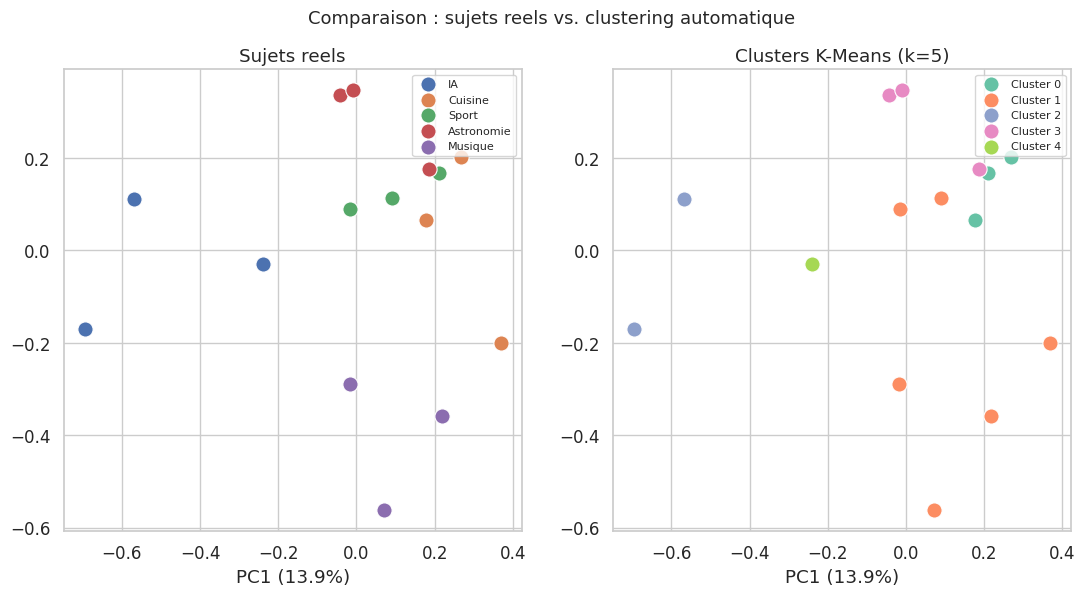
Adjusted Rand Index : 0.381
Résumé#
Ce chapitre a approfondi les deux premières étapes du pipeline de tout LLM : la tokenisation et les embeddings, en allant bien au-delà de l’introduction du chapitre 24 du volume précédent.
La tokenisation subword est l’approche universelle des LLM modernes. Le BPE byte-level (GPT-2/3, Claude) fusionne itérativement les paires d’octets les plus fréquentes, garantissant une couverture universelle de tous les textes. WordPiece (BERT) et SentencePiece (LLaMA, T5, Mistral) offrent des alternatives avec des propriétés multilingues légèrement différentes.
Les vocabulaires des LLM varient de 32 000 (LLaMA 2) a 128 000 tokens (LLaMA 3). La taille du vocabulaire est un compromis entre la compacité des séquences et la taille de la matrice d’embeddings. Les tokens spéciaux (BOS, EOS, PAD, tokens de rôle) structurent l’entrée et la sortie du modèle.
La fertilité d’un tokenizer varie considérablement selon la langue. Un tokenizer entrainé principalement sur de l’anglais pénalise les autres langues en produisant des séquences plus longues, ce qui a des implications en termes de coût, de fenêtre de contexte et de qualité.
Les embeddings contextuels produits par les couches Transformer constituent une avancée fondamentale par rapport aux embeddings statiques (Word2Vec, GloVe). Un même token reçoit des représentations différentes selon son contexte, capturant ainsi la polysémie et les nuances sémantiques.
Les sentence embeddings (Sentence-BERT,
all-MiniLM-L6-v2) permettent de représenter des phrases entières dans un espace vectoriel où la similarité cosinus correspond à la similarité sémantique. Ils sont entrainés par apprentissage contrastif et permettent la recherche sémantique en temps quasi-constant.La visualisation par PCA ou t-SNE/UMAP confirme que les sentence embeddings capturent la structure thématique des textes. Le clustering automatique (K-Means) sur ces embeddings retrouve les sujets sans supervision, ce qui illustre la richesse des représentations apprises.