Utiliser les API#
Les chapitres précédents ont présenté le fonctionnement interne des LLM : l’architecture Transformer, la tokenisation, les stratégies de décodage. Mais en pratique, la majorité des développeurs n’entrainent pas leurs propres modèles — ils les consomment via des API (Application Programming Interfaces). L’API est le point de contact entre un modèle hébergé par un fournisseur (Anthropic, OpenAI, Google, Mistral) et l’application qui l’utilise. Comprendre la structure de ces API, leurs paramètres, leurs coûts et leurs contraintes est indispensable pour construire des systèmes fiables.
Ce chapitre est résolument pratique. Nous examinerons d’abord les arbitrages entre modèles locaux et API distantes, puis nous détaillerons la structure d’un appel API (messages, roles, paramètres). Nous comparerons ensuite les API d’Anthropic (Claude) et d’OpenAI (GPT), avant d’aborder le streaming, la gestion de la fenêtre de contexte, et l’optimisation des coûts.
Tous les exemples d’appels API sont présentés sous forme de blocs de code non exécutables : ils nécessitent des clés d’API qui ne sont pas disponibles dans cet environnement de build. Les cellules exécutables sont réservées aux calculs locaux — comptage de tokens, estimations de coûts, visualisations.
Pourquoi les API ?#
Un LLM peut être deployé de deux facons : localement (le modèle tourne sur votre propre infrastructure) ou via une API distante (le modèle tourne sur les serveurs du fournisseur). Chaque approche présente des compromis distincts.
Définition 20 (API de LLM)
Une API de LLM est une interface de programmation qui permet d’envoyer des requêtes textuelles (prompts) à un modèle de langage hébergé à distance et de recevoir des réponses générées. L’interaction se fait généralement par requêtes HTTP (REST) ou via des bibliothèques clientes officielles. L’utilisateur paie à l’usage (par token) sans gérer l’infrastructure sous-jacente.
Les principaux critères de choix entre une approche locale et une approche API sont les suivants :
Critère |
Modèle local |
API distante |
|---|---|---|
Coût initial |
Elevé (GPU, infrastructure) |
Nul (pay-per-use) |
Coût marginal |
Faible (électricité, maintenance) |
Proportionnel au volume |
Latence |
Variable (dépend du hardware) |
Faible et stable |
Capacités |
Limitées par le modèle choisi |
Accès aux meilleurs modèles |
Confidentialité |
Données restent en local |
Données transitent par le fournisseur |
Maintenance |
A votre charge |
Gérée par le fournisseur |
Personnalisation |
Fine-tuning complet possible |
Fine-tuning limité ou absent |
Remarque 19
Le choix entre local et API n’est pas binaire. De nombreux systèmes de production combinent les deux : un modèle local léger pour les tâches simples et peu sensibles (classification, extraction), et une API vers un modèle frontier pour les tâches complexes (raisonnement, génération longue). Cette architecture hybride optimise le rapport coût/performance tout en préservant la confidentialité là où c’est nécessaire.
Remarque 20
Les clés d’API sont des secrets d’authentification qui donnent accès à des ressources facturées. Elles ne doivent jamais être écrites en dur dans le code source ni commitées dans un dépôt Git. Les bonnes pratiques incluent : variables d’environnement (ANTHROPIC_API_KEY), fichiers .env exclus du versioning, ou gestionnaires de secrets (AWS Secrets Manager, HashiCorp Vault). Une clé exposée peut entrainer des coûts non autorisés et des fuites de données.
Structure d’un appel API#
Malgré les différences entre fournisseurs, tous les appels API de LLM partagent une structure commune : un format de messages organisé par rôles, un choix de modèle, et un ensemble de paramètres de génération.
Le format de messages#
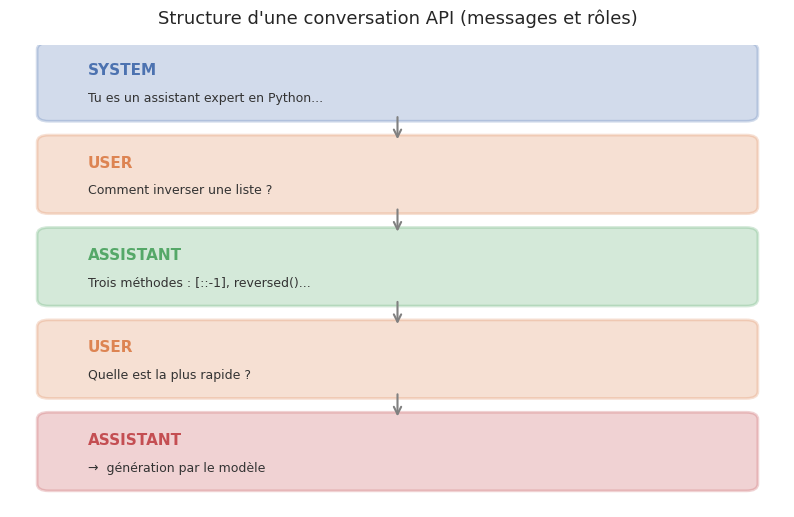
Les API modernes utilisent un format conversationnel structuré en messages. Chaque message a un rôle et un contenu.
Définition 21 (System prompt)
Le system prompt (ou message système) est une instruction de haut niveau envoyée au modèe avant la conversation. Il définit le comportement, le ton, les contraintes et le rôle du modèle. Il n’est pas visible pour l’utilisateur final dans les interfaces conversationnelles, mais il influence toute la génération subséquente. Le system prompt est le principal levier de cadrage d’un LLM via API.
Les trois rôles standard sont :
system: instructions globales qui cadrent le comportement du modèle (ton, expertise, contraintes, format de sortie).user: messages de l’utilisateur (questions, demandes, documents à analyser).assistant: réponses du modèle, ou réponses partielles pré-remplies pour guider la génération (prefilling).
[
{
"role": "system",
"content": "Tu es un assistant expert en Python. Reponds de façon concise."
},
{
"role": "user",
"content": "Comment inverser une liste en Python ?"
},
{
"role": "assistant",
"content": "Trois méthodes principales :\n1. `liste[::-1]` (copie inversée)\n2. `list(reversed(liste))` (iterateur inverse)\n3. `liste.reverse()` (inversion in-place)"
},
{
"role": "user",
"content": "Quelle est la plus rapide ?"
}
]
Paramètres de génération#
Les paramètres principaux contrôlent le comportement du modèle :
Paramètre |
Description |
Valeurs typiques |
|---|---|---|
|
Identifiant du modèle |
|
|
Nombre maximal de tokens générés |
256 – 4096 |
|
Contrôle l’aléatoire (0 = déterministe) |
0.0 – 1.0 |
|
Echantillonnage par noyau (nucleus sampling) |
0.9 – 1.0 |
|
Séquences déclenchant l’arrêt de la génération |
|
Remarque 21
De nombreuses API proposent désormais des modes de sortie structurée : JSON mode, schémas JSON, grammaires formelles. Ces modes contraignent le décodage pour garantir que la sortie respecte un format precis. Chez Anthropic, on utilise le prefilling (commencer la réponse de l’assistant par {) combine à stop_sequences: ["}"] ; chez OpenAI, le paramètre response_format avec un schéma JSON. Ces mécanismes sont essentiels pour les pipelines automatisés.
L’API Anthropic (Claude)#
L’API d’Anthropic utilise le endpoint Messages (/v1/messages). La bibliothèque Python officielle anthropic encapsule les appels HTTP.
Exemple 12 (Appel simple à l’API Claude)
import anthropic
client = anthropic.Anthropic() # clé via ANTHROPIC_API_KEY
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
system="Tu es un assistant pédagogique en informatique.",
messages=[
{"role": "user", "content": "Explique la différence entre une pile et une file."}
]
)
print(message.content[0].text)
print(f"Tokens utilisés : {message.usage.input_tokens} in, {message.usage.output_tokens} out")
Points clés de l’API Anthropic :
Le system prompt est un paramètre séparé (pas un message dans la liste).
La réponse est un objet
Messagecontenant une liste decontentblocks (texte, outil, image).L’objet
usagefournit le décompte exact des tokens consommés.Les modèles disponibles incluent Claude Opus, Sonnet et Haiku, avec des compromis performance/coût différents.
L’API Claude supporte également l’utilisation d’outils (tool use / function calling), permettant au modèle d’appeler des fonctions externes définies par le développeur. Ce mécanisme est fondamental pour la construction d’agents (chapitres 12 a 15).
Exemple 13 (Utilisation d’outils avec Claude)
import anthropic
client = anthropic.Anthropic()
# Définition d'un outil
tools = [
{
"name": "get_weather",
"description": "Obtient la météo actuelle pour une ville donnée.",
"input_schema": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "Nom de la ville"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["city"]
}
}
]
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
tools=tools,
messages=[{"role": "user", "content": "Quel temps fait-il à Paris ?"}]
)
# Le modèle peut répondre avec un bloc tool_use
for block in response.content:
if block.type == "tool_use":
print(f"Outil appele : {block.name}")
print(f"Arguments : {json.dumps(block.input, indent=2)}")
Lorsque le modèle décide d’utiliser un outil, il retourne un bloc tool_use avec le nom de l’outil et les arguments structurés. Le développeur exécute l’outil, puis renvoie le résultat dans un message tool_result pour que le modèle formule sa réponse finale.
L’API OpenAI#
L’API d’OpenAI utilise le endpoint Chat Completions (/v1/chat/completions). La structure est similaire à celle d’Anthropic, avec quelques différences notables.
Exemple 14 (Appel simple à l’API OpenAI)
from openai import OpenAI
client = OpenAI() # clé via OPENAI_API_KEY
response = client.chat.completions.create(
model="gpt-4o",
max_tokens=1024,
messages=[
{"role": "system", "content": "Tu es un assistant pédagogique en informatique."},
{"role": "user", "content": "Explique la différence entre une pile et une file."}
]
)
print(response.choices[0].message.content)
print(f"Tokens : {response.usage.prompt_tokens} in, {response.usage.completion_tokens} out")
Différences clés avec l’API Anthropic :
Le system prompt est un message dans la liste (rôle
system), pas un paramètre séparé.La réponse contient une liste de
choices(utile pourn > 1).Les noms de champs diffèrent :
prompt_tokensvsinput_tokens,completion_tokensvsoutput_tokens.Le format de retour est un objet
ChatCompletion, pas un objetMessage.
Aspect |
Anthropic (Claude) |
OpenAI (GPT) |
|---|---|---|
System prompt |
Paramètre séparé |
Message rôle |
Réponse |
|
|
Tokens entrée |
|
|
Tokens sortie |
|
|
Outils |
|
|
Streaming |
|
|
Streaming et latence#
Par défaut, un appel API attend que la génération soit terminée avant de retourner la réponse complète. Le streaming permet de recevoir les tokens au fur et à mesure de leur génération, réduisant le temps de première réponse perçu par l’utilisateur.
Exemple 15 (Streaming avec l’API Claude)
import anthropic
client = anthropic.Anthropic()
# Streaming : les tokens arrivent un par un
with client.messages.stream(
model="claude-sonnet-4-20250514",
max_tokens=512,
messages=[{"role": "user", "content": "Raconte une courte histoire."}]
) as stream:
for text in stream.text_stream:
print(text, end="", flush=True)
print() # retour à la ligne final
Le streaming utilise les Server-Sent Events (SSE) : le serveur envoie des évènements incrémentaux sur une connexion HTTP persistante. Chaque évènement contient un ou plusieurs tokens générés. Côté client, la bibliothèque gère la connexion et expose un itérateur.
Deux métriques de latence sont à distinguer :
Time-to-first-token (TTFT) : temps entre l’envoi de la requête et la reception du premier token. Dépend principalement du temps de prefill (traitement du prompt). Avec streaming, l’utilisateur voit la réponse commencer après ce delai.
Latence totale : temps entre l’envoi de la requête et la réception du dernier token. Proportionnelle au nombre de tokens générés.
Remarque 22
Le streaming n’est pas qu’une optimisation technique — c’est un choix d”expérience utilisateur. Un modèle qui affiche sa réponse token par token donne une impression de réactivité, même si la latence totale est identique à un appel non-streame. Pour les applications intéractives (chatbots, assistants de code), le streaming est quasi systématique. Pour les pipelines automatisés (classification, extraction), il est inutile et ajoute de la complexité au parsing de la réponse.
Remarque 23
Les API imposent des limites de débit (rate limits) exprimées en requêtes par minute (RPM) et en tokens par minute (TPM). Dépasser ces limites retourne une erreur HTTP 429. Les stratégies de gestion incluent : le backoff exponentiel (attendre un délai croissant avant de réessayer), les files d’attente avec contrôle de concurrence, et la répartition entre plusieurs clés ou fournisseurs. La bibliothèque anthropic gère automatiquement les retries avec backoff.
Gestion de la fenêtre de contexte#
Définition 22 (Fenêtre de contexte)
La fenêtre de contexte (context window) d’un LLM est le nombre maximal de tokens que le modèle peut traiter en une seule requête (prompt + réponse). Elle détermine la quantité d’information que le modèle peut « voir » simultanément. Au-delà de cette limite, les tokens les plus anciens sont tronqués ou la requête est rejetée.
Les tailles de fenêtre de contexte varient considérablement selon les modèles :
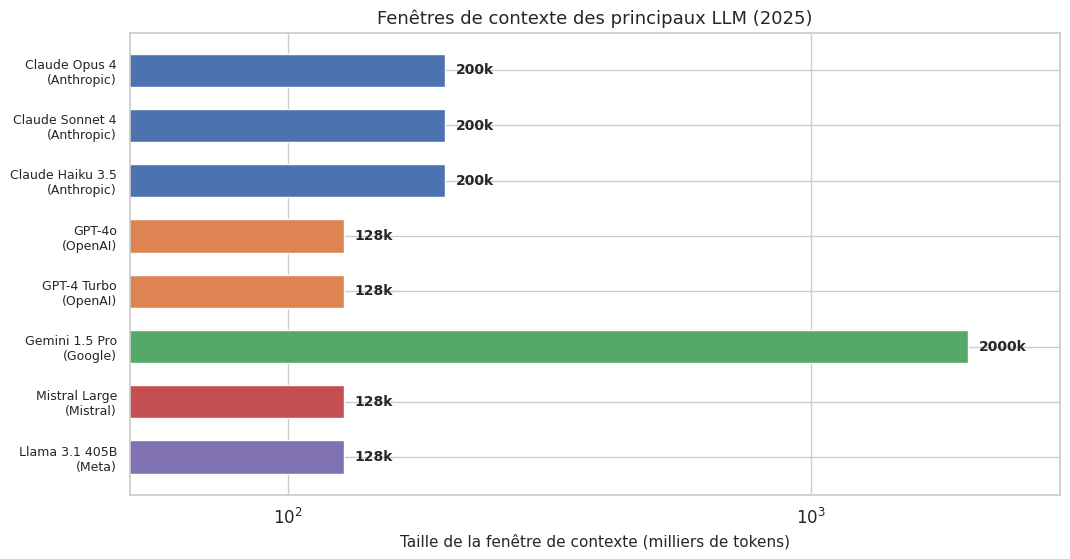
Propriété 5 (Mise à l’échelle de la fenêtre de contexte)
L’augmentation de la fenêtre de contexte n’est pas gratuite. L’auto-attention standard a une complexité en \(O(n^2)\) par rapport à la longueur de la séquence \(n\). Une fenêtre de 200k tokens requiert donc environ \((200/8)^2 = 625\) fois plus de calcul d’attention qu’une fenêtre de 8k tokens. Les fournisseurs utilisent des techniques d’attention optimisée (FlashAttention, attention à fenêtre glissante, KV-cache) pour rendre ces longues fenêtres praticables, mais le coût et la latence augmentent néanmoins avec la longueur du contexte.
Comptage de tokens#
Définition 23 (Comptage de tokens)
Le comptage de tokens consiste à déterminer le nombre de tokens que le tokeniseur d’un modèle donné produit pour un texte donné. C’est une étape cruciale pour : (1) vérifier que le prompt tient dans la fenêtre de contexte, (2) estimer le coût d’un appel, (3) gérer le budget de tokens entre system prompt, historique et réponse.
La bibliothèque tiktoken (OpenAI) permet de compter les tokens pour les modèles GPT. Pour les modèles Claude, Anthropic fournit un endpoint de comptage et la méthode client.count_tokens().
Texte GPT-4o GPT-3.5
------------------------------------------------------------------------------------------
Bonjour, comment allez-vous ? 6 7
L'apprentissage automatique est une branche de l'intelligence art... 14 20
def fibonacci(n):
if n <= 1:
return n
return fibo... 28 28
The quick brown fox jumps over the lazy dog. 10 10
Texte original : L'intelligence artificielle transforme notre quotidien.
Nombre de tokens (GPT-4o) : 9
Tokens : ['L', "'int", 'elligence', ' artific', 'ielle', ' transforme', ' notre', ' quotidien', '.']
IDs : [43, 37062, 33465, 105453, 22380, 184109, 12092, 59486, 13]
Exemple 16 (Budget de tokens dans une conversation)
Considérons une fenêtre de contexte de 200 000 tokens et la répartition suivante :
System prompt : ~500 tokens (instructions, persona, contraintes)
Réponse maximale (
max_tokens) : 4 096 tokensBudget restant pour l’historique : \(200\,000 - 500 - 4\,096 = 195\,404\) tokens
Avec une moyenne de ~150 tokens par message (utilisateur + assistant), cela permet environ 1 300 échanges dans une seule conversation. En pratique, les conversations atteignent rarement cette limite, mais les applications de type RAG (chapitre 10) qui injectent de longs documents dans le contexte la consomment rapidement.
# Calcul du budget de tokens
context_window = 200_000
system_tokens = 500
max_output = 4_096
budget_historique = context_window - system_tokens - max_output
tokens_par_echange = 150 # moyenne user + assistant
max_echanges = budget_historique // tokens_par_echange
print(f"Budget historique : {budget_historique:,} tokens")
print(f"Echanges max : ~{max_echanges}")
Modèle Budget Echanges max
----------------------------------------------------------
Claude (200k) 195,404 1,302
GPT-4o (128k) 123,404 822
Mistral Large (128k) 123,404 822
Gemini 1.5 Pro (2M) 1,991,308 13,275
Lorsque la fenêtre de contexte est insuffisante, plusieurs stratégies sont possibles :
Troncation : supprimer les messages les plus anciens de l’historique. Simple mais perd du contexte.
Résumé : utiliser le LLM pour résumer périodiquement l’historique, puis remplacer les messages anciens par le résumé.
RAG : ne pas stocker tout le contexte dans la fenêtre, mais le récupérer dynamiquement depuis une base de connaissances (chapitre 10).
Fenêtre glissante : conserver les \(k\) derniers échanges. Combiné avec un résumé des échanges précédents.
Remarque 24
En pratique, la gestion du contexte est l’un des défis majeurs des applications LLM en production. Le system prompt doit être aussi court que possible tout en restant précis. Les documents injectés (dans un pipeline RAG) doivent être décomposés en morceaux (chunks) de taille appropriée — trop petits, ils perdent le contexte local ; trop grands, ils saturent la fenêtre. L’ajout de metadata (source, date, score de pertinence) consomme aussi des tokens. Un budget de tokens bien géré est souvent la différence entre un prototype et un produit fiable.
Coûts et optimisation#
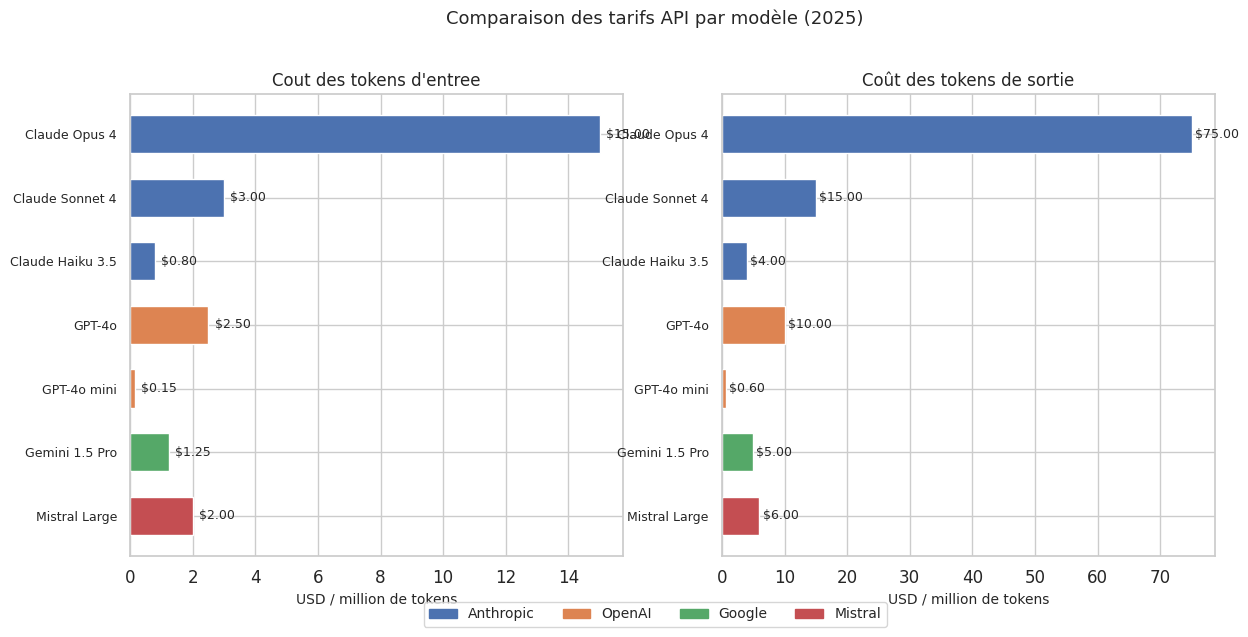
L’utilisation d’API de LLM est facturée par token, avec des tarifs différents pour les tokens d”entrée (prompt) et de sortie (génération). La sortie est généralement 3 à 5 fois plus coûteuse que l’entrée.
Remarque 25
L’estimation des coûts est critique pour la viabilité d’un projet. Un chatbot traitant 10 000 conversations par jour, avec 2 000 tokens par conversation (entrée + sortie), consomme 20 millions de tokens par jour. A 3 $/million de tokens en entrée et 15 $/million en sortie (tarifs Claude Sonnet), cela représente un budget significatif. L’optimisation passe par le choix du modèle adapté (Haiku pour les tâches simples, Sonnet pour les tâches moyennes, Opus pour les tâches complexes), la réduction de la longueur des prompts, et l’utilisation du prompt caching.
Modèle : Claude Sonnet 4
Tokens : 1500 in + 500 out
Coût : $0.012000
- Entrée : $0.004500
- Sortie : $0.007500
Prompt caching#
Le prompt caching est une optimisation proposée par Anthropic et OpenAI qui permet de réutiliser le traitement (prefill) d’un préfixe de prompt identique entre plusieurs requêtes. Lorsque le début du prompt est identique (system prompt, instructions longues, documents injectés), le fournisseur met en cache les représentations internes, réduisant à la fois la latence et le coût.
Chez Anthropic, le prompt caching réduit le coût des tokens cachés de 90 % et le TTFT de manière significative. C’est particulièrement avantageux pour les applications RAG où le même document est interrogé plusieurs fois.
Remarque 26
Le prompt caching est particulièrement efficace lorsqu’un préfixe long et stable est réutilisé entre les requêtes. Cas d’usage typiques : (1) un system prompt détaillé avec des instructions complexes, (2) un document injecté pour du RAG, interrogé par plusieurs utilisateurs, (3) un contexte de few-shot avec de nombreux exemples. Le cache a une durée de vie limitée (5 minutes chez Anthropic, variable chez OpenAI) et n’est pas garanti — il faut concevoir l’application pour fonctionner correctement avec ou sans cache.
Batch API#
Les API batch permettent d’envoyer un lot de requêtes à traiter de manière asynchrone, avec un tarif réduit (typiquement 50 % de réduction). Le temps de traitement est plus long (jusqu’à 24 heures), mais le coût par token est considérablement réduit. Cette approche convient aux taches non intéractives : évaluation de datasets, génération massive de contenu, classification en lot.
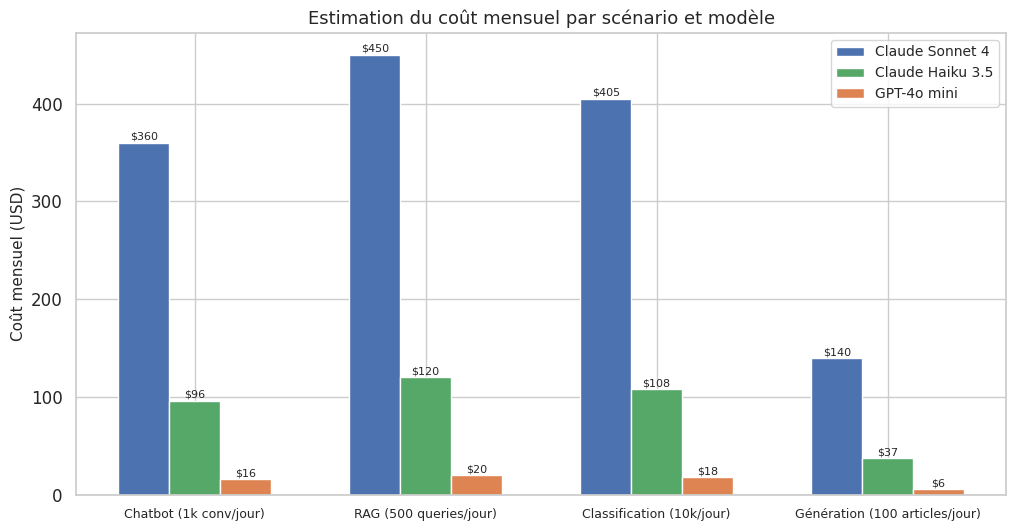
Scenario Tokens/mois Sonnet Haiku GPT-4o mini
------------------------------------------------------------------------------------------
Chatbot (1k conv/jour) 60,000,000 $ 360.00 $ 96.00 $ 15.75
RAG (500 queries/jour) 90,000,000 $ 450.00 $ 120.00 $ 20.25
Classification (10k/jour) 75,000,000 $ 405.00 $ 108.00 $ 18.00
Génération (100 articles/jour) 10,500,000 $ 139.50 $ 37.20 $ 5.62
Résumé#
Ce chapitre a presenté les aspects pratiques de l’utilisation des API de LLM, depuis les arbitrages fondamentaux jusqu’à l’optimisation des coûts.
Les API distantes offrent un accès immédiat aux modèles les plus performants sans gérer l’infrastructure, tandis que les modèles locaux préservent la confidentialité et permettent un contrôle total. Les architectures hybrides combinent souvent les deux.
La structure d’un appel API repose sur un format de messages avec trois rôles (
system,user,assistant) et des paramètres de génération (temperature,max_tokens,top_p,stop). Le system prompt est le principal levier de cadrage du comportement du modèle.L”API Anthropic (Claude) et l”API OpenAI (GPT) partagent une logique commune mais diffèrent dans les détails : position du system prompt, structure de la réponse, nommage des champs. Les deux supportent le tool use et le streaming.
Le streaming réduit le temps perçu de première réponse en transmettant les tokens au fur et à mesure de leur génération via Server-Sent Events. La distinction entre TTFT et latence totale est essentielle pour l’expérience utilisateur.
La fenêtre de contexte détermine la quantité d’information accessible au modèle en une seule requête. Sa gestion — troncation, résumé, RAG, fenêtre glissante — est un enjeu central des applications conversationnelles et documentaires.
Les coûts sont facturés par token, avec des tarifs différenciés entre entrée et sortie. Le choix du modèle adapté à la tache, le prompt caching, les API batch et la réduction de la longueur des prompts sont les principaux leviers d’optimisation.
La sécurité des clés d’API et la gestion des limites de débit (rate limiting) sont des prérequis pour tout déploiement en production. Les bibliothèques clientes officielles fournissent des mécanismes de retry et de backoff automatiques.
Le chapitre suivant abordera le prompt engineering (chapitre 5), ou nous verrons comment rédiger des prompts efficaces pour tirer le meilleur parti de ces API.