Fine-tuning efficace#
Les chapitres précédents ont montré comment utiliser les LLM via des API, structurer des prompts et orchestrer des agents. Mais que faire lorsque le modèle ne répond pas correctement à une tâche spécifique, malgrè un prompt optimisé ? La réponse classique est le fine-tuning : reprendre l’entrainement du modèle sur un jeu de données spécialisé. Le problème est que le fine-tuning complet d’un modèle de plusieurs milliards de paramètres exige une infrastructure coûteuse — des dizaines de GPU, des centaines de gigaoctets de mémoire, des jours de calcul.
Le fine-tuning efficace (parameter-efficient fine-tuning, PEFT) résout ce problème en ne modifiant qu’une fraction infime des paramètres du modèle. L’idée centrale, formalisée par la méthode LoRA (Hu et al., 2021), est que les mises à jour de poids nécessaires pour adapter un LLM à une tâche donnée vivent dans un sous-espace de faible dimension. Au lieu de modifier les \(d \times d\) paramètres d’une matrice de poids, on apprend deux petites matrices de rang \(r \ll d\) dont le produit approxime la mise à jour. Le résultat : 99 % des paramètres restent gelés, la mémoire requise chute de manière spectaculaire, et l’entrainement peut se faire sur un seul GPU grand public.
Ce chapitre présente les méthodes PEFT de manière à la fois théorique et pratique. Nous formaliserons LoRA et ses variantes, comparerons les différentes approches de fine-tuning efficace, puis réaliserons un fine-tuning complet de GPT-2 (124M parametres) avec la bibliothèque peft de Hugging Face — le tout exécutable sur une machine à 8 Go de RAM.
Pourquoi le fine-tuning efficace ?#
Le fine-tuning classique (full fine-tuning) consiste à reprendre l’entrainement de tous les paramètres d’un modèle pré-entrainé sur un jeu de données spécifique à la tâche cible. Pour un modèle de \(N\) paramètres, cela implique de stocker en mémoire les \(N\) poids du modèle, les \(N\) gradients correspondants, et l’état de l’optimiseur (pour Adam, \(2N\) valeurs supplémentaires : les moyennes mobiles du premier et du second ordre). Le coût mémoire total est donc d’environ \(16N\) octets en précision mixte (FP16 pour les poids et gradients, FP32 pour l’état de l’optimiseur).
Définition 107 (Fine-tuning complet)
Le fine-tuning complet (full fine-tuning) d’un modèle pré-entrainé de paramètres \(\theta \in \mathbb{R}^N\) consiste à minimiser une fonction de perte \(\mathcal{L}\) sur un jeu de données \(\mathcal{D}_{\text{task}}\) en mettant à jour tous les paramètres :
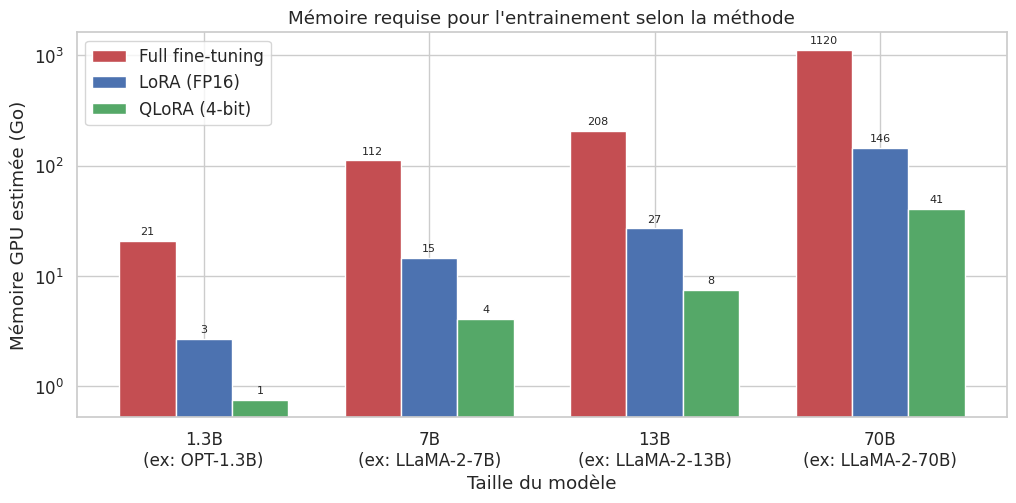
Le coût mémoire d’entrainement est d’environ \(16N\) octets (poids FP16 + gradients FP16 + etats d’optimiseur FP32), auxquels s’ajoutent les activations intermédiaires. Pour un modèle de 7 milliards de paramètres, cela représente environ 112 Go de mémoire GPU — bien au-delà de la capacité d’un GPU grand public.
Pour un modèle de 7B parametres, le full fine-tuning nécessite environ 112 Go de VRAM, soit au minimum deux GPU A100 de 80 Go. Pour un modèle de 70B, il faut un cluster entier. Cette barrière économique a motivé le développement des méthodes PEFT.
Définition 108 (Fine-tuning efficace en paramètres (PEFT))
Le fine-tuning efficace en paramètres (Parameter-Efficient Fine-Tuning, PEFT) désigne une famille de méthodes qui adaptent un modèle pré-entrainé à une tache spécifique en n’entrainant qu’un petit nombre de paramètres \(\phi\), avec \(|\phi| \ll N\). Le modèle pré-entrainé \(\theta_0\) reste gelé (frozen) et seuls les paramètres \(\phi\) sont mis à jour :
Le ratio \(|\phi| / N\) est typiquement de l’ordre de 0,1 % à 1 %, ce qui réduit la mémoire nécessaire d’un à deux ordres de grandeur par rapport au fine-tuning complet.
Remarque 102 (Full fine-tuning vs PEFT : compromis)
Le fine-tuning complet donne en théorie les meilleurs résultats, puisque l’espace de recherche est maximal. En pratique, cependant, les methodes PEFT atteignent souvent des performances comparables, voire supérieures, au full fine-tuning. Ce paradoxe apparent s’explique par deux facteurs : (1) le fine-tuning complet sur un petit jeu de données risque le surapprentissage (overfitting), tandis que les méthodes PEFT agissent comme un régularisateur implicite en restreignant l’espace des mises à jour ; (2) les mises à jour nécessaires pour adapter un LLM pré-entrainé à une tâche spécifique sont effectivement de faible rang — elles n’exploitent qu’un petit sous-espace de l’espace des paramètres.
LoRA : Low-Rank Adaptation#
LoRA (Low-Rank Adaptation), proposé par Hu et al. (2021), est la méthode PEFT la plus influente et la plus utilisée. Son principe repose sur une observation empirique fondamentale : les mises à jour de poids nécessaires pour adapter un LLM pré-entrainé ont un rang intrinsèque faible. Autrement dit, la matrice \(\Delta W\) qui représente la différence entre les poids adaptés et les poids originaux peut être bien approximée par un produit de deux matrices de faible rang.
Définition 109 (LoRA (Low-Rank Adaptation))
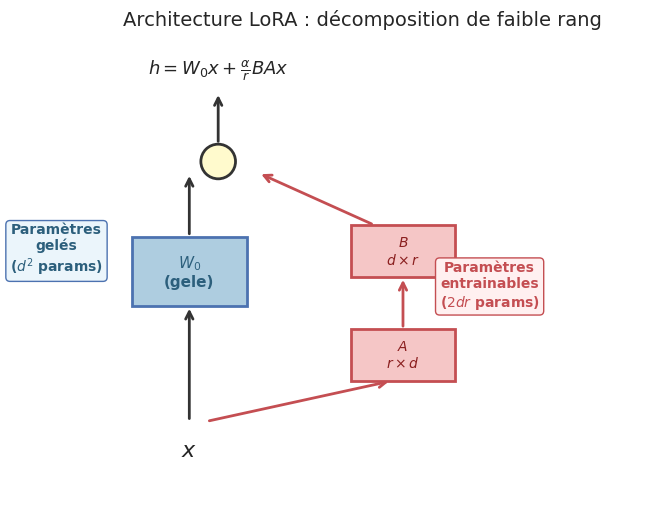
Soit \(W_0 \in \mathbb{R}^{d_{\text{out}} \times d_{\text{in}}}\) une matrice de poids pré-entrainée (par exemple, une projection \(W_Q\), \(W_K\), \(W_V\) ou \(W_O\) dans un bloc d’attention). LoRA remplace la mise à jour de \(W_0\) par une décomposition de faible rang :
où \(B \in \mathbb{R}^{d_{\text{out}} \times r}\) et \(A \in \mathbb{R}^{r \times d_{\text{in}}}\), avec \(r \ll \min(d_{\text{out}}, d_{\text{in}})\). Les poids originaux \(W_0\) sont gelés (pas de gradient). Seuls \(B\) et \(A\) sont entrainés. L’initialisation est \(A \sim \mathcal{N}(0, \sigma^2)\) et \(B = 0\), de sorte que \(\Delta W = 0\) au debut de l’entrainement. Le passage avant devient :
où \(\alpha\) est un facteur d’échelle (typiquement \(\alpha = r\) ou \(\alpha = 2r\)).
Propriété 24 (Nombre de paramètres entrainables de LoRA)
Pour une matrice de poids \(W_0 \in \mathbb{R}^{d_{\text{out}} \times d_{\text{in}}}\), LoRA introduit \(r \times (d_{\text{out}} + d_{\text{in}})\) paramètres entrainables. Pour un Transformer avec \(L\) couches et LoRA appliqué aux projections \(W_Q\) et \(W_V\) de dimension \(d \times d\), le nombre total de paramètres entrainables est :
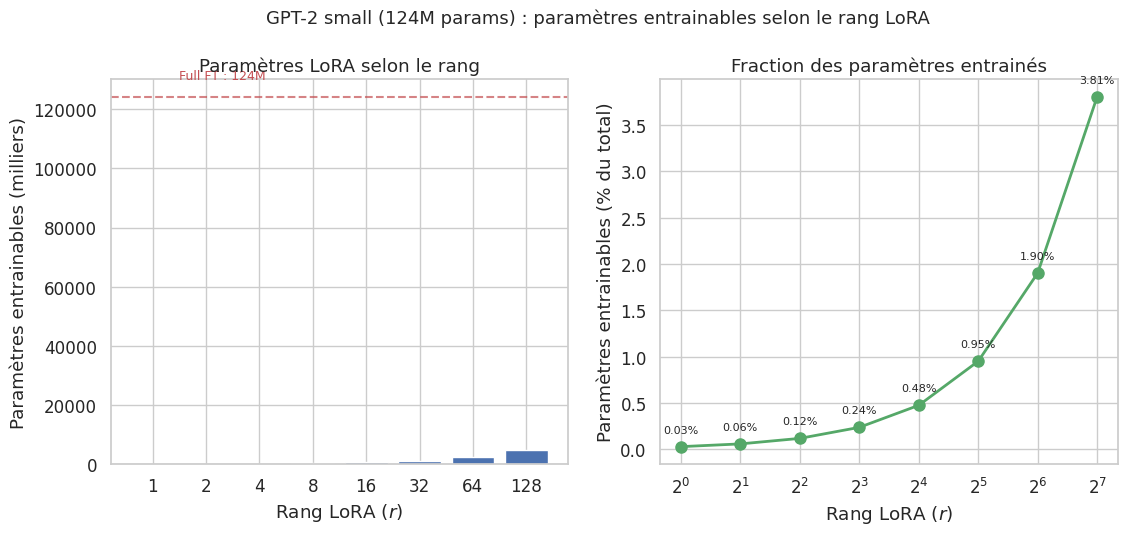
Pour GPT-2 small (\(L = 12\), \(d = 768\), \(r = 8\)), cela donne \(|\phi| = 4 \times 12 \times 768 \times 8 = 294\,912\) paramètres, soit 0,24 % des 124 millions de paramètres totaux.
Remarque 103 (Le rang r : un hyperparamètre central)
Le rang \(r\) est le principal hyperparamètre de LoRA. Un rang trop faible limite la capacité d’adaptation du modèle ; un rang trop élevé augmente le nombre de paramètres sans gain proportionnel et risque le surapprentissage. En pratique, \(r \in \{4, 8, 16, 32, 64\}\) couvre la plupart des scénarios. Hu et al. (2021) ont montré que pour de nombreuses tâches, \(r = 4\) ou \(r = 8\) suffisent, confirmant que les mises à jour de poids vivent effectivement dans un sous-espace de très faible dimension.
Propriété 25 (Compromis rang-performance)
La relation entre le rang \(r\) et la performance suit généralement une courbe à rendements décroissants :
Pour \(r = 1\) a \(r = 4\) : gain rapide de performance.
Pour \(r = 4\) a \(r = 16\) : gain marginal décroissant.
Pour \(r > 16\) : plateau, voire dégradation par surapprentissage sur de petits jeux de données.
Ce comportement est cohérent avec l’hypothèse du faible rang intrinsèque : les premières composantes principales de \(\Delta W\) capturent l’essentiel de l’adaptation, et les composantes supplémentaires n’ajoutent que du bruit.
Remarque 104 (Le facteur d’échelle alpha)
Le facteur \(\alpha\) dans LoRA contrôle l’amplitude de la mise à jour \(\Delta W\). Le ratio \(\alpha / r\) agit comme un taux d’apprentissage effectif pour les paramètres LoRA. En pratique, on fixe souvent \(\alpha = r\) (ratio de 1) ou \(\alpha = 2r\) (ratio de 2). Lorsqu’on augmente le rang \(r\), il est courant de garder \(\alpha\) constant (par exemple \(\alpha = 16\)), ce qui diminue automatiquement l’amplitude relative de chaque composante. Cette convention simplifie le réglage des hyperparamètres : le taux d’apprentissage reste stable indépendamment du rang choisi.
Implémentons LoRA from scratch pour comprendre le mécanisme en détail.
Dimension : 768 x 768
Rang LoRA : r = 8
Paramètres totaux : 602,112
Paramètres gelés : 589,824 (97.96%)
Paramètres entrainés : 12,288 (2.04%)
Ratio de compression : 49.0x
Différence max entre sortie base et sortie LoRA (début) : 0.0
=> LoRA n'altère pas le modèle au début de l'entrainement.
Exemple 75 (Calcul du nombre de paramètres LoRA)
Considérons un modèle de type LLaMA-7B avec \(L = 32\) couches, \(d_{\text{model}} = 4096\), et LoRA applique aux matrices \(W_Q\) et \(W_V\) avec un rang \(r = 16\). Le nombre de paramètres entrainables est :
Le modele complet a environ 6,7 milliards de paramètres. Le ratio est donc :
On entraine donc \(800\times\) moins de paramètres qu’avec le fine-tuning complet. En mémoire, cela passe d’environ 112 Go (full FT) a environ 16 Go (poids FP16 gelés + LoRA entrainable), ce qui tient sur un seul GPU A100-40G ou meme un GPU grand public avec QLoRA.
Remarque 105 (Economies de mémoire)
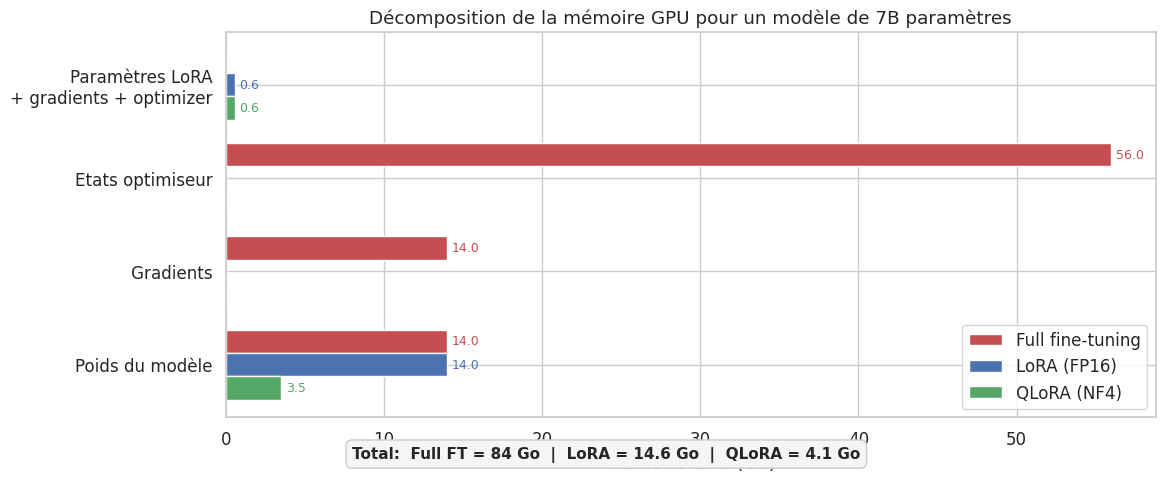
L’économie de mémoire de LoRA ne vient pas uniquement du nombre réduit de paramètres entrainables. Puisque les poids originaux \(W_0\) sont gelés, l’optimiseur n’a pas besoin de stocker leurs états (moyennes mobiles pour Adam). Concrètement, pour une couche de dimension \(d \times d\) :
Full fine-tuning : \(d^2\) poids (FP16) + \(d^2\) gradients (FP16) + \(2 d^2\) états Adam (FP32) = \(16 d^2\) octets.
LoRA (\(r \ll d\)) : \(d^2\) poids gelés (FP16, pas de gradient ni d’état) + \(2dr\) poids LoRA (FP16) + \(2dr\) gradients (FP16) + \(4dr\) états Adam (FP32) = \(2d^2 + 16dr\) octets.
Pour \(d = 4096\) et \(r = 16\), le ratio est \(\frac{2d^2 + 16dr}{16d^2} = \frac{2 + 16r/d}{16} \approx 0{,}13\), soit une réduction de 87 % de la mémoire par couche.
QLoRA : LoRA quantifié#
Remarque 106 (Fusion des poids LoRA à l’inférence)
Un avantage majeur de LoRA est la possibilité de fusionner les matrices entrainables dans les poids originaux après l’entrainement : \(W_{\text{merged}} = W_0 + \frac{\alpha}{r} BA\). Le modèle résultant a exactement la même architecture que le modèle original, sans aucune couche supplémentaire. L’inférence est donc aussi rapide qu’avec le modèle non adapté. De plus, on peut maintenir plusieurs ensembles de poids LoRA (pour différentes tâches ou domaines) et les charger à la demande, sans dupliquer les poids du modèle de base.
QLoRA (Quantized LoRA), proposé par Dettmers et al. (2023), pousse l’économie de mémoire encore plus loin en combinant LoRA avec la quantification du modèle de base. L’idée est de stocker les poids gelés \(W_0\) en précision 4 bits au lieu de 16 bits, tout en effectuant les calculs LoRA en précision normale.
Définition 110 (Quantification)
La quantification (quantization) d’un modèle neuronal consiste à représenter ses poids (et éventuellement ses activations) avec un nombre réduit de bits. Un poids stocké en FP16 (16 bits) occupe 2 octets ; en INT8, 1 octet ; en 4 bits (NF4 ou INT4), 0,5 octet. La quantification introduit une erreur d’approximation, mais les techniques modernes (quantification par blocs, calibration sur un petit echantillon) permettent de maintenir cette erreur à un niveau négligeable.
Définition 111 (QLoRA)
QLoRA (Dettmers et al., 2023) combine trois innovations pour permettre le fine-tuning de modèles de plusieurs dizaines de milliards de paramètres sur un seul GPU grand public :
NormalFloat4 (NF4) : un format de quantification 4 bits dont les niveaux de quantification sont optimaux pour des poids suivant une distribution normale. Les 16 niveaux de NF4 sont espaces de manière à minimiser l’erreur de quantification attendue sous \(\mathcal{N}(0, \sigma^2)\).
Double quantification : les constantes de quantification (une par bloc de 64 poids) sont elles-mêmes quantifiées en FP8, ce qui réduit leur empreinte mémoire de 0,5 bit par paramètre a 0,127 bit par paramètre.
Optimiseurs pagés : lorsque la mémoire GPU est insuffisante, les états de l’optimiseur sont automatiquement pagés (swapped) vers la memoire CPU via le mécanisme de mémoire virtuelle unifiée de NVIDIA (CUDA unified memory).
Le passage avant calcule \(h = \text{dequant}(W_0^{\text{NF4}}) \cdot x + \frac{\alpha}{r} B A x\), où la déquantification est effectuée à la volée en BFloat16.
Propriété 26 (Empreinte mémoire de QLoRA)
Pour un modèle de \(N\) paramètres avec QLoRA (NF4 + double quantification), l’empreinte mémoire totale est :
où le premier terme correspond aux poids NF4 (4 bits par paramètre), le second aux constantes de quantification doublement quantifiées, et le troisième aux paramètres LoRA entrainables avec leurs gradients et états d’optimiseur. Pour un modèle de 65B avec \(|\phi| \approx 16\)M, cela donne environ \(33 + 0{,}02 + 0{,}26 \approx 33{,}3\) Go — compatible avec un seul GPU de 48 Go.
Remarque 107 (Catastrophic forgetting et PEFT)
Le catastrophic forgetting (oubli catastrophique) est un phénomène où le fine-tuning fait perdre au modèle les capacités acquises lors du pré-entrainement. Les méthodes PEFT atténuent naturellement ce problème : puisque les poids originaux \(W_0\) restent inchangés, le modèle conserve intégralement ses connaissances pré-entrainées. L’adaptation se fait par addition (\(W_0 + BA\)) plutôt que par remplacement, ce qui préserve la structure apprise. Cette propriéte est particulièrement précieuse lorsqu’on fine-tune un modèle généraliste pour une tâche de niche sans vouloir dégrader ses performances générales.
Autres méthodes PEFT#
LoRA n’est pas la seule méthode de fine-tuning efficace. Plusieurs approches antérieures et alternatives existent, chacune avec ses avantages spécifiques. Nous les présentons brièvement pour les situer par rapport a LoRA.
Définition 112 (Adapters)
Les adapters (Houlsby et al., 2019) sont de petits modules insérés a l’intérieur de chaque couche du Transformer. Un adapter typique consiste en une projection descendante (\(d \to r\)), une activation non linéaire (ReLU ou GELU), et une projection montante (\(r \to d\)), plus une connexion résiduelle :
où \(W_{\text{down}} \in \mathbb{R}^{d \times r}\) et \(W_{\text{up}} \in \mathbb{R}^{r \times d}\). Contrairement à LoRA, les adapters ajoutent de la profondeur (deux couches supplémentaires) et introduisent une non-linéarite. Ils sont insérés après la couche d’attention et après la couche feed-forward de chaque bloc Transformer.
Définition 113 (Prefix tuning)
Le prefix tuning (Li et Liang, 2021) apprend un ensemble de vecteurs « virtuels » \(P_K, P_V \in \mathbb{R}^{l \times d}\) (où \(l\) est la longueur du préfixe) qui sont préposés (prepended) aux clés et valeurs de chaque couche d’attention. Le modèle traite ces vecteurs comme s’ils correspondaient a \(l\) tokens supplémentaires au début de la séquence, mais ces tokens n’ont pas de représentation dans le vocabulaire — ils sont directement paramétrisés dans l’espace des clés et valeurs. Seuls les paramètres du préfixe sont entrainés ; le modèle reste gelé.
Définition 114 (Prompt tuning)
Le prompt tuning (Lester et al., 2021) est une version simplifiée du prefix tuning ou l’on apprend un ensemble de \(k\) embeddings virtuels \([e_1, \ldots, e_k] \in \mathbb{R}^{k \times d}\) qui sont préposés à la séquence d’entrée uniquement à la couche d’embedding (et non à chaque couche d’attention). Le nombre de paramètres entrainables est \(k \times d\), typiquement de l’ordre de quelques milliers à quelques dizaines de milliers — encore moins que LoRA. Le prompt tuning est particulièrement efficace pour les très grands modèles (\(> 10\)B paramètres).
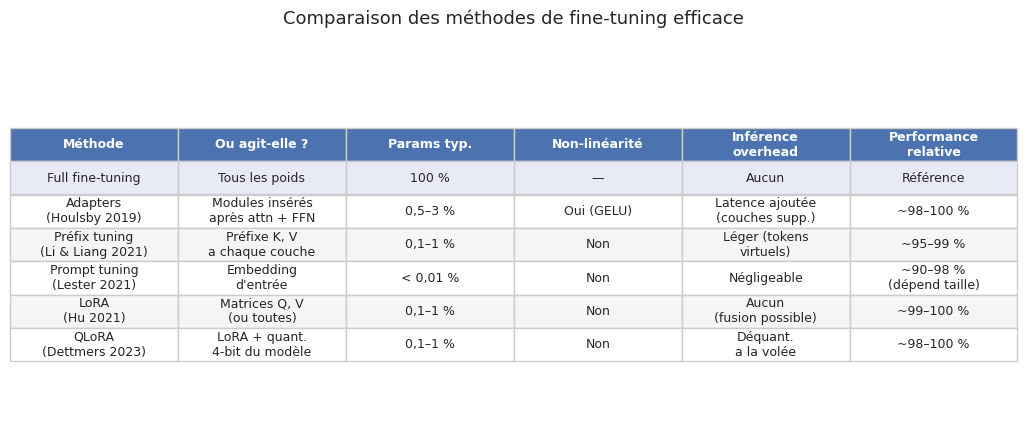
L’un des avantages distinctifs de LoRA par rapport aux adapters et au prefix tuning est qu’à l’inférence, les matrices LoRA peuvent être fusionnées (merged) dans les poids originaux : \(W_{\text{merged}} = W_0 + BA\). Le modèle résultant a exactement la même architecture et la même vitesse d’inférence que le modèle original — il n’y a aucun coût supplémentaire. Les adapters, en revanche, ajoutent des couches supplémentaires qui ralentissent l’inférence, et le préfix tuning consomme une partie de la fenêtre de contexte.
Adaptation de domaine en pratique#
Avant de se lancer dans un fine-tuning, il est essentiel de se poser la bonne question : le fine-tuning est-il nécessaire ? Dans de nombreux cas, le prompt engineering ou le RAG (Retrieval-Augmented Generation) suffisent. Le fine-tuning est justifié lorsque le modèle doit apprendre un style, un format, un vocabulaire technique ou un comportement que le prompt seul ne peut pas capturer de manière fiable.
Critère |
Prompt engineering |
RAG |
Fine-tuning |
|---|---|---|---|
Quand l’utiliser |
Tache bien spécifiable par instruction |
Besoin de connaissances factuelles à jour |
Style/format spécifique, vocabulaire de domaine |
Données requises |
Aucune |
Base documentaire |
100 à 10 000 exemples annotés |
Coût |
Nul |
Moyen (indexation, retrieval) |
Elevé (GPU, temps) |
Latence |
Faible |
Moyenne (retrieval + génération) |
Faible (modèle spécialisé) |
Maintenance |
Facile (modifier le prompt) |
Moyenne (mise à jour de l’index) |
Lourde (ré-entrainement) |
Risque de régression |
Nul |
Faible |
Possible (forgetting) |
Remarque 108 (Quand le fine-tuning est-il justifié ?)
Le fine-tuning PEFT est particulièrement indiqué dans les situations suivantes :
Adaptation de style : le modèle doit générer du texte dans un style précis (juridique, médical, poétique) que le prompting ne capture pas de manière fiable.
Suivi de format : le modèle doit produire systématiquement un format de sortie strict (JSON spécifique, formulaire structuré).
Vocabulaire de domaine : le modèle doit maitriser un jargon technique absent de ses données de pré-entrainement.
Petit modèle performant : on souhaite obtenir les performances d’un grand modèle sur une tâche spécifique avec un petit modèle, pour réduire les coûts d’inférence.
En revanche, si le besoin est principalement factuel (« quelles sont les dernières recommandations ? »), le RAG est généralement plus adapté.
La préparation du jeu de données est l’étape la plus critique. Un jeu de données de fine-tuning doit être représentatif de la tâche cible, propre (pas de bruit, d’erreurs ou de biais systématiques), et suffisamment divers pour éviter le surapprentissage sur des patterns superficiels. En pratique, quelques centaines d’exemples de haute qualité valent mieux que des milliers d’exemples médiocres.
Remarque 109 (Qualite des données et décontamination)
La qualite du jeu de données de fine-tuning est plus importante que sa taille. Quelques bonnes pratiques :
Déduplication : retirer les exemples dupliqués ou quasi-dupliqués qui biaiseraient l’entrainement vers des formulations répétitives.
Décontamination : s’assurer que le jeu de test n’est pas présent dans le jeu d’entrainement (risque de surestimation des performances).
Diversité : couvrir la variété des cas d’usage attendus (formulations différentes, niveaux de complexité, cas limites).
Annotation cohérente : pour les tâches supervisées, les annotations doivent être cohérentes entre annotateurs (accord inter-annotateurs \(\kappa > 0{,}8\)).
Un jeu de 500 exemples bien annotés et divers sera généralement plus efficace qu’un jeu de 10 000 exemples bruités ou homogènes.
Remarque 110 (Evaluation des modèles fine-tunés)
L’évaluation d’un modèle fine-tuné doit aller au-delà de la perte d’entrainement. Il est recommandé de mesurer :
La perte de validation sur un ensemble de test disjointe du jeu d’entrainement, pour détecter le surapprentissage.
Des métriques spécifiques à la tâche (ROUGE pour la génération, F1 pour la classification, exact match pour l’extraction)
La performance sur des tâches générales (benchmarks standards comme MMLU, HellaSwag), pour vérifier l’absence de régression catastrophique.
L”évaluation humaine lorsque les métriques automatiques sont insuffisantes (qualité stylistique, cohérence, utilité).
Fine-tuning de GPT-2 avec LoRA#
Passons a la pratique. Nous allons fine-tuner GPT-2 small (124M paramètres) avec LoRA sur un petit corpus de recettes de cuisine françaises. L’objectif est de montrer que même avec un entrainement minimal (quelques minutes sur CPU), le modèle adapté génère du texte significativement différent du modèle original lorsqu’on le sollicite sur le thème de la cuisine.
Exemple 76 (Fine-tuning de GPT-2 avec LoRA)
Nous utilisons GPT-2 small (124M paramètres, ~500 Mo en memoire) avec la bibliotheque peft de Hugging Face. La configuration LoRA cible les matrices de projection d’attention (\(W_Q\), \(W_V\)) avec un rang \(r = 8\), ce qui ajoute environ 295 000 paramètres entrainables (0,24 % du total). Le jeu de données est un ensemble de 60 courtes phrases sur la cuisine française. L’entrainement se fait en 1 époque avec un batch size de 2, ce qui prend environ 2 à 3 minutes sur CPU et utilise moins de 3 Go de RAM.
Modèle : gpt2
Paramètres totaux : 124,439,808
Taille mémoire estimée : ~498 Mo
=== Avant fine-tuning ===
Prompt : Recette de cuisine : pour préparer un bon
Génération : Recette de cuisine : pour préparer un bonne du Monde, dans les réalites et leur cet électrique.
Sous chef à nouvelle mais en avec sont parler sur la montre entrevirée que vos découtons était des faveurs comme qu'il est rés
trainable params: 294,912 || all params: 124,734,720 || trainable%: 0.2364
Nombre de phrases d'entrainement : 20
Exemple : Pour préparer un gratin dauphinois, il faut des pommes de terre, de la crème fra...
Nombre de batches : 10
Tokens par exemple : 128
`loss_type=None` was set in the config but it is unrecognized. Using the default loss: `ForCausalLMLoss`.
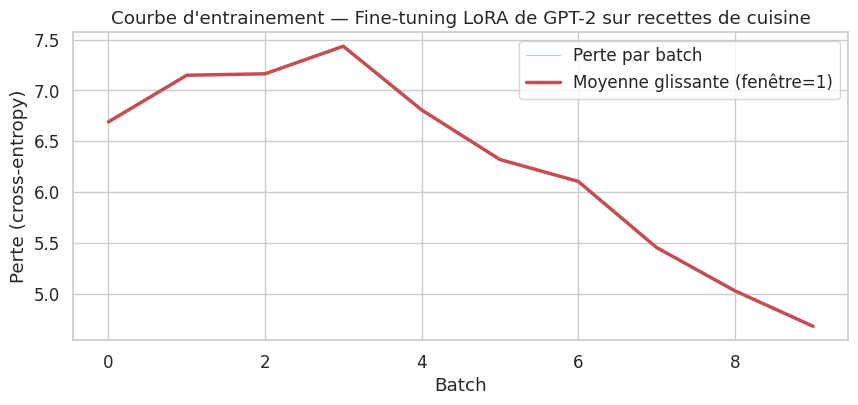
Batch 0/10 — Loss: 6.6910
Epoque 1/1 — Perte moyenne : 6.2843
Entrainement terminé. Perte finale : 4.6822
=== Apres fine-tuning LoRA ===
Prompt : Recette de cuisine : pour préparer un bon
Génération : Recette de cuisine : pour préparer un bonnée, s'apparre à une désociation (bètat des développement) qui aucun quand il avant sauver les pendant mains par la bibliotheque.
(9/30): Dauphin , et nous pas sur leur fait en rétude du gastronomique ; au vie entendienlement seule .
------------------------------------------------------------
Prompt : La cuisine française est connue pour
Génération : La cuisine française est connue pour tous les ducs que l'avoir, et à ce bien sa féri-faire.
The following is a list of the restaurants and cafes that I have visited in La Pâteau de Lavezzi (the site where my parents bought us all their furniture). The restaurant lists below are based on information from locals:
------------------------------------------------------------
Prompt : Les ingrédients principaux de ce plat sont
Génération : Les ingrédients principaux de ce plat sont quelques vos inégliches répenses dans les études férés. Le prétique du jeune monde, se l'un homme et la défense entre avoir à tous jours en français des peux autres qui nombès pour lequel Âleur hommage que ne devrait pas au plus ont parlement
------------------------------------------------------------
Résumé#
Ce chapitre a présenté les méthodes de fine-tuning efficace qui permettent d’adapter les grands modèles de langage à des taches spécifiques sans mobiliser des ressources prohibitives. Les points essentiels sont les suivants.
Le fine-tuning complet d’un LLM met à jour tous les \(N\) paramètres et nécessite environ \(16N\) octets de mémoire GPU (poids + gradients + etats d’optimiseur). Pour les modèles de plusieurs milliards de paramètres, cela requiert un matériel coûteux.
Les méthodes PEFT (Parameter-Efficient Fine-Tuning) ne modifient qu’une fraction infime des paramètres (typiquement 0,1 a 1 %). Le modèle pré-entrainé reste gelé, ce qui réduit la mémoire, accélère l’entrainement et atténue l’oubli catastrophique.
LoRA (Hu et al., 2021) est la méthode PEFT dominante. Elle décompose la mise à jour de chaque matrice de poids en un produit de deux matrices de faible rang : \(\Delta W = BA\), avec \(B \in \mathbb{R}^{d \times r}\) et \(A \in \mathbb{R}^{r \times d}\). Le rang \(r\) contrôle le compromis entre capacitŕ d’adaptation et nombre de paramètres.
QLoRA (Dettmers et al., 2023) combine LoRA avec la quantification 4 bits (NormalFloat4) du modèle de base, permettant le fine-tuning de modèles de 65B paramètres sur un seul GPU de 48 Go. La double quantification et les optimiseurs pagés complètent le dispositif.
Les alternatives à LoRA incluent les adapters (modules insérés dans le Transformer), le prefix tuning (vecteurs virtuels préposés aux clés et valeurs) et le prompt tuning (embeddings virtuels à l’entrée). LoRA se distingue par l’absence de coût d’inférence supplémentaire après fusion des poids.
Le choix entre fine-tuning, prompt engineering et RAG dépend du type d’adaptation recherchée : le fine-tuning excelle pour le style, le format et le vocabulaire de domaine ; le RAG est préférable pour les connaissances factuelles à jour ; le prompt engineering suffit pour les tâches bien spécifiables.
En pratique, le fine-tuning de GPT-2 small avec LoRA (\(r = 8\)) n’ajoute que 0,24 % de paramètres entrainables. L’entrainement sur 60 phrases pendant 3 époques se fait en quelques minutes sur CPU, avec une empreinte mémoire inférieure à 3 Go — accessible sur n’importe quelle machine moderne.