Evaluation et benchmarks#
L’évaluation des grands modèles de langage est un problème fondamentalement différent de l’évaluation des modèles supervisés classiques. En classification ou en régression, on dispose d’une vérité terrain unique et de métriques bien définies (accuracy, MSE). Pour un LLM qui génère du texte libre, la question « cette réponse est-elle correcte ? » n’admet souvent pas de réponse binaire. La qualité d’un résumé, la pertinence d’une explication ou la créativité d’un texte sont des jugements intrinsèquement subjectifs et multidimensionnels.
Ce chapitre présente les principaux outils d’évaluation des LLM, depuis les métriques automatiques héritées du traitement du langage naturel (BLEU, ROUGE, BERTScore) jusqu’aux approches modernes fondées sur le jugement humain (Chatbot Arena, classements Elo) ou sur l’utilisation d’un LLM comme juge. Nous implémentons chaque métrique à partir de zéro pour en comprendre la mécanique interne, avant de discuter des benchmarks standardisés qui structurent la recherche actuelle.
L’enjeu est considérable : les décisions de déploiement, de financement et de recherche reposent sur ces évaluations. Un benchmark mal conçu ou une métrique mal choisie peut orienter un domaine entier dans une direction sous-optimale. Comprendre les forces et les limites de chaque approche d’évaluation est donc une compétence essentielle pour tout praticien de l’IA.
Pourquoi évaluer est difficile#
L’évaluation des LLM se heurte à plusieurs difficultés fondamentales qui n’existent pas dans l’apprentissage supervisé classique.
Génération ouverte. Un LLM produit du texte libre : pour une même question, il existe une infinité de réponses valides. Demander « Expliquez la gravité » peut donner lieu à des réponses de longueurs, de styles et de niveaux de détail très différents, toutes parfaitement acceptables.
Subjectivité. La qualité d’un texte est en partie subjective. Deux évaluateurs humains peuvent légitimement être en désaccord sur la clarté d’une explication ou la pertinence d’un résumé. Cette variabilité inter-annotateurs pose un problème de reproductibilité.
Réponses multiples valides. En traduction automatique, « The cat is on the mat » peut être traduit par « Le chat est sur le tapis », « Le chat se trouve sur le tapis » ou « Sur le tapis se trouve le chat ». Toutes ces traductions sont correctes, mais une métrique qui compare à une seule référence pénalisera les reformulations légitimes.
Optimisation des benchmarks (benchmark gaming). Dès qu’un benchmark devient un critère de succès, les modèles peuvent être entraînés sur les données de test, les hyperparamètres ajustés spécifiquement, et les résultats présentés de manière sélective. Ce phénomène, lié à la loi de Goodhart, est une menace permanente pour la validité des évaluations.
Remarque 46
L’évaluation d’un LLM est nécessairement multidimensionnelle. Un modèle peut exceller en raisonnement mathématique mais produire des textes peu fluides, ou inversement. Aucune métrique scalaire unique ne peut capturer toutes les facettes de la qualité d’un modèle de langage. C’est pourquoi la communauté utilise des batteries de benchmarks couvrant des capacités variées : connaissances générales, raisonnement logique, génération de code, suivi d’instructions, sécurité, etc.
Métriques de génération : BLEU, ROUGE, BERTScore#
Les premières métriques d’évaluation automatique ont été développées pour la traduction automatique et le résumé. Elles reposent sur la comparaison entre un texte généré (l”hypothèse) et un ou plusieurs textes de référence.
BLEU#
Le score BLEU (Bilingual Evaluation Understudy), proposé par Papineni et al. en 2002, est la métrique historique de la traduction automatique. Il mesure la précision des n-grammes : quelle fraction des n-grammes de l’hypothèse apparaît dans la référence ?
Définition 39 (Score BLEU)
Soient \(h\) une hypothèse et \(r\) une référence. La précision modifiée des n-grammes est
où \(\mathcal{N}_n(h)\) désigne l’ensemble des n-grammes distincts de \(h\) et \(\text{count}(g, s)\) le nombre d’occurrences du n-gramme \(g\) dans \(s\). Le modificateur \(\min\) (dit clipping) empêche de compter un n-gramme plus de fois qu’il n’apparaît dans la référence.
Le score BLEU combine les précisions pour \(n = 1, \ldots, N\) (typiquement \(N = 4\)) avec une pénalité de brièveté :
Propriété 11 (Précision des n-grammes)
La précision modifiée \(p_n\) possède les propriétés suivantes :
\(0 \leq p_n \leq 1\) pour tout \(n\).
\(p_n\) est une mesure de précision : elle évalue quelle fraction de l’hypothèse est « couverte » par la référence.
\(p_n\) décroît généralement avec \(n\) : il est plus facile de trouver des unigrammes communs que des séquences de 4 mots identiques.
Le clipping empêche l’exploitation triviale qui consisterait à répéter un mot fréquent de la référence.
Implémentons le score BLEU à partir de zéro.
Exemple 31 (Calcul de BLEU sur un exemple)
Considérons la référence « le chat est assis sur le tapis » et deux hypothèses :
ref = "le chat est assis sur le tapis".split()
hyp1 = "le chat est sur le tapis".split() # bonne traduction, mot manquant
hyp2 = "le le le le le le le".split() # spam de "le"
Pour hyp1, les unigrammes communs sont nombreux (6 sur 6 sont dans la référence), mais il manque « assis ». Pour hyp2, le clipping limite le comptage de « le » à 2 (son nombre dans la référence), d’où \(p_1 = 2/7\).
--- hyp1 (bonne traduction) ---
p_1 = 1.0000
p_2 = 0.8000
p_3 = 0.5000
p_4 = 0.0000
BP = 0.8465
BLEU = 0.0000
--- hyp2 (spam de 'le') ---
p_1 = 0.2857
p_2 = 0.0000
p_3 = 0.0000
p_4 = 0.0000
BP = 1.0000
BLEU = 0.0000
Remarque 47
Le score BLEU présente plusieurs limitations bien connues :
Il ne tient pas compte de la sémantique : deux synonymes sont traités comme des mots différents.
Il pénalise les reformulations légitimes qui n’utilisent pas les mêmes mots que la référence.
Il mesure la précision mais pas le rappel : il ne vérifie pas que l’hypothèse couvre tout le contenu de la référence.
Il est sensible à la tokenisation et à la casse.
ROUGE#
ROUGE (Recall-Oriented Understudy for Gisting Evaluation), proposé par Lin en 2004, est la métrique standard du résumé automatique. Contrairement à BLEU, ROUGE se concentre sur le rappel : quelle fraction du contenu de la référence est présente dans l’hypothèse ?
Définition 40 (Métriques ROUGE)
ROUGE-N (rappel des n-grammes) :
En pratique, on utilise ROUGE-1 (\(n=1\)) et ROUGE-2 (\(n=2\)).
ROUGE-L (plus longue sous-séquence commune) : soit \(\text{LCS}(h, r)\) la longueur de la LCS entre \(h\) et \(r\).
avec typiquement \(\beta = 1\) (F1-mesure classique).
Remarque 48
ROUGE et BLEU sont complémentaires : BLEU mesure la précision (les mots générés sont-ils dans la référence ?) tandis que ROUGE mesure le rappel (les mots de la référence sont-ils dans l’hypothèse ?). Un résumé trop court obtient un bon BLEU mais un mauvais ROUGE ; un résumé trop long obtient un bon ROUGE mais un mauvais BLEU. En pratique, on reporte souvent la F1-mesure de ROUGE qui combine précision et rappel.
Exemple 32 (Calcul de ROUGE-L sur un exemple)
Considérons la référence « le chat dort sur le canapé » et l’hypothèse « le chat est allongé sur le canapé bleu ». La LCS est « le chat sur le canapé » (longueur 5) :
ref = "le chat dort sur le canapé".split() # 6 tokens
hyp = "le chat est allongé sur le canapé bleu".split() # 8 tokens
# Recall = 5/6, Precision = 5/8
Longueur LCS : 5
ROUGE-L (F1) : 0.7143
ROUGE-1 (rappel) : 0.8333
ROUGE-2 (rappel) : 0.6000
BERTScore#
Les métriques précédentes comparent des mots de manière exacte. BERTScore, proposé par Zhang et al. en 2020, utilise les représentations contextuelles d’un modèle BERT pré-entraîné pour mesurer la similarité sémantique entre l’hypothèse et la référence.
Définition 41 (BERTScore)
Soient \(\mathbf{h}_1, \ldots, \mathbf{h}_m\) les embeddings contextuels des tokens de l’hypothèse et \(\mathbf{r}_1, \ldots, \mathbf{r}_n\) ceux de la référence. BERTScore calcule :
où \(\cos(\mathbf{a}, \mathbf{b}) = \frac{\mathbf{a} \cdot \mathbf{b}}{\|\mathbf{a}\| \|\mathbf{b}\|}\). BERTScore peut reconnaître que « chien » et « canidé » sont sémantiquement proches, là où BLEU et ROUGE les traiteraient comme entièrement différents.
Comparaison des métriques#
Comparons le comportement de BLEU, ROUGE-1 et ROUGE-L sur plusieurs paires hypothèse/référence.
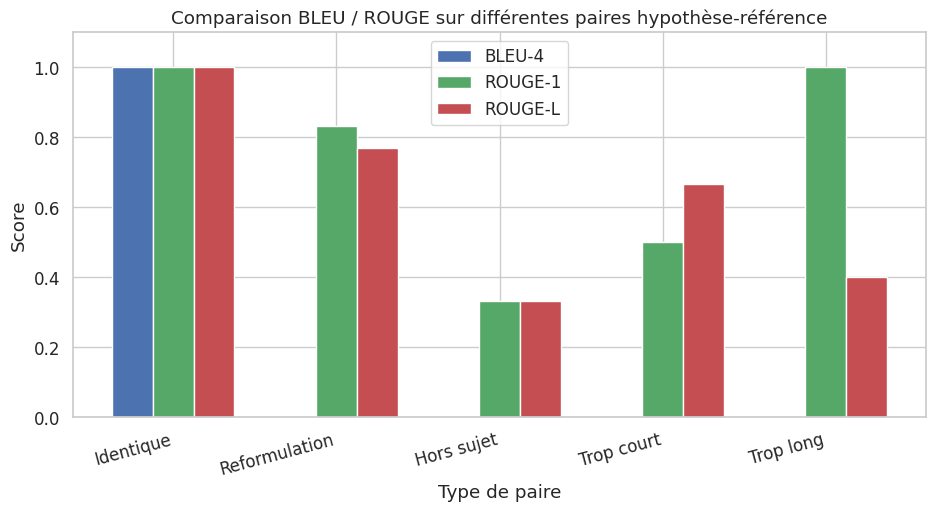
Perplexité et métriques de modèle de langue#
La perplexité est la métrique intrinsèque fondamentale pour évaluer un modèle de langue. Elle mesure à quel point le modèle est « surpris » par une séquence de tokens.
Définition 42 (Perplexité)
Soit un modèle de langue \(P\) et une séquence de tokens \(x_1, x_2, \ldots, x_N\). La perplexité est
La perplexité s’interprète comme le nombre moyen de choix que le modèle hésite entre à chaque position. Un modèle parfait a une perplexité de 1 ; un modèle uniforme sur un vocabulaire de taille \(V\) a une perplexité de \(V\). Plus la perplexité est basse, meilleur est le modèle. Elle est liée à l’entropie croisée \(H\) par \(\text{PPL} = \exp(H)\).
Remarque 49
La perplexité a des limitations importantes. Elle mesure la qualité des probabilités du modèle, pas l’utilité de ses réponses. Un modèle peut avoir une excellente perplexité sur Wikipédia tout en étant incapable de suivre des instructions. De plus, la perplexité dépend du corpus et de la tokenisation : des comparaisons entre modèles n’ont de sens que si le vocabulaire et le corpus sont identiques.
=== Modèle parfait ===
Perplexité = 1.00
=== Modèle uniforme ===
Perplexité = 6.00 (= |V| = 6)
=== Bon modèle ===
Perplexité = 1.44
=== Mauvais modèle ===
Perplexité = 6.93
Benchmarks standardisés#
Les benchmarks standardisés permettent de comparer les modèles sur des tâches reproductibles. Chaque benchmark cible une capacité spécifique.
Exemple 33 (Principaux benchmarks pour LLM)
Benchmark |
Domaine |
Format |
Métrique |
|---|---|---|---|
MMLU |
Connaissances (57 matières) |
QCM (4 choix) |
Accuracy |
HumanEval |
Code Python |
Génération |
pass@k |
GSM8K |
Maths (primaire) |
Résolution |
Accuracy |
MATH |
Maths (avancé) |
Résolution |
Accuracy |
TruthfulQA |
Véracité |
QCM / génération |
Accuracy |
MT-Bench |
Suivi d’instructions |
Multi-tour |
Note LLM (1-10) |
ARC |
Raisonnement scientifique |
QCM |
Accuracy |
HellaSwag |
Sens commun |
Complétion |
Accuracy |
MMLU évalue les connaissances sur 57 matières académiques. HumanEval teste la génération de code avec la métrique pass@\(k\). GSM8K et MATH testent le raisonnement mathématique à des niveaux croissants. TruthfulQA évalue la propension à reproduire des idées fausses courantes. MT-Bench utilise un LLM-juge pour noter la qualité conversationnelle.
Propriété 12 (Propriétés d’un bon benchmark)
Un benchmark d’évaluation de LLM devrait satisfaire :
Discriminant : il sépare efficacement les modèles de niveaux différents.
Non saturé : les meilleurs modèles n’atteignent pas le plafond.
Non contaminable : les données de test ne sont pas facilement mémorisables à partir du web.
Représentatif : il couvre les capacités réellement utiles en pratique.
Reproductible : le protocole d’évaluation est entièrement spécifié.
Visualisons les performances comparées de plusieurs modèles sur ces benchmarks.
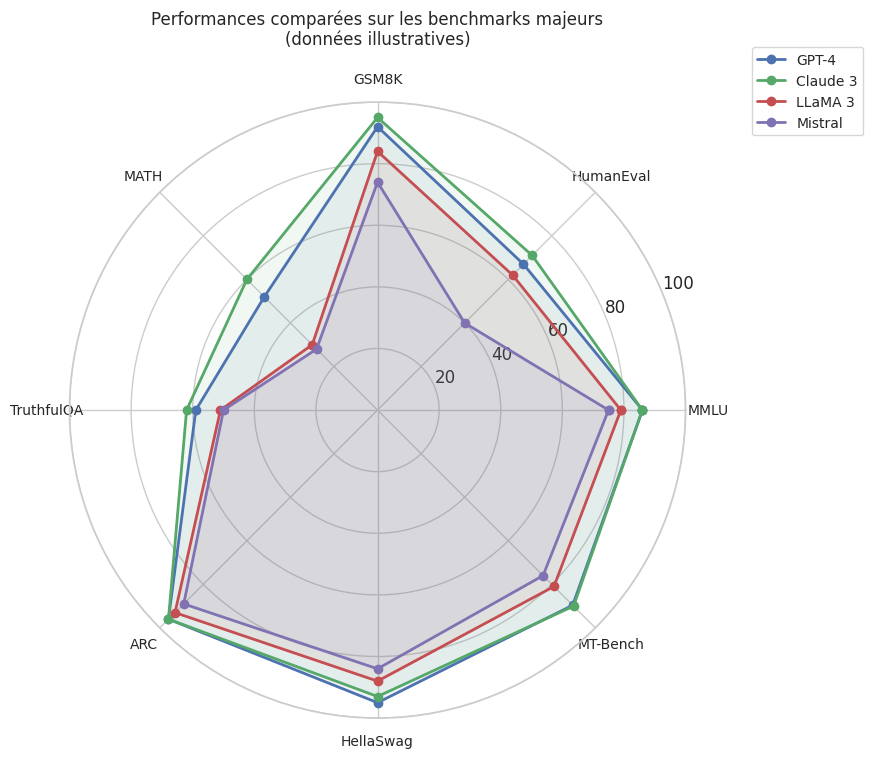
Évaluation par LLM (LLM-as-a-judge)#
Face aux limitations des métriques automatiques, une approche récente consiste à utiliser un LLM puissant comme juge pour évaluer les sorties d’autres modèles. Cette méthode, popularisée par Zheng et al. (2023) avec MT-Bench, exploite la capacité des LLM à produire des jugements nuancés et argumentés.
Définition 43 (LLM-as-a-judge)
L’évaluation par LLM-juge consiste à soumettre la sortie d’un modèle à un LLM puissant accompagnée d’un prompt d’évaluation structuré. Deux modes sont possibles :
Notation directe (single answer grading) : le juge attribue une note (par exemple 1 à 10) avec une justification.
Comparaison par paires (pairwise comparison) : le juge indique quelle réponse est meilleure (A, B ou égalité) avec une justification.
Le mode pairwise est généralement plus fiable car il est plus facile de comparer deux textes que d’attribuer une note absolue.
Remarque 50
L’évaluation par LLM-juge souffre de biais systématiques :
Biais de position : le juge tend à favoriser la réponse présentée en premier (ou en second). On atténue ce biais en évaluant chaque paire dans les deux ordres.
Biais de verbosité : préférence pour les réponses plus longues, même moins précises.
Auto-favoritisme : un LLM-juge tend à préférer les réponses de modèles de la même famille.
Biais de style : préférence pour un style particulier (listes à puces, formulations académiques).
Malgré ces biais, l’accord entre les jugements de GPT-4 et ceux d’évaluateurs humains experts dépasse 80 %, comparable à l’accord inter-annotateurs humain.
Exemple 34 (Prompt d’évaluation LLM-juge)
Un prompt typique pour l’évaluation pairwise :
[Instruction] Veuillez agir comme un juge impartial et évaluer la qualité
des réponses fournies par deux assistants IA à la question ci-dessous.
[Question] {question}
[Réponse A] {réponse_A}
[Réponse B] {réponse_B}
Évaluez selon les critères suivants : pertinence, exactitude, clarté.
Expliquez votre raisonnement, puis indiquez votre verdict final :
[[A]], [[B]] ou [[Égalité]].
Le prompt est conçu pour minimiser les biais en demandant une justification avant le verdict, forçant le juge à articuler son raisonnement.
Évaluation humaine et classements Elo#
Malgré les progrès des métriques automatiques, l”évaluation humaine reste la référence pour mesurer la qualité perçue des modèles de langage.
Exemple 35 (Chatbot Arena)
Chatbot Arena (LMSYS, UC Berkeley) est une plateforme ouverte d’évaluation par crowdsourcing :
Un utilisateur pose une question libre.
Deux modèles anonymes répondent en parallèle.
L’utilisateur vote pour la meilleure réponse (A, B ou égalité).
Les identités des modèles sont révélées après le vote.
Les votes sont agrégés en un classement Elo (Bradley-Terry). Plus d’un million de votes ont été collectés, offrant un signal statistiquement robuste sur les préférences humaines. L’avantage principal est que les questions sont réelles et diversifiées, non optimisables.
Définition 44 (Classement Elo)
Le système Elo attribue à chaque modèle un score reflétant sa force relative. Après un match entre \(A\) et \(B\) de scores \(R_A\) et \(R_B\) :
Probabilité attendue (modèle Bradley-Terry) :
Mise à jour après le résultat \(S_A \in \{0, 0{,}5, 1\}\) :
où \(K\) est le facteur de mise à jour. Un modèle qui gagne contre un adversaire mieux classé gagne beaucoup de points.
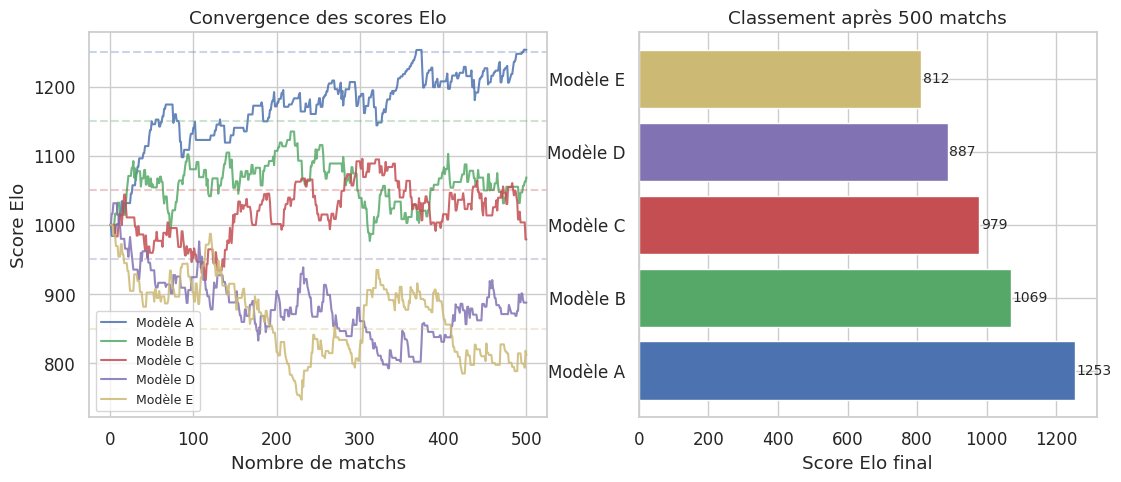
Remarque 51
Le système Elo converge vers les forces réelles des modèles à condition que le nombre de matchs soit suffisant et que les matchups soient diversifiés. En pratique, Chatbot Arena utilise une variante du modèle Bradley-Terry estimé par maximum de vraisemblance sur l’ensemble des votes, plutôt que la mise à jour séquentielle classique. Cela produit des intervalles de confiance et permet de tester si la différence entre deux modèles est statistiquement significative.
Simulons un classement Elo pour illustrer la convergence des scores.
Limites et bonnes pratiques#
Contamination des données#
Remarque 52
La contamination des données survient lorsque les données de test d’un benchmark apparaissent dans le corpus d’entraînement. Comme les LLM sont entraînés sur d’immenses volumes de texte du web, il est difficile de garantir l’absence de contamination. Un modèle peut alors « résoudre » un benchmark par mémorisation plutôt que par raisonnement. Des études ont montré des baisses de 10 à 15 points lorsque les questions contaminées sont retirées.
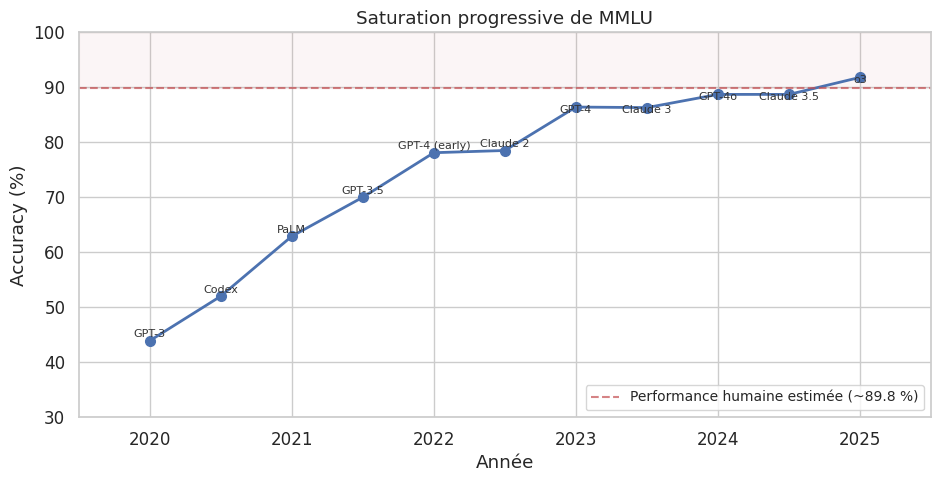
Saturation des benchmarks#
Remarque 53
La saturation se produit lorsque les meilleurs modèles atteignent le plafond théorique, rendant le benchmark incapable de discriminer. HellaSwag (de ~30 % à >95 %) et MMLU (de ~30 % à >90 %) en sont des exemples. Un benchmark saturé impose de concevoir de nouveaux benchmarks plus difficiles (MMLU-Pro, GPQA, FrontierMath).
Loi de Goodhart et bonnes pratiques#
Remarque 54
La loi de Goodhart stipule : « Quand une mesure devient un objectif, elle cesse d’être une bonne mesure. » Dès qu’un benchmark devient le critère de référence, les incitations à l’optimiser (contamination, entraînement ciblé, sélection des résultats) dégradent sa capacité à mesurer ce qu’il est censé mesurer. C’est pourquoi la communauté doit utiliser des méthodes d’évaluation dynamiques comme Chatbot Arena, où les questions ne sont pas fixées à l’avance.
Pour une évaluation rigoureuse des LLM, plusieurs principes se dégagent :
Évaluation multi-benchmark. Ne jamais se fier à un seul benchmark. Combiner connaissances (MMLU), raisonnement (GSM8K, MATH), code (HumanEval), sécurité (TruthfulQA) et qualité conversationnelle (MT-Bench).
Vérification de contamination. Tester si le modèle a vu les données de test, en utilisant des variantes paraphrasées.
Évaluation humaine complémentaire. Pour les tâches ouvertes, intégrer une évaluation humaine même partielle.
Transparence méthodologique. Documenter version du modèle, température, prompt exact, nombre de tentatives.
Métriques adaptées à la tâche. BLEU/ROUGE pour traduction et résumé, pass@\(k\) pour le code, accuracy pour les QCM, jugement LLM ou humain pour les tâches ouvertes.
Résumé#
Ce chapitre a présenté les principales méthodes d’évaluation des grands modèles de langage.
Évaluer un LLM est intrinsèquement difficile en raison de la génération ouverte, de la subjectivité, de l’existence de réponses multiples valides et des risques de benchmark gaming.
BLEU mesure la précision des n-grammes entre une hypothèse et une référence, avec une pénalité de brièveté. C’est la métrique historique de la traduction, mais elle ignore la sémantique.
ROUGE mesure le rappel des n-grammes (ROUGE-N) ou la couverture par la plus longue sous-séquence commune (ROUGE-L). C’est la métrique standard du résumé automatique.
BERTScore utilise les embeddings contextuels d’un modèle BERT pour capturer la similarité sémantique, surmontant la limitation de la correspondance exacte de mots.
La perplexité \(\text{PPL} = \exp(-\frac{1}{N}\sum \log P(x_i \mid x_{<i}))\) mesure la surprise du modèle de langue. Plus elle est basse, meilleur est le modèle, mais elle ne capture pas l’utilité des réponses.
Les benchmarks standardisés (MMLU, HumanEval, GSM8K, MATH, TruthfulQA, ARC, HellaSwag, MT-Bench) testent des capacités spécifiques mais souffrent de contamination et de saturation.
L’évaluation par LLM-juge offre une alternative scalable avec un accord supérieur à 80 % avec les experts, mais présente des biais de position, de verbosité et d’auto-favoritisme.
L’évaluation humaine et les classements Elo (Chatbot Arena) restent le gold standard. Le modèle Bradley-Terry convertit les comparaisons par paires en classement global.
Les limites incluent la contamination, la saturation, la loi de Goodhart et la nécessité d’une évaluation multidimensionnelle.
Les bonnes pratiques imposent une évaluation multi-benchmark, une vérification de contamination, une complémentarité entre métriques automatiques et jugement humain, et une transparence méthodologique.