Raisonnement avancé#
Le chapitre précédent a introduit le Chain-of-Thought (CoT) comme première stratégie pour inciter un LLM à raisonner étape par étape. Si le CoT linéaire améliore notablement les performances sur de nombreuses tâches, il reste fondamentalement contraint par sa nature séquentielle : le modèle ne peut ni explorer plusieurs pistes en parallèle, ni revenir sur une erreur intermédiaire, ni intéragir avec le monde extérieur pour vérifier une hypothèse.
Ce chapitre présente les paradigmes de raisonnement avancé qui surmontent ces limites. Le Tree-of-Thought (ToT) structure l’exploration en arbre avec retour arrière ; le Graph-of-Thought (GoT) généralise cette idée en autorisant la fusion et le raffinement de pensées ; ReAct entrelace raisonnement et action pour ancrer les réponses dans des observations externes. Enfin, le tool use et le function calling concrétisent ces paradigmes dans les API modernes, transformant le LLM en véritable agent outillé.
L’objectif est double : comprendre formellement chaque paradigme et savoir choisir la bonne stratégie selon la tâche. Chaque section est accompagnée de simulations en Python pur, sans appel à une API externe, afin d’illustrer la mécanique interne de ces approches.
Au-delà du raisonnement linéaire#
Le CoT linéaire produit une unique chaine de pensées \(t_1 \to t_2 \to \cdots \to t_n\) menant à la réponse. Cette structure souffre de trois limitations majeures :
Pas d’exploration : si la première pensée \(t_1\) part dans une mauvaise direction, toute la chaine est compromise.
Pas de retour arrière (backtracking) : une erreur à l’étape \(t_k\) se propage mécaniquement jusqu’à la réponse finale.
Pas d’ancrage externe (grounding) : le raisonnement se déroule entièrement « dans la tête » du modèle, source d’hallucinations pour les questions factuelles ou les calculs numériques.
Remarque 37 (Stratégies de recherche et raisonnement)
L’analogie avec les algorithmes de recherche en intelligence artificielle classique est éclairante. Le CoT correspond à une recherche en profondeur sans retour arrière (greedy depth-first). Le ToT introduit une veritable recherche en arbre (BFS ou DFS avec évaluation). Le GoT généralise au cas des graphes. ReAct ajoute la possibilité d’observer l’environnement entre deux étapes de recherche.
Paradigme |
Exploration |
Retour arrière |
Interaction externe |
|---|---|---|---|
CoT |
Non |
Non |
Non |
ToT |
Oui (arbre) |
Oui |
Non |
GoT |
Oui (graphe) |
Oui |
Non |
ReAct |
Séquentielle |
Non |
Oui (outils) |
Tree-of-Thought (ToT)#
Le Tree-of-Thought a été proposé par Yao et al. (2023) pour surmonter la linéarité du CoT en structurant le raisonnement comme un arbre de recherche.
Définition 34 (Tree-of-Thought (ToT))
Le Tree-of-Thought est un cadre de raisonnement dans lequel :
L”espace de pensées \(\mathcal{T}\) est un ensemble de pensées intermédiaires cohérentes, où chaque pensée \(t\) représente un pas de raisonnement partiel.
Un générateur \(G(t_{\text{parent}}) \to \{t_1, \ldots, t_b\}\) produit \(b\) pensées candidates à partir d’une pensée parente, formant un arbre de facteur de branchement \(b\).
Un évaluateur \(V(t) \to \mathbb{R}\) estime la qualité d’une pensée intermédiaire (par le LLM lui-même, via un prompt d’évaluation).
Un algorithme de recherche (BFS, DFS, beam search) explore l’arbre en utilisant \(V\) pour guider l’exploration et décider du retour arrière.
La résolution d’un problème \(p\) consiste à trouver le chemin \(t_0 \to t_1 \to \cdots \to t_n\) qui maximise la qualité de la solution finale, où \(t_0\) est la racine (enoncé du problème).
Le processus ToT alterne trois phases : génération de \(b\) pensées candidates, évaluation par le LLM (score numérique, vote ou jugement catégoriel), et sélection avec retour arrière sur les branches jugées sans issue.
Remarque 38 (Stratégies d’évaluation dans le ToT)
L’évaluateur peut prendre trois formes principales : (1) un score numérique (« sur 10, quelle est la qualité de cette étape ? »), (2) un vote parmi plusieurs candidats (le LLM choisit le meilleur), ou (3) un jugement catégoriel (« sure / maybe / impossible »). Le choix de la stratégie d’évaluation impacte fortement la qualité de l’élagage : un jugement trop permissif gaspille des appels, un jugement trop strict risque d’élaguer la bonne branche.
Propriété 8 (ToT vs CoT : garanties d’exploration)
Le ToT subsume strictement le CoT : avec \(b = 1\) et sans évaluation, le ToT se réduit à un CoT standard. Avec \(b > 1\), le ToT explore un espace exponentiellement plus grand (\(b^d\) noeuds à profondeur \(d\)), augmentant la probabilité de trouver un chemin correct au prix d’un nombre d’appels LLM en \(O(b^d)\).
Remarque 39 (Coût computationnel du ToT)
Pour un arbre de profondeur \(d\) et de facteur \(b\), le nombre de générations et d’évaluations est \(O(b^d)\). En pratique, Yao et al. utilisent \(b \leq 5\) et \(d \leq 4\), soit quelques dizaines d’appels — un coût 10 à 100 fois supérieur au CoT, réservé aux problèmes où la précision le justifie.
Exemple 27 (Le Game of 24 résolu par ToT)
Le Game of 24 consiste à combiner 4 nombres avec \(+, -, \times, \div\) pour obtenir 24. Pour \(\{4, 9, 10, 13\}\), le CoT échoue fréquemment. Le ToT explore plusieurs pistes :
Branche 1 : \(13 - 10 = 3\), puis \(9 - 3 = 6\), puis \(6 \times 4 = 24\) — succès
Branche 2 : \(13 - 9 = 4\), puis \(4 + 4 = 8\), puis \(8 \times 10 = 80\) — évaluateur : « impossible » — retour arrière
Branche 3 : \(10 + 13 = 23\), puis \(23 + 9 = 32\) — évaluateur : « dépasse 24 » — retour arrière
L’évaluateur élague les branches 2 et 3, concentrant l’exploration sur les pistes viables.
Noeuds explorés : 209
Solutions trouvées : 15
-> 3*4 puis 2*12 puis 1*24
-> 3*4 puis 2*12 puis 24*1
-> 3*4 puis 2*12 puis 24/1

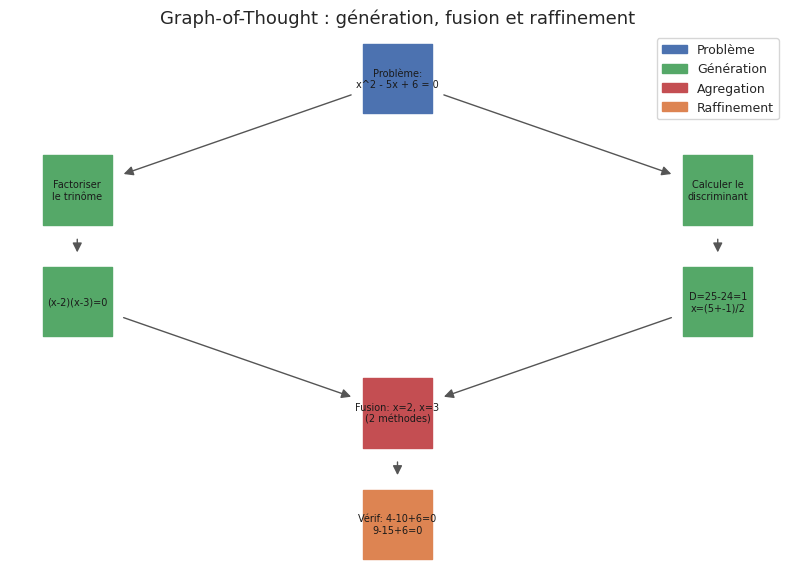
Graph-of-Thought (GoT) et variantes#
L’arbre du ToT impose une structure hiérarchique stricte : chaque pensée a un unique parent. Le Graph-of-Thought relache cette contrainte en autorisant la fusion, le raffinement et la recombinaison de pensées issues de branches différentes.
Définition 35 (Graph-of-Thought (GoT))
Le Graph-of-Thought (Besta et al., 2023) modélise le raisonnement comme un graphe orienté \(G = (V, E)\) où :
Chaque noeud \(v \in V\) représente une pensée (un état intermédiaire du raisonnement).
Chaque arête \((v_i, v_j) \in E\) représente une transformation d’une pensée en une autre.
Trois operations sont definies sur les noeuds :
Génération : produire de nouvelles pensées à partir d’une pensée existante.
Agrégation (merging) : fusionner plusieurs pensées en une synthèse, créant des arêtes convergentes.
Raffinement : améliorer une pensée existante par auto-critique.
A la différence du ToT, le GoT autorise les arêtes convergentes (plusieurs parents pour un noeud), ce qui permet de combiner les informations de plusieurs pistes de raisonnement.
Remarque 40 (Variantes du GoT)
Plusieurs travaux étendent l’idée du GoT. Algorithm of Thoughts (Sel et al., 2023) encode la logique d’exploration (DFS, BFS) directement dans le prompt, guidant le LLM pour qu’il simule l’exploration en un seul appel. Skeleton-of-Thought décompose le problème en sous-questions résolues en parallèle. Cumulative Reasoning valide chaque pensée avant de l’ajouter au graphe de connaissances du problème.
Propriété 9 (Expressivité du GoT)
Le GoT est strictement plus expressif que le ToT : tout arbre est un graphe sans cycle ni arête convergente, mais le GoT autorise en plus (1) les arêtes convergentes (agregation), (2) les boucles (raffinement itératif) et (3) les arêtes de saut (connexion entre noeuds de profondeurs non adjacentes). Cette expressivité supplémentaire permet de représenter des raisonnements où la synthèse de plusieurs sous-résultats est nécessaire.
Remarque 41 (Ancrage et coéerence dans les graphes de pensées)
L’avantage principal du GoT est la capacité de synthèse : fusionner les meilleurs éléments de plusieurs pistes. Cependant, cette fléxibilité introduit un risque de contradiction entre pensées fusionnées. La vérification de cohérence est donc un composant critique, souvent implémentée comme un prompt de validation supplémentaire.
ReAct : raisonner et agir#
Les paradigmes précédents fonctionnent « en vase clos ». ReAct (Yao et al., 2022) rompt cette autarcie en entrelacant raisonnement et action, permettant au modèle d’interagir avec des outils externes.
Définition 36 (ReAct (Reasoning + Acting))
ReAct est un paradigme où le LLM alterne trois types d’étapes :
Thought : le modèle raisonne sur la situation courante et planifie la prochaine action.
Action : le modèle émet une commande vers un outil externe (recherche, calculatrice, API, interpréteur de code).
Observation : le résultat de l’action est retourné au modèle sous forme textuelle.
Le cycle se repète jusqu’à la réponse finale. Formellement :
où \(q\) est la question, \(T_i\) la \(i\)-ème pensée, \(A_i\) la \(i\)-ème action, \(O_i\) la \(i\)-ème observation et \(r\) la réponse.
ReAct est le prototype de la boucle agent (agent loop) qui sera approfondie au chapitre 12. Le modèle n’est plus un système question-réponse statique mais un agent qui perçoit, raisonne et agit dans un environnement.
Propriété 10 (ReAct et ancrage factuel)
Soit \(p_{\text{halluc}}\) la probabilité qu’un LLM produise une réponse factuellement incorrecte. En mode CoT, \(p_{\text{halluc}}\) reste constant à chaque étape. En mode ReAct, chaque observation \(O_i\) fournit une contrainte factuelle qui réduit l’espace des réponses possibles. Expérimentalement, Yao et al. (2022) montrent que ReAct réduit le taux d’hallucination de 20 a 40 % sur les benchmarks de question-réponse multi-sauts (HotpotQA).
Remarque 42 (La boucle d’observation)
La force de ReAct réside dans le fait que les observations corrigent le raisonnement en temps réel. Si le modèle émet une hypothèse erronée, un appel d’outil retourne l’information correcte, et la pensée suivante intègre cette correction. Ce mécanisme d”ancrage factuel (grounding) réduit considérablement les hallucinations.
Exemple 28 (ReAct pour la recherche d’information)
Question : « Quel est le PIB par habitant du pays où est nee Marie Curie ? »
Thought 1: Je dois trouver le pays de naissance de Marie Curie.
Action 1: search("Marie Curie lieu de naissance")
Observation 1: Marie Curie est née a Varsovie, en Pologne.
Thought 2: Marie Curie est née en Pologne. Je cherche le PIB par habitant.
Action 2: search("PIB par habitant Pologne 2024")
Observation 2: Le PIB par habitant de la Pologne est d'environ 22 300 USD.
Thought 3: J'ai les informations nécessaires.
Action 3: finish("Environ 22 300 USD nominal (Pologne).")
Le modèle décompose le problème en sous-questions et utilise un outil de recherche pour chaque étape factuelle.
[ Question] Combien pèse la tour Eiffel par mètre de hauteur ?
[ Thought] Je dois trouver le poids et la hauteur de la tour Eiffel.
[ Action] search("tour Eiffel hauteur")
[Observation] La tour Eiffel mesure 330 m (avec antenne).
[ Thought] 330 m. Maintenant le poids.
[ Action] search("tour Eiffel poids")
[Observation] La structure métallique pèse environ 7 300 tonnes.
[ Thought] 7 300 t / 330 m. Je calcule.
[ Action] calculate(7300 / 330)
[Observation] Resultat : 22.12121212121212
[ Thought] Environ 22,1 t/m. J'ai la réponse.
[ Action] finish("~22,1 tonnes par mètre (7 300 t / 330 m).")

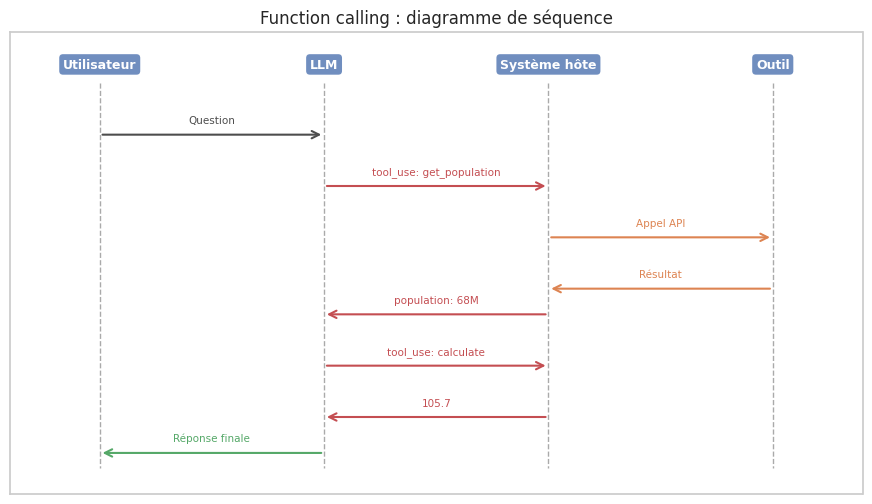
Tool use et function calling#
ReAct démontre l’intérêt d’équiper le LLM d’outils. Les API modernes (Claude, GPT-4, Gemini) formalisent cette idée via le tool use et le function calling.
Définition 37 (Tool use)
Le tool use designe la capacité d’un LLM à : (1) reconnaitre qu’une question nécessite un outil externe, (2) sélectionner l’outil approprié, (3) formuler l’appel dans un format structure (JSON), et (4) intégrer le résultat dans sa réponse. Le LLM n’exécute pas l’outil : il produit une requête d’appel que le système hôte intercepte et exécute.
Définition 38 (Function calling)
Le function calling est l’implémentation concrète du tool use dans les API. Le développeur définit des fonctions via un schéma JSON décrivant le nom, la description en langage naturel et les paramètres (types, contraintes). Lors de l’inférence, le modèle peut choisir d’appeler une ou plusieurs fonctions ; le système hôte exécute et retourne le résultat.
Exemple 29 (Définition d’un outil par JSON Schema)
Voici une définition d’outil typique pour une API de LLM :
{
"name": "get_weather",
"description": "Obtenir la météo actuelle pour une ville donnée.",
"input_schema": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "Nom de la ville"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["city"]
}
}
Le modèle produit alors un appel structure {"type": "tool_use", "name": "get_weather", "input": {"city": "Paris", "unit": "celsius"}}. Le système hôte exécute la fonction et retourne le résultat au modèle.
Remarque 43 (Parallèle tool use et plug-ins)
Le tool use transforme le LLM d’un système fermé en un système augmenté (tool-augmented LLM) qui peut calculer avec précision, accéder à des données actuelles, exécuter du code et intéragir avec des systèmes externes. On peut tracer un parallèle avec les plug-ins dans les logiciels classiques : le LLM est le noyau, et les outils sont des extensions qui lui confèrent des capacités spécifiques sans modifier ses poids.
Exemple 30 (Exécution de code comme outil)
Un LLM equipé d’un interpréteur Python peut résoudre des problèmes numériques :
Thought : Je vais calculer le 50e nombre premier avec un script Python.
Action : execute_python("
primes, n = [], 2
while len(primes) < 50:
if all(n % p for p in primes if p*p <= n): primes.append(n)
n += 1
print(primes[-1])
")
Observation : 229
Réponse : Le 50e nombre premier est 229.
Sans outil de calcul, le LLM aurait probablement halluciné une valeur incorrecte.
[Utilisateur] Densité de population de la France (superficie : 643 801 km2) ?
[Modèle->Outil] {"type": "tool_use", "name": "get_population", "input": {"country": "France"}}
[Outil->Modèle] {"population": 68042591}
[Modèle->Outil] {"type": "tool_use", "name": "calculate", "input": {"expression": "68042591 / 643801"}}
[Outil->Modèle] 105.7
[Modèle] La France : 68,042,591 hab. / 643 801 km2 = 105.7 hab./km2.
Comparaison des paradigmes de raisonnement#
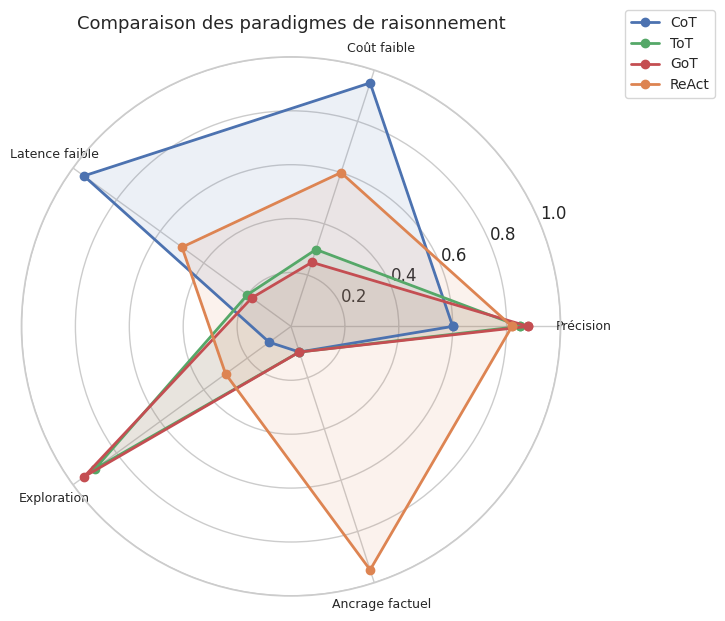
Les paradigmes présentés forment un spectre de stratégies. Le choix depend du compromis entre précision, coût et accès aux informations externes.
Paradigme Structure Exploration Retour arrière Outils Appels LLM Cas d'usage
CoT Chaine Non Non Non 1 Simple
CoT-SC Chaines multiples Echantillonnage Non Non ~k Maths
ToT Arbre BFS/DFS Oui Non ~b^d Puzzles
GoT Graphe BFS/DFS + fusion Oui Non ~b^d + fusions Composites
ReAct Boucle agent Séquentielle Non Oui ~2n QA factuel
Remarque 44 (Guide de choix)
En pratique, la sélection du paradigme dépend de trois facteurs : (1) la nature du problème — un problème combinatoire (puzzle, planification) bénéficie du ToT ou du GoT, un problème factuel du ReAct ; (2) le budget computationnel — le CoT coûte un appel, le ToT des dizaines, ReAct ajoute la latence des outils ; (3) le besoin d’ancrage — si la réponse dépend de données actuelles, le tool use est indispensable. Ces paradigmes sont combinables : un agent ReAct peut utiliser du ToT en interne.
Résumé#
Ce chapitre a présenté les paradigmes de raisonnement avancé qui etendent le Chain-of-Thought linéaire.
Le CoT linéaire souffre de trois limitations : absence d”exploration, de retour arrière et d”ancrage externe.
Le Tree-of-Thought (ToT) structure le raisonnement en arbre de recherche avec générateur, évaluateur et algorithme d’exploration. Il subsume le CoT au prix d’un coût en \(O(b^d)\) appels.
Le Graph-of-Thought (GoT) généralise le ToT en autorisant la fusion et le raffinement de pensées issues de branches différentes.
ReAct entrelace Thought, Action et Observation dans une boucle agent, permettant l’interaction avec des outils externes et l’ancrage factuel.
Le tool use et le function calling formalisent l’integration d’outils dans les API via des schemas JSON.
Le choix du paradigme dépend de la nature du problème, du budget computationnel et du besoin d’ancrage dans des données externes.
Ces paradigmes sont combinables et préfigurent les systèmes agents autonomes — thématique développée dans la partie IV.
Remarque 45
Les paradigmes de raisonnement avancé illustrent le passage du LLM passif vers un système actif qui explore, évalue, agit et s’auto-corrige. Cette évolution brouille la frontière entre modèle de langage et agent intelligent. Comprendre ces paradigmes est essentiel pour concevoir des systèmes LLM robustes, car le choix de la stratégie de raisonnement détermine directement la qualité, le coût et la fiabilité des réponses.