Sécurité et déploiement responsable#
Le chapitre précédent a traité de l’alignement des LLM, c’est-à-dire des techniques visant à faire en sorte que le comportement du modèle corresponde aux intentions de ses concepteurs et aux attentes de ses utilisateurs. Mais l’alignement, aussi soigné soit-il, ne suffit pas à garantir un déploiement sûr et responsable. Un modèle parfaitement aligné au sens du RLHF peut encore halluciner des faits inexistants, générer du contenu préjudiciable dans des cas limités, ou être exploité par des acteurs malveillants. Le passage du laboratoire à la production exige une couche supplémentaire de sécurité — technique, organisationnelle et réglementaire.
Ce chapitre aborde les six facettes de cette sécurité. Nous commencerons par les hallucinations, le problème le plus visible et le plus fréquemment rencontré en pratique : un LLM qui affirme avec assurance des informations fausses. Nous examinerons ensuite le filtrage de contenu, le watermarking du texte généré, le cadre réglementaire européen (EU AI Act), la gouvernance par la documentation, et enfin les bonnes pratiques de déploiement sécurisé en production.
L’approche est délibérément pratique : chaque section combine des définitions rigoureuses, des exemples de code exécutable en Python pur (sans appels à des API externes), et des diagrammes récapitulatifs. Le lecteur trouvera ici les outils conceptuels et techniques nécessaires pour déployer un système fondé sur un LLM de manière responsable.
Hallucinations : détection et mitigation#
Les LLM génèrent du texte en prédisant le token le plus probable conditionnellement aux tokens précédents. Ce mécanisme, purement statistique, n’intègre aucune notion de vérité factuelle. Le modèle ne « sait » pas si ce qu’il affirme est vrai ; il produit la continuation la plus vraisemblable compte tenu de ses données d’entrainement et du contexte. Cette propriété fondamentale est la source des hallucinations.
Définition 102 (Hallucination)
Une hallucination (hallucination) d’un LLM est une génération qui contient des informations fausses, non fondées ou incohérentes avec le contexte fourni, tout en étant présentée avec un niveau de confiance linguistique comparable à celui d’une génération correcte. Formellement, soit \(y = (y_1, \ldots, y_T)\) la séquence générée conditionnellement à un prompt \(x\). On dit que \(y\) contient une hallucination si \(y\) affirme une proposition \(p\) telle que :
\(p\) est factuellement fausse (hallucination factuelle), ou
\(p\) contredit le contexte \(x\) fourni au modèle (hallucination de fidélité), ou
\(p\) est non étayée par les sources accessibles au modèle (hallucination de fondement).
Les hallucinations sont inhérentes à la modélisation auto-régressive : le modèle optimise \(P(y_t \mid y_{<t}, x)\) et non \(P(y_t \text{ est vrai} \mid y_{<t}, x)\).
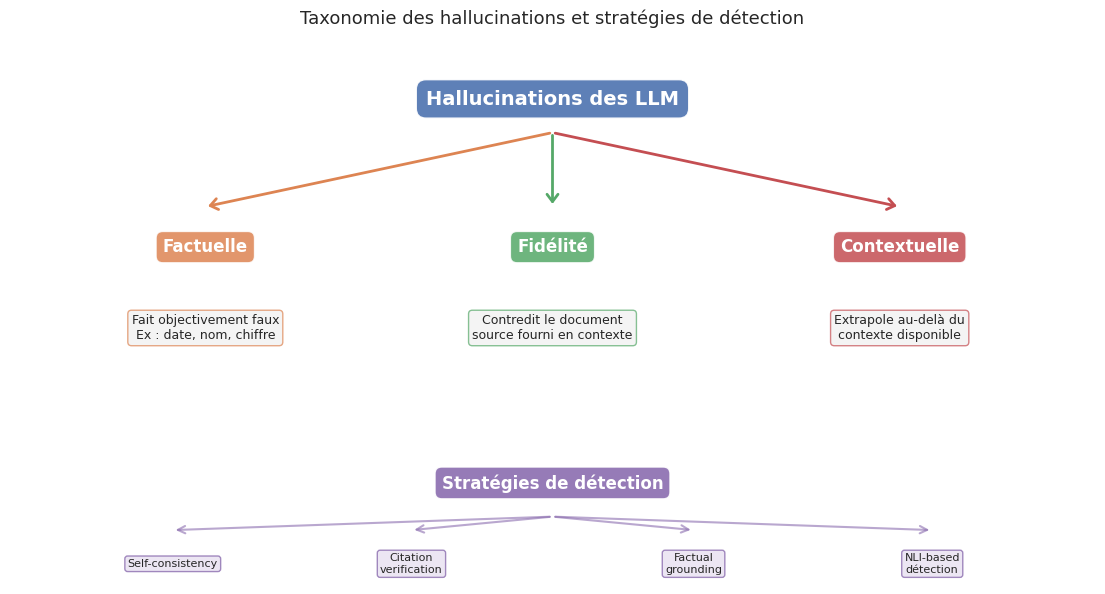
Remarque 99 (Taxonomie des hallucinations)
On distingue trois types principaux d’hallucinations :
Hallucination factuelle (factual hallucination) : le modèle affirme un fait objectivement faux. Exemple : « La tour Eiffel a été construite en 1923 par Gustave Courbet. » Ce type est le plus étudié et le plus facile à détecter automatiquement.
Hallucination de fidélité (faithfulness hallucination) : dans une tâche de résumé ou de QA avec contexte, le modèle génère une réponse qui contredit ou déforme le document source.
Hallucination contextuelle (contextual hallucination) : le modèle extrapole au-delà de ce que le contexte permet de déduire, par exemple en inventant des chiffres pour un trimestre non couvert par un rapport financier fourni.
Les hallucinations factuelles relèvent des connaissances paramétriques du modèle, tandis que les hallucinations de fidélité et contextuelles relèvent du traitement du contexte en entrée.
Définition 103 (Groundedness (fondement))
Le fondement (groundedness) d’une génération \(y\) par rapport à un ensemble de documents sources \(\mathcal{D} = \{d_1, \ldots, d_K\}\) mesure dans quelle mesure chaque affirmation de \(y\) est étayée par au moins un document de \(\mathcal{D}\). On décompose \(y\) en propositions atomiques \(\{p_1, \ldots, p_M\}\) et on définit :
où \(d \vDash p_i\) signifie que le document \(d\) étayé (entails) la proposition \(p_i\). Un score de 1 signifie que toutes les affirmations sont vérifiables ; un score faible signale des hallucinations de fidélité.
Remarque 100 (Stratégies de détection des hallucinations)
Plusieurs stratégies complémentaires permettent de détecter les hallucinations :
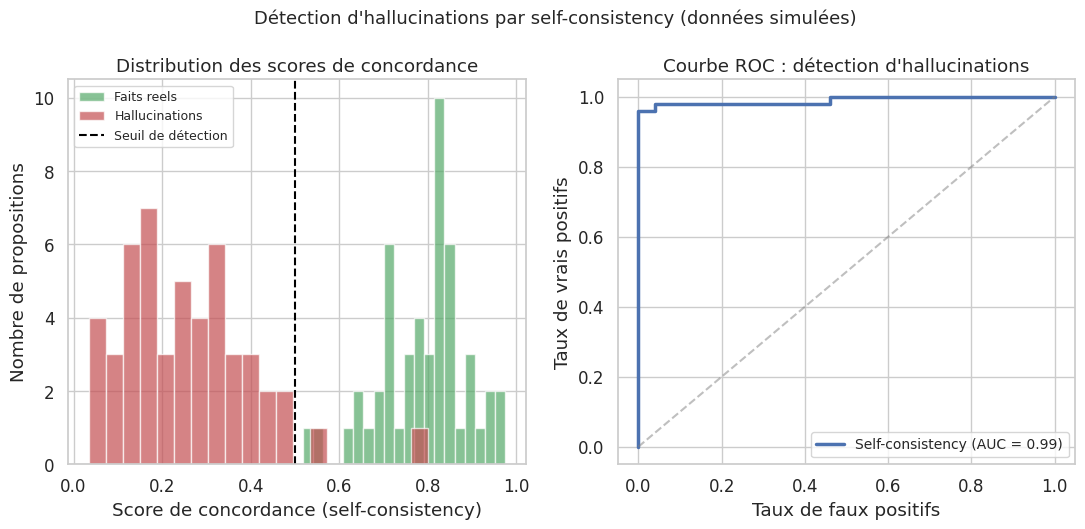
Self-consistency (Wang et al., 2023) : générer \(N\) réponses indépendantes au même prompt et mesurer la concordance. Un fait réel, encodé de manière redondante dans les paramètres, sera reproduit de manière cohérente, tandis qu’un fait inventé variera d’une génération à l’autre.
Vérification de citations : demander au modèle de citer ses sources, puis vérifier automatiquement que les citations existent et supportent les affirmations.
Factual grounding via NLI : utiliser un modèle d’inférence en langage naturel pour vérifier si chaque proposition est impliquée (entailed) par les documents sources. Un verdict de contradiction signale une hallucination.
Chain-of-Verification (Dhuliawala et al., 2023) : le modèle génère une réponse, produit des questions de vérification sur ses propres affirmations, y répond indépendamment, puis révise sa réponse initiale.
Aucune de ces strategies n’est parfaite ; une défense en profondeur combinant plusieurs approches est recommandée.
Exemple 71 (Détection d’hallucinations par self-consistency)
La méthode de self-consistency génère plusieurs réponses et mesure leur concordance :
def detect_hallucination_self_consistency(responses, threshold=0.5):
"""Detecte les hallucinations par self-consistency."""
n = len(responses)
scores = []
for i in range(n):
for j in range(i + 1, n):
words_i = set(responses[i].lower().split())
words_j = set(responses[j].lower().split())
if len(words_i | words_j) > 0:
overlap = len(words_i & words_j) / len(words_i | words_j)
scores.append(overlap)
concordance = np.mean(scores) if scores else 0.0
return {"concordance": concordance,
"hallucination_probable": concordance < threshold}
Les principales stratégies de mitigation des hallucinations sont : le RAG (fournir des documents sources dans le contexte, chapitre 10), la chain-of-verification (auto-vérification des affirmations), la temperature basse (réduire la variance des générations) et le fine-tuning sur la calibration (entrainer le modèle à exprimer son incertitude).
Filtrage de contenu#
Même un modèle bien aligné peut générer du contenu indésirable : discours de haine, instructions dangereuses, contenu explicite, désinformation. Le filtrage de contenu constitue une couche de défense indépendante de l’alignement, opérant en amont (filtrage des entrées) et en aval (filtrage des sorties).
Définition 104 (Filtre de contenu)
Un filtre de contenu (content filter) est une fonction \(f : \mathcal{X} \to \{0, 1\}^C\) qui associe à un texte \(x\) un vecteur binaire de \(C\) catégories de contenu (violence, haine, sexuel, illégal, auto-mutilation). En pratique, le filtre produit des scores continus \(s_c(x) \in [0, 1]\) et un seuil \(\tau_c\) détermine la décision :
Le choix des seuils \(\tau_c\) détermine le compromis entre précision (éviter de bloquer du contenu légitime) et rappel (bloquer tout contenu problématique).
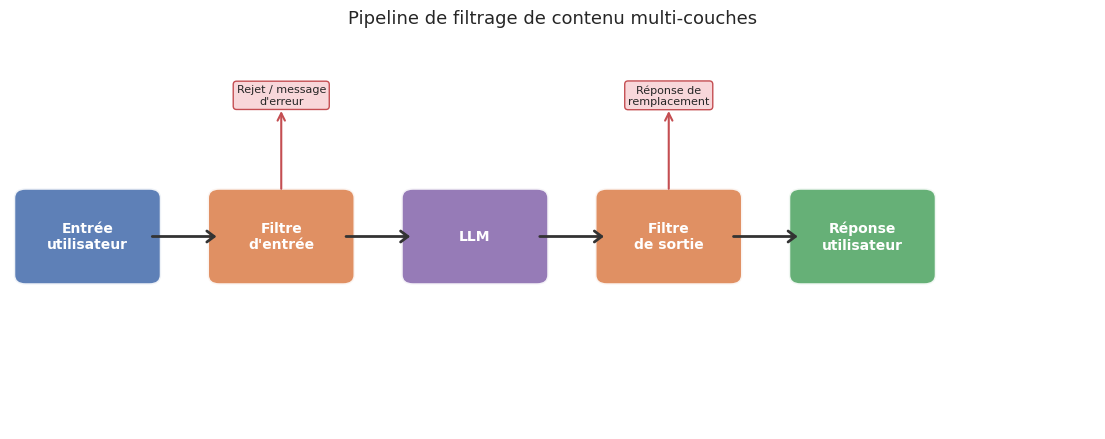
Les deux grandes familles d’approches sont les approches par classifieur (un Transformer fine-tune détecte les catégories problématiques — OpenAI Moderation API, LLaMA Guard) et les approches par règles (expressions régulières, listes de mots-clés). En pratique, les systèmes de production combinent les deux en cascade : un filtre par règles rapide effectue un premier tri, suivi d’un classifieur plus précis sur les cas ambigus.
Watermarking du texte généré#
A mesure que les LLM génèrent du texte indistinguable du texte humain, la question de la traçabilite devient cruciale. Le watermarking consiste à introduire un signal statistique imperceptible dans le texte généré, permettant de détecter à posteriori qu’un texte a été produit par un modèle spécifique.
Définition 105 (Watermarking de texte LLM)
Le watermarking (tatouage numérique) du texte généré par un LLM modifie le processus de génération pour introduire un signal statistique détectable mais imperceptible. L’approche de Kirchenbauer et al. (2023) fonctionne comme suit :
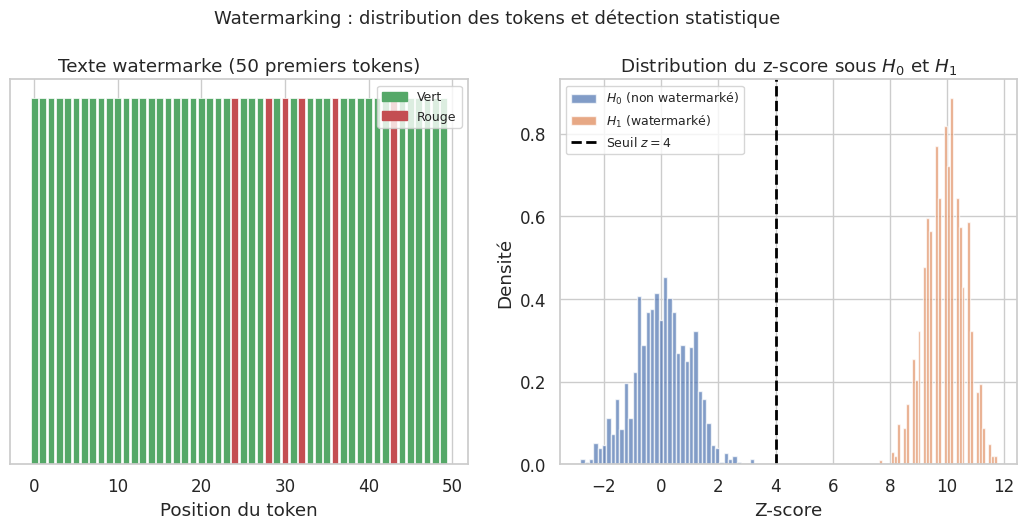
Partition du vocabulaire : pour chaque token \(y_t\), le token précédent \(y_{t-1}\) sert de graine à un PRNG qui partitionne \(\mathcal{V}\) en une liste verte \(G_t\) (\(\gamma |\mathcal{V}|\) tokens, \(\gamma \approx 0{,}5\)) et une liste rouge \(R_t = \mathcal{V} \setminus G_t\).
Biais de génération : un biais \(\delta > 0\) est ajouté aux logits des tokens verts :
Le texte watermarké contient donc une proportion de tokens verts significativement supérieure a \(\gamma\).
Propriété 23 (Détection du watermark par z-test)
Soit \(T\) le nombre de tokens et \(|G|\) le nombre de tokens verts observés. Sous \(H_0\) (texte non watermarké), chaque token a une probabilité \(\gamma\) d’être vert. Le z-score :
mesure l’écart à l’attendu. Un \(z > 4\) (soit \(p < 3 \times 10^{-5}\)) indique avec forte confiance que le texte est watermarké. La puissance du test croit avec \(T\) : plus le texte est long, plus le watermark est facile à détecter.
Tokens verts (watermarke) : 183/200 = 91.5%
Tokens verts (sans watermark) : 109/200 = 54.5%
Watermarké | verts: 91.5% | z = 11.74 | p = 0.00e+00 | WATERMARK DETECTE
Non watermarké | verts: 54.5% | z = 1.27 | p = 1.02e-01 | Pas de watermark
Exemple 72 (Démonstration du watermarking)
Le mécanisme de Kirchenbauer biaise la distribution de probabilité des tokens. Pour chaque position, le vocabulaire est divisé en tokens « verts » et « rouges » à partir du token précédent :
green_list, red_list = create_green_red_lists(
prev_token_id=42, vocab_size=1000, gamma=0.5
)
# Le biais delta = 2.0 augmente la probabilité des tokens verts
# sans rendre la génération perceptiblement différente pour un
# lecteur humain.
La robustesse du watermark dépend de la longueur du texte : avec \(T = 200\) tokens et \(\delta = 2{,}0\), le z-score est typiquement supérieur a 10. Pour des textes très courts (\(T < 25\)), la puissance du test est insuffisante.
Les limites du watermarking incluent : (1) la fragilité face à la paraphrase — un texte watermarké peut perdre son signal après reformulation par un autre LLM ; (2) l’impossibilité de watermarker des textes très courts ; (3) le risque de dégradation de la qualité si \(\delta\) est trop élevé ; (4) les questions éthiques liées à la surveillance. Néanmoins, le watermarking reste l’une des rares techniques permettant une détection fiable du texte généré par un LLM spécifique.
Cadre réglementaire : EU AI Act et LLM#
L’Union européenne a adopté en 2024 le AI Act (Règlement sur l’intelligence artificielle), premier cadre réglementaire complet au monde pour l’IA. Ce règlement, entrant en vigueur progressivement entre 2024 et 2027, a des implications directes pour les développeurs et déployeurs de LLM.
Définition 106 (AI Act et classification des risques)
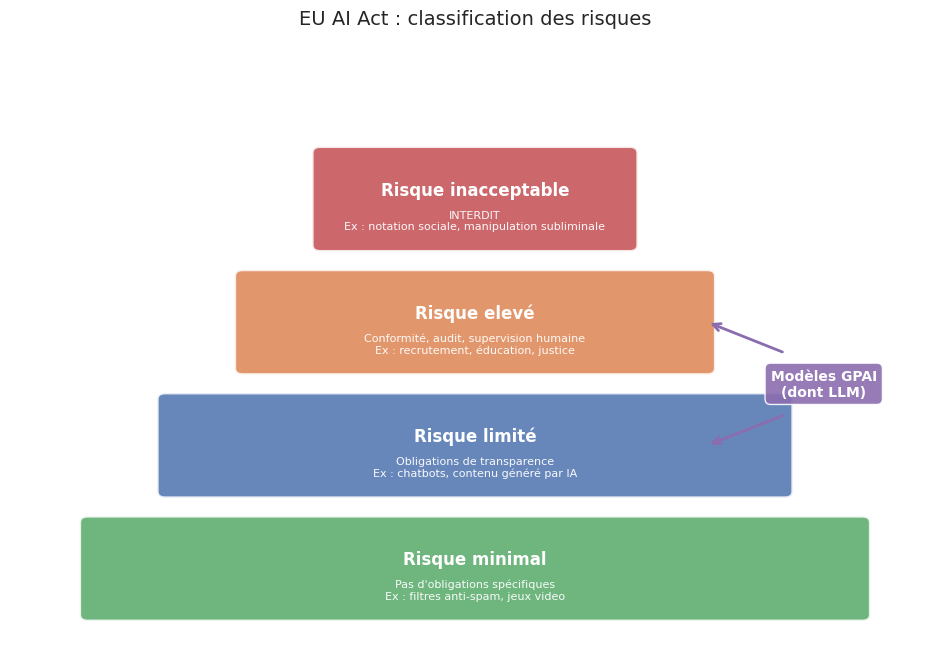
L”EU AI Act (Règlement (UE) 2024/1689) établit un cadre fondé sur une classification par niveaux de risque :
Risque inacceptable : systèmes interdits. Exemples : notation sociale, manipulation subliminale, identification biométrique à distance en temps réel (sauf exceptions).
Risque élevé : obligations strictes avant mise sur le marché. Exemples : IA dans le recrutement, l’éducation, la justice. Obligations : évaluation de conformité, gestion des risques, gouvernance des données, transparence, supervision humaine, robustesse.
Risque limité : obligations de transparence. Exemples : chatbots, systèmes génératifs. L’utilisateur doit être informé qu’il interagit avec une IA.
Risque minimal : pas d’obligations spécifiques. Exemples : filtres anti-spam, jeux video.
Les modèles GPAI (General-Purpose AI), dont les LLM, font l’objet de dispositions spécifiques (Titre VIII bis) avec des obligations proportionnées à leur impact.
Exemple 73 (Obligations spécifiques aux LLM selon l’AI Act)
Obligations pour tous les modèles GPAI :
Documentation technique détaillée (architecture, données d’entrainement, évaluations)
Politique de respect du droit d’auteur européen
Résumé détaillé des données d’entrainement
Désignation d’un représentant dans l’UE pour les fournisseurs hors-UE
Obligations supplémentaires pour les modèles à risque systémique (\(> 10^{25}\) FLOPs) :
Evaluations de modèle conformes à des protocoles standardisés
Evaluation et mitigation des risques systémiques
Tests adversariaux (red-teaming, chapitre 17)
Notification des incidents graves à la Commission européenne
Garanties de cybersécurité et reporting energétique
Le seuil de \(10^{25}\) FLOPs correspond approximativement à un modèle de la taille de GPT-4. Les modèles open-source bénéficient d’exemptions partielles, sauf s’ils présentent un risque systémique.
Remarque 101 (Checklist de conformité)
Pour un déploiement de LLM conforme a l’AI Act :
Le système est-il classé à risque élevé ? Si oui, évaluation de conformité obligatoire.
L’utilisateur est-il informé qu’il interagit avec une IA ?
Le contenu généré par IA est-il étiqueté comme tel ?
Une documentation technique est-elle disponible (model card, datasheet) ?
Les données d’entrainement respectent-elles le droit d’auteur europeen ?
Un mécanisme de supervision humaine est-il en place ?
Les risques de biais et de discrimination ont-ils été évalués ?
Le modèle a-t-il fait l’objet de tests adversariaux (red-teaming) ?
La consommation énergétique est-elle documentée ?
Cette checklist constitue un point de départ, non un substitut à une analyse de conformité complète.
Gouvernance et documentation#
La gouvernance des systèmes d’IA repose sur une documentation rigoureuse et standardisée. Trois instruments sont devenus des standards de fait : les model cards, les datasheets for datasets et les évaluations d’impact.
Exemple 74 (Model card pour un LLM)
Une model card (Mitchell et al., 2019) accompagne un modèle d’IA et décrit : (1) détails du modèle (architecture, taille, date), (2) utilisation prévue et hors périmètre, (3) métriques et évaluations, (4) données d’entrainement, (5) biais connus, (6) limites. Exemple :
# Model Card : MonLLM-7B
## Détails
- Transformer décodeur, 32 couches, d_model = 4096, 7.2B paramètres
- Entrainement : 2T tokens (70% EN, 15% FR, 15% autres)
## Utilisation prévue
- Génération de texte, résumé, QA
- NON recommandé : diagnostic médical, conseil juridique
## Evaluations
- MMLU : 62.4% | HumanEval : 35.2% | TruthfulQA : 48.1%
La documentation couvre trois niveaux : modèle (model card), données (datasheet for datasets, Gebru et al., 2021) et système (évaluation d’impact sur les droits fondamentaux). La traçabilité complète constitue le registre d’audit (audit trail), essentiel pour la responsabilité et la conformité réglementaire.
Déploiement sécurisé en production#
Le déploiement d’un LLM en production dépasse la mise à disposition d’un endpoint API. Un système robuste nécessite une architecture de sécurité multicouche couvrant le contrôle d’accès, la surveillance, la gestion des incidents et la supervision humaine.
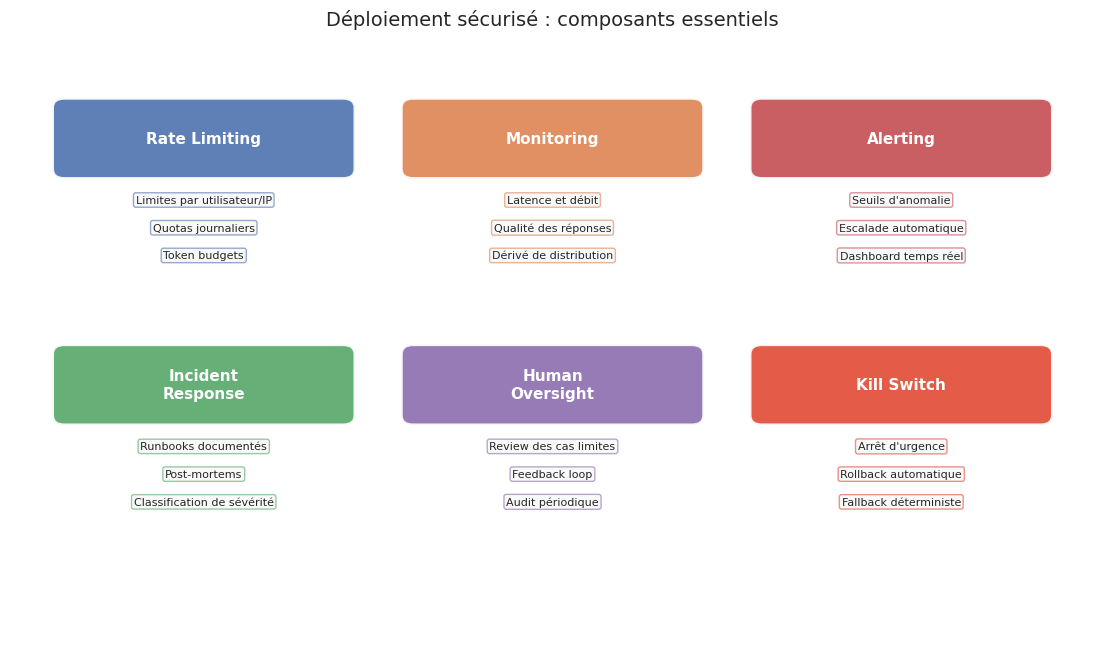
Rate limiting. Le contrôle du débit protège contre les abus et maitrise les coûts. Les limites sont définies par utilisateur, par clé API, par IP et par fenêtre temporelle. Un budget en tokens complète les limites en nombre de requêtes.
Monitoring. La surveillance couvre les métriques techniques (latence, débit, taux d’erreur) et les métriques de qualité (toxicité, hallucinations, satisfaction). La dérivé de distribution des requêtes peut signaler une tentative d’exploitation.
Alerting. Des alertes automatiques se déclenchent lorsque les métriques dépassent des seuils prédéfinis, avec escalade documentée.
Incident response. Un plan documente les procédures en cas de défaillance. Chaque incident fait l’objet d’un post-mortem analysant les causes racines.
Human oversight. La supervision humaine (exigence de l’AI Act pour les systèmes à risque élevé) prend la forme de revues manuelles des cas limites, de boucles de feedback et d’audits périodiques.
Kill switch. Un mécanisme d’arrêt d’urgence permet de désactiver le système en quelques secondes. Le mode dégradé remplace les réponses du LLM par des réponses prédefinies ; le rollback automatique revient à une version antérieure.
Résumé#
Ce chapitre a présenté les six facettes de la sécurité et du déploiement responsable des LLM.
Les hallucinations sont un comportement inhérent aux LLM, qui génèrent du texte statistiquement probable plutôt que factuellement vrai. On distingue les hallucinations factuelles, de fidélité et contextuelles. Les stratégies de détection incluent la self-consistency, la vérification de citations et le factual grounding par NLI. Les mitigations principales sont le RAG, la chain-of-verification et la réduction de la température.
Le filtrage de contenu constitue une couche de défense indépendante de l’alignement. Un pipeline complet comporte un filtrage en entrée, un filtrage en sortie et une classification thématique. Les approches par classifieur et par règles se complètent dans une architecture en cascade.
Le watermarking de Kirchenbauer et al. (2023) biaise la génération vers des tokens « verts » déterminés par le token précédent. La détection repose sur un z-test mesurant l’excès de tokens verts. La puissance du test croit avec la longueur du texte, mais le watermark est fragile face à la paraphrase.
L”EU AI Act (2024) établit un cadre réglèmentaire fondé sur quatre niveaux de risque (inacceptable, élevé, limité, minimal). Les modèles GPAI font l’objet d’obligations de documentation, de transparence et, au-delà de \(10^{25}\) FLOPs, d’évaluations de risque systémique et de red-teaming.
La gouvernance repose sur trois piliers documentaires : les model cards (niveau modèle), les datasheets for datasets (niveau données) et les évaluations d’impact (niveau système). Le registre d’audit assure la traçabilite des décisions à chaque étape du cycle de vie.
Le déploiement sécurisé exige une architecture multicouche : rate limiting, monitoring, alerting avec escalade, plan de réponse aux incidents, supervision humaine et kill switch. La dérivé de distribution des requêtes doit être surveillée comme indicateur précoce de tentatives d’exploitation.
La sécurité des LLM est un problème de défense en profondeur : aucune couche unique (alignement, filtrage, watermarking, réglementation) ne suffit à elle seule. C’est la combinaison de mesures techniques, organisationnelles et réglementaires qui permet un déploiement responsable.