Multimodalité#
Les chapitres précédents ont traité les LLM comme des machines textuelles : ils reçoivent du texte, produisent du texte, raisonnent sur du texte. Or les humains sont fondamentalement multimodaux — nous percevons le monde simultanément par la vision, l’audition, le toucher et le langage, et nous intégrons ces flux d’information en permanence pour comprendre et agir. Un médecin qui lit une radiographie combine l’image et le texte du rapport clinique ; un étudiant apprend d’un cours en combinant la parole, les diapositives et les notes écrites.
Depuis 2021, une serie d’avancées majeures a permis d’étendre les modèles de langage au-delà du texte, vers des architectures capables de traiter et de générer des images, de l’audio, de la vidéo et d’autres modalités. Cette évolution, amorcée par CLIP et DALL-E, a transformé le paysage de l’IA : les modèles les plus avances aujourd’hui — GPT-4o, Claude 3.5 Sonnet, Gemini 1.5 — sont nativement multimodaux.
Ce chapitre présente les fondations de la multimodalité dans le contexte des LLM. Nous étudierons CLIP et l’apprentissage contrastif texte-image, les architectures vision-langage (LLaVA, Flamingo, GPT-4V), les modèles audio (Whisper), les architectures unifiées et les principales applications multimodales. Nous ne chargeons aucun modèle multimodal complet (trop volumineux pour 8 Go de RAM), mais illustrons chaque concept par des calculs exécutables et des visualisations.
Vers des modèles multimodaux#
L’extension des modèles de langage à d’autres modalités répond à une double motivation. D’une part, de nombreuses tâches réelles ne peuvent pas être résolues par le texte seul : comprendre une photographie, transcrire de la parole, analyser un document PDF contenant des tableaux et des figures. D’autre part, l’intégration de plusieurs modalités permet un apprentissage plus riche — un modèle qui voit une image de chat accompagnée du mot « chat » apprend une représentation plus robuste que s’il ne voyait que l’image ou que le mot.
Définition 115 (Modèle multimodal)
Un modèle multimodal est un modèle d’apprentissage profond capable de traiter et/ou de générer des données provenant de plusieurs modalités (texte, image, audio, video, etc.) au sein d’une même architecture. Formellement, étant donné des entrées provenant de \(K\) modalités \(\{x^{(1)}, x^{(2)}, \ldots, x^{(K)}\}\), le modèle apprend une fonction \(f : \mathcal{X}^{(1)} \times \cdots \times \mathcal{X}^{(K)} \to \mathcal{Y}\) qui intègre l’information de toutes les modalités pour produire une sortie \(y\) dans un espace cible. L’enjeu central est l”alignement des représentations entre modalités : comment garantir qu’une image de chat et le texte « un chat assis sur un canapé » soient proches dans un espace de représentation commun ?
Les principales applications multimodales se regroupent en quatre catégories : la compréhension image-texte (image captioning, VQA, classification zero-shot), la compréhension de documents (factures, articles scientifiques, rapports médicaux), la parole et l’audio (ASR, traduction vocale), et la génération multimodale (DALL-E, Midjourney, Stable Diffusion).
Remarque 111
L’un des apports majeurs des modèles multimodaux est le transfert zero-shot entre modalités. Un modèle comme CLIP, entrainé sur des paires (image, texte), peut classifier des images dans des catégories qu’il n’a jamais vues explicitement pendant l’entrainement, simplement en comparant l’embedding de l’image avec les embeddings des descriptions textuelles des catégories. Ce paradigme élimine le besoin de datasets annotés spécifiques à chaque tâche, ce qui constitue un changement radical par rapport aux approches supervisées classiques.
CLIP : apprentissage contrastif texte-image#
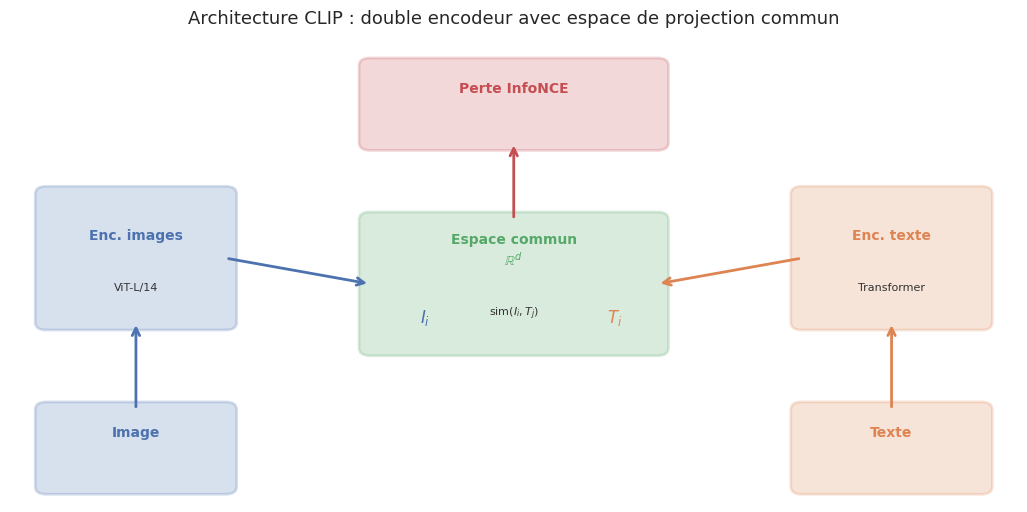
Le modèle CLIP (Contrastive Language-Image Pre-training, Radford et al., 2021) est un point tournant dans l’histoire des modèles multimodaux. Son principe est élégant : entrainer conjointement un encodeur d’images et un encodeur de texte pour que les paires (image, légende) correspondantes soient proches dans un espace de représentation commun, tandis que les paires non correspondantes sont éloignées.
Définition 116 (CLIP (Contrastive Language-Image Pre-training))
CLIP est un modèle multimodal composé de deux encodeurs entrainés conjointement :
Encodeur d’images \(f_I : \mathcal{I} \to \mathbb{R}^d\) — un Vision Transformer (ViT) ou un ResNet qui transforme une image en un vecteur d’embedding de dimension \(d\).
Encodeur de texte \(f_T : \mathcal{T} \to \mathbb{R}^d\) — un Transformer textuel qui transforme une légende en un vecteur d’embedding de même dimension \(d\).
Les deux encodeurs projettent leurs sorties dans un espace de représentation commun de dimension \(d\) (typiquement \(d = 512\) ou \(d = 768\)). L’entrainement utilise un corpus de 400 millions de paires (image, légende) collectées sur le web.
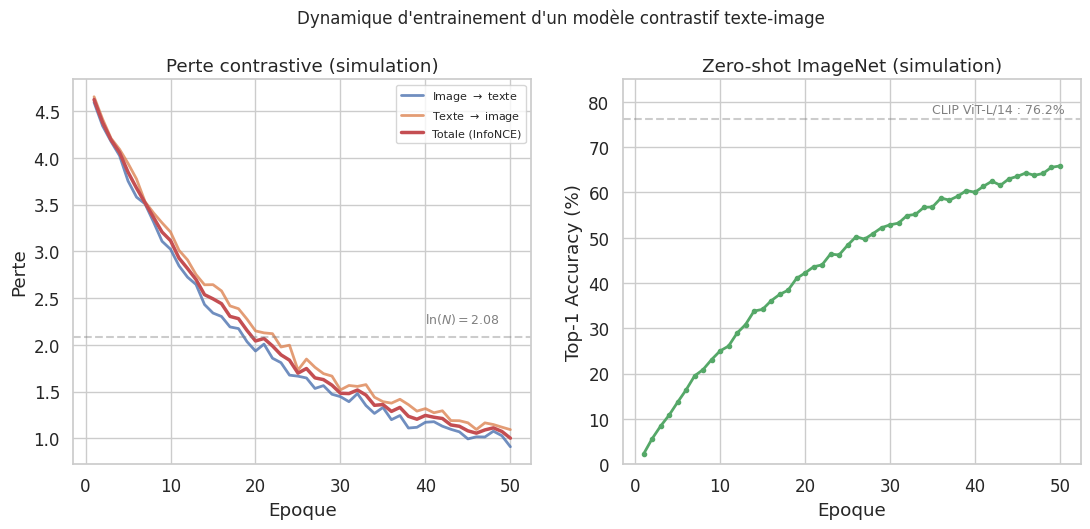
Définition 117 (Perte contrastive (InfoNCE))
La perte contrastive de CLIP, aussi appelée InfoNCE loss, est définie pour un batch de \(N\) paires (image, texte) comme :
où \(I_i = f_I(\text{image}_i)\) et \(T_i = f_T(\text{texte}_i)\) sont les embeddings normalisés, \(\text{sim}(a, b) = a^\top b / (\|a\| \cdot \|b\|)\) est la similarité cosinus, et \(\tau > 0\) est un paramètre de température appris. Le premier terme est la perte image-vers-texte et le second est la perte texte-vers-image.
Définition 118 (Encodeur visuel (Vision Encoder))
Un encodeur visuel (vision encoder) est un réseau de neurones qui transforme une image brute \(x \in \mathbb{R}^{H \times W \times 3}\) en une représentation vectorielle \(\mathbf{h} \in \mathbb{R}^d\). Dans le contexte de CLIP, l’encodeur visuel est généralement un Vision Transformer (ViT) qui découpe l’image en patchs de taille \(p \times p\) (typiquement \(14 \times 14\) ou \(16 \times 16\)), traite chaque patch comme un « token visuel » et applique un Transformer standard. Pour une image de \(224 \times 224\) pixels avec des patchs de \(16 \times 16\), on obtient \((224/16)^2 = 196\) tokens visuels, auxquels on ajoute un token [CLS] dont la représentation finale sert d’embedding global de l’image.
Définition 119 (Espace de projection commun)
L”espace de projection commun (joint embedding space) est un espace vectoriel \(\mathbb{R}^d\) dans lequel les représentations d’images et de textes cohabitent. Chaque encodeur possède une couche de projection linéaire :
où \(W_I \in \mathbb{R}^{d \times d_I}\), \(W_T \in \mathbb{R}^{d \times d_T}\) sont les matrices de projection. Apres projection, les embeddings sont normalisés (\(\|I_i\| = \|T_i\| = 1\)) de sorte que la similarité cosinus se réduit à un simple produit scalaire.
L’intuition derrière la perte contrastive est simple : dans un batch de \(N\) paires, chaque image doit être associée à son texte et à aucun autre. La matrice de similarité \(S \in \mathbb{R}^{N \times N}\), ou \(S_{ij} = \text{sim}(I_i, T_j)\), doit idéalement être une matrice diagonale.
Taille du batch : 8
Température : 0.07
Perte image -> texte : 0.2782
Perte texte -> image : 0.1624
Perte totale (InfoNCE) : 0.2203
Perte théorique (batch parfaitement aligné) : 2.0794
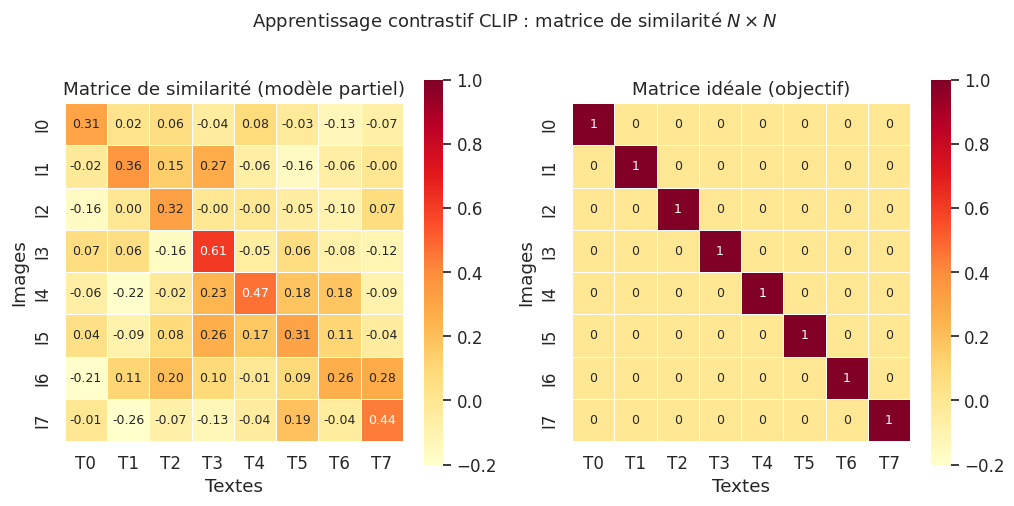
Exemple 77 (Classification zero-shot avec CLIP)
La force de CLIP réside dans la classification zero-shot : classer une image dans des catégories arbitraires sans aucun entrainement spécifique. L’idée est de créer des « prompts textuels » pour chaque catégorie, puis de sélectionner celle dont l’embedding est le plus similaire à celui de l’image.
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
image = Image.open("photo_chat.jpg")
categories = ["a photo of a cat", "a photo of a dog",
"a photo of a car", "a photo of a house"]
inputs = processor(text=categories, images=image,
return_tensors="pt", padding=True)
outputs = model(**inputs)
probs = outputs.logits_per_image.softmax(dim=1)
for cat, p in zip(categories, probs[0]):
print(f" {cat}: {p.item():.3f}")
Le modele CLIP (clip-vit-base-patch32) pèse environ 600 Mo. Pour des raisons de mémoire, cet exemple n’est pas exécuté dans le notebook.
Propriété 27 (Lois d’echelle de CLIP)
Radford et al. (2021) ont montré que les performances zero-shot de CLIP suivent des lois d’échelle similaires à celles des LLM textuels :
Echelle du modèle : augmenter la taille de l’encodeur visuel (de ViT-B/32 a ViT-L/14) améliore les performances sur ImageNet zero-shot (de 63 % a 76 %).
Echelle des données : passer de 15 millions a 400 millions de paires (image, texte) apporte des gains continus.
Qualité des données : la qualité et la diversité des légendes sont aussi importantes que la quantité. Le corpus WIT (WebImageText) de 400M de paires est un facteur clé du succès de CLIP.
Modèles vision-language#
CLIP est un modèle d”alignement : il apprend à mettre en correspondance images et textes dans un espace commun, mais ne génère pas de texte. Les modèles vision-language (Vision-Language Models, VLM) vont plus loin en combinant un encodeur visuel avec un LLM génératif, permettant de répondre à des questions sur des images, de dŕcrire des scènes et de raisonner visuellement.
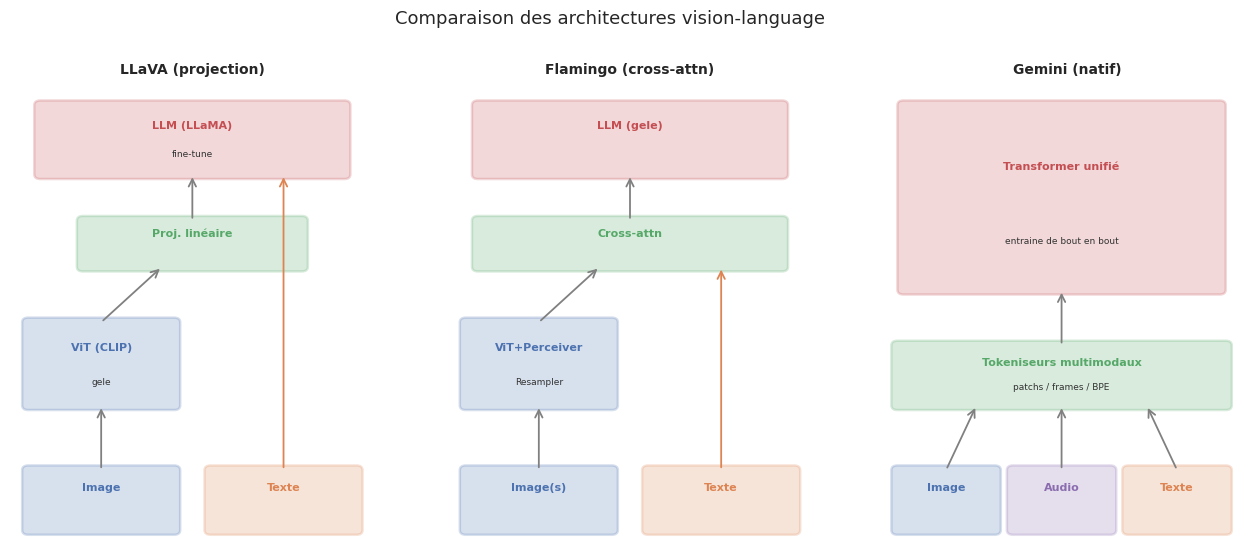
Exemple 78 (Architectures vision-language)
Modèle |
Architecture |
Intégration visuelle |
Année |
|---|---|---|---|
Flamingo |
NFNet/ViT + Chinchilla |
Cross-attention (Perceiver Resampler) |
2022 |
LLaVA |
ViT (CLIP) + LLaMA/Vicuna |
Projection linéaire des tokens visuels |
2023 |
GPT-4V |
Encodeur visuel + GPT-4 |
Non publié (probablement cross-attention) |
2023 |
Claude 3/3.5 |
Encodeur visuel + Claude |
Non publié |
2024 |
Gemini |
Encodeur multimodal natif |
Tokenisation native image/audio/video |
2023 |
Deux grandes strategies se dégagent :
Adapter-based (LLaVA, Flamingo) : un encodeur visuel pré-entrainé (souvent CLIP ViT) est connecté à un LLM via une couche de projection ou un module d’attention croisée.
Native multimodal (Gemini) : le modèle est entrainé dès le départ sur des données multimodales, sans séparation nette entre encodeur visuel et LLM.
Remarque 112
L’approche Visual Instruction Tuning (Liu et al., 2023), qui sous-tend LLaVA, consiste à générer des données d’entrainement en utilisant GPT-4 pour produire des paires (image + question, réponse détaillée) à partir de légendes et de boites englobantes. LLaVA-1.5 atteint des performances compétitives avec seulement 600k exemples d’instruction tuning, contre des milliards de paires pour CLIP. L’insight clé est que la majeure partie de la compréhension visuelle est déjà encodée dans le ViT pré-entrainé ; il suffit d’apprendre à « traduire » les tokens visuels dans le langage du LLM.
Remarque 113
Les modèles vision-language souffrent d”hallucinations visuelles : ils peuvent affirmer avec confiance la présence d’objets absents de l’image, inventer des détails ou ignorer des éléments visibles. Les benchmarks d’hallucination visuelle (POPE, CHAIR) montrent que même les meilleurs modèles (GPT-4V, Claude 3.5) hallucinent dans 5 à 15 % des cas. Les causes incluent les biais du LLM génératif (qui « invente » par défaut), le manque de résolution de l’encodeur visuel et les données d’entrainement bruitées.
Modèles audio et speech#
La parole est la modalité de communication la plus naturelle pour l’être humain. L’intégration de la compréhension audio dans les modèles multimodaux permet la transcription automatique, la traduction vocale et l’intéraction vocale directe avec les LLM.
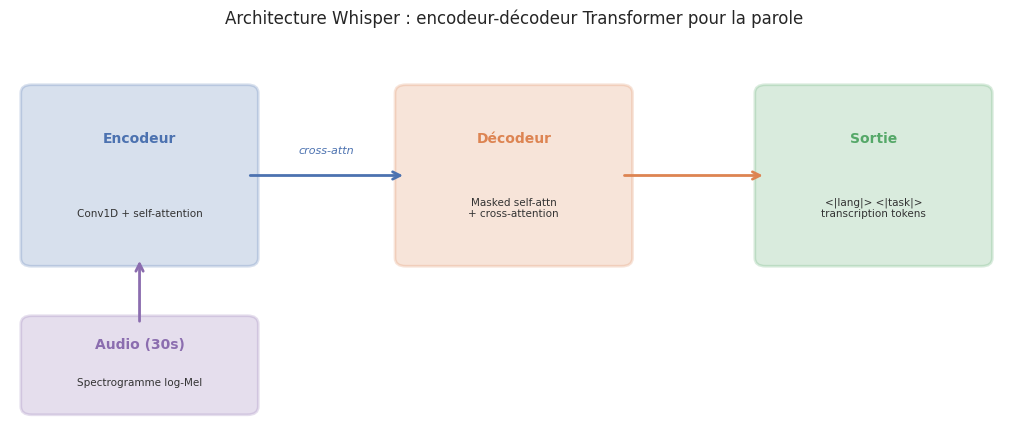
Définition 120 (Whisper (modèle de reconnaissance vocale))
Whisper (Radford et al., 2022) est un modèle de reconnaissance automatique de la parole (ASR) développé par OpenAI, fondé sur une architecture encodeur-decodeur Transformer :
Encodeur audio : transforme un spectrogramme log-Mel de 30 secondes (80 bandes \(\times\) ~3000 frames) en représentations contextuelles.
Décodeur textuel : génère la transcription de manière auto-régressive.
Multitâche : transcription, traduction, détection de langue et détection d’activité vocale, via des tokens spéciaux.
Données : 680 000 heures d’audio supervisé, 96 langues.
Tailles : de 39M (Tiny) a 1,5B (Large-v3) paramètres.
Exemple 79 (Utilisation de Whisper)
import whisper
model = whisper.load_model("base") # ~140 Mo
result = model.transcribe("audio.mp3")
print(result["text"])
print(result["language"])
for segment in result["segments"]:
print(f"[{segment['start']:.1f}s - {segment['end']:.1f}s] {segment['text']}")
Whisper base (74M paramètres, ~140 Mo) tourne sur CPU. Les modèles large-v3 (1,5B) offrent une qualité quasi humaine mais nécessitent un GPU.
Remarque 114
L’approche de Whisper est fondamentalement différente des systèmes ASR précédents (DeepSpeech, Wav2Vec 2.0) qui utilisaient des architectures encodeur seul avec un décodage CTC (Connectionist Temporal Classification). En adoptant l’architecture encodeur-décodeur et en entrainant sur des données massives et diversifiées, Whisper atteint une robustesse remarquable face au bruit, aux accents et aux conditions d’enregistrement variées. Les modèles recents (GPT-4o, Gemini 1.5) integrent nativement la compréhension audio, étendant les capacités de Whisper au raisonnement et à la compréhension du ton et des émotions.
Architectures unifiées#
Les premières approches multimodales (CLIP, LLaVA) étaient modulaires : un encodeur spécialisé par modalité, connecté à un LLM par une couche de projection ou d’attention croisée. Les architectures récentes tendent vers des modèles unifiés capables de traiter plusieurs modalités nativement.
Remarque 115
La distinction entre architectures modulaires (adapter-based) et unifiées (native multimodal) a des conséquences profondes. L’approche modulaire permet de réutiliser des composants pré-entrainés (CLIP ViT, LLaMA) et de ne fine-tuner que la couche de connexion, à moindre coût. L’approche unifiée apprend dès le départ à intégrer toutes les modalités dans une représentation commune — l’alignement est plus profond mais l’entrainement est beaucoup plus coûteux. Gemini (Google, 2023) est le premier modèle à grande échelle à adopter cette approche nativement.
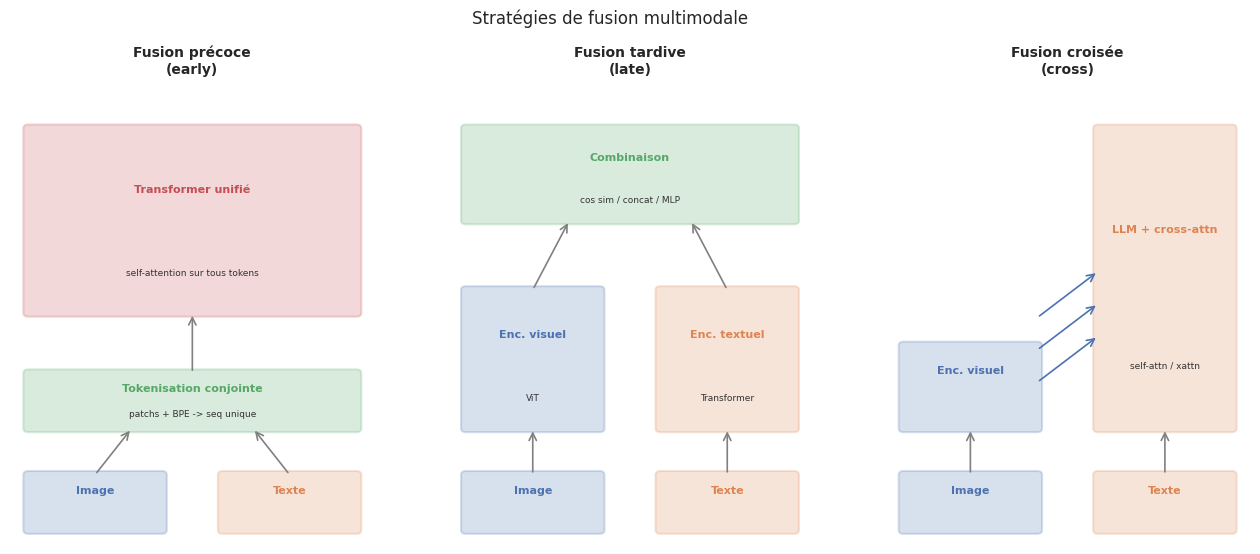
Les trois grandes stratégies de fusion entre modalités sont la fusion précoce (early fusion — tokenisation et concaténation de toutes les modalités avant le Transformer, approche de Gemini), la fusion tardive (late fusion — encodeurs indépendants combinés en sortie, approche de CLIP), et la fusion croisée (cross fusion — attention croisée à différents niveaux de profondeur, approche de Flamingo).
Remarque 116
Le choix entre fusion précoce, tardive et croisée implique un compromis fondamental. La fusion précoce permet les intéractions les plus riches entre modalités (chaque token visuel peut « voir » chaque token textuel des la première couche) mais requiert un entrainement multimodal de bout en bout extrêmement coûteux. La fusion tardive est la plus modulaire mais l’intéraction entre modalités est limitée à la couche finale. La fusion croisée offre un compromis intermédiaire, permettant une intéraction profonde tout en conservant des encodeurs spécialisés.
Applications multimodales#
Les modèles multimodaux ont ouvert un large éventail d’applications qui étaient hors de portée des modèles textuels purs.
Remarque 117
La compréhension de documents (document understanding) est l’une des applications multimodales les plus immédiates en entreprise. Les documents réels — factures, contrats, articles scientifiques, rapports medicaux — mélangent texte, tableaux, figures et mise en page. Des modèles comme GPT-4V et Claude 3.5 Sonnet surpassent les pipelines OCR + NLP traditionnels grace à leur compréhension holistique du document. Le benchmark DocVQA mesure la capacité à répondre à des questions sur des documents scannés ; les meilleurs modèles dépassent 90 % de précision.
Remarque 118
L”analyse vidéo étend la compréhension d’image à la dimension temporelle. Les approches actuelles échantillonnent typiquement \(k\) frames par vidéo, les encodent séparément avec un ViT, puis fournissent la séquence de représentations visuelles au LLM. Gemini 1.5 Pro, avec sa fenêtre de contexte de 2 millions de tokens, peut traiter directement jusqu’à une heure de video. Les défis principaux sont le coût computationnel (une minute de video à 1 fps représente déjà 60 images, soit environ 12 000 tokens visuels) et la compréhension des relations temporelles entre frames.
Exemple 80 (Génération d’images à partir de texte)
La génération d’images à partir de texte a connu une révolution entre 2021 et 2023 :
Modèle |
Approche |
Année |
|---|---|---|
DALL-E |
dVAE + Transformer auto-régressif |
2021 |
Stable Diffusion |
Diffusion latente (U-Net + CLIP) |
2022 |
Midjourney |
Propriétaire (probablement diffusion) |
2022 |
DALL-E 3 |
Diffusion + intégration ChatGPT |
2023 |
Le paradigme dominant est la diffusion latente (Latent Diffusion Model, LDM) : un autoencodeur compresse l’image dans un espace latent compact, puis un modèle de diffusion apprend à débruiter progressivement un bruit gaussien pour générer une image cohérente, conditionné par des embeddings CLIP du prompt textuel.
Remarque 119
L”imagerie médicale est un domaine d’application particulièrement prometteur pour les modèles multimodaux. La combinaison d’images médicales (radiographies, IRM, scanners) et de rapports cliniques textuels permet d’assister les radiologues dans le diagnostic. Des modèles spécialisés (MedPaLM-M, LLaVA-Med) sont entrainés sur des jeux de données médicaux. Les enjeux specifiques incluent la fiabilité (les hallucinations visuelles peuvent avoir des conséquences graves), la confidentialité des données patients et les exigences réglementaires.
Résumé#
Ce chapitre a présenté les fondements de la multimodalité dans le contexte des grands modèles de langage, un domaine en évolution rapide qui redéfinit les capacités de l’IA.
Les modèles multimodaux étendent les LLM au-delà du texte pour traiter images, audio et vidéo. Cette évolution répond au caractère fondamentalement multimodal de la perception humaine et ouvre des applications impossibles avec le texte seul (compréhension de documents, VQA, transcription vocale).
CLIP (Radford et al., 2021) a introduit l’apprentissage contrastif texte-image à grande échelle. Son architecture à double encodeur et sa perte InfoNCE alignent images et textes dans un espace commun, permettant la classification zero-shot sans aucun entrainement spécifique à la tâche.
La perte contrastive \(\mathcal{L}_{\text{InfoNCE}}\) maximise la similarité des paires correspondantes et minimise celle des paires non correspondantes dans un batch de \(N\) exemples. La température \(\tau\) contrôle la netteté de la distribution de similarité.
Les modèles vision-language (LLaVA, Flamingo, GPT-4V, Claude) combinent un encodeur visuel (ViT) avec un LLM génératif. L’intégration se fait par projection linéaire (LLaVA), attention croisée (Flamingo) ou fusion native (Gemini). Le Visual Instruction Tuning est une stratégie efficiente pour adapter un VLM avec peu de données.
Whisper (Radford et al., 2022) est un modèle encodeur-décodeur Transformer pour la reconnaissance vocale, entrainé sur 680 000 heures d’audio couvrant 96 langues. Son architecture multitâche unifie transcription, traduction et détection de langue.
Les architectures unifiées (Gemini, GPT-4o) tendent vers des modèles nativement multimodaux, entrainés de bout en bout sur toutes les modalités. Les trois stratégies de fusion — précoce, tardive et croisée — offrent différents compromis entre profondeur d’intégration et coût d’entrainement.
Les applications multimodales couvrent la compréhension de documents, l’analyse video, l’imagerie médicale et la génération d’images (DALL-E, Stable Diffusion, Midjourney). Les benchmarks multimodaux (VQAv2, MMMU, MathVista) montrent une progression rapide mais des défis persistants, notamment les hallucinations visuelles.