Réduction des endomorphismes#
Diagonaliser une matrice, c’est trouver le bon angle pour la regarder.
— James Joseph Sylvester
Valeurs propres et vecteurs propres#
Définition 171 (Valeur propre, vecteur propre, spectre)
Soit \(f \in \mathcal{L}(E)\). Un scalaire \(\lambda \in \mathbb{K}\) est une valeur propre de \(f\) s’il existe \(v \neq 0\) tel que \(f(v) = \lambda v\).
\(v\) est un vecteur propre associé à \(\lambda\). Le sous-espace propre est \(E_\lambda = \ker(f - \lambda\,\mathrm{id})\).
Le spectre de \(f\) est \(\mathrm{Sp}(f) = \{\lambda \in \mathbb{K} \mid \lambda \text{ valeur propre}\}\).
Remarque 95
Géométriquement, les directions propres sont les directions invariantes par \(f\) : \(f\) agit comme une homothétie de rapport \(\lambda\) sur \(E_\lambda\).
Exemple 90
Endomorphisme |
Valeurs propres |
Vecteurs propres |
|---|---|---|
\(\mathrm{id}_E\) |
\(\lambda = 1\) (mult. \(n\)) |
Tout \(v \neq 0\) |
Homothétie \(\alpha\,\mathrm{id}\) |
\(\lambda = \alpha\) |
Tout \(v \neq 0\) |
Symétrie par rapport à \(F\) |
\(1\) (sur \(F\)), \(-1\) (sur \(G\)) |
\(F\), \(G\) |
Rotation \(\pi/2\) dans \(\mathbb{R}^2\) |
Aucune sur \(\mathbb{R}\), \(\pm i\) sur \(\mathbb{C}\) |
— |
Dérivation sur \(\mathbb{R}[X]\) |
\(0, 1, 2, \ldots\) |
\(1, e^x, e^{2x}, \ldots\) |
Proposition 258 (Indépendance des vecteurs propres)
Des vecteurs propres associés à des valeurs propres distinctes sont linéairement indépendants. La somme des sous-espaces propres est directe :
Proof. Par récurrence sur \(p\). Supposons \(\sum_{i=1}^p \lambda_i v_i = 0\) (avec \(f(v_i) = \mu_i v_i\), \(\mu_i\) distincts). En appliquant \(f - \mu_p\,\mathrm{id}\) :
Par hypothèse de récurrence (les \(\mu_i - \mu_p \neq 0\)) : \(\lambda_i = 0\) pour \(i < p\), puis \(\lambda_p = 0\).
Polynôme caractéristique#
Définition 172 (Polynôme caractéristique)
C’est un polynôme de degré \(n\) en \(\lambda\) avec coefficient dominant \(1\) :
Remarque 96
Certains auteurs définissent \(\chi_f(\lambda) = \det(A - \lambda I_n)\) (signe \((-1)^n\) modifié). Les racines sont les mêmes.
Proposition 259 (Racines et valeurs propres)
Les matrices semblables ont le même polynôme caractéristique.
Proof. \(\lambda\) valeur propre \(\iff\) \(\ker(f-\lambda\,\mathrm{id}) \neq \{0\}\) \(\iff\) \((f-\lambda\,\mathrm{id})\) non inversible \(\iff\) \(\det(\lambda\,\mathrm{id}-f) = 0\).
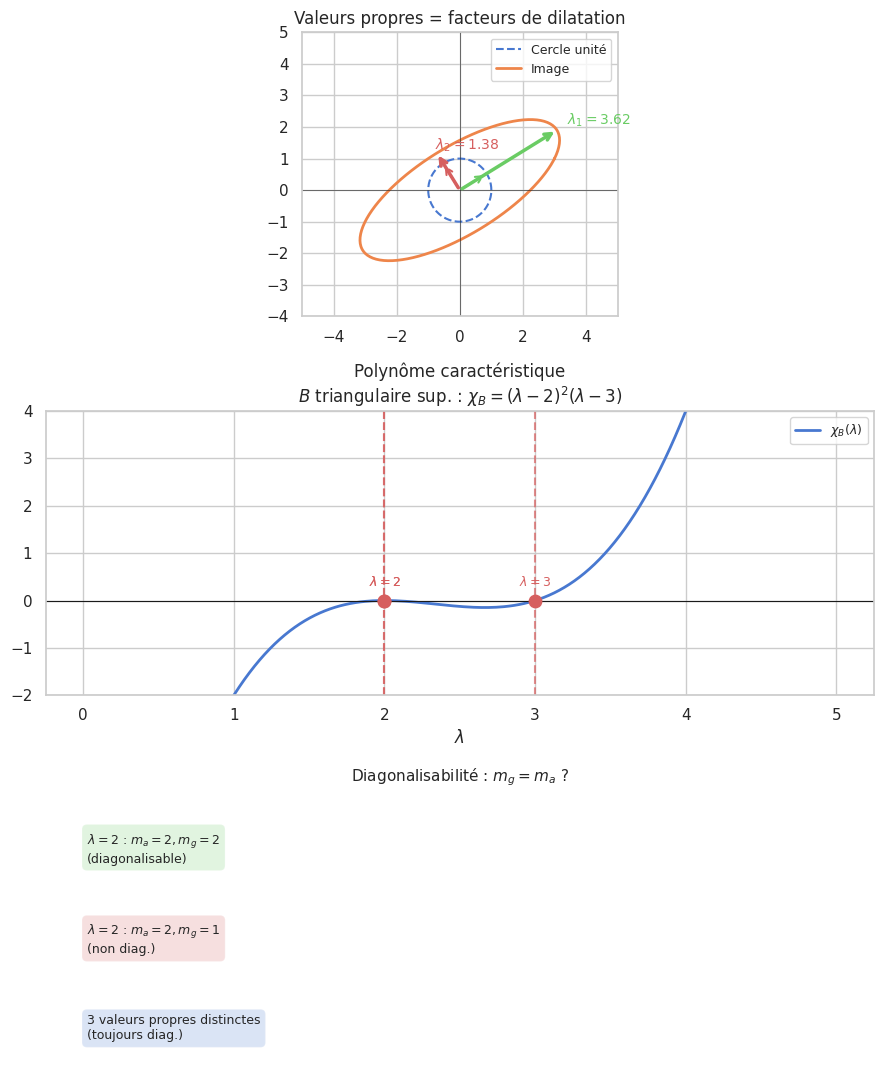
Définition 173 (Multiplicités)
Pour \(\lambda \in \mathrm{Sp}(f)\) :
Multiplicité algébrique \(m_a(\lambda)\) : ordre de \(\lambda\) comme racine de \(\chi_f\)
Multiplicité géométrique \(m_g(\lambda) = \dim E_\lambda\)
On a toujours \(1 \leq m_g(\lambda) \leq m_a(\lambda)\).
Diagonalisation#
Définition 174 (Endomorphisme diagonalisable)
\(f\) est diagonalisable s’il existe une base de \(E\) formée de vecteurs propres, i.e. sa matrice dans cette base est diagonale \(D = \mathrm{diag}(\lambda_1,\ldots,\lambda_n)\).
Proposition 260 (Caractérisations de la diagonalisabilité)
Les assertions suivantes sont équivalentes :
\(f\) est diagonalisable
\(E = \bigoplus_{\lambda \in \mathrm{Sp}(f)} E_\lambda\)
\(\sum_{\lambda} \dim E_\lambda = n\)
\(\chi_f\) est scindé sur \(\mathbb{K}\) et \(m_g(\lambda) = m_a(\lambda)\) pour tout \(\lambda\)
Proof. \((1 \Leftrightarrow 2)\) : \(f\) diagonalisable \(\Leftrightarrow\) il existe une base de vecteurs propres \(\Leftrightarrow\) \(E\) est la réunion directe des sous-espaces propres.
\((3 \Leftrightarrow 4)\) : \(\sum m_a(\lambda) = n\) (si \(\chi_f\) scindé) et \(m_g \leq m_a\) pour chaque \(\lambda\). L’égalité \(\sum m_g = n\) force \(m_g = m_a\) pour chaque \(\lambda\) et le fait que \(\chi_f\) est scindé.
Proposition 261 (Critère suffisant)
Si \(f\) a \(n = \dim E\) valeurs propres distinctes, alors \(f\) est diagonalisable.
Remarque 97
Méthode de diagonalisation :
Calculer \(\chi_f(\lambda) = \det(\lambda I - A)\)
Factoriser pour trouver les valeurs propres \(\lambda_i\) et leurs multiplicités algébriques \(m_a(\lambda_i)\)
Pour chaque \(\lambda_i\) : calculer \(E_{\lambda_i} = \ker(A - \lambda_i I)\) et vérifier \(\dim E_{\lambda_i} = m_a(\lambda_i)\)
Former \(P\) = matrice de passage (colonnes = vecteurs propres), alors \(D = P^{-1}AP\)
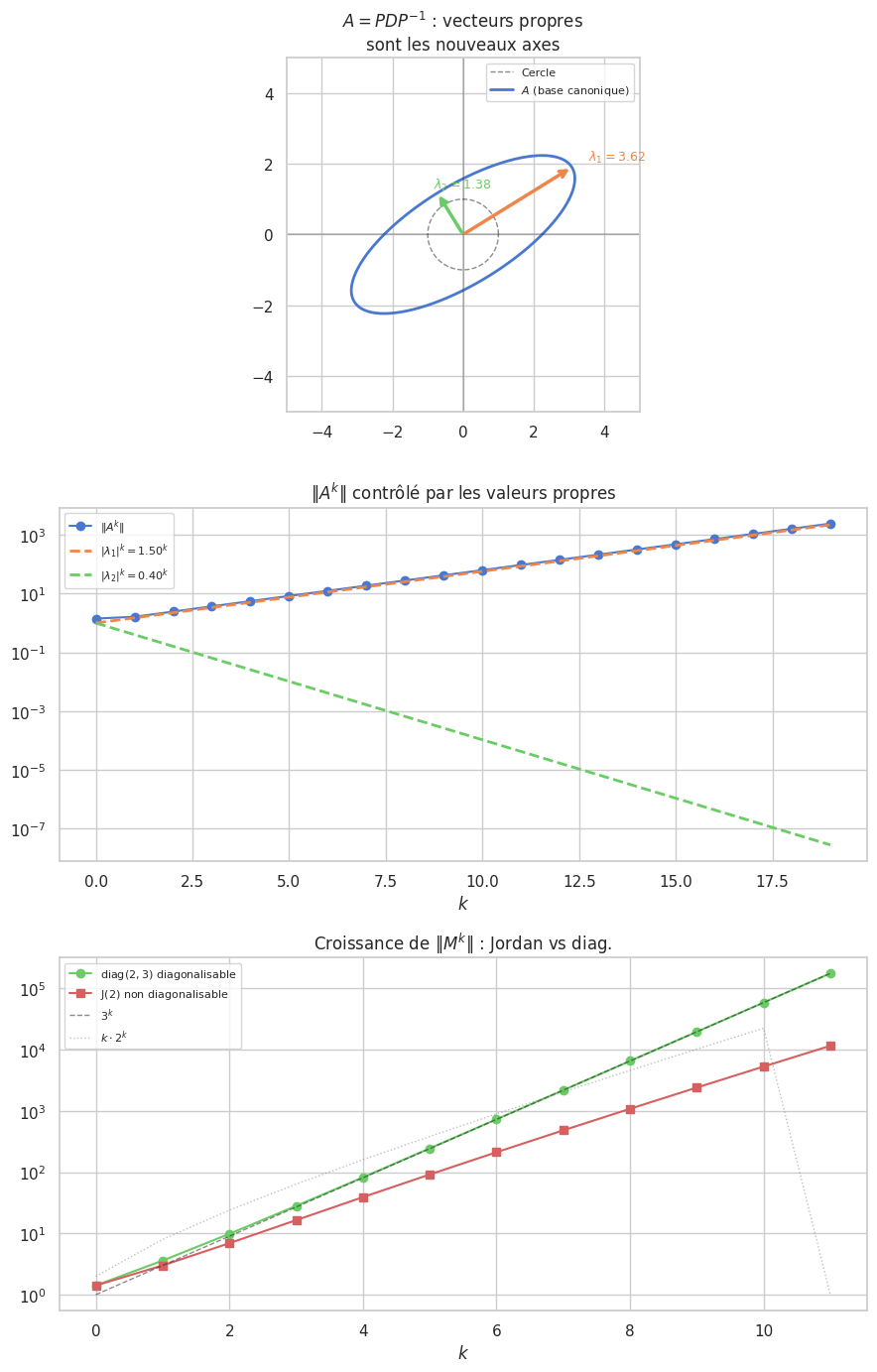
Proposition 262 (Puissances d’une matrice diagonalisable)
Si \(A = PDP^{-1}\) avec \(D = \mathrm{diag}(\lambda_1,\ldots,\lambda_n)\) :
Trigonalisation#
Définition 175 (Matrice trigonalisable)
\(A\) est trigonalisable si \(\exists P \in GL_n(\mathbb{K}),\ T\) triangulaire sup. : \(A = PTP^{-1}\).
Proposition 263 (Critère)
\(f\) est trigonalisable \(\iff\) \(\chi_f\) est scindé sur \(\mathbb{K}\).
En particulier, toute matrice complexe est trigonalisable (d’Alembert-Gauss).
Remarque 98
Les éléments diagonaux de \(T\) sont les valeurs propres (avec multiplicités). En effet, \(\det(\lambda I - T) = \prod_i(\lambda - t_{ii})\).
Théorème de Cayley-Hamilton#
Proposition 264 (Théorème de Cayley-Hamilton)
Tout endomorphisme est annulé par son propre polynôme caractéristique :
Proof. (Esquisse) Sur \(\mathbb{C}\) (puis par densité), \(f\) est trigonalisable : \(A = PTP^{-1}\). \(\chi_A = \chi_T = \prod_i(\lambda - t_{ii})\). Un calcul direct montre que \(\chi_T(T) = 0\), puis \(\chi_A(A) = P\chi_T(T)P^{-1} = 0\).
Exemple 91
\(A = \begin{pmatrix}1&2\\0&3\end{pmatrix}\), \(\chi_A(\lambda) = \lambda^2 - 4\lambda + 3\).
\(A^2 - 4A + 3I = \begin{pmatrix}1&8\\0&9\end{pmatrix} - \begin{pmatrix}4&8\\0&12\end{pmatrix} + \begin{pmatrix}3&0\\0&3\end{pmatrix} = \begin{pmatrix}0&0\\0&0\end{pmatrix}\). ✓
Remarque 99
Application. Cayley-Hamilton permet de calculer \(A^{-1}\) (et plus généralement toute puissance \(A^k\)) en fonction de \(I, A, \ldots, A^{n-1}\) : \(\chi_A(A) = 0\) donne \(A^n\) en fonction des puissances inférieures.
Polynôme minimal#
Définition 176 (Polynôme minimal)
Le polynôme minimal \(\mu_f\) est le polynôme annulateur unitaire de degré minimal.
Proposition 265 (Propriétés)
\(\mu_f \mid P\) pour tout annulateur \(P\) (en particulier \(\mu_f \mid \chi_f\))
\(\mu_f\) et \(\chi_f\) ont les mêmes racines (pas nécessairement les mêmes multiplicités)
\(f\) diagonalisable \(\iff\) \(\mu_f\) est scindé à racines simples (lemme des noyaux)
Proof. Lemme des noyaux. Si \(\mu_f = \prod_{i=1}^p (X - \lambda_i)\) à racines distinctes, alors les \((f - \lambda_i\,\mathrm{id})\) sont premiers entre eux deux à deux, et le lemme des noyaux donne \(E = \bigoplus_i \ker(f - \lambda_i\,\mathrm{id}) = \bigoplus_i E_{\lambda_i}\).
Exemple 92
Matrice |
\(\chi\) |
\(\mu\) |
Diag. ? |
|---|---|---|---|
\(I_n\) |
\((\lambda-1)^n\) |
\(\lambda-1\) |
Oui |
\(\begin{pmatrix}0&1\\0&0\end{pmatrix}\) |
\(\lambda^2\) |
\(\lambda^2\) |
Non |
\(\mathrm{diag}(1,1,2)\) |
\((\lambda-1)^2(\lambda-2)\) |
\((\lambda-1)(\lambda-2)\) |
Oui |
\(\begin{pmatrix}1&1&0\\0&1&0\\0&0&2\end{pmatrix}\) |
\((\lambda-1)^2(\lambda-2)\) |
\((\lambda-1)^2(\lambda-2)\) |
Non |
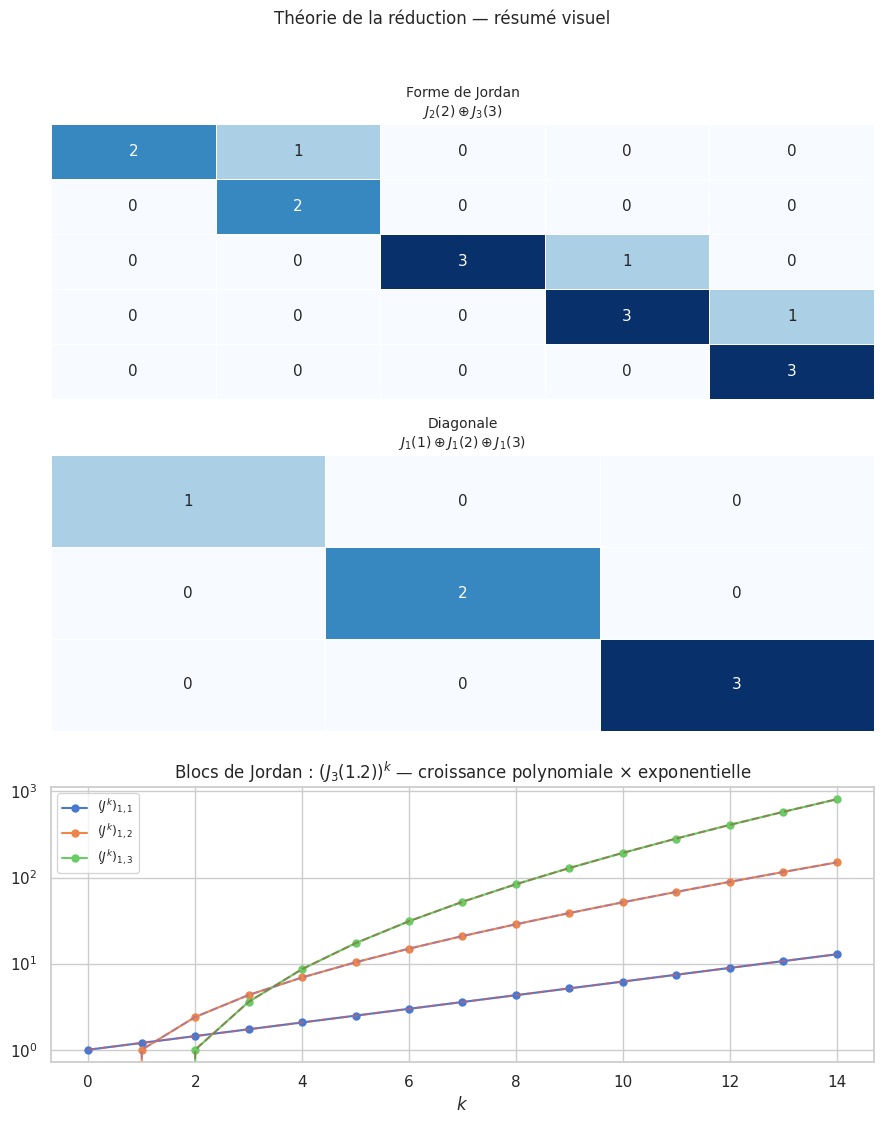
Forme de Jordan (introduction)#
Définition 177 (Bloc de Jordan)
Un bloc de Jordan de taille \(k\) associé à \(\lambda\) est la matrice \(k\times k\) :
Proposition 266 (Théorème de Jordan)
Toute matrice de \(\mathcal{M}_n(\mathbb{C})\) est semblable à une matrice de Jordan :
La décomposition est unique à permutation des blocs près.
Remarque 100
\(f\) diagonalisable \(\iff\) tous les blocs Jordan sont de taille 1 (toutes les valeurs propres ont \(m_g = m_a\)).
La taille du plus grand bloc de Jordan pour \(\lambda\) est l’ordre de \(\lambda\) comme racine de \(\mu_f\).
Cayley-Hamilton : \(\chi_f = \prod_i (\lambda - \lambda_i)^{m_a(\lambda_i)}\) ; \(\mu_f = \prod_i (\lambda - \lambda_i)^{k_{\max,i}}\).
Applications importantes#
Diagonalisation et systèmes récurrents#
Exemple 93
Suite de Fibonacci. Posons \(X_n = \begin{pmatrix}F_{n+1}\\F_n\end{pmatrix}\). Alors \(X_n = A X_{n-1}\) avec \(A = \begin{pmatrix}1&1\\1&0\end{pmatrix}\).
\(\chi_A = \lambda^2 - \lambda - 1\), racines \(\varphi = \frac{1+\sqrt5}{2}\) et \(\hat\varphi = \frac{1-\sqrt5}{2}\).
\(P = \begin{pmatrix}\varphi&\hat\varphi\\1&1\end{pmatrix}\), \(D = \mathrm{diag}(\varphi, \hat\varphi)\), \(A^n = PD^nP^{-1}\), d’où la formule de Binet :
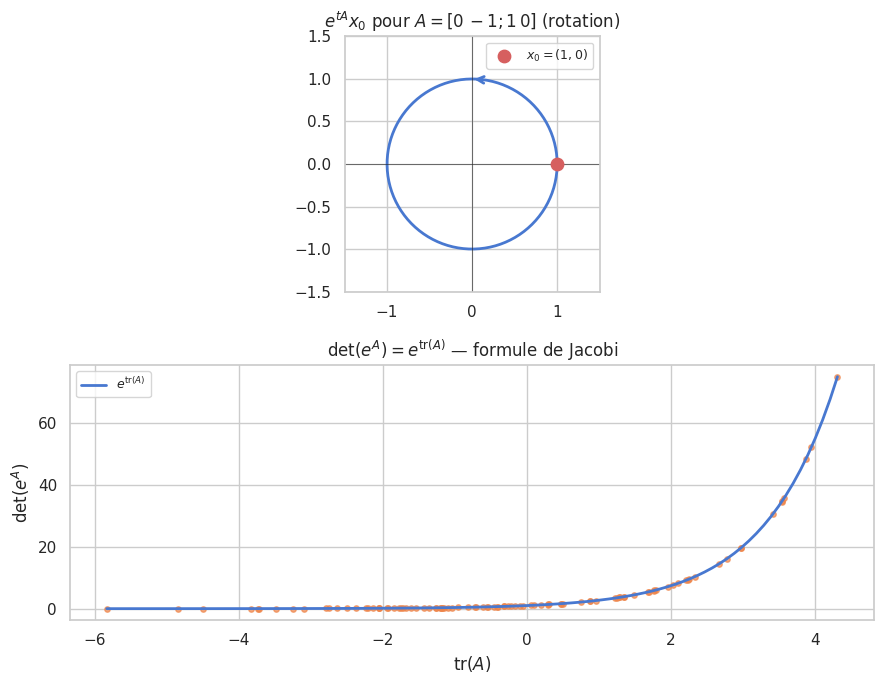
Exponentielle de matrice#
Définition 178 (Exponentielle de matrice)
La série converge pour toute matrice \(A\).
Proposition 267 (Propriétés)
Si \(A = PDP^{-1}\) (diagonalisable) : \(e^A = P\,\mathrm{diag}(e^{\lambda_i})\,P^{-1}\)
\(\det(e^A) = e^{\mathrm{tr}(A)}\) (formule de Jacobi-Liouville)
\(e^{A+B} = e^A e^B\) si \(AB = BA\)
\((e^{tA})' = A e^{tA}\) : solution de \(X' = AX\), \(X(0) = X_0\) est \(X(t) = e^{tA}X_0\)