Calcul différentiel en plusieurs variables#
Les fonctions de plusieurs variables sont les fonctions de la nature : la température dépend du lieu et du temps, la pression dépend du volume et de la température.
Augustin-Louis Cauchy
Introduction#
Le calcul différentiel en une variable repose sur la notion de dérivée, c’est-à-dire la meilleure approximation linéaire d’une fonction au voisinage d’un point. En dimension supérieure, cette notion se généralise en la différentielle, une application linéaire qui approxime la fonction. Ce cadre unifie les dérivées partielles, le gradient, la matrice jacobienne, et ouvre la voie à l’optimisation sous contraintes.
Dans ce chapitre, \(E\) et \(F\) désignent des espaces vectoriels normés de dimension finie (typiquement \(\mathbb{R}^n\) et \(\mathbb{R}^p\)), et \(U\) un ouvert de \(E\).
Dérivées partielles#
Définition 223 (Dérivée partielle)
Soit \(f : U \subset \mathbb{R}^n \to \mathbb{R}\) et \(a \in U\). La dérivée partielle de \(f\) par rapport à \(x_i\) en \(a\) est
si cette limite existe, où \(e_i\) est le \(i\)-ème vecteur de la base canonique. On note aussi \(\partial_i f(a)\) ou \(f_{x_i}(a)\).
Remarque 118
La dérivée partielle \(\partial_i f(a)\) est la dérivée de la fonction d’une variable \(t \mapsto f(a_1, \ldots, a_{i-1}, t, a_{i+1}, \ldots, a_n)\) en \(t = a_i\). On dérive par rapport à une variable en fixant les autres.
Exemple 113
\(f(x, y) = x^2 y + \sin(xy)\). Alors
Remarque 119
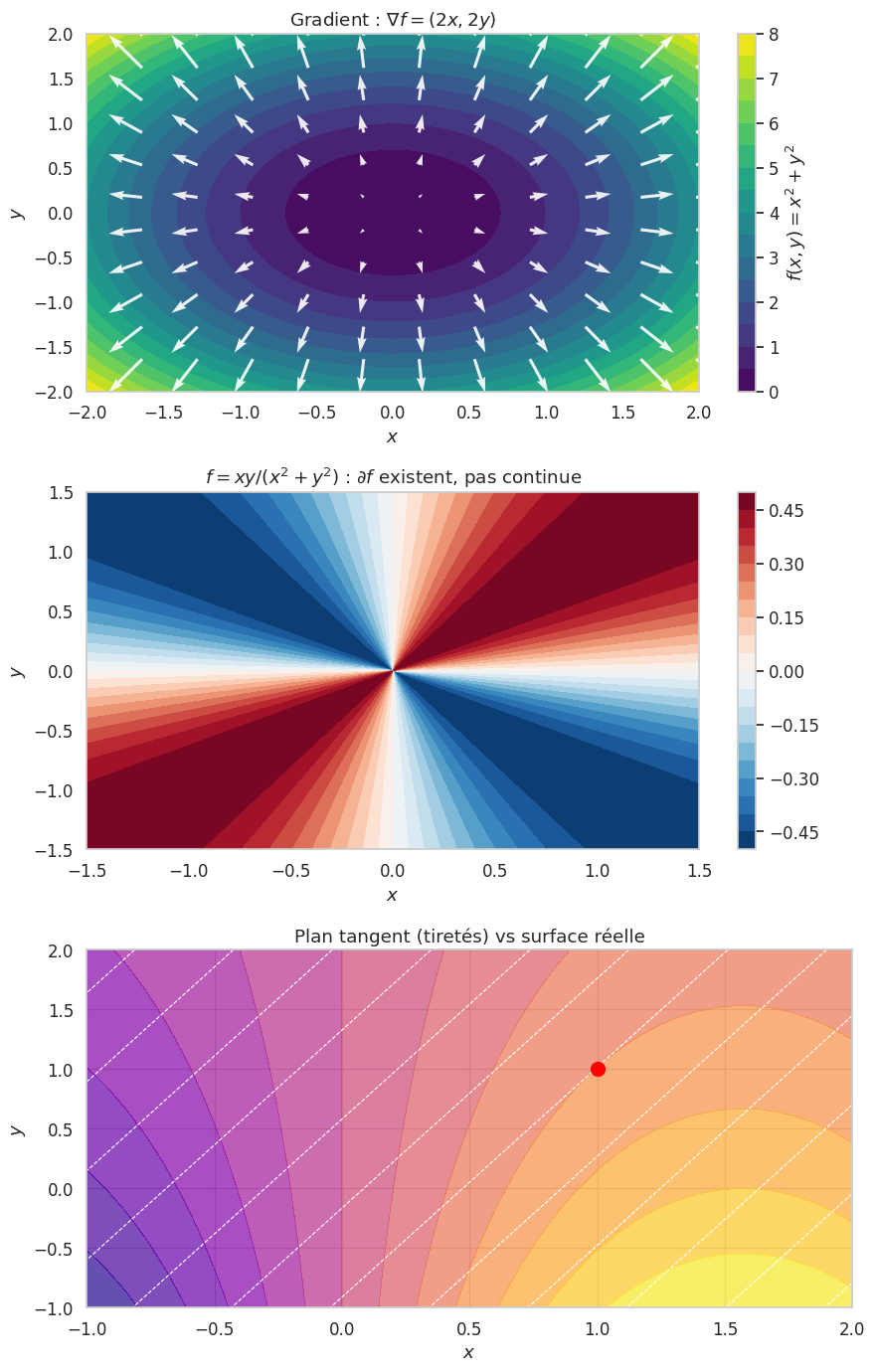
L’existence des dérivées partielles n’implique pas la continuité. Contre-exemple : \(f(x, y) = \frac{xy}{x^2 + y^2}\) pour \((x,y) \neq (0,0)\), \(f(0,0) = 0\). Les dérivées partielles existent en \((0,0)\) (\(\partial_x f(0,0) = \partial_y f(0,0) = 0\)), mais \(f\) n’est pas continue en \((0,0)\) : sur la diagonale \(y = x\), \(f(x,x) = 1/2 \not\to 0\).
Définition 224 (Dérivée directionnelle)
La dérivée directionnelle de \(f\) en \(a\) dans la direction \(v \in \mathbb{R}^n\) est
Les dérivées partielles sont les dérivées directionnelles dans les directions \(e_i\).
Différentielle#
Définition 225 (Différentielle (Fréchet))
Soit \(f : U \subset E \to F\) et \(a \in U\). On dit que \(f\) est différentiable en \(a\) s’il existe une application linéaire \(L : E \to F\) telle que
c’est-à-dire \(\dfrac{\|f(a + h) - f(a) - L(h)\|}{\|h\|} \to 0\) quand \(h \to 0\).
L’application \(L\) est unique et s’appelle la différentielle de \(f\) en \(a\), notée \(df_a\) ou \(Df(a)\).
Remarque 120
La différentielle \(df_a\) est la meilleure approximation linéaire de \(f\) au voisinage de \(a\). Géométriquement, c’est le plan tangent à la surface.
Proposition 302 (Différentiable \(\implies\) continue)
Si \(f\) est différentiable en \(a\), alors \(f\) est continue en \(a\).
Proof. \(f(a + h) - f(a) = L(h) + o(\|h\|) \to 0\) quand \(h \to 0\), car \(L\) est linéaire continue (dimension finie) et \(o(\|h\|) \to 0\).
Proposition 303 (Différentielle et dérivées partielles)
Si \(f : U \subset \mathbb{R}^n \to \mathbb{R}^p\) est différentiable en \(a\), alors toutes les dérivées partielles existent en \(a\) et
La réciproque est fausse : l’existence des dérivées partielles ne suffit pas.
Proof. Prenons \(h = te_i\) dans la définition de la différentielle :
Donc \(\dfrac{f(a + te_i) - f(a)}{t} \to L(e_i)\), c’est-à-dire \(\partial_i f(a) = L(e_i)\). Comme \(L\) est linéaire : \(L(h) = \sum h_i L(e_i) = \sum h_i \partial_i f(a)\).
Matrice jacobienne et gradient#
Définition 226 (Matrice jacobienne)
Si \(f = (f_1, \ldots, f_p) : U \subset \mathbb{R}^n \to \mathbb{R}^p\) est différentiable en \(a\), la matrice de \(df_a\) dans les bases canoniques est la matrice jacobienne :
Définition 227 (Gradient)
Si \(f : U \subset \mathbb{R}^n \to \mathbb{R}\) est différentiable en \(a\), le gradient de \(f\) en \(a\) est
On a \(df_a(h) = \langle \nabla f(a), h \rangle\) (produit scalaire canonique).
Le gradient est la direction de plus grande pente de \(f\) : \(D_v f(a) = \langle \nabla f(a), v \rangle \leq \|\nabla f(a)\| \|v\|\), avec égalité pour \(v = \nabla f(a)\).
Définition 228 (Jacobien)
Si \(n = p\) (application de \(\mathbb{R}^n\) dans \(\mathbb{R}^n\)), le jacobien de \(f\) en \(a\) est le déterminant de la matrice jacobienne : \(\det(J_f(a))\). Il mesure le facteur de dilatation des volumes locaux.
Condition suffisante de différentiabilité#
Théorème 33 (Condition de classe \(\mathcal{C}^1\))
Si les dérivées partielles \(\partial_i f\) existent dans un voisinage de \(a\) et sont continues en \(a\), alors \(f\) est différentiable en \(a\).
Proof. On traite le cas \(f : \mathbb{R}^2 \to \mathbb{R}\), la généralisation étant analogue.
Par le théorème des accroissements finis appliqué à chaque crochet :
pour certains \(c_1\) entre \(a_1\) et \(a_1 + h_1\), \(c_2\) entre \(a_2\) et \(a_2 + h_2\). Par continuité des dérivées partielles en \(a\) :
d’où la différentiabilité avec \(df_a(h_1, h_2) = \partial_1 f(a) h_1 + \partial_2 f(a) h_2\).
Définition 229 (Fonction de classe \(\mathcal{C}^1\))
\(f\) est de classe \(\mathcal{C}^1\) sur \(U\) si toutes ses dérivées partielles existent et sont continues sur \(U\). Par le théorème précédent, \(f\) est alors différentiable en tout point de \(U\).
Plus généralement, \(f\) est de classe \(\mathcal{C}^k\) si ses dérivées partielles d’ordre \(\leq k\) existent et sont continues.
Opérations sur la différentielle#
Proposition 304 (Linéarité)
Si \(f\) et \(g\) sont différentiables en \(a\), alors \(f + g\) et \(\lambda f\) le sont, et
Théorème 34 (Différentielle d’une composée (Chain rule))
Si \(f : U \to V\) est différentiable en \(a\) et \(g : V \to G\) est différentiable en \(f(a)\), alors \(g \circ f\) est différentiable en \(a\) et
En termes de matrices jacobiennes : \(J_{g \circ f}(a) = J_g(f(a)) \cdot J_f(a)\).
Proof. Posons \(L_1 = df_a\) et \(L_2 = dg_{f(a)}\).
Or \(L_2(o(\|h\|)) = o(\|h\|)\) car \(L_2\) est linéaire continue, et \(\|L_1(h)\| \leq \|L_1\| \cdot \|h\| = O(\|h\|)\). Donc \(g(f(a+h)) = g(f(a)) + (L_2 \circ L_1)(h) + o(\|h\|)\).
Exemple 114
Si \(\gamma(t) = (x(t), y(t))\) est un chemin et \(f(x, y)\) un champ scalaire, alors
Dérivées d’ordre supérieur et théorème de Schwarz#
Définition 230 (Dérivées partielles d’ordre 2)
Si \(\partial_i f\) existe et est elle-même dérivable par rapport à \(x_j\), on note
Attention à l’ordre : on dérive d’abord par rapport à \(x_i\), puis par rapport à \(x_j\).
Théorème 35 (Théorème de Schwarz)
Si \(f\) est de classe \(\mathcal{C}^2\), alors les dérivées partielles croisées commutent :
Proof. Considérons \(\varphi(s, t) = f(a + se_i + te_j) - f(a + se_i) - f(a + te_j) + f(a)\).
D’une part, en posant \(g(s) = f(a + se_i + te_j) - f(a + se_i)\) et en appliquant le TAF à \(g\) :
En appliquant le TAF à l’expression entre crochets par rapport à \(t\) :
pour un certain \(c_1\) proche de \(a\). Par symétrie du raisonnement :
Donc \(\partial_j \partial_i f(c_1) = \partial_i \partial_j f(c_2)\). En faisant \((s, t) \to (0, 0)\), par continuité des dérivées secondes : \(\partial_j \partial_i f(a) = \partial_i \partial_j f(a)\).
Définition 231 (Matrice hessienne)
Si \(f : U \subset \mathbb{R}^n \to \mathbb{R}\) est \(\mathcal{C}^2\), la matrice hessienne de \(f\) en \(a\) est
Par Schwarz, \(H_f(a)\) est symétrique. La forme quadratique associée intervient dans le développement de Taylor à l’ordre 2.
Théorème 36 (Formule de Taylor à l’ordre 2)
Si \(f \in \mathcal{C}^2(U, \mathbb{R})\), alors pour \(h\) petit :
Difféomorphismes et théorème d’inversion locale#
Définition 232 (Difféomorphisme)
\(f : U \to V\) est un difféomorphisme (de classe \(\mathcal{C}^k\)) si \(f\) est bijective et \(f\) et \(f^{-1}\) sont de classe \(\mathcal{C}^k\).
Théorème 37 (Théorème d’inversion locale)
Soit \(f : U \subset \mathbb{R}^n \to \mathbb{R}^n\) de classe \(\mathcal{C}^1\) et \(a \in U\) tel que \(\det(J_f(a)) \neq 0\) (i.e. \(df_a\) est inversible).
Alors il existe un voisinage ouvert \(V\) de \(a\) et un voisinage ouvert \(W\) de \(f(a)\) tels que \(f|_V : V \to W\) est un difféomorphisme de classe \(\mathcal{C}^1\). De plus, \(d(f^{-1})_{f(a)} = (df_a)^{-1}\), c’est-à-dire \(J_{f^{-1}}(f(a)) = J_f(a)^{-1}\).
Proof. L’idée est de se ramener au théorème du point fixe de Banach. On peut supposer \(a = 0\), \(f(0) = 0\), \(df_0 = \mathrm{Id}\) (quitte à composer par \((df_0)^{-1}\)).
Posons \(\Phi_y(x) = x - f(x) + y\). On cherche un point fixe \(x = \Phi_y(x)\), i.e. \(f(x) = y\).
Le jacobien de \(\Phi_y\) en \(x\) est \(I - J_f(x)\). Par continuité de \(J_f\) en \(0\) et \(J_f(0) = I\), il existe \(r > 0\) tel que pour \(\|x\| \leq r\) : \(\|J_f(x) - I\| \leq 1/2\), donc \(\|\Phi_y'(x)\| \leq 1/2\) (application contractante).
Pour \(\|y\| \leq r/2\) et \(x\) dans la boule \(B(0, r)\), on vérifie que \(\Phi_y\) est une contraction de \(\overline{B(0,r)}\) dans lui-même. Par Banach, il existe un unique point fixe \(x = x(y)\), ce qui donne \(f(x(y)) = y\). La régularité de \(x \mapsto x(y)\) découle de la formule des fonctions implicites.
Remarque 121
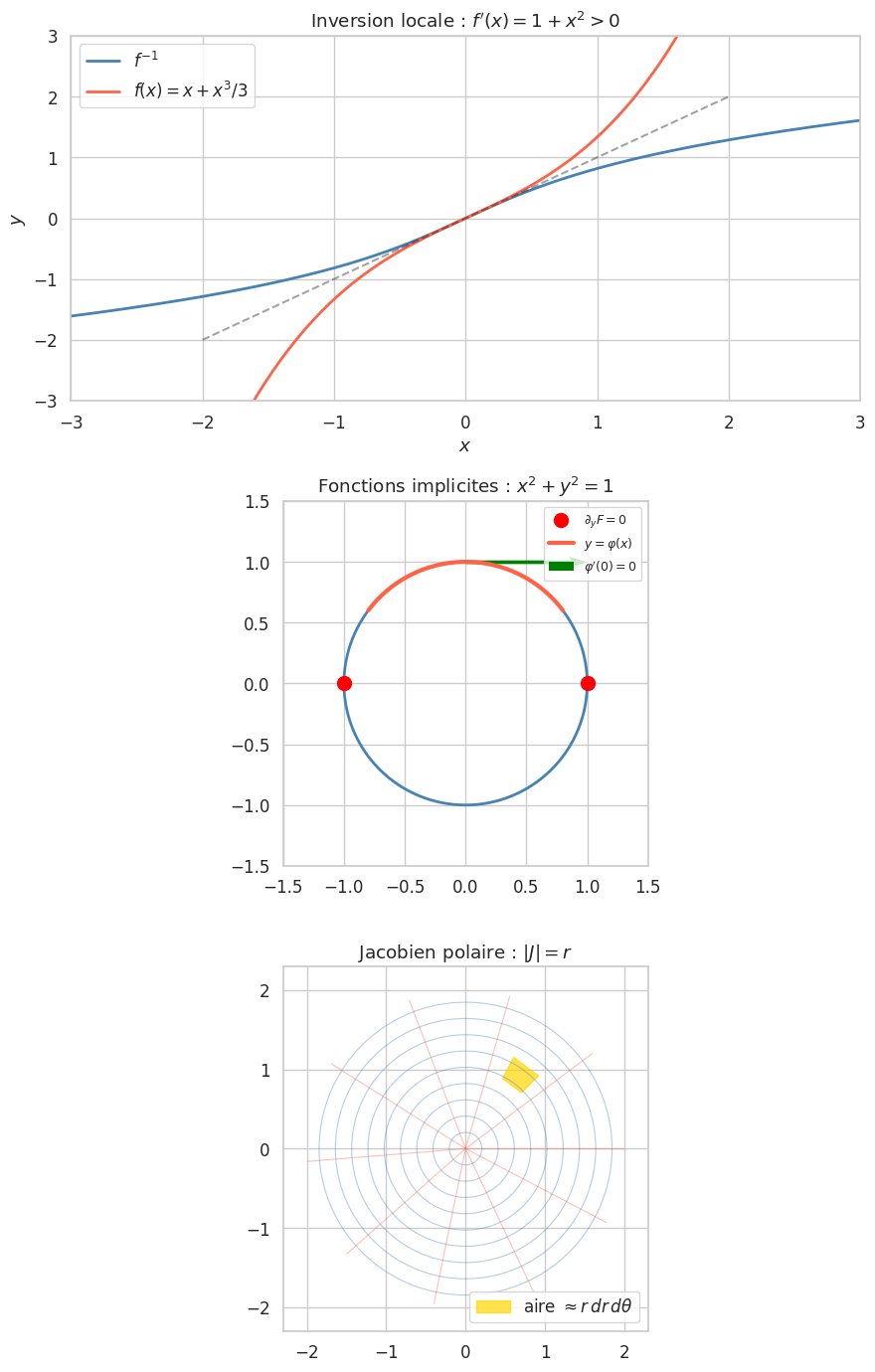
L’hypothèse \(\det(J_f(a)) \neq 0\) est nécessaire mais pas suffisante pour la bijectivité globale : le théorème ne garantit l’inversibilité que localement. Exemple : \(z \mapsto e^z\) est un difféomorphisme local partout sur \(\mathbb{C}\), mais non bijectif globalement.
Exemple 115
Le passage en coordonnées polaires \(f(r, \theta) = (r\cos\theta, r\sin\theta)\) a pour jacobien \(\det(J_f) = r\). Par le théorème d’inversion locale, \(f\) est un difféomorphisme local pour \(r \neq 0\), mais pas en \(r = 0\).
Théorème des fonctions implicites#
Théorème 38 (Théorème des fonctions implicites)
Soit \(F : U \subset \mathbb{R}^n \times \mathbb{R}^p \to \mathbb{R}^p\) de classe \(\mathcal{C}^1\) et \((a, b) \in U\) tel que \(F(a, b) = 0\) et \(\dfrac{\partial F}{\partial y}(a, b)\) est inversible (où \(y\) désigne les \(p\) dernières variables).
Alors il existe des voisinages \(V\) de \(a\) et \(W\) de \(b\) et une unique fonction \(\varphi : V \to W\) de classe \(\mathcal{C}^1\) telle que
De plus, en dérivant \(F(x, \varphi(x)) = 0\) par rapport à \(x\) (Chain rule) :
Proof. On applique le théorème d’inversion locale à \(G : \mathbb{R}^n \times \mathbb{R}^p \to \mathbb{R}^n \times \mathbb{R}^p\) définie par \(G(x, y) = (x, F(x, y))\).
La matrice jacobienne de \(G\) en \((a, b)\) est
Son déterminant est \(\det(\partial_y F(a,b)) \neq 0\) par hypothèse. Donc \(G\) est un difféomorphisme local de voisinage de \((a,b)\) vers voisinage de \((a, 0)\).
Son inverse s’écrit \(G^{-1}(x, z) = (x, \psi(x, z))\) pour une certaine fonction \(\psi\) lisse. En posant \(\varphi(x) = \psi(x, 0)\), on obtient \(F(x, \varphi(x)) = 0\).
Exemple 116
L’équation \(x^2 + y^2 = 1\) définit implicitement \(y = \varphi(x)\) au voisinage de tout point \((a, b)\) avec \(b \neq 0\). En effet, \(F(x, y) = x^2 + y^2 - 1\) et \(\partial_y F = 2y \neq 0\) si \(b \neq 0\). La dérivée implicite : \(\varphi'(x) = -\partial_x F / \partial_y F = -x/y\).
Remarque 122
Ce théorème est omniprésent en géométrie différentielle (définition des variétés), en optimisation (conditions KKT, multiplicateurs de Lagrange), et en mécanique analytique (contraintes holonomes).
Extrema#
Définition 233 (Extremum local)
\(f : U \subset \mathbb{R}^n \to \mathbb{R}\) admet un minimum local en \(a\) si \(f(x) \geq f(a)\) dans un voisinage de \(a\). Maximum local : \(f(x) \leq f(a)\).
Théorème 39 (Condition nécessaire du premier ordre)
Si \(f\) est différentiable en \(a\) et admet un extremum local en \(a\), alors \(\nabla f(a) = 0\) (point critique).
Proof. Pour tout \(h \in \mathbb{R}^n\), la fonction \(t \mapsto f(a + th)\) admet un extremum local en \(t = 0\), donc sa dérivée y est nulle : \(df_a(h) = 0\). Comme c’est vrai pour tout \(h\) : \(df_a = 0\).
Théorème 40 (Conditions du second ordre)
Soit \(f \in \mathcal{C}^2(U, \mathbb{R})\) avec \(\nabla f(a) = 0\). Soit \(H = H_f(a)\) la hessienne.
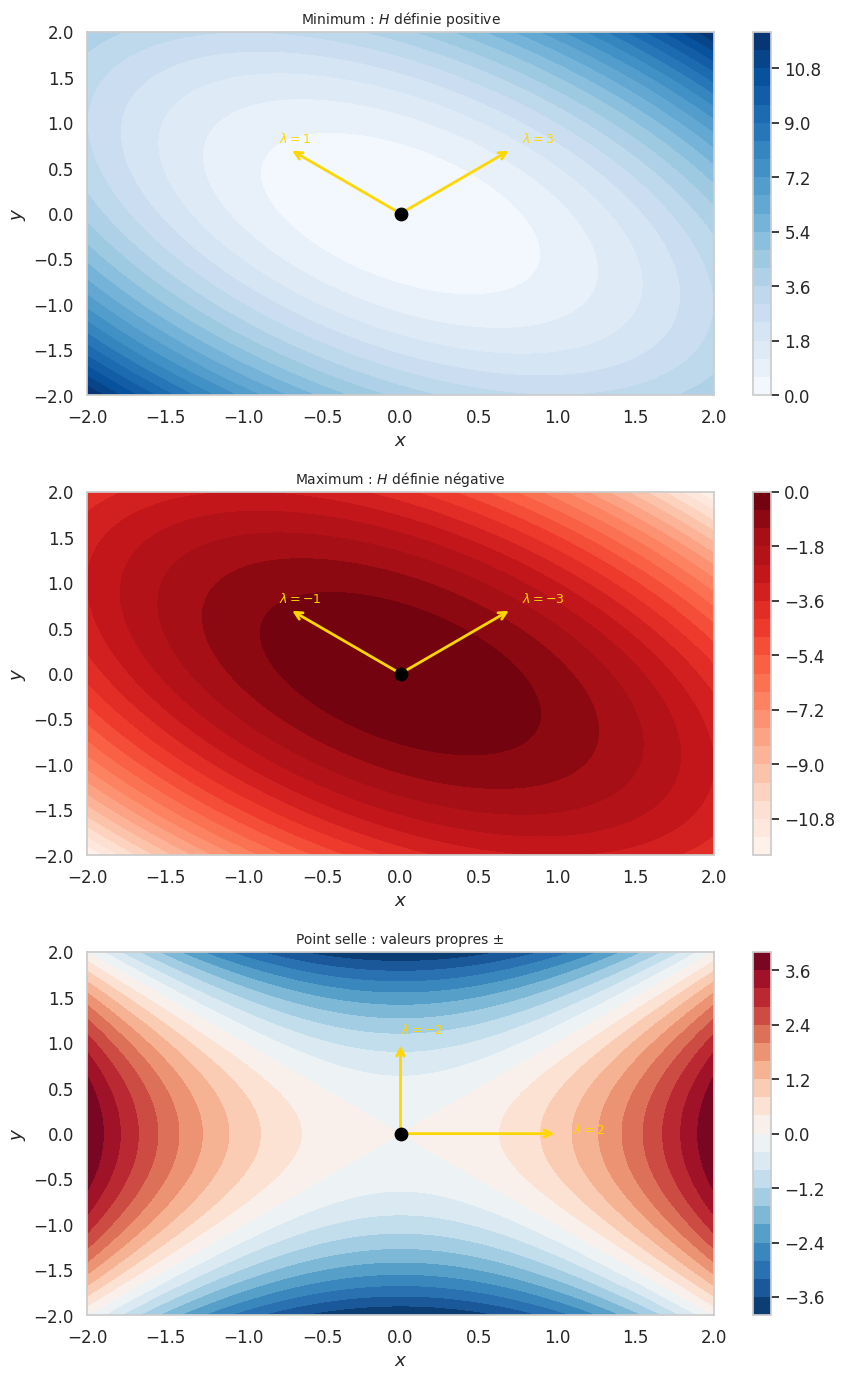
Si \(H\) est définie positive : \(a\) est un minimum local strict
Si \(H\) est définie négative : \(a\) est un maximum local strict
Si \(H\) a des valeurs propres de signes opposés : \(a\) est un point selle
Si \(H\) est positive (ou négative) mais pas définie : on ne peut pas conclure
Proof. Par Taylor à l’ordre 2 : \(f(a + h) = f(a) + \frac{1}{2} h^T H h + o(\|h\|^2)\).
Si \(H\) est définie positive, soit \(\lambda > 0\) sa plus petite valeur propre. Alors \(h^T H h \geq \lambda \|h\|^2\). Donc
pour \(\|h\|\) assez petit. Donc \(a\) est un minimum local strict.
Si \(H\) a des valeurs propres \(\lambda_+ > 0\) et \(\lambda_- < 0\), soit \(v_+\) et \(v_-\) les vecteurs propres correspondants. Alors \(f(a + tv_+) > f(a)\) et \(f(a + tv_-) < f(a)\) pour \(t\) petit : c’est un point selle.
Exemple 117
\(f(x, y) = x^2 + xy + y^2\). \(\nabla f = (2x + y, x + 2y) = 0 \implies (0, 0)\). \(H = \begin{pmatrix} 2 & 1 \\ 1 & 2 \end{pmatrix}\), valeurs propres \(1\) et \(3\) (positives) : minimum local en \((0, 0)\).
Exemple 118
\(f(x, y) = x^2 - y^2\). \(\nabla f = (2x, -2y) = 0 \implies (0, 0)\). \(H = \begin{pmatrix} 2 & 0 \\ 0 & -2 \end{pmatrix}\), valeurs propres \(2\) et \(-2\) : point selle.
Optimisation sous contraintes : multiplicateurs de Lagrange#
Théorème 41 (Multiplicateurs de Lagrange)
Soit \(f, g_1, \ldots, g_p : U \subset \mathbb{R}^n \to \mathbb{R}\) de classe \(\mathcal{C}^1\). Considérons le problème
Si \(x^* \in U\) est un extremum local de \(f\) sous ces contraintes, et si les gradients \(\nabla g_1(x^*), \ldots, \nabla g_p(x^*)\) sont linéairement indépendants (qualification des contraintes), alors il existe des réels \(\lambda_1, \ldots, \lambda_p\) (les multiplicateurs de Lagrange) tels que
Proof. La condition de qualification des contraintes assure que la variété \(M = \{x : g_j(x) = 0\}\) est une sous-variété lisse de dimension \(n - p\) au voisinage de \(x^*\) (par le théorème des fonctions implicites).
Soit \(\gamma : (-\varepsilon, \varepsilon) \to M\) un chemin lisse dans \(M\) avec \(\gamma(0) = x^*\). Alors \(f \circ \gamma\) admet un extremum en \(t = 0\), donc \((f \circ \gamma)'(0) = \nabla f(x^*) \cdot \gamma'(0) = 0\). Ainsi \(\nabla f(x^*)\) est orthogonal à \(T_{x^*}M\).
Or l’espace tangent à \(M\) en \(x^*\) est \(T_{x^*}M = \bigcap_j \ker(\nabla g_j(x^*))\). Son orthogonal est \(\mathrm{Vect}(\nabla g_1(x^*), \ldots, \nabla g_p(x^*))\). Donc \(\nabla f(x^*)\) s’écrit comme combinaison linéaire des \(\nabla g_j(x^*)\).
Remarque 123
Le lagrangien est \(\mathcal{L}(x, \lambda) = f(x) - \sum_j \lambda_j g_j(x)\). La condition s’écrit \(\nabla_x \mathcal{L} = 0\), \(g_j(x) = 0\).
Interprétation : aux extrema, le gradient de \(f\) est parallèle aux gradients des contraintes, i.e. on ne peut pas améliorer \(f\) en restant sur la contrainte.
Exemple 119
Inégalité AM-GM avec Lagrange : Maximiser \(f(x, y) = xy\) sous \(x + y = s\) (\(s > 0\)). \(\nabla f = (y, x)\), \(\nabla g = (1, 1)\). Condition : \((y, x) = \lambda(1, 1)\), donc \(x = y = s/2\). Valeur max : \(xy = s^2/4 \geq 0\), ce qui prouve \(xy \leq \left(\frac{x+y}{2}\right)^2\).
Exemple 120
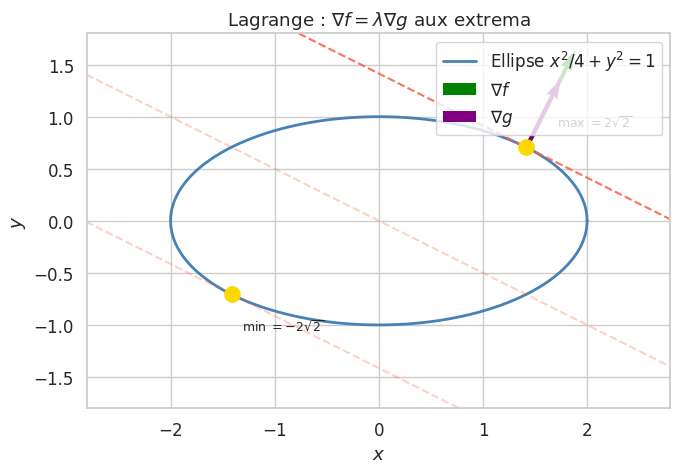
Extremum sur ellipse : Extrêmes de \(f(x, y) = x + 2y\) sur \(g(x, y) = x^2/4 + y^2 - 1 = 0\). Condition : \((1, 2) = \lambda(x/2, 2y)\), soit \(1 = \lambda x/2\) et \(2 = 2\lambda y\). De la seconde : \(\lambda = 1/y\). De la première : \(x = 2y\). Substitution : \(y^2 + y^2 = 1\), \(y = \pm 1/\sqrt{2}\). Points critiques : \((\sqrt{2}, 1/\sqrt{2})\) et \((-\sqrt{2}, -1/\sqrt{2})\), avec valeurs \(\sqrt{2} + \sqrt{2} = 2\sqrt{2}\) et \(-2\sqrt{2}\).
Résumé#
Concept |
Formule / Propriété |
|---|---|
Dérivée partielle |
\(\partial_i f(a) = \lim_{h \to 0} (f(a + he_i) - f(a))/h\) |
Différentielle |
\(f(a+h) = f(a) + df_a(h) + o(|h|)\) |
Matrice jacobienne |
\(J_f = (\partial_j f_i)\), matrice de \(df\) |
Gradient |
\(\nabla f = (\partial_1 f, \ldots, \partial_n f)^T\), \(df(h) = \langle \nabla f, h \rangle\) |
\(\mathcal{C}^1 \implies\) différentiable |
\(\partial_i f\) continues \(\implies\) \(f\) différentiable |
Chain rule |
\(d(g \circ f)_a = dg_{f(a)} \circ df_a\) |
Schwarz |
\(\mathcal{C}^2 \implies \partial_i \partial_j = \partial_j \partial_i\) |
Inversion locale |
\(\det J_f(a) \neq 0 \implies\) diffeo local (via Banach) |
Fonctions implicites |
\(\partial_y F\) inv. \(\implies\) \(y = \varphi(x)\) local |
Extrema |
\(\nabla f = 0\) + hessienne définie \(\implies\) extremum |
Lagrange |
\(\nabla f = \sum_j \lambda_j \nabla g_j\) aux extrema contraints |