Statistiques#
Tous les modèles sont faux, mais certains sont utiles.
George E. P. Box
Introduction#
La théorie des probabilités étudie les propriétés de phénomènes aléatoires dont le modèle est connu. La statistique résout le problème inverse : à partir de données observées, inférer les caractéristiques du modèle sous-jacent. Ce chapitre introduit les outils fondamentaux : estimation ponctuelle, borne de Cramér-Rao, intervalles de confiance et tests d’hypothèses.
Cadre statistique#
Définition 296 (Modèle statistique)
Un modèle statistique est un triplet \((\mathcal{X}, \mathcal{A}, (P_\theta)_{\theta \in \Theta})\) où :
\(\mathcal{X}\) est l”espace des observations
\((P_\theta)_{\theta \in \Theta}\) est une famille de probabilités paramétrisée par \(\theta \in \Theta\)
Le modèle est paramétrique si \(\Theta \subset \mathbb{R}^d\).
Définition 297 (Échantillon et statistique)
Un échantillon de taille \(n\) est \((X_1, \ldots, X_n)\) i.i.d. de loi \(P_\theta\).
Une statistique est une fonction mesurable \(T = T(X_1, \ldots, X_n)\) ne dépendant pas de \(\theta\).
Exemple 159
Moyenne empirique \(\bar{X}_n = \frac{1}{n}\sum X_i\)
Variance empirique \(S_n^2 = \frac{1}{n}\sum(X_i - \bar{X}_n)^2\) (biaisée)
Variance corrigée \(S_n'^2 = \frac{1}{n-1}\sum(X_i - \bar{X}_n)^2\) (sans biais)
Maximum \(X_{(n)} = \max(X_1, \ldots, X_n)\), minimum \(X_{(1)}\)
Estimation ponctuelle#
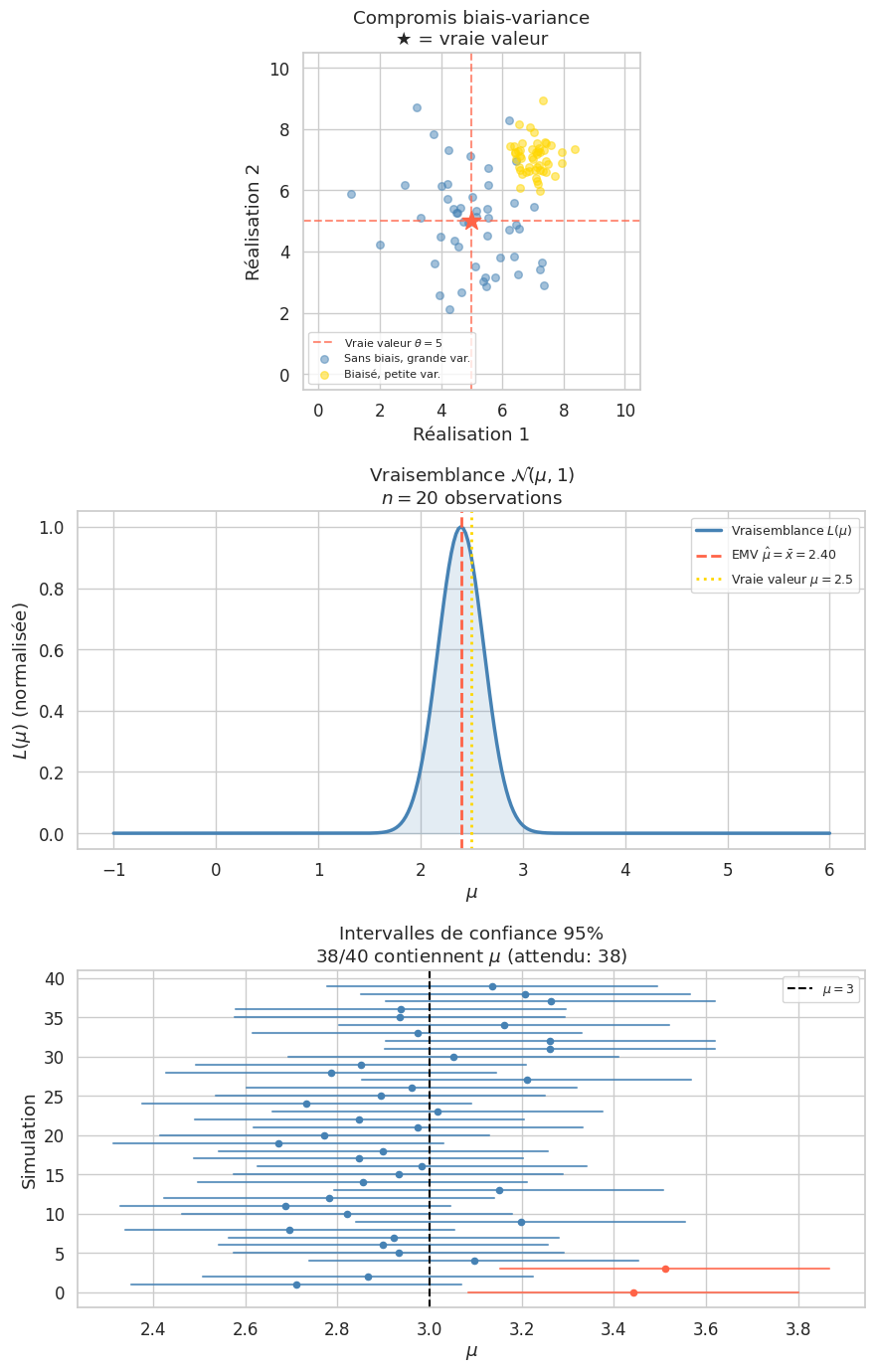
Définition 298 (Estimateur : biais et qualité)
Un estimateur de \(\theta\) est une statistique \(\hat{\theta}_n = T(X_1, \ldots, X_n)\) destinée à approcher \(\theta\).
Sans biais : \(\mathbb{E}_\theta[\hat{\theta}_n] = \theta\) pour tout \(\theta\)
Biais : \(b(\hat{\theta}_n) = \mathbb{E}_\theta[\hat{\theta}_n] - \theta\)
Convergent (consistent) : \(\hat{\theta}_n \xrightarrow{\mathbb{P}} \theta\)
EQM : \(\text{EQM}(\hat{\theta}_n) = \mathbb{E}[(\hat{\theta}_n - \theta)^2] = \text{Var}(\hat{\theta}_n) + b(\hat{\theta}_n)^2\)
Exemple 160
Variance empirique biaisée : \(\mathbb{E}[S_n^2] = \frac{n-1}{n}\sigma^2 \neq \sigma^2\).
Variance corrigée : \(\mathbb{E}[S_n'^2] = \sigma^2\) ✓.
Proof. \(\sum(X_i - \bar{X})^2 = \sum X_i^2 - n\bar{X}^2\). \(\mathbb{E}[\sum X_i^2] = n(\sigma^2 + \mu^2)\). \(\mathbb{E}[n\bar{X}^2] = n(\sigma^2/n + \mu^2) = \sigma^2 + n\mu^2\). \(\mathbb{E}[\sum(X_i - \bar{X})^2] = (n-1)\sigma^2\). Donc \(\mathbb{E}[S_n^2] = (n-1)\sigma^2/n\).
Borne de Cramér-Rao#
Définition 299 (Information de Fisher)
Pour un modèle régulier à densité \(f_\theta\), l”information de Fisher est
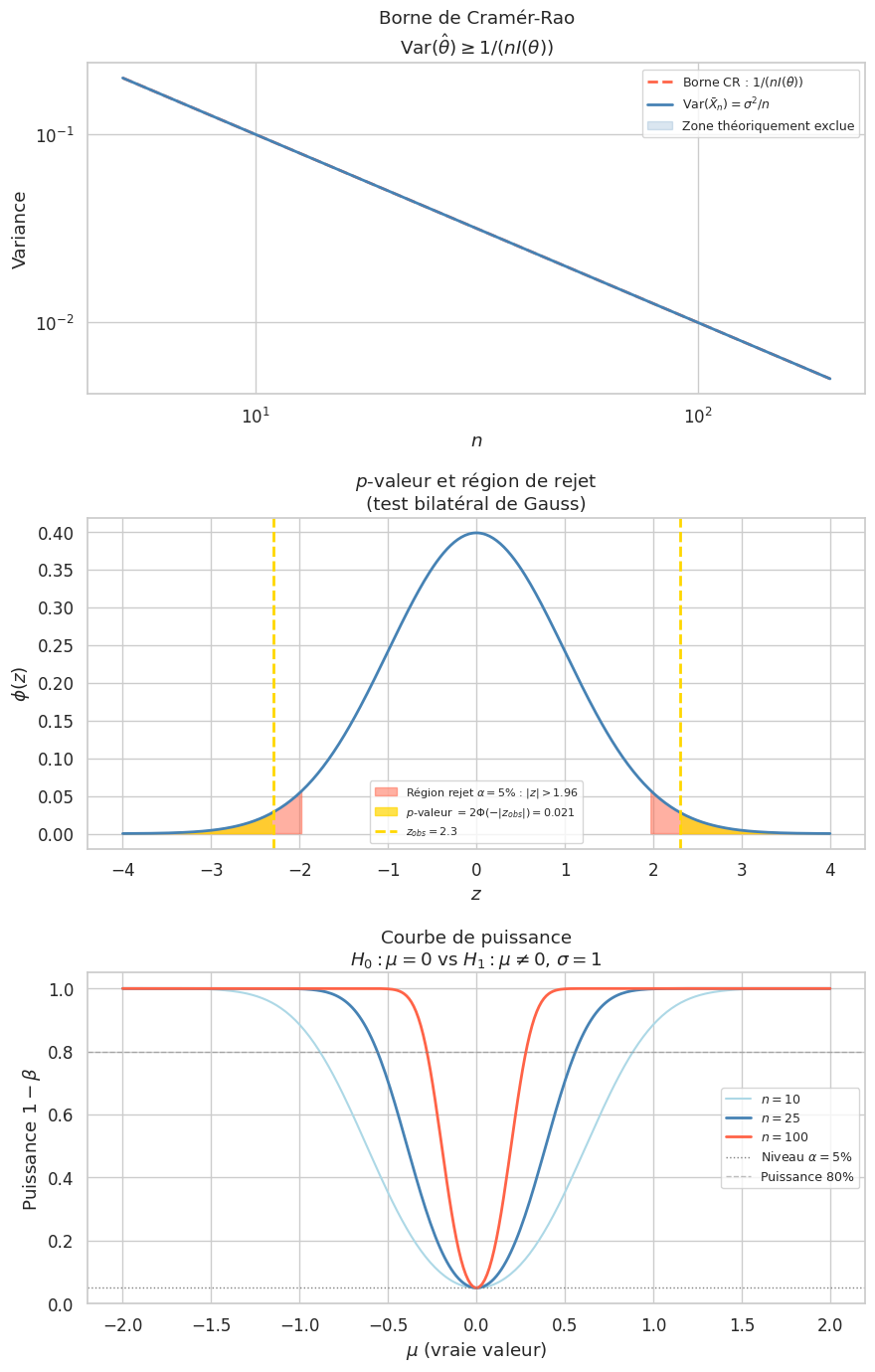
Théorème 85 (Borne de Cramér-Rao)
Pour tout estimateur sans biais \(\hat{\theta}\) de \(\theta\) :
Un estimateur atteignant cette borne est dit efficace.
Proof. Par l’inégalité de Cauchy-Schwarz appliquée à \(\text{Cov}\!\left(\hat{\theta}, \frac{\partial}{\partial\theta}\ln L(\theta)\right)\) où \(L(\theta) = \prod f_\theta(X_i)\) :
En dérivant \(\mathbb{E}_\theta[\hat{\theta}] = \theta\) sous le signe intégral (hypothèse de régularité) :
Et \(\text{Var}\!\left(\frac{\partial \ln L}{\partial\theta}\right) = nI(\theta)\), d’où \(\text{Var}(\hat{\theta}) \geq 1/(nI(\theta))\).
Exemple 161
Modèle gaussien \(\mathcal{N}(\theta, \sigma^2)\) (\(\sigma^2\) connu) : \(\ln f_\theta(x) = -\frac{(x-\theta)^2}{2\sigma^2} + \text{cte}\). \(\frac{\partial \ln f}{\partial\theta} = \frac{x-\theta}{\sigma^2}\). \(I(\theta) = \mathbb{E}\!\left[\left(\frac{X-\theta}{\sigma^2}\right)^2\right] = \frac{1}{\sigma^2}\).
Borne CR : \(\text{Var}(\hat{\theta}) \geq \sigma^2/n\). L’EMV \(\bar{X}_n\) vérifie \(\text{Var}(\bar{X}_n) = \sigma^2/n\) : il est efficace.
Méthode du maximum de vraisemblance#
Définition 300 (Vraisemblance et EMV)
La fonction de vraisemblance pour l’observation \((x_1, \ldots, x_n)\) est
La log-vraisemblance est \(\ell(\theta) = \sum_{i=1}^n \ln f_\theta(x_i)\).
L”estimateur du maximum de vraisemblance (EMV) est \(\hat{\theta}_{MV} = \arg\max_\theta L(\theta)\).
Remarque 143
L’EMV est en général : (1) convergent \(\hat{\theta}_{MV} \xrightarrow{\mathbb{P}} \theta\), (2) asymptotiquement normal \(\sqrt{n}(\hat{\theta}_{MV} - \theta) \xrightarrow{\mathcal{L}} \mathcal{N}(0, 1/I(\theta))\), (3) asymptotiquement efficace (atteint la borne CR asymptotiquement). C’est la méthode d’estimation la plus utilisée en pratique.
Exemple 162
Loi normale \(\mathcal{N}(\mu, \sigma^2)\), les deux paramètres inconnus :
\(\partial\ell/\partial\mu = 0 \implies \hat{\mu}_{MV} = \bar{x}\) \(\partial\ell/\partial\sigma^2 = 0 \implies \hat{\sigma}^2_{MV} = \frac{1}{n}\sum(x_i - \bar{x})^2 = S_n^2\) (biaisé, mais convergent).
Exemple 163
Loi de Bernoulli \(\mathcal{B}(p)\) : \(L(p) = p^{\sum x_i}(1-p)^{n-\sum x_i}\). \(\ell'(p) = \frac{\sum x_i}{p} - \frac{n - \sum x_i}{1-p} = 0 \implies \hat{p}_{MV} = \bar{x}\) (proportion empirique).
Intervalles de confiance#
Définition 301 (Intervalle de confiance)
Un intervalle de confiance (IC) au niveau \(1 - \alpha\) pour \(\theta\) est un intervalle aléatoire \([T_1, T_2]\) tel que
Remarque 144
Interprétation fréquentiste : si on répète l’expérience beaucoup de fois, environ \(100(1-\alpha)\%\) des intervalles construits contiennent \(\theta\). Ce n’est pas «\(\theta\) est dans l’intervalle avec probabilité \(95\%\)» — \(\theta\) est fixe.
Proposition 344 (IC pour \(\mu\) avec \(\sigma\) connu)
Si \(X_1, \ldots, X_n\) i.i.d. \(\mathcal{N}(\mu, \sigma^2)\) :
est un IC de niveau exact \(1 - \alpha\), où \(z_{\alpha/2} = \Phi^{-1}(1 - \alpha/2)\). Pour \(\alpha = 0{,}05\) : \(z_{0{,}025} = 1{,}96\).
Proof. \(Z = \frac{\bar{X}_n - \mu}{\sigma/\sqrt{n}} \sim \mathcal{N}(0,1)\) exactement. \(\mathbb{P}(-z_{\alpha/2} \leq Z \leq z_{\alpha/2}) = 1-\alpha\). En isolant \(\mu\) : \(\mathbb{P}(\bar{X}_n - z_{\alpha/2}\sigma/\sqrt{n} \leq \mu \leq \bar{X}_n + z_{\alpha/2}\sigma/\sqrt{n}) = 1-\alpha\).
Définition 302 (Loi de Student)
Si \(Z \sim \mathcal{N}(0,1)\) et \(V \sim \chi^2(n)\) sont indépendantes, alors \(T = Z/\sqrt{V/n}\) suit la loi de Student \(t(n)\). Sa densité est
Pour \(n \to \infty\) : \(t(n) \to \mathcal{N}(0,1)\).
Proposition 345 (IC pour \(\mu\) avec \(\sigma\) inconnu)
est un IC de niveau exact \(1-\alpha\), où \(t_{\alpha/2, n-1}\) est le quantile de \(t(n-1)\).
Proof. Pour un échantillon gaussien, \(\bar{X}_n\) et \(S_n'^2\) sont indépendantes (théorème de Fisher-Cochran) et \((n-1)S_n'^2/\sigma^2 \sim \chi^2(n-1)\). Donc
Proposition 346 (IC pour une proportion (grand échantillon))
Si \(X_1, \ldots, X_n\) i.i.d. \(\mathcal{B}(p)\) et \(n\) grand :
où \(\hat{p} = \bar{X}_n\). Par le TCL : \((\hat{p} - p)/\sqrt{p(1-p)/n} \xrightarrow{\mathcal{L}} \mathcal{N}(0,1)\).
Tests d’hypothèses#
Définition 303 (Test statistique)
Un test confronte deux hypothèses :
\(H_0\) : l”hypothèse nulle (statu quo)
\(H_1\) : l”hypothèse alternative
Un test est une règle de décision basée sur l’échantillon : on rejette \(H_0\) si la statistique de test tombe dans la région de rejet \(W\).
Définition 304 (Erreurs et puissance)
\(H_0\) vraie |
\(H_1\) vraie |
|
|---|---|---|
Accepter \(H_0\) |
Correct |
Erreur type II (\(\beta\)) |
Rejeter \(H_0\) |
Erreur type I (\(\alpha\)) |
Correct (puissance) |
Risque de 1re espèce : \(\alpha = \mathbb{P}_{H_0}(\text{rejeter } H_0)\) (faux positif)
Risque de 2e espèce : \(\beta = \mathbb{P}_{H_1}(\text{accepter } H_0)\) (faux négatif)
Puissance : \(1 - \beta = \mathbb{P}_{H_1}(\text{rejeter } H_0)\)
Un test est de niveau \(\alpha\) si \(\sup_{\theta \in H_0} \mathbb{P}_\theta(\text{rejeter}) \leq \alpha\).
Exemple 164
Test de Gauss \(H_0 : \mu = \mu_0\) contre \(H_1 : \mu \neq \mu_0\), \(\sigma\) connu.
Statistique : \(Z = \frac{\bar{X}_n - \mu_0}{\sigma/\sqrt{n}}\). Sous \(H_0\) : \(Z \sim \mathcal{N}(0,1)\). Région de rejet : \(|Z| > z_{\alpha/2}\).
Décision : rejeter \(H_0\) si \(|\bar{X}_n - \mu_0| > z_{\alpha/2} \cdot \sigma/\sqrt{n}\).
Définition 305 (\(p\)-valeur)
La \(p\)-valeur est la probabilité, sous \(H_0\), d’observer un résultat au moins aussi extrême que celui observé :
On rejette \(H_0\) au niveau \(\alpha\) si et seulement si \(p \leq \alpha\).
La \(p\)-valeur est le plus petit niveau \(\alpha\) auquel on rejetterait \(H_0\).
Théorème 86 (Test du \(\chi^2\) de Pearson)
Soit \(n\) observations classées en \(k\) catégories, effectifs observés \(O_i\) et théoriques \(E_i = np_i\) sous \(H_0\). La statistique
suit approximativement \(\chi^2(k-1-r)\) sous \(H_0\) (\(r\) = nombre de paramètres estimés). On rejette \(H_0\) si \(\chi^2 > \chi^2_{\alpha, k-1-r}\).
Résumé#
Concept |
Propriété clé |
|---|---|
Estimateur sans biais |
\(\mathbb{E}[\hat{\theta}] = \theta\) |
EQM |
\(\text{Var}(\hat{\theta}) + b(\hat{\theta})^2\) |
Convergent |
\(\hat{\theta}_n \xrightarrow{\mathbb{P}} \theta\) |
Info. de Fisher |
\(I(\theta) = \mathbb{E}[(\partial_\theta \ln f_\theta)^2]\) |
Cramér-Rao |
\(\text{Var}(\hat{\theta}) \geq 1/(nI(\theta))\) |
EMV |
\(\arg\max L(\theta)\), asymptotiquement efficace |
IC pour \(\mu\) (\(\sigma\) connu) |
\(\bar{X} \pm z_{\alpha/2}\sigma/\sqrt{n}\), niveau exact |
IC pour \(\mu\) (\(\sigma\) inconnu) |
\(\bar{X} \pm t_{\alpha/2,n-1}S'/\sqrt{n}\), loi de Student |
IC pour \(p\) |
\(\hat{p} \pm z_{\alpha/2}\sqrt{\hat{p}(1-\hat{p})/n}\) |
\(p\)-valeur |
Rejeter \(H_0\) si \(p \leq \alpha\) |
Test \(\chi^2\) |
\(\sum(O_i-E_i)^2/E_i \sim \chi^2(k-1-r)\) |