
Environnement et outils#
La science est ce que nous comprenons suffisamment bien pour l’expliquer à un ordinateur. L’art, c’est tout le reste.
Donald Knuth
Introduction#
L’apprentissage automatique repose sur un écosystème logiciel riche, dont Python est le pivot central. Ce chapitre présente les outils fondamentaux que tout praticien doit maitriser : le calcul numérique avec NumPy, la manipulation de données avec Pandas, la visualisation avec Matplotlib et Seaborn, et l’apprentissage automatique avec Scikit-learn. Nous verrons également les bonnes pratiques de reproductibilité.
Pourquoi Python ?#
Python s’est impose comme le langage de référence en apprentissage automatique pour plusieurs raisons :
Lisibilité : la syntaxe est proche du pseudocode, ce qui facilite le prototypage rapide.
Ecosystème scientifique : NumPy, SciPy, Pandas, Matplotlib, Scikit-learn, PyTorch, TensorFlow forment un écosystème cohérent et mature.
Intéroperabilité : les bibliothèques critiques (NumPy, SciPy) sont implémentées en C/Fortran, ce qui offre des performances proches du code natif.
Communauté : la communauté scientifique et industrielle est massive, assurant documentation, tutoriels et support.
import sys
print(f"Python {sys.version}")
Python 3.13.5 (main, Jun 25 2025, 18:55:22) [GCC 14.2.0]
NumPy#
NumPy (Numerical Python) est la brique fondamentale du calcul scientifique en Python. Il fournit le type ndarray, un tableau multidimensionnel homogène, ainsi qu’un ensemble complet d’operations vectorisées.
import numpy as np
print(f"NumPy {np.__version__}")
NumPy 2.3.5
Tableaux multidimensionnels#
Définition 1 (ndarray)
Un ndarray (ou tableau NumPy) est une structure de données représentant un tableau multidimensionnel homogène. Il est caracterisé par :
son type (
dtype) : le type de chaque élément (ex.float64,int32)sa forme (
shape) : un tuple \((n_1, n_2, \ldots, n_k)\) donnant la taille de chaque dimensionson rang (
ndim) : le nombre de dimensions \(k\)
Formellement, un ndarray de forme \((n_1, \ldots, n_k)\) représente un élément de \(\mathbb{R}^{n_1 \times n_2 \times \cdots \times n_k}\) (ou d’un autre type numérique).
# Création de tableaux
a = np.array([1, 2, 3, 4, 5])
print(f"Vecteur : {a}")
print(f"Shape : {a.shape}, dtype : {a.dtype}, ndim : {a.ndim}")
Vecteur : [1 2 3 4 5]
Shape : (5,), dtype : int64, ndim : 1
# Matrice 2D
M = np.array([[1, 2, 3],
[4, 5, 6]])
print(f"Matrice :\n{M}")
print(f"Shape : {M.shape}, ndim : {M.ndim}")
Matrice :
[[1 2 3]
[4 5 6]]
Shape : (2, 3), ndim : 2
# Fonctions de création courantes
zeros = np.zeros((3, 4)) # matrice 3x4 de zeros
ones = np.ones((2, 3)) # matrice 2x3 de uns
eye = np.eye(3) # matrice identité 3x3
lin = np.linspace(0, 1, 5) # 5 points équidistants dans [0, 1]
arange = np.arange(0, 10, 2) # équivalent de range, pas de 2
rand = np.random.randn(3, 3) # matrice 3x3 gaussienne
print(f"linspace : {lin}")
print(f"arange : {arange}")
print(f"Identite :\n{eye}")
linspace : [0. 0.25 0.5 0.75 1. ]
arange : [0 2 4 6 8]
Identite :
[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]
Operations vectorisées#
Proposition 1 (Operations élément par élément)
Soit \(A, B\) deux tableaux de même forme \((n_1, \ldots, n_k)\). Les opérations arithmétiques \(+, -, \times, /\) sont définies élément par élément :
où \(\circ \in \{+, -, \times, /\}\). Ces opérations sont vectorisées : elles sont executées en C, sans boucle Python explicite.
a = np.array([1.0, 2.0, 3.0, 4.0])
b = np.array([10.0, 20.0, 30.0, 40.0])
print(f"a + b = {a + b}")
print(f"a * b = {a * b}") # produit élément par élément
print(f"a / b = {a / b}")
print(f"a ** 2 = {a ** 2}") # puissance élément par élément
print(f"np.sqrt(a) = {np.sqrt(a)}")
a + b = [11. 22. 33. 44.]
a * b = [ 10. 40. 90. 160.]
a / b = [0.1 0.1 0.1 0.1]
a ** 2 = [ 1. 4. 9. 16.]
np.sqrt(a) = [1. 1.41421356 1.73205081 2. ]
Remarque 1
Le produit * entre deux tableaux NumPy est le produit élément par élément (produit de Hadamard), et non le produit matriciel. Pour le produit matriciel, on utilise l’opérateur @ ou la fonction np.dot.
# Produit matriciel
A = np.array([[1, 2],
[3, 4]])
B = np.array([[5, 6],
[7, 8]])
print(f"Produit élément par élément A * B :\n{A * B}")
print(f"\nProduit matriciel A @ B :\n{A @ B}")
Produit élément par élément A * B :
[[ 5 12]
[21 32]]
Produit matriciel A @ B :
[[19 22]
[43 50]]
Broadcasting#
Définition 2 (Broadcasting)
Le broadcasting est le mécanisme par lequel NumPy permet d’effectuer des opérations entre tableaux de formes différentes. Deux tableaux sont compatibles pour le broadcasting si, en parcourant leurs dimensions de droite à gauche, chaque paire de dimensions vérifie l’une des conditions suivantes :
Les dimensions sont égales : \(n_i = m_i\)
L’une des dimensions vaut 1 : \(n_i = 1\) ou \(m_i = 1\)
Si l’un des tableaux a moins de dimensions, il est préalablement complété par des dimensions de taille 1 à gauche.
Formellement, si \(A\) a pour forme \((n_1, \ldots, n_k)\) et \(B\) a pour forme \((m_1, \ldots, m_k)\) (après alignement), alors le resultat \(C = A \circ B\) a pour forme \((\max(n_1, m_1), \ldots, \max(n_k, m_k))\).
Exemple 1 (Broadcasting en pratique)
Si \(A\) est de forme \((3, 4)\) et \(b\) de forme \((4,)\) :
\(b\) est d’abord vu comme ayant la forme \((1, 4)\)
Les formes \((3, 4)\) et \((1, 4)\) sont compatibles (\(3 \neq 1\) mais la seconde dimension est égale)
Le résultat est de forme \((3, 4)\) : \(b\) est « répliqué » le long de la première dimension
# Broadcasting : ajouter un vecteur à chaque ligne d'une matrice
M = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
v = np.array([10, 20, 30])
print(f"M + v :\n{M + v}")
# Equivalent à : chaque ligne de M reçoit l'addition de v
M + v :
[[11 22 33]
[14 25 36]
[17 28 39]]
# Broadcasting : produit extérieur
x = np.array([1, 2, 3]).reshape(3, 1) # colonne (3, 1)
y = np.array([10, 20, 30]) # ligne (3,)
print(f"Produit extérieur x * y :\n{x * y}")
# x de forme (3, 1) et y de forme (3,) -> (1, 3) -> resultat (3, 3)
Produit extérieur x * y :
[[10 20 30]
[20 40 60]
[30 60 90]]
Indexation et slicing#
Remarque 2
L’indexation NumPy est une généralisation puissante de l’indexation Python. Outre l’indexation classique par position et le slicing, NumPy supporte l”indexation booléenne (masques) et l”indexation avancée (fancy indexing) par tableaux d’indices.
a = np.arange(10)
print(f"a = {a}")
print(f"a[3] = {a[3]}")
print(f"a[2:7] = {a[2:7]}")
print(f"a[::2] = {a[::2]}") # un élément sur deux
print(f"a[::-1] = {a[::-1]}") # inversion
a = [0 1 2 3 4 5 6 7 8 9]
a[3] = 3
a[2:7] = [2 3 4 5 6]
a[::2] = [0 2 4 6 8]
a[::-1] = [9 8 7 6 5 4 3 2 1 0]
# Indexation booléenne (masques)
a = np.array([1, -2, 3, -4, 5, -6])
masque = a > 0
print(f"a = {a}")
print(f"Masque (a > 0) : {masque}")
print(f"Eléments positifs : {a[masque]}")
# Modification conditionnelle
a[a < 0] = 0
print(f"Après mise à zero des négatifs : {a}")
a = [ 1 -2 3 -4 5 -6]
Masque (a > 0) : [ True False True False True False]
Eléments positifs : [1 3 5]
Après mise à zero des négatifs : [1 0 3 0 5 0]
# Indexation 2D
M = np.arange(12).reshape(3, 4)
print(f"M :\n{M}")
print(f"M[1, 2] = {M[1, 2]}") # élément (ligne 1, colonne 2)
print(f"M[:, 1] = {M[:, 1]}") # colonne 1
print(f"M[0:2, 1:3] :\n{M[0:2, 1:3]}") # sous-matrice
M :
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
M[1, 2] = 6
M[:, 1] = [1 5 9]
M[0:2, 1:3] :
[[1 2]
[5 6]]
Fonctions d’agrégation#
M = np.random.randn(4, 3)
print(f"M :\n{M}\n")
print(f"Somme totale : {M.sum():.4f}")
print(f"Somme par colonne : {M.sum(axis=0)}") # aggrégation le long des lignes
print(f"Somme par ligne : {M.sum(axis=1)}") # aggrégation le long des colonnes
print(f"Moyenne : {M.mean():.4f}")
print(f"Ecart-type : {M.std():.4f}")
print(f"Min, Max : {M.min():.4f}, {M.max():.4f}")
print(f"Argmin (global) : {M.argmin()}")
M :
[[-0.30354041 -0.86186641 0.63670767]
[-0.56290309 -1.62428139 1.07495726]
[-1.92541686 -1.07383455 -0.55276742]
[ 0.83407289 -0.29538444 -0.7677665 ]]
Somme totale : -5.4220
Somme par colonne : [-1.95778748 -3.85536678 0.391131 ]
Somme par ligne : [-0.52869915 -1.11222722 -3.55201883 -0.22907805]
Moyenne : -0.4518
Ecart-type : 0.8869
Min, Max : -1.9254, 1.0750
Argmin (global) : 6
Algèbre linéaire#
NumPy fournit un sous-module numpy.linalg pour les opérations d’algèbre linéaire courantes.
A = np.array([[2, 1],
[1, 3]])
# Déterminant
det = np.linalg.det(A)
print(f"det(A) = {det:.1f}")
# Valeurs propres et vecteurs propres
valeurs, vecteurs = np.linalg.eig(A)
print(f"Valeurs propres : {valeurs}")
print(f"Vecteurs propres :\n{vecteurs}")
# Inverse
A_inv = np.linalg.inv(A)
print(f"A^(-1) :\n{A_inv}")
print(f"Vérification A @ A^(-1) :\n{A @ A_inv}")
det(A) = 5.0
Valeurs propres : [1.38196601 3.61803399]
Vecteurs propres :
[[-0.85065081 -0.52573111]
[ 0.52573111 -0.85065081]]
A^(-1) :
[[ 0.6 -0.2]
[-0.2 0.4]]
Vérification A @ A^(-1) :
[[ 1.00000000e+00 0.00000000e+00]
[-5.55111512e-17 1.00000000e+00]]
# Résolution d'un système linéaire Ax = b
A = np.array([[3, 1], [1, 2]])
b = np.array([9, 8])
x = np.linalg.solve(A, b)
print(f"Solution de Ax = b : x = {x}")
print(f"Vérification : A @ x = {A @ x}")
Solution de Ax = b : x = [2. 3.]
Vérification : A @ x = [9. 8.]
Pandas#
Pandas est la bibliothèque de référence pour la manipulation et l’analyse de données tabulaires en Python. Elle fournit deux structures fondamentales : les Series et les DataFrame.
import pandas as pd
print(f"Pandas {pd.__version__}")
Pandas 3.0.0
Series#
Définition 3 (Series)
Une Series Pandas est un tableau unidimensionnel étiqueté. Chaque élément est associé à un index (étiquette). Formellement, une Series est une application \(f : I \to V\) où \(I\) est l’ensemble des étiquettes (l’index) et \(V\) l’ensemble des valeurs, toutes de même type.
# Création d'une Series
s = pd.Series([10, 20, 30, 40], index=['a', 'b', 'c', 'd'])
print(s)
print(f"\nIndex : {s.index.tolist()}")
print(f"Valeurs : {s.values}")
print(f"s['b'] = {s['b']}")
a 10
b 20
c 30
d 40
dtype: int64
Index : ['a', 'b', 'c', 'd']
Valeurs : [10 20 30 40]
s['b'] = 20
DataFrame#
Définition 4 (DataFrame)
Un DataFrame Pandas est un tableau bidimensionnel étiqueté : chaque ligne possède un index (etiquette de ligne) et chaque colonne possède un nom (étiquette de colonne). Chaque colonne est une Series. Formellement, un DataFrame de \(n\) lignes et \(p\) colonnes représente une matrice de données \(X \in \mathcal{V}_1 \times \cdots \times \mathcal{V}_p\) où chaque \(\mathcal{V}_j\) est le domaine de la \(j\)-ième variable (colonne). Les colonnes peuvent avoir des types différents (numérique, catégoriel, texte, dates…).
# Création d'un DataFrame
df = pd.DataFrame({
'nom': ['Alice', 'Bob', 'Charlie', 'Diana', 'Eve'],
'age': [25, 30, 35, 28, 32],
'ville': ['Paris', 'Lyon', 'Paris', 'Marseille', 'Lyon'],
'salaire': [45000, 52000, 61000, 48000, 55000]
})
print(df)
nom age ville salaire
0 Alice 25 Paris 45000
1 Bob 30 Lyon 52000
2 Charlie 35 Paris 61000
3 Diana 28 Marseille 48000
4 Eve 32 Lyon 55000
# Informations sur le DataFrame
print(df.info())
print(f"\nStatistiques descriptives :\n{df.describe()}")
<class 'pandas.DataFrame'>
RangeIndex: 5 entries, 0 to 4
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 nom 5 non-null str
1 age 5 non-null int64
2 ville 5 non-null str
3 salaire 5 non-null int64
dtypes: int64(2), str(2)
memory usage: 292.0 bytes
None
Statistiques descriptives :
age salaire
count 5.000000 5.000000
mean 30.000000 52200.000000
std 3.807887 6220.932406
min 25.000000 45000.000000
25% 28.000000 48000.000000
50% 30.000000 52000.000000
75% 32.000000 55000.000000
max 35.000000 61000.000000
Lecture de données#
Remarque 3
Pandas propose de nombreuses fonctions de lecture : read_csv, read_excel, read_json, read_sql, read_parquet, etc. Le format CSV (Comma-Separated Values) est le plus courant pour les jeux de données d’apprentissage automatique.
# Simulation : création d'un CSV en mémoire et lecture
from io import StringIO
csv_data = """nom,age,score,reussite
Alice,25,85.5,True
Bob,30,72.0,False
Charlie,35,91.2,True
Diana,28,68.3,False
Eve,32,88.7,True
Frank,27,75.1,True
"""
df = pd.read_csv(StringIO(csv_data))
print(df)
print(f"\nTypes :\n{df.dtypes}")
nom age score reussite
0 Alice 25 85.5 True
1 Bob 30 72.0 False
2 Charlie 35 91.2 True
3 Diana 28 68.3 False
4 Eve 32 88.7 True
5 Frank 27 75.1 True
Types :
nom str
age int64
score float64
reussite bool
dtype: object
Filtrage et selection#
# Selection de colonnes
print("Colonne 'score' :")
print(df['score'])
print("\nPlusieurs colonnes :")
print(df[['nom', 'score']])
Colonne 'score' :
0 85.5
1 72.0
2 91.2
3 68.3
4 88.7
5 75.1
Name: score, dtype: float64
Plusieurs colonnes :
nom score
0 Alice 85.5
1 Bob 72.0
2 Charlie 91.2
3 Diana 68.3
4 Eve 88.7
5 Frank 75.1
# Filtrage par condition (indexation booléenne)
reussis = df[df['reussite'] == True]
print("Etudiants ayant réussi :")
print(reussis)
# Conditions combinées
bons = df[(df['score'] > 80) & (df['age'] < 35)]
print("\nScore > 80 et age < 35 :")
print(bons)
Etudiants ayant réussi :
nom age score reussite
0 Alice 25 85.5 True
2 Charlie 35 91.2 True
4 Eve 32 88.7 True
5 Frank 27 75.1 True
Score > 80 et age < 35 :
nom age score reussite
0 Alice 25 85.5 True
4 Eve 32 88.7 True
# loc (par étiquettes) et iloc (par position)
print(f"df.loc[0, 'nom'] = {df.loc[0, 'nom']}")
print(f"df.iloc[0, 1] = {df.iloc[0, 1]}")
print(f"\nLignes 1 a 3, colonnes 'nom' et 'score' :")
print(df.loc[1:3, ['nom', 'score']])
df.loc[0, 'nom'] = Alice
df.iloc[0, 1] = 25
Lignes 1 a 3, colonnes 'nom' et 'score' :
nom score
1 Bob 72.0
2 Charlie 91.2
3 Diana 68.3
Groupby et agrégation#
Remarque 4
L’operation groupby implémente le paradigme split-apply-combine : les données sont partitionnées en groupes selon une ou plusieurs clés, une fonction d’agrégation est appliquée à chaque groupe, et les résultats sont recombinés en un seul objet.
df_villes = pd.DataFrame({
'ville': ['Paris', 'Lyon', 'Paris', 'Marseille', 'Lyon', 'Paris'],
'departement': ['75', '69', '75', '13', '69', '75'],
'ventes': [120, 80, 150, 90, 110, 130],
'mois': ['jan', 'jan', 'fev', 'jan', 'fev', 'mar']
})
print("Données :")
print(df_villes)
print("\nVentes moyennes par ville :")
print(df_villes.groupby('ville')['ventes'].mean())
print("\nStatistiques par ville :")
print(df_villes.groupby('ville')['ventes'].agg(['mean', 'sum', 'count']))
Données :
ville departement ventes mois
0 Paris 75 120 jan
1 Lyon 69 80 jan
2 Paris 75 150 fev
3 Marseille 13 90 jan
4 Lyon 69 110 fev
5 Paris 75 130 mar
Ventes moyennes par ville :
ville
Lyon 95.000000
Marseille 90.000000
Paris 133.333333
Name: ventes, dtype: float64
Statistiques par ville :
mean sum count
ville
Lyon 95.000000 190 2
Marseille 90.000000 90 1
Paris 133.333333 400 3
Merge (jointures)#
# Deux tables à joindre
clients = pd.DataFrame({
'client_id': [1, 2, 3, 4],
'nom': ['Alice', 'Bob', 'Charlie', 'Diana']
})
commandes = pd.DataFrame({
'commande_id': [101, 102, 103, 104, 105],
'client_id': [1, 2, 1, 3, 5],
'montant': [50.0, 30.0, 75.0, 120.0, 45.0]
})
# Inner join (par defaut)
result = pd.merge(clients, commandes, on='client_id')
print("Inner join :")
print(result)
# Left join
result_left = pd.merge(clients, commandes, on='client_id', how='left')
print("\nLeft join :")
print(result_left)
Inner join :
client_id nom commande_id montant
0 1 Alice 101 50.0
1 1 Alice 103 75.0
2 2 Bob 102 30.0
3 3 Charlie 104 120.0
Left join :
client_id nom commande_id montant
0 1 Alice 101.0 50.0
1 1 Alice 103.0 75.0
2 2 Bob 102.0 30.0
3 3 Charlie 104.0 120.0
4 4 Diana NaN NaN
Données manquantes#
df_nan = pd.DataFrame({
'A': [1, 2, np.nan, 4],
'B': [np.nan, 2, 3, 4],
'C': [1, 2, 3, np.nan]
})
print("Données avec valeurs manquantes :")
print(df_nan)
print(f"\nNombre de NaN par colonne :\n{df_nan.isna().sum()}")
# Remplissage
print(f"\nRemplissage par la moyenne :\n{df_nan.fillna(df_nan.mean())}")
# Suppression des lignes avec NaN
print(f"\nSuppression des lignes avec NaN :\n{df_nan.dropna()}")
Données avec valeurs manquantes :
A B C
0 1.0 NaN 1.0
1 2.0 2.0 2.0
2 NaN 3.0 3.0
3 4.0 4.0 NaN
Nombre de NaN par colonne :
A 1
B 1
C 1
dtype: int64
Remplissage par la moyenne :
A B C
0 1.000000 3.0 1.0
1 2.000000 2.0 2.0
2 2.333333 3.0 3.0
3 4.000000 4.0 2.0
Suppression des lignes avec NaN :
A B C
1 2.0 2.0 2.0
Matplotlib et Seaborn#
Matplotlib est la bibliothèque de visualisation de base en Python. Seaborn est construite au-dessus de Matplotlib et propose des graphiques statistiques de haut niveau avec un style soigné.
import matplotlib.pyplot as plt
import matplotlib
print(f"Matplotlib {matplotlib.__version__}")
Matplotlib 3.10.8
Graphiques de base avec Matplotlib#
# Courbe simple
x = np.linspace(0, 2 * np.pi, 200)
y1 = np.sin(x)
y2 = np.cos(x)
fig, ax = plt.subplots(figsize=(8, 4))
ax.plot(x, y1, label=r'$\sin(x)$', color='steelblue')
ax.plot(x, y2, label=r'$\cos(x)$', color='coral', linestyle='--')
ax.set_xlabel('$x$')
ax.set_ylabel('$f(x)$')
ax.set_title('Fonctions trigonométriques')
ax.legend()
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# Nuage de points
np.random.seed(42)
n = 100
x = np.random.randn(n)
y = 2 * x + 1 + np.random.randn(n) * 0.5
fig, ax = plt.subplots(figsize=(6, 5))
ax.scatter(x, y, alpha=0.6, edgecolors='k', linewidths=0.5)
ax.set_xlabel('$x$')
ax.set_ylabel('$y$')
ax.set_title('Nuage de points : $y = 2x + 1 + \\varepsilon$')
plt.tight_layout()
plt.show()

# Sous-graphiques (subplots)
fig, axes = plt.subplots(3, 1, figsize=(9, 11))
# Histogramme
data = np.random.randn(1000)
axes[0].hist(data, bins=30, color='steelblue', edgecolor='white', alpha=0.8)
axes[0].set_title('Histogramme')
# Diagramme en barres
categories = ['A', 'B', 'C', 'D']
valeurs = [23, 45, 56, 78]
axes[1].bar(categories, valeurs, color=['#3498db', '#e74c3c', '#2ecc71', '#f39c12'])
axes[1].set_title('Diagramme en barres')
# Boite a moustaches
data_box = [np.random.randn(50) + i for i in range(4)]
axes[2].boxplot(data_box, tick_labels=['G1', 'G2', 'G3', 'G4'])
axes[2].set_title('Boites à moustaches')
plt.tight_layout()
plt.show()
Graphiques statistiques avec Seaborn#
import seaborn as sns
print(f"Seaborn {sns.__version__}")
sns.set_theme(style='whitegrid')
Seaborn 0.13.2
# Chargement d'un jeu de données intègre
tips = sns.load_dataset('tips')
print(tips.head())
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
# Distribution
fig, axes = plt.subplots(2, 1, figsize=(9, 7))
sns.histplot(tips['total_bill'], kde=True, ax=axes[0], color='steelblue')
axes[0].set_title('Distribution de total_bill')
sns.boxplot(x='day', y='total_bill', data=tips, ax=axes[1])
axes[1].set_title('total_bill par jour')
plt.tight_layout()
plt.show()
# Relation entre variables
fig, axes = plt.subplots(2, 1, figsize=(9, 9))
sns.scatterplot(x='total_bill', y='tip', hue='smoker', data=tips, ax=axes[0])
axes[0].set_title('Pourboire vs. addition')
sns.heatmap(tips[['total_bill', 'tip', 'size']].corr(),
annot=True, cmap='coolwarm', vmin=-1, vmax=1, ax=axes[1])
axes[1].set_title('Matrice de correlation')
plt.tight_layout()
plt.show()
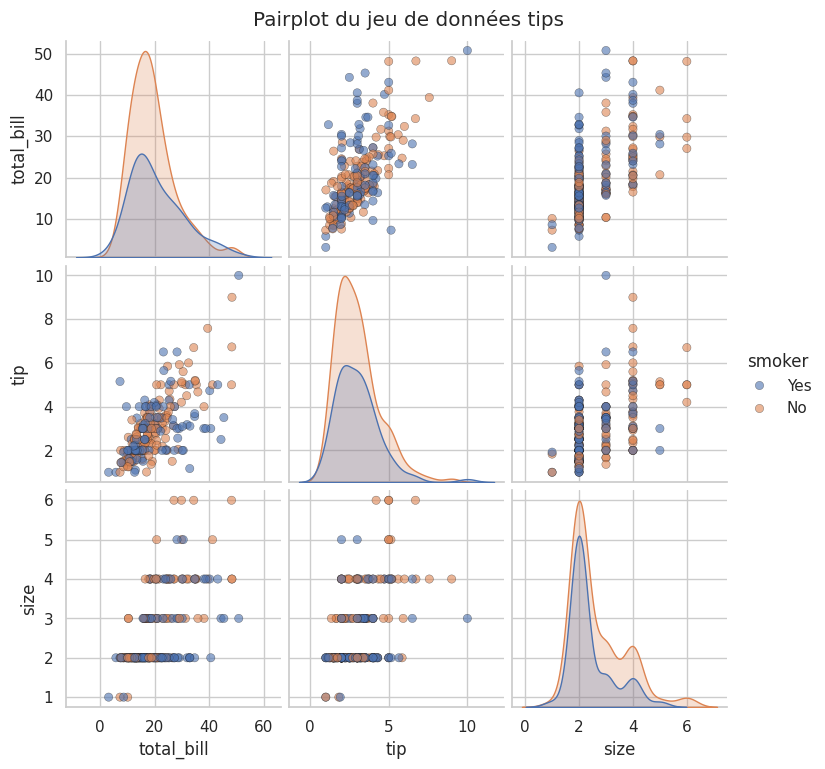
# Pairplot : vision globale des relations entre variables
sns.pairplot(tips, hue='smoker', height=2.5,
plot_kws={'alpha': 0.6, 'edgecolor': 'k', 'linewidth': 0.3})
plt.suptitle('Pairplot du jeu de données tips', y=1.02)
plt.show()
Scikit-learn#
Scikit-learn est la bibliothèque de reference pour l’apprentissage automatique classique en Python. Sa force reside dans une API cohérente et une architecture modulaire.
import sklearn
print(f"Scikit-learn {sklearn.__version__}")
Scikit-learn 1.8.0
Philosophie et API#
Définition 5 (Estimateur (Scikit-learn))
Un estimateur est tout objet qui apprend à partir de données. Dans Scikit-learn, un estimateur est une classe Python implémentant la méthode fit(X, y=None) qui ajuste le modèle aux données d’entrainement.
Classifieurs et regresseurs (apprentissage supervisé) implémentent en plus
predict(X)pour produire des prédictions.Transformateurs implémentent
transform(X)pour transformer les données (et souventfit_transform(X)pour combiner les deux en une seule passe).Pipelines chainent plusieurs transformateurs et un estimateur final.
Remarque 5
L’API uniforme de Scikit-learn suit toujours le même schema :
Instancier le modèle avec ses hyperparamètres :
model = MonModele(param=valeur)Entrainer sur les données :
model.fit(X_train, y_train)Prédire sur de nouvelles données :
y_pred = model.predict(X_test)Evaluer les performances :
score = model.score(X_test, y_test)
Cette uniformité est l’un des atouts majeurs de la bibliothèque : changer de modèle ne modifie qu’une seule ligne de code.
Exemple complet : classification#
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, classification_report
# 1. Charger les données
iris = load_iris()
X, y = iris.data, iris.target
print(f"Forme de X : {X.shape}")
print(f"Classes : {iris.target_names}")
Forme de X : (150, 4)
Classes : ['setosa' 'versicolor' 'virginica']
# 2. Séparer en entrainement / test
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)
print(f"Entrainement : {X_train.shape[0]} echantillons")
print(f"Test : {X_test.shape[0]} echantillons")
Entrainement : 105 echantillons
Test : 45 echantillons
# 3. Prétraiter (standardisation)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test) # on utilise les stats de l'entrainement
print(f"Moyenne avant standardisation : {X_train[:, 0].mean():.2f}")
print(f"Moyenne après standardisation : {X_train_scaled[:, 0].mean():.6f}")
print(f"Ecart-type après standardisation : {X_train_scaled[:, 0].std():.6f}")
Moyenne avant standardisation : 5.87
Moyenne après standardisation : 0.000000
Ecart-type après standardisation : 1.000000
# 4. Entrainer un classifieur
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train_scaled, y_train)
# 5. Prédire et évaluer
y_pred = knn.predict(X_test_scaled)
print(f"Précision : {accuracy_score(y_test, y_pred):.2%}")
print(f"\nRapport de classification :\n{classification_report(y_test, y_pred, target_names=iris.target_names)}")
Précision : 91.11%
Rapport de classification :
precision recall f1-score support
setosa 1.00 1.00 1.00 15
versicolor 0.79 1.00 0.88 15
virginica 1.00 0.73 0.85 15
accuracy 0.91 45
macro avg 0.93 0.91 0.91 45
weighted avg 0.93 0.91 0.91 45
Pipelines#
Définition 6 (Pipeline (Scikit-learn))
Un Pipeline est une séquence ordonnée d’étapes, chacune étant un couple (nom, estimateur). Toutes les étapes sauf la dernière doivent être des transformateurs (implémenter transform). La dernière étape peut être un estimateur quelconque. L’appel à fit du pipeline enchaine les fit_transform des étapes intermédiaires, puis le fit de la dernière étape.
from sklearn.pipeline import Pipeline
# Pipeline = standardisation + KNN
pipe = Pipeline([
('scaler', StandardScaler()),
('knn', KNeighborsClassifier(n_neighbors=5))
])
# En une seule ligne : entrainement et évaluation
pipe.fit(X_train, y_train)
score = pipe.score(X_test, y_test)
print(f"Score du pipeline : {score:.2%}")
Score du pipeline : 91.11%
Exemple : régression linéaire#
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Données synthétiques
np.random.seed(42)
X_reg = np.random.randn(100, 1) * 2
y_reg = 3 * X_reg.ravel() + 7 + np.random.randn(100) * 1.5
X_train_r, X_test_r, y_train_r, y_test_r = train_test_split(
X_reg, y_reg, test_size=0.3, random_state=42
)
# Entrainement
lr = LinearRegression()
lr.fit(X_train_r, y_train_r)
y_pred_r = lr.predict(X_test_r)
print(f"Coefficient : {lr.coef_[0]:.3f} (attendu : 3)")
print(f"Ordonnée à l'origine : {lr.intercept_:.3f} (attendu : 7)")
print(f"R^2 : {r2_score(y_test_r, y_pred_r):.4f}")
print(f"RMSE : {np.sqrt(mean_squared_error(y_test_r, y_pred_r)):.4f}")
Coefficient : 2.880 (attendu : 3)
Ordonnée à l'origine : 7.139 (attendu : 7)
R^2 : 0.9087
RMSE : 1.3861
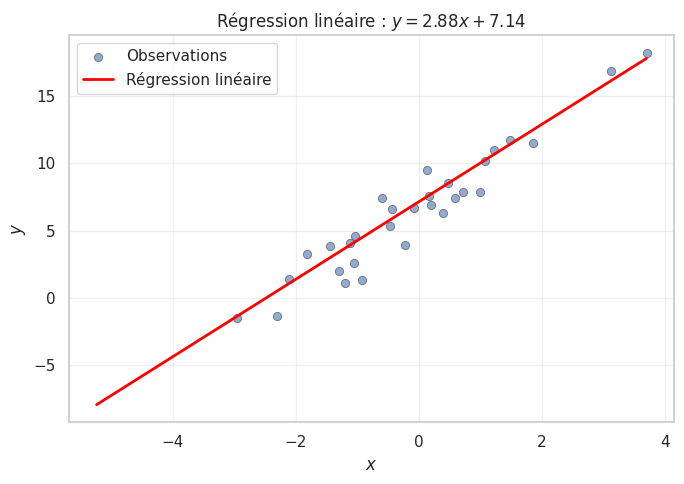
# Visualisation de la régression
fig, ax = plt.subplots(figsize=(7, 5))
ax.scatter(X_test_r, y_test_r, alpha=0.6, label='Observations', edgecolors='k', linewidths=0.5)
X_plot = np.linspace(X_reg.min(), X_reg.max(), 100).reshape(-1, 1)
ax.plot(X_plot, lr.predict(X_plot), color='red', linewidth=2, label='Régression linéaire')
ax.set_xlabel('$x$')
ax.set_ylabel('$y$')
ax.set_title(f'Régression linéaire : $y = {lr.coef_[0]:.2f}x + {lr.intercept_:.2f}$')
ax.legend()
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
Jupyter#
Les notebooks Jupyter sont l’environnement de travail privilegié pour l’exploration de données et le prototypage en apprentissage automatique.
Notebooks et kernels#
Définition 7 (Notebook Jupyter)
Un notebook Jupyter est un document intéractif composé d’une séquence de cellules. Chaque cellule est soit :
une cellule de code : contient du code exécutable (Python, R, Julia, etc.)
une cellule Markdown : contient du texte mis en forme, des équations LaTeX, des images
Le notebook est connecté à un kernel, un processus qui exécute le code. Le kernel maintient l’état (variables, imports) entre les exécutions de cellules.
Remarque 6
L’exécution des cellules dans un notebook n’est pas nécessairement séquentielle : l’utilisateur peut exécuter les cellules dans n’importe quel ordre. Cela peut mener à des états incohérents (variables définies dans un ordre différent de l’affichage). C’est une source classique de bugs ; il est recommandé de régulièrement redémarrer le kernel et de re-exécuter toutes les cellules depuis le debut (Restart & Run All).
Commandes magiques#
Les commandes magiques (magic commands) sont des extensions spécifiques à IPython/Jupyter qui facilitent le travail intéractif.
# %timeit : mesure du temps d'exécution (ligne)
%timeit np.dot(np.random.randn(100), np.random.randn(100))
7.48 μs ± 40.3 ns per loop (mean ± std. dev. of 7 runs, 100,000 loops each)
%%timeit
# Mesure du temps d'exécution (cellule entière)
a = np.random.randn(1000)
b = np.random.randn(1000)
c = a + b
46.2 μs ± 47.2 ns per loop (mean ± std. dev. of 7 runs, 10,000 loops each)
Remarque 7
Parmi les commandes magiques les plus utiles :
%timeit/%%timeit: benchmark%matplotlib inline: affichage des graphiques dans le notebook%who/%whos: lister les variables définies%load_ext: charger une extension%%writefile: écrire le contenu d’une cellule dans un fichier%run: exécuter un script Python
Comparaison : boucle Python vs. NumPy vectorisé#
Un exemple classique qui illustre l’intérêt du calcul vectorisé.
n = 100_000
a = np.random.randn(n)
b = np.random.randn(n)
# Version boucle Python
def dot_python(a, b):
s = 0.0
for i in range(len(a)):
s += a[i] * b[i]
return s
# Comparaison
import time
start = time.perf_counter()
for _ in range(10):
dot_python(a, b)
temps_python = (time.perf_counter() - start) / 10
start = time.perf_counter()
for _ in range(10):
np.dot(a, b)
temps_numpy = (time.perf_counter() - start) / 10
print(f"Boucle Python : {temps_python*1000:.2f} ms")
print(f"NumPy np.dot : {temps_numpy*1000:.4f} ms")
print(f"Accélération : x{temps_python/temps_numpy:.0f}")
Boucle Python : 34.15 ms
NumPy np.dot : 0.0682 ms
Accélération : x500
Reproductibilité#
La reproductibilité est un enjeu majeur en apprentissage automatique. Un résultat scientifique doit pouvoir être reproduit par un tiers disposant du même code et des mêmes données.
Graines aléatoires#
Définition 8 (Graine aléatoire)
Une graine aléatoire (random seed) est un entier qui initialise le générateur de nombres pseudo-aléatoires (PRNG). Fixer la graine garantit que la même séquence de nombres sera produite à chaque exécution, assurant la reproductibilité des resultats.
# Sans graine : résultats différents à chaque exécution
print("Sans graine :")
print(np.random.randn(3))
print(np.random.randn(3))
# Avec graine : résultats identiques
print("\nAvec graine (42) :")
np.random.seed(42)
print(np.random.randn(3))
np.random.seed(42)
print(np.random.randn(3))
Sans graine :
[-0.94098177 -0.96139537 0.76457362]
[ 0.00344685 -1.13088264 0.38307273]
Avec graine (42) :
[ 0.49671415 -0.1382643 0.64768854]
[ 0.49671415 -0.1382643 0.64768854]
Remarque 8
En pratique, il est recommandé d’utiliser un objet np.random.Generator plutôt que la graine globale np.random.seed. Cela évite les effets de bord entre différentes parties du code.
# Bonne pratique : utiliser un Generator
rng = np.random.default_rng(seed=42)
print(f"Echantillon 1 : {rng.standard_normal(3)}")
rng2 = np.random.default_rng(seed=42)
print(f"Echantillon 2 : {rng2.standard_normal(3)}") # identique
Echantillon 1 : [ 0.30471708 -1.03998411 0.7504512 ]
Echantillon 2 : [ 0.30471708 -1.03998411 0.7504512 ]
Environnements virtuels#
Remarque 9
Un environnement virtuel isole les dépendances d’un projet. Cela garantit que les versions des bibliothèques utilisées sont fixées et que le projet ne souffre pas de conflits avec d’autres projets.
Deux outils courants :
venv(integré a Python) :python -m venv mon_envconda(Anaconda/Miniconda) :conda create -n mon_env python=3.11
Le fichier requirements.txt ou environment.yml enregistre les dépendances et leurs versions, permettant à un tiers de reconstruire l’environnement exact.
# Afficher les versions des packages clés
import importlib
packages = ['numpy', 'pandas', 'matplotlib', 'seaborn', 'sklearn']
for pkg in packages:
try:
mod = importlib.import_module(pkg)
version = getattr(mod, '__version__', 'N/A')
print(f"{pkg:15s} {version}")
except ImportError:
print(f"{pkg:15s} non installé")
numpy 2.3.5
pandas 3.0.0
matplotlib 3.10.8
seaborn 0.13.2
sklearn 1.8.0
Versionnement du code#
Remarque 10
Le versionnement du code avec Git est indispensable en pratique. Quelques bonnes pratiques :
Versionner le code et les notebooks (attention : les notebooks sont des fichiers JSON, les diffs sont difficiles à lire ; des outils comme
nbstripoutoujupytextaident à gérer cela).Ne pas versionner les données volumineuses (utiliser Git LFS ou DVC).
Documenter les expériences (hyperparamètres, résultats) dans un fichier de suivi ou un outil dedié (MLflow, Weights & Biases).
Résumé des bonnes pratiques#
Proposition 2 (Checklist de reproductibilite)
Pour qu’une expérience d’apprentissage automatique soit reproductible, il convient de :
Fixer les graines aléatoires de tous les générateurs (NumPy, Python, framework de deep learning)
Geler les versions des dépendances (
requirements.txt,environment.yml)Versionner le code (Git) et documenter les modifications
Séparer les données du code et documenter leur provenance
Automatiser le pipeline (scripts, Makefiles, pipelines CI/CD)
Documenter les hyperparamètres et les résultats de chaque expérience
# Exemple : fixer toutes les graines pour une reproductibilité maximale
import random
SEED = 42
# Python
random.seed(SEED)
# NumPy
np.random.seed(SEED)
rng = np.random.default_rng(SEED)
# Scikit-learn utilise le paramètre random_state
# ex : train_test_split(..., random_state=SEED)
# ex : RandomForestClassifier(random_state=SEED)
print(f"Graine globale fixée a {SEED}")
print(f"random.random() = {random.random():.6f}")
print(f"np.random.randn(1) = {np.random.randn(1)[0]:.6f}")
print(f"rng.standard_normal()= {rng.standard_normal():.6f}")
Graine globale fixée a 42
random.random() = 0.639427
np.random.randn(1) = 0.496714
rng.standard_normal()= 0.304717
Résumé#
Ce chapitre a presenté les outils fondamentaux de l’ecosystème Python pour l’apprentissage automatique :
Outil |
Role |
Import |
|---|---|---|
NumPy |
Calcul numérique, tableaux multidimensionnels |
|
Pandas |
Manipulation de données tabulaires |
|
Matplotlib |
Visualisation de base |
|
Seaborn |
Visualisation statistique |
|
Scikit-learn |
Apprentissage automatique classique |
|
Jupyter |
Environnement intéractif |
– |
Ces outils seront utilisés tout au long de cet ouvrage. La maitrise de NumPy et Pandas est un prérequis pour manipuler efficacement les données, et la compréhension de l’API Scikit-learn est essentielle pour aborder les chapitres suivants sur les algorithmes d’apprentissage.