
Classification#
Tout l’art de la classification repose sur le tracé d’une frontière au bon endroit.
Vladimir Vapnik
La classification est le problème fondamental de l’apprentissage supervisé dans lequel la variable cible \(y\) est catégorielle (ou discrète). Contrairement à la régression, où l’on prédit une valeur continue, le classifieur attribue chaque observation à une classe parmi un ensemble fini. Ce chapitre développe le modèle de base de la classification — la régression logistique — et introduit les outils d’évaluation indispensables pour juger de la qualité d’un classifieur.
Le problème de classification#
Définition 66 (Problème de classification)
Soit un ensemble d’entraînement \(\mathcal{D} = \{(\mathbf{x}_i, y_i)\}_{i=1}^n\) où \(\mathbf{x}_i \in \mathbb{R}^p\) est un vecteur de features et \(y_i \in \{1, 2, \ldots, K\}\) est l’étiquette de classe. Le problème de classification consiste à trouver une fonction \(f : \mathbb{R}^p \to \{1, \ldots, K\}\) qui minimise une mesure d’erreur sur des données non vues.
On distingue deux cas fondamentaux :
Classification binaire (\(K = 2\)) : on cherche à séparer deux classes, souvent notées \(y \in \{0, 1\}\) (négatif / positif). Exemples : spam / non-spam, tumeur maligne / bénigne, fraude / légitime.
Classification multiclasse (\(K \geq 3\)) : on attribue l’observation à l’une de \(K\) classes. Exemples : reconnaissance de chiffres manuscrits (\(K = 10\)), classification d’espèces (\(K = 3\) pour Iris), diagnostic médical parmi plusieurs pathologies.
Remarque 60
La classification multilabel (une observation peut appartenir à plusieurs classes simultanément) est un problème distinct que nous n’abordons pas ici. De même, la classification ordinale (les classes sont ordonnées, comme « faible / moyen / élevé ») nécessite des traitements spécifiques.
Pourquoi la régression linéaire ne convient pas#
On pourrait être tenté de traiter la classification binaire comme une régression en codant \(y \in \{0, 1\}\) et en ajustant un modèle linéaire \(\hat{y} = \mathbf{x}^\top \boldsymbol{\beta}\). Ce choix pose plusieurs problèmes :
Les prédictions ne sont pas bornées : \(\hat{y}\) peut prendre des valeurs négatives ou supérieures à 1, ce qui n’a pas de sens comme probabilité.
La frontière de décision est linéaire mais la fonction de coût (MSE) n’est pas adaptée à une cible binaire.
Les résidus ne sont pas normaux : la distribution de \(y \mid \mathbf{x}\) est une Bernoulli, pas une gaussienne.
Il faut donc un modèle qui produit des probabilités \(\hat{p} = P(y = 1 \mid \mathbf{x}) \in [0, 1]\), puis assigne la classe par seuillage. C’est exactement le rôle de la régression logistique.
Régression logistique#
La fonction sigmoïde#
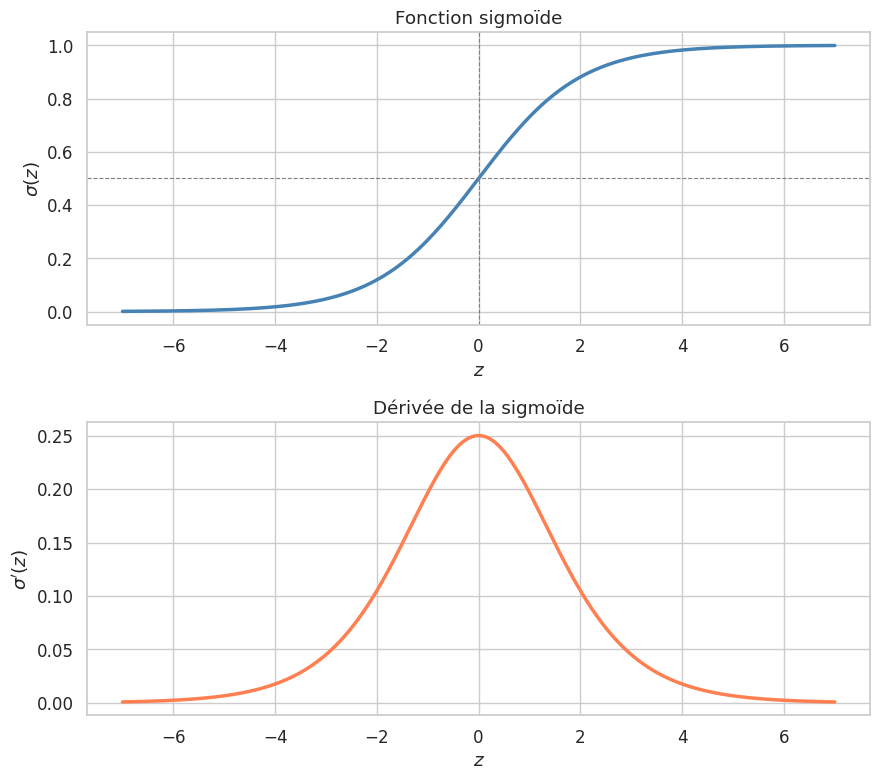
Définition 67 (Fonction sigmoïde (logistique))
La fonction sigmoïde (ou logistique) est définie par
Elle transforme tout réel \(z \in \mathbb{R}\) en une valeur dans l’intervalle \(]0, 1[\).
Proposition 13 (Propriétés de la sigmoïde)
La fonction sigmoïde possède les propriétés suivantes :
\(\sigma(0) = 1/2\)
\(\lim_{z \to +\infty} \sigma(z) = 1\) et \(\lim_{z \to -\infty} \sigma(z) = 0\)
\(\sigma(-z) = 1 - \sigma(z)\) (symétrie)
\(\sigma'(z) = \sigma(z)(1 - \sigma(z))\) (dérivée)
La fonction inverse est le logit : \(\sigma^{-1}(p) = \ln\!\left(\frac{p}{1-p}\right)\)
Proof. Pour la propriété 4, on pose \(\sigma(z) = (1 + e^{-z})^{-1}\) et on dérive :
Pour la propriété 3 :
Modèle de régression logistique#
Définition 68 (Régression logistique)
Le modèle de régression logistique pour la classification binaire modélise la probabilité de la classe positive comme
où \(\boldsymbol{\beta} \in \mathbb{R}^p\) est le vecteur de poids et \(\beta_0 \in \mathbb{R}\) le biais (intercept).
La prédiction est obtenue par seuillage :
Remarque 61
Malgré son nom, la régression logistique est bien un classifieur, pas un régresseur. Le terme « régression » est historique et fait référence à la modélisation d’une probabilité continue \(P(y = 1 \mid \mathbf{x})\).
Interprétation probabiliste#
La régression logistique peut être interprétée comme un modèle linéaire généralisé (GLM) avec un lien logit. En notant \(p = P(y = 1 \mid \mathbf{x})\), le modèle suppose que le log-odds (logarithme du rapport de cotes) est une fonction linéaire des features :
Définition 69 (Rapport de cotes (odds ratio))
Le rapport de cotes (odds) est le ratio de la probabilité de la classe positive à celle de la classe négative :
Pour une feature \(x_j\), une augmentation d’une unité multiplie les odds par \(e^{\beta_j}\). Si \(\beta_j > 0\), la probabilité de la classe positive augmente ; si \(\beta_j < 0\), elle diminue.
Exemple 6
Considérons un modèle de prédiction de spam avec une feature \(x_1\) = « nombre d’occurrences du mot gratuit ». Si \(\beta_1 = 0.8\), alors chaque occurrence supplémentaire multiplie les odds de spam par \(e^{0.8} \approx 2.23\) : le message devient 2.23 fois plus susceptible d’être un spam (en termes de cotes).
Frontière de décision#
Définition 70 (Frontière de décision)
La frontière de décision (decision boundary) de la régression logistique est l’ensemble des points \(\mathbf{x}\) pour lesquels
C’est un hyperplan dans \(\mathbb{R}^p\). En dimension 2, c’est une droite.
Remarque 62
La frontière de décision de la régression logistique est toujours linéaire. Pour obtenir des frontières non linéaires, on peut ajouter des features polynomiales (comme en régression polynomiale) ou utiliser d’autres modèles (SVM à noyau, arbres de décision, réseaux de neurones).
Fonction de coût : log-loss (entropie croisée binaire)#
Les paramètres \((\boldsymbol{\beta}, \beta_0)\) sont estimés par maximum de vraisemblance. Chaque observation suit une loi de Bernoulli :
où \(p_i = \sigma(\mathbf{x}_i^\top \boldsymbol{\beta} + \beta_0)\). La log-vraisemblance est
Maximiser la log-vraisemblance équivaut à minimiser la log-loss (ou entropie croisée binaire).
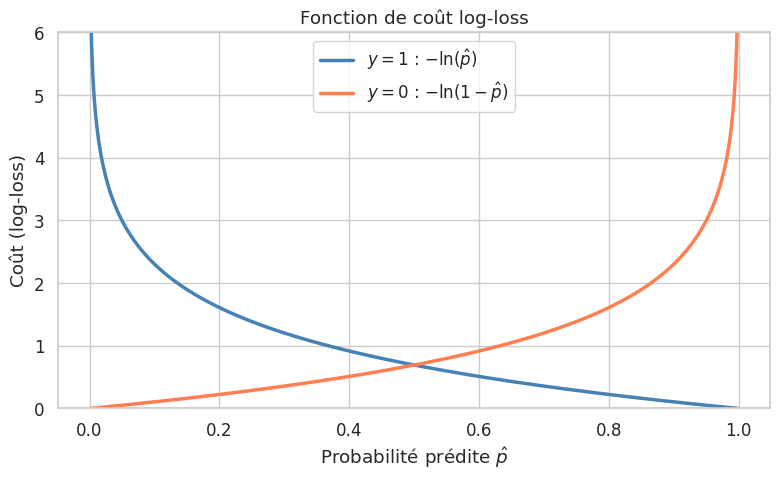
Définition 71 (Log-loss (entropie croisée binaire))
La log-loss (binary cross-entropy) est la fonction de coût de la régression logistique :
où \(\hat{p}_i = \sigma(\mathbf{x}_i^\top \boldsymbol{\beta} + \beta_0)\).
Remarque 63
La log-loss pénalise fortement les prédictions confiantes mais erronées : si \(y_i = 1\) et \(\hat{p}_i \approx 0\), le terme \(-\ln(\hat{p}_i) \to +\infty\). Cela force le modèle à produire des probabilités calibrées.
Optimisation#
La log-loss est une fonction convexe par rapport à \((\boldsymbol{\beta}, \beta_0)\), ce qui garantit l’existence d’un minimum global. Il n’existe pas de solution analytique, mais les algorithmes d’optimisation itératifs convergent de manière fiable :
Descente de gradient : \(\boldsymbol{\beta} \leftarrow \boldsymbol{\beta} - \eta \nabla_{\boldsymbol{\beta}} \mathcal{L}\)
Newton-Raphson (IRLS) : convergence quadratique, utilisé par défaut dans Scikit-learn (
solver='lbfgs')Descente de gradient stochastique (SGD) : pour les très grands jeux de données
Proposition 14 (Gradient de la log-loss)
Le gradient de la log-loss par rapport à \(\boldsymbol{\beta}\) est
Ce gradient a la même forme que celui de la régression linéaire avec le MSE, ce qui n’est pas une coïncidence mais une propriété des GLM avec lien canonique.
Régularisation#
En pratique, on ajoute une pénalité de régularisation pour éviter le surapprentissage. Scikit-learn utilise par défaut une régularisation L2 :
Le paramètre \(C > 0\) contrôle la force de la régularisation : plus \(C\) est petit, plus la régularisation est forte.
Remarque 64
Attention à la convention de Scikit-learn : le paramètre C est l”inverse de la force de régularisation \(\lambda\), soit \(C = 1/\lambda\). Cela signifie que C=0.01 correspond à une régularisation forte et C=100 à une régularisation faible.
Extension multiclasse#
Approche One-vs-Rest (OvR)#
Définition 72 (One-vs-Rest (OvR))
La stratégie One-vs-Rest (ou One-vs-All) décompose un problème à \(K\) classes en \(K\) problèmes binaires. Pour chaque classe \(k \in \{1, \ldots, K\}\) :
On entraîne un classifieur binaire \(f_k\) qui distingue la classe \(k\) (positive) de toutes les autres (négatives).
Chaque classifieur produit un score \(s_k(\mathbf{x}) = \mathbf{x}^\top \boldsymbol{\beta}_k + \beta_{0,k}\).
La classe prédite est celle avec le score le plus élevé :
Remarque 65
L’approche OvR est simple et parallélisable, mais les classifieurs binaires sont entraînés sur des jeux déséquilibrés (une classe contre toutes les autres). De plus, les scores \(s_k(\mathbf{x})\) ne sont pas directement comparables car ils proviennent de modèles distincts.
Fonction softmax et régression logistique multinomiale#
Définition 73 (Fonction softmax)
La fonction softmax généralise la sigmoïde au cas multiclasse. Pour un vecteur de scores \(\mathbf{z} = (z_1, \ldots, z_K) \in \mathbb{R}^K\) :
Elle produit un vecteur de probabilités : \(\text{softmax}(\mathbf{z})_k \geq 0\) et \(\sum_{k=1}^K \text{softmax}(\mathbf{z})_k = 1\).
Définition 74 (Régression logistique multinomiale)
La régression logistique multinomiale modélise directement les probabilités des \(K\) classes :
La fonction de coût est l”entropie croisée catégorielle :
Remarque 66
Dans Scikit-learn, LogisticRegression utilise par défaut l’approche softmax (multinomiale) pour les solveurs qui la supportent (lbfgs, newton-cg, sag, saga). Le paramètre multi_class ayant été retiré dans les versions récentes, le choix est désormais automatique.
Scores bruts :
[[2. 1. 0.1]
[0.5 2.5 0.3]
[0.2 0.1 3. ]]
Probabilités après softmax :
[[0.659 0.2424 0.0986]
[0.1086 0.8025 0.0889]
[0.0545 0.0493 0.8962]]
Somme par ligne : [1. 1. 1.]
Classes prédites : [0 1 2]
Frontières de décision#
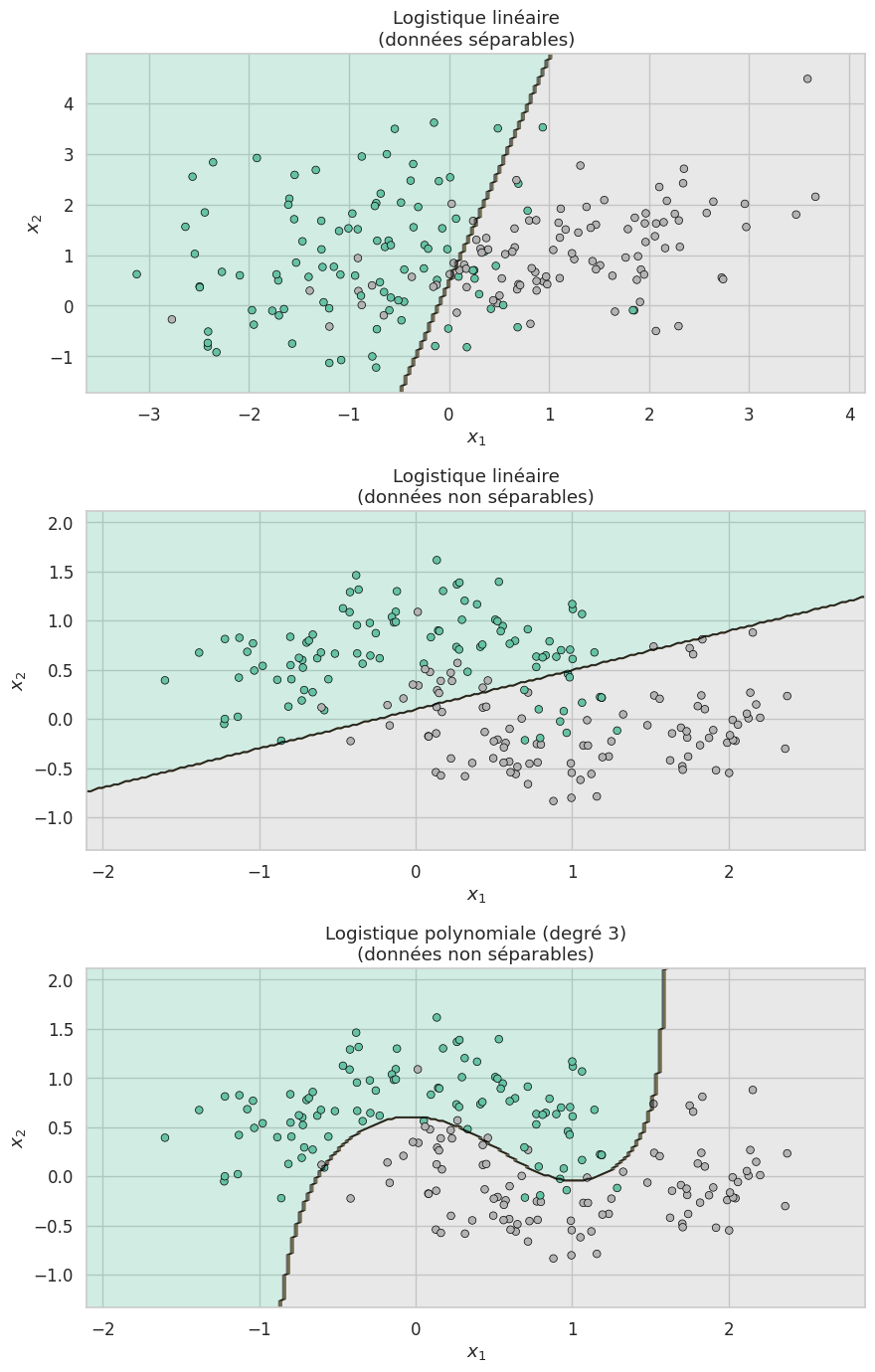
La visualisation des frontières de décision en 2D est un outil pédagogique essentiel pour comprendre le comportement d’un classifieur. On fixe deux features et on colore chaque point de l’espace selon la classe prédite.
Remarque 67
L’ajout de features polynomiales permet à la régression logistique de capturer des frontières non linéaires. C’est un compromis entre la simplicité du modèle linéaire et la flexibilité des modèles plus complexes. Le degré du polynôme et le paramètre de régularisation \(C\) contrôlent conjointement la complexité de la frontière.
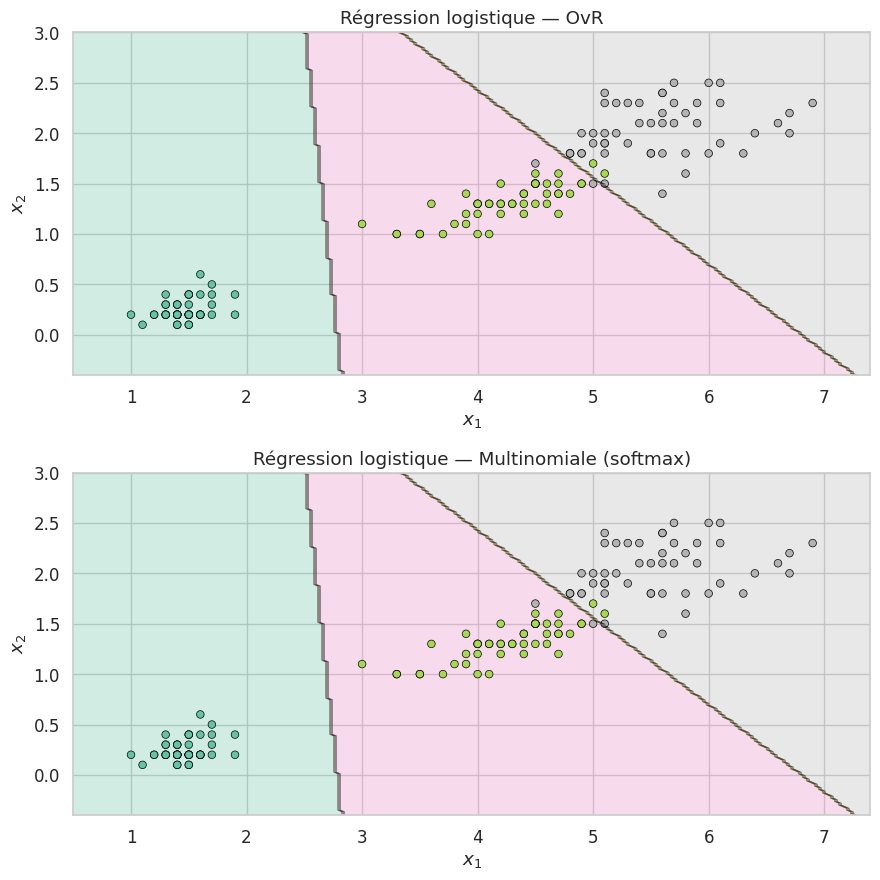
Frontières multiclasses#
Remarque 68
Sur le jeu Iris (features petal length et petal width), les approches OvR et multinomiale produisent des frontières similaires car les classes sont relativement bien séparées. Les différences apparaissent surtout lorsque les classes se chevauchent fortement ou lorsque les problèmes binaires OvR sont très déséquilibrés.
Métriques de classification#
L’évaluation d’un classifieur ne se réduit pas à un seul chiffre. Selon le contexte (diagnostic médical, détection de fraude, filtrage de spam), les erreurs n’ont pas le même coût. Cette section présente les métriques essentielles.
Matrice de confusion#
Définition 75 (Matrice de confusion)
Pour un problème binaire, la matrice de confusion est un tableau \(2 \times 2\) qui croise les classes réelles et les classes prédites :
Prédit positif |
Prédit négatif |
|
|---|---|---|
Réel positif |
VP (Vrai Positif) |
FN (Faux Négatif) |
Réel négatif |
FP (Faux Positif) |
VN (Vrai Négatif) |
VP (True Positive) : positif correctement identifié
VN (True Negative) : négatif correctement identifié
FP (False Positive, erreur de type I) : négatif classé à tort comme positif
FN (False Negative, erreur de type II) : positif classé à tort comme négatif
Exemple 7
Dans un test de dépistage médical :
VP : patient malade correctement diagnostiqué
FN : patient malade non détecté (le plus dangereux)
FP : patient sain faussement diagnostiqué (anxiété inutile, examens supplémentaires)
VN : patient sain correctement identifié
Dans ce contexte, on cherche à minimiser les FN (haute sensibilité), quitte à accepter davantage de FP.
Accuracy, précision, rappel, F1-score#
Définition 76 (Accuracy)
L”accuracy (exactitude) est la proportion de prédictions correctes :
Remarque 69
L’accuracy est trompeuse en présence de déséquilibre de classes. Si 95 % des observations sont négatives, un modèle qui prédit toujours « négatif » obtient une accuracy de 95 %, alors qu’il ne détecte aucun positif.
Définition 77 (Précision et rappel)
La précision (precision) est la proportion de vrais positifs parmi les prédictions positives :
Le rappel (recall, ou sensibilité, ou taux de vrais positifs) est la proportion de positifs correctement détectés :
Définition 78 (F1-score)
Le F1-score est la moyenne harmonique de la précision et du rappel :
Plus généralement, le \(F_\beta\)-score pondère le rappel \(\beta^2\) fois plus que la précision :
Remarque 70
Le choix entre précision et rappel dépend du coût des erreurs :
Haute précision souhaitée : quand un faux positif est coûteux (par exemple, un système judiciaire : condamner un innocent est grave).
Haut rappel souhaité : quand un faux négatif est coûteux (par exemple, dépistage d’une maladie grave : manquer un patient malade est dangereux).
Le F1-score est un compromis ; le \(F_2\)-score favorise le rappel, le \(F_{0.5}\)-score favorise la précision.
Courbe ROC et AUC#
Définition 79 (Courbe ROC)
La courbe ROC (Receiver Operating Characteristic) représente le taux de vrais positifs (rappel) en fonction du taux de faux positifs pour différents seuils de décision \(\tau\) :
En faisant varier \(\tau\) de 0 à 1, on obtient une courbe dans le carré \([0,1]^2\).
Définition 80 (AUC (Area Under the Curve))
L”AUC est l’aire sous la courbe ROC :
\(\text{AUC} = 1\) : classifieur parfait
\(\text{AUC} = 0.5\) : classifieur aléatoire (diagonale)
\(\text{AUC} < 0.5\) : classifieur pire que le hasard (inverser les prédictions)
Proposition 15 (Interprétation probabiliste de l’AUC)
L’AUC est égale à la probabilité qu’un exemple positif tiré au hasard reçoive un score plus élevé qu’un exemple négatif tiré au hasard :
où \(\mathbf{x}^+\) est de classe positive et \(\mathbf{x}^-\) de classe négative.
Courbe précision-rappel#
Définition 81 (Courbe précision-rappel)
La courbe précision-rappel (precision-recall curve) représente la précision en fonction du rappel pour différents seuils de décision. Elle est particulièrement informative lorsque les classes sont déséquilibrées, car elle ne prend pas en compte les vrais négatifs (contrairement à la courbe ROC).
L”AP (Average Precision) est l’aire sous la courbe précision-rappel.
Remarque 71
Pour un jeu de données très déséquilibré (par exemple 1 % de positifs), la courbe ROC peut sembler optimiste car l’abscisse (TFP) est diluée par le grand nombre de vrais négatifs. La courbe précision-rappel est alors plus discriminante : un classifieur aléatoire y apparaît comme une ligne horizontale à \(\text{Precision} = \text{prévalence}\) (1 %), et non comme une diagonale à 50 %.
Exemple complet avec Scikit-learn#
Mettons en pratique l’ensemble de ces concepts sur le jeu de données Breast Cancer Wisconsin, un problème de classification binaire classique (tumeur maligne ou bénigne).
Dimensions : (569, 30)
Classes : ['malignant' 'benign'] (0 = malignant, 1 = benign)
Répartition : {np.int64(0): np.int64(212), np.int64(1): np.int64(357)}
Accuracy entraînement : 0.9890
Accuracy test : 0.9825
Matrice de confusion#
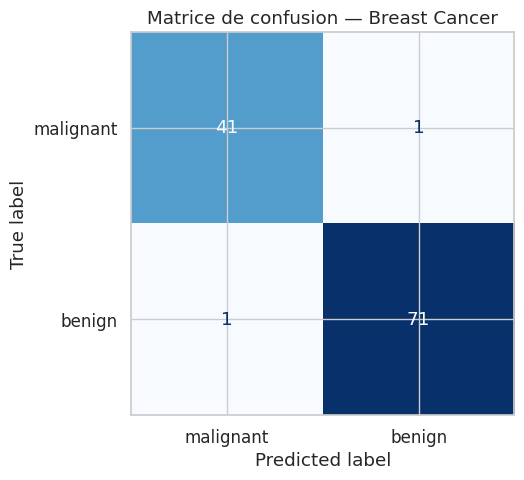
VP = 71, VN = 41, FP = 1, FN = 1
Rapport de classification#
precision recall f1-score support
malignant 0.98 0.98 0.98 42
benign 0.99 0.99 0.99 72
accuracy 0.98 114
macro avg 0.98 0.98 0.98 114
weighted avg 0.98 0.98 0.98 114
Courbe ROC et AUC#
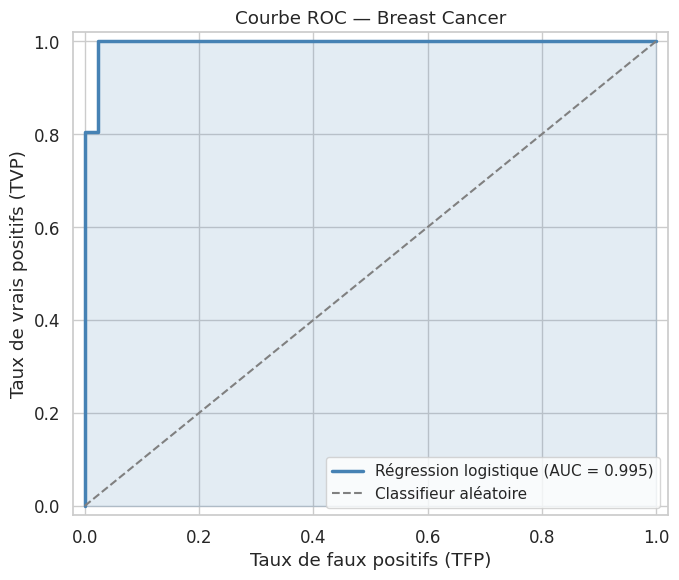
Courbe précision-rappel#
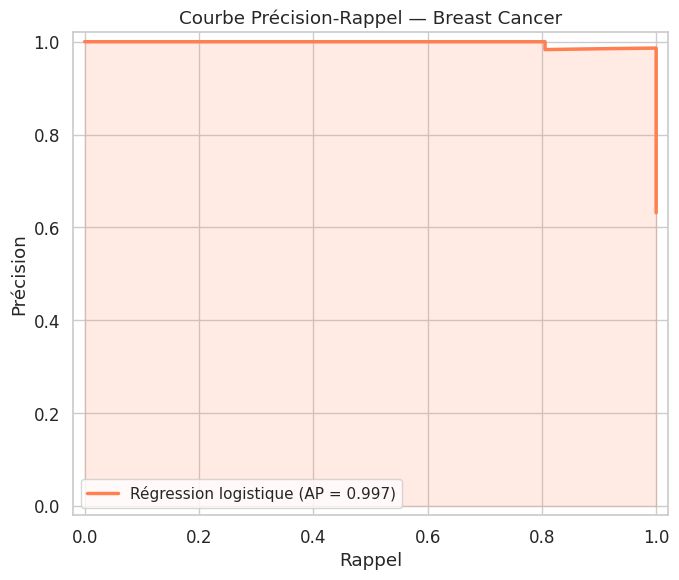
Influence du seuil de décision#
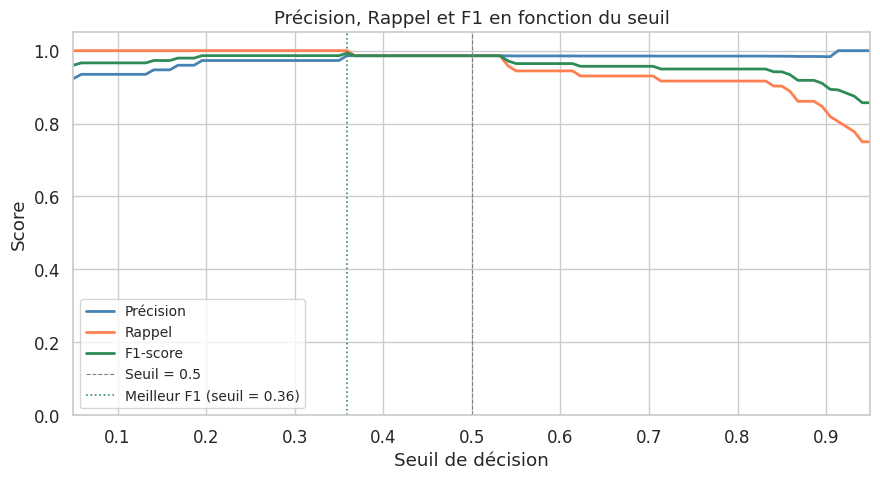
Remarque 72
Le seuil par défaut de \(0.5\) n’est pas toujours optimal. En ajustant le seuil, on peut déplacer le compromis précision-rappel selon les besoins du problème. Le graphique ci-dessus montre clairement cette relation inverse : augmenter le seuil améliore la précision mais réduit le rappel, et inversement.
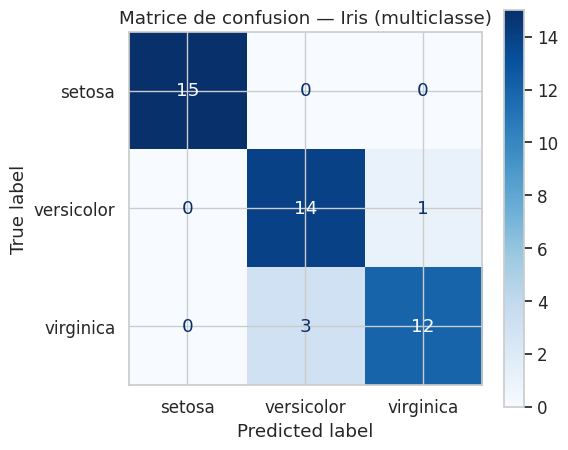
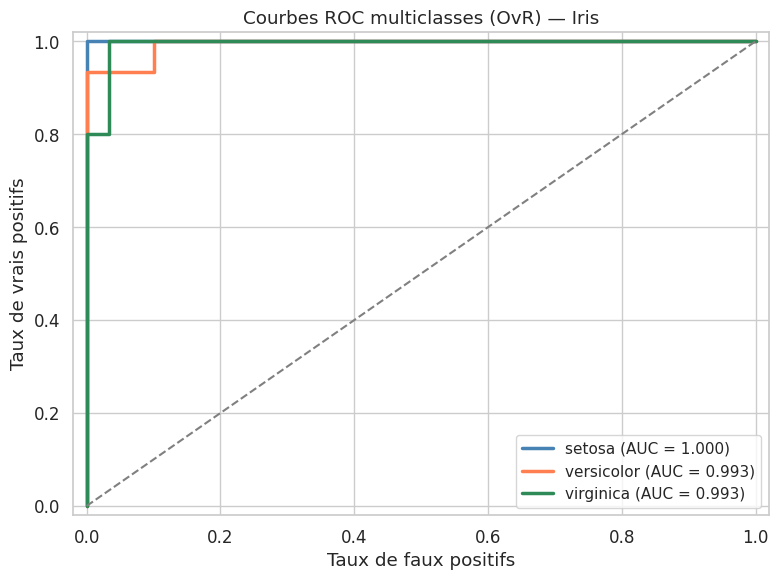
Exemple multiclasse : Iris#
Accuracy test : 0.9111
precision recall f1-score support
setosa 1.00 1.00 1.00 15
versicolor 0.82 0.93 0.88 15
virginica 0.92 0.80 0.86 15
accuracy 0.91 45
macro avg 0.92 0.91 0.91 45
weighted avg 0.92 0.91 0.91 45
Courbes ROC multiclasses (One-vs-Rest)#
Résumé#
La régression logistique est le point d’entrée de la classification en apprentissage automatique. Ses atouts sont nombreux : interprétabilité (les coefficients ont une signification en termes d’odds ratio), efficacité computationnelle, et capacité à produire des probabilités calibrées. Ses limites — la linéarité de la frontière de décision — peuvent être partiellement contournées par l’ajout de features polynomiales.
Concept |
Résumé |
|---|---|
Sigmoïde |
\(\sigma(z) = 1/(1 + e^{-z})\), transforme \(\mathbb{R} \to ]0, 1[\) |
Modèle logistique |
\(P(y=1 \mid \mathbf{x}) = \sigma(\mathbf{x}^\top \boldsymbol{\beta} + \beta_0)\) |
Frontière de décision |
Hyperplan \(\mathbf{x}^\top \boldsymbol{\beta} + \beta_0 = 0\) |
Log-loss |
\(-\frac{1}{n}\sum [y_i \ln \hat{p}_i + (1-y_i)\ln(1-\hat{p}_i)]\) |
Softmax |
Généralisation multiclasse de la sigmoïde |
Accuracy |
Proportion de prédictions correctes |
Précision |
VP / (VP + FP) |
Rappel |
VP / (VP + FN) |
F1-score |
Moyenne harmonique de précision et rappel |
AUC |
Aire sous la courbe ROC, mesure globale de discrimination |
Remarque 73
La régression logistique est rarement le modèle le plus performant, mais c’est presque toujours un excellent modèle de référence (baseline). Avant de recourir à des méthodes plus complexes (SVM, forêts aléatoires, réseaux de neurones), il est indispensable de vérifier qu’elles surpassent significativement ce modèle simple. Les chapitres suivants présenteront des alternatives plus flexibles, mais les métriques et les outils d’évaluation introduits ici resteront valables pour tous les classifieurs.