
Interprétabilité des modèles#
La science est ce que nous comprenons suffisamment bien pour l’expliquer à un ordinateur. L’art est tout le reste.
— Donald Knuth, Things a Computer Scientist Rarely Talks About
Les chapitres précédents ont présenté des modèles de complexité croissante : de la régression linéaire (chapitre 5) aux réseaux de neurones profonds (chapitres 16–20), en passant par les méthodes d’ensemble (chapitre 9) et les machines à vecteurs de support (chapitre 10). Cette montée en complexité s’accompagne d’un gain en performance prédictive, mais aussi d’une perte progressive de transparence : comprendre pourquoi un modèle produit une prédiction donnée devient de plus en plus difficile. Ce chapitre traite de l”interprétabilité des modèles d’apprentissage automatique — la capacité à comprendre, expliquer et justifier les décisions d’un modèle — et présente les outils théoriques et pratiques permettant d’ouvrir la boîte noire.
Introduction : le problème de la boîte noire#
Pourquoi l’interprétabilité est essentielle#
Un modèle d’apprentissage automatique qui produit des prédictions précises mais inexplicables pose plusieurs problèmes fondamentaux :
Confiance : un médecin n’acceptera pas un diagnostic automatisé sans comprendre le raisonnement sous-jacent. Un ingénieur ne déploiera pas un modèle en production s’il ne peut pas anticiper ses modes de défaillance.
Débogage : lorsqu’un modèle se trompe, il faut pouvoir identifier la source de l’erreur — une feature mal construite, un biais dans les données, un artefact du prétraitement — pour corriger le problème.
Exigences réglementaires : le Règlement Général sur la Protection des Données (RGPD) européen consacre un « droit à l’explication » pour les décisions automatisées. L’AI Act de l’Union Européenne impose des obligations de transparence pour les systèmes d’IA à haut risque.
Compréhension scientifique : en sciences, un modèle n’est pas une fin en soi mais un outil pour comprendre les phénomènes. Un modèle prédictif mais opaque ne fait pas progresser la connaissance.
Équité : détecter et corriger les biais discriminatoires (genre, origine, âge) dans un modèle nécessite de comprendre comment ces variables influencent les prédictions.
Remarque 253
Le terme « boîte noire » (black box) désigne un modèle dont le fonctionnement interne est opaque pour l’utilisateur. Les réseaux de neurones profonds, les forêts aléatoires avec des centaines d’arbres et les méthodes de gradient boosting sont des exemples typiques de boîtes noires. À l’opposé, un modèle linéaire ou un petit arbre de décision est une « boîte blanche » (white box) dont chaque composante est directement interprétable.
Interprétabilité et explicabilité#
Les termes interprétabilité et explicabilité sont souvent utilisés de manière interchangeable, mais une distinction utile peut être faite.
Définition 304 (Interprétabilité et explicabilité)
L”interprétabilité (interpretability) est la propriété intrinsèque d’un modèle permettant à un humain de comprendre son mécanisme de décision. Un modèle est interprétable si sa structure est suffisamment simple pour être appréhendée directement.
L”explicabilité (explainability) désigne la capacité à fournir des explications a posteriori du comportement d’un modèle, éventuellement complexe, à l’aide de techniques externes. Un modèle explicable n’est pas nécessairement interprétable : on peut expliquer les prédictions d’un réseau de neurones sans pour autant comprendre l’ensemble de ses paramètres.
On distingue également deux niveaux d’explication :
Explication globale : comprendre le comportement général du modèle sur l’ensemble des données (quelles features sont globalement importantes ? quelles relations le modèle a-t-il capturées ?).
Explication locale : comprendre pourquoi le modèle a produit une prédiction particulière pour une observation donnée.
Modèles intrinsèquement interprétables#
Avant de recourir à des techniques d’explication post hoc, il convient de rappeler que certains modèles sont intrinsèquement interprétables : leur structure même permet de comprendre le processus de décision.
Modèles linéaires : lecture des coefficients#
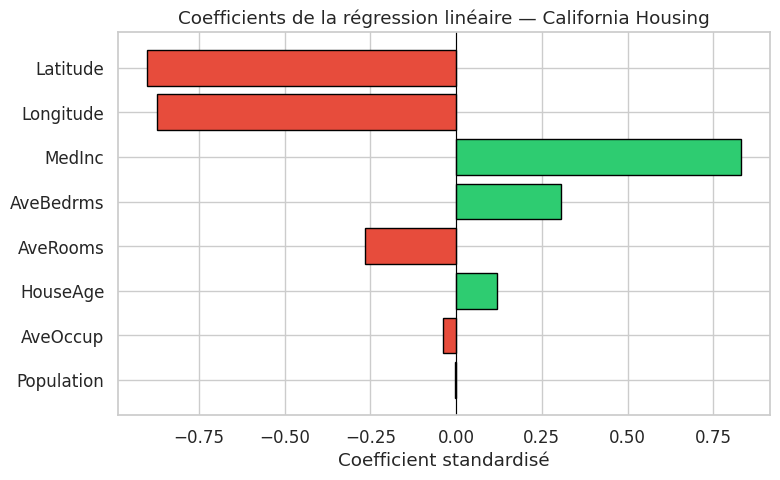
Le modèle linéaire (chapitre 5) est l’archétype du modèle interprétable. Dans un modèle de régression linéaire \(\hat{y} = \beta_0 + \beta_1 x_1 + \cdots + \beta_p x_p\), chaque coefficient \(\beta_j\) a une interprétation directe : c’est la variation de la prédiction \(\hat{y}\) associée à une augmentation d’une unité de \(x_j\), toutes choses égales par ailleurs.
Exemple 41 (Interprétation des coefficients d’une régression linéaire)
Considérons un modèle linéaire pour prédire le prix médian des logements en Californie. Si le coefficient associé à la variable MedInc (revenu médian) est \(\hat{\beta} = 0.85\), cela signifie qu’une augmentation d’une unité du revenu médian (en dizaines de milliers de dollars) est associée à une augmentation de \(0.85 \times 100\,000 = 85\,000\) dollars du prix médian, les autres variables étant fixées.
R² sur l'ensemble d'entraînement : 0.606
Remarque 254
Pour que les coefficients soient comparables entre eux, il est indispensable de standardiser les variables avant l’ajustement (chapitre 4). Sans standardisation, un coefficient élevé peut simplement refléter une échelle de mesure différente plutôt qu’une influence réelle plus forte. Après standardisation, la valeur absolue du coefficient mesure l’importance relative de chaque variable.
Arbres de décision : extraction de règles#
Les arbres de décision (chapitre 8) sont le second modèle intrinsèquement interprétable. Chaque chemin de la racine à une feuille se lit comme une suite de conditions logiques, directement traduisible en règle humainement compréhensible.
Règles de l'arbre de décision :
|--- petal length (cm) <= 2.45
| |--- class: 0
|--- petal length (cm) > 2.45
| |--- petal width (cm) <= 1.75
| | |--- petal length (cm) <= 4.95
| | | |--- class: 1
| | |--- petal length (cm) > 4.95
| | | |--- class: 2
| |--- petal width (cm) > 1.75
| | |--- petal length (cm) <= 4.85
| | | |--- class: 2
| | |--- petal length (cm) > 4.85
| | | |--- class: 2
Remarque 255
Un arbre de décision de profondeur 3 contient au plus \(2^3 = 8\) feuilles et peut être visualisé et compris par un non-spécialiste. Cependant, un arbre de profondeur 20 avec des milliers de feuilles devient aussi opaque qu’un réseau de neurones. L’interprétabilité d’un arbre dépend donc de sa taille. En pratique, on limite la profondeur (paramètre max_depth) pour préserver la lisibilité, au prix d’une perte potentielle de performance.
Modèles additifs généralisés (GAM)#
Les modèles additifs généralisés (Generalized Additive Models, GAM) étendent les modèles linéaires en remplaçant les termes linéaires par des fonctions non linéaires univariées :
Définition 305 (Modèle additif généralisé)
Un GAM modélise la variable cible comme une somme de fonctions lisses univariées des features :
où \(g\) est une fonction de lien, et chaque \(f_j\) est une fonction lisse (typiquement un spline) estimée à partir des données. L’interprétation est directe : chaque \(f_j\) représente la contribution marginale de la variable \(x_j\) à la prédiction, indépendamment des autres variables.
Les GAM conservent l’interprétabilité des modèles linéaires — chaque variable contribue de manière additive et sa contribution peut être visualisée — tout en capturant des relations non linéaires. Leur principale limitation est l’absence d’interactions entre variables, sauf si celles-ci sont explicitement ajoutées.
Le compromis interprétabilité–performance#
Remarque 256
Il existe un compromis fondamental entre l’interprétabilité et la performance prédictive d’un modèle. Les modèles les plus interprétables (régression linéaire, petits arbres, GAM) sont généralement moins performants que les modèles complexes (forêts aléatoires, gradient boosting, réseaux profonds) sur des problèmes difficiles. Cependant, ce compromis n’est pas absolu : sur des données tabulaires de dimension modérée, un modèle linéaire bien régularisé ou un GAM peut rivaliser avec un gradient boosting, tout en offrant une transparence totale.
Importance des features#
L”importance des features (feature importance) est la forme la plus courante d’explication globale : elle attribue un score numérique à chaque variable, reflétant sa contribution à la performance du modèle. Deux grandes familles de méthodes coexistent.
Importance par permutation#
L’importance par permutation (permutation importance) est une méthode agnostique au modèle (model-agnostic) : elle s’applique à tout modèle supervisé.
Définition 306 (Importance par permutation)
L”importance par permutation de la variable \(x_j\) est définie comme la diminution de performance du modèle lorsque les valeurs de \(x_j\) sont aléatoirement permutées dans l’ensemble de test, brisant ainsi la relation entre \(x_j\) et la cible \(y\) :
où \(s\) est le score du modèle sur les données originales, et \(s_j^{(k)}\) est le score après la \(k\)-ième permutation aléatoire de \(x_j\).
L’idée est intuitive : si la permutation d’une variable dégrade fortement les prédictions, c’est que le modèle utilise cette variable ; si la performance reste inchangée, la variable est superflue.
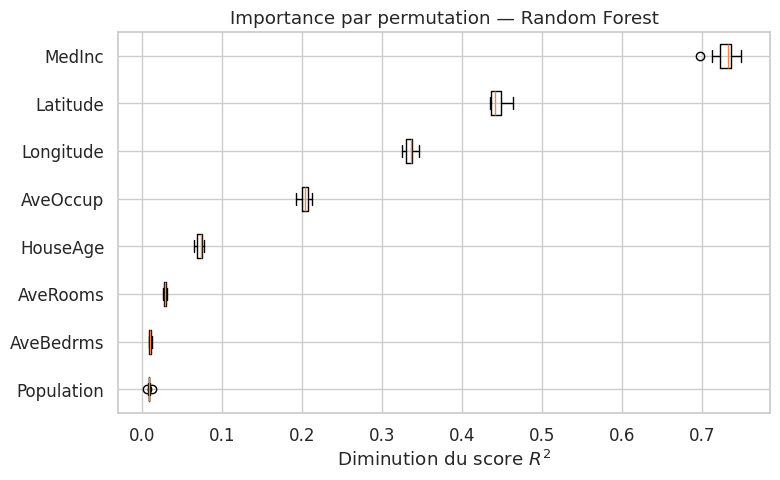
Exemple 42 (Importance par permutation d’une forêt aléatoire)
Entraînons une forêt aléatoire sur le jeu California Housing et calculons l’importance par permutation de chaque variable.
R² (test) : 0.805
Importance basée sur l’impureté#
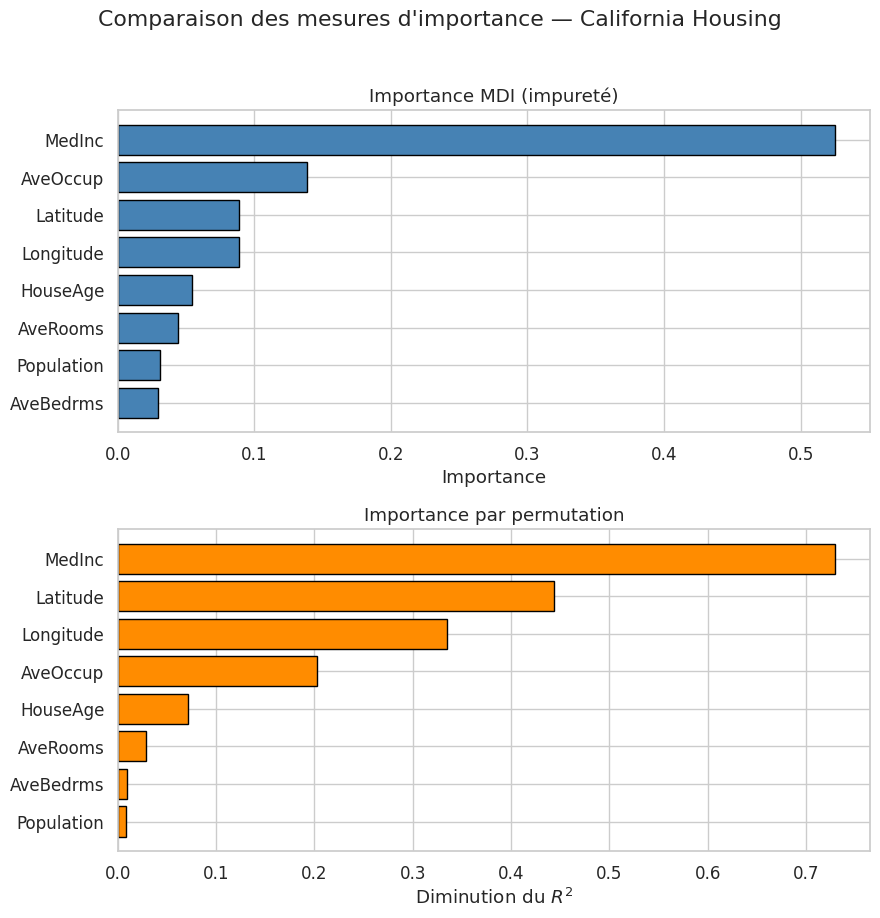
Pour les modèles à base d’arbres, scikit-learn fournit une mesure d’importance intégrée : l’importance basée sur la diminution moyenne d’impureté (Mean Decrease in Impurity, MDI).
Définition 307 (Importance MDI)
L”importance MDI de la variable \(x_j\) dans un ensemble d’arbres est la somme pondérée des diminutions d’impureté (Gini ou entropie en classification, variance en régression) produites par les divisions sur \(x_j\), moyennée sur tous les arbres :
où \(T\) est le nombre d’arbres, \(\mathcal{V}_t\) l’ensemble des noeuds internes de l’arbre \(t\), \(j(v)\) la variable utilisée pour la division au noeud \(v\), \(p(v)\) la proportion d’observations atteignant \(v\), et \(\Delta I(v)\) la diminution d’impureté.
Remarque 257
L’importance MDI présente un biais connu : elle surestime l’importance des variables à forte cardinalité (beaucoup de valeurs distinctes) car celles-ci offrent davantage de seuils de division possibles. L’importance par permutation, calculée sur un jeu de test indépendant, ne souffre pas de ce biais et constitue une mesure plus fiable. En pratique, on privilégie l’importance par permutation pour les conclusions finales, et l’importance MDI comme indicateur rapide lors de l’exploration.
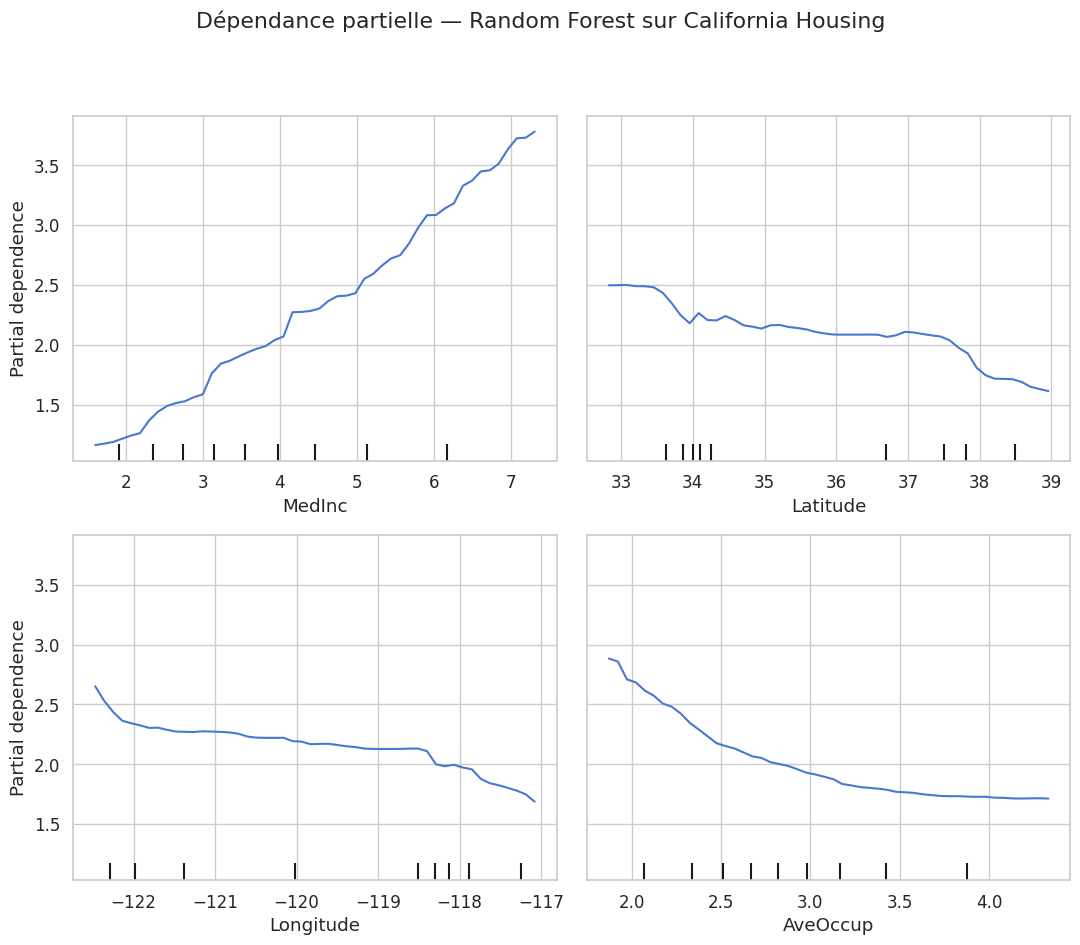
Graphiques de dépendance partielle#
Les graphiques de dépendance partielle (Partial Dependence Plots, PDP) complètent les mesures d’importance en montrant comment la prédiction varie en fonction d’une ou deux variables.
Définition 308 (Dépendance partielle)
La fonction de dépendance partielle de la variable \(x_j\) est définie comme la moyenne de la prédiction du modèle sur toutes les valeurs possibles des autres variables :
où \(\mathbf{x}_{i, \setminus j}\) désigne les valeurs des variables autres que \(x_j\) pour l’observation \(i\).
LIME : explications locales par modèle substitut#
Principe de LIME#
LIME (Local Interpretable Model-agnostic Explanations) est une méthode d’explication locale et agnostique au modèle, introduite par Ribeiro et al. (2016). L’idée fondamentale est la suivante : même si un modèle est globalement complexe, son comportement au voisinage d’un point particulier peut souvent être approximé par un modèle simple — typiquement un modèle linéaire.
Définition 309 (LIME)
Soit \(f\) un modèle complexe et \(\mathbf{x}_0\) une observation à expliquer. LIME cherche un modèle interprétable \(g \in \mathcal{G}\) (par exemple un modèle linéaire) qui approxime localement \(f\) au voisinage de \(\mathbf{x}_0\). Le modèle substitut \(g\) est obtenu par :
où :
\(\mathbf{z}_1, \ldots, \mathbf{z}_N\) sont des perturbations de \(\mathbf{x}_0\) générées aléatoirement au voisinage de \(\mathbf{x}_0\)
\(\pi_{\mathbf{x}_0}(\mathbf{z}_i) = \exp\left(-\frac{\|\mathbf{z}_i - \mathbf{x}_0\|^2}{2\sigma^2}\right)\) est un noyau de proximité qui pondère les perturbations par leur distance à \(\mathbf{x}_0\)
\(\Omega(g)\) est un terme de régularisation qui pénalise la complexité de \(g\) (par exemple le nombre de features non nulles)
Algorithme#
L’algorithme LIME procède en quatre étapes :
Perturbation : générer \(N\) échantillons \(\mathbf{z}_i\) au voisinage de \(\mathbf{x}_0\) en perturbant aléatoirement les valeurs des features.
Prédiction : obtenir les prédictions \(f(\mathbf{z}_i)\) du modèle complexe pour chaque perturbation.
Pondération : calculer les poids \(\pi_{\mathbf{x}_0}(\mathbf{z}_i)\) mesurant la proximité de chaque perturbation à \(\mathbf{x}_0\).
Ajustement : entraîner un modèle linéaire pondéré sur les paires \((\mathbf{z}_i, f(\mathbf{z}_i))\) avec les poids \(\pi_{\mathbf{x}_0}(\mathbf{z}_i)\), en régularisant pour ne conserver que les features les plus influentes.
Les coefficients du modèle linéaire résultant fournissent l’explication locale : un coefficient positif indique que la feature pousse la prédiction vers le haut, un coefficient négatif vers le bas.
Exemple 43 (Application de LIME à une classification)
Illustrons LIME sur le jeu de données Wine avec un gradient boosting classifier. On expliquera la prédiction pour une observation particulière.
Accuracy (test) : 0.944
Observation 0 : classe prédite = 0 (classe class_0)
Probabilités : {np.str_('class_0'): np.float64(1.0), np.str_('class_1'): np.float64(0.0), np.str_('class_2'): np.float64(0.0)}
/home/loc/legacy_workspace/notebooks/.venv/lib/python3.13/site-packages/sklearn/utils/validation.py:2691: UserWarning: X does not have valid feature names, but GradientBoostingClassifier was fitted with feature names
warnings.warn(
/home/loc/legacy_workspace/notebooks/.venv/lib/python3.13/site-packages/sklearn/utils/validation.py:2691: UserWarning: X does not have valid feature names, but GradientBoostingClassifier was fitted with feature names
warnings.warn(
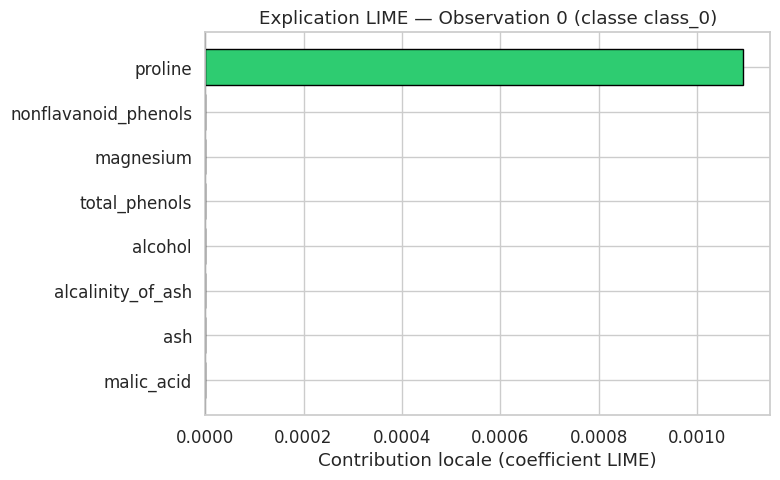
Remarque 258
LIME présente plusieurs limitations importantes :
Instabilité : les explications dépendent de l’échantillonnage aléatoire des perturbations. Deux exécutions peuvent donner des explications légèrement différentes.
Choix du noyau : la largeur de bande \(\sigma\) du noyau de proximité influence fortement la taille du voisinage considéré, et donc l’explication. Il n’existe pas de méthode universelle pour choisir \(\sigma\).
Hypothèse de linéarité locale : si le modèle est fortement non linéaire même localement, l’approximation linéaire peut être trompeuse.
Indépendance des features : les perturbations sont générées en supposant les features indépendantes, ce qui peut créer des combinaisons irréalistes.
Malgré ces limitations, LIME reste un outil populaire pour sa simplicité et son universalité. Pour des explications plus robustes sur le plan théorique, on préfère les valeurs de Shapley présentées dans la section suivante.
SHAP : valeurs de Shapley pour l’apprentissage automatique#
Les valeurs de Shapley en théorie des jeux#
Les valeurs de Shapley sont un concept fondamental de la théorie des jeux coopératifs, introduit par Lloyd Shapley en 1953. Dans un jeu coopératif, un ensemble de joueurs collabore pour produire un gain total. La question est : comment répartir équitablement ce gain entre les joueurs ?
En apprentissage automatique, les « joueurs » sont les features, le « gain » est la prédiction du modèle, et la question devient : quelle est la contribution de chaque feature à la prédiction pour une observation donnée ?
Définition 310 (Valeur de Shapley)
Soit \(N = \{1, \ldots, p\}\) l’ensemble des features et \(v : 2^N \to \mathbb{R}\) une fonction de valeur qui associe à chaque sous-ensemble \(S \subseteq N\) la prédiction du modèle utilisant uniquement les features de \(S\). La valeur de Shapley de la feature \(j\) est :
Cette formule moyenne la contribution marginale de la feature \(j\) sur toutes les coalitions possibles \(S\) ne contenant pas \(j\), pondérées par le nombre de permutations correspondantes.
Les valeurs de Shapley sont l”unique répartition satisfaisant quatre propriétés souhaitables.
Définition 311 (Propriétés des valeurs de Shapley)
Les valeurs de Shapley satisfont les quatre axiomes suivants :
Efficacité (efficiency) : la somme des contributions égale la différence entre la prédiction et la prédiction moyenne :
Symétrie (symmetry) : si deux features contribuent de manière identique dans toutes les coalitions, elles reçoivent la même valeur de Shapley.
Joueur nul (dummy) : une feature qui n’apporte aucune contribution marginale dans aucune coalition reçoit une valeur de Shapley nulle.
Additivité (additivity) : pour un modèle combinant deux fonctions \(f = f_1 + f_2\), les valeurs de Shapley se décomposent : \(\phi_j(f) = \phi_j(f_1) + \phi_j(f_2)\).
Remarque 259
Le calcul exact des valeurs de Shapley nécessite d’évaluer la fonction de valeur pour tous les sous-ensembles possibles de features, soit \(2^p\) évaluations. Pour \(p = 20\) features, cela représente déjà plus d’un million de coalitions. En pratique, on utilise des approximations efficaces : KernelSHAP (échantillonnage pondéré, applicable à tout modèle) et TreeSHAP (algorithme polynomial exact pour les modèles à base d’arbres).
SHAP : Shapley Additive exPlanations#
SHAP (SHapley Additive exPlanations), introduit par Lundberg et Lee (2017), unifie plusieurs méthodes d’explication existantes — dont LIME — dans le cadre théorique des valeurs de Shapley. SHAP propose que chaque explication locale prenne la forme :
où \(\mathbf{z}' \in \{0, 1\}^p\) est un vecteur binaire indiquant quelles features sont « présentes », \(\phi_0 = \mathbb{E}[f(\mathbf{X})]\) est la prédiction de base, et \(\phi_j\) est la valeur de Shapley de la feature \(j\).
TreeSHAP et KernelSHAP#
Deux algorithmes principaux sont proposés :
TreeSHAP : un algorithme en \(O(TLD^2)\) (où \(T\) est le nombre d’arbres, \(L\) le nombre de feuilles et \(D\) la profondeur) qui calcule les valeurs de Shapley exactes pour les modèles à base d’arbres (forêts aléatoires, gradient boosting). C’est l’algorithme de choix pour ces modèles.
KernelSHAP : une approximation basée sur la régression pondérée, applicable à tout modèle. Plus lent que TreeSHAP mais universel.
Exemple 44 (Calcul des valeurs SHAP pour une forêt aléatoire)
Calculons et visualisons les valeurs SHAP pour le modèle de forêt aléatoire entraîné sur California Housing.
/home/loc/legacy_workspace/notebooks/.venv/lib/python3.13/site-packages/sklearn/utils/validation.py:2691: UserWarning: X does not have valid feature names, but RandomForestRegressor was fitted with feature names
warnings.warn(
Prédiction pour l'observation 0 : 0.509
Valeur de base (moyenne) : 2.072
Somme des SHAP values : -1.514
Différence prédiction - base : -1.562
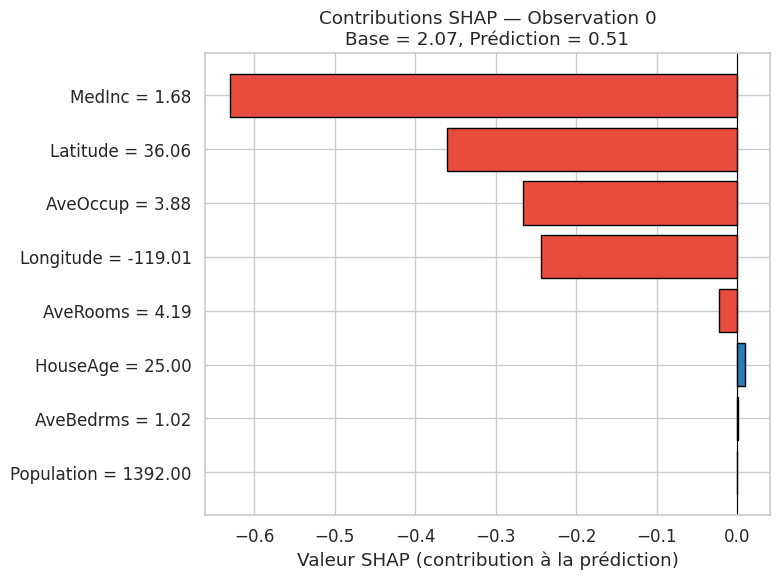
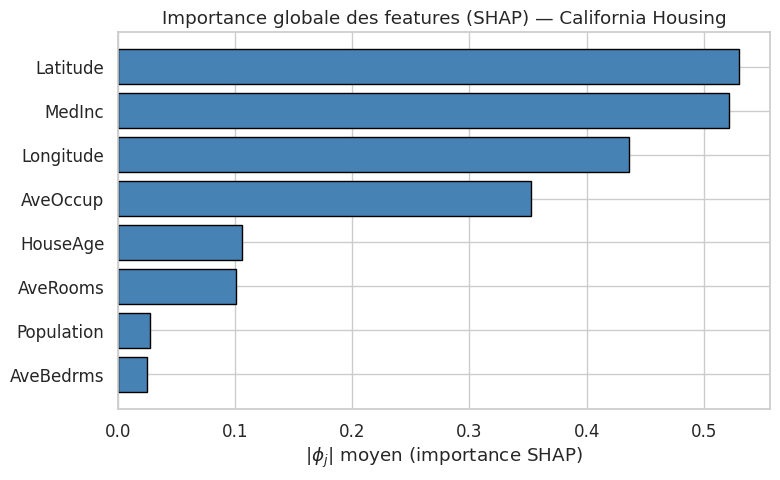
Visualisations SHAP globales#
Au-delà des explications individuelles, les valeurs SHAP permettent des visualisations globales puissantes.
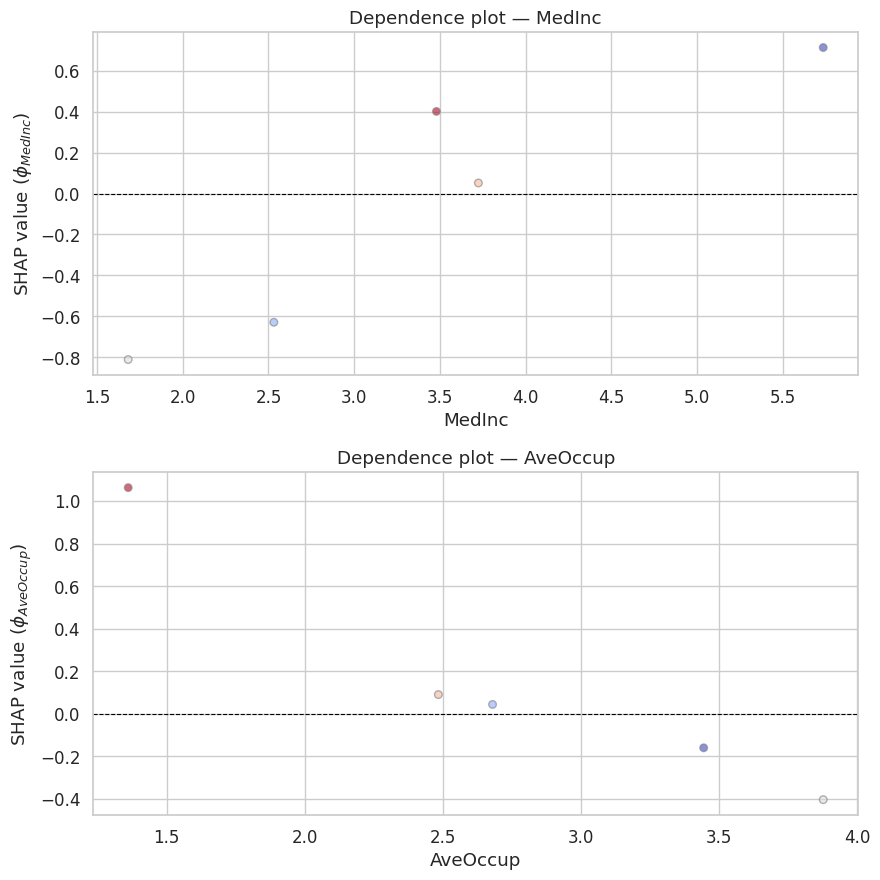
Remarque 260
Le dependence plot est l’un des graphiques les plus informatifs de SHAP. Il montre la valeur de Shapley \(\phi_j\) en fonction de la valeur de la feature \(x_j\), colorée par une variable d’interaction. Pour MedInc (revenu médian), on observe typiquement une relation monotone croissante : plus le revenu est élevé, plus la contribution à la prédiction du prix est positive. La couleur (ici la latitude) révèle les interactions : à revenu égal, la localisation géographique module l’effet sur le prix.
SHAP vs LIME : comparaison#
Critère |
LIME |
SHAP |
|---|---|---|
Fondement théorique |
Heuristique |
Théorie des jeux (Shapley) |
Propriétés garanties |
Aucune |
Efficacité, symétrie, joueur nul, additivité |
Type d’explication |
Locale |
Locale + globale |
Stabilité |
Faible (dépend de l’échantillonnage) |
Forte (valeurs uniques) |
Vitesse (arbres) |
Modérée |
Très rapide (TreeSHAP) |
Vitesse (modèle quelconque) |
Modérée |
Lente (KernelSHAP) |
Remarque 261
En pratique, SHAP est aujourd’hui préféré à LIME pour la plupart des applications, en raison de ses garanties théoriques et de sa stabilité. L’exception concerne les modèles pour lesquels ni TreeSHAP ni un calcul rapide ne sont disponibles et où le temps de calcul est critique : dans ce cas, LIME peut constituer une alternative pragmatique.
Visualisation de l’attention et des gradients#
Pour les réseaux de neurones profonds (chapitres 16–20), les méthodes d’interprétabilité reposent sur la structure interne du réseau elle-même.
Cartes d’attention dans les Transformers#
Les modèles à base de Transformers (chapitre 23) utilisent un mécanisme d”attention qui produit naturellement des matrices de poids indiquant quelles parties de l’entrée le modèle « regarde » pour produire chaque élément de la sortie. Ces matrices d’attention peuvent être visualisées pour comprendre le comportement du modèle.
Définition 312 (Poids d’attention)
Dans un mécanisme d’attention (scaled dot-product attention), les poids d’attention pour une requête \(\mathbf{q}_i\) et un ensemble de clés \(\mathbf{K}\) sont :
Le poids \(\alpha_{ij}\) indique l’importance relative de la position \(j\) pour le calcul de la sortie à la position \(i\). La visualisation de la matrice \((\alpha_{ij})\) fournit une carte d’attention interprétable.
Remarque 262
Les cartes d’attention doivent être interprétées avec prudence. Plusieurs études ont montré que les poids d’attention ne reflètent pas toujours fidèlement l’importance des tokens pour la prédiction finale. En particulier, dans les architectures multi-têtes et multi-couches, l’attention d’une seule tête à une seule couche peut être trompeuse. Des méthodes plus rigoureuses comme l”attention rollout ou les attributions par gradient offrent une image plus fiable.
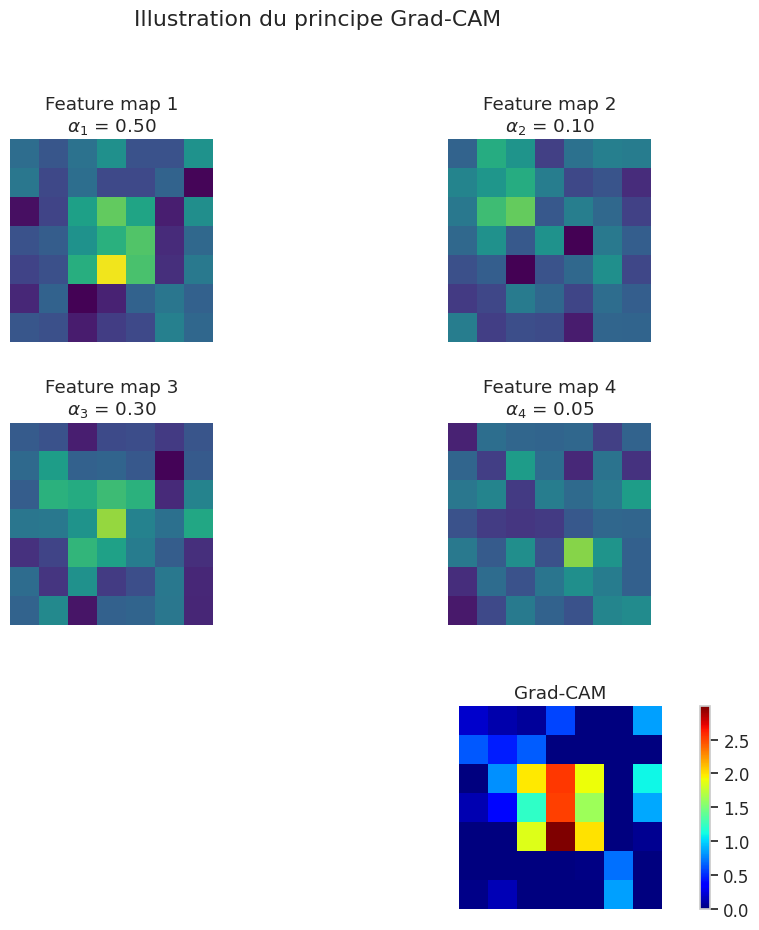
Grad-CAM pour les réseaux convolutifs#
Pour les réseaux convolutifs (chapitre 19), Grad-CAM (Gradient-weighted Class Activation Mapping) est la méthode de référence pour visualiser les régions de l’image qui ont le plus contribué à la prédiction.
Définition 313 (Grad-CAM)
Soit \(A^k \in \mathbb{R}^{H \times W}\) la carte d’activation de la \(k\)-ième feature map de la dernière couche convolutive, et \(y^c\) le score de la classe \(c\) avant softmax. Les poids d’importance de chaque feature map sont :
La carte Grad-CAM est la combinaison linéaire positive des feature maps pondérées par ces poids :
Le ReLU élimine les contributions négatives, ne conservant que les régions ayant une influence positive sur la classe \(c\).
Exemple 45 (Illustration du principe Grad-CAM)
Illustrons le concept de carte d’activation sur un exemple synthétique simulant des feature maps.
Méthodes par gradient#
Au-delà de Grad-CAM, plusieurs méthodes exploitent les gradients du modèle pour attribuer une importance à chaque feature d’entrée.
Définition 314 (Attribution par gradient)
L”attribution par gradient (vanilla gradient) pour une entrée \(\mathbf{x}\) et une classe cible \(c\) est simplement le gradient de la sortie par rapport à l’entrée :
Des variantes plus sophistiquées incluent :
Gradient \(\times\) Input : \(x_j \cdot \frac{\partial f_c}{\partial x_j}\)
Integrated Gradients : \(\text{IG}_j = (x_j - x'_j) \int_0^1 \frac{\partial f_c(\mathbf{x}' + \alpha(\mathbf{x} - \mathbf{x}'))}{\partial x_j} d\alpha\)
où \(\mathbf{x}'\) est une entrée de référence (typiquement un vecteur nul).
Remarque 263
Les Integrated Gradients (Sundararajan et al., 2017) sont particulièrement intéressants car ils satisfont deux propriétés théoriques essentielles : la complétude (la somme des attributions égale la différence de prédiction entre l’entrée et la référence) et la sensibilité (toute feature qui modifie la prédiction reçoit une attribution non nulle). Ces propriétés font des Integrated Gradients un analogue des valeurs de Shapley pour les réseaux de neurones.
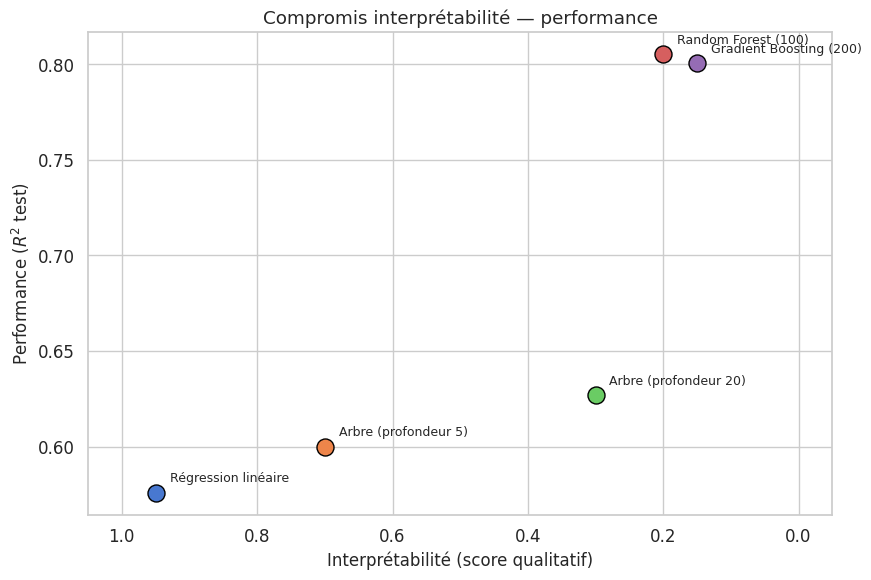
Interprétabilité et performance : quel modèle choisir ?#
Le compromis précision–interprétabilité#
Le choix d’un modèle ne repose pas uniquement sur sa performance prédictive. Dans de nombreuses applications, l’interprétabilité est une contrainte aussi importante que la précision.
R² train R² test
Régression linéaire 0.613 0.576
Arbre (profondeur 5) 0.638 0.600
Arbre (profondeur 20) 0.996 0.627
Random Forest (100) 0.974 0.805
Gradient Boosting (200) 0.836 0.800
Quand préférer un modèle interprétable ?#
Les modèles intrinsèquement interprétables sont à privilégier dans les situations suivantes :
Domaines à haute criticité : médecine, justice, finance, où les décisions affectent directement des individus et où la transparence est une obligation éthique ou légale.
Données tabulaires de dimension modérée : sur ces problèmes, l’écart de performance entre un modèle linéaire bien régularisé et un gradient boosting est souvent faible, alors que le gain en interprétabilité est considérable.
Phase exploratoire : pour comprendre les données et identifier les variables pertinentes avant de passer à un modèle plus complexe.
Débogage : un modèle interprétable sert de baseline contre laquelle comparer les modèles complexes. Si un réseau de neurones ne bat pas significativement une régression logistique, c’est un signal d’alerte.
Remarque 264
Cynthia Rudin, dans son article influent Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead (2019), argumente que pour les décisions à fort enjeu, les méthodes d’explication post hoc (LIME, SHAP) ne sont pas suffisantes : elles fournissent une approximation de l’explication, pas l’explication elle-même. La recommandation est d’investir l’effort dans la construction de modèles intrinsèquement interprétables plutôt que d’expliquer des modèles opaques après coup.
Le cadre réglementaire#
Le contexte réglementaire autour de l’IA évolue rapidement et impose des exigences croissantes en matière de transparence.
Définition 315 (Obligations de transparence (AI Act))
Le Règlement européen sur l’intelligence artificielle (AI Act, 2024) classifie les systèmes d’IA selon leur niveau de risque :
Risque inacceptable : systèmes interdits (notation sociale, manipulation subliminale).
Risque élevé : systèmes soumis à des obligations strictes de transparence, documentation technique, évaluation de conformité. Exemples : diagnostic médical assisté, scoring de crédit, recrutement automatisé.
Risque limité : obligations de transparence (l’utilisateur doit savoir qu’il interagit avec une IA).
Risque minimal : pas d’obligations spécifiques.
Pour les systèmes à risque élevé, l’article 13 exige que le système soit « suffisamment transparent pour permettre aux utilisateurs d’interpréter les résultats du système et de les utiliser de manière appropriée ».
Méthode Portée Agnostique Garanties théoriques
Coefficients linéaires Globale Non Fortes
Règles d'arbre Globale Non Fortes
GAM Globale Non Fortes
Importance par permutation Globale Oui Modérées
Importance MDI Globale Non (arbres) Faibles
Dépendance partielle (PDP) Globale Oui Modérées
LIME Locale Oui Faibles
SHAP (Shapley) Locale + Globale Oui / Spécialisé Fortes (Shapley)
Grad-CAM Locale Non (CNN) Modérées
Integrated Gradients Locale Non (NN) Fortes
Résumé#
Ce chapitre a présenté les outils fondamentaux pour comprendre et expliquer les décisions des modèles d’apprentissage automatique :
Concept |
Idée clé |
|---|---|
Interprétabilité intrinsèque |
Modèles linéaires, arbres peu profonds, GAM : transparence par construction |
Importance des features |
Permutation importance (agnostique), MDI (arbres) : quelles variables comptent ? |
Dépendance partielle |
PDP : comment une variable influence la prédiction |
LIME |
Modèle substitut local : explication linéaire au voisinage d’un point |
SHAP (Shapley) |
Répartition équitable des contributions, fondée en théorie des jeux |
TreeSHAP / KernelSHAP |
Algorithmes efficaces pour les arbres / tout modèle |
Grad-CAM |
Carte d’activation pour les CNN : où le réseau regarde-t-il ? |
Integrated Gradients |
Attribution par gradient pour les réseaux de neurones |
AI Act |
Cadre réglementaire européen imposant la transparence |
Remarque 265
L’interprétabilité n’est pas un luxe réservé aux applications réglementées : c’est une composante essentielle de la pratique rigoureuse de l’apprentissage automatique. Un modèle que l’on ne peut pas expliquer est un modèle que l’on ne peut pas déboguer, améliorer, ni déployer en confiance. Les outils présentés dans ce chapitre — de la simple lecture des coefficients d’une régression linéaire aux valeurs de Shapley en passant par les cartes d’attention et Grad-CAM — forment une boîte à outils complète pour naviguer entre le besoin de performance et l’exigence de transparence. La règle d’or est de toujours commencer par le modèle le plus simple qui répond au problème, et de ne complexifier que si les données et le contexte l’exigent.