
Réduction de dimensionnalité#
´
La simplicité est la sophistication suprème.
Leonard de Vinci
Les chapitres précédents ont traité de l’apprentissage supervisé : régression, classification, évaluation. Nous ouvrons maintenant la Partie III consacrée à l”apprentissage non supervisé, où l’on cherche à extraire de la structure à partir de données non étiquetées. Le premier problème fondamental de cette famille est la réduction de dimensionnalité : comment représenter des données vivant dans un espace de grande dimension par un nombre réduit de variables, tout en préservant au mieux l’information pertinente ?
Ce chapitre présente les méthodes classiques et modernes de réduction de dimensionnalité : l’Analyse en Composantes Principales (ACP), l’ACP noyau, la décomposition en valeurs singulières (SVD), l’analyse discriminante linéaire (LDA), t-SNE et UMAP. Nous terminerons par un exemple complet sur le jeu de données MNIST.
Introduction : la malédiction de la dimensionnalité#
En apprentissage automatique, les données sont souvent représentées par un grand nombre de variables (features). Un jeu d’images de \(28 \times 28\) pixels possède \(d = 784\) dimensions ; un corpus textuel représente par TF-IDF peut atteindre des dizaines de milliers de dimensions. Travailler dans de tels espaces pose des problèmes fondamentaux, regroupés sous le terme de malédiction de la dimensionnalité (curse of dimensionality), introduit par Richard Bellman en 1961.
Concentration des distances#
L’un des phénomènes les plus contre-intuitifs des espaces de grande dimension est la concentration des distances : lorsque \(d\) augmente, les distances entre points tendent à devenir indiscernables.
Proposition 36 (Concentration des distances)
Soient \(\mathbf{x}_1, \ldots, \mathbf{x}_n\) des points tirés uniformément dans l’hypercube \([0, 1]^d\). Notons \(D_{\max} = \max_{i \neq j} \|\mathbf{x}_i - \mathbf{x}_j\|\) et \(D_{\min} = \min_{i \neq j} \|\mathbf{x}_i - \mathbf{x}_j\|\). Alors, sous des conditions générales, lorsque \(d \to \infty\) :
Autrement dit, le rapport entre la plus grande et la plus petite distance inter-points tend vers 1 : toutes les distances se concentrent autour d’une même valeur.
Remarque 130
Cette concentration a des conséquences directes sur les algorithmes basés sur les distances, comme les \(k\)-plus proches voisins (chapitre 7) ou le clustering (chapitre 13). Si toutes les distances sont similaires, la notion de « voisin le plus proche » perd son sens, et les algorithmes deviennent inefficaces.
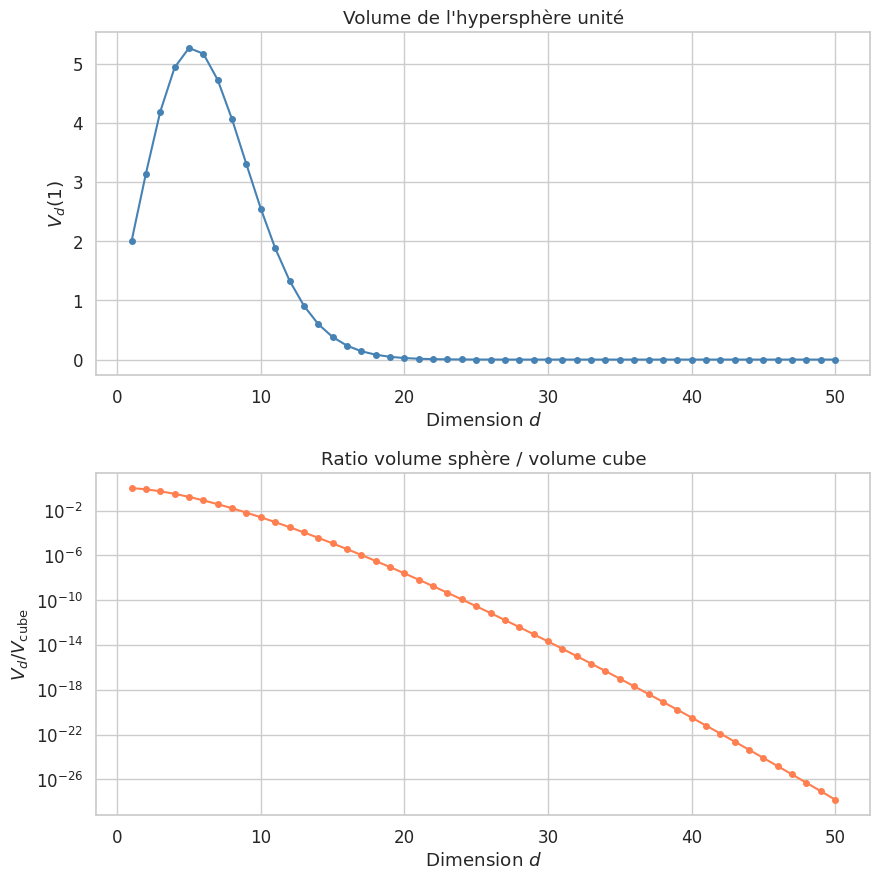
Volume des hypersphères#
Un autre phénomène remarquable concerne le volume des hypersphères.
Proposition 37 (Volume de l’hypersphère)
Le volume de l’hypersphère de rayon \(r\) en dimension \(d\) est
où \(\Gamma\) designe la fonction gamma d’Euler. Lorsque \(d \to \infty\), \(V_d(r) \to 0\) pour tout rayon \(r\) fixe. En d’autres termes, le volume de l’hypersphère devient negligeable devant celui de l’hypercube englobant \([-r, r]^d\).
Illustrons numériquement ce phénomène.

Motivations de la reduction de dimensionnalité#
La reduction de dimensionnalité répond à plusieurs besoins pratiques :
Visualisation : projeter des données en 2D ou 3D pour les explorer visuellement.
Compression : réduire la taille des données tout en conservant l’information essentielle.
Réduction du bruit : éliminer les dimensions qui ne portent que du bruit, améliorant ainsi la généralisation des modèles.
Colinéarité : lorsque les variables sont fortement corrélées, la réduction permet d’obtenir des features décorrélées, stabilisant l’estimation des modèles.
Coût calculatoire : réduire \(d\) accélère l’entrainement et l’inférence des algorithmes.
Définition 138 (Réduction de dimensionnalité)
Soit \(\mathbf{X} \in \mathbb{R}^{n \times d}\) une matrice de données. Une méthode de réduction de dimensionnalité cherche une représentation \(\mathbf{Z} \in \mathbb{R}^{n \times k}\) avec \(k \ll d\), telle qu’une certaine mesure de fidélité entre \(\mathbf{X}\) et \(\mathbf{Z}\) soit maximisée (ou, de manière équivalente, qu’une certaine mesure de perte d’information soit minimisée).
Analyse en Composantes Principales (ACP)#
L”Analyse en Composantes Principales (Principal Component Analysis, PCA) est la méthode de réduction de dimensionnalité la plus classique et la plus utilisée. Son principe est de projeter les données sur les directions de variance maximale.
Formulation#
Définition 139 (ACP — maximisation de la variance)
Soit \(\mathbf{X} \in \mathbb{R}^{n \times d}\) la matrice des données centrées (chaque colonne a une moyenne nulle). L’ACP cherche une direction unitaire \(\mathbf{w}_1 \in \mathbb{R}^d\) telle que la variance de la projection \(\mathbf{X}\mathbf{w}_1\) soit maximale :
où \(\mathbf{S} = \frac{1}{n-1} \mathbf{X}^\top \mathbf{X}\) est la matrice de covariance empirique.
La \(j\)-ième composante principale est obtenue en maximisant la variance sous la contrainte d’orthogonalité avec les composantes précédentes :
Proposition 38 (ACP et valeurs propres)
Les directions optimales \(\mathbf{w}_1, \ldots, \mathbf{w}_d\) sont les vecteurs propres de la matrice de covariance \(\mathbf{S}\), ordonnés par valeurs propres décroissantes \(\lambda_1 \geq \lambda_2 \geq \cdots \geq \lambda_d \geq 0\). La variance de la projection sur \(\mathbf{w}_j\) vaut exactement \(\lambda_j\).
Proof. On cherche le maximum de \(\mathbf{w}^\top \mathbf{S} \mathbf{w}\) sous la contrainte \(\mathbf{w}^\top \mathbf{w} = 1\). Par la méthode des multiplicateurs de Lagrange, on forme
La condition de stationnarité donne \(\nabla_{\mathbf{w}} \mathcal{L} = 2\mathbf{S}\mathbf{w} - 2\lambda \mathbf{w} = 0\), soit \(\mathbf{S}\mathbf{w} = \lambda \mathbf{w}\). Ainsi \(\mathbf{w}\) est un vecteur propre de \(\mathbf{S}\) et la valeur de l’objectif est \(\mathbf{w}^\top \mathbf{S} \mathbf{w} = \lambda \mathbf{w}^\top \mathbf{w} = \lambda\). Pour maximiser, on choisit la plus grande valeur propre \(\lambda_1\). Par récurrence, les composantes suivantes correspondent aux valeurs propres suivantes.
Variance expliquée et choix du nombre de composantes#
Définition 140 (Variance expliquée)
Le ratio de variance expliquee par les \(k\) premières composantes principales est
Ce ratio mesure la proportion d’information (au sens de la variance) conservée lors de la projection sur les \(k\) premières composantes.
En pratique, on choisit \(k\) tel que \(\rho_k\) dépasse un seuil (typiquement 90 % ou 95 %), ou bien on utilise le scree plot (diagramme des éboulis) pour identifier un « coude » dans la décroissance des valeurs propres.
ACP avec Scikit-learn#
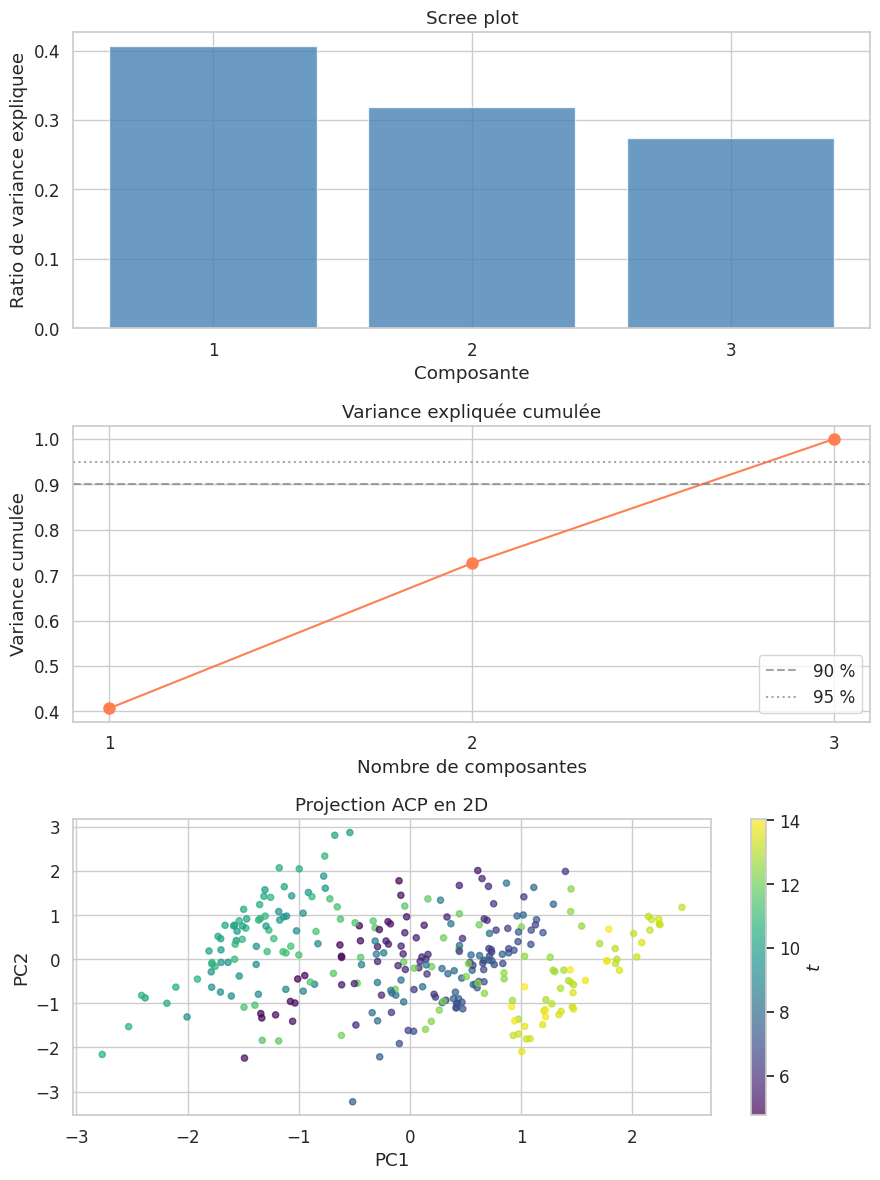
Variance expliquée par composante : [0.40671892 0.31941195 0.27386913]
Variance cumulée : [0.40671892 0.72613087 1. ]
Remarque 131
Il est crucial de standardiser les données (centrer et réduire) avant d’appliquer l’ACP. En effet, l’ACP maximise la variance : si les variables ont des échelles différentes, celles à grande variance domineront les premières composantes, indépendamment de leur pertinence. La standardisation met toutes les variables sur un pied d’égalité.
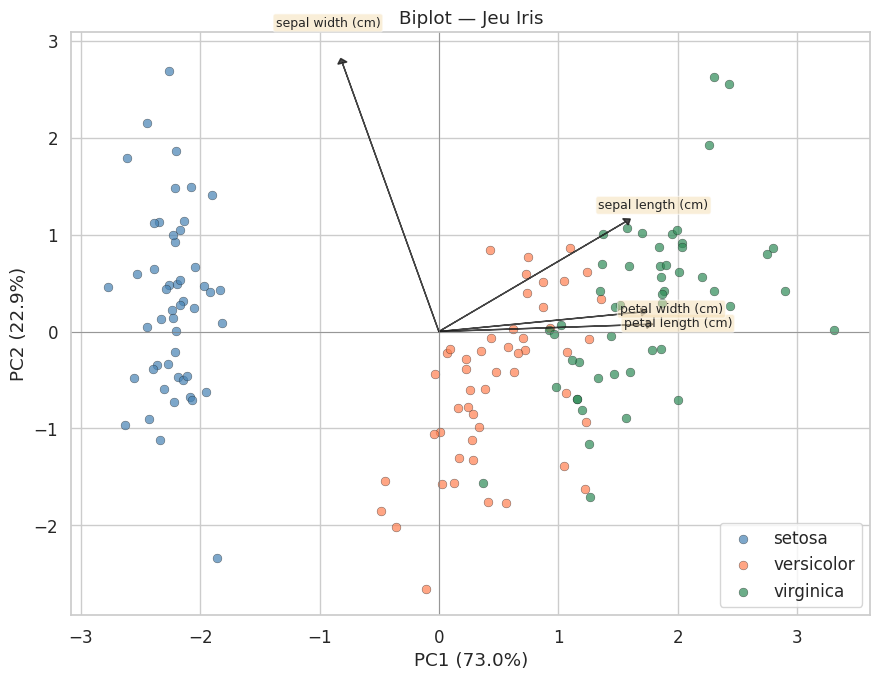
Biplot#
Le biplot est un graphique qui superpose la projection des observations et les directions des variables originales dans l’espace des composantes principales. Il permet de comprendre quelles variables contribuent à chaque composante.
ACP noyau (Kernel PCA)#
Limitations de l’ACP linéaire#
L’ACP classique est une méthode linéaire : elle ne capture que les correlations liéeaires entre les variables. Lorsque la structure sous-jacente des données est non linéaire (par exemple une variété courbe), l’ACP linéaire ne parvient pas à trouver une représentation compacte satisfaisante.
Exemple 12
Considérons des données disposées en cercles concentriques dans \(\mathbb{R}^2\). L’ACP linéaire ne peut pas séparer les deux cercles en projetant sur une seule composante, car aucune direction linéaire ne les distingue.
Le kernel trick appliqué à l’ACP#
L’idée de l”ACP noyau est d’appliquer l’astuce du noyau (kernel trick), vue au chapitre 10 sur les SVM, à l’ACP. On projette implicitement les données dans un espace de grande (voire infinie) dimension via une fonction \(\phi : \mathbb{R}^d \to \mathcal{H}\), puis on applique l’ACP linéaire dans cet espace.
Définition 141 (ACP noyau)
Soit \(\kappa : \mathbb{R}^d \times \mathbb{R}^d \to \mathbb{R}\) une fonction noyau definie positive, c’est-à-dire telle qu’il existe un espace de Hilbert \(\mathcal{H}\) et une application \(\phi\) vérifiant \(\kappa(\mathbf{x}, \mathbf{x}') = \langle \phi(\mathbf{x}), \phi(\mathbf{x}') \rangle_{\mathcal{H}}\). L”ACP noyau consiste à :
Calculer la matrice de Gram \(\mathbf{K} \in \mathbb{R}^{n \times n}\) avec \(K_{ij} = \kappa(\mathbf{x}_i, \mathbf{x}_j)\).
Centrer \(\mathbf{K}\) dans l’espace des features : \(\tilde{\mathbf{K}} = \mathbf{K} - \mathbf{1}_n \mathbf{K} - \mathbf{K} \mathbf{1}_n + \mathbf{1}_n \mathbf{K} \mathbf{1}_n\), ou \(\mathbf{1}_n = \frac{1}{n}\mathbf{11}^\top\).
Calculer les valeurs propres et vecteurs propres de \(\tilde{\mathbf{K}}\).
Les composantes principales noyau sont données par les vecteurs propres normalisés.
Les noyaux les plus courants sont :
Noyau RBF (gaussien) : \(\kappa(\mathbf{x}, \mathbf{x}') = \exp\!\left(-\gamma \|\mathbf{x} - \mathbf{x}'\|^2\right)\)
Noyau polynomial : \(\kappa(\mathbf{x}, \mathbf{x}') = (\gamma \, \mathbf{x}^\top \mathbf{x}' + c_0)^p\)
Exemple : cercles concentriques#
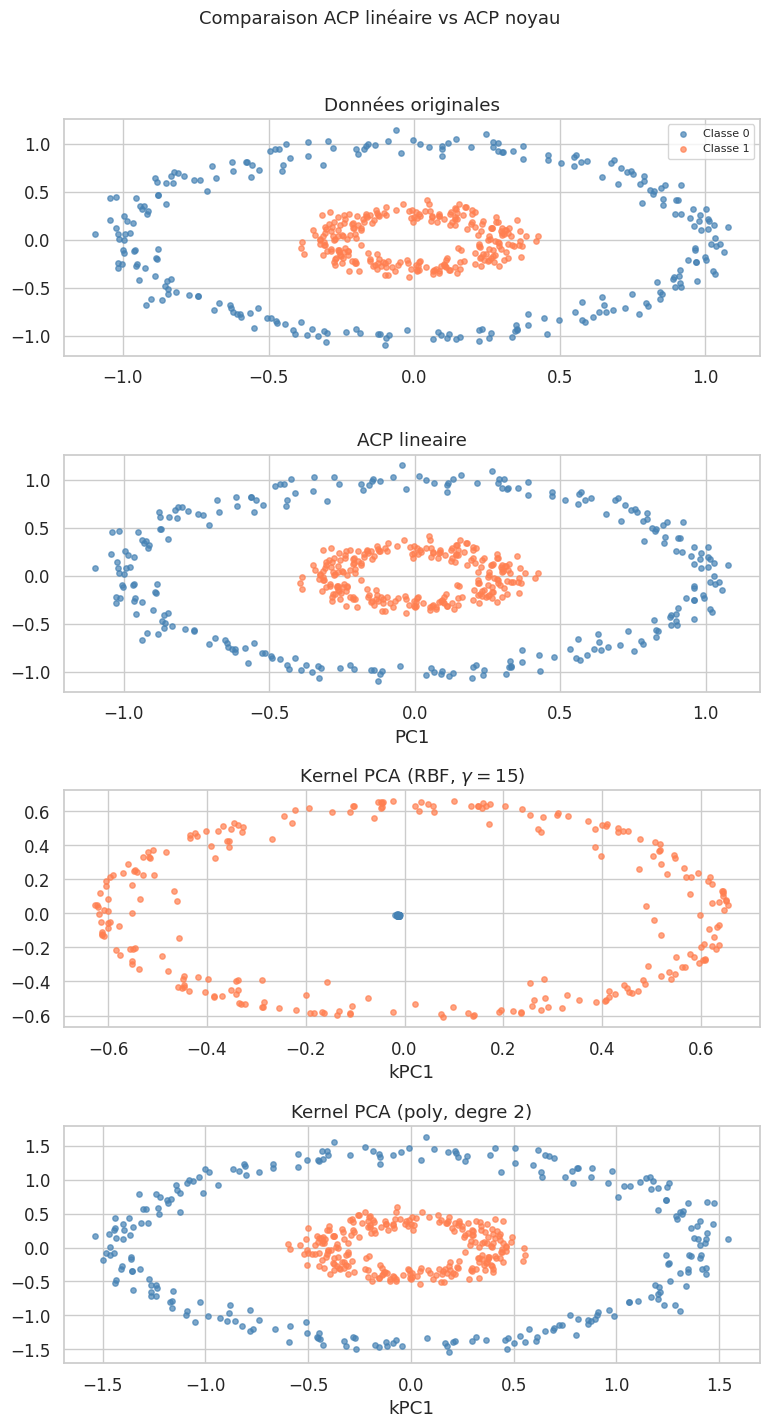
Remarque 132
L’ACP noyau avec un noyau RBF parvient à « dérouler » les cercles concentriques et à séparer linéairement les deux classes dans l’espace projeté. Le choix du paramètre \(\gamma\) est cependant crucial : une valeur trop petite revient à l’ACP linéaire, une valeur trop grande conduit à un sur-ajustement au bruit. En pratique, on peut utiliser la validation croisée pour sélectionner \(\gamma\) dans un pipeline supervisé.
Décomposition en valeurs singulières (SVD)#
Lien avec l’ACP#
La décomposition en valeurs singulières (Singular Value Decomposition, SVD) est une factorisation matricielle fondamentale, étroitement liée a l’ACP.
Définition 142 (SVD)
Toute matrice \(\mathbf{X} \in \mathbb{R}^{n \times d}\) admet une décomposition
où :
\(\mathbf{U} \in \mathbb{R}^{n \times n}\) est une matrice orthogonale (les colonnes sont les vecteurs singuliers gauches),
\(\boldsymbol{\Sigma} \in \mathbb{R}^{n \times d}\) est une matrice diagonale dont les entrées \(\sigma_1 \geq \sigma_2 \geq \cdots \geq 0\) sont les valeurs singulières,
\(\mathbf{V} \in \mathbb{R}^{d \times d}\) est une matrice orthogonale (les colonnes sont les vecteurs singuliers droits).
Proposition 39 (Lien SVD-ACP)
Si \(\mathbf{X}\) est centrée, alors la matrice de covariance s’ecrit \(\mathbf{S} = \frac{1}{n-1}\mathbf{X}^\top \mathbf{X} = \frac{1}{n-1} \mathbf{V} \boldsymbol{\Sigma}^\top \boldsymbol{\Sigma} \mathbf{V}^\top\). Les vecteurs propres de \(\mathbf{S}\) sont donc les colonnes de \(\mathbf{V}\) (les vecteurs singuliers droits de \(\mathbf{X}\)), et les valeurs propres sont \(\lambda_j = \frac{\sigma_j^2}{n-1}\).
Autrement dit, l’ACP de \(\mathbf{X}\) s’obtient directement à partir de la SVD de \(\mathbf{X}\), sans calculer explicitement \(\mathbf{S}\), ce qui est plus stable numériquement.
SVD tronquée#
En pratique, on n’a besoin que des \(k\) premières composantes. La SVD tronquée calcule uniquement les \(k\) plus grandes valeurs singulières et les vecteurs associés, ce qui est bien plus efficace que la SVD complète pour des matrices de grande taille.
Définition 143 (SVD tronquée)
La SVD tronquée de rang \(k\) est l’approximation
où \(\mathbf{U}_k \in \mathbb{R}^{n \times k}\), \(\boldsymbol{\Sigma}_k \in \mathbb{R}^{k \times k}\) et \(\mathbf{V}_k \in \mathbb{R}^{d \times k}\). Le théorème d’Eckart-Young garantit que cette approximation est optimale au sens de la norme de Frobenius parmi toutes les matrices de rang \(k\).
Remarque 133
TruncatedSVD de Scikit-learn est particulièrement adapté aux matrices creuses (sparse matrices), car il ne nécessite pas de centrer les données (ce qui détruirait la parcimonie). C’est le choix recommandé pour les représentations TF-IDF en traitement du langage naturel.
Application : compression d’images#

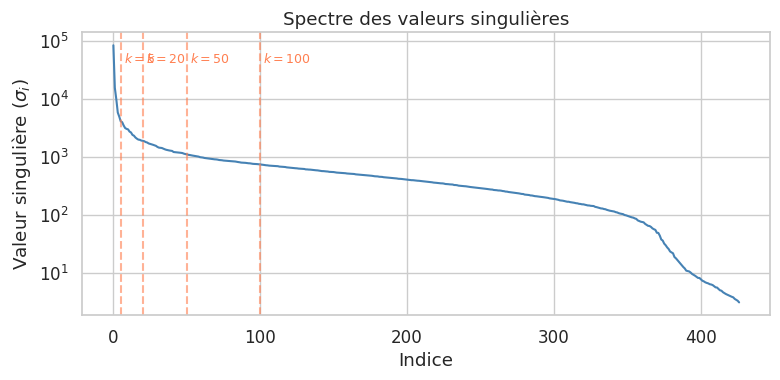
Analyse discriminante linéaire (LDA)#
Distinction supervisée/non supervisée#
Contrairement à l’ACP qui est une méthode non supervisée (elle ignore les étiquettes), l”Analyse Discriminante Linéaire (Linear Discriminant Analysis, LDA) est une méthode supervisée de réduction de dimensionnalité. Elle cherche les projections qui maximisent la séparabilité entre les classes.
Définition 144 (Matrices de dispersion inter- et intra-classes)
Soit \(\{(\mathbf{x}_i, y_i)\}_{i=1}^n\) un jeu étiqueté avec \(C\) classes. On définit :
La moyenne globale : \(\boldsymbol{\mu} = \frac{1}{n} \sum_{i=1}^n \mathbf{x}_i\)
La moyenne de la classe \(c\) : \(\boldsymbol{\mu}_c = \frac{1}{n_c} \sum_{i : y_i = c} \mathbf{x}_i\)
La matrice de dispersion intra-classe (within-class scatter) :
La matrice de dispersion inter-classes (between-class scatter) :
Proposition 40 (Critère de Fisher)
La LDA cherche la direction \(\mathbf{w}\) qui maximise le critère de Fisher :
La solution est donnée par les vecteurs propres du problème généralisé \(\mathbf{S}_B \mathbf{w} = \lambda \mathbf{S}_W \mathbf{w}\), ou de manière équivalente, par les vecteurs propres de \(\mathbf{S}_W^{-1} \mathbf{S}_B\).
Le nombre maximal de composantes discriminantes est \(\min(d, C-1)\), car \(\operatorname{rang}(\mathbf{S}_B) \leq C - 1\).
Remarque 134
La LDA peut être vue sous deux angles complémentaires :
Comme une méthode de réduction de dimensionnalité supervisée (projection sur au plus \(C-1\) axes).
Comme un classifieur génératif qui suppose que les classes suivent des lois normales avec la même matrice de covariance.
Dans Scikit-learn, LinearDiscriminantAnalysis joue ces deux rôles.
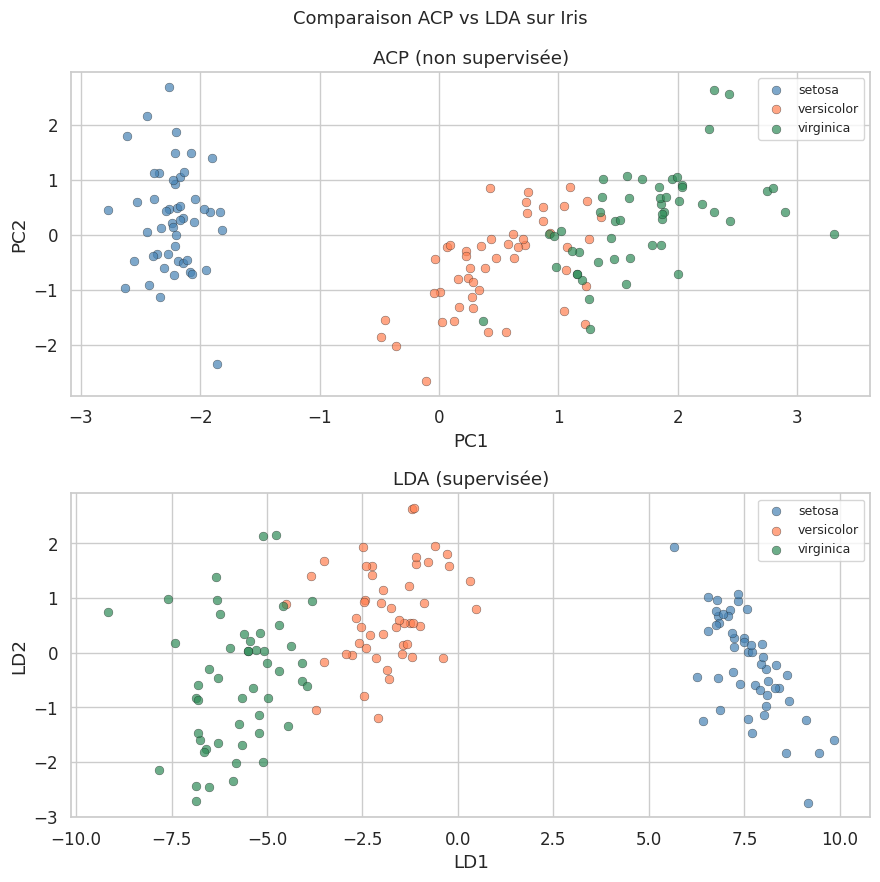
Remarque 135
Sur le jeu Iris, la LDA sépare nettement les trois classes avec seulement deux composantes discriminantes (le maximum pour \(C = 3\)), tandis que l’ACP, qui ignore les étiquettes, ne garantit pas une telle séparation. Cependant, la LDA nécessite des étiquettes et n’est donc pas utilisable dans un contexte purement non supervisé.
t-SNE#
Les méthodes vues jusqu’ici (ACP, LDA) sont linéaires : elles projettent les données à l’aide de transformations linéaires. Pour la visualisation de données complexes en haute dimension, des méthodes non linéaires sont souvent plus appropriées. La plus célèbre est t-SNE (t-distributed Stochastic Neighbor Embedding), proposée par van der Maaten et Hinton en 2008.
Principe#
Définition 145 (t-SNE)
L’algorithme t-SNE procède en deux étapes :
1. Distributions conditionnelles dans l’espace original. Pour chaque paire de points \((\mathbf{x}_i, \mathbf{x}_j)\), on définit la probabilité conditionnelle
puis on symétrise : \(p_{ij} = \frac{p_{j|i} + p_{i|j}}{2n}\). Le paramètre \(\sigma_i\) est ajusté pour que la perplexité locale corresponde à une valeur prescrite.
2. Distribution dans l’espace de basse dimension. Dans l’espace de projection \(\mathbb{R}^2\) (ou \(\mathbb{R}^3\)), les similarités sont modelisées par une distribution de Student à un degré de liberté (distribution de Cauchy) :
3. Optimisation. On minimise la divergence de Kullback-Leibler \(\mathrm{KL}(P \| Q) = \sum_{i \neq j} p_{ij} \log \frac{p_{ij}}{q_{ij}}\) par descente de gradient.
Définition 146 (Perplexité)
La perplexité est un hyperparamètre de t-SNE qui contrôle le nombre effectif de voisins considérés pour chaque point :
où \(H(P_i) = -\sum_j p_{j|i} \log_2 p_{j|i}\) est l’entropie de Shannon de la distribution conditionnelle. Une perplexité typique est comprise entre 5 et 50. Des valeurs basses privilégient la structure locale, des valeurs élevées prennent en compte davantage de structure globale.
Remarque 136
t-SNE présente plusieurs limitations importantes à garder en tête :
Non paramétrique : t-SNE ne définit pas de transformation applicable à de nouvelles données (pas de methode
transform).Non déterministe : le résultat depend de l’initialisation aléatoire (fixer
random_statepour la reproductibilité).Structure globale non preserveée : t-SNE excelle à préserver les distances locales, mais les distances entre clusters éloignés ne sont pas nécessairement significatives.
Sensible à la perplexité : des valeurs différentes peuvent donner des résultats visuellement très différents.
Complexité : \(O(n^2)\) en temps et en mémoire (des approximations comme Barnes-Hut réduisent cela a \(O(n \log n)\)).
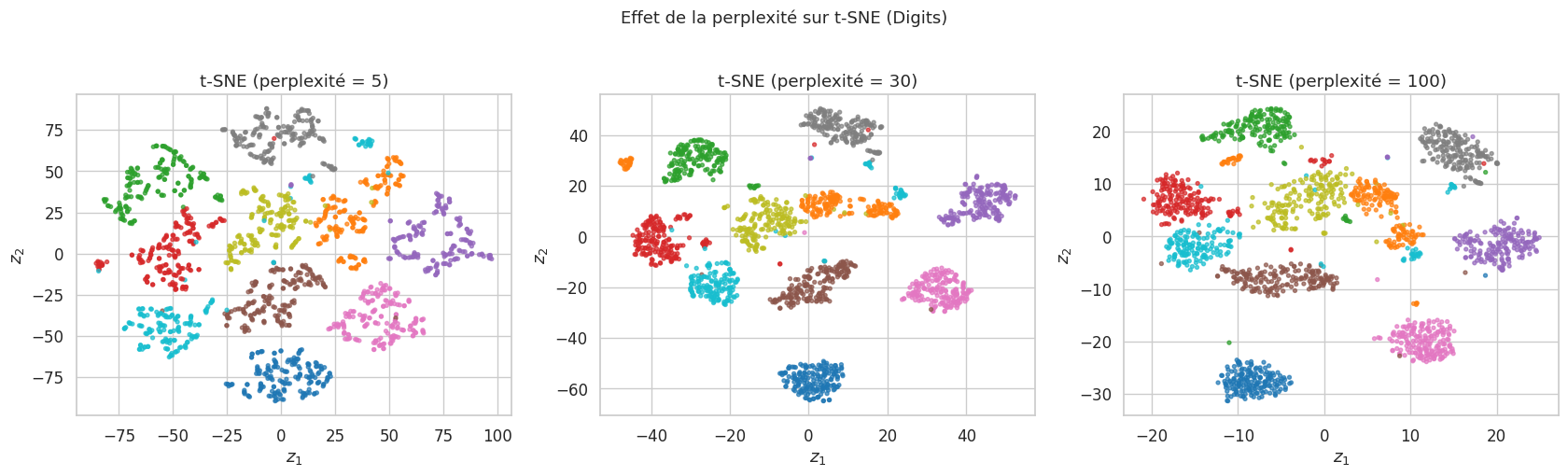
UMAP#
UMAP (Uniform Manifold Approximation and Projection), proposé par McInnes, Healy et Melville en 2018, est une alternative à t-SNE qui s’est rapidement imposée comme la méthode de référence pour la visualisation en haute dimension.
Intuition topologique#
Définition 147 (UMAP — principe)
UMAP repose sur une approche topologique :
Construction d’un graphe k-NN flou (fuzzy simplicial set). Pour chaque point \(\mathbf{x}_i\), on considère ses \(k\) plus proches voisins. Les distances sont transformees en poids d’aretes via une fonction de decroissance exponentielle, calibrée localement pour que chaque point « voie » son voisinage de manière uniforme. On obtient un graphe pondéré qui encode la topologie locale des données.
Projection en basse dimension. On initialise une représentation \(\mathbf{Z} \in \mathbb{R}^{n \times 2}\) et on construit un graphe similaire dans l’espace de basse dimension.
Optimisation d’une entropie croisée floue (fuzzy cross-entropy). On ajuste \(\mathbf{Z}\) pour minimiser la divergence entre les deux graphes, préservant ainsi la topologie locale.
Remarque 137
UMAP présente plusieurs avantages par rapport à t-SNE :
Vitesse : UMAP est significativement plus rapide, avec une complexité typique \(O(n^{1.14})\) en pratique.
Structure globale : UMAP preserve mieux les relations inter-clusters que t-SNE.
Paramétrique : une extension paramétrique de UMAP existe, permettant de transformer de nouvelles données.
Scalabilité : UMAP gère efficacement des jeux de données de plusieurs millions de points.
Dimensions : contrairement à t-SNE, UMAP peut projeter en plus de 2-3 dimensions, ce qui permet son utilisation comme pré-traitement pour d’autres algorithmes.
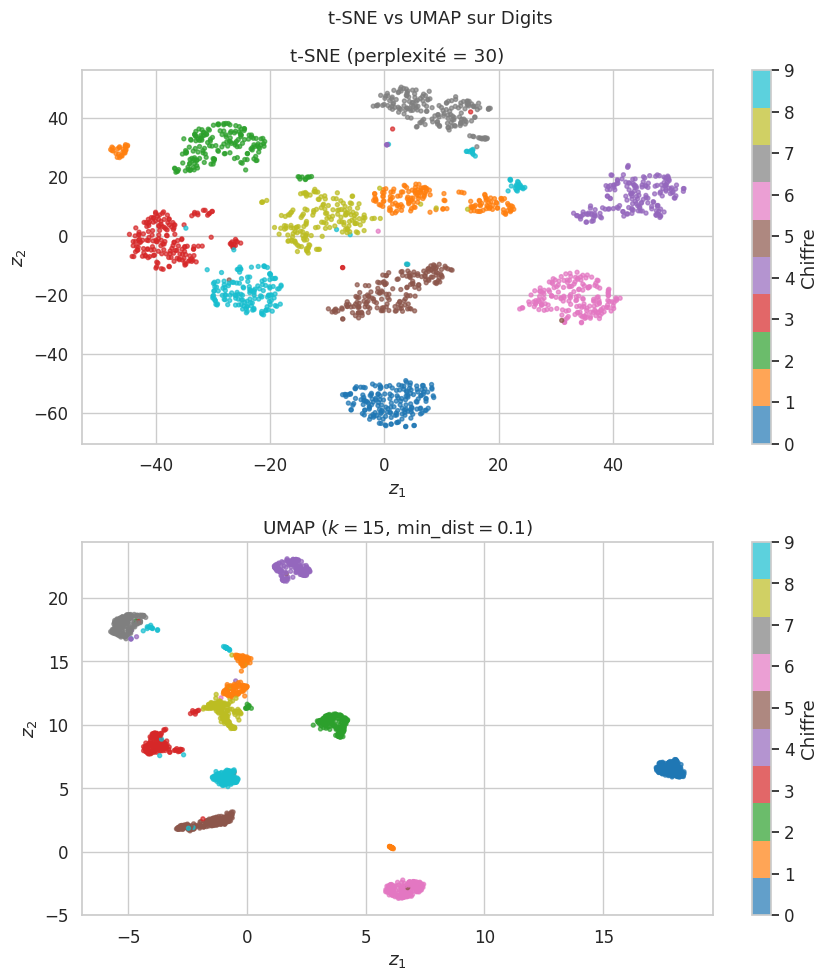
Remarque 138
Les hyperparamètres principaux de UMAP sont :
n_neighbors(\(k\)) : nombre de voisins, contrôle l’équilibre local/global (similaire à la perplexité de t-SNE).min_dist: distance minimale entre points dans l’espace projeté. Une valeur faible produit des clusters plus compacts.metric: la métrique de distance utilisée dans l’espace original (euclidienne par défaut, mais d’autres sont possibles).
Comparaison pratique des méthodes#
Apres avoir présenté individuellement chaque méthode, il est utile de les comparer de manière synthétique pour guider le choix en pratique.
Méthode |
Linéaire |
Supervisée |
Paramétrique |
Complexité |
Usage principal |
|---|---|---|---|---|---|
ACP |
Oui |
Non |
Oui |
\(O(nd^2)\) |
Compression, pré-traitement |
Kernel PCA |
Non |
Non |
Oui |
\(O(n^3)\) |
Structures non linéaires |
SVD tronquée |
Oui |
Non |
Oui |
\(O(ndk)\) |
Données creuses (NLP) |
LDA |
Oui |
Oui |
Oui |
\(O(nd^2)\) |
Classification, réduction supervisée |
t-SNE |
Non |
Non |
Non |
\(O(n^2)\) |
Visualisation 2D/3D |
UMAP |
Non |
Non |
Semi* |
\(O(n^{1.14})\) |
Visualisation, pré-traitement |
* UMAP dispose d’une extension paramétrique optionnelle.
Remarque 139
Recommandations pratiques :
Exploration visuelle : UMAP ou t-SNE (UMAP préféré pour les grands jeux de données).
Pré-traitement pour un modèle supervisé : ACP (compression, décorrelation) ou LDA (si les étiquettes sont disponibles).
Données textuelles creuses :
TruncatedSVD(ne détruit pas la parcimonie).Structures non linéaires avec besoin de
transform: Kernel PCA.Pipeline ACP \(\to\) t-SNE : réduire à 50 composantes par ACP avant d’appliquer t-SNE accélère considérablement le calcul et réduit le bruit, sans perte notable de qualité.
Exemple complet : MNIST digits#
Pour conclure ce chapitre, nous appliquons un pipeline complet de réduction de dimensionnalité au jeu de données MNIST (chiffres manuscrits), en comparant plusieurs méthodes sur un meme jeu.
Dimensions : (1797, 64)
Classes : [0 1 2 3 4 5 6 7 8 9]
Nombre d'observations par classe :
Chiffre 0 : 178
Chiffre 1 : 182
Chiffre 2 : 177
Chiffre 3 : 183
Chiffre 4 : 181
Chiffre 5 : 182
Chiffre 6 : 181
Chiffre 7 : 179
Chiffre 8 : 174
Chiffre 9 : 180

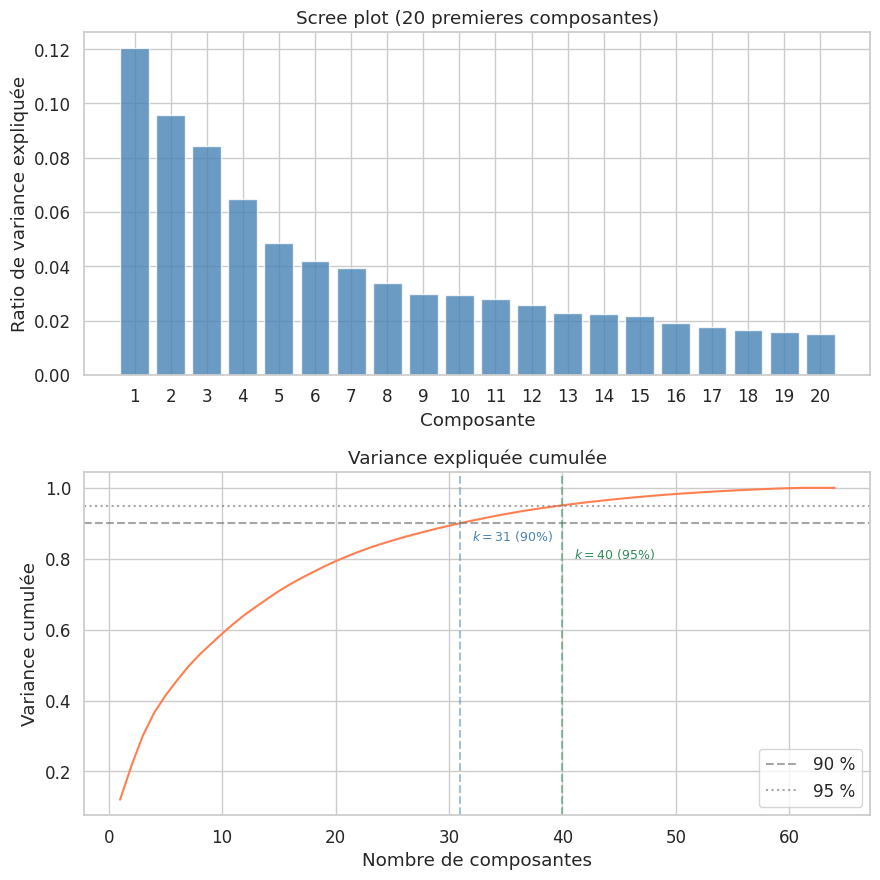
Composantes pour 90% de variance : 31
Composantes pour 95% de variance : 40
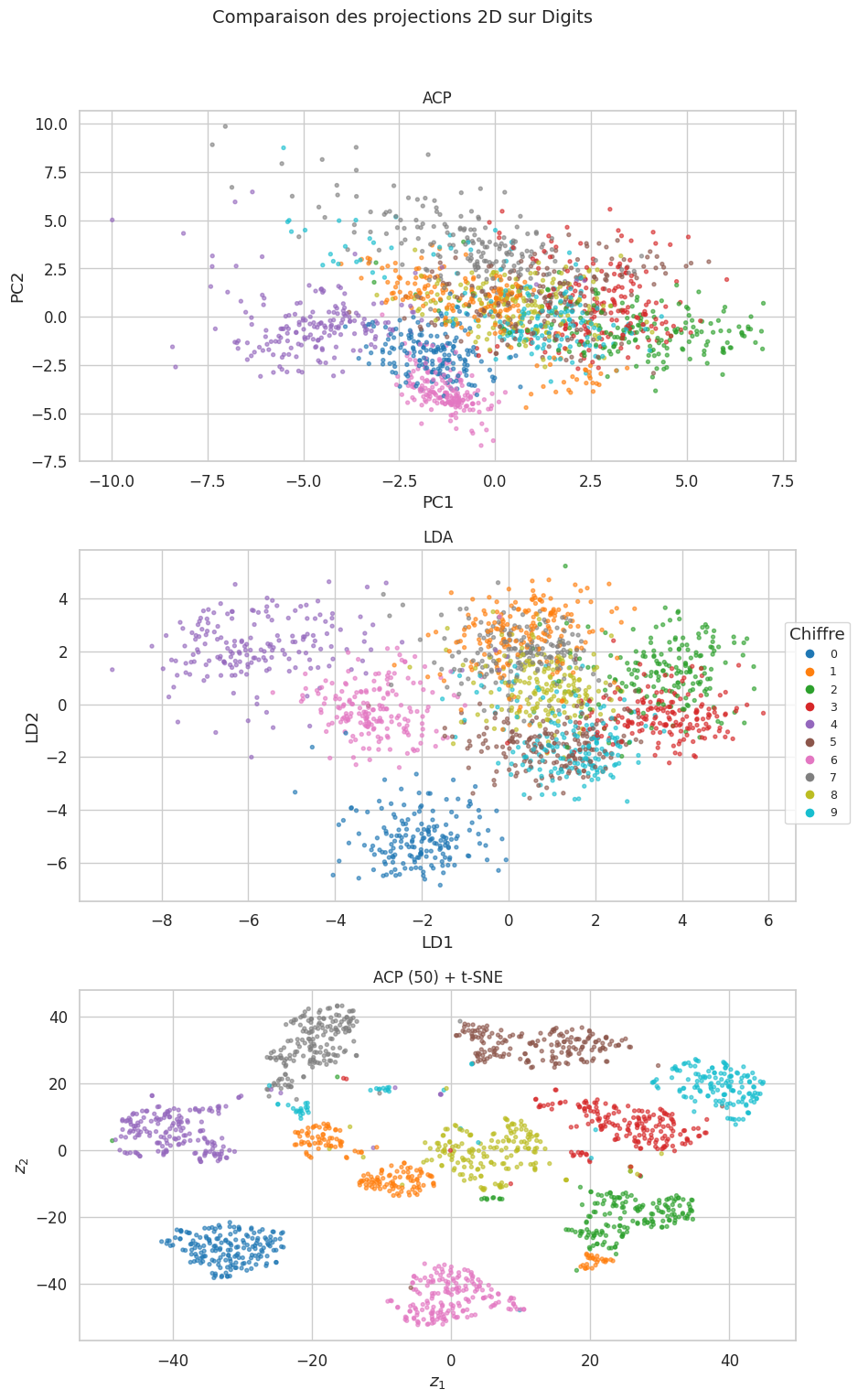
Remarque 140
Quelques observations sur les résultats :
L”ACP en 2D ne sépare que grossièrement les classes — elle préserve la variance globale mais pas nécessairement la structure par classe.
La LDA sépare mieux les classes, car elle utilise les étiquettes pour maximiser la séparabilité.
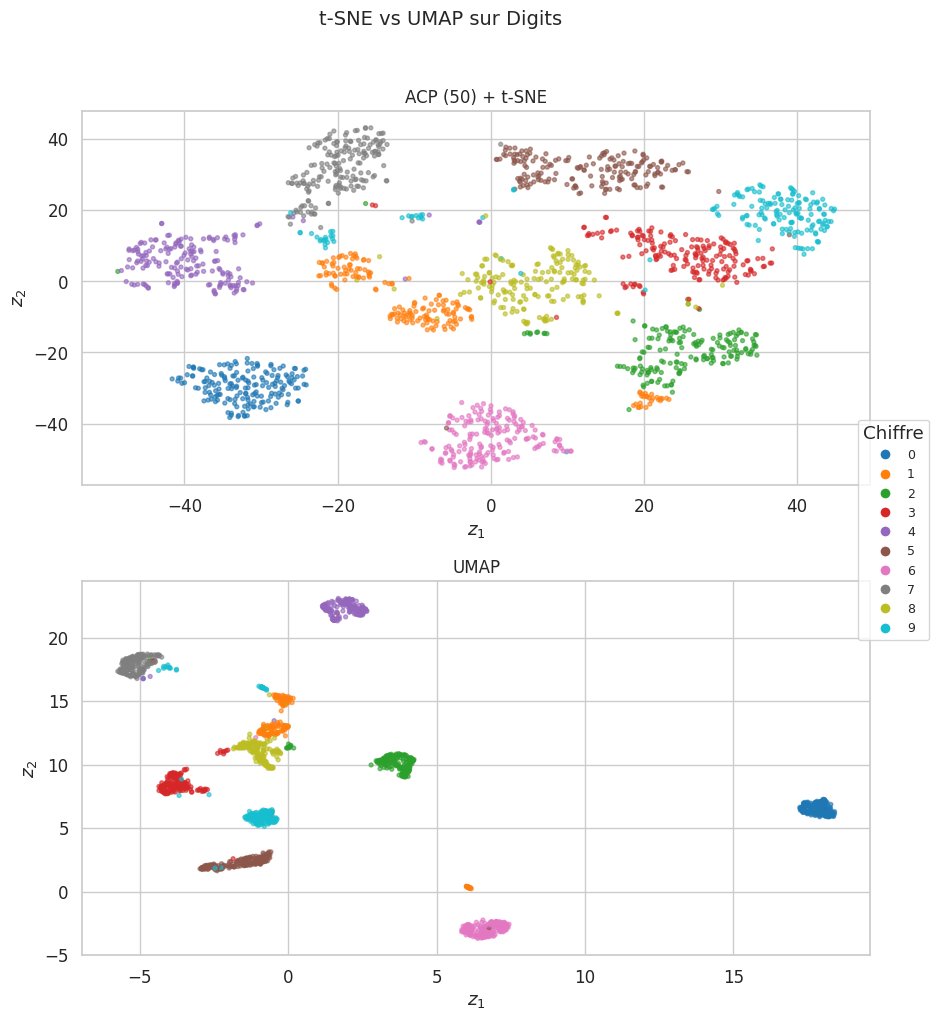
Le pipeline ACP + t-SNE produit des clusters bien définis, révélant la structure locale des données.
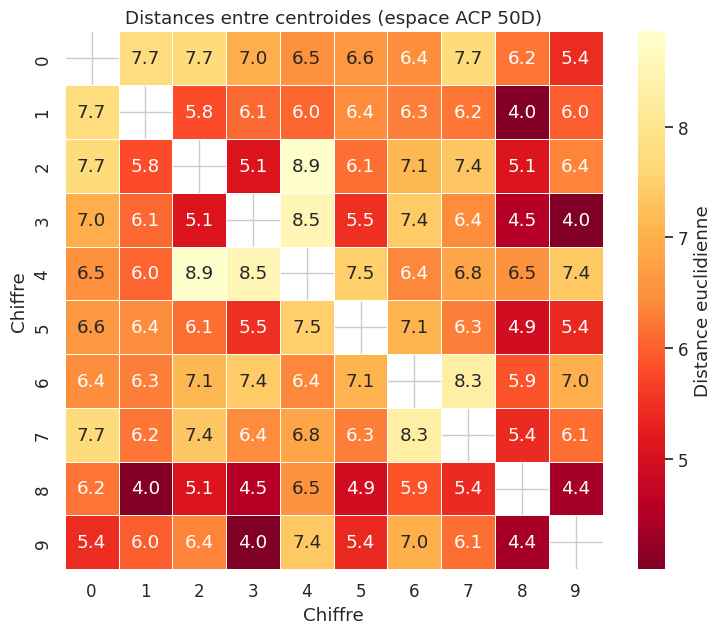
UMAP donne des résultats comparables à t-SNE avec un temps de calcul réduit, et tend à mieux preserver la structure globale (les clusters de chiffres similaires, comme 3/5/8 ou 4/9, restent proches).
Résumé#
Ce chapitre a presenté les principales méthodes de réduction de dimensionnalité, des approches linéaires classiques aux méthodes non linéaires modernes. Retenons les points essentiels :
La malédiction de la dimensionnalité rend indispensable la réduction du nombre de variables pour la visualisation, le débruitage et l’efficacité calculatoire.
L”ACP est la méthode de référence pour la compression linéaire, fondée sur la diagonalisation de la matrice de covariance.
L”ACP noyau étend l’ACP aux structures non linéaires grace à l’astuce du noyau.
La SVD tronquée offre une alternative efficace à l’ACP, particulièrement adaptée aux matrices creuses.
La LDA est la seule méthode supervisée presentée ici ; elle maximise la séparation entre classes.
t-SNE excelle pour la visualisation 2D de données complexes, en préservant les distances locales.
UMAP est une alternative plus rapide et souvent plus fidèle à la structure globale que t-SNE.
Le chapitre suivant abordera le clustering (chapitre 13), qui constitue le deuxième pilier de l’apprentissage non supervisé : au lieu de réduire la dimension, on cherchera à regrouper les observations en clusters homogènes. Les techniques de réduction de dimensionnalité vues ici seront des outils précieux pour visualiser et améliorer les résultats du clustering.