
Évaluation et sélection de modèles#
Tous les modèles sont faux, mais certains sont utiles.
George E. P. Box
Un modèle d’apprentissage automatique n’a de valeur que s’il généralise : sa capacité à produire des prédictions fiables sur des données qu’il n’a jamais vues est le critère fondamental de sa qualité. Un modèle qui restitue parfaitement les données d’entraînement mais échoue sur de nouvelles observations est inutile en pratique. Ce chapitre traite des outils théoriques et pratiques permettant d’évaluer honnêtement la performance d’un modèle, de diagnostiquer ses faiblesses, de régler ses hyperparamètres et, in fine, de choisir le meilleur modèle parmi plusieurs candidats.
Introduction : la généralisation#
L’objectif de l’apprentissage supervisé est de trouver une fonction \(\hat{f}\) qui, à partir d’une entrée \(\mathbf{x}\), prédit une sortie \(y\) aussi fidèlement que possible. On dispose d’un ensemble d’entraînement \(\mathcal{D}_{\text{train}} = \{(\mathbf{x}_i, y_i)\}_{i=1}^n\) tiré d’une distribution inconnue \(P(\mathbf{x}, y)\). La qualité de \(\hat{f}\) se mesure par le risque réel (ou erreur de généralisation) :
Définition 123 (Risque réel)
Le risque réel (true risk) d’un modèle \(\hat{f}\) relativement à une fonction de perte \(L\) est
Ce risque est inaccessible en pratique puisqu’il nécessite la connaissance de la distribution \(P\).
Le risque empirique calculé sur les données d’entraînement est un estimateur biaisé du risque réel : le modèle a été ajusté pour minimiser précisément cette quantité, ce qui le conduit à sous-estimer l’erreur réelle. Toute la problématique de l’évaluation consiste à estimer le risque réel de façon fiable, sans tricher.
Remarque 117
L’erreur d’entraînement (training error) est presque toujours inférieure à l’erreur de généralisation. L’écart entre les deux est une signature du surapprentissage (overfitting). Un bon protocole d’évaluation doit mettre en évidence cet écart.
Compromis biais-variance#
Décomposition formelle#
Considérons un problème de régression avec le modèle vrai \(y = f(\mathbf{x}) + \varepsilon\), où \(\varepsilon\) est un bruit irréductible de moyenne nulle et de variance \(\sigma^2\). Si l’on entraîne un modèle \(\hat{f}_{\mathcal{D}}\) sur un jeu de données \(\mathcal{D}\) tiré aléatoirement, l’erreur quadratique moyenne en un point \(\mathbf{x}_0\) se décompose comme suit.
Proposition 32 (Décomposition biais-variance)
Pour tout point \(\mathbf{x}_0\), l’erreur quadratique moyenne du modèle \(\hat{f}_{\mathcal{D}}\) se décompose en
soit, en notation compacte :
Chacun de ces trois termes a une interprétation précise :
Le biais mesure l’erreur systématique : c’est l’écart entre la vraie fonction \(f\) et la prédiction moyenne du modèle sur tous les jeux d’entraînement possibles. Un biais élevé signifie que le modèle est trop simple pour capturer la structure des données.
La variance mesure la sensibilité du modèle au jeu d’entraînement particulier utilisé. Une variance élevée signifie que le modèle s’adapte trop aux fluctuations aléatoires de \(\mathcal{D}\).
Le bruit irréductible est la part d’erreur due à la variabilité intrinsèque des données, que nul modèle ne peut éliminer.
Remarque 118
Le compromis biais-variance est un dilemme fondamental : augmenter la complexité d’un modèle réduit le biais mais augmente la variance, et réciproquement. L’objectif est de trouver le point d’équilibre qui minimise l’erreur totale de généralisation.
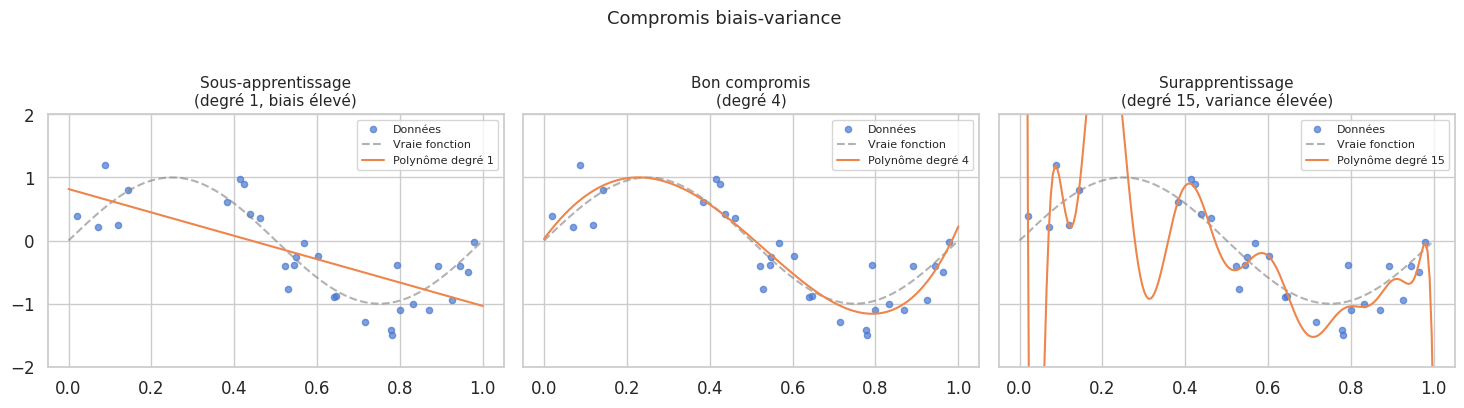
Sous-apprentissage et surapprentissage#
Définition 124 (Sous-apprentissage et surapprentissage)
Le sous-apprentissage (underfitting) se produit lorsque le modèle est trop simple pour capturer la structure des données. Il se manifeste par un biais élevé : l’erreur d’entraînement et l’erreur de validation sont toutes deux élevées.
Le surapprentissage (overfitting) se produit lorsque le modèle est trop complexe et mémorise le bruit des données d’entraînement. Il se manifeste par une variance élevée : l’erreur d’entraînement est faible mais l’erreur de validation est élevée.
Illustrons ce compromis avec un problème de régression polynomiale.
Validation croisée#
La validation croisée (cross-validation, CV) est la méthode standard pour estimer l’erreur de généralisation d’un modèle sans gaspiller de données. Plutôt que de réserver un unique ensemble de test, elle fait tourner les rôles entre entraînement et validation.
Holdout (train/test split)#
La méthode la plus simple consiste à partitionner les données en deux sous-ensembles : un ensemble d’entraînement et un ensemble de test.
Définition 125 (Holdout)
Soit \(\mathcal{D} = \{(\mathbf{x}_i, y_i)\}_{i=1}^n\). Le holdout partitionne \(\mathcal{D}\) en
typiquement avec \(|\mathcal{D}_{\text{train}}| \approx 0{,}8 \cdot n\) et \(|\mathcal{D}_{\text{test}}| \approx 0{,}2 \cdot n\). L’erreur de généralisation est estimée par
Remarque 119
Le holdout est simple mais présente deux inconvénients majeurs : (1) l’estimation dépend fortement de la partition choisie, et (2) les données de test sont « gaspillées » — elles ne servent pas à l’entraînement. Ces deux problèmes sont particulièrement critiques lorsque \(n\) est petit.
Validation croisée à \(k\) plis#
Définition 126 (Validation croisée à \(k\) plis)
La validation croisée à \(k\) plis (\(k\)-fold cross-validation) partitionne \(\mathcal{D}\) en \(k\) sous-ensembles (ou plis) de taille approximativement égale \(\mathcal{D}_1, \ldots, \mathcal{D}_k\). Pour chaque pli \(j \in \{1, \ldots, k\}\) :
Le modèle est entraîné sur \(\mathcal{D} \setminus \mathcal{D}_j\) (tous les plis sauf le \(j\)-ème).
Il est évalué sur \(\mathcal{D}_j\).
L’estimateur de l’erreur de généralisation est la moyenne des erreurs sur les \(k\) plis :
où \(\hat{f}_j\) est le modèle entraîné sans le pli \(j\).
Le choix de \(k\) est un compromis :
\(k\) petit (par ex. 5) : entraînement rapide mais estimation plus variable, chaque modèle n’utilise que \((k-1)/k\) des données.
\(k\) grand (par ex. 10 ou \(n\)) : estimation moins biaisée mais plus coûteuse et potentiellement plus variable.
Le choix \(k = 5\) ou \(k = 10\) est le plus courant et recommandé dans la littérature.
Holdout — Accuracy test : 1.0000
5-Fold CV — Accuracy : 0.9733 ± 0.0249
Scores par pli : [0.9667 1. 0.9333 0.9667 1. ]
10-Fold CV — Accuracy : 0.9733 ± 0.0327
Validation croisée stratifiée#
Définition 127 (Validation croisée stratifiée)
La validation croisée stratifiée (stratified \(k\)-fold CV) construit les \(k\) plis de sorte que chaque pli conserve la même proportion de chaque classe que l’ensemble complet. Si la classe \(c\) représente une fraction \(p_c\) de l’ensemble total, chaque pli contiendra environ \(p_c \cdot |\mathcal{D}_j|\) exemples de la classe \(c\).
Remarque 120
La stratification est essentielle lorsque les classes sont déséquilibrées. Sans stratification, un pli pourrait ne contenir aucun exemple d’une classe minoritaire, rendant l’évaluation sur ce pli non représentative. Scikit-learn utilise la stratification par défaut dans cross_val_score pour les problèmes de classification.
Distribution des classes : [180 20]
KFold — Distribution par pli :
Pli 1 : [34 6]
Pli 2 : [37 3]
Pli 3 : [36 4]
Pli 4 : [36 4]
Pli 5 : [37 3]
StratifiedKFold — Distribution par pli :
Pli 1 : [36 4]
Pli 2 : [36 4]
Pli 3 : [36 4]
Pli 4 : [36 4]
Pli 5 : [36 4]
Leave-One-Out (LOO)#
Définition 128 (Leave-One-Out)
Le Leave-One-Out (LOO) est le cas particulier de la validation croisée à \(k\) plis avec \(k = n\). À chaque itération, un seul exemple sert d’ensemble de test et les \(n - 1\) restants servent d’entraînement :
où \(\hat{f}_{-i}\) est le modèle entraîné sur \(\mathcal{D} \setminus \{(\mathbf{x}_i, y_i)\}\).
Remarque 121
Le LOO fournit un estimateur quasi non biaisé du risque réel, mais sa variance est élevée car les \(n\) ensembles d’entraînement sont presque identiques (ils partagent \(n - 2\) exemples). De plus, il est très coûteux en calcul : il requiert \(n\) entraînements du modèle. En pratique, le LOO est rarement utilisé sauf lorsque \(n\) est très petit (quelques dizaines d’observations).
LOO (178 itérations) — Accuracy : 0.9831
10-Fold CV — Accuracy : 0.9833 ± 0.0255
Résumé des stratégies de validation#
Proposition 33 (Guide de choix de la stratégie de validation)
Méthode |
Biais |
Variance |
Coût |
Usage recommandé |
|---|---|---|---|---|
Holdout 80/20 |
Modéré |
Élevée |
Faible |
\(n\) très grand (\(> 10^5\)) |
5-Fold CV |
Modéré |
Modérée |
Modéré |
Usage général |
10-Fold CV |
Faible |
Modérée |
Modéré |
Usage général, estimation fine |
Stratified \(k\)-Fold |
Faible |
Modérée |
Modéré |
Classes déséquilibrées |
LOO |
Très faible |
Élevée |
Très élevé |
\(n\) très petit (\(< 50\)) |
En pratique, la validation croisée stratifiée à 5 ou 10 plis est le choix par défaut le plus robuste.
Courbes d’apprentissage#
Les courbes d’apprentissage (learning curves) représentent l’erreur d’entraînement et l’erreur de validation en fonction de la taille de l’ensemble d’entraînement \(n\). Elles constituent un outil de diagnostic visuel puissant pour identifier le biais et la variance.
Définition 129 (Courbe d’apprentissage)
Soit \(\hat{R}_{\text{train}}(n)\) et \(\hat{R}_{\text{val}}(n)\) les erreurs d’entraînement et de validation lorsque le modèle est entraîné sur \(n\) exemples. La courbe d’apprentissage trace ces deux quantités en fonction de \(n\).
L’allure de ces courbes permet de diagnostiquer la nature du problème :
Biais élevé (sous-apprentissage) : les deux courbes convergent vers une erreur élevée. Ajouter des données ne résoudra pas le problème ; il faut augmenter la complexité du modèle.
Variance élevée (surapprentissage) : l’erreur d’entraînement est faible mais l’erreur de validation est nettement supérieure, avec un écart persistant. Ajouter des données peut aider ; sinon, il faut réduire la complexité du modèle ou régulariser.
Bon compromis : les deux courbes convergent vers une erreur faible avec un écart réduit.
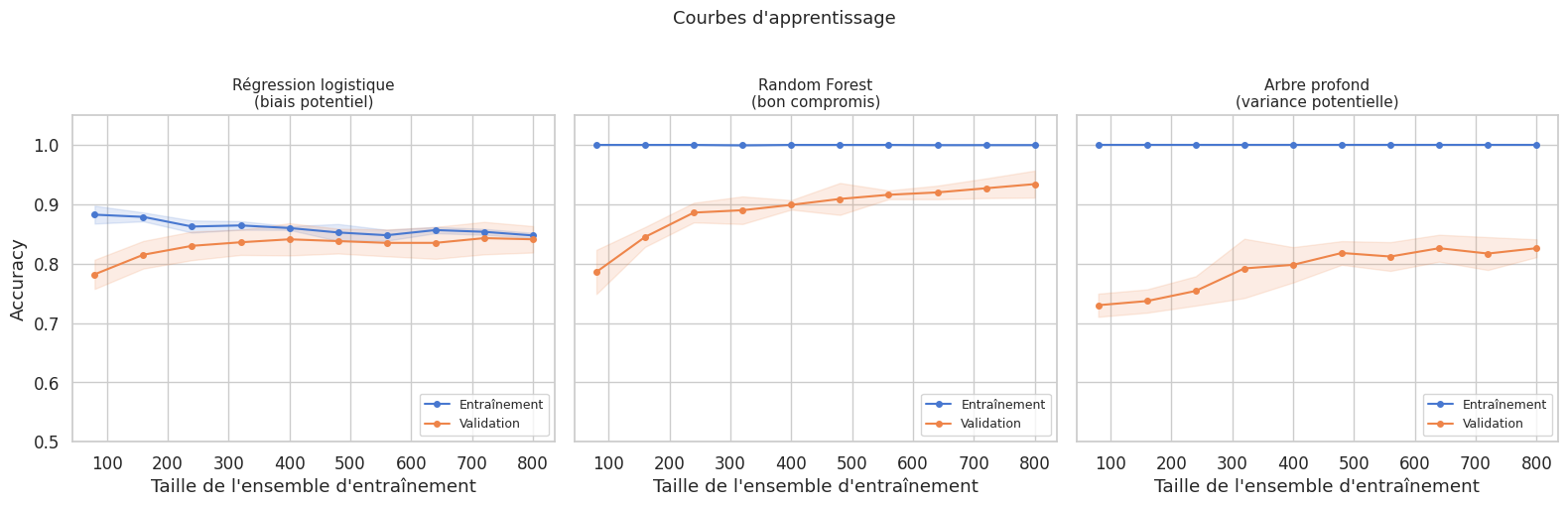
Remarque 122
Les courbes d’apprentissage indiquent non seulement le type de problème (biais ou variance) mais aussi si l’acquisition de données supplémentaires serait bénéfique. Si les deux courbes ont convergé, collecter davantage de données ne changera rien : il faut modifier le modèle.
Recherche d’hyperparamètres#
Les hyperparamètres sont les paramètres d’un modèle qui ne sont pas appris lors de l’entraînement mais fixés avant celui-ci (profondeur maximale d’un arbre, coefficient de régularisation \(C\), nombre de voisins \(k\), etc.). Leur choix a un impact considérable sur la performance du modèle.
Définition 130 (Hyperparamètre)
Un hyperparamètre \(\lambda \in \Lambda\) est un paramètre qui contrôle le processus d’apprentissage mais n’est pas optimisé par la procédure d’entraînement elle-même. L’objectif de la recherche d’hyperparamètres est de trouver
c’est-à-dire l’hyperparamètre qui minimise l’erreur estimée par validation croisée.
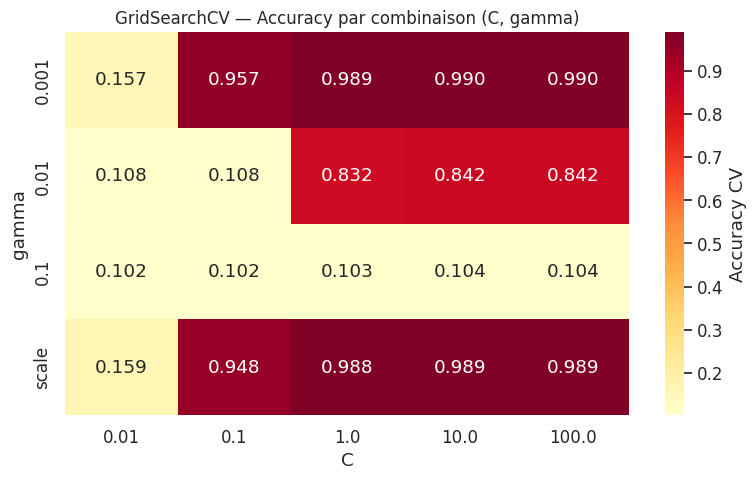
Recherche par grille (GridSearchCV)#
Définition 131 (Recherche par grille)
La recherche par grille (grid search) évalue toutes les combinaisons d’une grille d’hyperparamètres prédéfinie. Si l’on a \(p\) hyperparamètres avec respectivement \(n_1, n_2, \ldots, n_p\) valeurs candidates, le nombre total de combinaisons est
Chaque combinaison est évaluée par validation croisée à \(k\) plis, soit \(N \times k\) entraînements au total.
Remarque 123
La recherche par grille souffre de la malédiction de la dimensionnalité : le nombre de combinaisons croît exponentiellement avec le nombre d’hyperparamètres. Pour 5 hyperparamètres avec 10 valeurs chacun, on obtient \(10^5 = 100\,000\) combinaisons. En pratique, la grille doit rester raisonnablement petite.
Meilleurs hyperparamètres : {'C': 10, 'gamma': 0.001, 'kernel': 'rbf'}
Meilleur score CV : 0.9896
Score sur le test : 0.9917
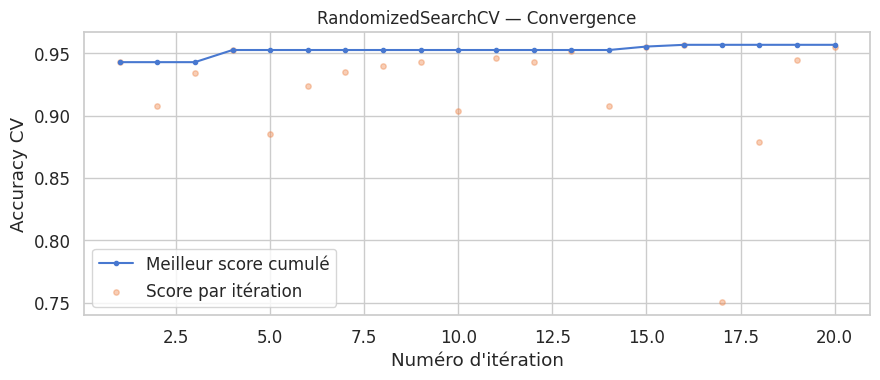
Recherche aléatoire (RandomizedSearchCV)#
Définition 132 (Recherche aléatoire)
La recherche aléatoire (randomized search) échantillonne \(N\) combinaisons d’hyperparamètres aléatoirement à partir de distributions spécifiées par l’utilisateur, plutôt que d’explorer une grille exhaustive. Si \(\Lambda\) est l’espace des hyperparamètres et \(p(\lambda)\) la distribution d’échantillonnage :
Proposition 34 (Avantage de la recherche aléatoire (Bergstra & Bengio, 2012))
Pour un budget de calcul fixe \(N\), la recherche aléatoire est souvent plus efficace que la recherche par grille car :
Elle explore un plus grand nombre de valeurs distinctes pour chaque hyperparamètre.
Si certains hyperparamètres sont plus importants que d’autres, la grille gaspille des évaluations sur les dimensions peu influentes.
Avec \(N\) tirages, la probabilité de trouver un point dans les \(5\,\%\) meilleurs de l’espace est \(1 - 0{,}95^N \approx 0{,}99\) pour \(N \geq 60\).
Meilleurs hyperparamètres : {'max_depth': 15, 'max_features': 'sqrt', 'min_samples_leaf': 1, 'min_samples_split': 8, 'n_estimators': 58}
Meilleur score CV : 0.9569
Score sur le test : 0.9667
Recherche bayésienne#
Définition 133 (Optimisation bayésienne des hyperparamètres)
L”optimisation bayésienne modélise la fonction objectif \(f(\lambda) = \hat{R}_{\text{CV}}(\hat{f}_\lambda)\) par un modèle substitut (surrogate model), typiquement un processus gaussien ou un modèle de type Tree-structured Parzen Estimator (TPE). À chaque itération, le modèle substitut est utilisé pour choisir le prochain point \(\lambda\) à évaluer via une fonction d’acquisition (Expected Improvement, Upper Confidence Bound, etc.) qui équilibre exploration et exploitation.
Remarque 124
L’optimisation bayésienne est plus efficace que les recherches par grille ou aléatoire lorsque l’évaluation de \(f(\lambda)\) est coûteuse (entraînement long, grands jeux de données). Plusieurs bibliothèques implémentent cette approche :
Optuna : framework flexible avec pruning automatique des essais peu prometteurs.
scikit-optimize (
skopt) : intégration avec scikit-learn viaBayesSearchCV.Hyperopt : optimisation basée sur TPE.
L’installation se fait via pip install optuna ou pip install scikit-optimize.
Exemple 11 (Recherche bayésienne avec Optuna)
Voici un exemple de structure typique avec Optuna (non exécuté ici pour éviter la dépendance) :
import optuna
def objective(trial):
C = trial.suggest_float('C', 1e-3, 1e3, log=True)
gamma = trial.suggest_float('gamma', 1e-4, 1e1, log=True)
clf = SVC(C=C, gamma=gamma, kernel='rbf')
score = cross_val_score(clf, X_train, y_train, cv=5).mean()
return score
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=100)
print(study.best_params)
L’avantage d’Optuna est sa capacité à pruner les essais peu prometteurs dès les premières époques, économisant ainsi du temps de calcul.
Comparaison de modèles#
Une fois plusieurs modèles entraînés et évalués par validation croisée, il est tentant de simplement choisir celui avec le meilleur score moyen. Cependant, les scores de CV sont des variables aléatoires : une différence observée peut être due au hasard. Des tests statistiques permettent de déterminer si les différences sont significatives.
Comparaison de deux modèles#
Définition 134 (Test \(t\) apparié sur les plis)
Pour comparer deux modèles \(A\) et \(B\) évalués sur les mêmes \(k\) plis, on considère les différences de performance \(d_j = R_j^A - R_j^B\) pour \(j = 1, \ldots, k\). Sous l’hypothèse nulle \(H_0 : \mu_d = 0\) (les deux modèles ont la même performance), la statistique
suit approximativement une loi de Student à \(k - 1\) degrés de liberté, où \(\bar{d}\) et \(s_d\) sont la moyenne et l’écart-type des différences.
Remarque 125
Le test \(t\) apparié classique sous-estime la variance car les ensembles d’entraînement des différents plis se chevauchent. Le test \(t\) corrigé de Nadeau et Bengio (2003) corrige ce biais en ajustant la variance :
où \(n_{\text{test}}\) et \(n_{\text{train}}\) sont les tailles des ensembles de test et d’entraînement dans chaque pli.
Logistic Regression : 0.9661 ± 0.0076
KNN (k=5) : 0.9861 ± 0.0109
Decision Tree : 0.8648 ± 0.0251
Random Forest : 0.9789 ± 0.0078
SVM (RBF) : 0.9889 ± 0.0071
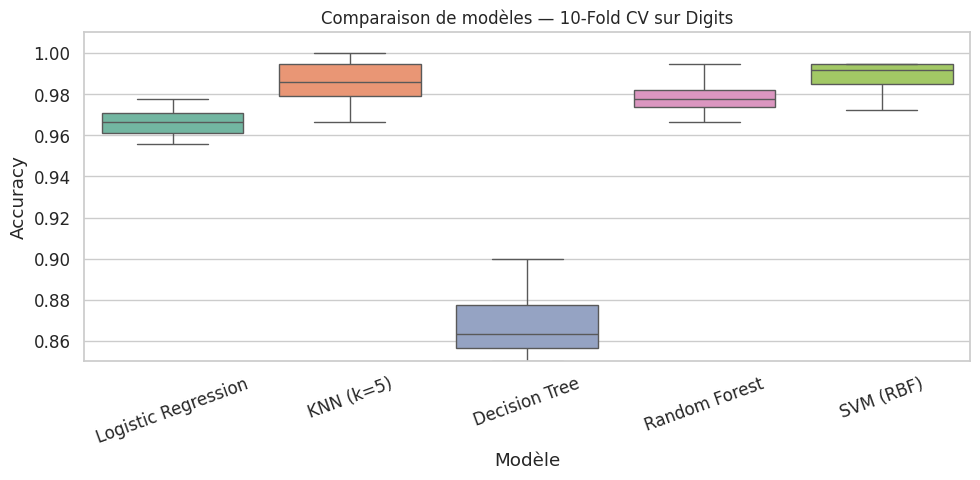
Comparaison multiple#
Définition 135 (Test de Friedman)
Le test de Friedman est un test non paramétrique utilisé pour comparer \(m\) modèles évalués sur \(k\) plis. Pour chaque pli, les modèles sont classés par rang. Sous l’hypothèse nulle (tous les modèles ont la même performance), la statistique de Friedman
suit approximativement une loi \(\chi^2\) à \(m - 1\) degrés de liberté, où \(R_j\) est le rang moyen du modèle \(j\).
Remarque 126
Si le test de Friedman rejette \(H_0\), on procède à des comparaisons post-hoc pour identifier quelles paires de modèles diffèrent significativement. Le test de Nemenyi est le pendant non paramétrique du test de Tukey HSD. Deux modèles sont significativement différents si la différence de leurs rangs moyens dépasse la distance critique :
où \(q_\alpha\) est la valeur critique de la distribution de l’étendue studentisée.
Test de Friedman : statistique = 32.27, p-value = 1.6830e-06
→ On rejette H0 : au moins un modèle diffère significativement.
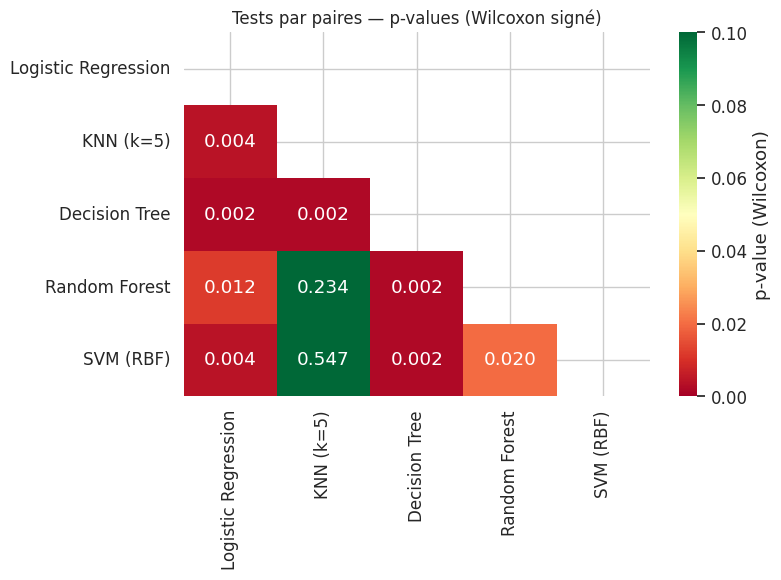
Remarque 127
Lorsqu’on effectue de multiples comparaisons, le risque de faux positifs augmente. Il faut appliquer une correction de Bonferroni ou une correction de Holm pour maintenir le taux d’erreur global au niveau souhaité. Avec \(m\) modèles, on effectue \(\binom{m}{2}\) comparaisons, et le seuil corrigé par Bonferroni est \(\alpha / \binom{m}{2}\).
Sélection de modèles : pipeline complet#
Le problème de la fuite de données#
Définition 136 (Fuite de données)
La fuite de données (data leakage) se produit lorsque de l’information provenant de l’ensemble de test influence le processus d’entraînement ou de sélection du modèle. Les formes les plus courantes sont :
Prétraitement (scaling, imputation) ajusté sur l’ensemble complet avant la séparation train/test.
Sélection d’hyperparamètres évaluée sur les mêmes données que l’évaluation finale.
Sélection de features basée sur la cible avant la séparation.
Pour éviter la fuite de données lors de la sélection d’hyperparamètres, il faut utiliser la validation croisée imbriquée (nested cross-validation).
Validation croisée imbriquée#
Définition 137 (Validation croisée imbriquée)
La validation croisée imbriquée (nested CV) utilise deux boucles de CV :
La boucle externe (\(k_{\text{ext}}\) plis) estime la performance de généralisation du processus complet (sélection d’hyperparamètres + entraînement).
La boucle interne (\(k_{\text{int}}\) plis) sélectionne les meilleurs hyperparamètres pour chaque pli externe.
Pour chaque pli externe \(j\) :
Séparer \(\mathcal{D}_{\text{train}}^{(j)}\) (entraînement) et \(\mathcal{D}_{\text{test}}^{(j)}\) (test).
Sur \(\mathcal{D}_{\text{train}}^{(j)}\), exécuter une recherche d’hyperparamètres par CV interne (\(k_{\text{int}}\) plis).
Réentraîner le modèle avec les meilleurs hyperparamètres sur \(\mathcal{D}_{\text{train}}^{(j)}\) complet.
Évaluer sur \(\mathcal{D}_{\text{test}}^{(j)}\).
Le score final est la moyenne des scores des \(k_{\text{ext}}\) plis externes.
Remarque 128
La CV imbriquée fournit une estimation non biaisée de la performance de généralisation du processus de sélection de modèle. Sans elle, la sélection d’hyperparamètres utilise (indirectement) les données de test via la CV, ce qui conduit à un optimisme de sélection (selection bias) : le score CV surestime légèrement la vraie performance.
Nested Cross-Validation (5 plis externes × 3 plis internes)
============================================================
Logistic Regression : 0.9711 ± 0.0037 (plis : [0.9694 0.9667 0.9777 0.9721 0.9694])
Random Forest : 0.9783 ± 0.0054 (plis : [0.9861 0.975 0.9721 0.9833 0.9749])
SVM : 0.9850 ± 0.0060 (plis : [0.9778 0.9944 0.9889 0.9833 0.9805])
Comparaison : CV simple vs Nested CV
============================================================
Logistic Regression : CV simple = 0.9254, Nested CV = 0.9711, Δ = -0.0456
Random Forest : CV simple = 0.9410, Nested CV = 0.9783, Δ = -0.0373
SVM : CV simple = 0.9560, Nested CV = 0.9850, Δ = -0.0289
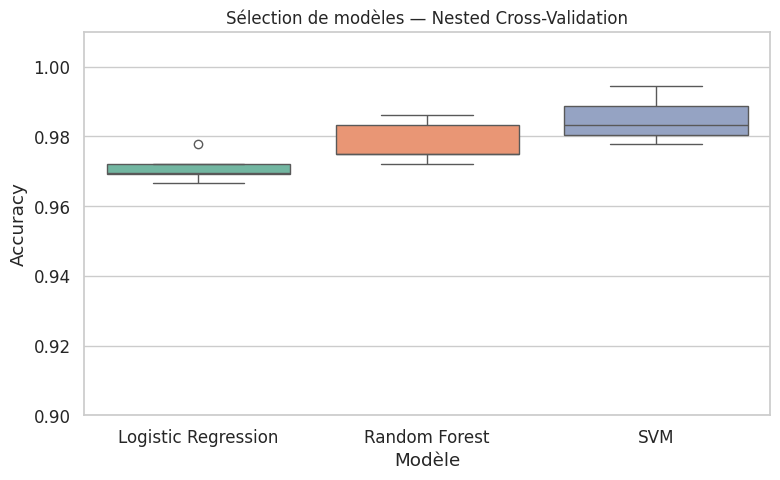
Pipeline de sélection complet#
Proposition 35 (Protocole de sélection de modèles)
Un protocole rigoureux de sélection de modèles suit les étapes suivantes :
Séparation initiale : réserver un ensemble de test final (holdout) qui ne sera utilisé qu’une seule fois, à la toute fin.
Définition des candidats : identifier les familles de modèles et leurs espaces d’hyperparamètres.
Nested CV : pour chaque candidat, estimer la performance de généralisation par validation croisée imbriquée sur l’ensemble d’entraînement.
Sélection : choisir le modèle (famille + stratégie de recherche d’hyperparamètres) ayant le meilleur score nested CV.
Réentraînement final : réentraîner le modèle sélectionné (avec recherche d’hyperparamètres par CV) sur l’intégralité de l’ensemble d’entraînement.
Évaluation finale : évaluer une unique fois sur l’ensemble de test réservé. Ce score est l’estimation la plus honnête de la performance en production.
Ce protocole garantit qu’aucune information de l’ensemble de test n’a influencé les décisions de modélisation.
Ensemble d'entraînement : 1527 exemples
Ensemble de test final : 270 exemples
Meilleurs hyperparamètres : {'clf__C': 1, 'clf__gamma': 'scale'}
Score CV interne : 0.9830
==================================================
SCORE FINAL SUR LE TEST : 0.9667
==================================================
Résumé#
Ce chapitre a couvert les outils essentiels pour évaluer et sélectionner des modèles d’apprentissage automatique de manière rigoureuse :
La décomposition biais-variance fournit le cadre théorique : l’erreur de généralisation est la somme du biais au carré, de la variance et du bruit irréductible. Le choix de la complexité du modèle est un compromis entre ces deux premiers termes.
La validation croisée (holdout, \(k\)-fold, stratifiée, LOO) estime l’erreur de généralisation sans gaspiller de données. La CV stratifiée à 5 ou 10 plis est le choix par défaut.
Les courbes d’apprentissage diagnostiquent visuellement le biais et la variance en traçant les erreurs d’entraînement et de validation en fonction de la taille des données.
La recherche d’hyperparamètres (grille, aléatoire, bayésienne) optimise les paramètres non appris du modèle. La recherche aléatoire est souvent préférable à la grille pour un budget fixe.
La comparaison statistique de modèles (test \(t\) apparié, test de Friedman, test de Nemenyi) garantit que les différences observées ne sont pas dues au hasard.
La validation croisée imbriquée fournit une estimation non biaisée de la performance du processus complet de sélection de modèle, évitant la fuite de données.
Remarque 129
L’évaluation n’est pas une étape finale mais un processus itératif. Les résultats de l’évaluation guident le choix du modèle, du prétraitement et des hyperparamètres. Un bon praticien consacre autant de soin à l’évaluation qu’à la modélisation elle-même.