
Prétraitement#
Garbage in, garbage out.
Proverbe informatique
Le prétraitement des données est l’étape la plus importante et souvent la plus chronophage d’un projet d’apprentissage automatique. Un modèle, aussi sophistiqué soit-il, ne peut compenser des données mal préparées. Ce chapitre couvre les transformations essentielles qui précèdent la modélisation : mise à l’échelle, encodage, ingénierie de features, sélection de variables, composition de pipelines, gestion du déséquilibre de classes et transformation de la variable cible.
Mise à l’échelle des features#
De nombreux algorithmes (régression linéaire régularisée, SVM, KNN, réseaux de neurones) sont sensibles à l’échelle des variables. Une feature exprimée en milliers (comme un salaire) dominera une feature comprise entre 0 et 1 (comme un taux). La mise à l’échelle (scaling) uniformise les plages de valeurs.
Standardisation (z-score)#
Définition 33 (Standardisation)
Soit \(\mathbf{x} = (x_1, \ldots, x_n)\) les valeurs d’une feature. La standardisation (ou z-score normalization) transforme chaque valeur en
où \(\bar{x} = \frac{1}{n}\sum_{i=1}^n x_i\) est la moyenne empirique et \(s = \sqrt{\frac{1}{n-1}\sum_{i=1}^n (x_i - \bar{x})^2}\) est l’écart-type empirique corrigé.
La feature transformée a une moyenne nulle et un écart-type unitaire.
Remarque 34
La standardisation ne rend pas la distribution gaussienne. Elle ne fait que centrer et réduire. Si la distribution originale est asymétrique ou contient des valeurs aberrantes, elles le resteront après transformation.
Moyenne avant : [2.e+03 3.e-01]
Écart-type avant : [7.90569415e+02 1.58113883e-01]
Moyenne après : [0. 0.]
Écart-type après : [1.118 1.118]
Normalisation Min-Max#
Définition 34 (Normalisation Min-Max)
La normalisation Min-Max projette les valeurs dans l’intervalle \([0, 1]\) :
Plus généralement, pour un intervalle cible \([a, b]\) :
Remarque 35
La normalisation Min-Max est très sensible aux valeurs aberrantes : un seul outlier peut écraser toutes les autres valeurs dans une plage étroite. Elle est préférable lorsque les données sont bornées et n’ont pas d’outliers significatifs.
Min après : [0. 0.]
Max après : [1. 1.]
Données transformées :
[[0. 0. ]
[0.5 0.5 ]
[0.25 0.25]
[1. 1. ]
[0.75 0.75]]
Mise à l’échelle robuste#
Définition 35 (Mise à l’échelle robuste)
La mise à l’échelle robuste (robust scaling) utilise la médiane et l’écart interquartile (IQR) :
où \(\text{med}(\mathbf{x})\) est la médiane, \(Q_1\) le premier quartile et \(Q_3\) le troisième quartile.
Remarque 36
Cette méthode est préférable lorsque le jeu de données contient des valeurs aberrantes, car la médiane et l’IQR sont des statistiques robustes (leur point de rupture est de 25 %, contre 0 % pour la moyenne et l’écart-type).
RobustScaler : [-1. -0.5 0. 0.5 48. ]
StandardScaler : [-0.54 -0.51 -0.49 -0.46 2. ]
Proposition 6 (Choix de la méthode de mise à l’échelle)
StandardScaler : choix par défaut, adapté aux distributions approximativement gaussiennes
MinMaxScaler : utile pour les réseaux de neurones et lorsque les bornes sont connues
RobustScaler : en présence de valeurs aberrantes
Dans tous les cas, le scaler doit être ajusté (fit) uniquement sur les données d’entraînement, puis appliqué (transform) aux données de test. C’est une source fréquente de fuite de données (data leakage).
Encodage des variables catégorielles#
Les algorithmes de machine learning travaillent avec des valeurs numériques. Les variables catégorielles (couleur, pays, catégorie de produit) doivent être converties en représentations numériques.
Label Encoding#
Définition 36 (Label Encoding)
Le label encoding attribue un entier unique à chaque catégorie :
où \(\mathcal{C}\) est l’ensemble des catégories.
Remarque 37
Le label encoding introduit un ordre artificiel entre les catégories. Le modèle pourra interpréter \(\text{rouge} = 0 < \text{bleu} = 1 < \text{vert} = 2\) comme une relation d’ordre, ce qui est incorrect pour une variable nominale. Il est adapté aux variables ordinales (petit < moyen < grand) et aux arbres de décision (qui ne sont pas sensibles à l’ordre).
Encodé : [1 0 2 0 1]
Classes : ['bleu' 'rouge' 'vert']
Encodage ordinal#
Définition 37 (Encodage ordinal)
L”encodage ordinal est un label encoding dans lequel l’ordre des entiers respecte un ordre naturel entre les catégories. On spécifie explicitement la correspondance
Encodé : [1. 2. 0. 2. 1.]
One-Hot Encoding#
Définition 38 (One-Hot Encoding)
Le one-hot encoding représente une variable catégorielle à \(k\) modalités par \(k\) variables binaires (ou \(k - 1\) pour éviter la multicolinéarité). Pour une catégorie \(c_j\) :
Remarque 38
Le one-hot encoding est le choix standard pour les variables nominales (sans ordre) avec un nombre raisonnable de modalités. Lorsque la cardinalité est élevée (\(k > 50\)), la dimension explose et d’autres méthodes sont préférables (target encoding, hashing).
x0_Lyon x0_Marseille x0_Paris
0 0.0 0.0 1.0
1 1.0 0.0 0.0
2 0.0 1.0 0.0
3 1.0 0.0 0.0
4 0.0 0.0 1.0
Target Encoding#
Définition 39 (Target Encoding)
Le target encoding (ou mean encoding) remplace chaque catégorie par la moyenne de la variable cible conditionnellement à cette catégorie :
où \(n_c\) est le nombre d’observations de la catégorie \(c\).
Remarque 39
Le target encoding est puissant pour les variables à haute cardinalité, mais il comporte un risque élevé de fuite de données (target leakage). En pratique, on utilise une régularisation (lissage bayésien) ou une validation croisée interne pour atténuer l’overfitting.
Catégories : ['A' 'B' 'A' 'C' 'B' 'A' 'C' 'C' 'A' 'B' 'C' 'A' 'B' 'C' 'A' 'B']
Cible : [10 20 12 30 22 11 28 32 13 19 27 14 21 31 9 18]
Encodé : [11.63 19.34 10.82 29.36 19.34 10.82 30.96 28.23 11.63 21. 30.96 10.82
19.74 28.23 12.05 21. ]
Proposition 7 (Choix de l’encodage)
Type de variable |
Méthode recommandée |
|---|---|
Ordinale (ordre naturel) |
OrdinalEncoder |
Nominale, faible cardinalité (\(k \leq 15\)) |
OneHotEncoder |
Nominale, haute cardinalité (\(k > 15\)) |
TargetEncoder |
Cible d’un classificateur |
LabelEncoder |
Arbre de décision (toute catégorielle) |
OrdinalEncoder (les arbres gèrent l’ordre) |
Feature engineering#
Le feature engineering consiste à créer de nouvelles variables à partir des variables existantes. C’est souvent ce qui fait la différence entre un modèle médiocre et un modèle performant.
Interactions entre features#
Définition 40 (Feature d’interaction)
Soit \(x_j\) et \(x_k\) deux features. Une feature d’interaction est le produit \(x_j \cdot x_k\). Plus généralement, pour un degré \(d\), on considère les monômes \(x_{j_1}^{a_1} \cdots x_{j_p}^{a_p}\) avec \(a_1 + \cdots + a_p \leq d\).
Exemple 4
Pour prédire le prix d’un appartement, la surface \(s\) et le nombre de pièces \(p\) sont informatifs séparément. Mais le ratio \(s/p\) (surface par pièce) capture une information que ni \(s\) ni \(p\) seul ne contient : des pièces trop petites ou anormalement grandes.
Transformations polynomiales#
Définition 41 (Features polynomiales)
Soit \(\mathbf{x} = (x_1, \ldots, x_p)\) un vecteur de features. La transformation polynomiale de degré \(d\) génère tous les monômes de degré \(\leq d\) :
Le nombre de features générées est \(\binom{p + d}{d}\).
Remarque 40
Les features polynomiales permettent à un modèle linéaire de capturer des relations non linéaires. Toutefois, le nombre de features croît de manière combinatoire avec \(d\) et \(p\) : pour \(p = 10\) features et un degré \(d = 3\), on obtient \(\binom{13}{3} = 286\) features. La régularisation devient alors indispensable.
Features originales : 2
Features générées : 5
Noms : ['x0' 'x1' 'x0^2' 'x0 x1' 'x1^2']
[[ 2. 3. 4. 6. 9.]
[ 1. 4. 1. 4. 16.]
[ 5. 2. 25. 10. 4.]]
Discrétisation (binning)#
Définition 42 (Discrétisation)
La discrétisation (ou binning) transforme une variable continue en variable catégorielle en partitionnant son domaine en intervalles (bins) :
Les bornes \(b_0 < b_1 < \cdots < b_K\) définissent \(K\) intervalles.
Remarque 41
La discrétisation est utile pour capturer des relations non linéaires avec des modèles linéaires, réduire l’impact des outliers, et rendre le modèle plus interprétable. En revanche, elle détruit de l’information : deux valeurs proches d’une frontière de bin peuvent se retrouver dans des catégories différentes.
Bornes des bins : ['18', '30', '48', '70', '81']
Âges : [18 25 35 42 55 67 73 81]
Bins : [0 0 1 1 2 2 3 3]
Sélection de features#
Réduire le nombre de features améliore l’interprétabilité, réduit l’overfitting, et accélère l’entraînement. On distingue trois familles de méthodes.
Méthodes par filtre#
Définition 43 (Sélection par filtre)
Les méthodes par filtre (filter methods) évaluent chaque feature indépendamment du modèle, à l’aide d’un critère statistique :
Seuil de variance : on élimine les features dont la variance est inférieure à un seuil \(\tau\)
Corrélation avec la cible : on sélectionne les features les plus corrélées (Pearson, Spearman, information mutuelle)
Test statistique : chi-deux pour les variables catégorielles, ANOVA F-test pour les variables continues
Variance : 10 -> 10 features
SelectKBest : 10 -> 5 features
Features sélectionnées : [1 3 4 6 9]
Scores F : [ 0.21 49.15 1.56 150.98 1.98 0.43 28.1 0.21 1.14 83.79]
Méthodes wrapper#
Définition 44 (Sélection wrapper)
Les méthodes wrapper évaluent des sous-ensembles de features en entraînant un modèle. Elles sont plus coûteuses mais tiennent compte des interactions entre variables :
Forward selection : on part de zéro et on ajoute les features une à une
Backward elimination : on part de toutes les features et on les retire une à une
Recursive Feature Elimination (RFE) : on entraîne le modèle, on élimine la feature la moins importante, et on itère
RFE : 10 -> 5 features
Features sélectionnées : [1 2 3 6 9]
Classement : [3 1 1 1 5 4 1 2 6 1]
Méthodes embarquées#
Définition 45 (Sélection embarquée)
Les méthodes embarquées (embedded methods) intègrent la sélection directement dans le processus d’apprentissage :
Régularisation L1 (Lasso) : la pénalité \(\lambda \|\boldsymbol{\beta}\|_1\) pousse certains coefficients exactement à zéro, éliminant les features correspondantes
Importance des features dans les arbres et forêts aléatoires
Proposition 8 (Sélection par Lasso)
Le problème Lasso s’écrit
Les features \(j\) telles que \(\hat{\beta}_j = 0\) sont éliminées. Le paramètre \(\lambda\) contrôle la parcimonie : plus \(\lambda\) est grand, plus de coefficients sont mis à zéro.
Lasso : 10 -> 2 features
Coefficients : [ 0. 0. 0. 0.168 0. 0. 0. -0. 0. -0.099]
Features retenues : [3 9]
Pipelines Scikit-learn#
En pratique, le prétraitement consiste en une chaîne de transformations. Les pipelines de Scikit-learn permettent de composer ces étapes de manière reproductible et compatible avec la validation croisée.
Pipeline#
Définition 46 (Pipeline)
Un Pipeline est une séquence ordonnée d’étapes \((\text{nom}_1, T_1), \ldots, (\text{nom}_k, T_k), (\text{nom}_{k+1}, M)\) où \(T_1, \ldots, T_k\) sont des transformateurs et \(M\) est un estimateur final. L’appel à fit ajuste toutes les étapes séquentiellement, et predict applique les transformations puis la prédiction.
Pipeline explicite — Accuracy : 0.807 (+/- 0.023)
make_pipeline — Accuracy : 0.807 (+/- 0.023)
ColumnTransformer#
Définition 47 (ColumnTransformer)
Le ColumnTransformer applique des transformations différentes à des sous-ensembles de colonnes, puis concatène les résultats. Il est indispensable lorsque le jeu de données contient à la fois des variables numériques et catégorielles.
Pipeline mixte — Accuracy : 0.970 (+/- 0.024)
Remarque 42
Le pipeline garantit que le prétraitement est ajusté uniquement sur les données d’entraînement à chaque fold de la validation croisée. Sans pipeline, on risque une fuite de données : le scaler verrait les statistiques du test set, biaisant l’évaluation à la hausse.
Composition avancée#
Pipeline complet — Accuracy : 0.960 (+/- 0.020)
Gestion du déséquilibre de classes#
Dans de nombreux problèmes réels (fraude, diagnostic médical, détection d’anomalies), la classe positive est très minoritaire. Un classifieur naïf qui prédit toujours la classe majoritaire obtient une accuracy élevée mais est inutile. Plusieurs stratégies existent.
Pondération des classes#
Définition 48 (Pondération des classes)
Le paramètre class_weight='balanced' ajuste le poids de chaque classe inversement proportionnellement à sa fréquence :
où \(n\) est le nombre total d’échantillons, \(k\) le nombre de classes et \(n_c\) le nombre d’échantillons de la classe \(c\). Ainsi, la classe minoritaire reçoit un poids plus élevé dans la fonction de coût.
Répartition : classe 0 = 946, classe 1 = 54
Sans pondération — F1 : 0.190
Avec class_weight='balanced' — F1 : 0.261
Rééchantillonnage#
Définition 49 (SMOTE)
Le Synthetic Minority Oversampling Technique (SMOTE) génère des exemples synthétiques de la classe minoritaire. Pour chaque exemple minoritaire \(\mathbf{x}_i\) :
On identifie ses \(k\) plus proches voisins dans la classe minoritaire
On choisit aléatoirement un voisin \(\mathbf{x}_j\)
On crée un point synthétique \(\mathbf{x}_{\text{new}} = \mathbf{x}_i + \lambda (\mathbf{x}_j - \mathbf{x}_i)\) où \(\lambda \sim \mathcal{U}(0, 1)\)
Remarque 43
SMOTE ne doit être appliqué que sur les données d’entraînement, jamais sur le test set. L’utilisation dans un pipeline avec imblearn garantit cette contrainte. Le sous-échantillonnage (undersampling) de la classe majoritaire est une alternative plus simple mais qui perd de l’information.
Proposition 9 (Stratégies de rééchantillonnage)
Méthode |
Principe |
Avantage |
Inconvénient |
|---|---|---|---|
SMOTE |
Suréchan. par interpolation |
Pas de perte d’information |
Peut créer du bruit |
RandomOverSampler |
Duplication aléatoire |
Simple |
Risque d’overfitting |
RandomUnderSampler |
Suppression aléatoire |
Réduit le temps d’entraînement |
Perte d’information |
class_weight |
Pondération de la loss |
Aucune modification des données |
Effet parfois insuffisant |
Transformation de la cible#
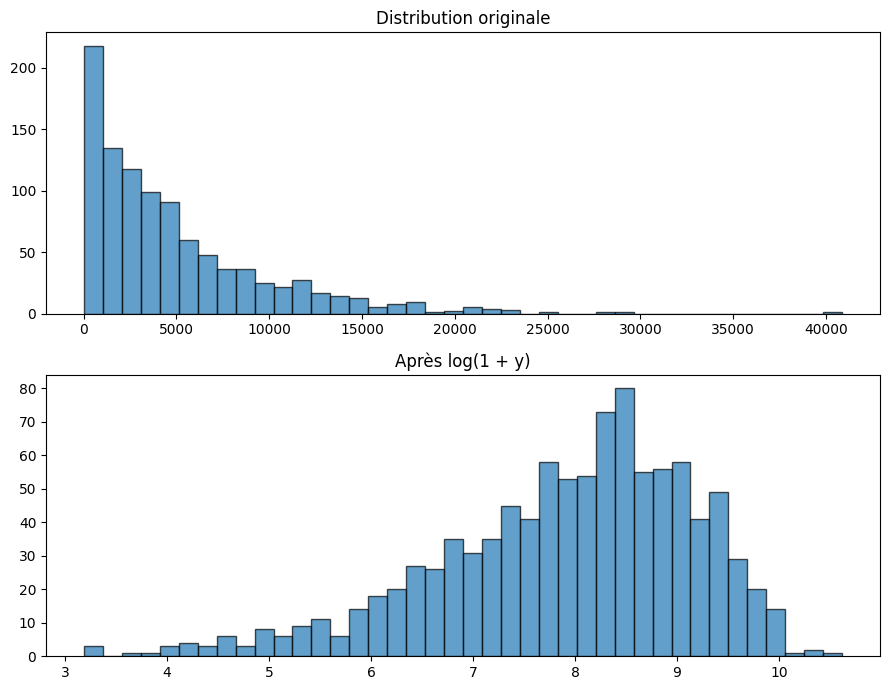
Lorsque la variable cible \(y\) a une distribution très asymétrique (revenus, prix immobiliers, comptages), transformer \(y\) avant l’entraînement peut améliorer significativement les performances d’un modèle linéaire.
Transformation logarithmique#
Définition 50 (Transformation logarithmique)
Pour une cible strictement positive \(y > 0\), la transformation logarithmique est
On entraîne le modèle sur \(y'\), puis on inverse la prédiction : \(\hat{y} = \exp(\hat{y}')\).
Pour gérer les valeurs nulles, on utilise \(y' = \ln(1 + y)\).
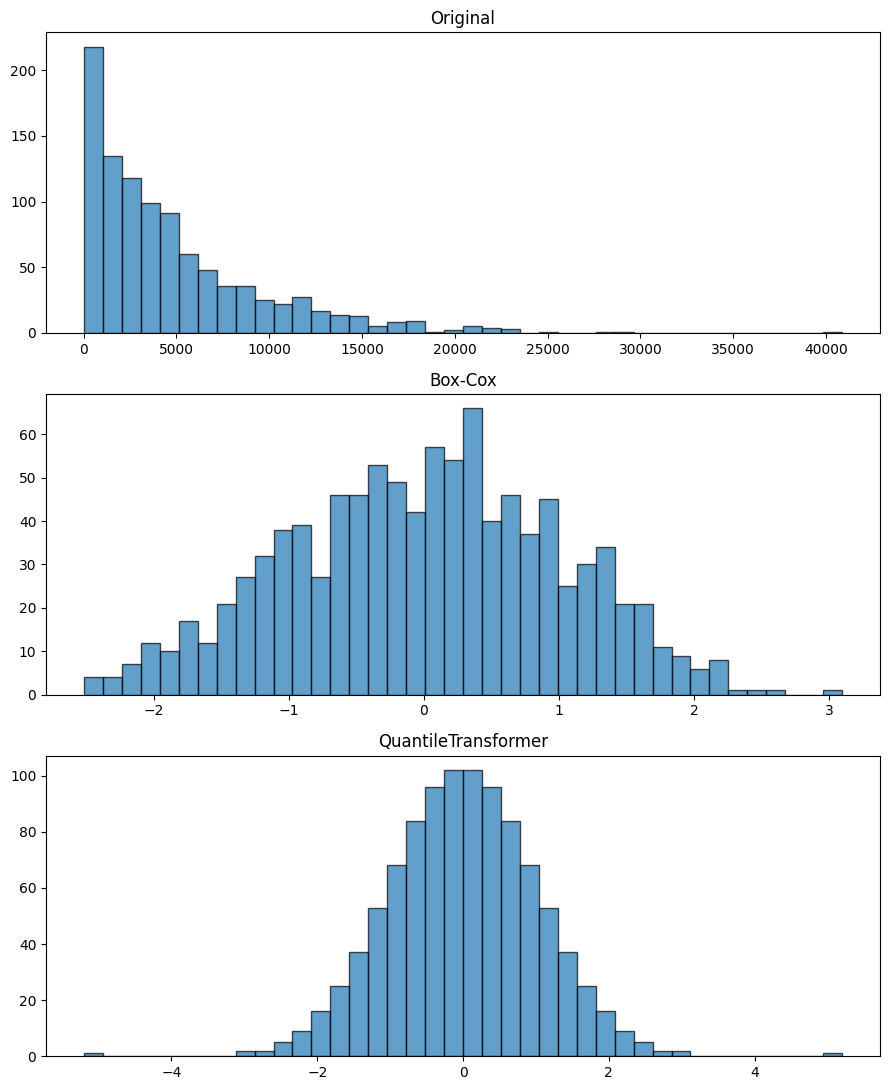
Transformation de Box-Cox#
Définition 51 (Transformation de Box-Cox)
La transformation de Box-Cox est une famille paramétrée de transformations, définie pour \(y > 0\) :
Le paramètre \(\lambda\) est choisi par maximum de vraisemblance pour rendre la distribution de \(y^{(\lambda)}\) aussi proche que possible d’une gaussienne.
Remarque 44
Box-Cox nécessite \(y > 0\). Pour des données pouvant être nulles ou négatives, on utilise la transformation de Yeo-Johnson, qui généralise Box-Cox à \(\mathbb{R}\) tout entier.
QuantileTransformer#
Définition 52 (Transformation par quantiles)
Le QuantileTransformer transforme chaque feature (ou la cible) pour que sa distribution empirique suive une loi uniforme ou une loi normale. Il utilise la fonction de répartition empirique :
où \(\hat{F}\) est la CDF empirique et \(\Phi^{-1}\) est la fonction quantile de la loi cible (normale standard si output_distribution='normal').
Remarque 45
Pour transformer la cible dans un pipeline Scikit-learn, on utilise TransformedTargetRegressor, qui applique la transformation à \(y\) lors du fit et l’inversion lors du predict.
Sans transformation — R² : -2.456
Avec log-transform — R² : 0.298
Résumé#
Le prétraitement est rarement linéaire : le bon pipeline dépend de la nature des données et du modèle. En règle générale :
Étape |
Outils principaux |
|---|---|
Mise à l’échelle |
|
Encodage |
|
Feature engineering |
|
Sélection |
|
Composition |
|
Déséquilibre |
|
Transformation cible |
|
Remarque 46
Le prétraitement fait partie intégrante du modèle. Il doit être intégré dans un pipeline et soumis à la validation croisée au même titre que les hyperparamètres de l’estimateur. Toute transformation ajustée sur les données d’entraînement doit être appliquée telle quelle aux données de test, sans recalcul des paramètres.