
Régression linéaire#
Tous les modèles sont faux, mais certains sont utiles.
George E. P. Box
La régression linéaire est le modèle le plus fondamental de l’apprentissage supervisé. Malgré sa simplicité apparente, elle constitue la pierre angulaire sur laquelle reposent de nombreuses méthodes plus élaborées. Ce chapitre présente la régression linéaire simple et multiple, ses hypothèses, les méthodes de diagnostic, la régularisation et les métriques d’évaluation, le tout illustré par un exemple complet avec Scikit-learn.
Introduction#
En apprentissage supervisé, on distingue deux grandes familles de problèmes selon la nature de la variable cible \(y\) :
Régression : la variable cible est continue (prix d’un bien immobilier, température, chiffre d’affaires).
Classification : la variable cible est discrète (catégorie d’un email : spam ou non, espèce d’une fleur).
La régression cherche à modéliser la relation entre une ou plusieurs variables explicatives \(x_1, \ldots, x_p\) et une variable cible \(y \in \mathbb{R}\). Le modèle le plus simple pour exprimer cette relation est le modèle linéaire.
Remarque 47
La régression linéaire ne se limite pas aux relations « en ligne droite ». Grâce aux transformations polynomiales, aux interactions et aux fonctions de base, un modèle linéaire dans ses paramètres peut capturer des relations fortement non linéaires dans l’espace des features. La linéarité du modèle porte sur les coefficients \(\boldsymbol{\beta}\), pas sur les variables d’entrée.
Régression linéaire simple#
La régression linéaire simple modélise la relation entre une variable explicative \(x\) et une variable cible \(y\).
Le modèle#
Définition 53 (Modèle de régression linéaire simple)
Soit \((x_1, y_1), \ldots, (x_n, y_n)\) un échantillon de \(n\) observations. Le modèle de régression linéaire simple postule que
où :
\(\beta_0 \in \mathbb{R}\) est l”ordonnée à l’origine (intercept) : la valeur prédite de \(y\) lorsque \(x = 0\)
\(\beta_1 \in \mathbb{R}\) est la pente : la variation de \(y\) associée à une augmentation unitaire de \(x\)
\(\varepsilon_i\) est le terme d’erreur (ou résidu théorique), supposé aléatoire, de moyenne nulle et de variance constante \(\sigma^2\)
Remarque 48
Le terme d’erreur \(\varepsilon_i\) capture tout ce que le modèle linéaire ne peut expliquer : l’effet de variables non incluses, le bruit de mesure, et toute non-linéarité résiduelle. C’est l’écart entre la valeur observée \(y_i\) et la valeur prédite \(\hat{y}_i = \beta_0 + \beta_1 x_i\).
Méthode des moindres carrés#
L’estimation des paramètres \(\beta_0\) et \(\beta_1\) se fait en minimisant la somme des carrés des résidus (Residual Sum of Squares, RSS).
Définition 54 (Moindres carrés ordinaires (MCO))
Les estimateurs des moindres carrés ordinaires (MCO, ou Ordinary Least Squares, OLS) sont les valeurs \(\hat{\beta}_0, \hat{\beta}_1\) qui minimisent
En annulant les dérivées partielles par rapport à \(\beta_0\) et \(\beta_1\), on obtient les formules closes :
où \(\bar{x} = \frac{1}{n}\sum_{i=1}^n x_i\) et \(\bar{y} = \frac{1}{n}\sum_{i=1}^n y_i\) sont les moyennes empiriques.
Proof. On pose \(f(\beta_0, \beta_1) = \sum_{i=1}^n (y_i - \beta_0 - \beta_1 x_i)^2\). Les conditions nécessaires d’optimalité (annulation du gradient) donnent le système :
De la première équation, on tire \(\sum y_i = n\beta_0 + \beta_1 \sum x_i\), soit \(\hat{\beta}_0 = \bar{y} - \hat{\beta}_1 \bar{x}\).
En substituant dans la seconde équation et en développant, on obtient
La matrice hessienne est définie positive (car \(\sum (x_i - \bar{x})^2 > 0\) dès que les \(x_i\) ne sont pas tous égaux), donc le point critique est bien un minimum global.
Interprétation géométrique#
Proposition 10 (Projection orthogonale)
La solution des moindres carrés \(\hat{\mathbf{y}} = \hat{\beta}_0 \mathbf{1} + \hat{\beta}_1 \mathbf{x}\) est la projection orthogonale du vecteur \(\mathbf{y} \in \mathbb{R}^n\) sur le sous-espace vectoriel \(\text{Im}(\mathbf{X})\) engendré par les colonnes de la matrice de design \(\mathbf{X} = [\mathbf{1} \mid \mathbf{x}]\).
Le vecteur des résidus \(\hat{\boldsymbol{\varepsilon}} = \mathbf{y} - \hat{\mathbf{y}}\) est orthogonal à \(\text{Im}(\mathbf{X})\) :
Autrement dit, les résidus sont orthogonaux à chaque colonne de \(\mathbf{X}\). C’est l’interprétation géométrique du théorème de la projection.
Remarque 49
Cette interprétation géométrique est fondamentale. Parmi tous les vecteurs de \(\text{Im}(\mathbf{X})\), celui qui est le plus proche de \(\mathbf{y}\) (au sens de la norme euclidienne) est la projection orthogonale \(\hat{\mathbf{y}}\). La régression linéaire par moindres carrés est donc un problème d’approximation au sens des moindres carrés dans un espace vectoriel de dimension finie.
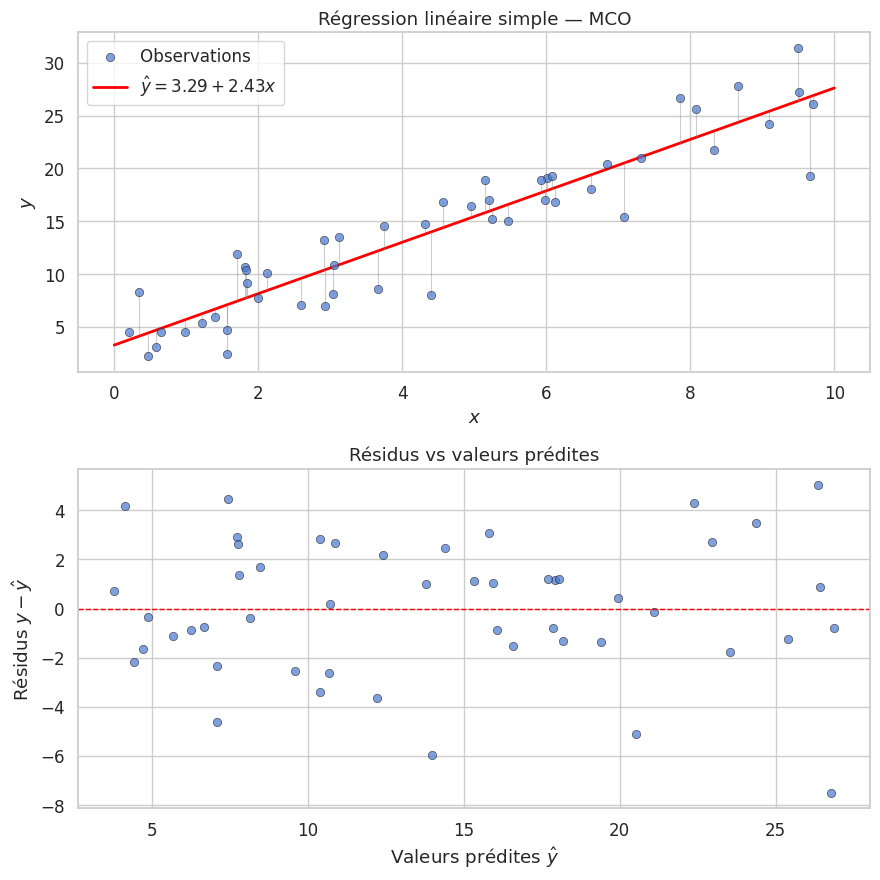
Coefficients estimés (calcul manuel) :
β₀ = 3.2901 (valeur théorique : 3)
β₁ = 2.4330 (valeur théorique : 2.5)
Régression linéaire multiple#
La régression linéaire multiple généralise le modèle simple à \(p\) variables explicatives.
Le modèle#
Définition 55 (Modèle de régression linéaire multiple)
Soit un échantillon de \(n\) observations avec \(p\) variables explicatives. Le modèle de régression linéaire multiple s’écrit
Sous forme matricielle :
où :
\(\mathbf{y} = (y_1, \ldots, y_n)^T \in \mathbb{R}^n\) est le vecteur des réponses
\(\mathbf{X} \in \mathbb{R}^{n \times (p+1)}\) est la matrice de design, dont la première colonne est un vecteur de \(1\) (pour l’intercept) et les colonnes suivantes contiennent les valeurs des variables explicatives
\(\boldsymbol{\beta} = (\beta_0, \beta_1, \ldots, \beta_p)^T \in \mathbb{R}^{p+1}\) est le vecteur des paramètres
\(\boldsymbol{\varepsilon} = (\varepsilon_1, \ldots, \varepsilon_n)^T \in \mathbb{R}^n\) est le vecteur des erreurs
Solution des moindres carrés#
Proposition 11 (Estimateur des moindres carrés (cas multiple))
Si la matrice \(\mathbf{X}^T\mathbf{X}\) est inversible (c’est-à-dire si \(\mathbf{X}\) est de rang plein \(p + 1\)), l’estimateur MCO est donné par
Le vecteur des valeurs prédites est
où \(\mathbf{H} = \mathbf{X}(\mathbf{X}^T\mathbf{X})^{-1}\mathbf{X}^T\) est la matrice chapeau (hat matrix), qui projette orthogonalement \(\mathbf{y}\) sur l’espace colonne de \(\mathbf{X}\).
Proof. On minimise \(\|\mathbf{y} - \mathbf{X}\boldsymbol{\beta}\|^2 = (\mathbf{y} - \mathbf{X}\boldsymbol{\beta})^T(\mathbf{y} - \mathbf{X}\boldsymbol{\beta})\). En développant et en dérivant par rapport à \(\boldsymbol{\beta}\) :
L’annulation du gradient donne les équations normales :
Si \(\mathbf{X}^T\mathbf{X}\) est inversible, on obtient \(\hat{\boldsymbol{\beta}} = (\mathbf{X}^T\mathbf{X})^{-1}\mathbf{X}^T\mathbf{y}\). La matrice \(\mathbf{X}^T\mathbf{X}\) est semi-définie positive ; elle est définie positive si et seulement si \(\mathbf{X}\) est de rang plein, ce qui garantit l’unicité de la solution.
Remarque 50
En pratique, on n’inverse jamais directement \(\mathbf{X}^T\mathbf{X}\) (numériquement instable et coûteux). On résout les équations normales par décomposition de Cholesky, ou mieux, on utilise la décomposition QR de \(\mathbf{X}\) : si \(\mathbf{X} = \mathbf{Q}\mathbf{R}\), alors \(\hat{\boldsymbol{\beta}} = \mathbf{R}^{-1}\mathbf{Q}^T\mathbf{y}\). Scikit-learn utilise cette approche en interne.
Coefficients estimés (calcul matriciel) :
β₀ = 2.8212 (valeur théorique : 3)
β₁ = 1.9317 (valeur théorique : 2)
β₂ = -1.2123 (valeur théorique : -1.5)
Coefficients estimés (Scikit-learn) :
intercept = 2.8212
coef = [ 1.93165494 -1.21227544]
Hypothèses du modèle#
Le modèle de régression linéaire repose sur un ensemble d’hypothèses. Leur vérification est essentielle pour s’assurer de la validité des inférences (intervalles de confiance, tests d’hypothèses) et de la qualité des prédictions.
Définition 56 (Hypothèses de Gauss-Markov)
Le modèle \(\mathbf{y} = \mathbf{X}\boldsymbol{\beta} + \boldsymbol{\varepsilon}\) repose sur les hypothèses suivantes :
Linéarité : la relation entre \(\mathbf{y}\) et \(\mathbf{X}\) est linéaire dans les paramètres \(\boldsymbol{\beta}\)
Exogénéité : \(\mathbb{E}[\boldsymbol{\varepsilon} \mid \mathbf{X}] = \mathbf{0}\) (les erreurs sont de moyenne nulle conditionnellement aux régresseurs)
Homoscédasticité : \(\text{Var}(\varepsilon_i \mid \mathbf{X}) = \sigma^2\) pour tout \(i\) (variance constante des erreurs)
Absence d’autocorrélation : \(\text{Cov}(\varepsilon_i, \varepsilon_j \mid \mathbf{X}) = 0\) pour \(i \neq j\) (indépendance des erreurs)
Rang plein : \(\text{rang}(\mathbf{X}) = p + 1\) (pas de multicolinéarité parfaite)
Sous ces hypothèses, le théorème de Gauss-Markov garantit que l’estimateur MCO est le meilleur estimateur linéaire non biaisé (Best Linear Unbiased Estimator, BLUE).
Remarque 51
On ajoute parfois une sixième hypothèse, la normalité des erreurs : \(\boldsymbol{\varepsilon} \sim \mathcal{N}(\mathbf{0}, \sigma^2 \mathbf{I}_n)\). Cette hypothèse n’est pas nécessaire pour la propriété BLUE, mais elle est requise pour construire des intervalles de confiance exacts et des tests de Student sur les coefficients.
Proposition 12 (Conséquences de la violation des hypothèses)
Hypothèse violée |
Conséquence |
|---|---|
Non-linéarité |
Biais systématique, sous-apprentissage |
Hétéroscédasticité |
MCO non optimal, erreurs standard incorrectes |
Autocorrélation |
Erreurs standard sous-estimées, tests invalides |
Multicolinéarité |
Coefficients instables, grande variance des estimateurs |
Non-normalité des résidus |
Tests et intervalles de confiance approximatifs |
Diagnostic des résidus#
Le diagnostic des résidus est la vérification a posteriori des hypothèses du modèle. On analyse les résidus \(\hat{\varepsilon}_i = y_i - \hat{y}_i\) pour détecter d’éventuelles violations.
Définition 57 (Résidus standardisés)
Les résidus standardisés (ou résidus studentisés internes) sont définis par
où \(\hat{\sigma}\) est l’estimateur de l’écart-type résiduel et \(h_{ii}\) est le \(i\)-ème élément diagonal de la matrice chapeau \(\mathbf{H}\). La correction par \(\sqrt{1 - h_{ii}}\) tient compte du fait que les résidus n’ont pas tous la même variance, même sous homoscédasticité.
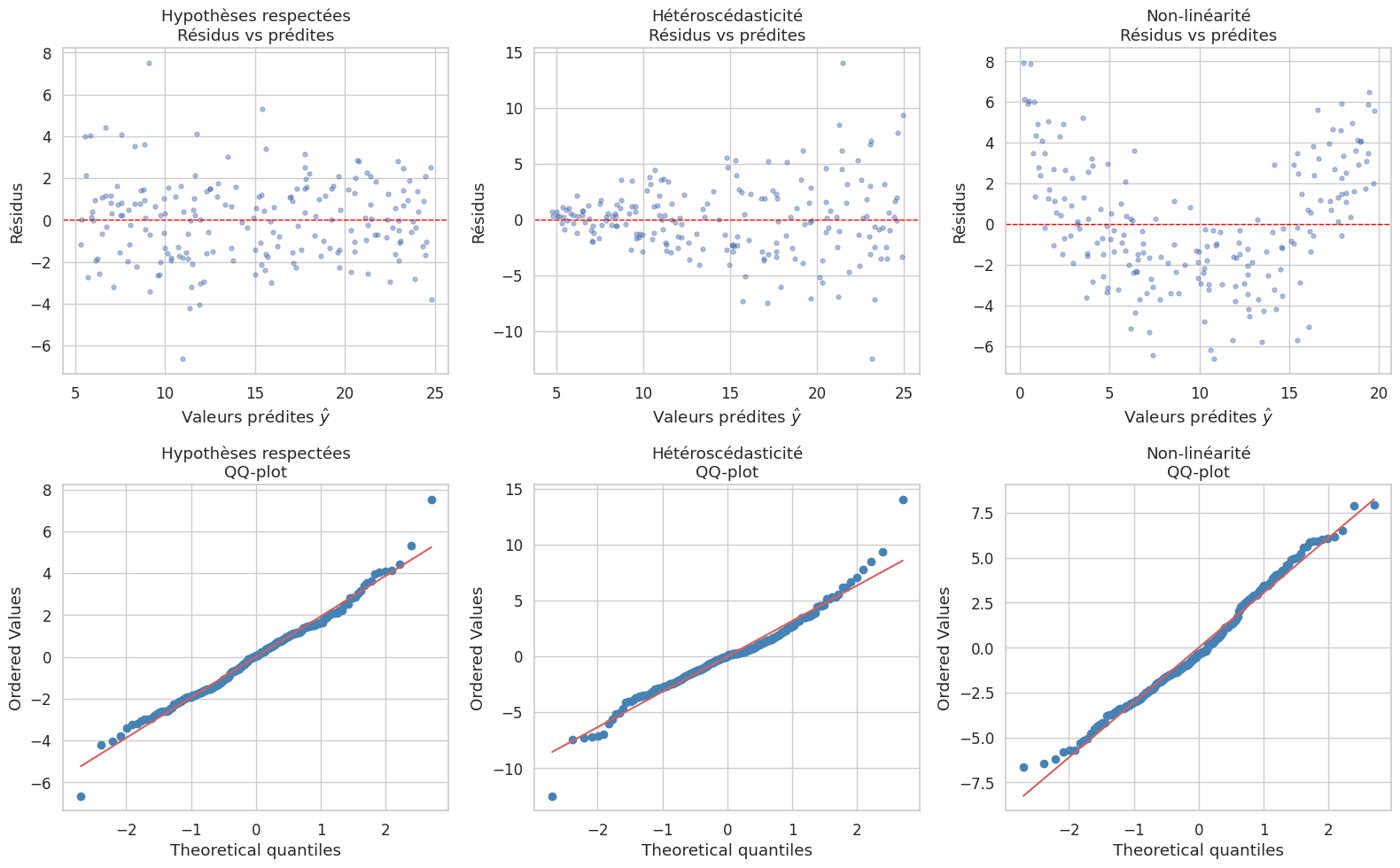
Remarque 52
Les graphiques de diagnostic se lisent comme suit :
Résidus vs prédites : on attend un nuage sans structure visible, centré sur zéro, de largeur constante. Un motif en « entonnoir » indique de l’hétéroscédasticité ; une forme en « U » ou « arc » indique de la non-linéarité.
QQ-plot : on attend un alignement sur la diagonale. Des écarts dans les queues signalent une distribution non normale (queues lourdes ou légères).
Hypothèses respectées
Shapiro-Wilk : W = 0.9879, p = 0.0862
D'Agostino-Pearson : S = 7.0282, p = 0.0298
→ Normal (Shapiro-Wilk, α = 0.05)
Hétéroscédasticité
Shapiro-Wilk : W = 0.9669, p = 0.0001
D'Agostino-Pearson : S = 19.4711, p = 0.0001
→ Non normal (Shapiro-Wilk, α = 0.05)
Non-linéarité
Shapiro-Wilk : W = 0.9860, p = 0.0445
D'Agostino-Pearson : S = 4.5133, p = 0.1047
→ Non normal (Shapiro-Wilk, α = 0.05)
Régularisation#
Lorsque le nombre de variables est élevé, que les variables sont corrélées entre elles (multicolinéarité) ou que l’on souhaite prévenir le surapprentissage, on peut régulariser le modèle en ajoutant une pénalité sur la norme des coefficients à la fonction de coût.
Régression Ridge (\(L_2\))#
Définition 58 (Régression Ridge)
La régression Ridge (ou régression de Tikhonov) ajoute une pénalité \(L_2\) au problème des moindres carrés :
où \(\alpha > 0\) est le paramètre de régularisation. La solution admet une forme close :
L’ajout de \(\alpha \mathbf{I}\) rend la matrice toujours inversible, même en cas de multicolinéarité.
Remarque 53
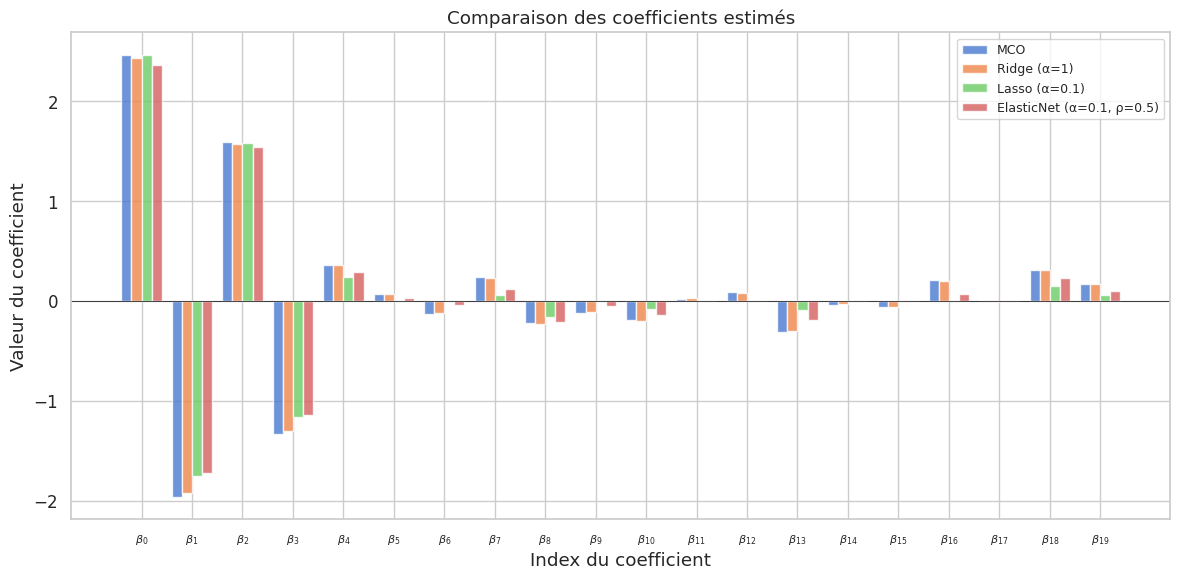
Ridge ne met jamais de coefficient exactement à zéro : il les réduit (shrinks) vers zéro. Plus \(\alpha\) est grand, plus les coefficients sont petits, mais aucun n’est annulé. Ridge est donc un outil de régularisation, pas de sélection de variables.
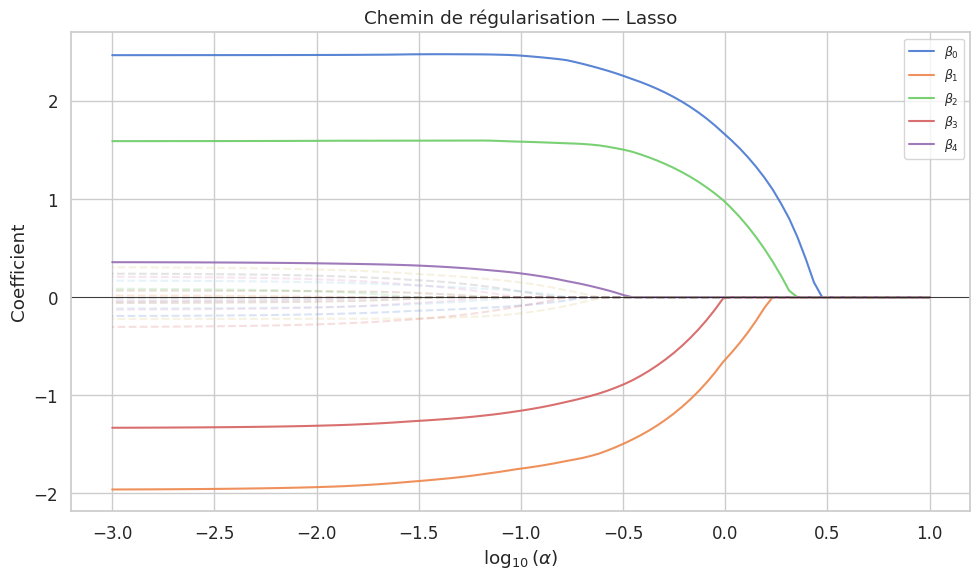
Régression Lasso (\(L_1\))#
Définition 59 (Régression Lasso)
La régression Lasso (Least Absolute Shrinkage and Selection Operator) ajoute une pénalité \(L_1\) :
où \(\|\boldsymbol{\beta}\|_1 = \sum_{j=1}^p |\beta_j|\) est la norme \(L_1\).
Contrairement à Ridge, Lasso peut mettre certains coefficients exactement à zéro, réalisant ainsi une sélection automatique de variables.
Remarque 54
La propriété de parcimonie du Lasso provient de la géométrie de la boule \(L_1\) : ses « coins » sont alignés sur les axes, ce qui favorise les solutions où certaines coordonnées sont nulles. Géométriquement, la contrainte \(\|\boldsymbol{\beta}\|_1 \leq t\) est un polyèdre (losange en 2D) dont les sommets se trouvent sur les axes.
ElasticNet#
Définition 60 (ElasticNet)
Le ElasticNet combine les pénalités \(L_1\) et \(L_2\) :
où \(\rho \in [0, 1]\) est le ratio de mélange (l1_ratio) :
\(\rho = 1\) : Lasso pur
\(\rho = 0\) : Ridge pur
\(0 < \rho < 1\) : compromis entre sélection de variables (L1) et stabilité (L2)
Remarque 55
ElasticNet corrige deux limitations du Lasso :
Lorsque \(p > n\) (plus de variables que d’observations), Lasso sélectionne au plus \(n\) variables. ElasticNet peut en sélectionner davantage.
En présence de variables fortement corrélées, Lasso a tendance à n’en sélectionner qu’une et à ignorer les autres. ElasticNet les conserve en groupe grâce à la composante Ridge.
Métriques d’évaluation#
L’évaluation d’un modèle de régression repose sur des métriques quantifiant l’écart entre les valeurs observées \(y_i\) et les valeurs prédites \(\hat{y}_i\).
Définition 61 (Erreur quadratique moyenne (MSE))
L”erreur quadratique moyenne (Mean Squared Error) est
Elle pénalise fortement les grandes erreurs (à cause du carré). Son unité est le carré de l’unité de \(y\).
Définition 62 (Racine de l’erreur quadratique moyenne (RMSE))
La RMSE (Root Mean Squared Error) est la racine carrée de la MSE :
Elle a la même unité que \(y\), ce qui la rend plus interprétable que la MSE.
Définition 63 (Erreur absolue moyenne (MAE))
L”erreur absolue moyenne (Mean Absolute Error) est
Elle est plus robuste aux valeurs aberrantes que la MSE, car elle ne met pas les erreurs au carré.
Définition 64 (Coefficient de détermination (\(R^2\)))
Le coefficient de détermination \(R^2\) mesure la proportion de la variance de \(y\) expliquée par le modèle :
où \(\text{TSS} = \sum(y_i - \bar{y})^2\) est la somme totale des carrés.
\(R^2 = 1\) : le modèle explique parfaitement la variance de \(y\)
\(R^2 = 0\) : le modèle ne fait pas mieux que prédire la moyenne \(\bar{y}\)
\(R^2 < 0\) : le modèle est pire que la prédiction par la moyenne (possible sur le test set)
Définition 65 (\(R^2\) ajusté)
Le \(R^2\) ajusté corrige le \(R^2\) pour le nombre de variables \(p\) :
Contrairement au \(R^2\) brut, le \(R^2\) ajusté peut diminuer lorsqu’on ajoute une variable non informative, car la pénalisation \(\frac{n-1}{n-p-1}\) augmente avec \(p\).
Remarque 56
Le \(R^2\) augmente mécaniquement lorsqu’on ajoute des variables au modèle, même si elles sont inutiles. C’est pourquoi il ne doit jamais être utilisé seul pour comparer des modèles avec des nombres de variables différents. Le \(R^2\) ajusté ou les critères d’information (AIC, BIC) sont plus appropriés.
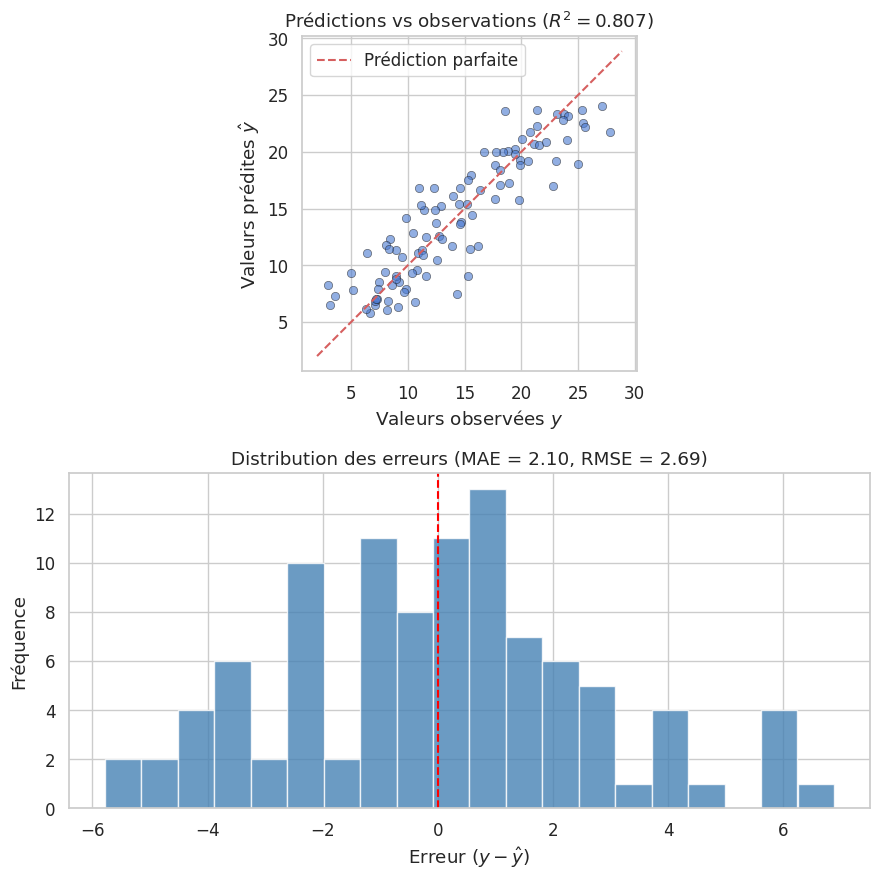
Métriques d'évaluation :
MSE = 7.2593
RMSE = 2.6943
MAE = 2.1031
R² = 0.8071
R² ajusté = 0.8052
Exemple complet avec Scikit-learn#
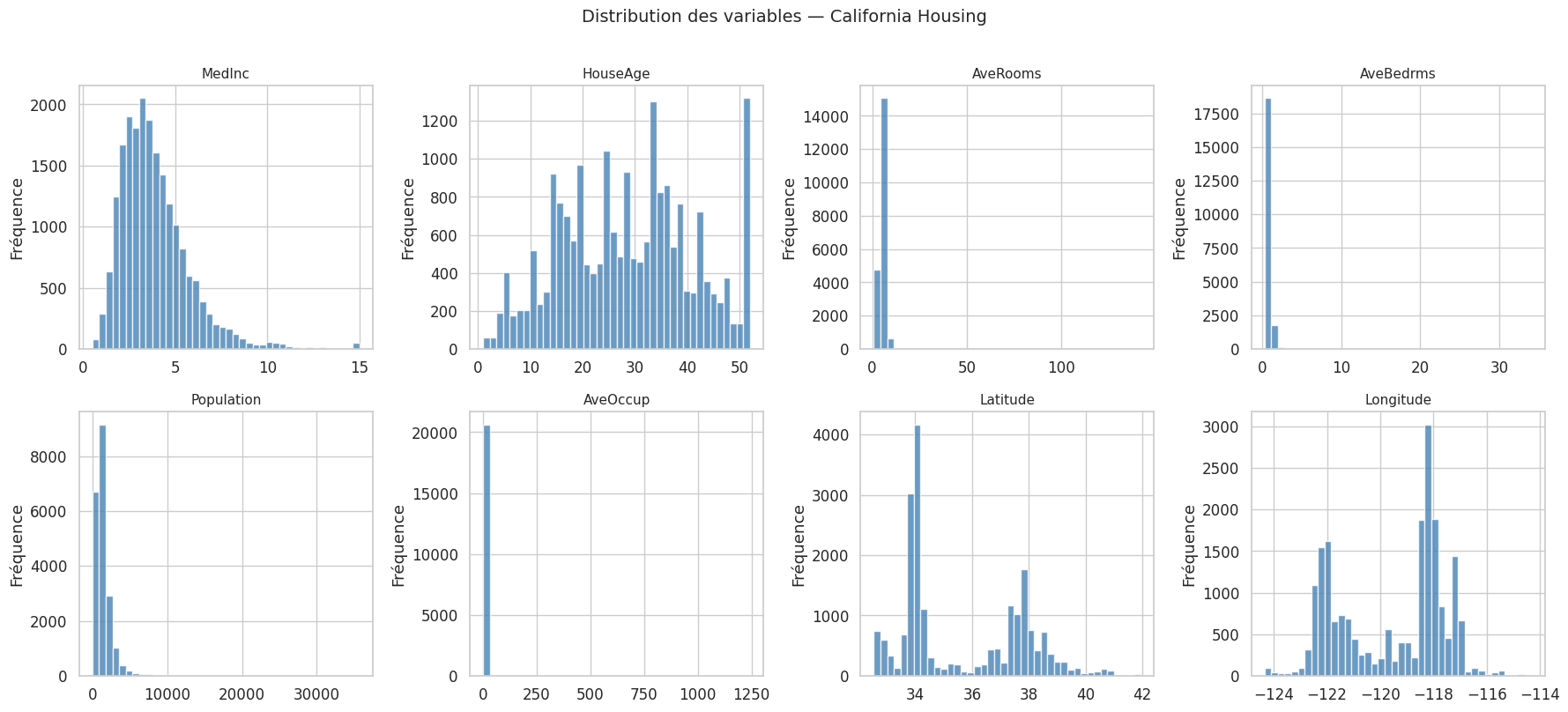
Mettons en pratique l’ensemble des concepts sur un jeu de données réel : California Housing. L’objectif est de prédire la valeur médiane des maisons dans un district californien à partir de caractéristiques sociodémographiques et géographiques.
Dimensions : (20640, 9)
Variables : ['MedInc', 'HouseAge', 'AveRooms', 'AveBedrms', 'Population', 'AveOccup', 'Latitude', 'Longitude', 'MedHouseVal']
Aperçu :
| MedInc | HouseAge | AveRooms | AveBedrms | Population | AveOccup | Latitude | Longitude | MedHouseVal | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 8.3252 | 41.0 | 6.984127 | 1.023810 | 322.0 | 2.555556 | 37.88 | -122.23 | 4.526 |
| 1 | 8.3014 | 21.0 | 6.238137 | 0.971880 | 2401.0 | 2.109842 | 37.86 | -122.22 | 3.585 |
| 2 | 7.2574 | 52.0 | 8.288136 | 1.073446 | 496.0 | 2.802260 | 37.85 | -122.24 | 3.521 |
| 3 | 5.6431 | 52.0 | 5.817352 | 1.073059 | 558.0 | 2.547945 | 37.85 | -122.25 | 3.413 |
| 4 | 3.8462 | 52.0 | 6.281853 | 1.081081 | 565.0 | 2.181467 | 37.85 | -122.25 | 3.422 |
| MedInc | HouseAge | AveRooms | AveBedrms | Population | AveOccup | Latitude | Longitude | MedHouseVal | |
|---|---|---|---|---|---|---|---|---|---|
| count | 20640.000 | 20640.000 | 20640.000 | 20640.000 | 20640.000 | 20640.000 | 20640.000 | 20640.000 | 20640.000 |
| mean | 3.871 | 28.639 | 5.429 | 1.097 | 1425.477 | 3.071 | 35.632 | -119.570 | 2.069 |
| std | 1.900 | 12.586 | 2.474 | 0.474 | 1132.462 | 10.386 | 2.136 | 2.004 | 1.154 |
| min | 0.500 | 1.000 | 0.846 | 0.333 | 3.000 | 0.692 | 32.540 | -124.350 | 0.150 |
| 25% | 2.563 | 18.000 | 4.441 | 1.006 | 787.000 | 2.430 | 33.930 | -121.800 | 1.196 |
| 50% | 3.535 | 29.000 | 5.229 | 1.049 | 1166.000 | 2.818 | 34.260 | -118.490 | 1.797 |
| 75% | 4.743 | 37.000 | 6.052 | 1.100 | 1725.000 | 3.282 | 37.710 | -118.010 | 2.647 |
| max | 15.000 | 52.000 | 141.909 | 34.067 | 35682.000 | 1243.333 | 41.950 | -114.310 | 5.000 |
Analyse exploratoire#
Exemple 5
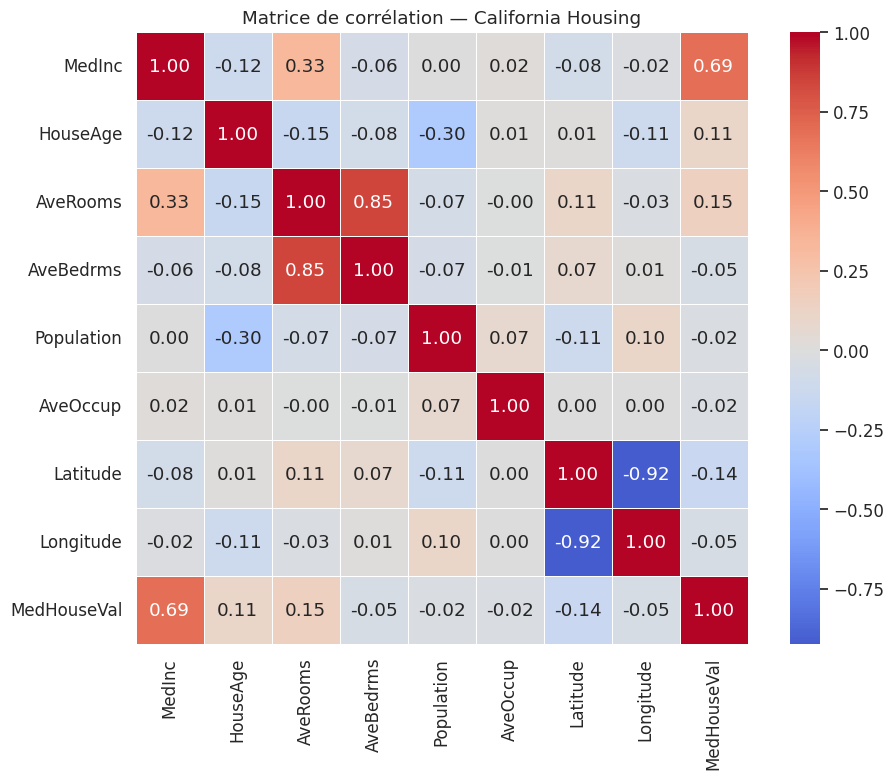
On observe que MedInc (revenu médian) est la variable la plus corrélée à MedHouseVal (\(r \approx 0.69\)). Les variables AveRooms et AveBedrms sont fortement corrélées entre elles (\(r \approx 0.85\)), signe de multicolinéarité. La variable HouseAge est faiblement corrélée à la cible (\(r \approx 0.11\)), mais pourrait néanmoins contribuer en combinaison avec d’autres features.
Préparation des données#
Entraînement : 16512 observations
Test : 4128 observations
Entraînement et comparaison des modèles#
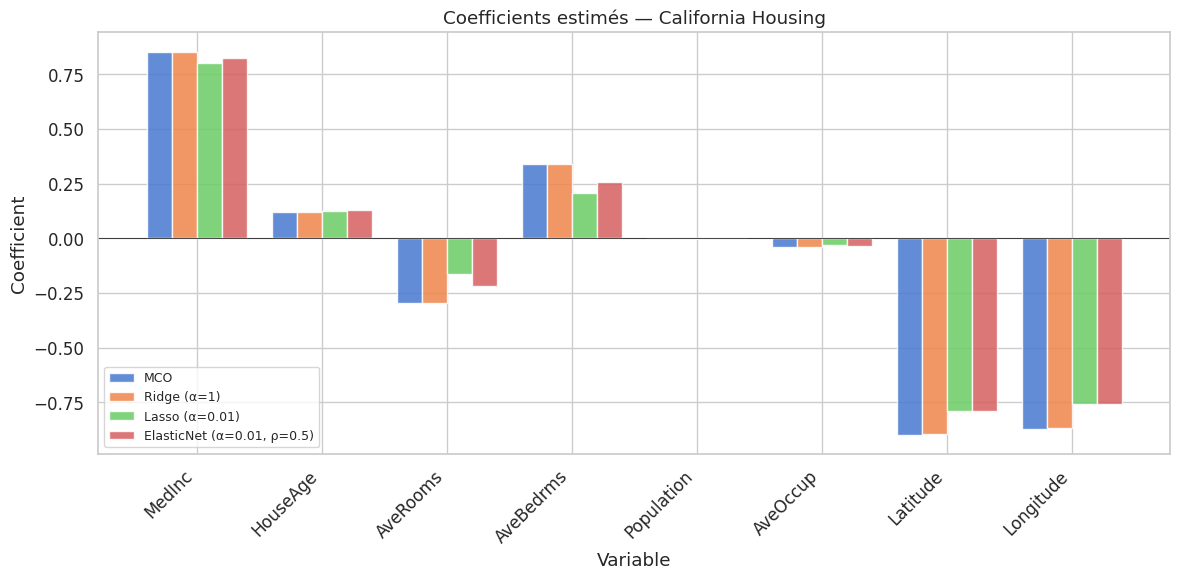
MCO RMSE = 0.7456 MAE = 0.5332 R² = 0.5758
Ridge (α=1) RMSE = 0.7456 MAE = 0.5332 R² = 0.5758
Lasso (α=0.01) RMSE = 0.7404 MAE = 0.5353 R² = 0.5816
ElasticNet (α=0.01, ρ=0.5) RMSE = 0.7416 MAE = 0.5341 R² = 0.5803
Diagnostic du modèle MCO#
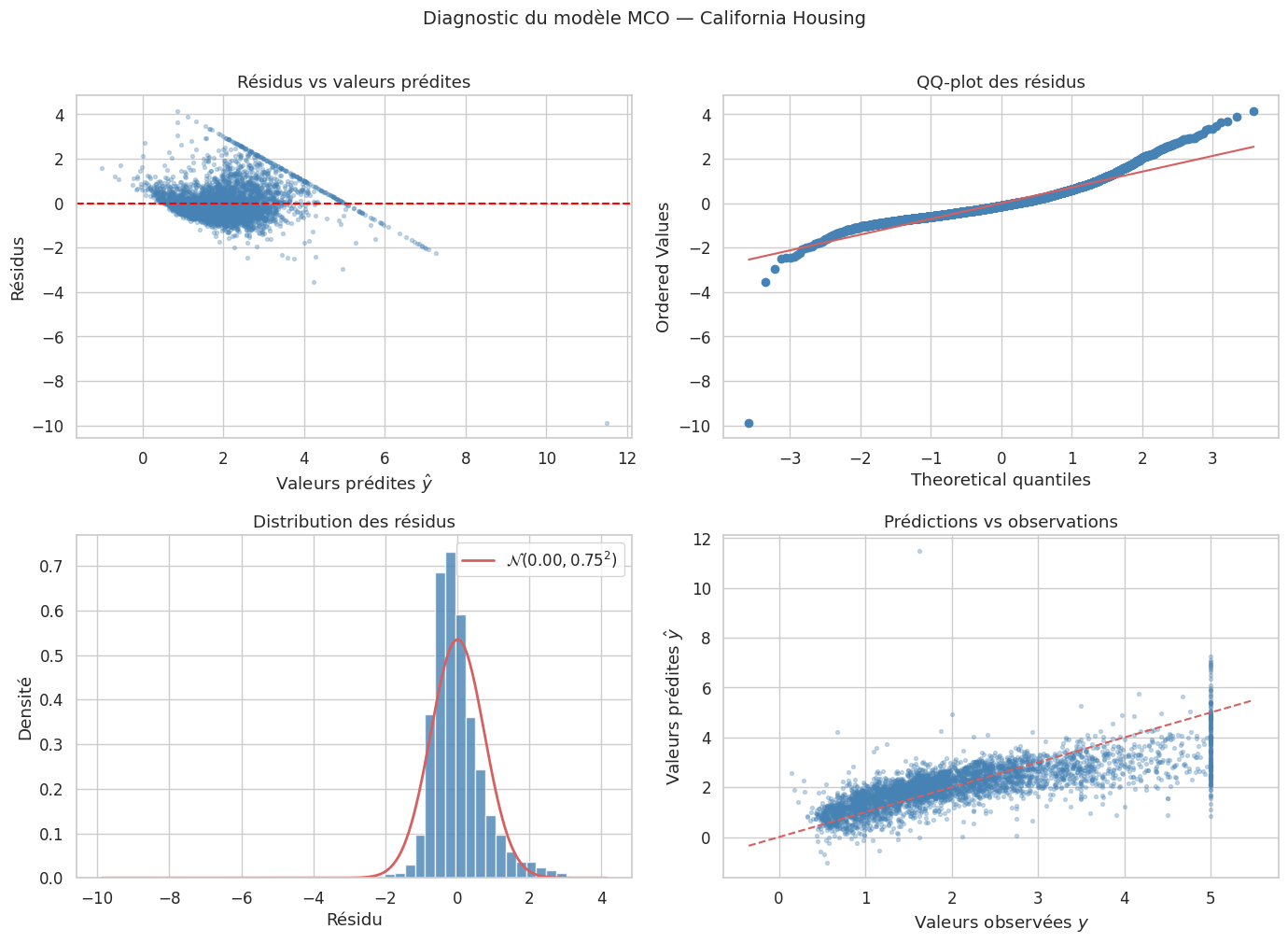
Remarque 57
Le diagnostic sur California Housing révèle plusieurs violations des hypothèses :
Le graphique des résidus vs prédites montre une structure non aléatoire, avec une accumulation de résidus négatifs pour les grandes valeurs prédites. Cela s’explique par le plafonnement de la variable cible à \(5.0\) (les prix supérieurs à 500 000 $ ont été censurés).
Le QQ-plot montre des queues lourdes, indiquant une non-normalité des résidus.
Ces observations suggèrent qu’un modèle linéaire simple est insuffisant pour capturer pleinement la structure des données. Des transformations non linéaires ou des modèles plus flexibles seraient à envisager.
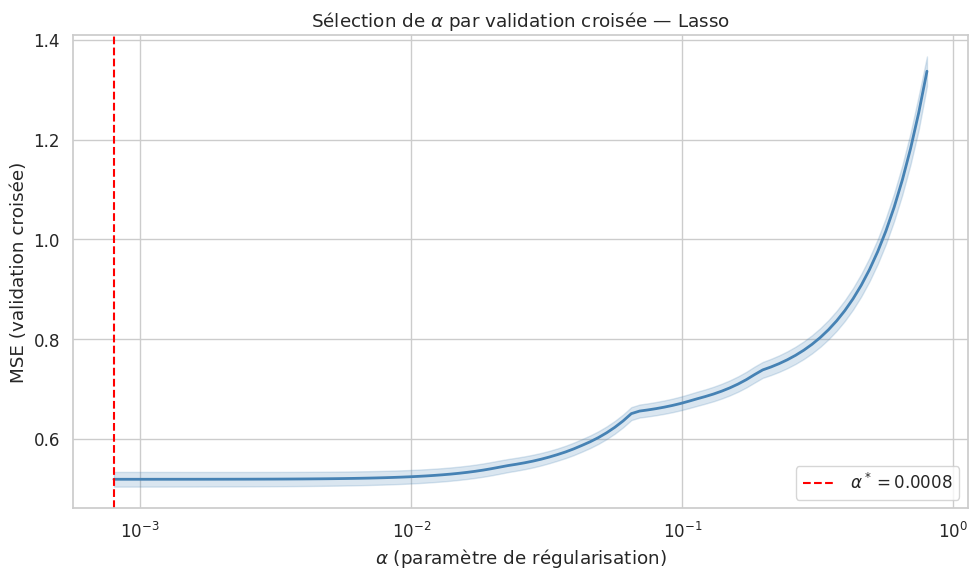
Sélection du paramètre de régularisation par validation croisée#
Ridge — meilleur α : 0.0010
Ridge — R² test : 0.5758
Lasso — meilleur α : 0.0008
Lasso — R² test : 0.5766
Lasso — coefficients non nuls : 8 / 8
Résumé des résultats#
Modèle MSE RMSE MAE R²
MCO 0.555892 0.745581 0.533200 0.575788
Ridge (α=1) 0.555855 0.745557 0.533193 0.575816
Lasso (α=0.01) 0.548255 0.740442 0.535326 0.581615
ElasticNet (α=0.01, ρ=0.5) 0.549953 0.741588 0.534077 0.580319
Remarque 58
Sur le jeu California Housing, les quatre modèles donnent des performances très proches. Cela s’explique par le fait que toutes les variables sont informatives et que le nombre d’observations (\(n \approx 20\,000\)) est largement supérieur au nombre de variables (\(p = 8\)). La régularisation apporte un bénéfice principalement lorsque \(p\) est grand relativement à \(n\), ou en présence de forte multicolinéarité. Dans le cas présent, la régularisation ne dégrade pas les performances, ce qui confirme la robustesse des modèles pénalisés.
Résumé#
Ce chapitre a couvert les fondements de la régression linéaire :
Concept |
Formule / idée clé |
|---|---|
Modèle simple |
\(y = \beta_0 + \beta_1 x + \varepsilon\) |
Modèle multiple |
\(\mathbf{y} = \mathbf{X}\boldsymbol{\beta} + \boldsymbol{\varepsilon}\) |
Solution MCO |
\(\hat{\boldsymbol{\beta}} = (\mathbf{X}^T\mathbf{X})^{-1}\mathbf{X}^T\mathbf{y}\) |
Ridge (\(L_2\)) |
\(\hat{\boldsymbol{\beta}} = (\mathbf{X}^T\mathbf{X} + \alpha\mathbf{I})^{-1}\mathbf{X}^T\mathbf{y}\) |
Lasso (\(L_1\)) |
Sélection de variables par parcimonie |
ElasticNet |
Compromis \(L_1\) / \(L_2\) |
MSE, RMSE |
Sensibles aux grandes erreurs |
MAE |
Robuste aux valeurs aberrantes |
\(R^2\) |
Proportion de variance expliquée |
Remarque 59
La régression linéaire est rarement le modèle le plus performant sur un problème complexe, mais elle offre plusieurs avantages irremplaçables : une interprétabilité totale des coefficients, une rapidité d’entraînement, une solution analytique en forme close, et un cadre théorique bien établi (inférence, intervalles de confiance, tests). C’est le modèle de référence (baseline) avec lequel tout modèle plus complexe doit être comparé.