
Mécanisme d’attention et Transformers#
Attention is all you need.
— Ashish Vaswani et al., Attention Is All You Need (2017)
Le chapitre 20 a présenté les réseaux récurrents (RNN, LSTM, GRU) et mis en évidence leurs deux limitations fondamentales : la difficulté à capturer des dépendances à longue portée et l’impossibilité de paralléliser le calcul sur la dimension temporelle. Le mécanisme d’attention, proposé initialement comme complément aux architectures seq2seq, apporte une solution élégante au premier problème en permettant au modèle de « regarder » directement toutes les positions de la séquence d’entrée. L’architecture Transformer, introduite par Vaswani et al. en 2017, pousse cette idée à son terme en abandonnant entièrement la récurrence au profit de l”auto-attention (self-attention), résolvant ainsi simultanément les deux limitations. Ce chapitre présente le mécanisme d’attention, l’auto-attention, l’attention multi-têtes, l’encodage positionnel et l’architecture Transformer complète, avec des implémentations détaillées en PyTorch.
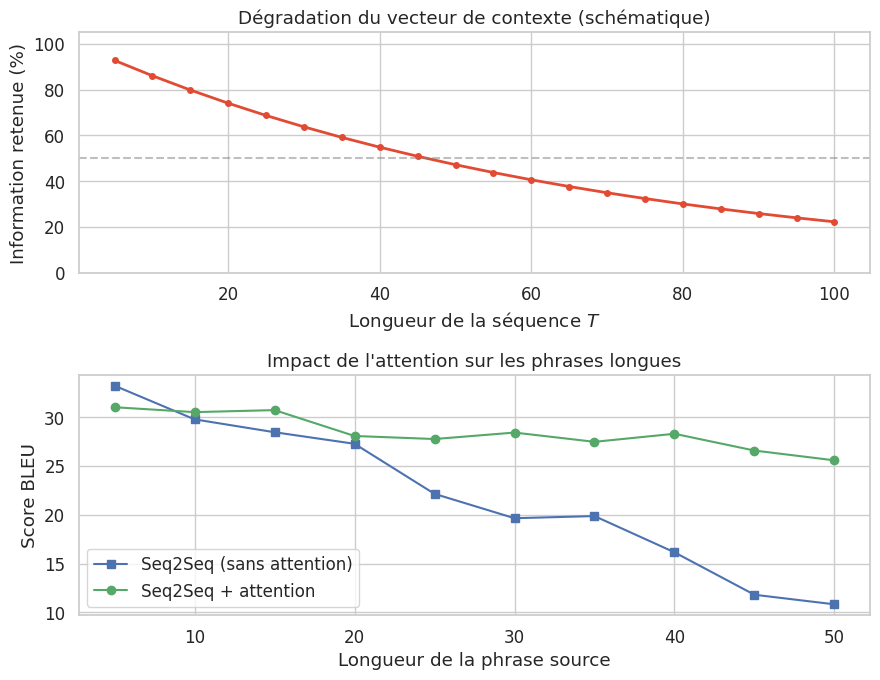
Le problème du goulot d’étranglement informationnel#
Rappel : l’architecture seq2seq#
Dans l’architecture encodeur-décodeur classique (chapitre 20), l’encodeur RNN lit la séquence d’entrée \((x_1, \ldots, x_T)\) et produit un unique vecteur de contexte \(\mathbf{c} = h_T\), le dernier état caché. Le décodeur doit ensuite générer toute la séquence de sortie à partir de ce seul vecteur.
Remarque 233
Ce vecteur \(\mathbf{c}\) constitue un goulot d’étranglement (bottleneck) : toute l’information de la séquence d’entrée, quelle que soit sa longueur, doit être compressée dans un vecteur de dimension fixe. En pratique, les performances des modèles seq2seq se dégradent significativement lorsque la longueur des séquences d’entrée augmente, car l’information des premiers tokens est progressivement « écrasée » par celle des tokens suivants.
Mécanisme d’attention#
L’idée centrale du mécanisme d’attention est simple : plutôt que de compresser toute la séquence en un unique vecteur, on permet au décodeur d”accéder directement à tous les états cachés de l’encodeur à chaque pas de temps de la génération. Un système de scores détermine l’importance relative de chaque état caché de l’encodeur pour le pas de décodage courant.
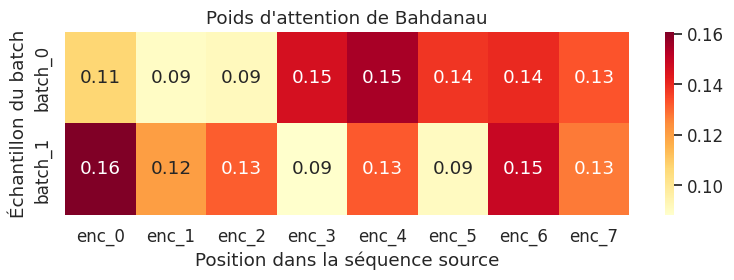
Attention de Bahdanau (additive)#
Le mécanisme d’attention a été introduit par Bahdanau, Cho et Bengio en 2015 dans le contexte de la traduction automatique neuronale.
Définition 267 (Attention additive (Bahdanau))
Soient \((\bar{h}_1, \ldots, \bar{h}_T)\) les états cachés de l’encodeur et \(s_{t-1}\) l’état caché courant du décodeur. L”attention de Bahdanau calcule un vecteur de contexte \(\mathbf{c}_t\) propre à chaque pas de décodage \(t\) :
Score d’alignement (fonction de score additive) :
Poids d’attention (normalisation par softmax) :
Vecteur de contexte (combinaison convexe) :
où \(W_s \in \mathbb{R}^{d_a \times d_s}\), \(W_h \in \mathbb{R}^{d_a \times d_h}\) et \(\mathbf{v} \in \mathbb{R}^{d_a}\) sont des paramètres apprenables, et \(d_a\) est la dimension de l’espace d’alignement.
Attention de Luong (multiplicative)#
Luong et al. (2015) ont proposé des fonctions de score alternatives, plus simples et souvent plus efficaces.
Définition 268 (Fonctions de score d’attention)
Soit \(s_t\) l’état du décodeur et \(\bar{h}_j\) un état de l’encodeur. Les principales fonctions de score sont :
Nom |
Formule |
Complexité |
|---|---|---|
Dot product |
\(e_{t,j} = s_t^\top \bar{h}_j\) |
\(O(d)\) |
Général (bilinéaire) |
\(e_{t,j} = s_t^\top W_a \, \bar{h}_j\) |
\(O(d^2)\) |
Additif (Bahdanau) |
\(e_{t,j} = \mathbf{v}^\top \tanh(W_s s_t + W_h \bar{h}_j)\) |
\(O(d)\) |
Scaled dot product |
\(e_{t,j} = \frac{s_t^\top \bar{h}_j}{\sqrt{d}}\) |
\(O(d)\) |
Le scaled dot product divise par \(\sqrt{d}\) pour éviter que les valeurs du produit scalaire ne deviennent trop grandes en haute dimension, ce qui écraserait les gradients du softmax.
Implémentation de l’attention additive#
Vecteur de contexte : torch.Size([2, 64])
Poids d'attention : torch.Size([2, 8])
Somme des poids : tensor([1.0000, 1.0000], grad_fn=<SumBackward1>)
Auto-attention (Self-Attention)#
L’attention telle que décrite précédemment relie un décodeur à un encodeur : c’est une attention croisée (cross-attention). L”auto-attention applique le même principe au sein d’une même séquence : chaque position peut « regarder » toutes les autres positions de la même séquence pour construire sa représentation.
Formalisme Query-Key-Value#
Définition 269 (Auto-attention avec Query, Key, Value)
Soit \(X \in \mathbb{R}^{T \times d}\) une séquence de \(T\) vecteurs de dimension \(d\). L’auto-attention projette chaque vecteur en trois rôles à l’aide de matrices apprenables :
où \(W^Q, W^K \in \mathbb{R}^{d \times d_k}\) et \(W^V \in \mathbb{R}^{d \times d_v}\).
\(Q\) (queries) : ce que chaque position « cherche »
\(K\) (keys) : ce que chaque position « annonce »
\(V\) (values) : l’information que chaque position « transmet »
La sortie est :
Remarque 234
L’analogie avec un système de recherche d’information est éclairante : chaque position émet une requête (\(Q\)), et le score de pertinence entre cette requête et la clé (\(K\)) de chaque autre position détermine combien de valeur (\(V\)) cette position apporte. Le facteur \(\frac{1}{\sqrt{d_k}}\) empêche les produits scalaires de devenir trop grands lorsque \(d_k\) est élevé, ce qui concentrerait le softmax sur un seul élément et annulerait les gradients.
Dérivation détaillée#
Considérons une séquence de \(T\) positions. La matrice \(QK^\top \in \mathbb{R}^{T \times T}\) contient les scores de similarité entre toutes les paires de positions :
Si les composantes de \(Q\) et \(K\) sont des variables aléatoires i.i.d. de moyenne nulle et de variance unitaire, alors \(\mathbb{E}[\mathbf{q}_i^\top \mathbf{k}_j] = 0\) et \(\text{Var}[\mathbf{q}_i^\top \mathbf{k}_j] = d_k\). Diviser par \(\sqrt{d_k}\) ramène la variance à 1, ce qui maintient le softmax dans une zone à gradients raisonnables.
Propriété 1 (Complexité de l’auto-attention)
Pour une séquence de longueur \(T\) et une dimension \(d_k\) :
Complexité temporelle : \(O(T^2 \cdot d_k)\) pour le calcul de \(QK^\top\)
Complexité mémoire : \(O(T^2)\) pour stocker la matrice d’attention
Longueur du chemin de gradient : \(O(1)\) entre deux positions quelconques (contre \(O(T)\) pour un RNN)
La complexité quadratique en \(T\) est le principal inconvénient de l’auto-attention, mais elle est largement compensée par la parallélisation totale du calcul et la capacité à capturer des dépendances à longue portée.
Implémentation de l’auto-attention#
Entrée X : torch.Size([1, 6, 32])
Sortie : torch.Size([1, 6, 32])
Poids attention: torch.Size([1, 6, 6])
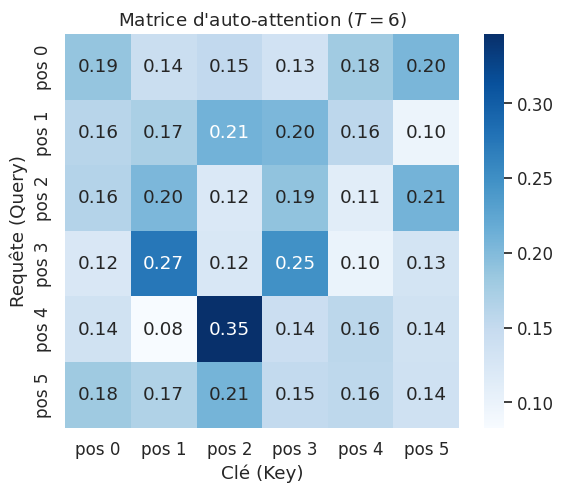
Exemple 28 (Intuition de l’auto-attention)
Considérons la phrase « Le chat dort sur le canapé car il est fatigué ». Lorsque l’auto-attention traite le mot « il », elle doit déterminer à quoi ce pronom fait référence. Les scores d’attention entre la query de « il » et les keys de tous les autres mots permettront idéalement d’attribuer un poids élevé à « chat », capturant ainsi la relation de coréférence — une dépendance à longue portée que les RNN peinent à modéliser.
Attention multi-têtes (Multi-Head Attention)#
Motivation#
Une seule tête d’attention ne peut capturer qu’un seul « type » de relation entre positions. Or, dans une phrase, les relations sont multiples : syntaxiques, sémantiques, coréférentielles, etc. L’attention multi-têtes résout ce problème en exécutant plusieurs mécanismes d’attention en parallèle, chacun dans un sous-espace différent.
Définition 270 (Attention multi-têtes)
L”attention multi-têtes avec \(h\) têtes est définie par :
où chaque tête \(i\) est :
avec \(W_i^Q \in \mathbb{R}^{d_{\text{model}} \times d_k}\), \(W_i^K \in \mathbb{R}^{d_{\text{model}} \times d_k}\), \(W_i^V \in \mathbb{R}^{d_{\text{model}} \times d_v}\) et \(W^O \in \mathbb{R}^{h \cdot d_v \times d_{\text{model}}}\).
Typiquement, \(d_k = d_v = d_{\text{model}} / h\), de sorte que le coût total est comparable à celui d’une seule tête de dimension \(d_{\text{model}}\).
Implémentation#
Entrée : torch.Size([2, 10, 64])
Sortie : torch.Size([2, 10, 64])
Poids attention: torch.Size([2, 8, 10, 10]) (batch, têtes, T_q, T_k)
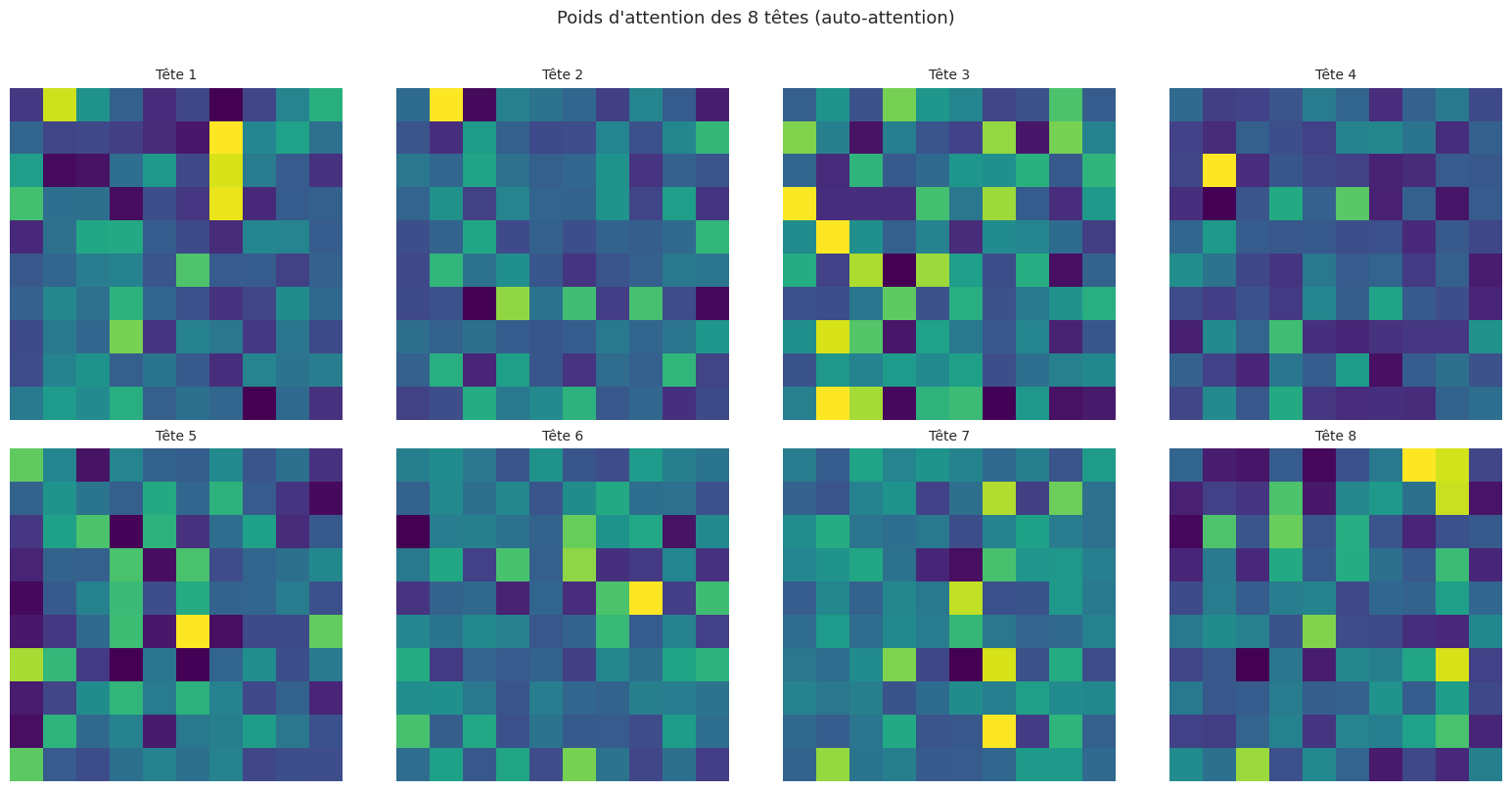
Remarque 235
Chaque tête apprend à détecter un type de relation différent. Des analyses empiriques montrent que certaines têtes se spécialisent dans les relations syntaxiques (sujet-verbe), d’autres dans les dépendances positionnelles (positions adjacentes), et d’autres encore dans les relations sémantiques à longue portée. La projection finale \(W^O\) apprend à combiner ces informations complémentaires.
Encodage positionnel (Positional Encoding)#
Pourquoi encoder la position ?#
L’auto-attention est une opération invariante par permutation : si l’on permute l’ordre des tokens dans la séquence, les poids d’attention changent, mais la relation entre chaque paire reste la même. Or, l’ordre des mots est crucial en langue naturelle (« le chat mange la souris » \(\neq\) « la souris mange le chat »). Il faut donc injecter explicitement l’information de position.
Définition 271 (Encodage positionnel sinusoïdal)
L”encodage positionnel sinusoïdal de Vaswani et al. associe à chaque position \(\text{pos}\) et chaque dimension \(i\) du modèle un signal :
Ce choix garantit que :
Chaque position reçoit un encodage unique.
La distance relative entre deux positions peut être exprimée comme une transformation linéaire de leurs encodages : \(PE_{\text{pos}+k}\) est une fonction linéaire de \(PE_{\text{pos}}\) pour tout décalage fixe \(k\).
Les longueurs de séquence non vues à l’entraînement peuvent être traitées grâce à l’extrapolation naturelle des fonctions sinusoïdales.
Forme de l'encodage positionnel : (100, 64)
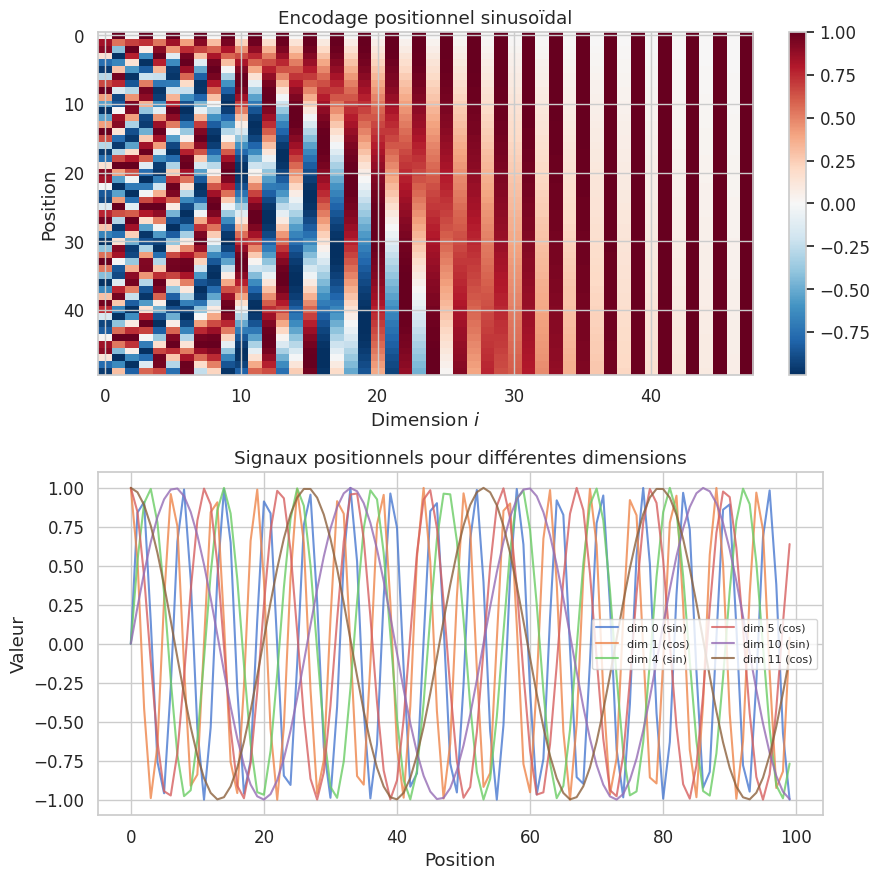
Remarque 236
Les dimensions basses (fréquence haute) varient rapidement avec la position, encodant les relations locales. Les dimensions hautes (fréquence basse) varient lentement, encodant la position absolue à grande échelle. L’ensemble forme un « spectre » de fréquences analogue à une transformée de Fourier de la position. Depuis 2017, d’autres schémas d’encodage positionnel ont été proposés — encodages apprenables, RoPE (Rotary Position Embedding), ALiBi — mais l’encodage sinusoïdal reste la référence pédagogique.
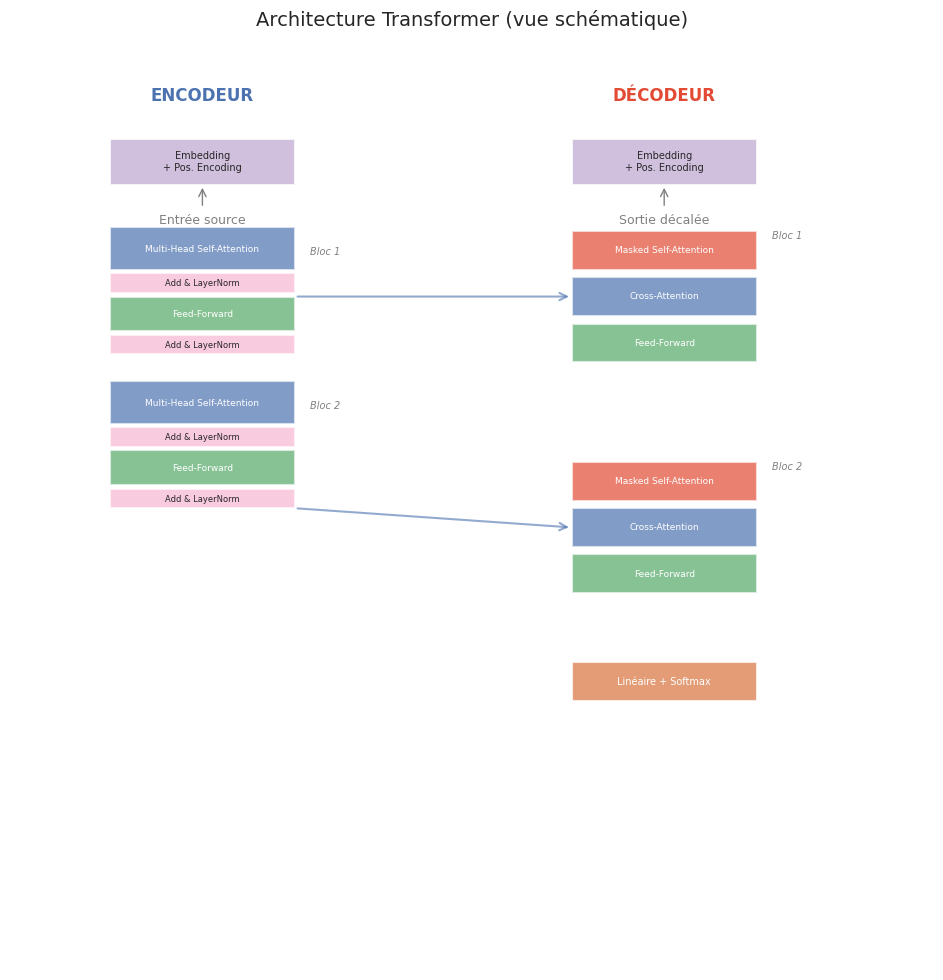
Architecture Transformer#
Vue d’ensemble#
L’architecture Transformer est composée d’un encodeur et d’un décodeur, chacun constitué d’un empilement de blocs identiques. L’encodeur transforme la séquence d’entrée en une représentation contextuelle riche, et le décodeur génère la séquence de sortie token par token en s’appuyant sur la sortie de l’encodeur.
Définition 272 (Architecture Transformer)
Le Transformer (Vaswani et al., 2017) est composé de :
Encodeur (\(N\) blocs identiques) : chaque bloc contient :
Une couche d”auto-attention multi-têtes
Une couche feed-forward position-wise : \(\text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2\)
Des connexions résiduelles et une normalisation de couche (layer norm) après chaque sous-couche : \(\text{LayerNorm}(x + \text{SubLayer}(x))\)
Décodeur (\(N\) blocs identiques) : chaque bloc contient :
Une couche d”auto-attention multi-têtes masquée (empêche de « regarder le futur »)
Une couche d”attention croisée multi-têtes (queries du décodeur, keys/values de l’encodeur)
Une couche feed-forward position-wise
Des connexions résiduelles et layer norm après chaque sous-couche
La configuration standard utilise \(N = 6\) blocs, \(d_{\text{model}} = 512\), \(h = 8\) têtes, et \(d_{ff} = 2048\).
Bloc encodeur#
Entrée : torch.Size([2, 10, 64])
Sortie : torch.Size([2, 10, 64])
Poids : torch.Size([2, 8, 10, 10])
Propriété 2 (Connexions résiduelles et normalisation)
Les connexions résiduelles (residual connections) facilitent l’entraînement de réseaux profonds en permettant au gradient de se propager directement à travers les couches. La normalisation de couche (Layer Normalization) stabilise les activations en normalisant sur la dimension des features :
où \(\mu\) et \(\sigma\) sont la moyenne et l’écart-type calculés sur la dernière dimension, et \(\gamma\), \(\beta\) sont des paramètres apprenables. Contrairement au Batch Normalization (utilisé dans les CNN), la Layer Norm ne dépend pas de la taille du batch et fonctionne identiquement en entraînement et en inférence.
Bloc décodeur#
Masque causal (8x8) :
tensor([[0, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 0, 0, 0]], dtype=torch.int32)
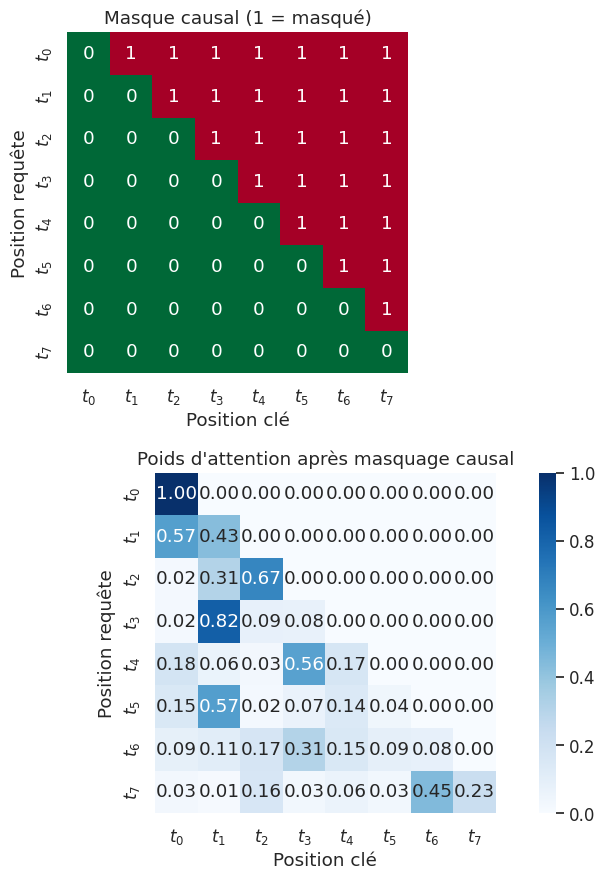
Transformer complet#
Nombre de paramètres : 251,236
Entraînement d’un Transformer sur une tâche jouet#
Pour illustrer le fonctionnement du Transformer, entraînons-le sur une tâche simple de copie de séquence : le modèle doit apprendre à reproduire la séquence d’entrée en sortie. C’est un test classique pour vérifier qu’une architecture seq2seq fonctionne correctement.
Préparation des données#
Exemple d'entrée source : [5, 19, 13, 2, 17, 14, 13, 6]
Exemple d'entrée cible : [1, 5, 19, 13, 2, 17, 14, 13, 6]
Exemple de sortie cible : [5, 19, 13, 2, 17, 14, 13, 6, 0]
Planification du taux d’apprentissage (warmup)#
Définition 273 (Warmup du taux d’apprentissage)
Le Transformer utilise une planification du taux d’apprentissage avec échauffement (warmup) suivie d’une décroissance :
Le taux augmente linéairement pendant les premiers warmup_steps pas, puis décroît proportionnellement à l’inverse de la racine carrée du numéro de pas. Cette stratégie évite les instabilités au début de l’entraînement, lorsque les paramètres sont encore aléatoires.
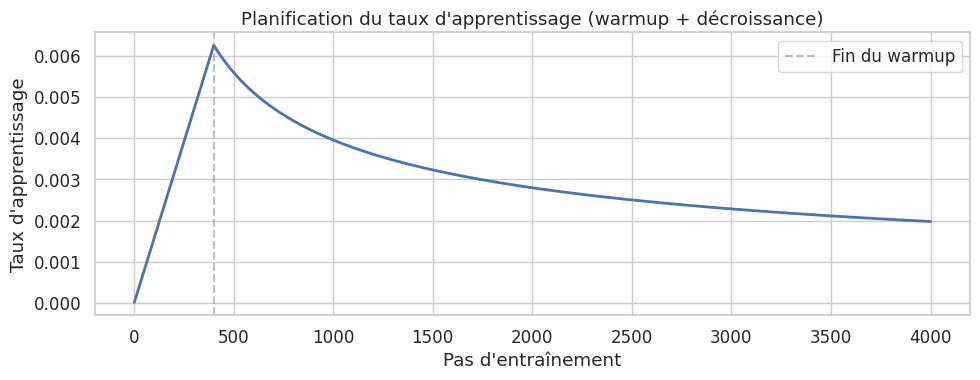
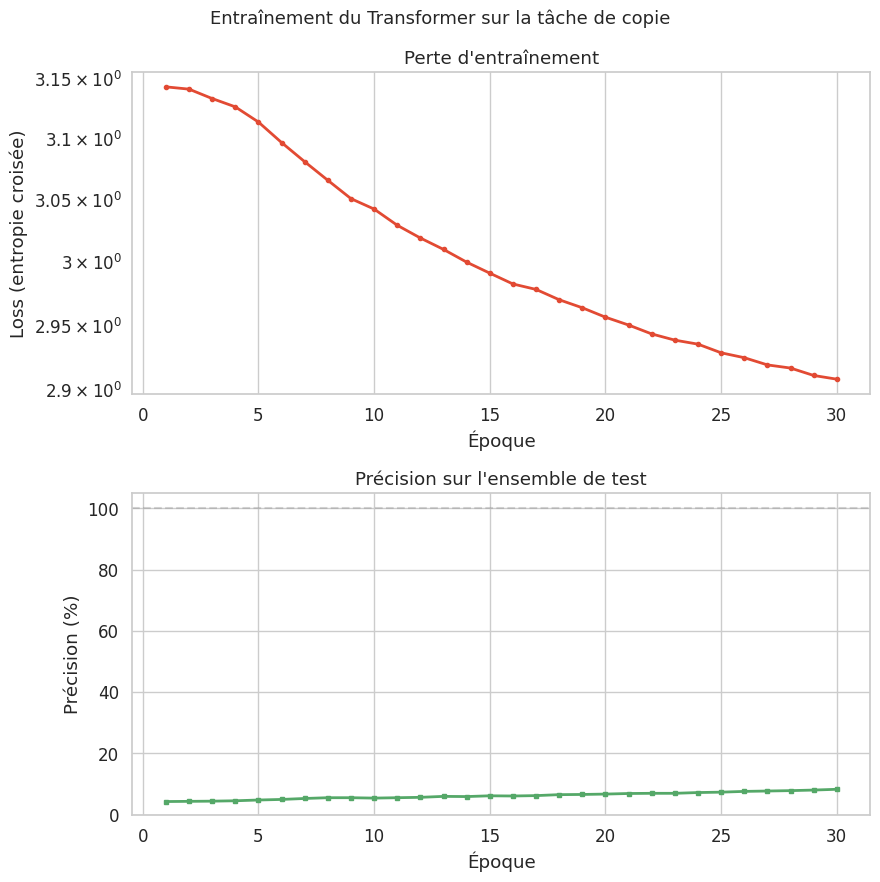
Boucle d’entraînement#
Époque 5 | Loss: 3.1138 | Précision test: 4.8%
Époque 10 | Loss: 3.0425 | Précision test: 5.4%
Époque 15 | Loss: 2.9912 | Précision test: 6.2%
Époque 20 | Loss: 2.9563 | Précision test: 6.8%
Époque 25 | Loss: 2.9285 | Précision test: 7.4%
Époque 30 | Loss: 2.9080 | Précision test: 8.3%
Exemples de copie (source → prédiction) :
--------------------------------------------------
Source : [11, 4, 10, 6, 4, 8, 7, 10]
Prédiction: [11, 4, 15, 9, 7, 16, 4, 6] [ERREUR]
Source : [12, 15, 9, 18, 7, 13, 7, 2]
Prédiction: [11, 17, 9, 9, 9, 17, 7, 17] [ERREUR]
Source : [15, 16, 15, 13, 13, 12, 19, 13]
Prédiction: [15, 9, 13, 9, 7, 7, 9, 9] [ERREUR]
Source : [11, 4, 5, 11, 13, 15, 15, 17]
Prédiction: [11, 14, 15, 13, 4, 15, 5, 5] [ERREUR]
Source : [13, 4, 3, 7, 6, 11, 6, 3]
Prédiction: [11, 3, 16, 2, 3, 8, 4, 8] [ERREUR]
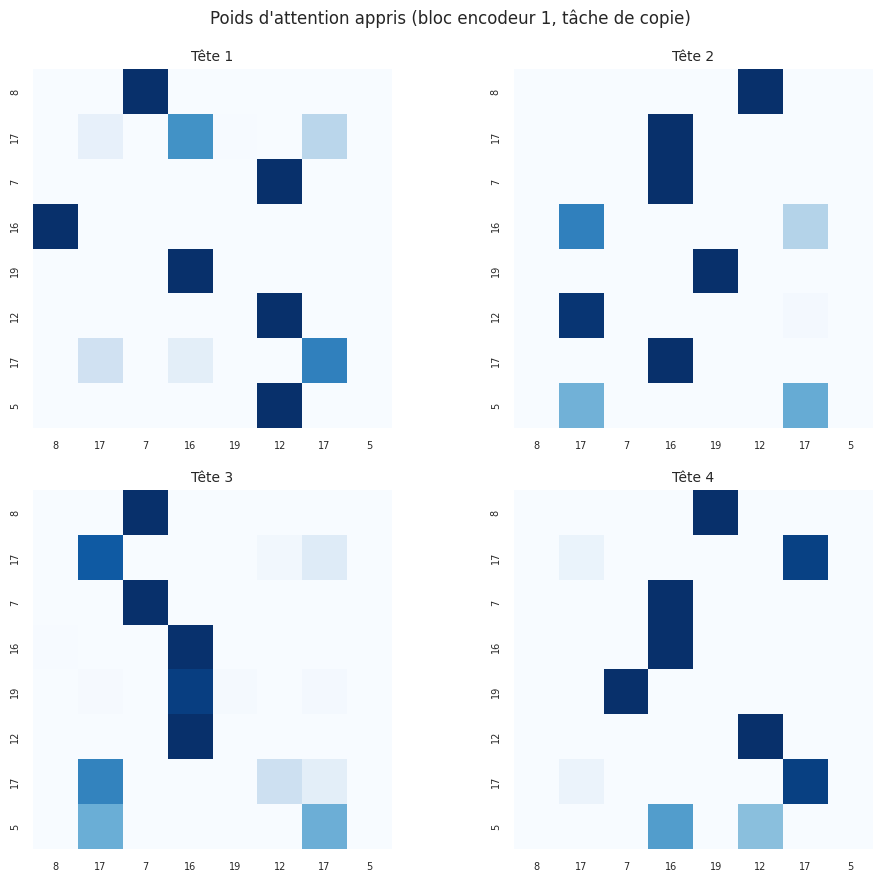
Visualisation de l’attention apprise#
Impact et postérité#
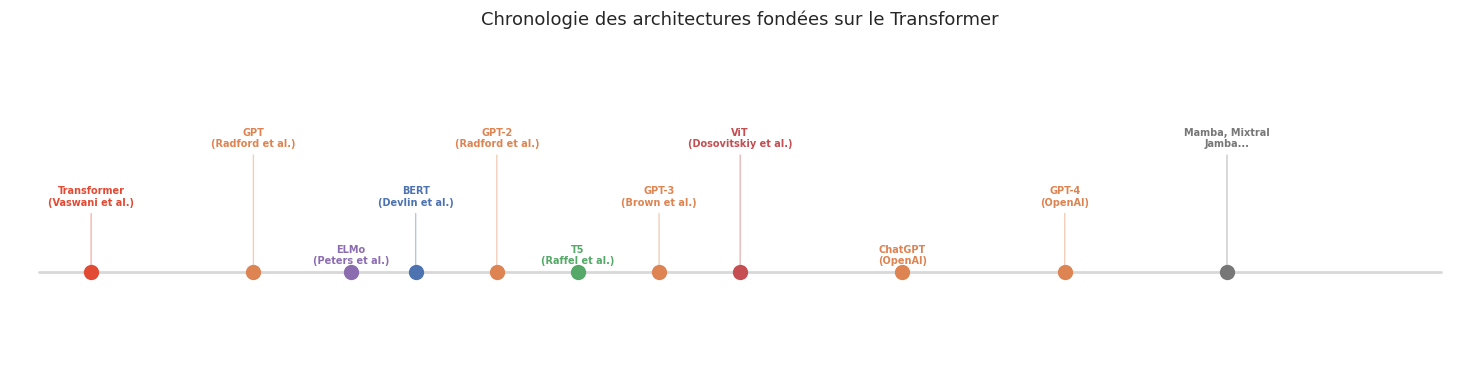
L’article Attention Is All You Need de Vaswani et al. (2017) a provoqué une révolution dans l’apprentissage profond. En éliminant la récurrence, le Transformer a permis un passage à l’échelle sans précédent et a engendré une famille de modèles qui dominent aujourd’hui le traitement du langage naturel, la vision par ordinateur et bien d’autres domaines.
Modèles fondateurs#
Exemple 29 (Descendants majeurs du Transformer)
Encodeur seul :
BERT (Bidirectional Encoder Representations from Transformers, Devlin et al., 2019) : pré-entraîné par prédiction de mots masqués (masked language modeling) et prédiction de phrase suivante. A défini le paradigme « pré-entraînement + fine-tuning » en NLP. Détails au chapitre 24.
Décodeur seul :
GPT (Generative Pre-trained Transformer, Radford et al., 2018) : pré-entraîné en modélisation de langage auto-régressive (\(P(x_t \mid x_1, \ldots, x_{t-1})\)). A donné naissance à GPT-2, GPT-3, GPT-4 et ChatGPT.
Encodeur-décodeur :
T5 (Text-to-Text Transfer Transformer, Raffel et al., 2020) : formule toutes les tâches NLP comme des problèmes texte-vers-texte.
BART (Lewis et al., 2020) : combinaison d’un encodeur bidirectionnel et d’un décodeur auto-régressif.
Vision :
ViT (Vision Transformer, Dosovitskiy et al., 2021) : applique le Transformer aux images en les découpant en patches. Détails au chapitre 25.
Remarque 237
Le Transformer n’est pas limité au texte. Son architecture a été adaptée avec succès aux images (ViT, Swin Transformer), à l’audio (Whisper), à la biologie (AlphaFold 2), à la chimie (MolBERT), à la robotique (RT-2) et même aux jeux (MuZero). La modularité du mécanisme d’attention — sa capacité à modéliser des relations arbitraires entre éléments d’un ensemble — en fait une brique de base véritablement universelle de l’apprentissage profond moderne.
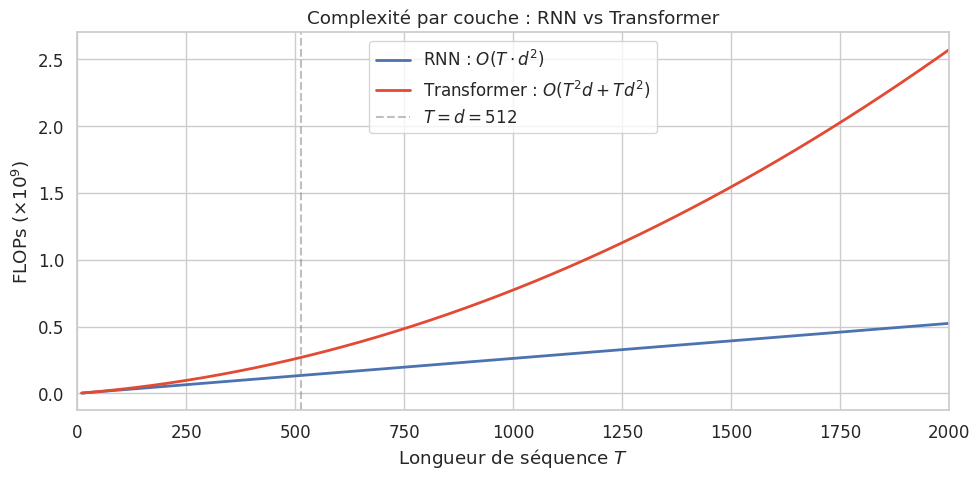
Comparaison avec les architectures précédentes#
Théorème 5 (Avantages du Transformer sur les RNN)
Soit une séquence de longueur \(T\) et un modèle de dimension \(d\). Le tableau suivant compare les propriétés fondamentales :
Propriété |
RNN |
Transformer |
|---|---|---|
Complexité par couche |
\(O(T \cdot d^2)\) |
\(O(T^2 \cdot d + T \cdot d^2)\) |
Opérations séquentielles |
\(O(T)\) |
\(O(1)\) |
Longueur max. du chemin de gradient |
\(O(T)\) |
\(O(1)\) |
Parallélisation |
Non |
Oui |
Pour \(T < d\) (cas fréquent en NLP où \(T \sim 512\) et \(d \sim 512\) ou plus), le terme \(O(T^2 \cdot d)\) de l’attention est dominé par \(O(T \cdot d^2)\), et le Transformer est plus rapide que le RNN grâce à la parallélisation complète.
Résumé#
Ce chapitre a présenté le mécanisme d’attention et l’architecture Transformer, qui ont révolutionné l’apprentissage profond depuis 2017.
Le mécanisme d’attention résout le goulot d’étranglement des modèles seq2seq en permettant au décodeur d’accéder directement à tous les états de l’encodeur, pondérés par des scores de pertinence. Les variantes principales sont l’attention additive (Bahdanau) et l’attention multiplicative (Luong).
L”auto-attention (self-attention) applique ce principe au sein d’une même séquence. Le formalisme Query-Key-Value et le scaled dot-product attention \(\text{softmax}(QK^\top / \sqrt{d_k}) V\) constituent le coeur du Transformer.
L”attention multi-têtes exécute \(h\) mécanismes d’attention en parallèle dans des sous-espaces différents, capturant des types de relations complémentaires.
L”encodage positionnel sinusoïdal injecte l’information d’ordre dans une architecture qui en est autrement dépourvue, grâce à des signaux de fréquences variées.
L’architecture Transformer combine auto-attention multi-têtes, couches feed-forward, connexions résiduelles et normalisation de couche en blocs encodeur et décodeur empilés. Le masque causal dans le décodeur empêche le modèle de « tricher » en regardant le futur.
L’entraînement du Transformer utilise un planificateur de taux d’apprentissage avec warmup, l’optimiseur Adam avec des hyperparamètres spécifiques, et le gradient clipping pour stabiliser la convergence.
L”impact du Transformer est considérable : BERT, GPT, T5, ViT et des centaines d’autres modèles en sont dérivés. L’attention est devenue la brique fondamentale de l’apprentissage profond moderne, et ses descendants seront étudiés dans les chapitres 24 (NLP) et 25 (Vision).
Remarque 238
Le Transformer illustre un principe profond en apprentissage automatique : la bonne inductive bias — ici, la capacité à modéliser des relations arbitraires entre éléments d’une séquence sans a priori de localité — peut l’emporter sur des architectures plus structurées (RNN, CNN) lorsque les données et la puissance de calcul sont suffisantes. Comprendre l’attention et le Transformer est aujourd’hui un prérequis indispensable pour aborder les modèles de fondation (foundation models) qui façonnent l’IA contemporaine.