
Traitement du langage naturel#
Le langage est le vêtement de la pensée.
— Samuel Johnson, Vies des poètes anglais
Le traitement du langage naturel (Natural Language Processing, NLP) est le domaine de l’intelligence artificielle qui vise à donner aux machines la capacité de comprendre, d’interpréter et de générer le langage humain. Contrairement aux données numériques structurées rencontrées dans les chapitres précédents, le texte est une donnée non structurée, discrète, de longueur variable et profondément ambiguë. Un même mot peut avoir plusieurs sens (polysémie), une même idée peut s’exprimer de mille façons (paraphrase), et la compréhension d’une phrase nécessite souvent des connaissances extérieures au texte (pragmatique). Ces défis font du NLP l’un des domaines les plus stimulants de l’apprentissage automatique.
Ce chapitre s’appuie sur les architectures récurrentes (chapitre 20) et l’architecture Transformer (chapitre 23) pour présenter les concepts fondamentaux du NLP moderne : la tokenisation, les représentations vectorielles des mots, les modèles de langue, les modèles pré-entraînés (BERT, GPT, T5) et le fine-tuning. Nous utiliserons l’écosystème Hugging Face pour illustrer ces concepts par du code exécutable.
Introduction : le texte comme donnée#
Pourquoi le texte est difficile#
Les données textuelles présentent des caractéristiques fondamentalement différentes des données tabulaires ou des images :
Discrétion : le texte est composé de symboles discrets (caractères, mots), non de valeurs continues.
Longueur variable : les phrases, paragraphes et documents n’ont pas de taille fixe.
Structure hiérarchique : caractères \(\to\) mots \(\to\) phrases \(\to\) paragraphes \(\to\) documents.
Ambiguïté : un même mot peut changer de sens selon le contexte (avocat : fruit ou profession).
Dépendances à longue portée : le sens d’un pronom peut dépendre d’un référent éloigné dans le texte.
Définition 274 (Traitement du langage naturel)
Le traitement du langage naturel (NLP) est le sous-domaine de l’intelligence artificielle dédié à l’analyse et à la génération automatique du langage humain. Formellement, étant donné un texte \(\mathbf{x} = (x_1, x_2, \ldots, x_T)\) composé de \(T\) unités linguistiques (tokens), le NLP cherche à apprendre des fonctions \(f\) permettant de :
Comprendre : extraire une représentation structurée \(f(\mathbf{x}) = \mathbf{z} \in \mathbb{R}^d\) capturant le sens du texte.
Générer : produire une séquence \(\mathbf{y} = (y_1, \ldots, y_{T'})\) conditionnée par un contexte.
Transformer : convertir un texte d’entrée en un texte de sortie (traduction, résumé, reformulation).
Le pipeline classique du NLP#
Avant l’ère des modèles pré-entraînés, le NLP suivait un pipeline linéaire : segmentation du texte en phrases, tokenisation, étiquetage morpho-syntaxique (POS tagging), lemmatisation, extraction de caractéristiques manuelles (sac de mots, TF-IDF), puis application d’un classifieur. Aujourd’hui, les modèles de type Transformer apprennent directement des représentations à partir du texte brut, mais la tokenisation reste une étape cruciale.
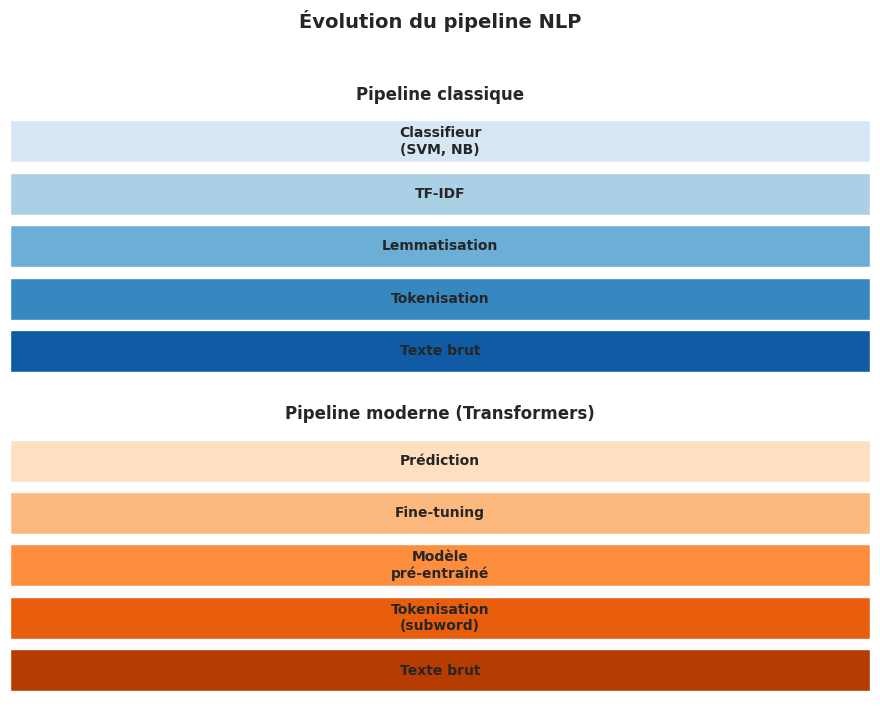
Tokenisation#
La tokenisation est l’opération qui convertit une chaîne de caractères en une séquence d’unités élémentaires — les tokens — que le modèle peut traiter. C’est la toute première étape de tout pipeline NLP, et son choix influence profondément les performances du système.
Tokenisation par mots (word-level)#
L’approche la plus intuitive consiste à découper le texte en mots, par exemple en utilisant les espaces et la ponctuation comme délimiteurs.
Définition 275 (Tokenisation par mots)
La tokenisation par mots (word-level tokenization) segmente un texte en mots individuels :
Le vocabulaire \(\mathcal{V}\) est l’ensemble de tous les tokens distincts rencontrés dans le corpus d’entraînement. Sa taille \(|\mathcal{V}|\) est un hyperparamètre crucial.
Cette approche souffre de plusieurs limitations :
Vocabulaire ouvert : tout mot absent du vocabulaire d’entraînement est inconnu (out-of-vocabulary, OOV).
Formes fléchies : mange, mangeait, mangerons sont des tokens distincts, sans lien explicite.
Taille du vocabulaire : un corpus en français contient facilement plus de 500 000 formes distinctes.
Tokenisation par espaces (12 tokens) :
['Le', 'traitement', 'du', 'langage', 'naturel', 'est', 'un', 'domaine', 'fascinant', 'de', "l'intelligence", 'artificielle.']
Tokenisation avec ponctuation (15 tokens) :
['Le', 'traitement', 'du', 'langage', 'naturel', 'est', 'un', 'domaine', 'fascinant', 'de', 'l', "'", 'intelligence', 'artificielle', '.']
Tokenisation par caractères (character-level)#
À l’autre extrême, on peut tokeniser chaque caractère individuellement. Le vocabulaire est très petit (quelques dizaines de symboles), mais les séquences deviennent très longues, rendant l’apprentissage des dépendances à longue portée difficile.
Tokenisation par caractères (89 tokens) :
['L', 'e', ' ', 't', 'r', 'a', 'i', 't', 'e', 'm', 'e', 'n', 't', ' ', 'd', 'u', ' ', 'l', 'a', 'n', 'g', 'a', 'g', 'e', ' ', 'n', 'a', 't', 'u', 'r'] ...
Vocabulaire : 19 caractères uniques
Tokenisation par sous-mots (subword)#
La tokenisation par sous-mots (subword tokenization) constitue le compromis optimal entre les niveaux mot et caractère. Elle décompose les mots rares en sous-unités fréquentes, tout en conservant les mots courants intacts.
Définition 276 (Tokenisation par sous-mots)
La tokenisation par sous-mots segmente le texte en unités intermédiaires entre le mot et le caractère. Un mot courant reste intact, tandis qu’un mot rare est décomposé :
Les trois algorithmes principaux sont :
BPE (Byte Pair Encoding) : fusionne itérativement les paires de symboles les plus fréquentes.
WordPiece : similaire à BPE, mais sélectionne les fusions maximisant la vraisemblance du modèle de langue.
SentencePiece : traite le texte comme une séquence brute d’octets, sans pré-tokenisation par espaces.
Exemple 30 (Algorithme BPE pas à pas)
Considérons le vocabulaire initial de caractères et le corpus :
Mot |
Fréquence |
|---|---|
l o w |
5 |
l o w e r |
2 |
n e w |
6 |
w i d e r |
3 |
Itération 1 : la paire la plus fréquente est \((l, o)\) avec \(5 + 2 = 7\) occurrences \(\to\) fusion en lo.
Itération 2 : la paire \((lo, w)\) a \(5 + 2 = 7\) occurrences \(\to\) fusion en low.
Itération 3 : la paire \((n, e)\) a \(6\) occurrences \(\to\) fusion en ne.
On continue jusqu’à atteindre la taille de vocabulaire souhaitée.
Fusions BPE :
Étape 1 : w + </w> → w</w> (fréquence : 11)
Étape 2 : l + o → lo (fréquence : 7)
Étape 3 : n + e → ne (fréquence : 6)
Étape 4 : ne + w</w> → new</w> (fréquence : 6)
Étape 5 : lo + w</w> → low</w> (fréquence : 5)
Vocabulaire final :
low</w> (fréquence : 5)
lo w e r </w> (fréquence : 2)
new</w> (fréquence : 6)
w i d e r </w> (fréquence : 3)
Remarque 239
Le choix de la stratégie de tokenisation a un impact majeur sur les performances. Les modèles modernes utilisent presque exclusivement la tokenisation par sous-mots : BERT utilise WordPiece avec un vocabulaire de 30 000 tokens, GPT-2 utilise BPE avec 50 257 tokens, et T5 utilise SentencePiece avec 32 000 tokens. Ce compromis permet de gérer les mots rares sans exploser la taille du vocabulaire.
Représentations vectorielles des mots#
Pour qu’un réseau de neurones puisse traiter du texte, il faut convertir les tokens discrets en vecteurs numériques. La qualité de cette représentation vectorielle — appelée embedding ou plongement — est déterminante pour les performances du modèle.
Encodage one-hot#
L’approche la plus simple consiste à représenter chaque token par un vecteur one-hot.
Définition 277 (Encodage one-hot)
Étant donné un vocabulaire \(\mathcal{V}\) de taille \(V\), l”encodage one-hot associe à chaque token \(w_i \in \mathcal{V}\) un vecteur \(\mathbf{e}_i \in \{0, 1\}^V\) tel que :
Ce codage présente deux limitations majeures :
Dimensionnalité : les vecteurs sont de dimension \(V\) (typiquement \(10^4\) à \(10^5\)), ce qui est extrêmement creux.
Absence de sémantique : \(\langle \mathbf{e}_i, \mathbf{e}_j \rangle = 0\) pour tout \(i \neq j\), donc roi est aussi distant de reine que de table.
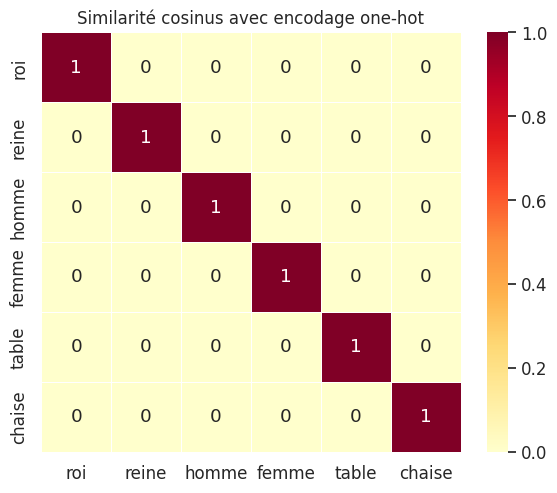
Avec le one-hot, tous les mots sont également distants les uns des autres.
Word2Vec#
Le modèle Word2Vec, proposé par Mikolov et al. en 2013, a révolutionné le NLP en montrant qu’il est possible d’apprendre des représentations vectorielles denses et sémantiques des mots à partir de grands corpus non annotés, en exploitant une idée simple : un mot est caractérisé par la compagnie qu’il tient (hypothèse distributionnelle de Firth, 1957).
Définition 278 (Word2Vec)
Word2Vec apprend un plongement \(\mathbf{w} \in \mathbb{R}^d\) pour chaque mot du vocabulaire, où \(d \ll V\) (typiquement \(d = 100\) à \(300\)). Deux architectures sont proposées :
Skip-gram : prédit les mots du contexte à partir du mot central. Étant donné un mot cible \(w_t\), le modèle maximise la probabilité des mots voisins dans une fenêtre de taille \(c\) :
où la probabilité est définie par un softmax :
CBOW (Continuous Bag of Words) : prédit le mot central à partir de la moyenne des vecteurs de contexte :
Remarque 240
Le calcul du dénominateur du softmax nécessite une somme sur tout le vocabulaire \(V\), ce qui est prohibitif. L”échantillonnage négatif (negative sampling) remplace ce calcul par une classification binaire : pour chaque paire positive \((w_t, w_{t+j})\), on échantillonne \(k\) mots négatifs. L’objectif devient :
où \(P_n(w) \propto f(w)^{3/4}\) est la distribution de bruit basée sur la fréquence des mots.
Skip-gram : 100,000 paramètres
- Embeddings centraux : 1000 × 50 = 50,000
- Embeddings contexte : 1000 × 50 = 50,000
GloVe#
GloVe (Global Vectors for Word Representation), proposé par Pennington et al. en 2014, combine les avantages des méthodes par co-occurrence (comme LSA) et des méthodes prédictives (comme Word2Vec). L’idée centrale est de factoriser la matrice de co-occurrence des mots.
Définition 279 (GloVe)
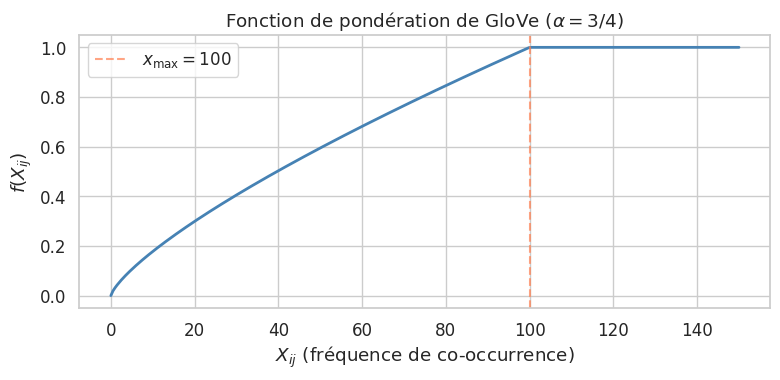
Soit \(X_{ij}\) le nombre de fois où le mot \(j\) apparaît dans le contexte du mot \(i\) dans le corpus. GloVe minimise la fonction de coût pondérée :
où \(\mathbf{w}_i, \tilde{\mathbf{w}}_j \in \mathbb{R}^d\) sont les vecteurs du mot et du contexte, \(b_i, \tilde{b}_j\) sont des biais, et \(f\) est une fonction de pondération qui limite l’influence des co-occurrences très fréquentes :
avec typiquement \(x_{\max} = 100\) et \(\alpha = 3/4\).
Propriétés des embeddings#
Les embeddings de mots capturent des régularités sémantiques et syntaxiques remarquables, que l’on peut explorer par des opérations algébriques simples dans l’espace vectoriel.
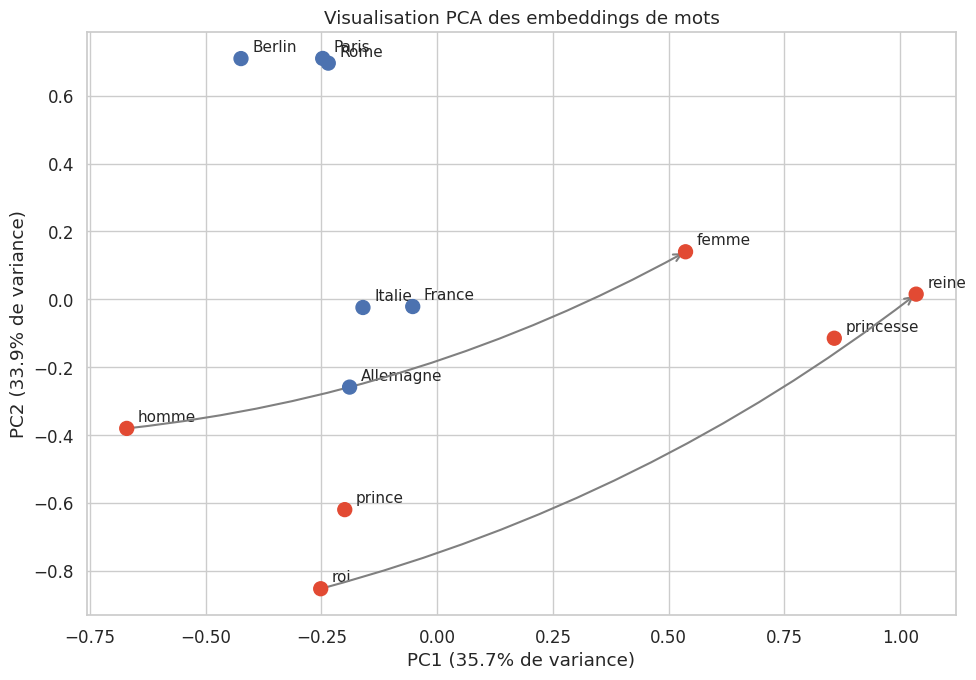
Exemple 31 (Analogies vectorielles)
Les embeddings de Word2Vec et GloVe permettent de résoudre des analogies de la forme A est à B ce que C est à D par simple arithmétique vectorielle :
Ces régularités émergent de l’entraînement sur de grands corpus sans aucune supervision explicite de ces relations.
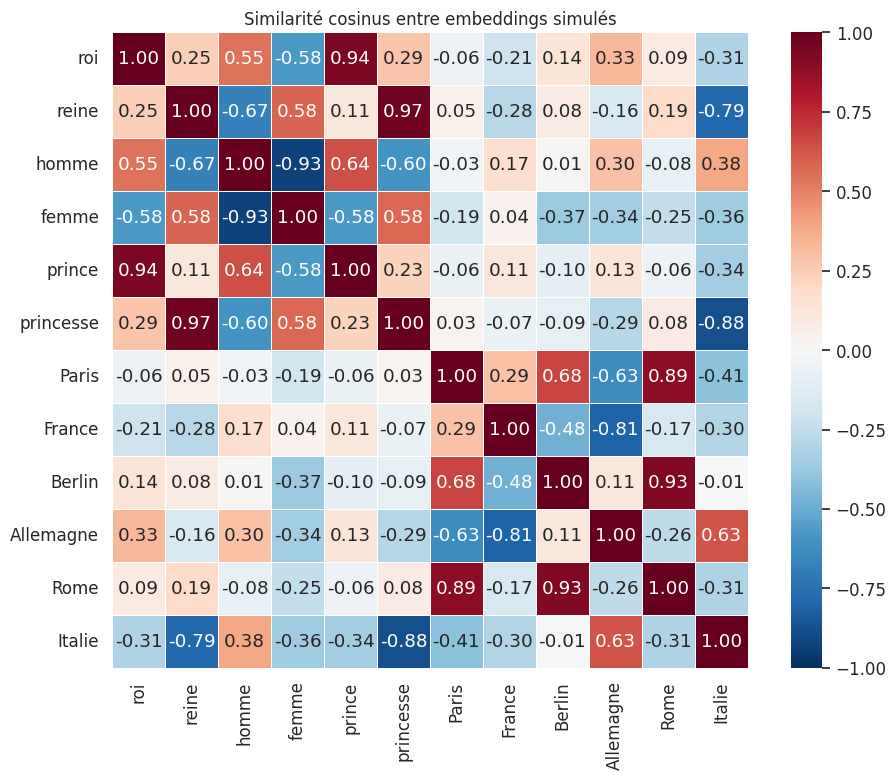
Analogie : roi - homme + femme = ?
reine (similarité : 0.959)
princesse (similarité : 0.956)
prince (similarité : 0.330)
Analogie : France - Paris + Berlin = ?
Allemagne (similarité : 0.882)
Italie (similarité : 0.538)
roi (similarité : 0.266)
Visualisation par réduction de dimensionnalité#
Comme introduit au chapitre 12, les techniques de réduction de dimensionnalité comme t-SNE et PCA permettent de projeter les embeddings de haute dimension dans un espace 2D pour les visualiser.
Modèles de langue#
Un modèle de langue est un modèle probabiliste qui assigne une probabilité à toute séquence de mots. Il est au coeur du NLP moderne, car les modèles pré-entraînés (BERT, GPT) sont fondamentalement des modèles de langue.
Modèles N-gram#
Définition 280 (Modèle de langue N-gram)
Un modèle de langue assigne une probabilité à une séquence de mots \(\mathbf{w} = (w_1, \ldots, w_T)\) :
Un modèle N-gram approxime cette probabilité en supposant que la distribution de \(w_t\) ne dépend que des \(N-1\) mots précédents (hypothèse de Markov d’ordre \(N-1\)) :
Les probabilités sont estimées par comptage sur le corpus :
Les modèles N-gram sont simples et rapides, mais limités : ils ne capturent pas les dépendances au-delà de la fenêtre de \(N-1\) mots, et souffrent de la parcimonie des données (de nombreux N-grams n’apparaissent jamais dans le corpus).
Modèles de langue neuronaux#
Les modèles de langue neuronaux remplacent la table de comptage par un réseau de neurones qui apprend des représentations continues. Initialement basés sur des RNN (chapitre 20), les modèles de langue modernes reposent sur l’architecture Transformer (chapitre 23).
Modèle de langue RNN : 2,320,264 paramètres
Entrée : torch.Size([2, 20]) → Logits : torch.Size([2, 20, 5000])
Perplexité#
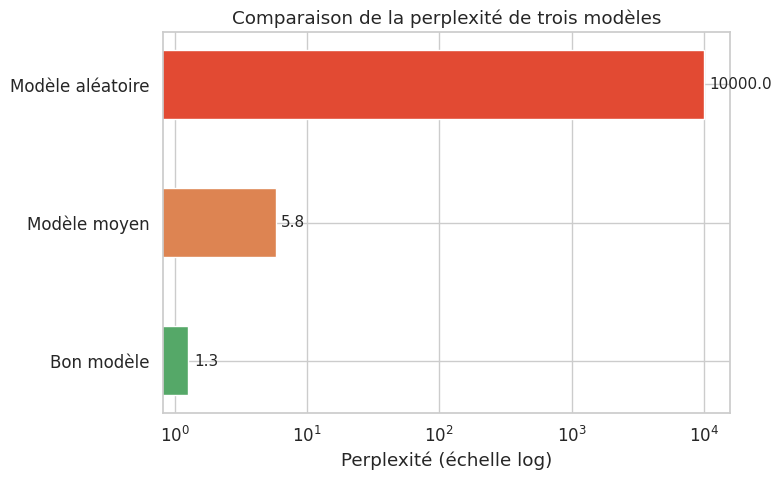
La perplexité est la métrique standard pour évaluer les modèles de langue.
Définition 281 (Perplexité)
La perplexité d’un modèle de langue sur une séquence test \(\mathbf{w} = (w_1, \ldots, w_T)\) est définie comme l’exponentielle de l’entropie croisée moyenne :
La perplexité peut s’interpréter comme le nombre moyen de choix que le modèle hésite entre à chaque position. Un modèle parfait (qui prédit avec certitude le bon mot) a une perplexité de 1. Un modèle aléatoire uniforme sur un vocabulaire de \(V\) mots a une perplexité de \(V\).
Modèles pré-entraînés#
La révolution majeure du NLP depuis 2018 est le paradigme pré-entraînement puis fine-tuning (pre-train then fine-tune). Des modèles massifs sont d’abord pré-entraînés sur d’immenses corpus de texte non annoté (apprentissage auto-supervisé), puis adaptés (fine-tuned) à des tâches spécifiques avec un jeu de données étiqueté beaucoup plus petit.
BERT#
Définition 282 (BERT)
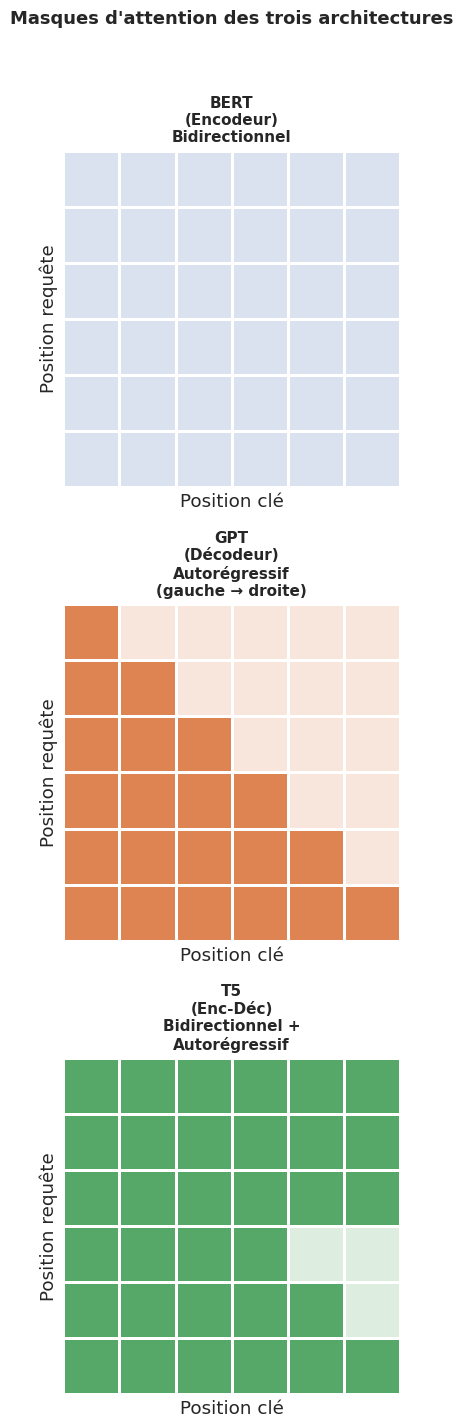
BERT (Bidirectional Encoder Representations from Transformers), proposé par Devlin et al. en 2018, est un encodeur Transformer pré-entraîné avec deux objectifs :
Modélisation de langue masquée (Masked Language Modeling, MLM) : 15 % des tokens sont masqués aléatoirement, et le modèle doit les prédire à partir du contexte bidirectionnel :
où \(\mathcal{M}\) est l’ensemble des positions masquées.
Prédiction de phrase suivante (Next Sentence Prediction, NSP) : le modèle prédit si deux segments de texte se suivent dans le corpus original.
L’architecture est un encodeur Transformer empilé :
BERT-base : 12 couches, 768 dimensions cachées, 12 têtes d’attention, 110M paramètres.
BERT-large : 24 couches, 1024 dimensions, 16 têtes, 340M paramètres.
Phrase originale : Le chat noir dort sur le canapé rouge
Phrase masquée : Le chat noir dort sur le [MASK] rouge
Objectif MLM : prédire les tokens masqués à partir du contexte bidirectionnel.
Tokens masqués : ['canapé']
GPT#
Définition 283 (GPT)
GPT (Generative Pre-trained Transformer), proposé par Radford et al. en 2018, est un décodeur Transformer pré-entraîné avec un objectif de modélisation de langue autoregressif :
Contrairement à BERT, GPT ne voit que le contexte à gauche (passé) grâce à un masque d’attention causal. Cette contrainte autoregressive rend GPT naturellement adapté à la génération de texte.
Les versions successives diffèrent principalement par leur taille :
GPT-1 : 12 couches, 117M paramètres.
GPT-2 : 48 couches, 1.5B paramètres.
GPT-3 : 96 couches, 175B paramètres.
T5#
Définition 284 (T5)
T5 (Text-to-Text Transfer Transformer), proposé par Raffel et al. en 2020, reformule toutes les tâches NLP comme des problèmes de texte-vers-texte (text-to-text). L’architecture est un Transformer encodeur-décodeur complet.
Exemples de reformulation :
Classification : entrée =
"sentiment: Ce film est excellent"\(\to\) sortie ="positif"Traduction : entrée =
"translate English to French: Hello"\(\to\) sortie ="Bonjour"Résumé : entrée =
"summarize: [long texte]"\(\to\) sortie ="[résumé]"
Le pré-entraînement utilise un objectif de débruitage (span corruption) sur le corpus C4 (Colossal Clean Crawled Corpus).
Remarque 241
Le tableau suivant résume les différences architecturales entre les trois familles de modèles pré-entraînés :
Caractéristique |
BERT |
GPT |
T5 |
|---|---|---|---|
Architecture |
Encodeur seul |
Décodeur seul |
Encodeur-Décodeur |
Pré-entraînement |
MLM + NSP |
Autorégressif |
Span corruption |
Contexte |
Bidirectionnel |
Gauche → droite |
Bidirectionnel (enc.) + autorégressif (déc.) |
Force |
Compréhension |
Génération |
Polyvalence |
Taille (base) |
110M params |
117M params |
220M params |
Cas d’usage |
Classification, NER, QA extractif |
Génération, complétion |
Toute tâche seq2seq |
Fine-tuning#
Le paradigme de l’apprentissage par transfert en NLP#
Le fine-tuning consiste à adapter un modèle pré-entraîné à une tâche spécifique en continuant l’entraînement sur un jeu de données étiqueté, typiquement beaucoup plus petit que le corpus de pré-entraînement. C’est l’équivalent NLP du transfer learning étudié pour les CNN au chapitre 19.
Définition 285 (Fine-tuning)
Le fine-tuning d’un modèle pré-entraîné \(f_\theta\) pour une tâche cible consiste à :
Initialiser le modèle avec les poids pré-entraînés \(\theta_{\text{pre}}\).
Ajouter une tête de classification (classification head) adaptée à la tâche : typiquement une couche linéaire \(\mathbf{W} \in \mathbb{R}^{d \times C}\) au-dessus de la représentation du token
[CLS].Entraîner l’ensemble des paramètres \((\theta, \mathbf{W})\) sur le jeu de données étiqueté avec un taux d’apprentissage faible (\(\eta \sim 2 \times 10^{-5}\) à \(5 \times 10^{-5}\)).
La fonction de coût pour une tâche de classification à \(C\) classes est l’entropie croisée :
où \(\hat{y}_{ic} = \text{softmax}(\mathbf{W}\, f_\theta(\mathbf{x}_i)_{[\text{CLS}]})_c\).
Paramètres totaux : 108,096,771
Paramètres de la tête de classification : 2,307
Proportion de nouveaux paramètres : 0.0021%
Remarque 242
Quelques bonnes pratiques pour le fine-tuning :
Taux d’apprentissage : utiliser un taux faible (\(2 \times 10^{-5}\)) pour ne pas détruire les représentations pré-entraînées.
Échauffement (warmup) : augmenter progressivement le taux d’apprentissage pendant les premières itérations.
Nombre d’époques : 2 à 5 époques suffisent généralement pour le fine-tuning.
Gel des couches (freezing) : on peut geler les premières couches du modèle et ne fine-tuner que les couches supérieures, surtout si les données sont peu nombreuses.
Taux d’apprentissage discriminatif : appliquer des taux d’apprentissage décroissants selon la profondeur des couches.
Exemple : analyse de sentiments#
L’analyse de sentiments — déterminer si un texte exprime une opinion positive, négative ou neutre — est l’une des tâches NLP les plus courantes et un excellent cas d’application du fine-tuning.
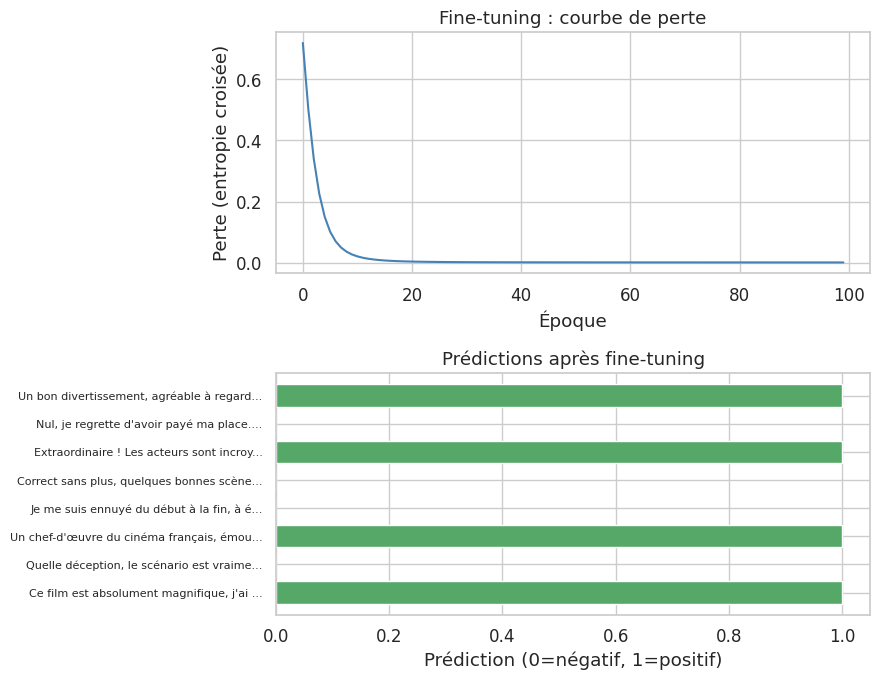
Précision sur l'entraînement : 100%
Hugging Face : l’écosystème du NLP moderne#
La bibliothèque Hugging Face Transformers est devenue l’outil de référence pour le NLP appliqué. Elle fournit une interface unifiée pour des milliers de modèles pré-entraînés, des tokenizers optimisés et des pipelines prêts à l’emploi.
L’API Pipeline#
L’API pipeline permet d’utiliser un modèle pré-entraîné en une seule ligne de code, en encapsulant la tokenisation, l’inférence et le post-traitement.
Exemple 32 (Utilisation de l’API Pipeline)
from transformers import pipeline
# Analyse de sentiments
classifieur = pipeline("sentiment-analysis")
resultat = classifieur("Ce film est vraiment excellent !")
# [{'label': 'POSITIVE', 'score': 0.9998}]
# Génération de texte
generateur = pipeline("text-generation", model="gpt2")
texte = generateur("Le traitement du langage naturel", max_length=50)
# Question-réponse
qa = pipeline("question-answering")
resultat = qa(question="Qui a inventé BERT ?",
context="BERT a été proposé par Devlin et al. chez Google en 2018.")
# {'answer': 'Devlin et al. chez Google', 'score': 0.92}
Les pipelines disponibles incluent : sentiment-analysis, ner, question-answering, summarization, translation, text-generation, fill-mask, zero-shot-classification, entre autres.
Tokenizers Hugging Face#
Texte : Le chat mange du poisson
Tokens : ['[CLS]', 'le', 'chat', 'mange', 'du', 'poisson', '[SEP]']
IDs : [2, 5, 6, 7, 8, 9, 3]
Longueur : 7 tokens
Remarque 243
Les tokenizers modernes ajoutent des tokens spéciaux qui jouent des rôles précis :
[CLS]: placé en début de séquence, sa représentation finale sert pour la classification.[SEP]: sépare deux segments (utile pour les tâches de paires de phrases).[MASK]: remplace un token dans l’objectif MLM de BERT.[PAD]: complète les séquences courtes pour former des batches de taille fixe.
Ces tokens sont essentiels au bon fonctionnement des modèles pré-entraînés.
Le Model Hub#
Le Model Hub de Hugging Face héberge plus de 500 000 modèles pré-entraînés couvrant des dizaines de langues et de tâches. Pour le français, les modèles les plus utilisés sont :
CamemBERT : un modèle BERT entraîné sur un large corpus en français (138 Go de texte).
FlauBERT : un autre modèle de type BERT pour le français.
Mistral / LLaMA : des modèles de type GPT multilingues avec de bonnes performances en français.
Exemple 33 (Fine-tuning avec Hugging Face Transformers)
Voici le schéma typique d’un fine-tuning avec la bibliothèque Transformers :
from transformers import (
AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
)
from datasets import load_dataset
# 1. Charger les données
dataset = load_dataset("allocine") # Critiques de films en français
# 2. Charger le modèle et le tokenizer pré-entraînés
model_name = "camembert-base"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# 3. Tokeniser le dataset
def preprocess(examples):
return tokenizer(examples["review"], truncation=True, padding="max_length", max_length=256)
tokenized = dataset.map(preprocess, batched=True)
# 4. Configurer l'entraînement
args = TrainingArguments(
output_dir="./resultats",
num_train_epochs=3,
per_device_train_batch_size=16,
learning_rate=2e-5,
warmup_steps=500,
evaluation_strategy="epoch",
)
# 5. Entraîner
trainer = Trainer(model=model, args=args, train_dataset=tokenized["train"],
eval_dataset=tokenized["test"])
trainer.train()
Ce code fine-tune CamemBERT pour la classification de sentiments sur le dataset Allociné (critiques de films en français) en quelques dizaines de lignes.
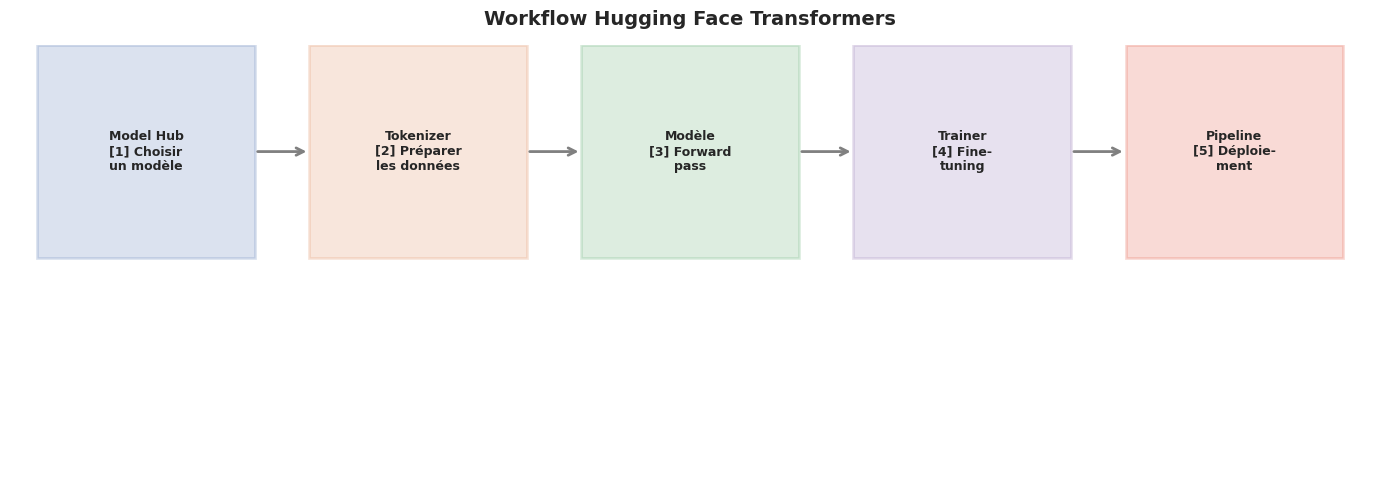
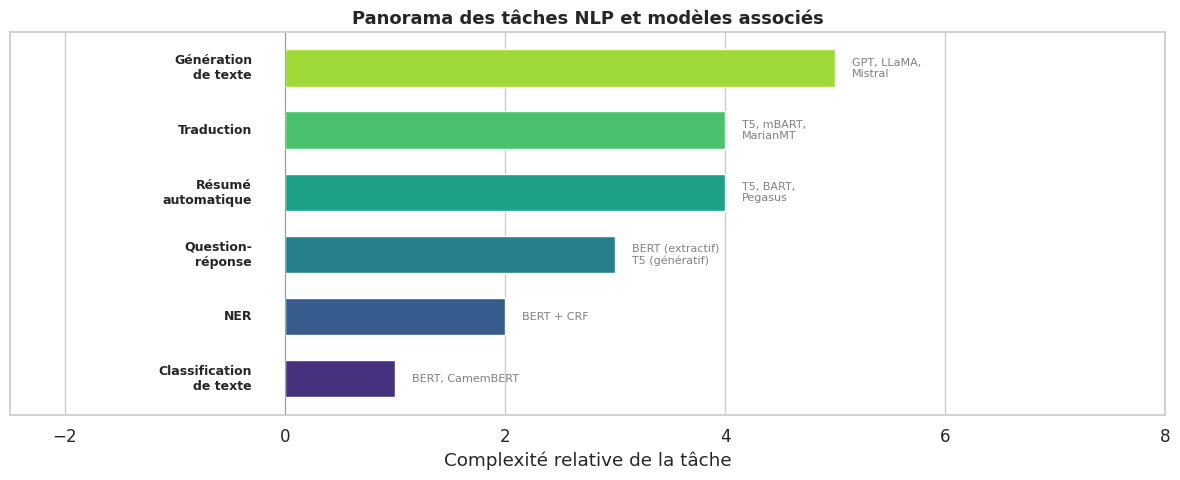
Applications du NLP#
Le NLP couvre un spectre très large d’applications. Cette section présente les tâches les plus importantes avec leurs formulations et leurs modèles associés.
Classification de texte#
La classification de texte consiste à attribuer une ou plusieurs catégories à un document. C’est la tâche NLP la plus courante, avec des applications comme l’analyse de sentiments, la détection de spam, la catégorisation de documents et la détection de langue.
Exemple 34 (Tâches de classification de texte)
Tâche |
Entrée |
Sortie |
Modèle typique |
|---|---|---|---|
Analyse de sentiments |
« Ce restaurant est excellent » |
Positif |
BERT fine-tuné |
Détection de spam |
« Gagnez 1000€ maintenant ! » |
Spam |
CamemBERT fine-tuné |
Catégorisation |
Article de presse |
Sport / Politique / … |
RoBERTa fine-tuné |
Inférence textuelle |
Prémisse + Hypothèse |
Contradiction / Implication / Neutre |
BERT fine-tuné |
Reconnaissance d’entités nommées (NER)#
La reconnaissance d’entités nommées (Named Entity Recognition, NER) consiste à identifier et classifier les entités mentionnées dans un texte : personnes, organisations, lieux, dates, montants, etc.
Définition 286 (Reconnaissance d’entités nommées)
Le NER est une tâche de classification au niveau du token : pour chaque token \(w_t\) d’une séquence, le modèle prédit une étiquette \(y_t \in \{\text{O}, \text{B-PER}, \text{I-PER}, \text{B-ORG}, \text{I-ORG}, \text{B-LOC}, \text{I-LOC}, \ldots\}\) selon le schéma BIO (Begin, Inside, Outside) :
Exemple :
Token |
Victor |
Hugo |
est |
né |
à |
Besançon |
|---|---|---|---|---|---|---|
Étiquette |
B-PER |
I-PER |
O |
O |
O |
B-LOC |

Question-réponse (Question Answering)#
La tâche de question-réponse consiste à extraire ou générer une réponse à une question à partir d’un contexte donné.
Exemple 35 (Types de question-réponse)
Il existe principalement deux paradigmes :
QA extractif : la réponse est un extrait (span) du contexte. Le modèle prédit les positions de début et de fin de la réponse.
Contexte : « BERT a été proposé par Devlin et al. en 2018 chez Google. »
Question : « Quand BERT a-t-il été proposé ? »
Réponse : « en 2018 » (positions 8 à 9)
QA génératif : la réponse est générée librement, sans contrainte d’extraction. Les modèles T5 et GPT sont adaptés à cette approche.
Résumé automatique et traduction#
Le résumé automatique et la traduction automatique sont des tâches de type séquence-vers-séquence (seq2seq) naturellement traitées par les architectures encodeur-décodeur (T5, mBART) ou les modèles autorégressifs (GPT). Comme étudié au chapitre 23, le mécanisme d’attention croisée du Transformer est particulièrement adapté à ces tâches, car il permet au décodeur de se concentrer sur les parties pertinentes de la séquence d’entrée.
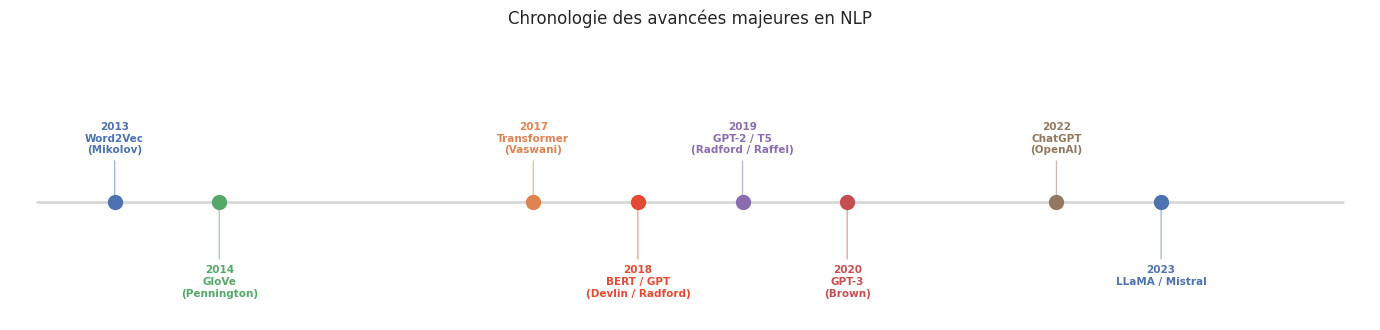
Résumé#
Ce chapitre a présenté les concepts fondamentaux du traitement du langage naturel, depuis la représentation du texte jusqu’aux modèles pré-entraînés modernes.
La tokenisation est la première étape de tout pipeline NLP. La tokenisation par sous-mots (BPE, WordPiece, SentencePiece) offre le meilleur compromis entre gestion du vocabulaire ouvert et longueur des séquences.
Les représentations vectorielles des mots (Word2Vec, GloVe) permettent de capturer la sémantique dans un espace continu de faible dimension, où les relations entre mots se traduisent par des régularités géométriques (analogies, similarités).
Les modèles de langue assignent des probabilités aux séquences de mots. Des modèles N-gram aux réseaux de neurones, leur qualité se mesure par la perplexité.
Les modèles pré-entraînés — BERT (encodeur bidirectionnel), GPT (décodeur autorégressif) et T5 (encodeur-décodeur) — ont transformé le NLP en montrant que des représentations universelles du langage peuvent être apprises de manière auto-supervisée sur de grands corpus.
Le fine-tuning permet d’adapter ces modèles massifs à des tâches spécifiques avec peu de données étiquetées, constituant le paradigme dominant du NLP moderne.
L’écosystème Hugging Face (Transformers, Model Hub, Datasets) fournit une interface unifiée et accessible pour exploiter ces modèles en quelques lignes de code.
Les applications du NLP couvrent un spectre très large : classification, NER, question-réponse, résumé, traduction et génération de texte. La tendance actuelle est aux grands modèles de langue (Large Language Models, LLM) de plus en plus polyvalents.
Remarque 244
Le NLP a connu une accélération sans précédent depuis l’introduction du Transformer (chapitre 23). Les frontières entre comprendre et générer du texte s’estompent avec l’émergence de modèles de plus en plus grands et polyvalents. Cependant, les concepts fondamentaux — tokenisation, embeddings, modèles de langue, fine-tuning — restent les briques élémentaires indispensables pour comprendre, utiliser et évaluer ces systèmes. La maîtrise de ces fondamentaux permet de naviguer avec discernement dans un domaine en évolution rapide.