
Clustering#
Les choses se rassemblent naturellement par affinités ; la tâche du savant est de découvrir l’ordre caché sous l’apparent désordre.
Carl von Linné
Le clustering (ou partitionnement, regroupement) est la tâche fondamentale de l’apprentissage non supervisé : étant donné un ensemble d’observations sans étiquettes, il s’agit de les répartir en groupes homogènes (appelés clusters) de sorte que les observations d’un même groupe soient similaires entre elles et dissemblables de celles des autres groupes. Contrairement à la classification supervisée, aucune information sur la structure attendue n’est fournie à l’algorithme — celui-ci doit la découvrir seul à partir des données.
Les applications du clustering sont omniprésentes : segmentation de clientèle en marketing, compression d’images par quantification vectorielle, regroupement de gènes en bioinformatique, détection de communautés dans les réseaux sociaux, organisation automatique de documents, ou encore détection d’anomalies. Ce chapitre présente les méthodes principales — des plus classiques (K-Means, clustering hiérarchique) aux approches par densité (DBSCAN, OPTICS) et probabilistes (modèles de mélange gaussien) — ainsi que les outils d’évaluation qui permettent de juger la qualité d’un partitionnement.
Taxonomie des méthodes de clustering#
Avant de détailler chaque algorithme, il est utile de dresser une carte des grandes familles de méthodes :
Méthodes par partitionnement : elles cherchent à diviser les données en \(k\) groupes non chevauchants en optimisant un critère global (K-Means, K-Medoids).
Méthodes hiérarchiques : elles construisent une hiérarchie emboîtée de clusters, soit par agglomération (bottom-up), soit par division (top-down).
Méthodes par densité : elles définissent les clusters comme des régions de haute densité séparées par des régions de basse densité (DBSCAN, OPTICS).
Méthodes basées sur des modèles : elles supposent que les données sont générées par un mélange de distributions et estiment les paramètres de ce mélange (Gaussian Mixture Models).
Chaque famille possède ses hypothèses, ses forces et ses limites. Le choix de la méthode dépend fondamentalement de la géométrie attendue des clusters, de la taille du jeu de données et de la présence éventuelle de bruit.
K-Means#
L’algorithme K-Means est sans doute la méthode de clustering la plus connue et la plus utilisée. Il cherche à partitionner \(n\) observations en \(k\) clusters en minimisant la somme des distances au carré entre chaque observation et le centroïde de son cluster.
Définition 148 (Problème K-Means)
Soit \(\mathcal{X} = \{\mathbf{x}_1, \ldots, \mathbf{x}_n\} \subset \mathbb{R}^d\) un ensemble de \(n\) observations. Le problème K-Means consiste à trouver une partition \(\{C_1, \ldots, C_k\}\) de \(\mathcal{X}\) et des centroïdes \(\{\boldsymbol{\mu}_1, \ldots, \boldsymbol{\mu}_k\} \subset \mathbb{R}^d\) qui minimisent l”inertie (ou within-cluster sum of squares, WCSS) :
où \(\boldsymbol{\mu}_j = \frac{1}{|C_j|} \sum_{\mathbf{x}_i \in C_j} \mathbf{x}_i\) est le centroïde du cluster \(C_j\).
Ce problème d’optimisation est NP-difficile dans le cas général, mais l’algorithme de Lloyd fournit une heuristique efficace qui converge vers un minimum local.
Algorithme de Lloyd#
Définition 149 (Algorithme de Lloyd (K-Means))
L’algorithme de Lloyd procède par itérations alternées de deux étapes :
Étape d’affectation : chaque observation est assignée au cluster dont le centroïde est le plus proche :
Étape de mise à jour : chaque centroïde est recalculé comme la moyenne des observations de son cluster :
L’algorithme s’arrête lorsque les affectations ne changent plus (ou que la variation de \(J\) est inférieure à un seuil \(\varepsilon\)).
Proposition 41 (Convergence de K-Means)
L’algorithme de Lloyd fait décroître (au sens large) l’inertie \(J\) à chaque itération. Puisque le nombre de partitions possibles est fini, l’algorithme converge en un nombre fini d’itérations vers un minimum local de \(J\). Cependant, ce minimum local peut être très éloigné du minimum global.
Proof. À l’étape d’affectation, chaque point est assigné au centroïde le plus proche, ce qui ne peut que diminuer (ou laisser inchangée) la somme \(J\). À l’étape de mise à jour, le nouveau centroïde est la moyenne des points du cluster, qui minimise la somme des distances au carré dans ce cluster (par propriété du barycentre). Ainsi, \(J^{(t+1)} \leq J^{(t)}\) à chaque itération. Comme \(J \geq 0\) et que la suite est décroissante et bornée inférieurement, elle converge. Le nombre fini de partitions possibles garantit la terminaison en un nombre fini d’étapes.
Initialisation K-Means++#
La qualité du résultat dépend fortement de l’initialisation. L’initialisation aléatoire peut conduire à des résultats médiocres. L’algorithme K-Means++ propose une initialisation intelligente.
Définition 150 (Initialisation K-Means++)
L’initialisation K-Means++ choisit les centroïdes initiaux de manière séquentielle :
Choisir \(\boldsymbol{\mu}_1\) uniformément au hasard parmi les observations.
Pour \(j = 2, \ldots, k\) : choisir \(\boldsymbol{\mu}_j = \mathbf{x}_i\) avec une probabilité proportionnelle à
Autrement dit, les points éloignés des centroïdes déjà choisis ont une plus grande probabilité d’être sélectionnés.
Proposition 42 (Garantie K-Means++)
L’initialisation K-Means++ garantit en espérance que l’inertie initiale vérifie
où \(J^*\) est la valeur optimale de l’inertie. Cette garantie est \(O(\log k)\)-compétitive.
La complexité de l’algorithme K-Means est \(O(n \cdot k \cdot d \cdot T)\) où \(T\) est le nombre d’itérations, ce qui le rend très efficace pour de grands jeux de données.
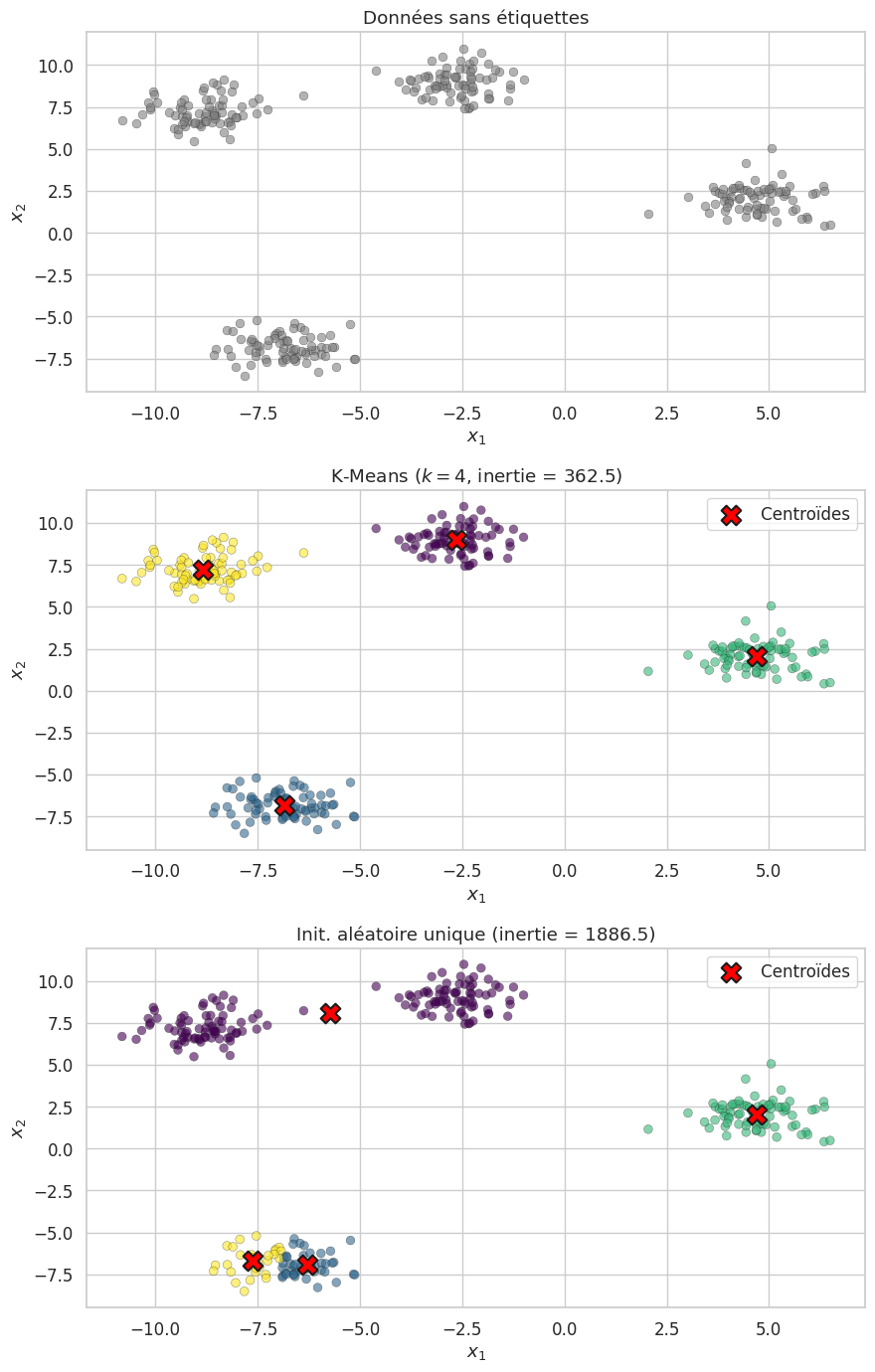
Remarque 141
K-Means suppose implicitement que les clusters sont sphériques (isotropes) et de tailles comparables. Lorsque les clusters ont des formes allongées, des densités inégales ou des tailles très différentes, K-Means peut produire des partitions sous-optimales.
Choix du nombre de clusters#
Le paramètre \(k\) doit être fixé à l’avance dans K-Means. Plusieurs heuristiques permettent de guider ce choix.
Méthode du coude (Elbow Method)#
La méthode du coude consiste à tracer l’inertie \(J(k)\) en fonction de \(k\) et à repérer le point d’inflexion — le « coude » — au-delà duquel l’ajout d’un cluster supplémentaire n’apporte qu’une réduction marginale de l’inertie.
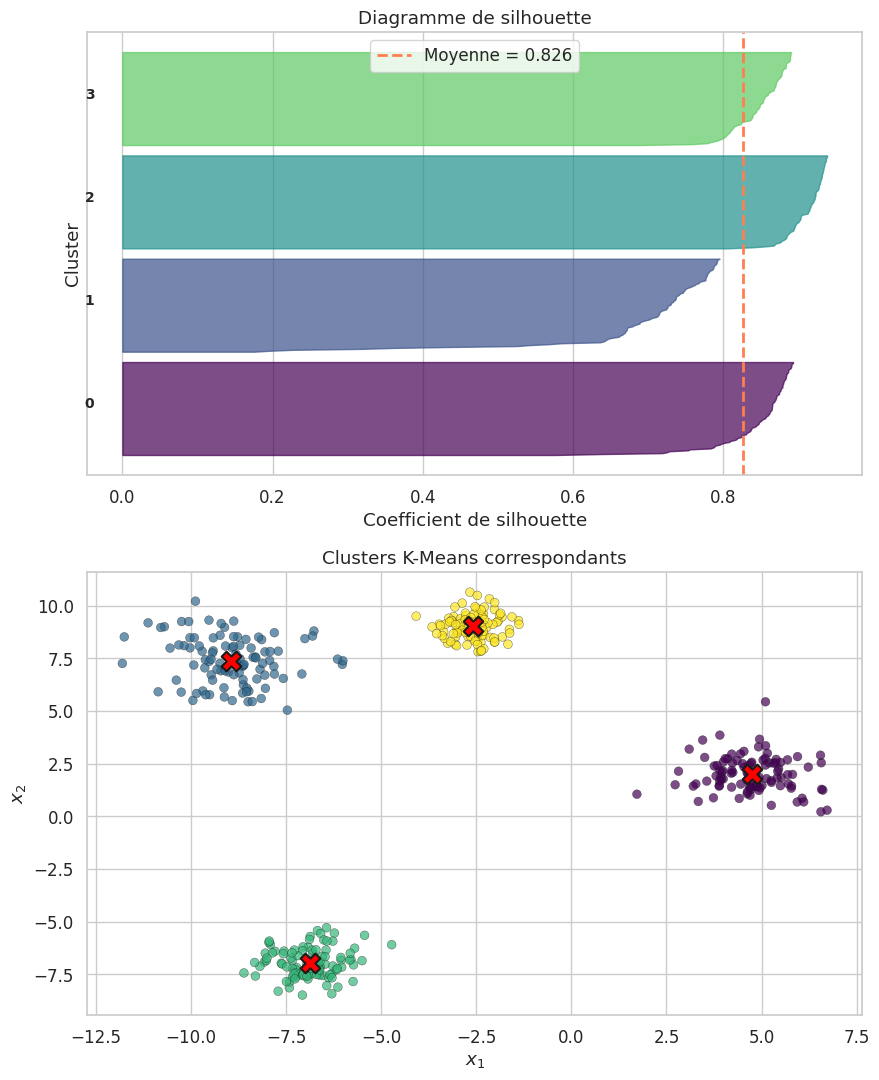
Score de silhouette#
Définition 151 (Score de silhouette)
Pour une observation \(\mathbf{x}_i\) appartenant au cluster \(C_j\), on définit :
\(a(\mathbf{x}_i) = \frac{1}{|C_j| - 1} \sum_{\mathbf{x}_l \in C_j,\, l \neq i} \|\mathbf{x}_i - \mathbf{x}_l\|\) : la distance intra-cluster moyenne.
\(b(\mathbf{x}_i) = \min_{m \neq j} \frac{1}{|C_m|} \sum_{\mathbf{x}_l \in C_m} \|\mathbf{x}_i - \mathbf{x}_l\|\) : la distance moyenne au cluster le plus proche.
Le coefficient de silhouette de \(\mathbf{x}_i\) est :
Il vérifie \(s(\mathbf{x}_i) \in [-1, 1]\). Une valeur proche de \(1\) indique que l’observation est bien assignée ; une valeur proche de \(-1\) indique une mauvaise assignation.
Indices Calinski-Harabasz et Davies-Bouldin#
Définition 152 (Indice de Calinski-Harabasz)
L’indice de Calinski-Harabasz (ou Variance Ratio Criterion) est défini par :
où \(\text{SS}_B = \sum_{j=1}^k |C_j| \|\boldsymbol{\mu}_j - \boldsymbol{\mu}\|^2\) est la dispersion inter-clusters et \(\text{SS}_W = \sum_{j=1}^k \sum_{\mathbf{x}_i \in C_j} \|\mathbf{x}_i - \boldsymbol{\mu}_j\|^2\) est la dispersion intra-clusters. Un indice élevé indique des clusters denses et bien séparés.
Définition 153 (Indice de Davies-Bouldin)
L’indice de Davies-Bouldin mesure la similarité moyenne entre chaque cluster et celui qui lui ressemble le plus :
où \(s_j = \frac{1}{|C_j|} \sum_{\mathbf{x}_i \in C_j} \|\mathbf{x}_i - \boldsymbol{\mu}_j\|\) est la dispersion moyenne du cluster \(C_j\). Un indice faible indique un meilleur partitionnement.
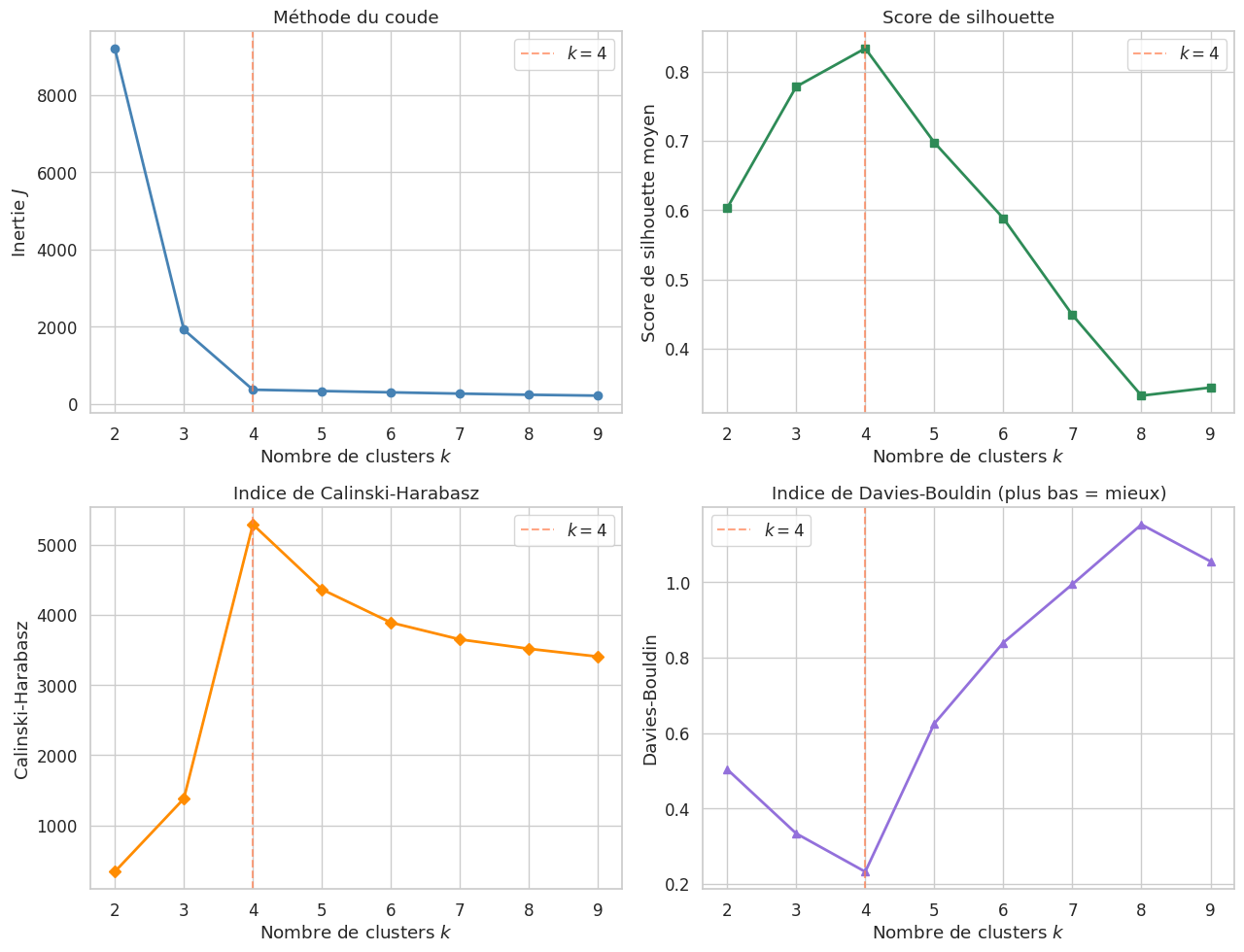
Les quatre critères convergent vers \(k = 4\) : le coude dans la courbe d’inertie, le maximum du score de silhouette, le maximum de l’indice de Calinski-Harabasz et le minimum de l’indice de Davies-Bouldin.
Mini-Batch K-Means#
Lorsque le jeu de données est très volumineux, l’algorithme K-Means standard peut être coûteux. Le Mini-Batch K-Means propose une approximation stochastique qui traite à chaque itération un sous-échantillon aléatoire (mini-batch) au lieu de l’ensemble des données.
Définition 154 (Mini-Batch K-Means)
À chaque itération \(t\) :
Tirer un mini-batch \(\mathcal{B}^{(t)} \subset \mathcal{X}\) de taille \(b \ll n\).
Affecter chaque \(\mathbf{x}_i \in \mathcal{B}^{(t)}\) au centroïde le plus proche.
Mettre à jour les centroïdes par une moyenne mobile pondérée : pour chaque centroïde \(\boldsymbol{\mu}_j\) ayant reçu des points du mini-batch,
où \(n_j\) est le nombre cumulé de points assignés à \(C_j\) depuis le début.
Remarque 142
Le Mini-Batch K-Means produit des résultats légèrement moins bons que K-Means en termes d’inertie, mais il est considérablement plus rapide pour de grands jeux de données, avec une complexité par itération de \(O(b \cdot k \cdot d)\) au lieu de \(O(n \cdot k \cdot d)\).
Méthode Temps (s) Inertie Silhouette
-----------------------------------------------------------------
K-Means 0.705 87433 0.499
Mini-Batch K-Means 0.021 92518 0.577
Clustering hiérarchique#
Le clustering hiérarchique construit une hiérarchie emboîtée de clusters, représentée sous forme d’un arbre binaire appelé dendrogramme. L’approche agglomérative (la plus courante) procède de manière ascendante : chaque observation commence comme son propre cluster, puis les clusters les plus proches sont fusionnés itérativement.
Définition 155 (Clustering agglomératif)
L’algorithme de clustering agglomératif procède comme suit :
Initialiser \(n\) clusters singletons : \(C_i = \{\mathbf{x}_i\}\) pour \(i = 1, \ldots, n\).
Tant qu’il reste plus d’un cluster :
Trouver la paire \((C_a, C_b)\) qui minimise la distance inter-clusters \(d(C_a, C_b)\).
Fusionner \(C_a\) et \(C_b\) en un nouveau cluster \(C_a \cup C_b\).
Mettre à jour la matrice de distances.
Le dendrogramme enregistre l’ordre des fusions et les distances correspondantes.
Le choix du critère de liaison (linkage) détermine la façon dont la distance entre deux clusters est calculée.
Définition 156 (Critères de liaison)
Soient \(C_a\) et \(C_b\) deux clusters. Les critères de liaison classiques sont :
Liaison simple (single linkage) : \(d(C_a, C_b) = \min_{\mathbf{x} \in C_a,\, \mathbf{y} \in C_b} \|\mathbf{x} - \mathbf{y}\|\)
Liaison complète (complete linkage) : \(d(C_a, C_b) = \max_{\mathbf{x} \in C_a,\, \mathbf{y} \in C_b} \|\mathbf{x} - \mathbf{y}\|\)
Liaison moyenne (average linkage) : \(d(C_a, C_b) = \frac{1}{|C_a| |C_b|} \sum_{\mathbf{x} \in C_a} \sum_{\mathbf{y} \in C_b} \|\mathbf{x} - \mathbf{y}\|\)
Liaison de Ward : minimise l’augmentation de la variance intra-cluster lors de la fusion :
Remarque 143
La liaison simple a tendance à créer des clusters allongés (effet de chaîne). La liaison complète produit des clusters compacts mais est sensible aux outliers. La liaison de Ward tend à produire des clusters sphériques et de tailles équilibrées, similaires à ceux de K-Means.
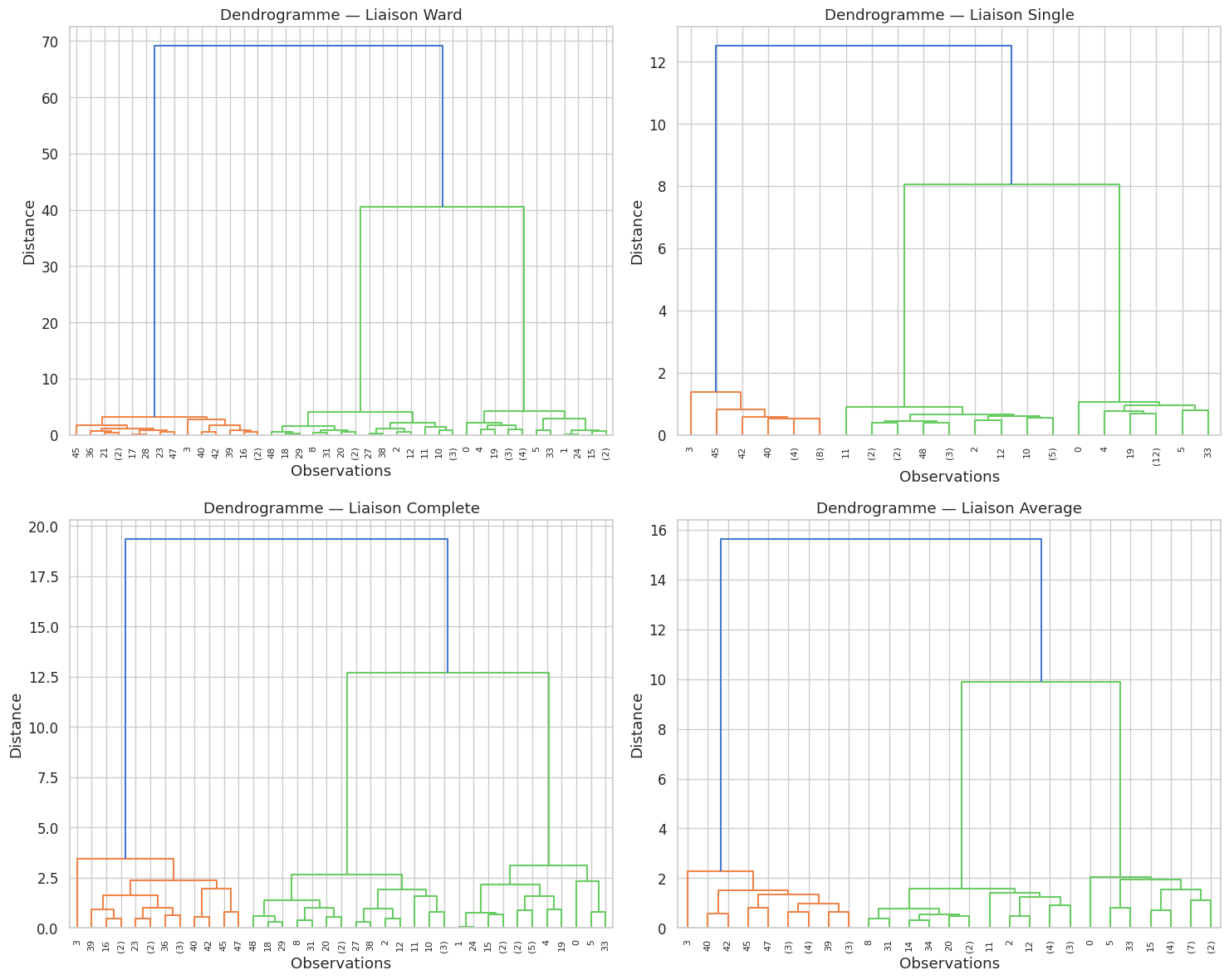
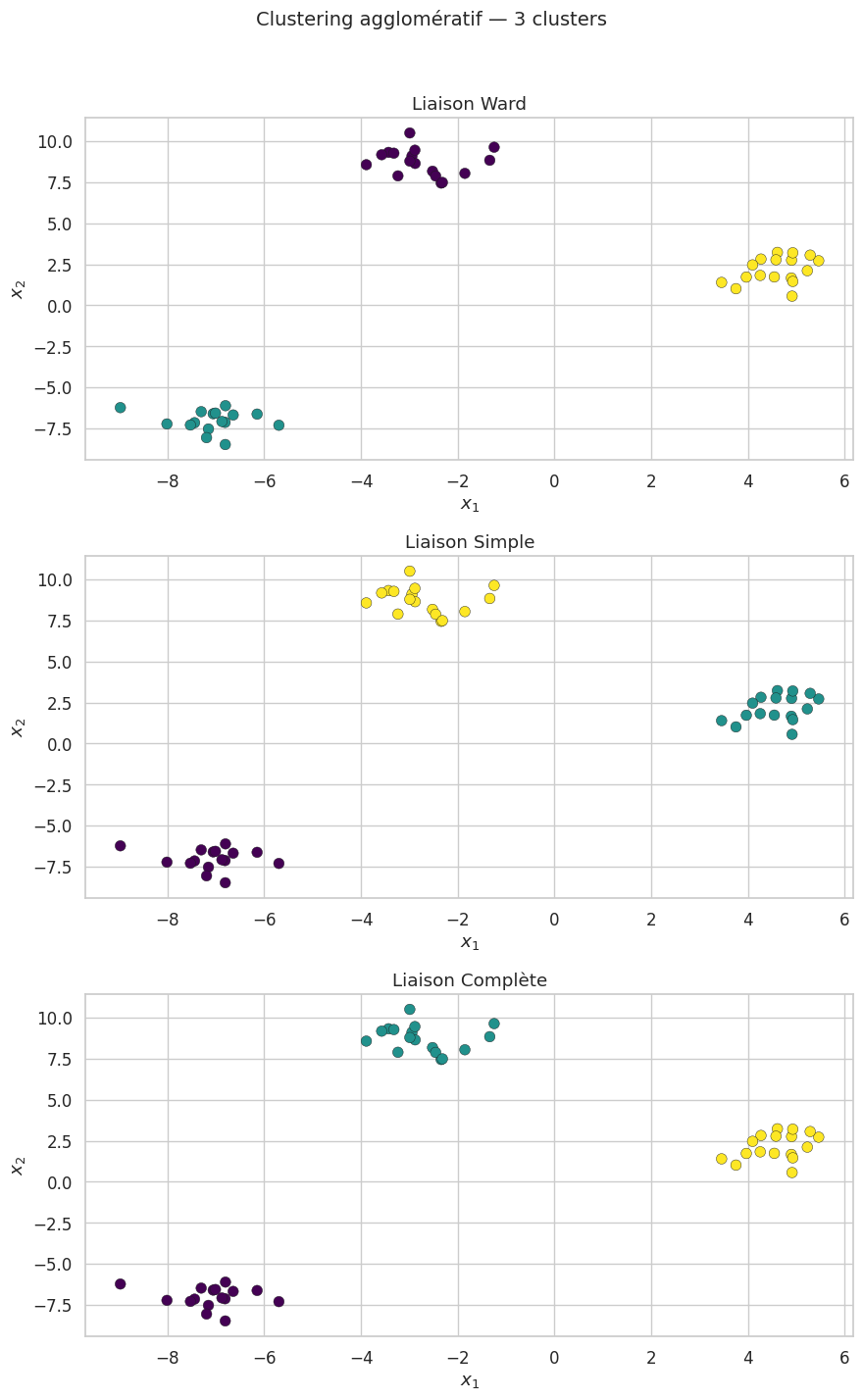
DBSCAN#
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) est un algorithme de clustering fondé sur la notion de densité locale. Contrairement à K-Means, il ne requiert pas de spécifier le nombre de clusters à l’avance et peut détecter des clusters de forme arbitraire. De plus, il identifie naturellement les points aberrants (bruit).
Définition 157 (\(\varepsilon\)-voisinage et densité)
Soit \(\varepsilon > 0\). Le \(\varepsilon\)-voisinage d’un point \(\mathbf{x}_i\) est l’ensemble
Définition 158 (Points noyau, frontière et bruit)
Soit \(\text{MinPts} \in \mathbb{N}^*\) un seuil de densité minimale.
Un point \(\mathbf{x}_i\) est un point noyau (core point) si \(|N_\varepsilon(\mathbf{x}_i)| \geq \text{MinPts}\).
Un point \(\mathbf{x}_i\) est un point frontière (border point) s’il n’est pas un point noyau mais appartient au \(\varepsilon\)-voisinage d’au moins un point noyau.
Un point \(\mathbf{x}_i\) est un point de bruit (noise point) s’il n’est ni un point noyau ni un point frontière.
Définition 159 (Densité-connexité)
Deux points noyau \(\mathbf{x}_i\) et \(\mathbf{x}_j\) sont directement densité-accessibles si \(\mathbf{x}_j \in N_\varepsilon(\mathbf{x}_i)\). Deux points sont densité-connexes s’il existe une chaîne de points noyau directement densité-accessibles les reliant. Un cluster au sens de DBSCAN est un ensemble maximal de points densité-connexes.
Remarque 144
DBSCAN possède deux hyperparamètres : \(\varepsilon\) (rayon du voisinage) et \(\text{MinPts}\) (nombre minimal de voisins). Le choix de \(\varepsilon\) est souvent guidé par le graphe des \(k\)-distances : on trie les distances au \(k\)-ième plus proche voisin par ordre décroissant et on repère le « coude » de la courbe. Une règle empirique courante est \(\text{MinPts} = 2d\) où \(d\) est la dimension des données.
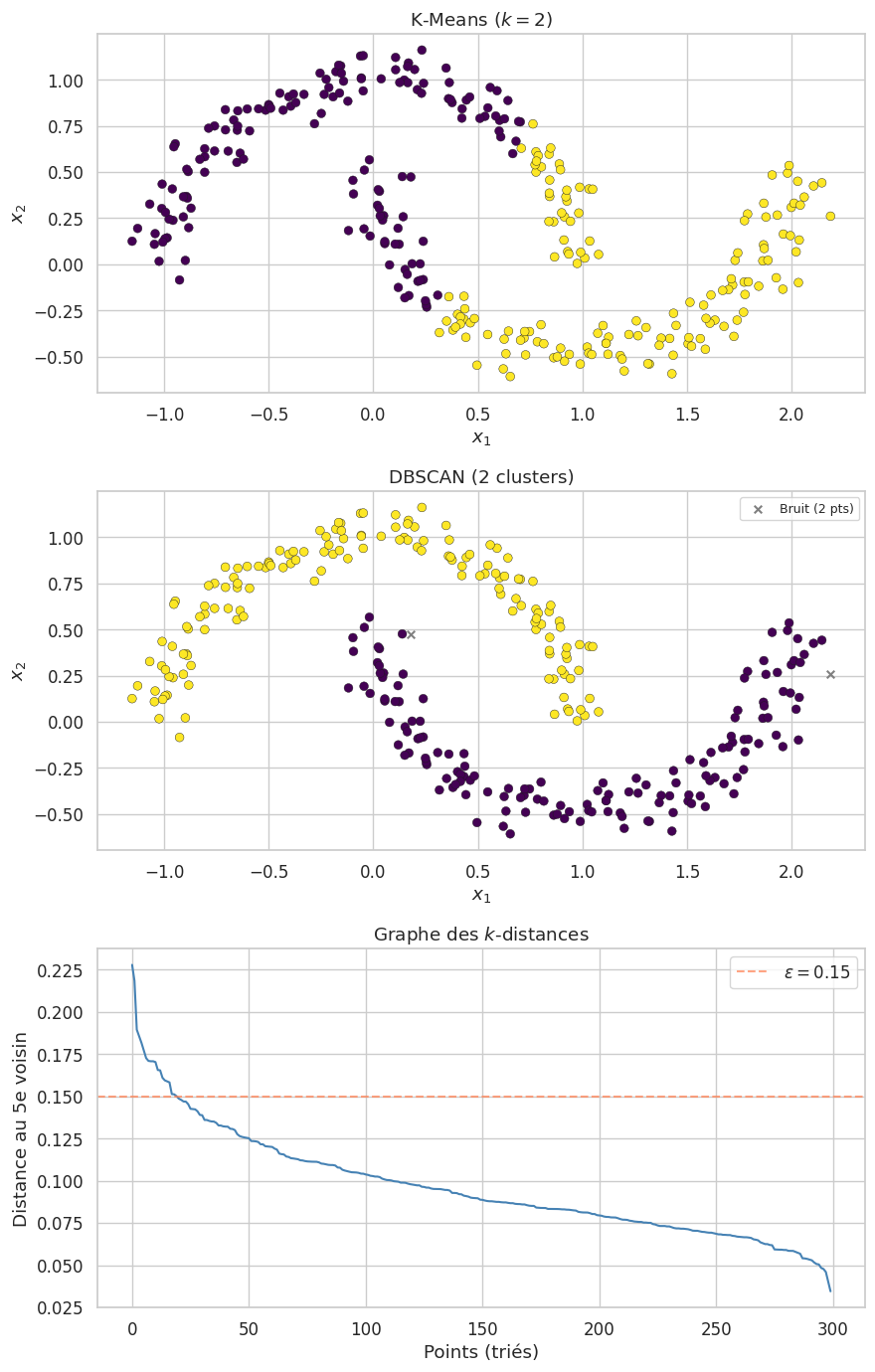
OPTICS#
OPTICS (Ordering Points To Identify the Clustering Structure) est une extension de DBSCAN qui élimine le besoin de fixer un paramètre \(\varepsilon\) global. L’algorithme produit un diagramme d’atteignabilité (reachability plot) qui révèle la structure multi-échelle des clusters.
Définition 160 (Distance d’atteignabilité)
La distance noyau (core distance) d’un point \(\mathbf{x}_i\) est la distance minimale \(\varepsilon'\) telle que \(|N_{\varepsilon'}(\mathbf{x}_i)| \geq \text{MinPts}\) :
La distance d’atteignabilité de \(\mathbf{x}_j\) par rapport à \(\mathbf{x}_i\) est :
Remarque 145
Dans le diagramme d’atteignabilité, les clusters apparaissent comme des vallées : une zone de faibles distances d’atteignabilité entourée de pics. La profondeur et la largeur des vallées renseignent respectivement sur la densité et la taille des clusters.
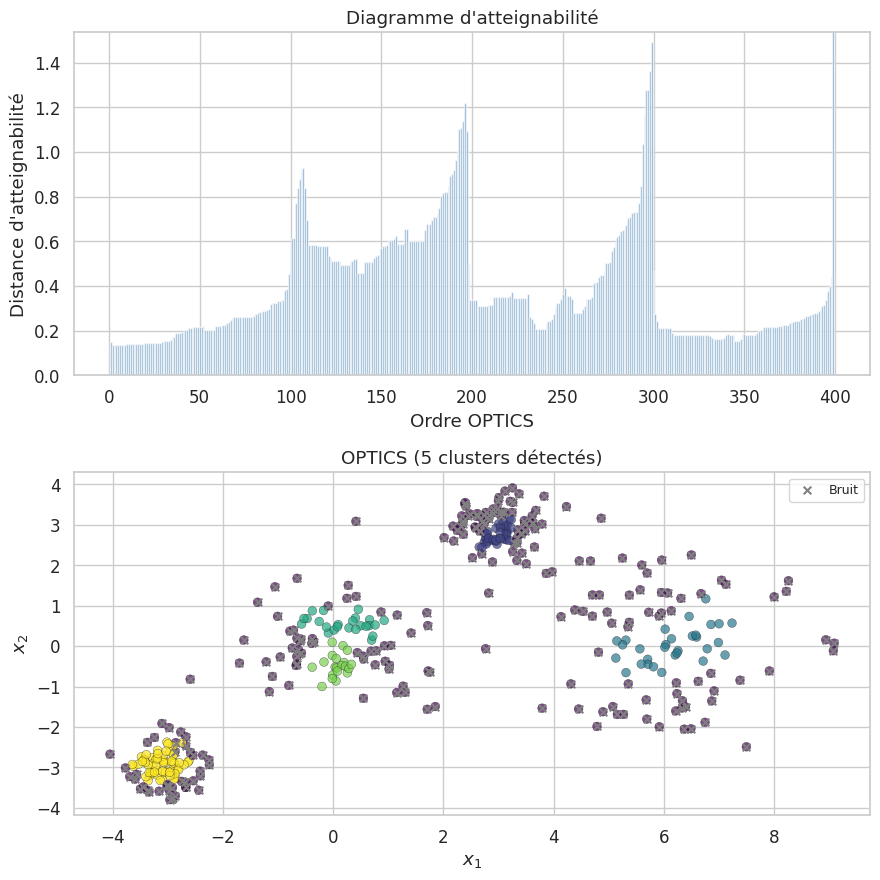
Modèles de mélange gaussien (GMM)#
Les modèles de mélange gaussien (Gaussian Mixture Models, GMM) adoptent une approche probabiliste du clustering. On suppose que les données sont générées par un mélange de \(k\) distributions gaussiennes, chacune caractérisée par sa moyenne, sa matrice de covariance et son poids dans le mélange.
Définition 161 (Modèle de mélange gaussien)
Un mélange de \(k\) gaussiennes est défini par la densité :
où :
\(\pi_j \geq 0\) avec \(\sum_{j=1}^k \pi_j = 1\) sont les poids du mélange (probabilités a priori).
\(\boldsymbol{\mu}_j \in \mathbb{R}^d\) est la moyenne de la \(j\)-ème composante.
\(\boldsymbol{\Sigma}_j \in \mathbb{R}^{d \times d}\) est la matrice de covariance (symétrique définie positive) de la \(j\)-ème composante.
\(\mathcal{N}(\mathbf{x} \mid \boldsymbol{\mu}, \boldsymbol{\Sigma}) = \frac{1}{(2\pi)^{d/2} |\boldsymbol{\Sigma}|^{1/2}} \exp\!\left(-\frac{1}{2}(\mathbf{x} - \boldsymbol{\mu})^\top \boldsymbol{\Sigma}^{-1} (\mathbf{x} - \boldsymbol{\mu})\right)\)
Algorithme EM (Expectation-Maximization)#
L’estimation des paramètres \(\boldsymbol{\theta} = \{(\pi_j, \boldsymbol{\mu}_j, \boldsymbol{\Sigma}_j)\}_{j=1}^k\) par maximum de vraisemblance se fait via l’algorithme EM.
Définition 162 (Algorithme EM pour les GMM)
L’algorithme EM alterne deux étapes :
E-step (Espérance) : calculer les responsabilités — la probabilité a posteriori que l’observation \(\mathbf{x}_i\) appartienne au cluster \(j\) :
M-step (Maximisation) : mettre à jour les paramètres en utilisant les responsabilités :
Proposition 43 (Convergence de l’algorithme EM)
L’algorithme EM fait croître (au sens large) la log-vraisemblance à chaque itération :
L’algorithme converge vers un point stationnaire de la vraisemblance (maximum local ou point selle).
Choix du nombre de composantes : BIC et AIC#
Définition 163 (BIC et AIC)
Le critère d’information bayésien (BIC) et le critère d’information d’Akaike (AIC) pénalisent la vraisemblance par la complexité du modèle :
où \(p\) est le nombre de paramètres libres du modèle et \(n\) le nombre d’observations. On choisit le modèle qui minimise le BIC (ou l’AIC).
Remarque 146
Les GMM fournissent un clustering souple (soft clustering) : chaque observation est associée à un vecteur de probabilités d’appartenance \((\gamma_{i1}, \ldots, \gamma_{ik})\), contrairement au clustering dur de K-Means. Pour obtenir un clustering dur, on assigne chaque point au cluster de responsabilité maximale : \(\hat{y}_i = \arg\max_j \gamma_{ij}\).
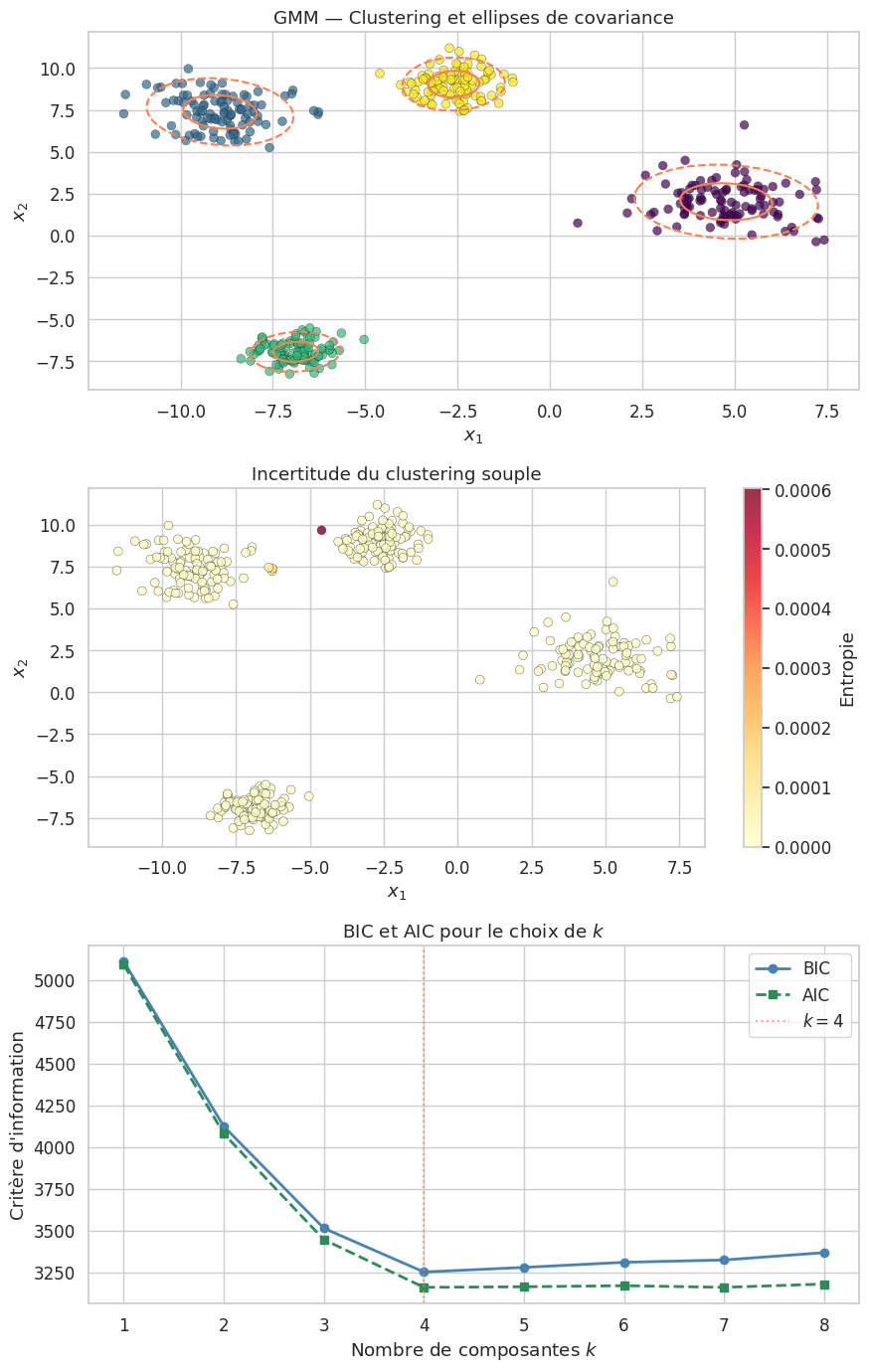
Comparaison pratique#
Chaque algorithme de clustering possède ses propres hypothèses sur la forme des clusters, sa propre scalabilité et ses propres sensibilités. Le tableau ci-dessous résume les caractéristiques principales.
Méthode |
Forme des clusters |
Scalabilité |
Paramètres |
Bruit |
|---|---|---|---|---|
K-Means |
Sphérique |
\(O(nkdT)\) |
\(k\) |
Sensible |
Mini-Batch K-Means |
Sphérique |
\(O(bkdT)\) |
\(k\), batch |
Sensible |
Hiérarchique (Ward) |
Sphérique |
\(O(n^2 \log n)\) |
\(k\) ou seuil |
Sensible |
Hiérarchique (single) |
Arbitraire (chaîne) |
\(O(n^2)\) |
\(k\) ou seuil |
Très sensible |
DBSCAN |
Arbitraire |
\(O(n \log n)\)* |
\(\varepsilon\), MinPts |
Robuste |
OPTICS |
Arbitraire |
\(O(n \log n)\)* |
MinPts, \(\xi\) |
Robuste |
GMM |
Ellipsoïdale |
\(O(nk d^2 T)\) |
\(k\), type cov. |
Modéré |
* avec un index spatial (KD-tree, ball tree).
Illustrons cette comparaison sur trois jeux de données synthétiques aux géométries variées.
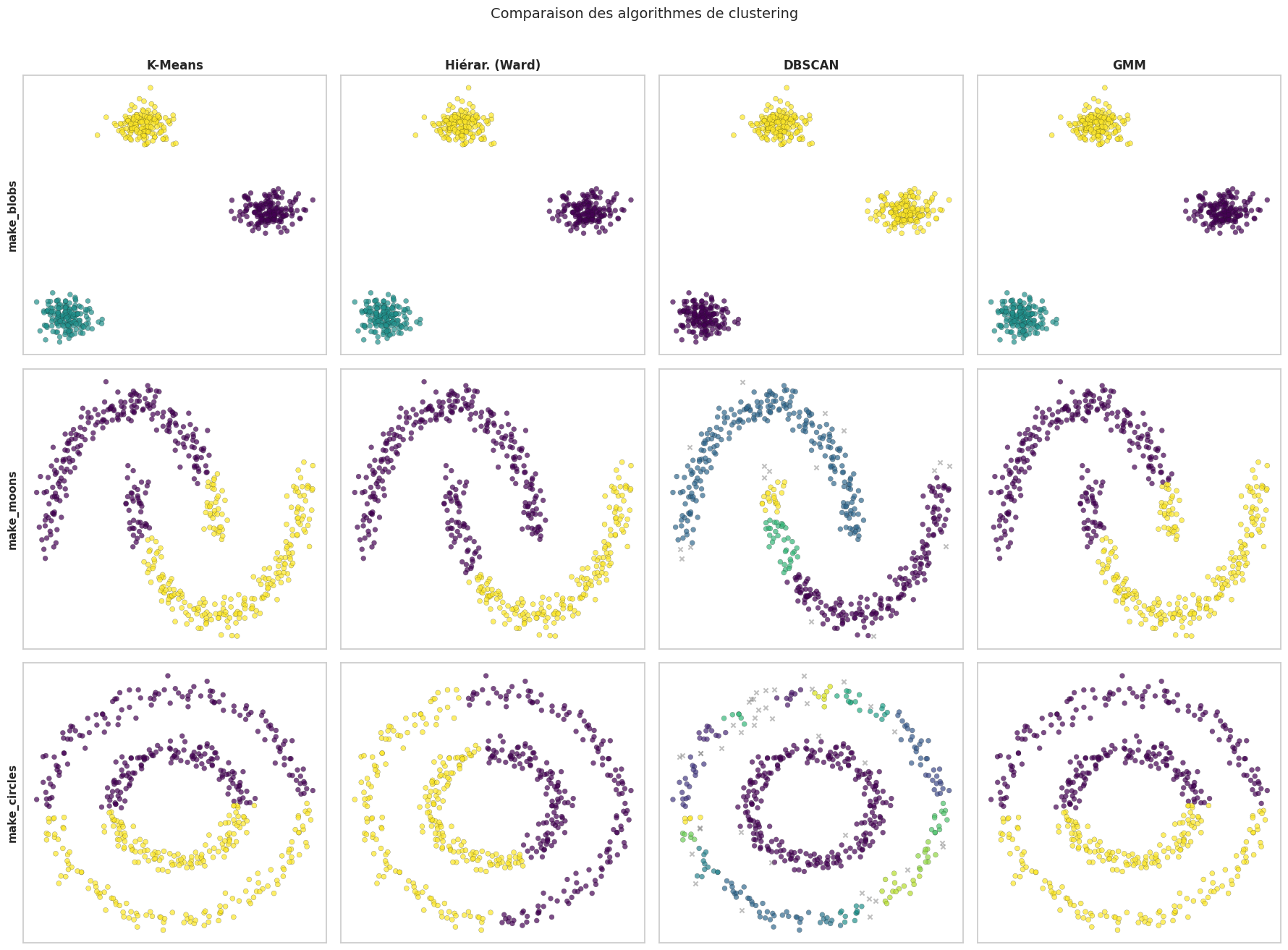
Remarque 147
Cette comparaison met en évidence les forces et faiblesses de chaque méthode. K-Means et le clustering hiérarchique de Ward excellent sur les blobs sphériques mais échouent sur les lunes et les cercles concentriques. DBSCAN identifie correctement ces structures non convexes, à condition que le paramètre \(\varepsilon\) soit bien choisi. Les GMM peuvent s’adapter à des clusters ellipsoïdaux mais restent limités face à des géométries fortement non convexes.
Métriques d’évaluation#
L’évaluation d’un clustering est un problème délicat car, en l’absence d’étiquettes, il n’existe pas de notion objective de « bonne » partition. On distingue deux familles de métriques.
Métriques externes#
Les métriques externes comparent le clustering obtenu à une partition de référence (vérité terrain). Elles ne sont utilisables que lorsqu’on dispose d’étiquettes, par exemple pour comparer des algorithmes sur des jeux de données de référence.
Définition 164 (Adjusted Rand Index (ARI))
Soit \(U = \{U_1, \ldots, U_R\}\) la partition obtenue et \(V = \{V_1, \ldots, V_C\}\) la partition de référence. L”indice de Rand ajusté est :
où \(\text{RI} = \frac{a + b}{\binom{n}{2}}\), avec \(a\) le nombre de paires d’observations qui sont dans le même cluster dans \(U\) et dans \(V\), et \(b\) le nombre de paires qui sont dans des clusters différents dans \(U\) et dans \(V\). L’ARI vaut \(1\) pour un accord parfait et \(0\) en espérance pour un clustering aléatoire.
Définition 165 (Normalized Mutual Information (NMI))
L”information mutuelle normalisée est définie par :
où \(I(U; V) = \sum_{i=1}^R \sum_{j=1}^C \frac{|U_i \cap V_j|}{n} \log \frac{n \, |U_i \cap V_j|}{|U_i| \, |V_j|}\) est l’information mutuelle et \(H(U)\), \(H(V)\) sont les entropies des partitions. La NMI est comprise dans \([0, 1]\).
Définition 166 (Homogénéité, complétude et V-mesure)
Homogénéité : un clustering est homogène si chaque cluster ne contient que des éléments d’une seule classe.
Complétude : un clustering est complet si tous les éléments d’une même classe sont regroupés dans un seul cluster.
La V-mesure est la moyenne harmonique de l’homogénéité et de la complétude :
Métriques internes#
Les métriques internes évaluent la qualité du clustering sans étiquettes de référence, en mesurant la cohésion intra-cluster et la séparation inter-clusters. Le score de silhouette, l’indice de Calinski-Harabasz et l’indice de Davies-Bouldin (déjà définis plus haut) en sont les exemples les plus courants.
Remarque 148
Les métriques internes ont un biais en faveur de certaines géométries : le score de silhouette et l’indice de Calinski-Harabasz favorisent les clusters convexes et bien séparés. Ils peuvent donner des résultats trompeurs sur des clusters de forme complexe (lunes, cercles concentriques). Les métriques externes, lorsqu’elles sont disponibles, fournissent une évaluation plus fiable.
Modèle ARI NMI Homog. Compl. V-mes. Silh. CH DB
-----------------------------------------------------------------------------------------------
K-Means (k=4) 1.000 1.000 1.000 1.000 1.000 0.839 8696.8 0.225
K-Means (k=3) 0.713 0.857 0.750 1.000 0.857 0.767 2041.2 0.345
Hiérar. (Ward, k=4) 1.000 1.000 1.000 1.000 1.000 0.839 8696.8 0.225
DBSCAN 1.000 1.000 1.000 1.000 1.000 0.839 8696.8 0.225
GMM (k=4) 1.000 1.000 1.000 1.000 1.000 0.839 8696.8 0.225
Résumé#
Ce chapitre a présenté les principales méthodes de clustering, chacune répondant à des hypothèses différentes sur la structure des données :
K-Means est simple, rapide et efficace pour des clusters sphériques et équilibrés, mais nécessite de fixer \(k\) et est sensible à l’initialisation.
Le Mini-Batch K-Means offre un compromis vitesse-précision pour de très grands jeux de données.
Le clustering hiérarchique produit une hiérarchie riche (dendrogramme) et ne requiert pas de fixer \(k\) à l’avance, mais sa complexité quadratique limite son usage aux jeux de données de taille modérée.
DBSCAN et OPTICS découvrent des clusters de forme arbitraire et identifient naturellement le bruit, mais sont sensibles au choix des paramètres de densité.
Les GMM offrent un cadre probabiliste élégant avec clustering souple, mais supposent des clusters de forme ellipsoïdale.
Le choix de la méthode dépend de la géométrie attendue des clusters, de la taille du jeu de données, de la présence de bruit et du besoin (ou non) d’un clustering souple. Les métriques d’évaluation — internes (silhouette, Calinski-Harabasz, Davies-Bouldin) et externes (ARI, NMI, V-mesure) — fournissent des outils essentiels pour comparer et valider les partitions obtenues. En pratique, il est recommandé d’essayer plusieurs algorithmes et de confronter les résultats, car aucune méthode n’est universellement supérieure.