
MLOps et déploiement#
Ce qui n’est pas en production n’existe pas.
— Adapté de Peter Drucker, The Effective Executive
Un modèle d’apprentissage automatique entraîné dans un notebook Jupyter ne crée aucune valeur tant qu’il n’est pas accessible aux utilisateurs ou aux systèmes qui en ont besoin. Selon diverses études industrielles, une majorité écrasante des projets de machine learning ne parviennent jamais en production, non pas par manque de performance algorithmique, mais par défaut d’ingénierie logicielle, d’infrastructure et de processus. Le MLOps — contraction de Machine Learning Operations — est la discipline qui vise à combler cet écart en appliquant les principes du DevOps et de l’ingénierie des données au cycle de vie complet des modèles. Ce chapitre parcourt les étapes clés du déploiement : sérialisation des modèles, création d’API de prédiction, conteneurisation, suivi des expériences, pipelines CI/CD, monitoring en production et orchestration à grande échelle.
Introduction : le cycle de vie du ML#
Du notebook à la production#
Le travail d’un data scientist dans un notebook représente une fraction mineure du système de machine learning en production. L’article fondateur de Sculley et al. (2015), Hidden Technical Debt in Machine Learning Systems, illustre cette réalité : le code du modèle lui-même est un petit rectangle au centre d’un vaste écosystème comprenant la collecte de données, la validation, l’extraction de features, le serving, le monitoring et la gestion de configuration.
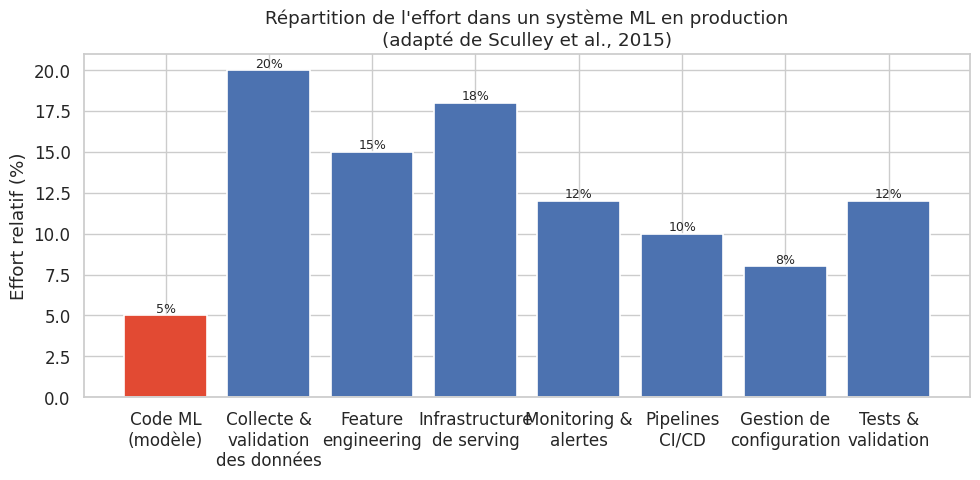
Définition 316 (MLOps)
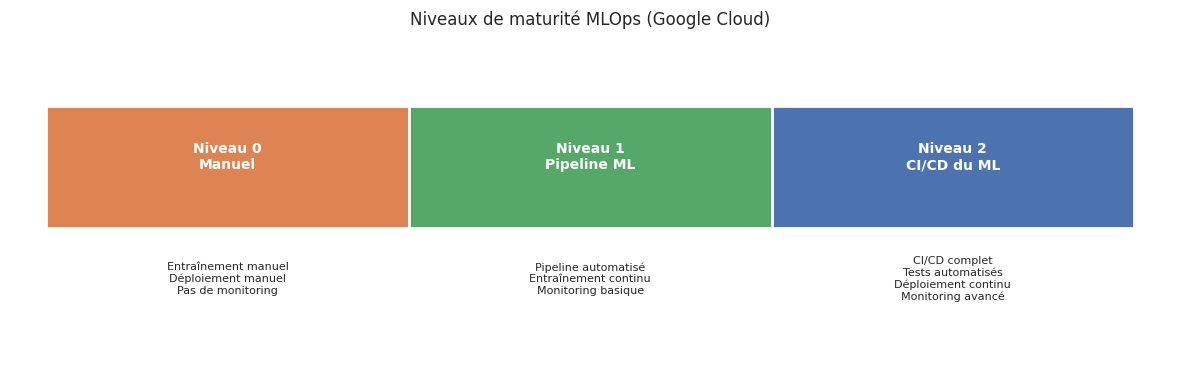
Le MLOps (Machine Learning Operations) est un ensemble de pratiques qui combine le Machine Learning, le DevOps et l”ingénierie des données pour déployer et maintenir des systèmes ML en production de manière fiable et efficace. Le MLOps couvre l’ensemble du cycle de vie :
Développement : expérimentation, entraînement, évaluation.
Déploiement : sérialisation, conteneurisation, mise en service.
Opérations : monitoring, détection de dérive, réentraînement.
Pourquoi la plupart des projets ML échouent en production#
Les causes d’échec sont rarement algorithmiques. Elles relèvent le plus souvent de problèmes d’ingénierie et d’organisation :
Absence de reproductibilité : les expériences ne sont pas versionnées, les résultats ne sont pas reproductibles.
Décalage données d’entraînement / production (training-serving skew) : les données en production diffèrent de celles utilisées pour l’entraînement.
Absence de monitoring : le modèle se dégrade silencieusement sans que personne ne s’en aperçoive.
Dette technique : code spaghetti, dépendances non gérées, absence de tests.
Fossé organisationnel : les data scientists et les ingénieurs logiciels travaillent en silos.
Remarque 266
Le MLOps n’est pas uniquement une question d’outils. C’est avant tout une culture d’ingénierie qui exige la collaboration entre data scientists, ingénieurs ML, ingénieurs DevOps et équipes métier. Les outils ne sont que le support de cette collaboration.
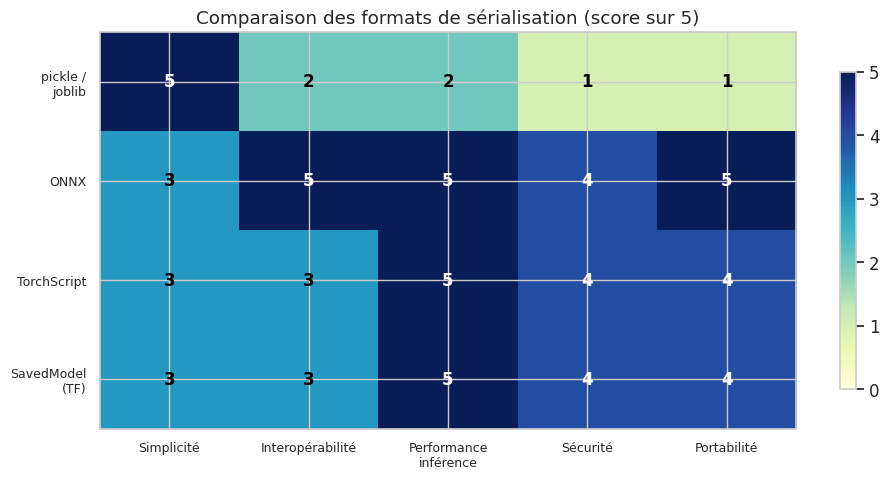
Sérialisation des modèles#
La première étape du déploiement consiste à sérialiser le modèle entraîné, c’est-à-dire le convertir en un format persistant qui peut être chargé ultérieurement par un service de prédiction, potentiellement dans un environnement différent de celui d’entraînement.
pickle et joblib#
Le module pickle de Python permet de sérialiser n’importe quel objet Python, y compris les modèles scikit-learn. La bibliothèque joblib offre une alternative plus efficace pour les objets contenant de grands tableaux NumPy.
Définition 317 (Sérialisation)
La sérialisation (serialization) est le processus de conversion d’un objet en mémoire en une séquence d’octets pouvant être stockée sur disque ou transmise sur le réseau. La désérialisation est l’opération inverse. Pour un modèle ML, cela inclut les paramètres appris, la structure du modèle et éventuellement les métadonnées de prétraitement.
Précision du modèle : 0.9100
Précision après chargement pickle : 0.9100
Taille du fichier : 612.5 Ko
Précision après chargement joblib : 0.9100
Taille du fichier : 616.4 Ko
Remarque 267
Attention : pickle exécute du code arbitraire lors de la désérialisation. Ne chargez jamais un fichier pickle provenant d’une source non fiable. Un fichier pickle malveillant peut exécuter n’importe quelle commande système. Pour le partage de modèles entre équipes ou organisations, préférez des formats comme ONNX.
ONNX : Open Neural Network Exchange#
ONNX est un format ouvert et interopérable pour représenter des modèles de machine learning. Il permet de passer d’un framework à un autre (scikit-learn, PyTorch, TensorFlow) et d’optimiser l’inférence grâce au runtime ONNX.
Code d'export ONNX :
# Installation : pip install skl2onnx onnxruntime
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
import onnxruntime as rt
# Définir le type d'entrée
initial_type = [('X', FloatTensorType([None, 20]))]
# Convertir le modèle
onnx_model = convert_sklearn(model, initial_types=initial_type)
# Sauvegarder
with open("model.onnx", "wb") as f:
f.write(onnx_model.SerializeToString())
# Inférence avec ONNX Runtime
sess = rt.InferenceSession("model.onnx")
input_name = sess.get_inputs()[0].name
pred = sess.run(None, {input_name: X_test.astype(np.float32)})[0]
TorchScript pour PyTorch#
Pour les modèles PyTorch, TorchScript permet de sérialiser le modèle dans un format indépendant de Python, utilisable en C++ pour l’inférence haute performance.
Code TorchScript :
import torch
import torch.nn as nn
class MonModele(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(20, 64)
self.fc2 = nn.Linear(64, 2)
def forward(self, x):
x = torch.relu(self.fc1(x))
return self.fc2(x)
model = MonModele()
model.eval()
# Méthode 1 : Tracing (avec un exemple d'entrée)
example_input = torch.randn(1, 20)
traced_model = torch.jit.trace(model, example_input)
traced_model.save("model_traced.pt")
# Méthode 2 : Scripting (analyse statique du code)
scripted_model = torch.jit.script(model)
scripted_model.save("model_scripted.pt")
# Chargement (fonctionne aussi en C++)
loaded = torch.jit.load("model_traced.pt")
prediction = loaded(example_input)
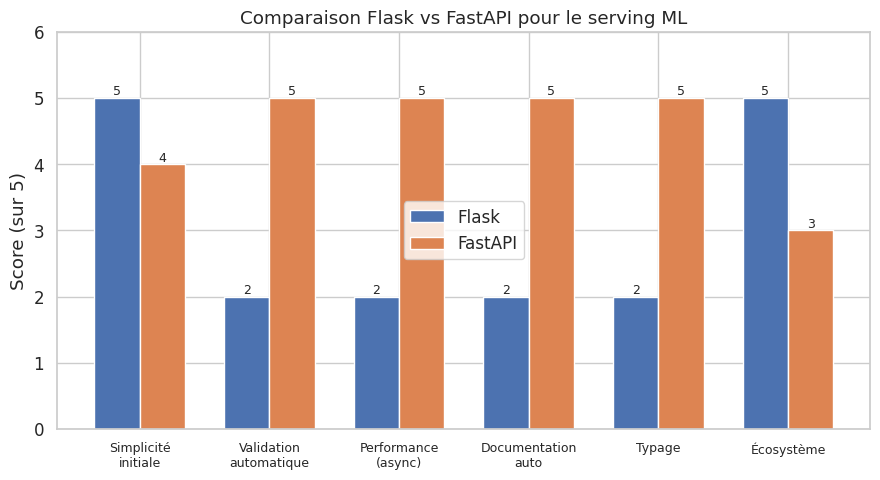
API de prédiction#
Une fois le modèle sérialisé, il faut l’exposer via une API (Application Programming Interface) pour que d’autres systèmes puissent envoyer des requêtes et recevoir des prédictions. Les API REST sont le standard de facto pour le serving de modèles ML.
Flask : API minimale#
Flask est un micro-framework web Python qui permet de créer une API de prédiction en quelques lignes.
Définition 318 (API REST)
Une API REST (Representational State Transfer) est une interface basée sur le protocole HTTP permettant à des clients d’interagir avec un serveur via des requêtes standardisées (GET, POST, PUT, DELETE). Dans le contexte du ML, un client envoie des données d’entrée via une requête POST et reçoit les prédictions en réponse au format JSON.
Application Flask minimale :
# app_flask.py
from flask import Flask, request, jsonify
import joblib
import numpy as np
app = Flask(__name__)
model = joblib.load("model_joblib.pkl")
@app.route("/predict", methods=["POST"])
def predict():
data = request.get_json()
X = np.array(data["features"]).reshape(1, -1)
prediction = model.predict(X).tolist()
probability = model.predict_proba(X).tolist()
return jsonify({
"prediction": prediction,
"probability": probability
})
@app.route("/health", methods=["GET"])
def health():
return jsonify({"status": "healthy"})
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000)
FastAPI : API moderne et asynchrone#
FastAPI est un framework moderne qui offre la validation automatique des données via Pydantic, la documentation interactive (Swagger/OpenAPI) et le support natif de l’asynchrone.
Application FastAPI avec validation :
# app_fastapi.py
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel, Field
import joblib
import numpy as np
from typing import List
# Schéma de requête
class PredictionRequest(BaseModel):
features: List[float] = Field(
...,
min_length=20,
max_length=20,
description="Vecteur de 20 features numériques"
)
class Config:
json_schema_extra = {
"example": {
"features": [0.1] * 20
}
}
# Schéma de réponse
class PredictionResponse(BaseModel):
prediction: int
probability: List[float]
model_version: str
# Application
app = FastAPI(
title="API de prédiction ML",
description="Service de classification binaire",
version="1.0.0"
)
# Chargement du modèle au démarrage
model = joblib.load("model_joblib.pkl")
MODEL_VERSION = "1.0.0"
@app.post("/predict", response_model=PredictionResponse)
async def predict(request: PredictionRequest):
try:
X = np.array(request.features).reshape(1, -1)
prediction = int(model.predict(X)[0])
probability = model.predict_proba(X)[0].tolist()
return PredictionResponse(
prediction=prediction,
probability=probability,
model_version=MODEL_VERSION
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/health")
async def health():
return {"status": "healthy", "model_version": MODEL_VERSION}
Exemple 46 (Test de l’API avec curl)
Une fois l’API lancée (par exemple avec uvicorn app_fastapi:app --host 0.0.0.0 --port 8000), on peut envoyer une requête de prédiction :
curl -X POST "http://localhost:8000/predict" \
-H "Content-Type: application/json" \
-d '{"features": [0.1, -0.3, 0.5, 1.2, -0.8, 0.3, 0.7, -1.1, 0.4, 0.9,
-0.2, 0.6, -0.5, 0.1, 0.8, -0.3, 0.4, -0.7, 0.2, 1.0]}'
La documentation interactive est automatiquement disponible à http://localhost:8000/docs.
Conteneurisation#
Docker pour le ML#
La conteneurisation avec Docker résout le problème classique du « ça marche sur ma machine ». Un conteneur encapsule l’application, ses dépendances et sa configuration dans une image reproductible et portable.
Définition 319 (Conteneur Docker)
Un conteneur Docker est une unité logicielle légère et isolée qui empaquette une application et toutes ses dépendances (bibliothèques, runtime, fichiers de configuration) dans une image immuable. Contrairement à une machine virtuelle, un conteneur partage le noyau du système d’exploitation hôte, ce qui le rend beaucoup plus léger :
Dockerfile pour service de prédiction :
# Dockerfile pour un service de prédiction ML
# Étape 1 : image de base
FROM python:3.11-slim
# Métadonnées
LABEL maintainer="equipe-ml@entreprise.fr"
LABEL version="1.0.0"
# Variables d'environnement
ENV PYTHONUNBUFFERED=1
ENV MODEL_PATH=/app/models/model.pkl
# Répertoire de travail
WORKDIR /app
# Copier les dépendances en premier (cache Docker)
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copier le code source
COPY app/ ./app/
COPY models/ ./models/
# Exposer le port
EXPOSE 8000
# Vérification de santé
HEALTHCHECK --interval=30s --timeout=5s --retries=3 \
CMD curl -f http://localhost:8000/health || exit 1
# Commande de lancement
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000"]
Multi-stage builds#
Les builds multi-étapes permettent de réduire la taille de l’image finale en séparant l’environnement de construction de l’environnement d’exécution.
Dockerfile multi-stage :
# Dockerfile multi-stage
# --- Étape de construction ---
FROM python:3.11-slim AS builder
WORKDIR /build
COPY requirements.txt .
RUN pip install --no-cache-dir --prefix=/install -r requirements.txt
# --- Étape finale (image légère) ---
FROM python:3.11-slim AS runtime
WORKDIR /app
COPY --from=builder /install /usr/local
COPY app/ ./app/
COPY models/ ./models/
# Utilisateur non-root pour la sécurité
RUN useradd --create-home appuser
USER appuser
EXPOSE 8000
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000"]
Docker Compose pour les services ML#
En pratique, un système ML en production comporte plusieurs services (API, base de données de features, monitoring, etc.) que Docker Compose permet d’orchestrer localement.
Docker Compose pour un système ML :
# docker-compose.yml
version: "3.8"
services:
# Service de prédiction
prediction-api:
build: .
ports:
- "8000:8000"
environment:
- MODEL_PATH=/app/models/model.pkl
- LOG_LEVEL=info
volumes:
- ./models:/app/models:ro
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8000/health"]
interval: 30s
timeout: 5s
retries: 3
restart: unless-stopped
# Serveur MLflow pour le suivi
mlflow:
image: ghcr.io/mlflow/mlflow:latest
ports:
- "5000:5000"
environment:
- MLFLOW_BACKEND_STORE_URI=sqlite:///mlflow.db
volumes:
- mlflow-data:/mlflow
command: mlflow server --host 0.0.0.0
# Prometheus pour le monitoring
prometheus:
image: prom/prometheus:latest
ports:
- "9090:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml:ro
volumes:
mlflow-data:
Remarque 268
Pour l’inférence GPU, il faut utiliser une image de base avec le support CUDA (par exemple nvidia/cuda:12.2-runtime-ubuntu22.04) et le NVIDIA Container Toolkit. La commande de lancement devient docker run --gpus all .... Les images GPU sont considérablement plus volumineuses (plusieurs Go).
Suivi des expériences#
Le problème de la reproductibilité#
Sans un système de suivi rigoureux, les expériences de machine learning deviennent rapidement ingérables : quel jeu d’hyperparamètres a produit le meilleur modèle ? Quelles données ont été utilisées ? Quelle version du code ?
Définition 320 (Suivi des expériences)
Le suivi des expériences (experiment tracking) consiste à enregistrer systématiquement, pour chaque exécution d’un pipeline ML :
Les paramètres : hyperparamètres, configuration du prétraitement.
Les métriques : performances sur les ensembles de validation et de test.
Les artefacts : modèle sérialisé, courbes d’apprentissage, matrices de confusion.
Les métadonnées : version du code, horodatage, environnement d’exécution.
MLflow#
MLflow est une plateforme open-source de gestion du cycle de vie ML. Son module Tracking permet d’enregistrer et de comparer les expériences de manière structurée.
Suivi d'expériences avec MLflow :
import mlflow
import mlflow.sklearn
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.model_selection import cross_val_score
from sklearn.metrics import accuracy_score, f1_score, precision_score, recall_score
# Configurer le serveur de suivi
mlflow.set_tracking_uri("http://localhost:5000")
mlflow.set_experiment("classification-binaire")
# Dictionnaire d'expériences à comparer
experiments = {
"RandomForest_50": RandomForestClassifier(n_estimators=50, random_state=42),
"RandomForest_100": RandomForestClassifier(n_estimators=100, random_state=42),
"GBM_100": GradientBoostingClassifier(n_estimators=100, random_state=42),
"GBM_200": GradientBoostingClassifier(n_estimators=200, learning_rate=0.05,
random_state=42),
}
for name, model in experiments.items():
with mlflow.start_run(run_name=name):
# Enregistrer les paramètres
mlflow.log_params(model.get_params())
# Entraîner
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# Calculer et enregistrer les métriques
metrics = {
"accuracy": accuracy_score(y_test, y_pred),
"f1": f1_score(y_test, y_pred),
"precision": precision_score(y_test, y_pred),
"recall": recall_score(y_test, y_pred),
}
mlflow.log_metrics(metrics)
# Enregistrer le modèle comme artefact
mlflow.sklearn.log_model(model, "model")
print(f"{name}: accuracy={metrics['accuracy']:.4f}")
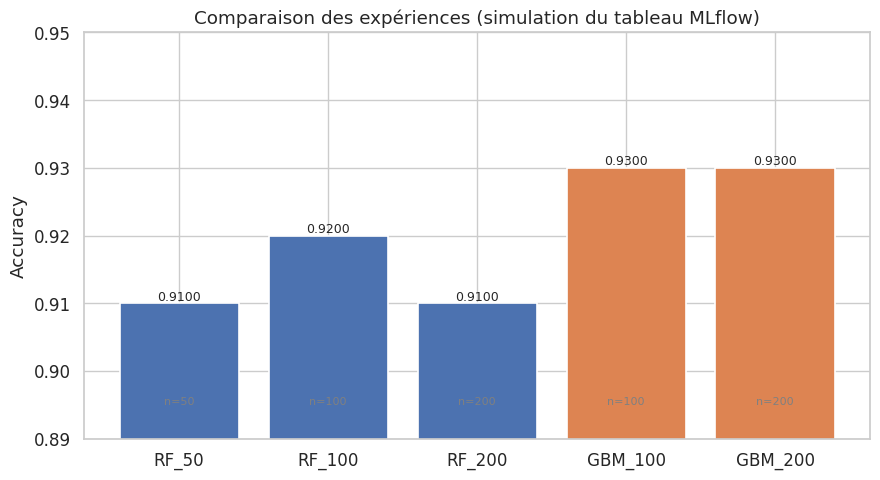
Weights & Biases (W&B)#
Remarque 269
Weights & Biases (W&B) est une plateforme commerciale (avec un tier gratuit) offrant des fonctionnalités similaires à MLflow avec une interface web particulièrement soignée. W&B excelle dans la visualisation interactive des expériences, le suivi des ressources GPU, et la collaboration en équipe. L’intégration se fait en quelques lignes :
import wandb
wandb.init(project="mon-projet", config=hyperparameters)
wandb.log({"loss": loss, "accuracy": accuracy})
wandb.finish()
Le choix entre MLflow (open-source, auto-hébergé) et W&B (SaaS, interface riche) dépend des contraintes de l’organisation : souveraineté des données, budget, infrastructure existante.
Pipelines CI/CD pour le ML#
Tests du code ML#
Le code de machine learning nécessite des tests spécifiques au-delà des tests unitaires classiques : vérification de la forme des données, des plages de valeurs des prédictions, de la reproductibilité.
Définition 321 (CI/CD pour le ML)
L”intégration continue (Continuous Integration, CI) pour le ML consiste à exécuter automatiquement, à chaque modification du code, un ensemble de tests et de validations :
Tests unitaires : fonctions de prétraitement, feature engineering.
Tests d’intégration : pipeline complet sur un petit jeu de données.
Tests du modèle : performance minimale, absence de régression.
Tests de l’API : endpoints, schémas de requête/réponse.
Le déploiement continu (Continuous Deployment, CD) automatise la mise en production après validation.
Tests du modèle avec pytest :
# tests/test_model.py
import pytest
import numpy as np
import joblib
@pytest.fixture
def model():
return joblib.load("models/model.pkl")
@pytest.fixture
def sample_input():
return np.random.randn(1, 20)
class TestModel:
def test_prediction_shape(self, model, sample_input):
"""La prédiction doit être un scalaire."""
pred = model.predict(sample_input)
assert pred.shape == (1,)
def test_prediction_values(self, model, sample_input):
"""La prédiction doit être 0 ou 1."""
pred = model.predict(sample_input)
assert pred[0] in [0, 1]
def test_probability_range(self, model, sample_input):
"""Les probabilités doivent être dans [0, 1]."""
proba = model.predict_proba(sample_input)
assert np.all(proba >= 0) and np.all(proba <= 1)
assert np.isclose(proba.sum(), 1.0)
def test_minimum_accuracy(self, model):
"""Le modèle doit atteindre au moins 80% de précision."""
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=500, n_features=20,
n_informative=10, random_state=99)
acc = (model.predict(X) == y).mean()
assert acc > 0.80, f"Précision insuffisante : {acc:.4f}"
def test_prediction_deterministic(self, model, sample_input):
"""Les prédictions doivent être déterministes."""
pred1 = model.predict(sample_input)
pred2 = model.predict(sample_input)
np.testing.assert_array_equal(pred1, pred2)
GitHub Actions pour le ML#
Pipeline GitHub Actions pour le ML :
# .github/workflows/ml-pipeline.yml
name: Pipeline ML CI/CD
on:
push:
branches: [main]
pull_request:
branches: [main]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Configurer Python
uses: actions/setup-python@v5
with:
python-version: "3.11"
cache: "pip"
- name: Installer les dépendances
run: pip install -r requirements.txt
- name: Lancer les tests unitaires
run: pytest tests/ -v --tb=short
- name: Vérifier la qualité du code
run: |
ruff check .
mypy app/ --ignore-missing-imports
train-and-validate:
needs: test
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Configurer Python
uses: actions/setup-python@v5
with:
python-version: "3.11"
cache: "pip"
- name: Installer les dépendances
run: pip install -r requirements.txt
- name: Entraîner le modèle
run: python scripts/train.py
- name: Valider le modèle
run: python scripts/validate.py --min-accuracy 0.85
- name: Sauvegarder le modèle
uses: actions/upload-artifact@v4
with:
name: model
path: models/model.pkl
deploy:
needs: train-and-validate
if: github.ref == 'refs/heads/main'
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Télécharger le modèle
uses: actions/download-artifact@v4
with:
name: model
path: models/
- name: Construire l'image Docker
run: docker build -t ml-api:${{ github.sha }} .
- name: Pousser vers le registre
run: |
docker tag ml-api:${{ github.sha }} registry.example.com/ml-api:latest
docker push registry.example.com/ml-api:latest
Monitoring en production#
Dérive des données et dérive conceptuelle#
Un modèle en production interagit avec des données vivantes qui évoluent au fil du temps. Deux types de dérive menacent les performances :
Définition 322 (Dérive des données et dérive conceptuelle)
La dérive des données (data drift ou covariate shift) se produit lorsque la distribution des variables d’entrée change au cours du temps :
La dérive conceptuelle (concept drift) se produit lorsque la relation entre les entrées et la cible change :
La dérive des données peut être détectée par des tests statistiques sur les distributions d’entrée. La dérive conceptuelle est plus insidieuse car elle nécessite des données étiquetées en production.
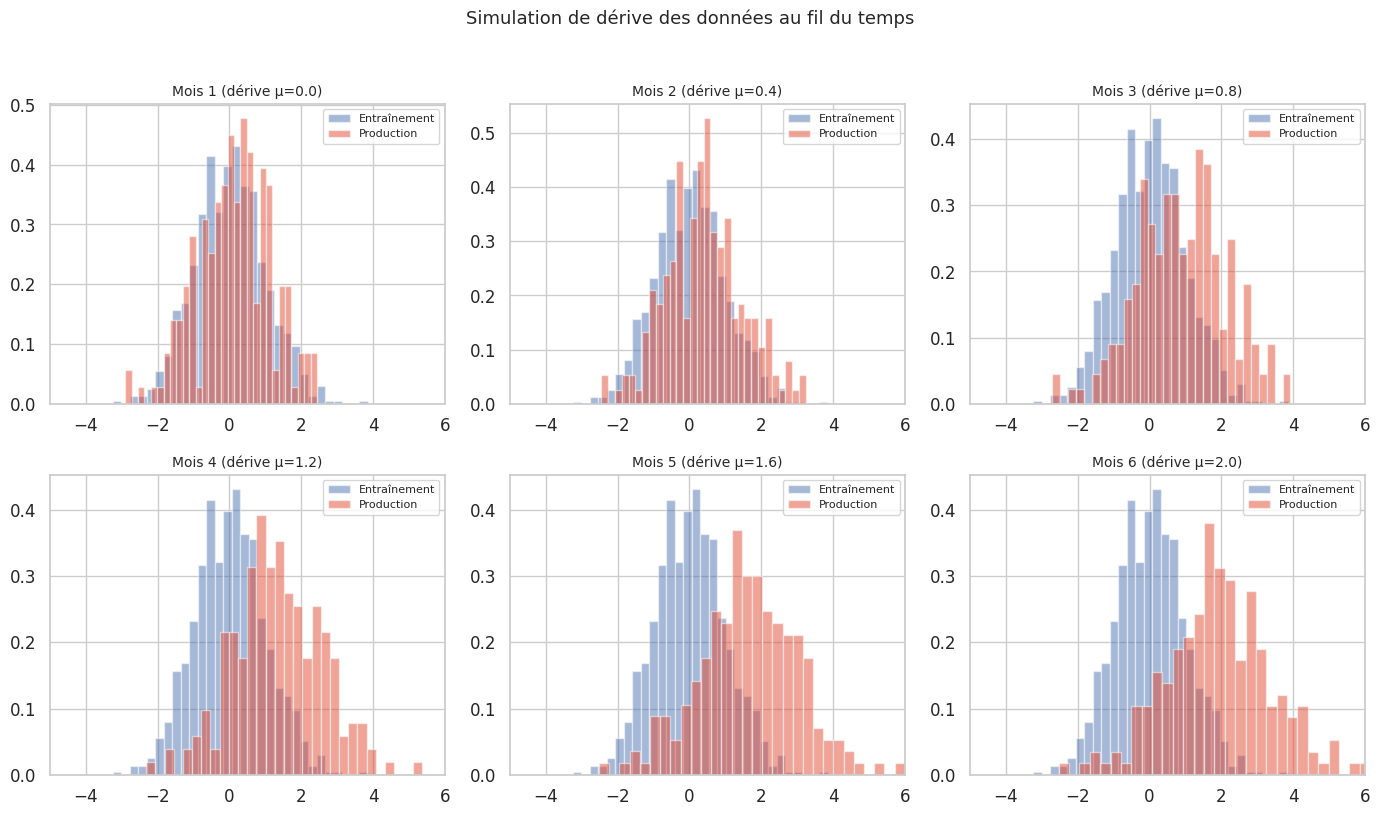
Détection de dérive par test statistique#
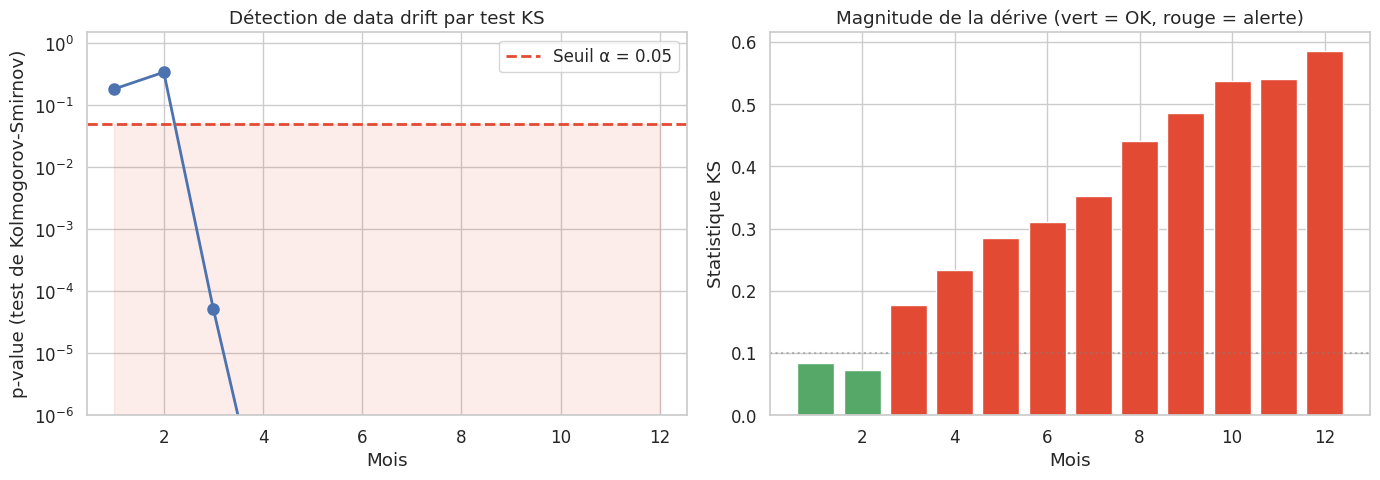
Alerte de dérive détectée aux mois : [3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
Exemple 47 (Stratégies de détection de dérive)
Plusieurs approches complémentaires permettent de détecter la dérive :
Test de Kolmogorov-Smirnov : compare deux distributions empiriques, sensible aux écarts de forme et de localisation.
Population Stability Index (PSI) : mesure largement utilisée dans le secteur bancaire pour détecter les changements de distribution.
Test du \(\chi^2\) : adapté aux variables catégorielles.
Distance de Wasserstein : mesure de transport optimal entre distributions.
Monitoring des performances : suivi de l’accuracy, du F1, ou d’une métrique métier au fil du temps (nécessite des étiquettes).
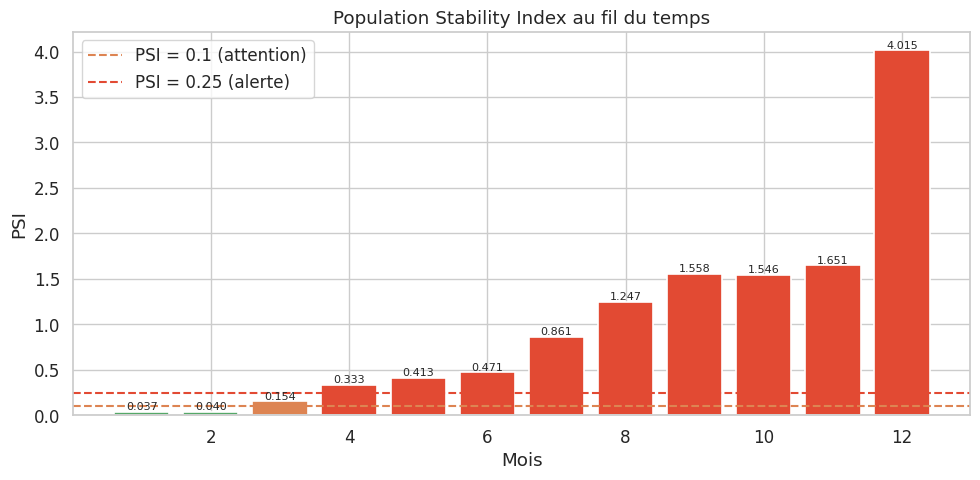
Interprétation du PSI :
PSI < 0.10 : pas de changement significatif
0.10 ≤ PSI < 0.25 : changement modéré, surveillance recommandée
PSI ≥ 0.25 : changement significatif, réentraînement recommandé
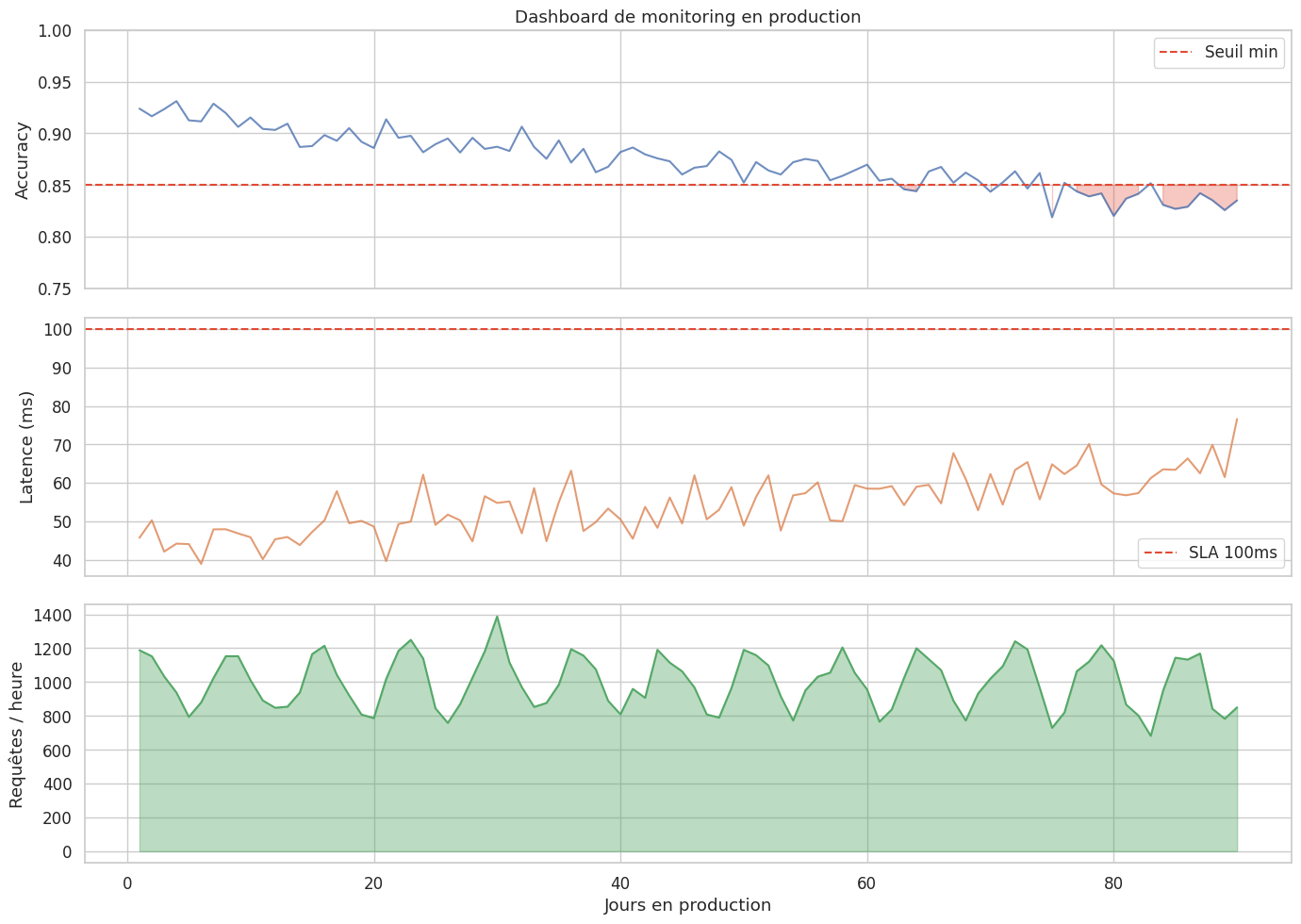
Stratégies d’alerte#
Remarque 270
Un système de monitoring efficace doit aller au-delà de la simple détection de dérive. Il doit intégrer :
Des seuils d’alerte hiérarchisés : avertissement, alerte critique, action automatique.
Des fenêtres temporelles adaptées : dérive lente (semaines) vs dérive brutale (heures).
Des dashboards temps réel : Grafana, Kibana, ou solutions spécialisées (Evidently AI, Whylabs).
Des procédures de réponse : réentraînement automatique, rollback vers un modèle précédent, alerte humaine.
La règle d’or est de monitorer autant la qualité des données d’entrée que les performances du modèle, car la dérive des données est souvent le signe avant-coureur de la dégradation des performances.
Infrastructure et orchestration#
Vue d’ensemble#
Pour les déploiements à grande échelle, au-delà de Docker Compose, des outils d’orchestration et des services cloud gérés prennent le relais.
Définition 323 (Orchestration de conteneurs)
L”orchestration de conteneurs est le processus automatisé de gestion, mise à l’échelle et mise en réseau de conteneurs. Kubernetes (K8s) est le standard de facto. Il gère :
Le scaling automatique : ajuster le nombre de répliques selon la charge.
Le load balancing : distribuer les requêtes entre les répliques.
Les rolling updates : déployer une nouvelle version sans interruption de service.
La self-healing : redémarrer automatiquement les conteneurs défaillants.
Manifeste Kubernetes pour un service ML :
# deployment.yaml - Déploiement Kubernetes pour un service ML
apiVersion: apps/v1
kind: Deployment
metadata:
name: ml-prediction-api
labels:
app: ml-api
spec:
replicas: 3
selector:
matchLabels:
app: ml-api
template:
metadata:
labels:
app: ml-api
spec:
containers:
- name: ml-api
image: registry.example.com/ml-api:latest
ports:
- containerPort: 8000
resources:
requests:
memory: "512Mi"
cpu: "250m"
limits:
memory: "1Gi"
cpu: "500m"
livenessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 10
periodSeconds: 30
readinessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 5
periodSeconds: 10
---
apiVersion: v1
kind: Service
metadata:
name: ml-api-service
spec:
selector:
app: ml-api
ports:
- port: 80
targetPort: 8000
type: LoadBalancer
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: ml-api-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: ml-prediction-api
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
Services cloud gérés#
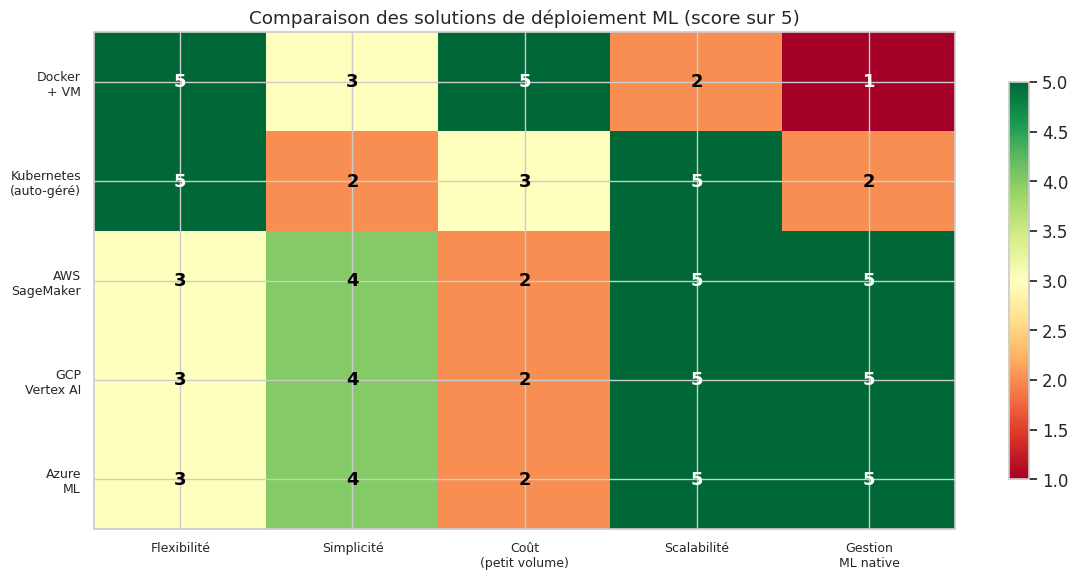
Exemple 48 (Quand utiliser quoi ?)
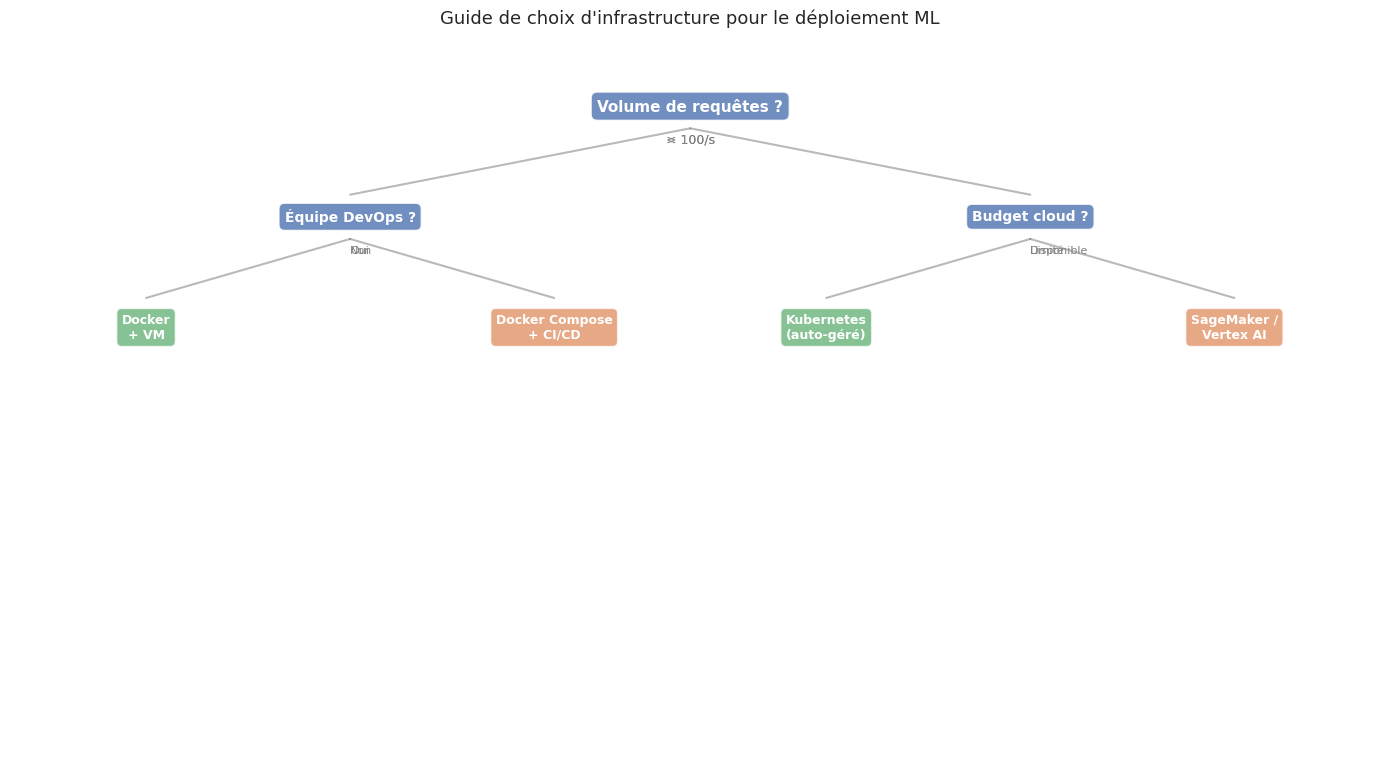
Le choix de l’infrastructure dépend de la maturité de l’équipe, du volume de requêtes et du budget :
Docker + VM simple : prototypage, faible trafic (< 100 req/s), petite équipe. Le plus simple et le moins coûteux pour démarrer.
Kubernetes : trafic important, besoin de scaling automatique, équipe avec expertise DevOps. Complexe mais très flexible.
AWS SageMaker / GCP Vertex AI / Azure ML : équipes souhaitant se concentrer sur le ML sans gérer l’infrastructure. Coût plus élevé mais time-to-market réduit. Idéal pour les organisations déjà dans l’écosystème cloud correspondant.
Serverless (AWS Lambda, Cloud Functions) : modèles légers avec trafic sporadique. Facturation à l’usage, pas de serveur à gérer, mais limites sur la taille du modèle et le temps d’exécution.
Résumé#
Ce chapitre a parcouru les étapes essentielles du MLOps, la discipline qui permet de transformer un modèle de machine learning expérimental en un système fiable en production.
La sérialisation convertit un modèle entraîné en un format persistant.
pickleetjoblibsont simples mais présentent des risques de sécurité. ONNX offre l’interopérabilité entre frameworks et des performances d’inférence optimisées. TorchScript est la solution native de PyTorch pour le déploiement.Les API de prédiction exposent le modèle via des endpoints HTTP. Flask permet un prototypage rapide, tandis que FastAPI offre la validation automatique, la documentation interactive et les performances asynchrones.
La conteneurisation avec Docker garantit la reproductibilité de l’environnement. Les builds multi-étapes réduisent la taille des images. Docker Compose orchestre les services localement.
Le suivi des expériences avec MLflow ou W&B assure la reproductibilité et la traçabilité de chaque itération du modèle.
Les pipelines CI/CD automatisent les tests, la validation et le déploiement des modèles. Les tests ML spécifiques (forme des prédictions, performances minimales, déterminisme) complètent les tests logiciels classiques.
Le monitoring en production détecte la dérive des données (data drift) et la dérive conceptuelle (concept drift) par des tests statistiques (Kolmogorov-Smirnov, PSI). Les alertes hiérarchisées et les dashboards permettent une réponse rapide.
L”orchestration avec Kubernetes et les services cloud gérés (SageMaker, Vertex AI) permettent le passage à l’échelle, le choix dépendant de la maturité de l’équipe et du budget disponible.
Remarque 271
Le MLOps n’est pas une destination mais un processus d’amélioration continue. Il est préférable de commencer simplement — un modèle sérialisé avec joblib, une API Flask, un script de déploiement — puis de monter en maturité progressivement à mesure que les besoins se précisent. L’erreur la plus courante est de vouloir mettre en place une infrastructure complexe avant même d’avoir un modèle qui apporte de la valeur. Comme le rappelle la sagesse de l’ingénierie logicielle : make it work, make it right, make it fast — dans cet ordre.