
Machines à vecteurs de support#
L’essence de l’apprentissage statistique est de trouver le bon compromis entre la fidélité aux données et la simplicité du modèle.
Vladimir Vapnik
Les machines à vecteurs de support (Support Vector Machines, SVM) constituent l’une des familles d’algorithmes les plus élégantes de l’apprentissage automatique. Développées par Vladimir Vapnik et ses collaborateurs dans les années 1990, les SVM reposent sur une idée géométrique simple mais puissante : trouver l’hyperplan qui sépare les classes avec la marge maximale. Cette approche, fondée sur la théorie de l’apprentissage statistique, offre des garanties théoriques fortes en termes de généralisation. Grâce à l”astuce du noyau (kernel trick), les SVM peuvent également modéliser des frontières de décision non linéaires sans jamais calculer explicitement la transformation vers un espace de grande dimension.
Ce chapitre couvre les SVM linéaires à marge dure et souple, l’astuce du noyau, les noyaux classiques, l’extension à la régression (SVR), et des exemples complets avec Scikit-learn.
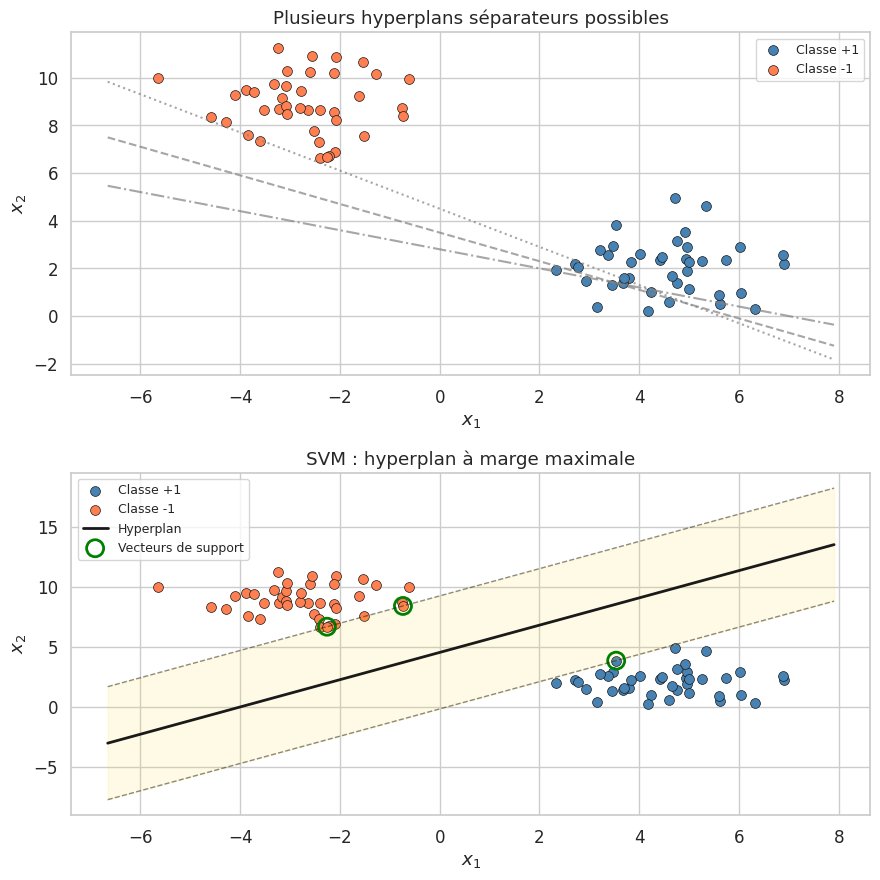
Introduction : intuition géométrique#
Considérons un problème de classification binaire en deux dimensions. Si les deux classes sont linéairement séparables, il existe une infinité d’hyperplans (ici des droites) qui les séparent. Le classifieur à marge maximale choisit celui qui maximise la distance entre l’hyperplan et les points les plus proches de chaque classe. Cette distance est appelée la marge.
Définition 112 (Hyperplan séparateur)
Soit \(\mathcal{X} \subseteq \mathbb{R}^d\) l’espace des features. Un hyperplan dans \(\mathbb{R}^d\) est l’ensemble
où \(\mathbf{w} \in \mathbb{R}^d\) est le vecteur normal à l’hyperplan et \(b \in \mathbb{R}\) est le biais (ou intercept). L’hyperplan divise l’espace en deux demi-espaces : \(\mathbf{w} \cdot \mathbf{x} + b > 0\) et \(\mathbf{w} \cdot \mathbf{x} + b < 0\).
Définition 113 (Marge)
Soit un hyperplan séparateur défini par \((\mathbf{w}, b)\) et un jeu de données \(\{(\mathbf{x}_i, y_i)\}_{i=1}^n\) avec \(y_i \in \{-1, +1\}\). La marge fonctionnelle de l’observation \((\mathbf{x}_i, y_i)\) est
La marge géométrique est la distance euclidienne entre le point le plus proche et l’hyperplan :
Remarque 107
L’idée fondamentale des SVM est que l’hyperplan à marge maximale est celui qui généralise le mieux. Intuitivement, une marge large laisse plus de « place » pour les nouvelles observations, réduisant le risque de mauvaise classification. Cette intuition est formalisée par la théorie de Vapnik-Chervonenkis, qui montre que maximiser la marge revient à minimiser une borne sur l’erreur de généralisation.
SVM linéaire : formulation#
Problème d’optimisation (marge dure)#
Lorsque les données sont parfaitement séparables, on cherche l’hyperplan qui maximise la marge géométrique. On peut montrer que cela revient à résoudre le problème d’optimisation suivant.
Définition 114 (SVM à marge dure)
Étant donné un jeu d’entraînement \(\{(\mathbf{x}_i, y_i)\}_{i=1}^n\) avec \(y_i \in \{-1, +1\}\), le SVM à marge dure (hard margin SVM) résout le problème d’optimisation convexe :
sous les contraintes
La marge géométrique vaut \(\gamma = \frac{2}{\|\mathbf{w}\|}\), de sorte que minimiser \(\|\mathbf{w}\|^2\) revient à maximiser la marge.
Remarque 108
La contrainte \(y_i (\mathbf{w} \cdot \mathbf{x}_i + b) \geq 1\) impose que chaque point soit du bon côté de l’hyperplan, à une distance d’au moins \(\frac{1}{\|\mathbf{w}\|}\). Les points pour lesquels l’égalité est atteinte (\(y_i (\mathbf{w} \cdot \mathbf{x}_i + b) = 1\)) se trouvent exactement sur la frontière de la marge : ce sont les vecteurs de support. Ils sont les seuls points qui déterminent l’hyperplan optimal. Si l’on supprime un point qui n’est pas un vecteur de support, la solution ne change pas.
Problème dual et multiplicateurs de Lagrange#
Le problème d’optimisation se résout en pratique via sa formulation duale, obtenue par la méthode des multiplicateurs de Lagrange.
Proposition 27 (Formulation duale du SVM)
Le problème dual du SVM à marge dure est
sous les contraintes
où les \(\alpha_i\) sont les multiplicateurs de Lagrange. À l’optimum, le vecteur de poids se reconstruit par
et les vecteurs de support sont les points pour lesquels \(\alpha_i^* > 0\).
Proof. On introduit les multiplicateurs de Lagrange \(\alpha_i \geq 0\) et on forme le lagrangien
Les conditions de stationnarité donnent
En substituant ces expressions dans le lagrangien, on obtient le problème dual. Par les conditions KKT (Karush-Kuhn-Tucker), on a \(\alpha_i [y_i (\mathbf{w} \cdot \mathbf{x}_i + b) - 1] = 0\) pour tout \(i\) : si \(\alpha_i > 0\), alors la contrainte est active, c’est-à-dire que \(\mathbf{x}_i\) est un vecteur de support.
Remarque 109
La formulation duale est cruciale pour deux raisons. Premièrement, le nombre de variables d’optimisation est \(n\) (le nombre d’observations) plutôt que \(d\) (la dimension), ce qui est avantageux lorsque \(d \gg n\). Deuxièmement, les données n’apparaissent qu’à travers des produits scalaires \(\mathbf{x}_i \cdot \mathbf{x}_j\), ce qui ouvre la porte à l’astuce du noyau.
Marge souple (soft margin)#
En pratique, les données sont rarement parfaitement séparables. De plus, même si elles le sont, la marge dure est très sensible aux outliers : un seul point mal placé peut modifier considérablement l’hyperplan. La marge souple introduit des variables de relâchement (slack variables) qui autorisent certains points à violer la marge, moyennant une pénalité.
Définition 115 (SVM à marge souple)
Le SVM à marge souple (soft margin SVM) résout le problème
sous les contraintes
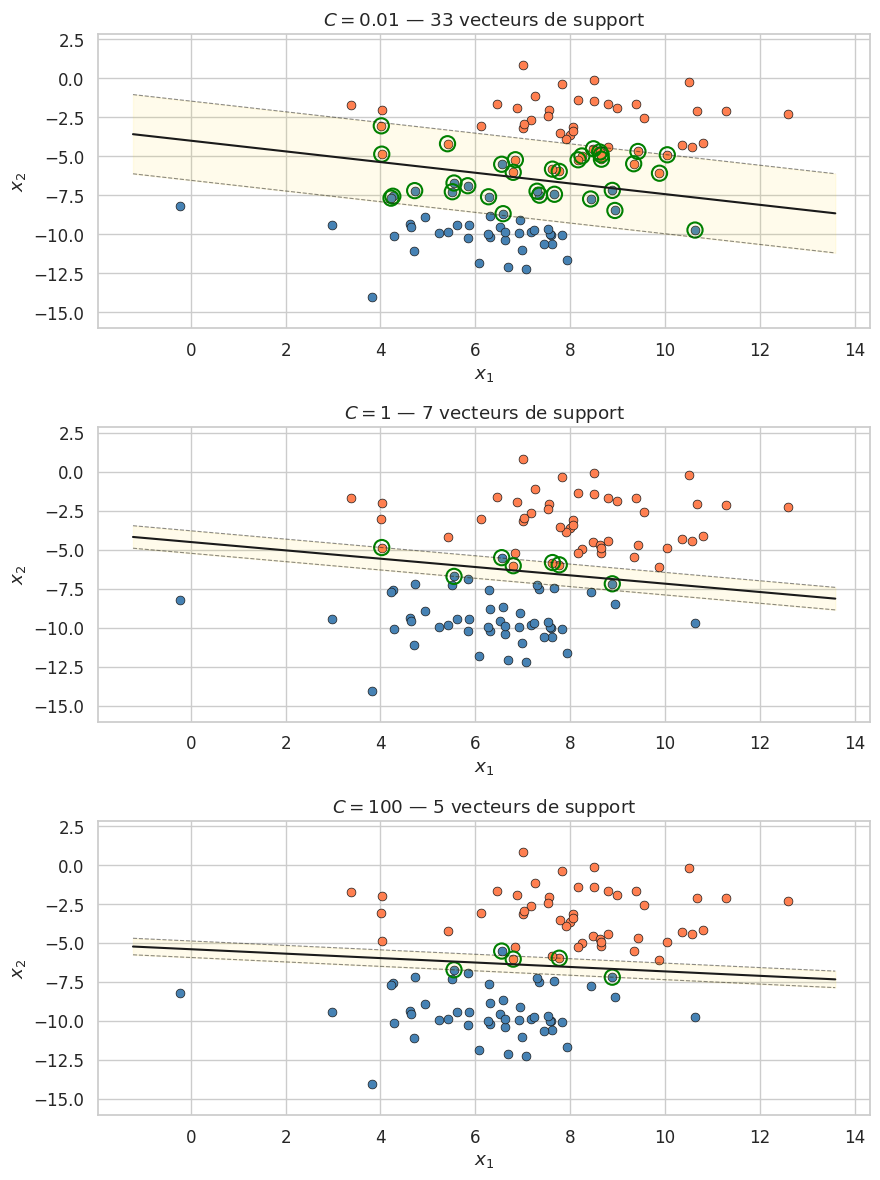
où \(\xi_i\) est la variable de relâchement (slack variable) associée à l’observation \(i\), et \(C > 0\) est l”hyperparamètre de régularisation qui contrôle le compromis entre la largeur de la marge et le nombre de violations autorisées.
Remarque 110
L’interprétation des variables de relâchement est la suivante :
\(\xi_i = 0\) : le point est correctement classé et se trouve à l’extérieur de la marge ou exactement sur sa frontière.
\(0 < \xi_i < 1\) : le point est correctement classé mais se trouve à l’intérieur de la marge.
\(\xi_i = 1\) : le point se trouve exactement sur l’hyperplan de décision.
\(\xi_i > 1\) : le point est mal classé.
Le paramètre \(C\) joue un rôle analogue à l’inverse du paramètre de régularisation :
\(C\) grand : on tolère peu de violations, la marge est étroite et le modèle est plus susceptible d’overfitting.
\(C\) petit : on tolère davantage de violations, la marge est large et le modèle est plus régularisé.
Proposition 28 (Formulation duale du SVM à marge souple)
Le problème dual du SVM à marge souple est
sous les contraintes
La seule différence avec le cas à marge dure est la borne supérieure \(\alpha_i \leq C\), qui empêche un seul point d’avoir un poids arbitrairement élevé.
Astuce du noyau (kernel trick)#
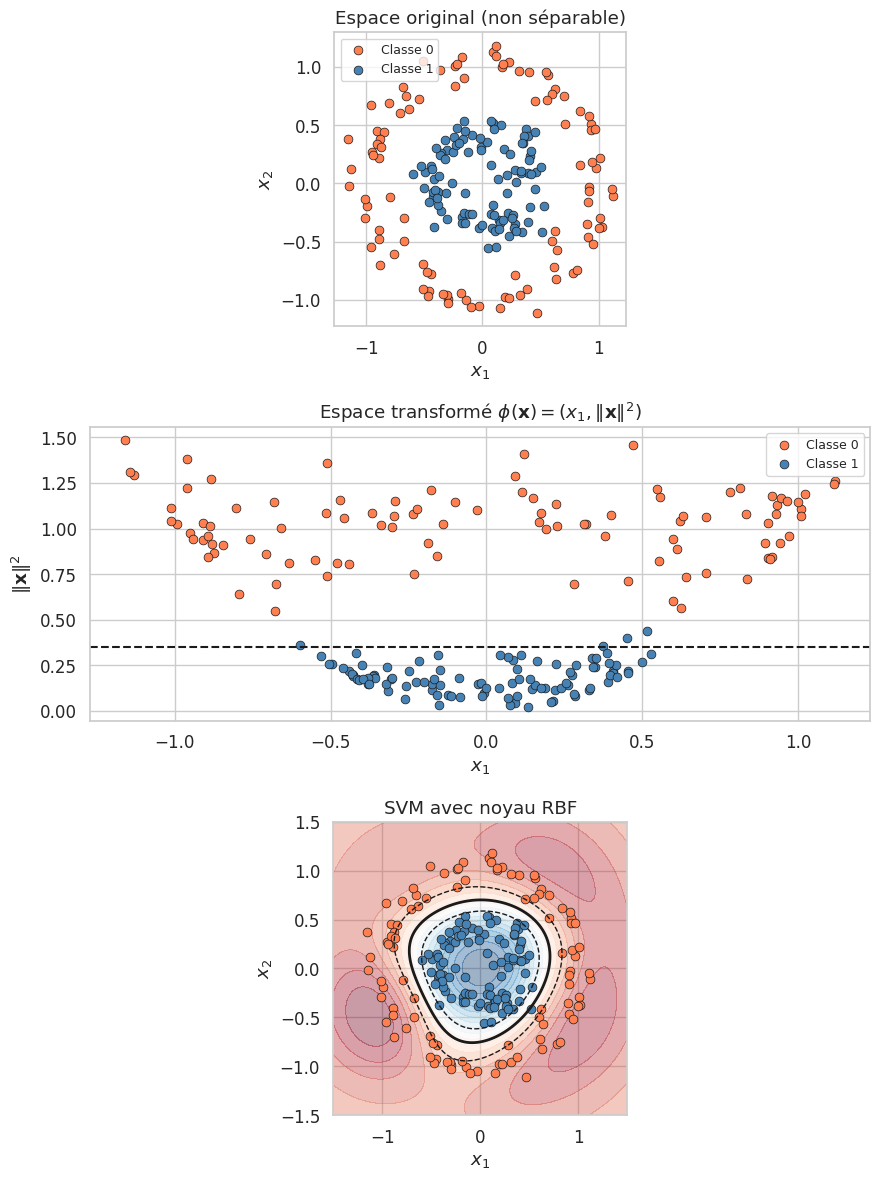
Les SVM linéaires ne peuvent modéliser que des frontières de décision linéaires. Pour traiter des problèmes non linéairement séparables, on peut transformer les données dans un espace de dimension supérieure où elles deviennent séparables. L”astuce du noyau permet de réaliser cette transformation de manière implicite, sans jamais calculer les coordonnées dans l’espace transformé.
Définition 116 (Fonction noyau)
Une fonction noyau (kernel function) est une fonction \(K : \mathbb{R}^d \times \mathbb{R}^d \to \mathbb{R}\) telle qu’il existe un espace de Hilbert \(\mathcal{H}\) et une application \(\phi : \mathbb{R}^d \to \mathcal{H}\) vérifiant
pour tout \(\mathbf{x}, \mathbf{x}' \in \mathbb{R}^d\). On dit que \(K\) est un noyau défini positif si la matrice de Gram \(\mathbf{G}\) définie par \(G_{ij} = K(\mathbf{x}_i, \mathbf{x}_j)\) est semi-définie positive pour tout ensemble fini de points \(\{\mathbf{x}_1, \ldots, \mathbf{x}_n\}\).
Proposition 29 (Théorème de Mercer (version simplifiée))
Une fonction symétrique \(K : \mathbb{R}^d \times \mathbb{R}^d \to \mathbb{R}\) est un noyau valide (c’est-à-dire qu’il existe un espace \(\mathcal{H}\) et une application \(\phi\) tels que \(K(\mathbf{x}, \mathbf{x}') = \langle \phi(\mathbf{x}), \phi(\mathbf{x}') \rangle\)) si et seulement si la matrice de Gram \(\mathbf{G}\) associée est semi-définie positive pour tout choix fini de points.
Ce résultat est fondamental car il garantit que l’on peut remplacer tout produit scalaire \(\mathbf{x}_i \cdot \mathbf{x}_j\) dans la formulation duale par \(K(\mathbf{x}_i, \mathbf{x}_j)\), sans avoir à expliciter \(\phi\).
Remarque 111
L’astuce du noyau est d’une puissance remarquable. Considérons par exemple un noyau gaussien : la transformation \(\phi\) correspondante envoie les données dans un espace de dimension infinie. Le calcul explicite de \(\phi(\mathbf{x})\) serait impossible, mais le calcul du noyau \(K(\mathbf{x}, \mathbf{x}')\) ne coûte que \(O(d)\). La formulation duale du SVM ne fait intervenir que des produits scalaires, que l’on remplace directement par les évaluations du noyau.
Exemple 10
Considérons le noyau polynomial de degré 2 en dimension 2 : \(K(\mathbf{x}, \mathbf{x}') = (\mathbf{x} \cdot \mathbf{x}')^2\). Si \(\mathbf{x} = (x_1, x_2)\) et \(\mathbf{x}' = (x_1', x_2')\), alors
Ce qui correspond au produit scalaire dans l’espace de dimension 3 avec la transformation \(\phi(\mathbf{x}) = (x_1^2, \sqrt{2} x_1 x_2, x_2^2)\). Le noyau calcule implicitement ce produit scalaire sans construire \(\phi(\mathbf{x})\).
Noyaux classiques#
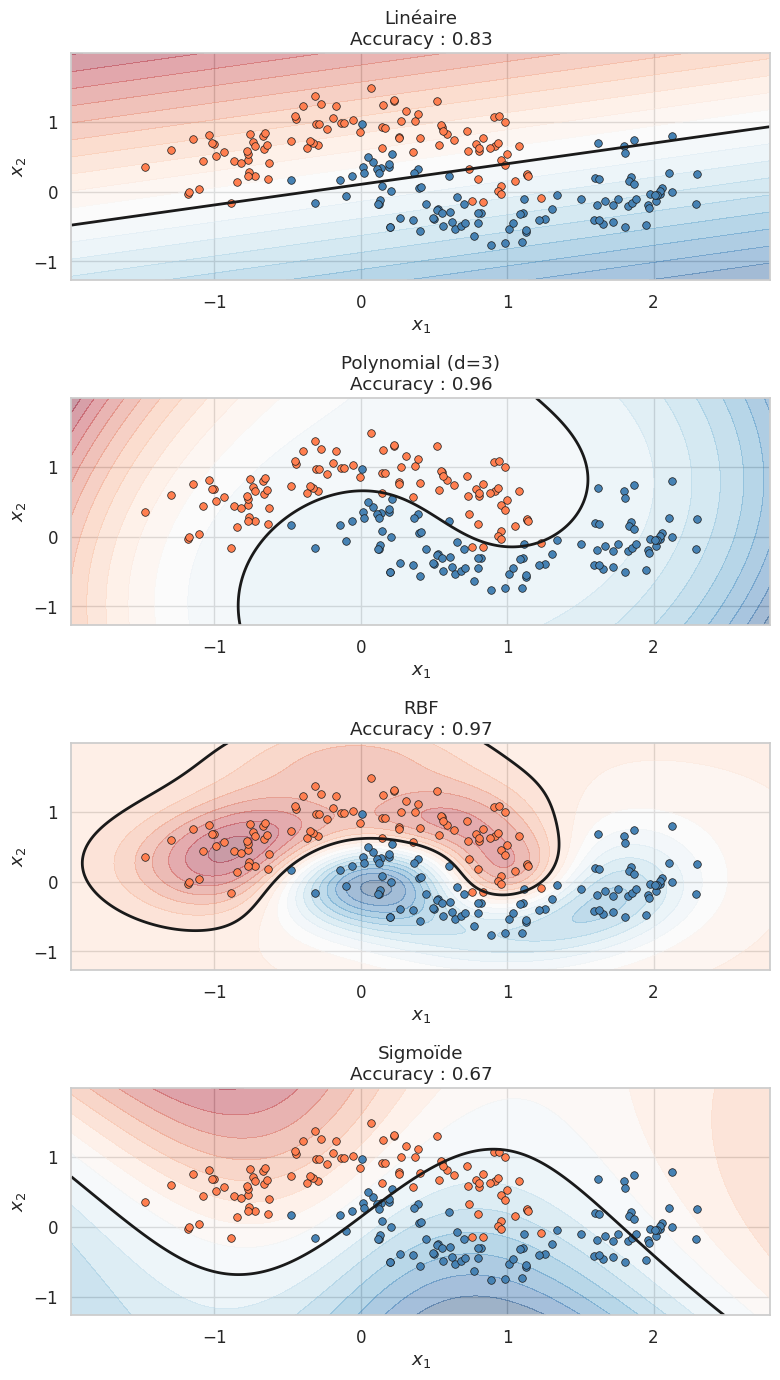
Plusieurs noyaux sont couramment utilisés en pratique. Le choix du noyau dépend de la nature des données et de la complexité de la frontière de décision recherchée.
Définition 117 (Noyau linéaire)
Le noyau linéaire est simplement le produit scalaire standard :
Il correspond à \(\phi(\mathbf{x}) = \mathbf{x}\) (pas de transformation). Le SVM avec noyau linéaire est équivalent au SVM linéaire classique.
Définition 118 (Noyau polynomial)
Le noyau polynomial de degré \(p\) est défini par
où \(p \in \mathbb{N}^*\) est le degré, \(\gamma > 0\) un facteur d’échelle et \(r \geq 0\) le terme constant (coef0). La transformation implicite \(\phi\) envoie les données dans un espace contenant tous les monômes de degré \(\leq p\), de dimension \(\binom{d + p}{p}\).
Définition 119 (Noyau RBF (gaussien))
Le noyau RBF (Radial Basis Function), ou noyau gaussien, est défini par
où \(\gamma = \frac{1}{2\sigma^2}\) contrôle la « portée » du noyau. La transformation implicite \(\phi\) envoie les données dans un espace de Hilbert de dimension infinie. Plus \(\gamma\) est grand (ou \(\sigma\) petit), plus le noyau est localisé et la frontière de décision est complexe.
Remarque 112
Le noyau RBF est le choix par défaut dans Scikit-learn et souvent le plus performant en pratique. Il peut approximer n’importe quelle frontière de décision continue avec suffisamment de données. Cependant, il possède deux hyperparamètres sensibles : \(C\) et \(\gamma\). Un \(\gamma\) trop grand conduit à de l’overfitting (chaque point d’entraînement forme son propre « îlot »), tandis qu’un \(\gamma\) trop petit rend le modèle quasi-linéaire.
Définition 120 (Noyau sigmoïde)
Le noyau sigmoïde est défini par
Il est lié aux réseaux de neurones (la tangente hyperbolique étant une fonction d’activation classique). Ce noyau n’est pas défini positif pour toutes les valeurs de \(\gamma\) et \(r\), il est donc à utiliser avec précaution.
Proposition 30 (Choix du noyau)
Noyau |
Formule |
Quand l’utiliser |
|---|---|---|
Linéaire |
\(K(\mathbf{x}, \mathbf{x}') = \mathbf{x} \cdot \mathbf{x}'\) |
Données de grande dimension (\(d \gg n\)), texte, problèmes linéairement séparables |
Polynomial |
\(K(\mathbf{x}, \mathbf{x}') = (\gamma \mathbf{x} \cdot \mathbf{x}' + r)^p\) |
Interactions entre features connues, NLP |
RBF |
\(K(\mathbf{x}, \mathbf{x}') = \exp(-\gamma |\mathbf{x} - \mathbf{x}'|^2)\) |
Choix par défaut, non-linéarité modérée à forte |
Sigmoïde |
\(K(\mathbf{x}, \mathbf{x}') = \tanh(\gamma \mathbf{x} \cdot \mathbf{x}' + r)\) |
Rarement utilisé, analogie réseau de neurones |
Effet de \(\gamma\) sur le noyau RBF#
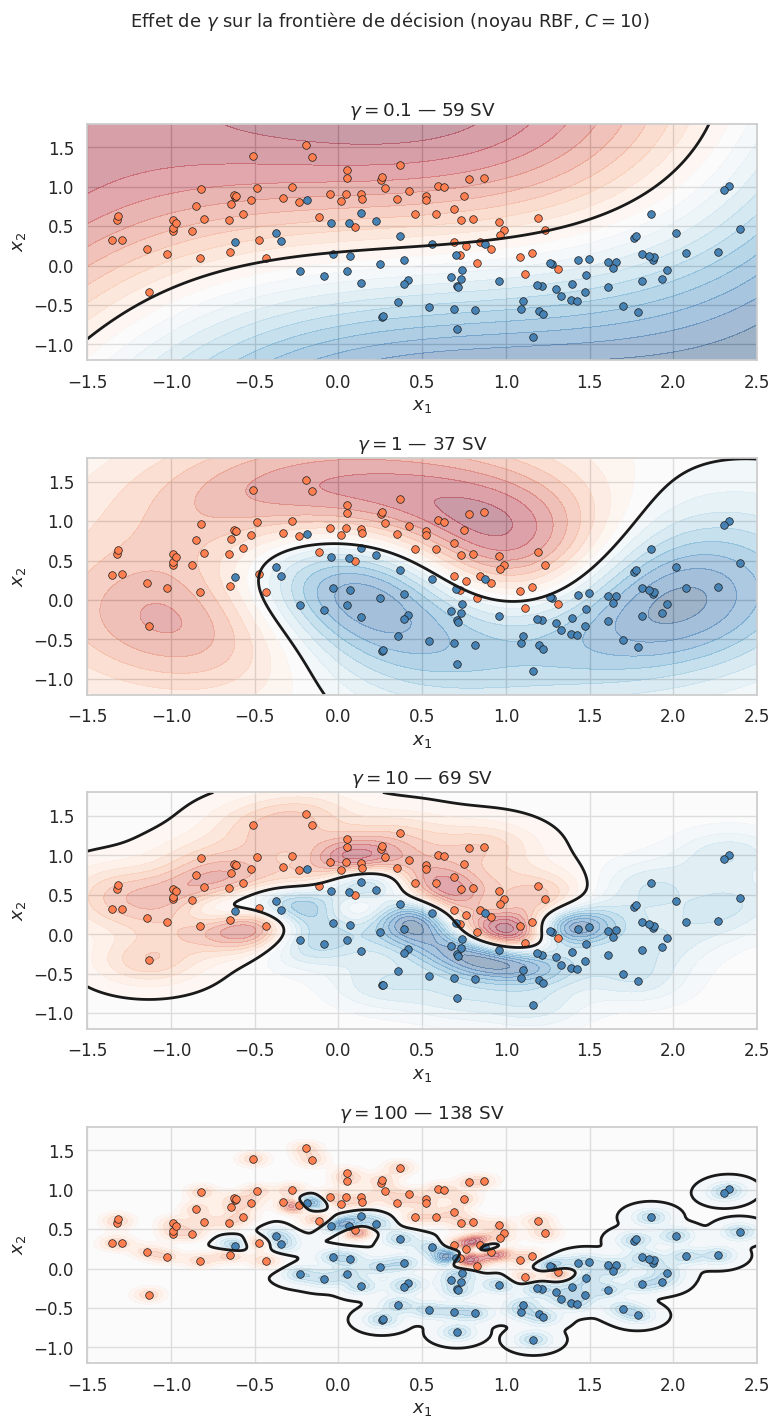
Remarque 113
On observe clairement le compromis biais-variance en fonction de \(\gamma\) :
\(\gamma = 0.1\) : frontière très lisse, proche d’un hyperplan linéaire (sous-apprentissage).
\(\gamma = 1\) : bon compromis, la frontière épouse la forme des données.
\(\gamma = 10\) : la frontière devient plus irrégulière.
\(\gamma = 100\) : chaque point d’entraînement forme presque son propre îlot, signe clair de surapprentissage.
SVM pour la régression (SVR)#
Les SVM peuvent être adaptés à la régression. Au lieu de maximiser la marge entre deux classes, le SVR (Support Vector Regression) cherche une fonction qui approche les données avec une tolérance \(\varepsilon\) : les erreurs inférieures à \(\varepsilon\) ne sont pas pénalisées.
Définition 121 (Régression à vecteurs de support (\(\varepsilon\)-SVR))
Soit un jeu d’entraînement \(\{(\mathbf{x}_i, y_i)\}_{i=1}^n\) avec \(y_i \in \mathbb{R}\). Le \(\varepsilon\)-SVR résout le problème d’optimisation
sous les contraintes
Le paramètre \(\varepsilon > 0\) définit un tube autour de la fonction de régression : les points situés à l’intérieur du tube ne contribuent pas à la perte. Les variables \(\xi_i\) et \(\xi_i^*\) mesurent les violations au-dessus et en dessous du tube, respectivement.
Définition 122 (Perte \(\varepsilon\)-insensible)
La perte \(\varepsilon\)-insensible (\(\varepsilon\)-insensitive loss) est définie par
Contrairement à la perte quadratique, cette fonction est exactement nulle lorsque l’erreur est inférieure à \(\varepsilon\), ce qui conduit à une solution parcimonieuse (seuls les points hors du tube sont des vecteurs de support).
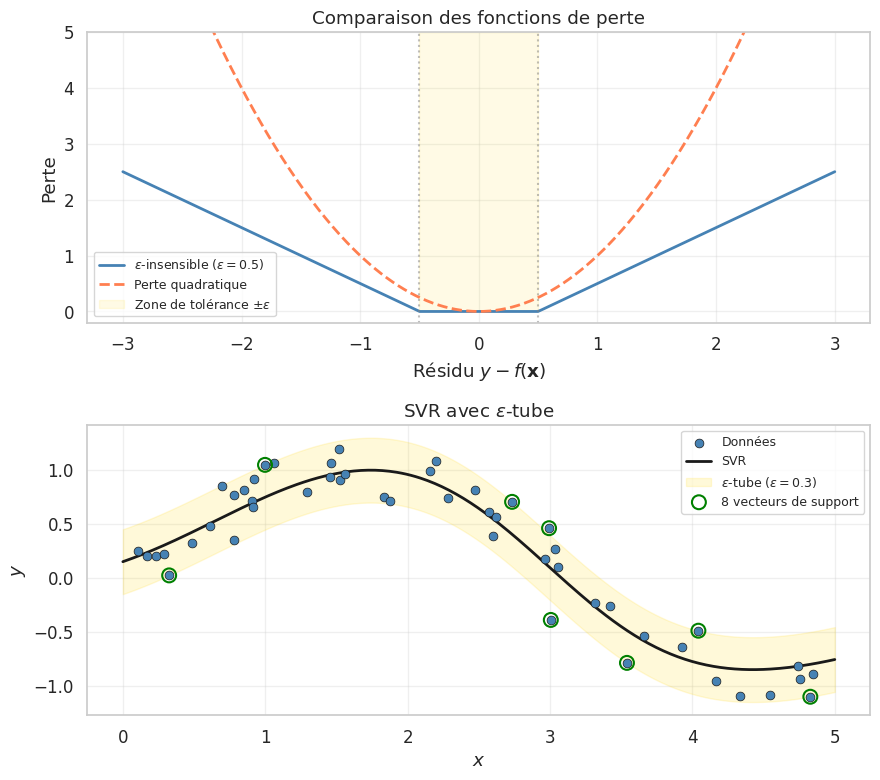
Remarque 114
Les hyperparamètres du SVR sont :
\(C\) : contrôle le compromis entre la platitude de la fonction (\(\|\mathbf{w}\|\) petit) et la tolérance aux erreurs hors du tube. Un \(C\) grand pénalise davantage les violations.
\(\varepsilon\) : la largeur du tube. Un \(\varepsilon\) grand ignore plus d’erreurs (modèle plus lisse, moins de vecteurs de support). Un \(\varepsilon\) petit force le modèle à passer plus près de chaque point.
\(\gamma\) (pour le noyau RBF) : contrôle la complexité de la fonction, comme en classification.
Exemple complet avec Scikit-learn#
Mettons en pratique l’ensemble des concepts sur un problème de classification plus réaliste.
Génération des données et prétraitement#
Entraînement : 350 observations
Test : 150 observations
Répartition des classes (train) : [172 178]
Comparaison des noyaux#
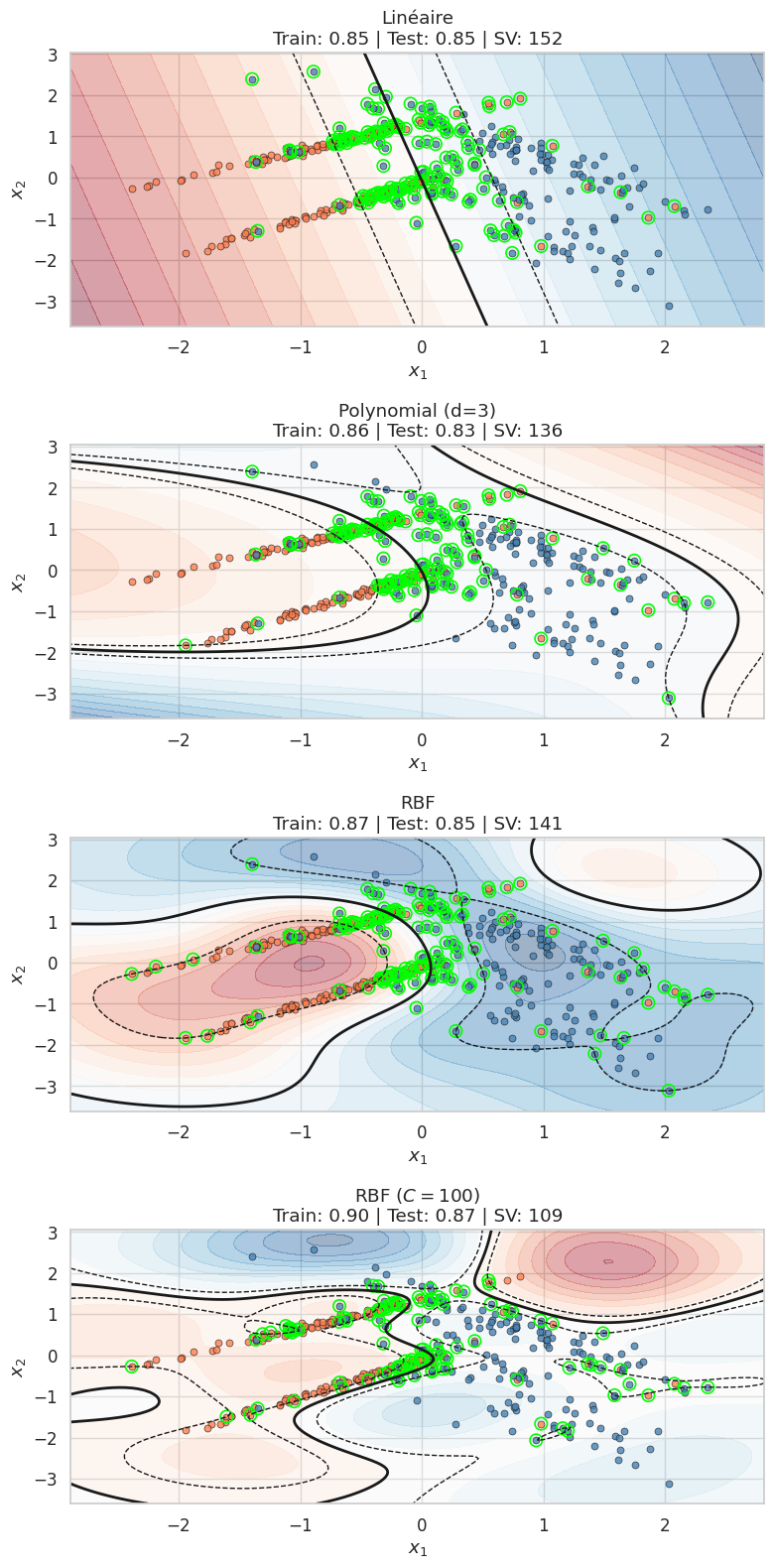
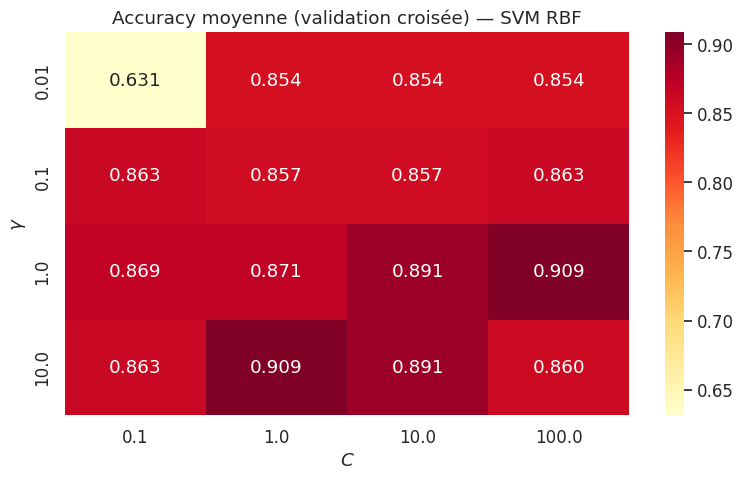
Recherche des hyperparamètres par validation croisée#
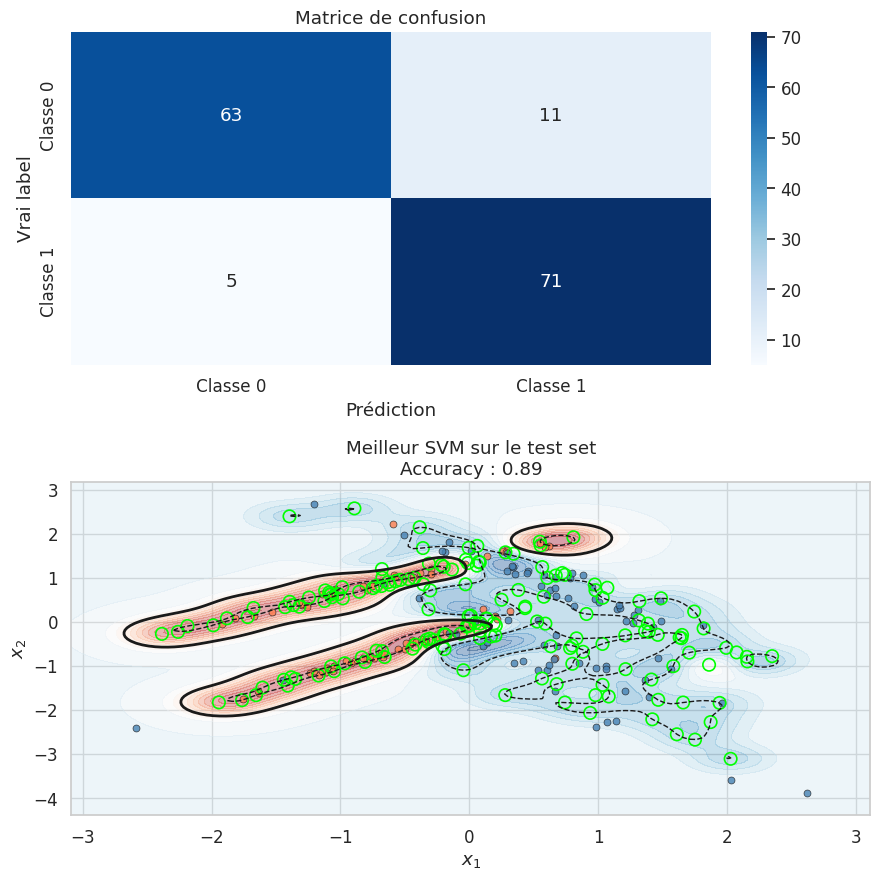
Meilleurs hyperparamètres : {'svc__C': 1, 'svc__gamma': 10}
Meilleur score CV : 0.9086
Score sur le test : 0.8933
Évaluation du meilleur modèle#
Rapport de classification :
precision recall f1-score support
0 0.93 0.85 0.89 74
1 0.87 0.93 0.90 76
accuracy 0.89 150
macro avg 0.90 0.89 0.89 150
weighted avg 0.90 0.89 0.89 150
SVM et données multi-classes#
Remarque 115
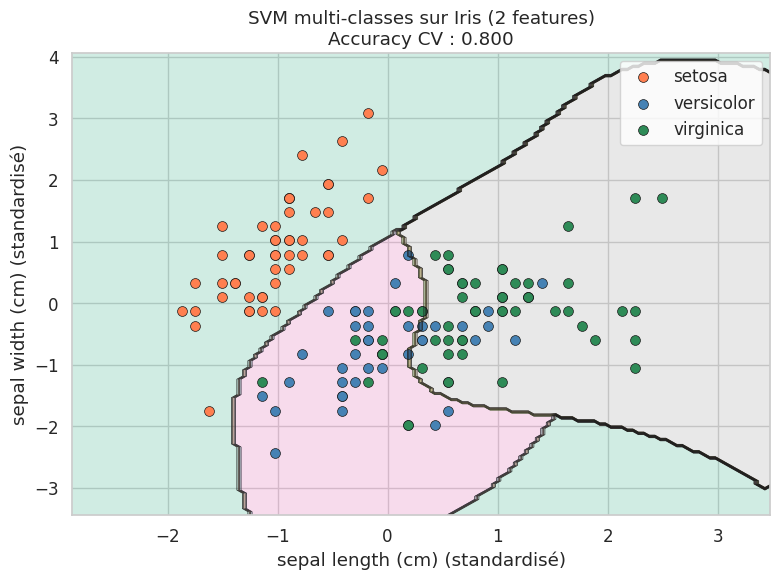
Le SVM est nativement un classifieur binaire. Pour traiter les problèmes multi-classes, Scikit-learn utilise par défaut la stratégie un-contre-un (one-vs-one, OVO) : pour \(k\) classes, on entraîne \(\binom{k}{2}\) classifieurs binaires, chacun distinguant une paire de classes. La prédiction finale est obtenue par vote majoritaire. L’alternative un-contre-tous (one-vs-rest, OVR) entraîne \(k\) classifieurs, chacun distinguant une classe de toutes les autres.
Iris (2 features) — Accuracy CV : 0.800 (+/- 0.060)
Résumé#
Les machines à vecteurs de support sont un outil puissant et théoriquement fondé pour la classification et la régression. Voici les points clés à retenir :
Concept |
Description |
|---|---|
Marge maximale |
Le SVM cherche l’hyperplan qui maximise la distance aux points les plus proches (vecteurs de support) |
Marge souple |
Les variables de relâchement \(\xi_i\) et le paramètre \(C\) permettent de tolérer des erreurs de classification |
Astuce du noyau |
Remplacer le produit scalaire par une fonction noyau \(K(\mathbf{x}, \mathbf{x}')\) permet de modéliser des frontières non linéaires |
Noyau RBF |
\(K(\mathbf{x}, \mathbf{x}') = \exp(-\gamma |\mathbf{x} - \mathbf{x}'|^2)\) : choix par défaut, très flexible |
SVR |
La perte \(\varepsilon\)-insensible et le tube \(\varepsilon\) étendent les SVM à la régression |
Hyperparamètres |
\(C\) (régularisation), \(\gamma\) (portée du noyau), \(\varepsilon\) (tolérance SVR) : à optimiser par validation croisée |
Proposition 31 (Avantages et limites des SVM)
Avantages :
Fondements théoriques solides (théorie de Vapnik-Chervonenkis, bornes de généralisation)
Efficaces en grande dimension (\(d \gg n\)), notamment avec le noyau linéaire
Robustes aux outliers grâce à la marge souple (seuls les vecteurs de support comptent)
L’astuce du noyau offre une grande flexibilité sans coût de calcul excessif
Limites :
Complexité d’entraînement en \(O(n^2)\) à \(O(n^3)\) selon l’implémentation, ce qui les rend inadaptés aux très grands jeux de données (\(n > 10^5\))
Sensibilité aux hyperparamètres (\(C\), \(\gamma\)) : une recherche par grille est souvent nécessaire
Pas de probabilités calibrées par défaut (l’option
probability=Trueutilise la méthode de Platt, coûteuse)Difficulté d’interprétation en espace noyau (les vecteurs de support vivent dans l’espace transformé)
Remarque 116
En pratique, la mise à l’échelle des features est indispensable pour les SVM. Puisque la marge dépend des distances euclidiennes (ou des produits scalaires), une feature dont les valeurs sont en milliers dominera une feature entre 0 et 1. Il faut toujours standardiser les données avant d’entraîner un SVM, idéalement au sein d’un Pipeline pour éviter toute fuite de données.