
Autoencodeurs#
Apprendre, c’est se retrouver.
— Malcolm de Chazal, Sens-Plastique
Les chapitres précédents ont introduit les architectures fondamentales de l’apprentissage profond : le perceptron multicouche (chapitre 16), la rétropropagation (chapitre 17), le cadre PyTorch (chapitre 18), les réseaux convolutifs (chapitre 19) et les réseaux récurrents (chapitre 20). Toutes ces architectures relèvent de l”apprentissage supervisé : elles nécessitent des étiquettes pour guider l’optimisation. Mais que se passe-t-il lorsque l’on souhaite apprendre une représentation compacte des données sans supervision ? C’est précisément l’objectif de l”apprentissage de représentations (representation learning), dont les autoencodeurs constituent l’une des approches les plus élégantes.
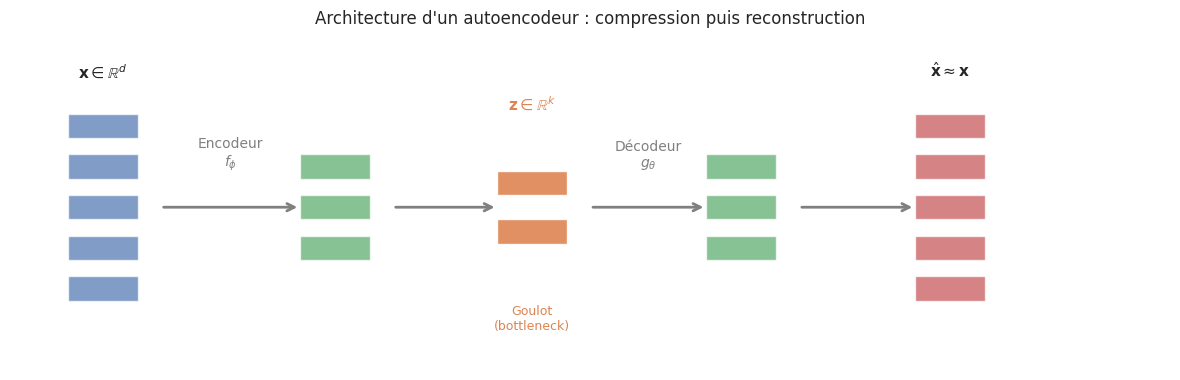
Un autoencodeur est un réseau de neurones entraîné à reconstruire son entrée en la faisant passer par un goulot d’étranglement (bottleneck) de dimension inférieure. En forçant le réseau à comprimer l’information, on l’oblige à découvrir les structures essentielles des données — une idée qui rejoint la réduction de dimensionnalité étudiée au chapitre 12, mais avec une puissance de modélisation bien supérieure grâce à la non-linéarité des réseaux de neurones.
Ce chapitre présente trois variantes d’autoencodeurs — le modèle classique, le débruiteur et le variationnel — avec leurs fondements mathématiques, leurs implémentations en PyTorch et des visualisations détaillées de leurs espaces latents.
Périphérique utilisé : cpu
Introduction : apprendre des représentations#
De la réduction linéaire à la compression neuronale#
Au chapitre 12, nous avons étudié l”Analyse en Composantes Principales (ACP), qui projette les données sur un sous-espace linéaire maximisant la variance conservée. L’ACP est un outil puissant mais limité : elle ne capture que les relations linéaires entre les variables. Pour des données complexes comme les images, les relations pertinentes sont fondamentalement non-linéaires.
Exemple 24 (Limites de l’ACP)
Considérons des images de visages. Deux visages peuvent être proches dans l’espace des pixels (même fond, même luminosité) tout en représentant des personnes très différentes, ou inversement. L’ACP, qui mesure la proximité par la distance euclidienne dans l’espace original, ne peut capturer ces subtilités sémantiques. Un autoencodeur, grâce à ses couches non-linéaires, peut apprendre une représentation latente où la distance reflète des attributs significatifs (expression, orientation, identité).
L’idée fondatrice des autoencodeurs est simple : utiliser un réseau de neurones pour apprendre simultanément une fonction de compression (l’encodeur) et une fonction de décompression (le décodeur), de sorte que la composition des deux reconstruise fidèlement l’entrée.
Définition 252 (Autoencodeur)
Un autoencodeur est une paire de fonctions paramétrées :
Un encodeur \(f_\phi : \mathcal{X} \to \mathcal{Z}\) qui associe à chaque entrée \(\mathbf{x} \in \mathbb{R}^d\) un code latent \(\mathbf{z} = f_\phi(\mathbf{x}) \in \mathbb{R}^k\) avec \(k \ll d\).
Un décodeur \(g_\theta : \mathcal{Z} \to \mathcal{X}\) qui reconstruit l’entrée à partir du code : \(\hat{\mathbf{x}} = g_\theta(\mathbf{z})\).
L’entraînement minimise l”erreur de reconstruction :
où \(\ell\) est typiquement l’erreur quadratique moyenne \(\|\mathbf{x} - \hat{\mathbf{x}}\|^2\) ou l’entropie croisée binaire.
Préparation des données#
Tout au long de ce chapitre, nous utiliserons des données synthétiques simulant des chiffres manuscrits. Nous générons un jeu de données de motifs structurés en 2D qui permettent d’illustrer clairement les concepts sans dépendre d’un téléchargement externe.
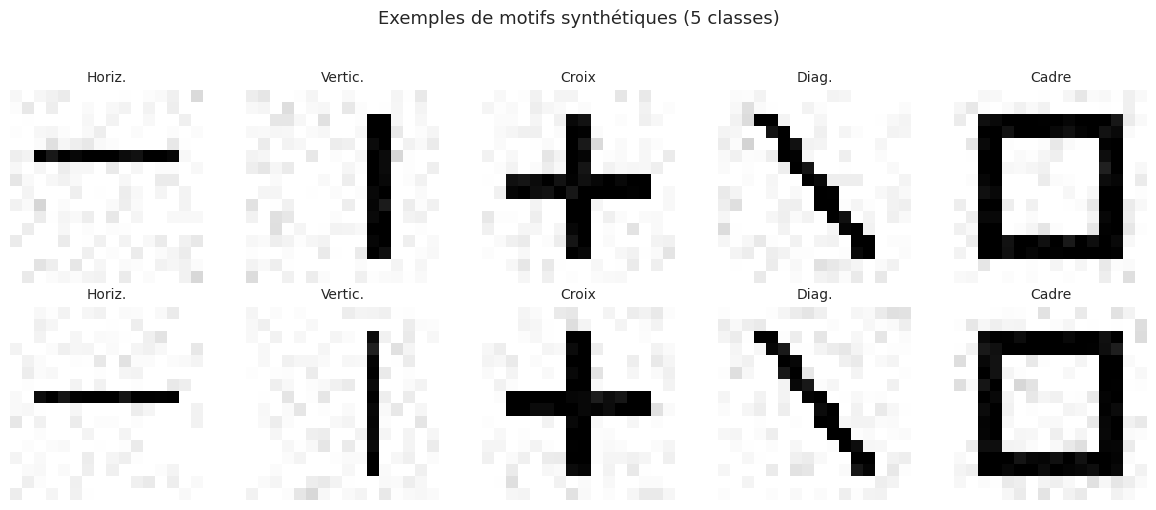
Dimensions : 4000 images de 16×16 pixels
Dimension d'entrée aplatie : 256
Autoencodeur simple (Vanilla Autoencoder)#
Architecture#
L’autoencodeur le plus simple est constitué de couches entièrement connectées. L’encodeur réduit progressivement la dimensionnalité jusqu’au goulot d’étranglement, puis le décodeur la reconstruit symétriquement.
Définition 253 (Autoencodeur sous-complet)
Un autoencodeur est dit sous-complet (undercomplete) lorsque la dimension de l’espace latent \(k\) est strictement inférieure à la dimension de l’entrée \(d\). Cette contrainte force le réseau à apprendre une compression non triviale. Si le réseau est linéaire et la perte est l’erreur quadratique, l’autoencodeur sous-complet apprend le même sous-espace que l’ACP.
Inversement, un autoencodeur sur-complet (overcomplete) a \(k \geq d\) et peut apprendre l’identité sans extraire de structure. Il nécessite des régularisations supplémentaires pour être utile.
Remarque 214
Le lien entre ACP et autoencodeur linéaire a été établi par Baldi et Hornik (1989). Avec des activations non-linéaires (ReLU, sigmoïde), l’autoencodeur dépasse l’ACP en capturant des variétés non-linéaires (nonlinear manifolds) dans l’espace des données.
Implémentation en PyTorch#
Autoencoder(
(encoder): Sequential(
(0): Linear(in_features=256, out_features=128, bias=True)
(1): ReLU()
(2): Linear(in_features=128, out_features=64, bias=True)
(3): ReLU()
(4): Linear(in_features=64, out_features=2, bias=True)
)
(decoder): Sequential(
(0): Linear(in_features=2, out_features=64, bias=True)
(1): ReLU()
(2): Linear(in_features=64, out_features=128, bias=True)
(3): ReLU()
(4): Linear(in_features=128, out_features=256, bias=True)
(5): Sigmoid()
)
)
Nombre total de paramètres : 82,818
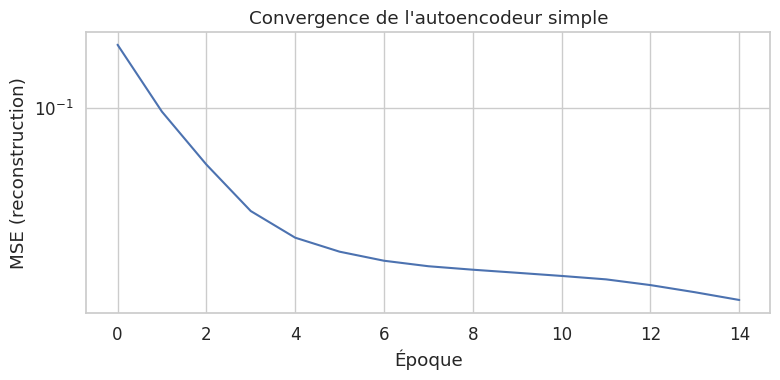
Entraînement#
La fonction de perte est l”erreur quadratique moyenne (MSE) entre l’entrée et la reconstruction. On utilise l’optimiseur Adam, introduit au chapitre 17, qui combine les avantages du momentum et de l’adaptation du pas d’apprentissage.
Entraînement de l'autoencodeur simple (dim. latente = 2) :
Visualisation des reconstructions#

Remarque 215
Avec seulement 2 dimensions latentes, l’autoencodeur parvient à reconstruire les grandes lignes des motifs, mais perd inévitablement certains détails. C’est le compromis fondamental de la compression : plus la dimension latente est faible, plus l’information est condensée, mais plus la reconstruction est approximative.
Évaluation quantitative#
Erreur de reconstruction (test) :
MSE : 0.014826
MAE : 0.049181
Autoencodeur débruiteur (Denoising Autoencoder)#
Motivation#
L’autoencodeur simple peut parfois apprendre une représentation trop spécifique, capturant le bruit des données plutôt que leur structure fondamentale. L”autoencodeur débruiteur (Denoising Autoencoder, DAE), proposé par Vincent et al. (2008), résout ce problème de manière élégante : on corrompt volontairement l’entrée par du bruit, puis on entraîne le réseau à reconstruire la version originale (non bruitée).
Définition 254 (Autoencodeur débruiteur)
Soit \(\tilde{\mathbf{x}} = \mathbf{x} + \boldsymbol{\epsilon}\) une version bruitée de l’entrée, où \(\boldsymbol{\epsilon} \sim \mathcal{N}(0, \sigma^2 I)\). L”autoencodeur débruiteur minimise :
L’entrée du réseau est la version bruitée \(\tilde{\mathbf{x}}\), mais la cible de reconstruction est la version propre \(\mathbf{x}\). Le réseau apprend ainsi à débruiter les données, ce qui l’oblige à capturer la structure sous-jacente plutôt que les fluctuations aléatoires.
Remarque 216
L’autoencodeur débruiteur a une interprétation théorique profonde : minimiser la perte de débruitage revient approximativement à maximiser un score (score matching), c’est-à-dire à apprendre le gradient du log de la distribution des données. Cette connexion, établie par Alain et Bengio (2014), relie les autoencodeurs débruiteurs aux modèles génératifs par score (score-based generative models), une famille de modèles qui a conduit aux récents modèles de diffusion.
Implémentation#
On réutilise la même architecture que l’autoencodeur simple, mais en ajoutant du bruit gaussien aux entrées pendant l’entraînement.
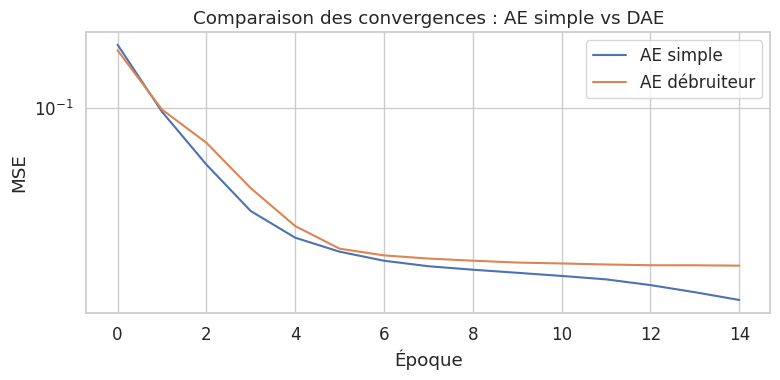
Entraînement de l'autoencodeur débruiteur :
Débruitage en action#

Remarque 217
La perte du DAE est systématiquement plus élevée que celle de l’AE simple, ce qui est attendu : le DAE doit reconstruire l’entrée propre à partir d’une version bruitée, une tâche intrinsèquement plus difficile. Cependant, cette difficulté supplémentaire agit comme une régularisation qui conduit à des représentations plus robustes et plus généralisables.
Autoencodeur variationnel (Variational Autoencoder)#
Motivation : de la compression à la génération#
Les autoencodeurs classiques apprennent un mapping déterministe de l’entrée vers l’espace latent. L’espace latent résultant est souvent irrégulier : certaines régions ne correspondent à aucune donnée réelle, et l’interpolation entre deux codes latents peut produire des reconstructions incohérentes.
L”autoencodeur variationnel (VAE), proposé par Kingma et Welling (2014), résout ce problème en imposant une structure probabiliste à l’espace latent. Au lieu d’encoder chaque entrée en un point \(\mathbf{z}\), l’encodeur produit les paramètres d’une distribution — la moyenne \(\boldsymbol{\mu}\) et la variance \(\boldsymbol{\sigma}^2\) — à partir de laquelle on échantillonne le code latent. Cette approche transforme l’autoencodeur en un véritable modèle génératif.
Définition 255 (Autoencodeur variationnel (VAE))
Un autoencodeur variationnel est un modèle génératif latent défini par :
Un prior sur l’espace latent : \(p(\mathbf{z}) = \mathcal{N}(\mathbf{0}, \mathbf{I})\)
Un décodeur (modèle génératif) : \(p_\theta(\mathbf{x} \mid \mathbf{z})\), paramétré par un réseau de neurones
Un encodeur (inférence approchée) : \(q_\phi(\mathbf{z} \mid \mathbf{x}) = \mathcal{N}(\boldsymbol{\mu}_\phi(\mathbf{x}),\, \text{diag}(\boldsymbol{\sigma}^2_\phi(\mathbf{x})))\)
L’encodeur approxime la distribution a posteriori intractable \(p(\mathbf{z} \mid \mathbf{x})\) par une gaussienne diagonale dont les paramètres sont produits par un réseau de neurones.
La borne inférieure variationnelle (ELBO)#
La log-vraisemblance marginale \(\log p_\theta(\mathbf{x})\) est intractable car elle requiert une intégration sur tout l’espace latent :
On maximise à la place une borne inférieure (Evidence Lower Bound, ELBO) :
Théorème 1 (ELBO (Evidence Lower Bound))
Pour toute distribution \(q_\phi(\mathbf{z} \mid \mathbf{x})\), on a :
Le premier terme encourage une bonne reconstruction des données. Le second terme, la divergence de Kullback-Leibler, force la distribution a posteriori approchée \(q_\phi\) à rester proche du prior \(p(\mathbf{z}) = \mathcal{N}(\mathbf{0}, \mathbf{I})\), ce qui régularise l’espace latent et le rend propice à la génération.
Remarque 218
L’écart entre \(\log p_\theta(\mathbf{x})\) et l’ELBO est exactement \(D_{\text{KL}}(q_\phi(\mathbf{z} \mid \mathbf{x}) \| p_\theta(\mathbf{z} \mid \mathbf{x}))\). Maximiser l’ELBO revient donc à la fois à maximiser la vraisemblance des données et à rapprocher l’encodeur de la vraie distribution a posteriori.
Divergence KL pour des gaussiennes#
Lorsque \(q_\phi(\mathbf{z} \mid \mathbf{x}) = \mathcal{N}(\boldsymbol{\mu}, \text{diag}(\boldsymbol{\sigma}^2))\) et \(p(\mathbf{z}) = \mathcal{N}(\mathbf{0}, \mathbf{I})\), la divergence KL admet une forme analytique.
Théorème 2 (Divergence KL entre gaussiennes)
Soit \(q = \mathcal{N}(\boldsymbol{\mu}, \text{diag}(\boldsymbol{\sigma}^2))\) et \(p = \mathcal{N}(\mathbf{0}, \mathbf{I})\), avec \(\boldsymbol{\mu} \in \mathbb{R}^k\) et \(\boldsymbol{\sigma} \in \mathbb{R}^k\). Alors :
Démonstration. Par définition de la divergence KL :
Le premier terme est l’entropie négative de \(q\) :
Le second terme, puisque \(p = \mathcal{N}(\mathbf{0}, \mathbf{I})\) :
En soustrayant :
L’astuce de reparamétrisation#
Pour rétropropager le gradient à travers l’opération d’échantillonnage \(\mathbf{z} \sim q_\phi(\mathbf{z} \mid \mathbf{x})\), on utilise l”astuce de reparamétrisation (reparameterization trick) : au lieu d’échantillonner directement depuis \(\mathcal{N}(\boldsymbol{\mu}, \boldsymbol{\sigma}^2)\), on écrit :
Ainsi, l’aléa est déporté dans \(\boldsymbol{\epsilon}\), et le gradient peut remonter à travers \(\boldsymbol{\mu}\) et \(\boldsymbol{\sigma}\), qui sont des sorties déterministes de l’encodeur.
Définition 256 (Astuce de reparamétrisation)
L”astuce de reparamétrisation consiste à exprimer la variable latente comme une transformation déterministe et différentiable d’un bruit externe :
Cette écriture permet de calculer \(\nabla_\phi \mathbb{E}_{q_\phi}[f(\mathbf{z})]\) par rétropropagation (chapitre 17), puisque \(\mathbf{z}\) est une fonction différentiable de \(\phi\).
Implémentation du VAE en PyTorch#
VAE(
(encoder_body): Sequential(
(0): Linear(in_features=256, out_features=128, bias=True)
(1): ReLU()
(2): Linear(in_features=128, out_features=64, bias=True)
(3): ReLU()
)
(fc_mu): Linear(in_features=64, out_features=2, bias=True)
(fc_log_var): Linear(in_features=64, out_features=2, bias=True)
(decoder): Sequential(
(0): Linear(in_features=2, out_features=64, bias=True)
(1): ReLU()
(2): Linear(in_features=64, out_features=128, bias=True)
(3): ReLU()
(4): Linear(in_features=128, out_features=256, bias=True)
(5): Sigmoid()
)
)
Entraînement du VAE :
Analyse de la perte ELBO#
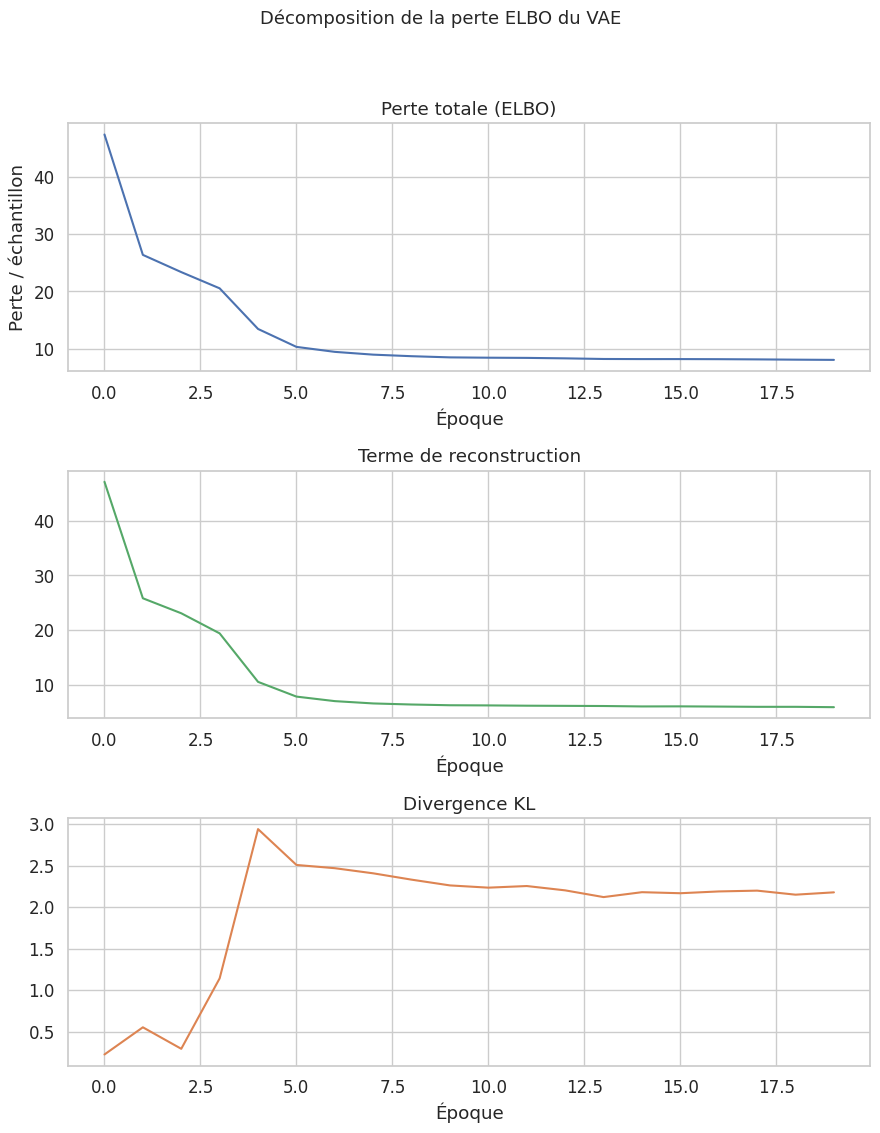
Remarque 219
On observe un phénomène classique : au début de l’entraînement, la divergence KL diminue (l’encodeur tente de s’écarter du prior pour mieux représenter les données), puis elle augmente progressivement lorsque la régularisation prend le dessus. Cet équilibre dynamique entre reconstruction et régularisation est au coeur du fonctionnement du VAE.
Reconstructions du VAE#
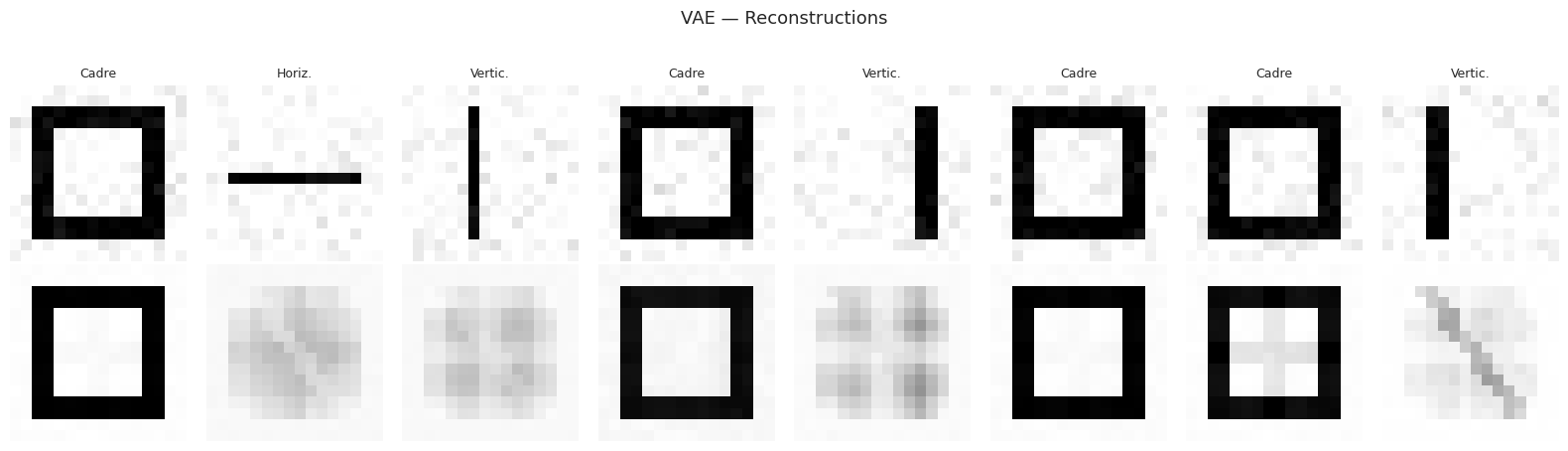
Génération de nouveaux échantillons#
L’avantage majeur du VAE sur l’autoencodeur simple est sa capacité à générer de nouvelles données en échantillonnant directement dans l’espace latent.

Espace latent#
Visualisation de l’espace latent 2D#
L’un des atouts d’une dimension latente de 2 est la possibilité de visualiser directement la structure de l’espace latent. Comparons les espaces latents de l’autoencodeur simple et du VAE.
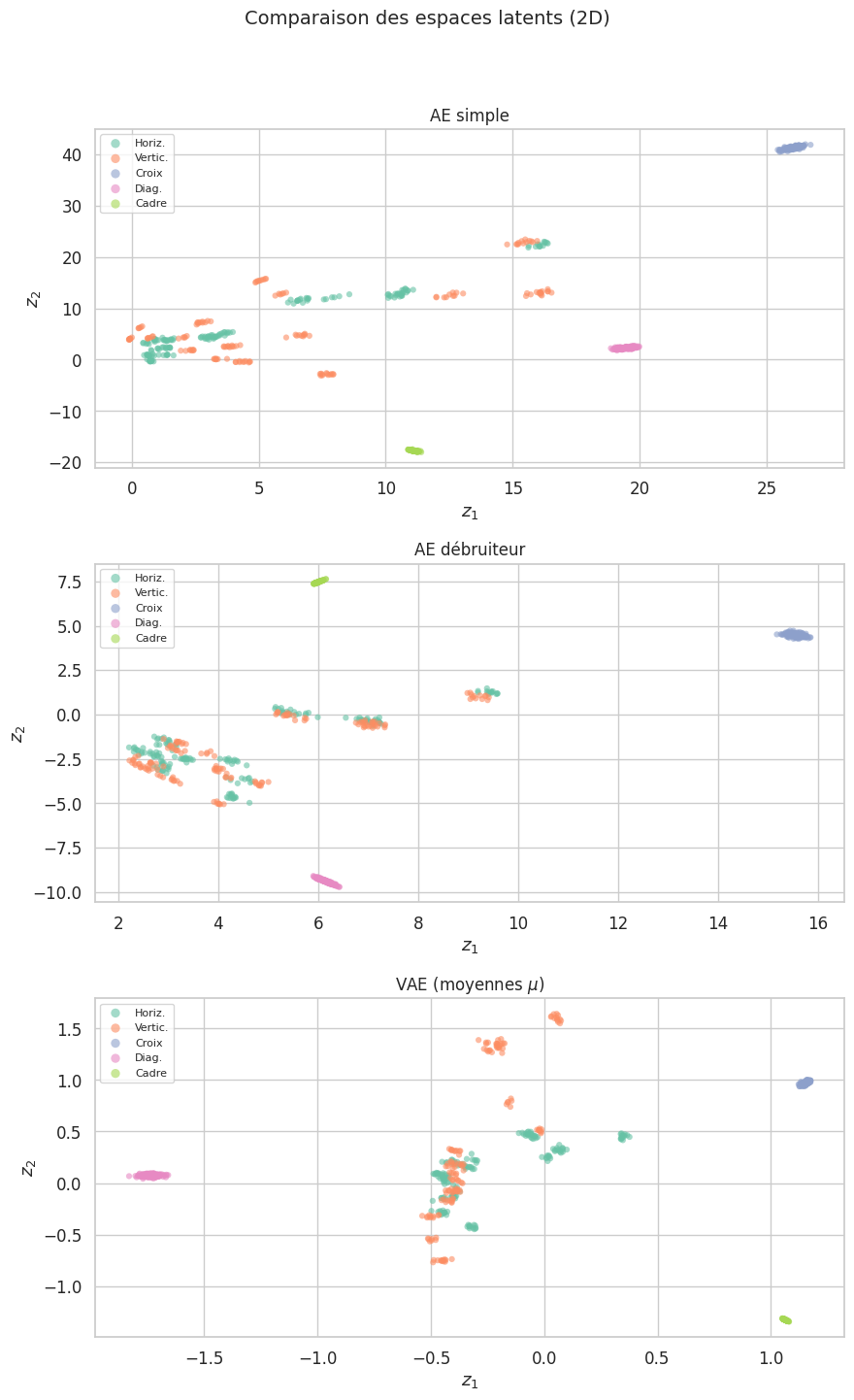
Remarque 220
La différence est frappante. L’espace latent de l’AE simple est irrégulier : les classes forment des amas de formes arbitraires, avec des « trous » entre eux. L’espace latent du VAE est au contraire régulier et continu, organisé autour de l’origine (grâce au prior gaussien). Cette régularité est ce qui permet au VAE de générer des échantillons réalistes : n’importe quel point de l’espace latent correspond à une image plausible.
Interpolation dans l’espace latent#
Pour évaluer la continuité de l’espace latent, on peut interpoler linéairement entre deux codes latents et observer les images générées le long du chemin.

Remarque 221
L’interpolation du VAE produit des transitions plus fluides et cohérentes. Chaque image intermédiaire ressemble à un motif plausible, tandis que l’AE simple peut produire des artefacts dans les régions de l’espace latent qui ne sont couvertes par aucune donnée d’entraînement. C’est une conséquence directe de la régularisation KL qui impose une structure continue à l’espace latent.
Grille de décodage de l’espace latent#
Une autre visualisation instructive consiste à balayer systématiquement l’espace latent 2D et à décoder chaque point en une image.
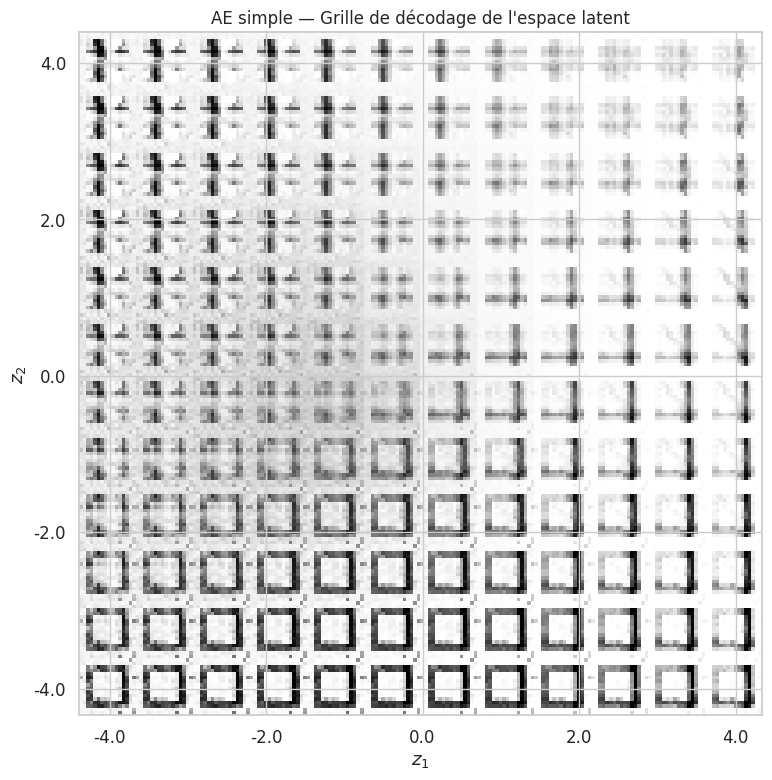
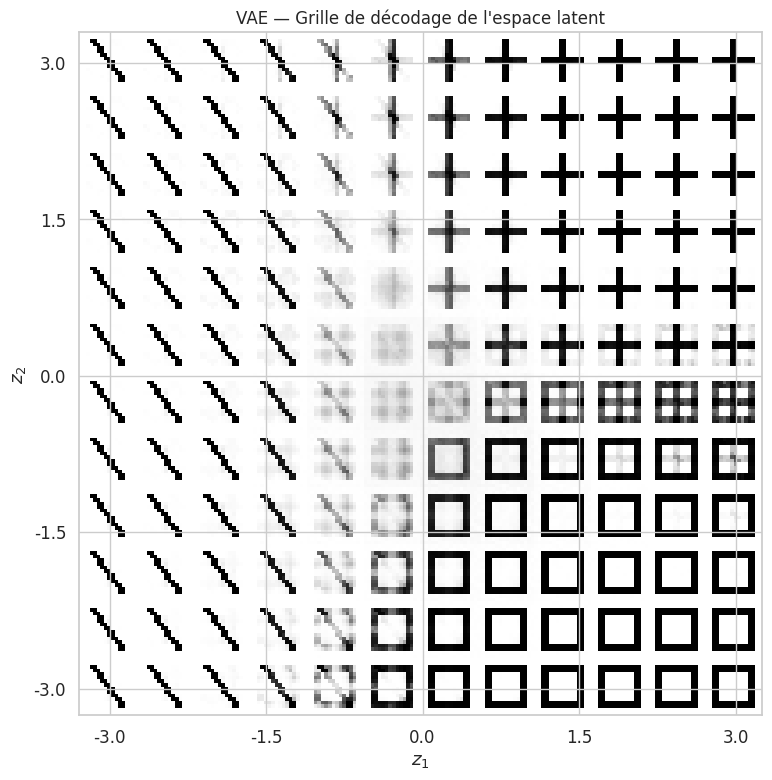
Exemple 25 (Lecture de la grille latente)
Dans la grille du VAE, on observe des transitions progressives entre les classes de motifs lorsqu’on se déplace dans l’espace latent. Par exemple, une barre horizontale se transforme graduellement en croix lorsqu’on se déplace le long d’un certain axe. Cette propriété de continuité sémantique est absente de l’AE simple, où le passage d’une région à une autre peut produire des images incohérentes.
Applications#
Détection d’anomalies#
L’erreur de reconstruction d’un autoencodeur peut servir de score d’anomalie. Un échantillon « normal » sera bien reconstruit (faible erreur), tandis qu’une anomalie — absente des données d’entraînement — produira une reconstruction de mauvaise qualité (forte erreur). Cette approche rejoint les méthodes étudiées au chapitre 14.
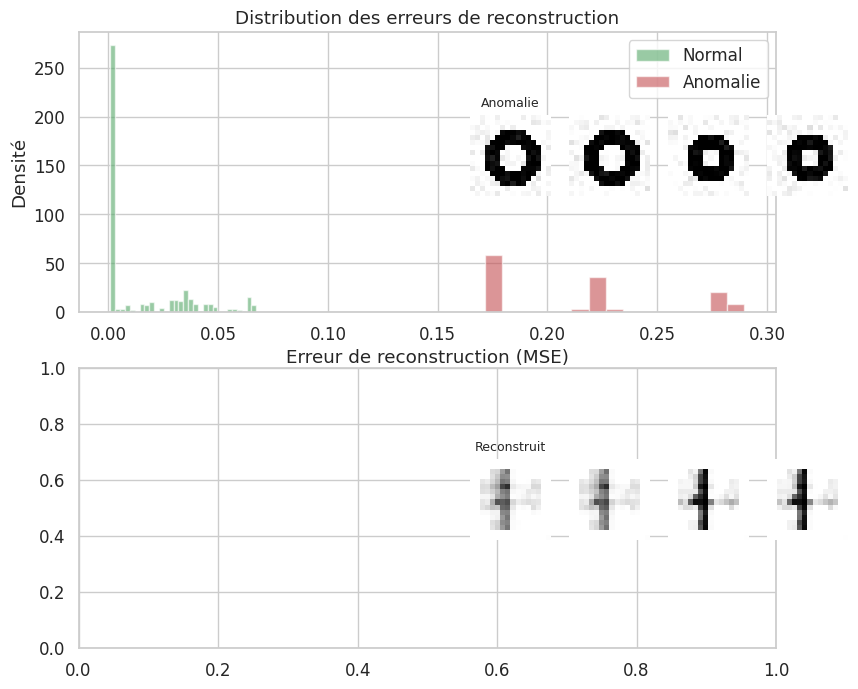
Erreur moyenne (normal) : 0.014826
Erreur moyenne (anomalie): 0.213865
Ratio anomalie/normal : 14.4x
Compression de données#
Un autoencodeur réalise une compression avec perte (lossy compression). Le taux de compression est le rapport entre la dimension originale et la dimension latente.
dim_latente= 2 — taux= 128.0:1 — MSE=0.020483
dim_latente= 4 — taux= 64.0:1 — MSE=0.017652
dim_latente= 8 — taux= 32.0:1 — MSE=0.020959
dim_latente= 16 — taux= 16.0:1 — MSE=0.015935
dim_latente= 32 — taux= 8.0:1 — MSE=0.016754
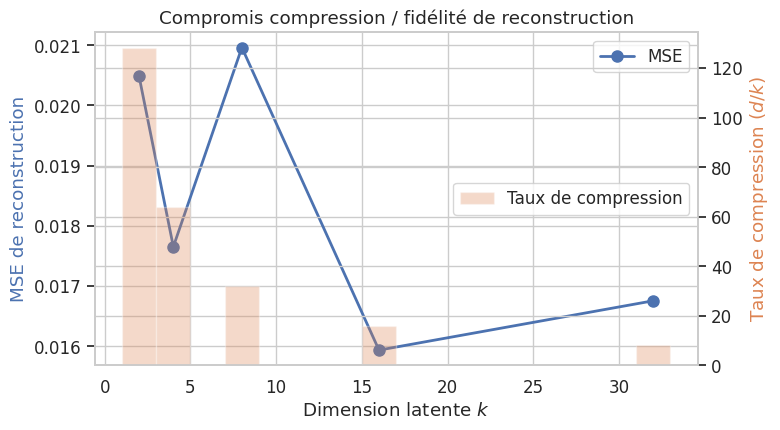
Remarque 222
On observe le compromis fondamental de la compression : augmenter la dimension latente améliore la reconstruction mais réduit le taux de compression. Le choix de \(k\) dépend de l’application : pour la visualisation, \(k = 2\) ou \(3\) est privilégié ; pour la compression ou le préentraînement, des valeurs plus élevées préservent davantage d’information.
Comparaison avec l’ACP#
Au chapitre 12, nous avons vu que l’ACP projette les données sur les axes de plus grande variance. Comparons l’ACP avec l’autoencodeur sur les mêmes données.
MSE (2 composantes) :
ACP : 0.029335
AE simple : 0.014826
VAE : 0.021678

Remarque 223
L’autoencodeur non-linéaire surpasse systématiquement l’ACP pour un même nombre de dimensions latentes, car il peut capturer des structures non-linéaires dans les données. Le VAE a une reconstruction légèrement inférieure à l’AE simple en raison de la régularisation KL, mais son espace latent est beaucoup plus structuré et permet la génération.
Tableau récapitulatif des variantes#
Modèle Type Génératif Régularisation Espace latent Forces
AE simple Déterministe Non Bottleneck Irrégulier Simple, rapide
AE débruiteur Déterministe Non Bruit + Bottleneck Robuste Robuste au bruit
VAE Probabiliste Oui KL + Bottleneck Continu, régulier Génération, interpolation
ACP (linéaire) Déterministe Non Orthogonalité Linéaire Interprétable, analytique
Extensions et variantes modernes#
Le problème du flou dans les VAE#
Le terme de reconstruction MSE du VAE tend à produire des images floues, car il pénalise la distance pixel par pixel sans considérer la structure perceptuelle. Plusieurs solutions ont été proposées.
Définition 257 (Beta-VAE)
Le \(\beta\)-VAE (Higgins et al., 2017) pondère le terme KL par un hyperparamètre \(\beta > 0\) :
\(\beta > 1\) : régularisation plus forte, espace latent plus disentangled (facteurs indépendants).
\(\beta < 1\) : meilleure reconstruction, espace latent moins régulier.
\(\beta = 1\) : VAE standard.
beta=0.1 — MSE=0.021427
beta=1.0 — MSE=0.023927
beta=4.0 — MSE=0.048923
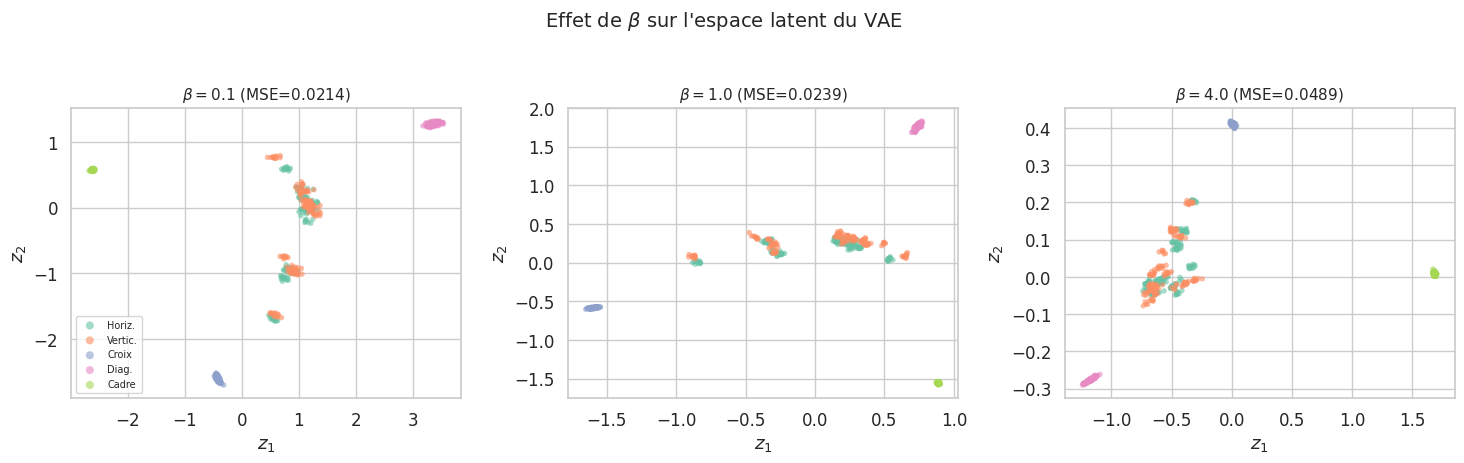
Remarque 224
Avec \(\beta > 1\), les clusters deviennent plus compacts et mieux séparés, mais la qualité de la reconstruction diminue. C’est le compromis fondamental du \(\beta\)-VAE : un espace latent plus désentrelacé (disentangled) au prix d’une reconstruction plus floue. Le choix de \(\beta\) dépend de l’objectif : génération (\(\beta \approx 1\)), apprentissage de représentations interprétables (\(\beta > 1\)), ou reconstruction fidèle (\(\beta < 1\)).
Autoencodeurs convolutifs#
Pour les données d’images, il est naturel de remplacer les couches denses par des couches convolutives (chapitre 19). L’encodeur utilise des convolutions avec stride pour réduire la résolution, tandis que le décodeur utilise des convolutions transposées (transposed convolutions) pour la reconstruire.
Définition 258 (Autoencodeur convolutif)
Un autoencodeur convolutif utilise :
Encodeur : couches de convolution 2D avec stride \(> 1\) (sous-échantillonnage progressif) :
Décodeur : couches de convolution transposée (ConvTranspose2D) avec stride \(> 1\) (sur-échantillonnage progressif) :
Le goulot d’étranglement est un tenseur de petite résolution spatiale et grand nombre de canaux, souvent aplati en vecteur pour la couche latente.
Paramètres — AE dense : 82,818 | AE convolutif : 12,131
Entraînement de l'autoencodeur convolutif :
MSE (test) — AE dense : 0.014826 | AE convolutif : 0.024243
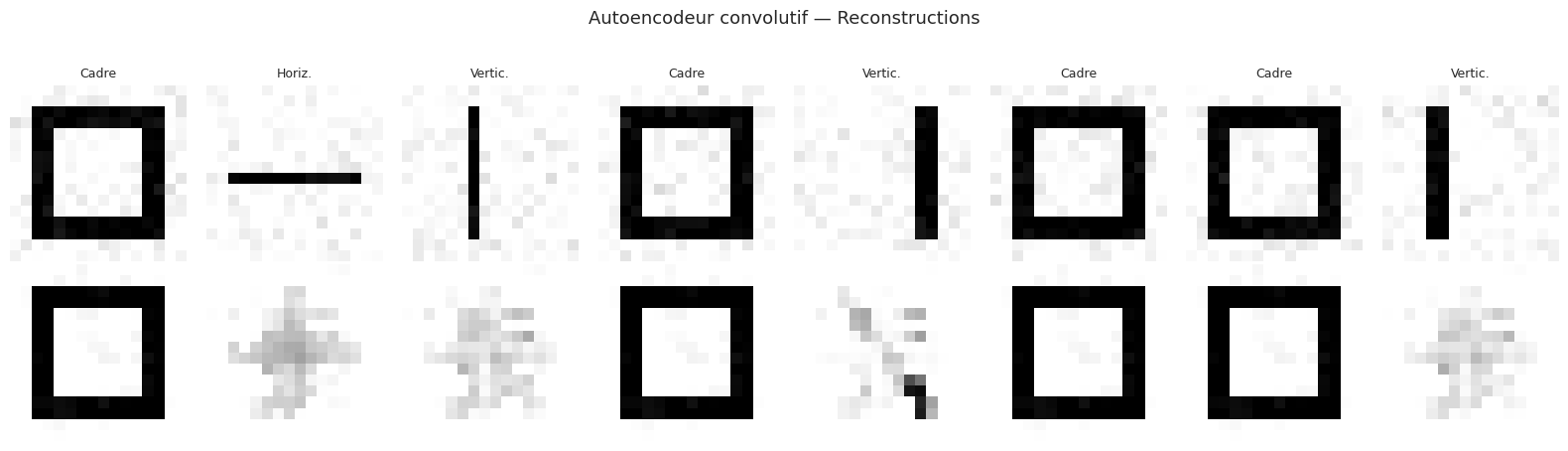
Remarque 225
L’autoencodeur convolutif exploite la structure spatiale des images grâce au partage de poids et à la connectivité locale (chapitre 19). Pour des images de plus grande taille (par exemple \(64 \times 64\) ou \(256 \times 256\)), les architectures convolutives deviennent indispensables car les couches denses ne sont plus praticables en raison du nombre de paramètres.
Résumé#
Ce chapitre a présenté les autoencodeurs, une famille de réseaux de neurones entraînés à reconstruire leurs entrées à travers un goulot d’étranglement, apprenant ainsi des représentations comprimées des données.
L”autoencodeur simple (vanilla) compresse les données via un encodeur et les reconstruit via un décodeur symétrique. Avec des activations non-linéaires, il dépasse l’ACP (chapitre 12) en capturant des structures non-linéaires.
L”autoencodeur débruiteur (DAE) améliore la robustesse des représentations en s’entraînant à reconstruire les entrées propres à partir de versions corrompues par du bruit. Il agit comme une forme de régularisation qui force le réseau à capturer la structure essentielle des données.
L”autoencodeur variationnel (VAE) introduit une structure probabiliste dans l’espace latent en encodant chaque entrée comme une distribution gaussienne plutôt qu’un point. La perte ELBO combine un terme de reconstruction et une divergence KL qui régularise l’espace latent.
L”astuce de reparamétrisation permet de rétropropager le gradient à travers l’opération d’échantillonnage, rendant l’entraînement du VAE possible par descente de gradient (chapitre 17).
L”espace latent du VAE est continu et régulier, ce qui permet des interpolations fluides et la génération de nouveaux échantillons en décodant des points échantillonnés du prior.
Les autoencodeurs trouvent des applications en compression, débruitage, détection d’anomalies (chapitre 14) et apprentissage de représentations. Les variantes convolutives sont préférées pour les données d’images.
Le \(\beta\)-VAE offre un contrôle explicite du compromis entre qualité de reconstruction et régularité de l’espace latent, favorisant l’apprentissage de représentations désentrelacées.
Remarque 226
Les autoencodeurs constituent une brique fondamentale de l’apprentissage profond moderne. Le cadre variationnel a ouvert la voie à toute une famille de modèles génératifs profonds, incluant les réseaux adversariaux génératifs (GAN, chapitre 22), les flux normalisants (normalizing flows) et les récents modèles de diffusion (diffusion models) qui dominent aujourd’hui la génération d’images. Les idées centrales — espace latent structuré, reparamétrisation, compromis reconstruction-régularisation — réapparaîtront tout au long de la suite de cet ouvrage.