
Éthique et biais#
Science sans conscience n’est que ruine de l’âme.
— Rabelais, Pantagruel
L’apprentissage automatique est passé en quelques années du laboratoire de recherche aux décisions qui affectent la vie quotidienne de millions de personnes : octroi de crédit, diagnostic médical, recrutement, justice pénale, modération de contenus. Cette omniprésence confère aux praticiens du machine learning une responsabilité considérable. Un modèle entraîné sur des données biaisées reproduit et amplifie les injustices historiques ; un système opaque prive les personnes affectées de tout recours. Ce chapitre — le dernier de cet ouvrage — aborde les questions d”éthique, de biais, d”équité algorithmique et de vie privée qui doivent accompagner chaque étape du cycle de vie d’un modèle, depuis la collecte des données jusqu’à son déploiement en production.
Introduction : pourquoi l’éthique compte#
Des controverses révélatrices#
Plusieurs affaires médiatisées ont mis en lumière les risques des systèmes d’apprentissage automatique déployés sans garde-fous suffisants.
COMPAS (Correctional Offender Management Profiling for Alternative Sanctions). Ce logiciel, utilisé par des tribunaux américains pour évaluer le risque de récidive, a été analysé en 2016 par l’organisation ProPublica. L’enquête a révélé que le système attribuait aux accusés noirs un risque de récidive deux fois plus élevé qu’aux accusés blancs, à profil criminel comparable. Le score était présenté aux juges comme une aide à la décision pour fixer les peines et les conditions de libération.
Reconnaissance faciale. Plusieurs études, notamment les travaux de Joy Buolamwini et Timnit Gebru (Gender Shades, 2018), ont montré que les systèmes commerciaux de reconnaissance faciale présentaient des taux d’erreur pouvant atteindre 34,7 % pour les femmes à peau foncée, contre moins de 1 % pour les hommes à peau claire. Ces disparités s’expliquent par le manque de diversité dans les jeux de données d’entraînement.
Outil de recrutement d’Amazon. En 2018, il a été révélé qu’Amazon avait abandonné un outil interne de tri automatique de CV après avoir constaté qu’il pénalisait systématiquement les candidatures féminines. Le modèle, entraîné sur dix années de données de recrutement dominées par des profils masculins, avait appris à associer le genre féminin à un signal négatif.
Remarque 272
Ces exemples ne sont pas des défaillances techniques isolées : ils sont la conséquence directe de choix humains — choix des données, des variables, des métriques d’optimisation, du cadre de déploiement. L’éthique en apprentissage automatique n’est pas un supplément optionnel ; elle fait partie intégrante de la compétence du praticien.
La responsabilité du praticien#
Le développeur d’un modèle de machine learning n’est pas un simple technicien : il fait des choix qui ont des conséquences sociales. Quelles données collecter ? Quelles variables inclure ? Quelle métrique optimiser ? Comment interpréter et communiquer les résultats ? À chacune de ces étapes, des décisions apparemment techniques encodent des valeurs et des hypothèses sur le monde.
Biais dans les données#
Sources de biais#
Les biais dans les données d’entraînement constituent la source la plus fréquente d’injustice algorithmique. On distingue plusieurs catégories.
Définition 324 (Principales sources de biais dans les données)
Biais historique (historical bias) : les données reflètent des inégalités ou des discriminations passées. Exemple : si les femmes ont historiquement été sous-représentées dans les postes de direction, un modèle entraîné sur ces données associera le genre féminin à une moindre probabilité de promotion.
Biais de représentation (representation bias) : certains groupes sont sous-représentés dans les données collectées. Exemple : un jeu de données d’images faciales contenant 80 % de visages à peau claire.
Biais de mesure (measurement bias) : les variables mesurées ne capturent pas fidèlement le phénomène d’intérêt, et les erreurs de mesure sont corrélées à l’appartenance à un groupe. Exemple : utiliser le nombre d’arrestations comme proxy de la criminalité réelle, alors que les pratiques policières varient selon les quartiers.
Biais d’agrégation (aggregation bias) : un modèle unique est appliqué à des populations hétérogènes pour lesquelles les relations entre variables diffèrent. Exemple : un même modèle de diagnostic pour des populations ayant des prévalences très différentes d’une maladie.
Biais de sélection (selection bias) : l’échantillon de données n’est pas représentatif de la population cible. Exemple : un modèle de détection de fraude entraîné uniquement sur les transactions ayant déjà fait l’objet d’une enquête.
Biais d’étiquetage (label bias) : les étiquettes elles-mêmes sont biaisées par les jugements humains. Exemple : des annotateurs qui attribuent plus facilement l’étiquette « toxique » à des textes en dialecte afro-américain.
Exemple 49 (Biais de survie)
Le biais de survie (survivorship bias) est un cas particulier de biais de sélection : on n’observe que les individus ayant « survécu » à un processus de filtrage. L’exemple classique est celui d’Abraham Wald durant la Seconde Guerre mondiale : les militaires voulaient renforcer les zones des avions les plus touchées par les impacts de balles sur les appareils revenus de mission. Wald fit remarquer qu’il fallait au contraire renforcer les zones sans impacts — car les avions touchés à ces endroits n’étaient pas revenus. En machine learning, un modèle de crédit entraîné uniquement sur les clients ayant obtenu un prêt souffre du même biais : il ne sait rien des clients refusés.
Démonstration : biais dans un jeu de données synthétique#
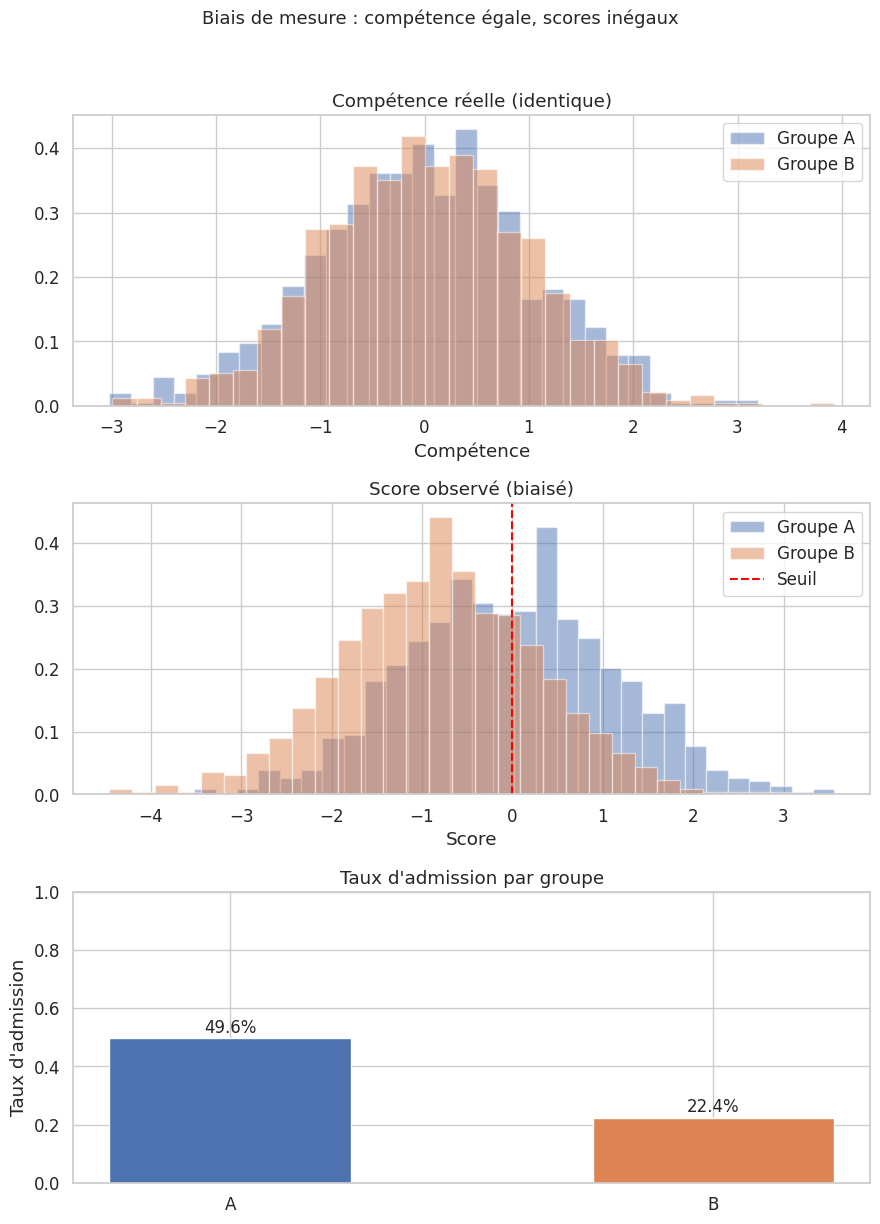
Construisons un jeu de données synthétique simulant un processus de sélection biaisé. Nous modélisons un scénario d’admission universitaire où un attribut sensible (le groupe d’appartenance) influence à la fois la variable observée (le score au test) et la décision finale.
Taux d'admission par groupe :
groupe
A 0.496
B 0.224
Name: admis, dtype: float64
Différence de compétence réelle moyenne : 0.025
Remarque 273
Dans cet exemple, la compétence réelle des deux groupes est identique par construction. Pourtant, le biais de mesure (le décalage de \(-0.8\) sur le score du groupe B) produit une disparité d’admission considérable. Si l’on entraîne un modèle sur ces données historiques, il apprendra à reproduire et renforcer cette inégalité. Le biais est d’autant plus pernicieux qu’il est invisible si l’on ne dispose pas d’une mesure indépendante de la compétence réelle.
Biais dans les modèles#
Amplification des biais#
Un modèle d’apprentissage automatique ne se contente pas de reproduire les biais présents dans les données : il peut les amplifier. Ce phénomène s’explique par le fait que l’optimisation pousse le modèle à exploiter toute corrélation statistique présente dans les données, y compris les corrélations spurieuses liées à l’appartenance à un groupe protégé.
Définition 325 (Discrimination par proxy)
La discrimination par proxy (proxy discrimination) survient lorsqu’un modèle utilise des variables qui, bien que neutres en apparence, sont fortement corrélées à un attribut sensible. Par exemple :
Le code postal est souvent un proxy de l’origine ethnique en raison de la ségrégation résidentielle.
Le prénom peut être un proxy du genre ou de l’origine culturelle.
Le type de navigateur web a été utilisé comme proxy du niveau socio-économique.
Supprimer l’attribut sensible des données d’entraînement (approche dite fairness through unawareness) ne suffit donc pas à éliminer la discrimination.
Boucles de rétroaction#
Définition 326 (Boucle de rétroaction)
Une boucle de rétroaction (feedback loop) apparaît lorsque les prédictions d’un modèle influencent les données futures sur lesquelles il sera réentraîné, créant un cycle auto-renforçant :
Exemple : un algorithme de police prédictive envoie davantage de patrouilles dans certains quartiers. Ces patrouilles supplémentaires entraînent mécaniquement plus d’arrestations dans ces quartiers, ce qui renforce la prédiction initiale, indépendamment du taux de criminalité réel.
Démonstration : impact disparate d’un classifieur biaisé#
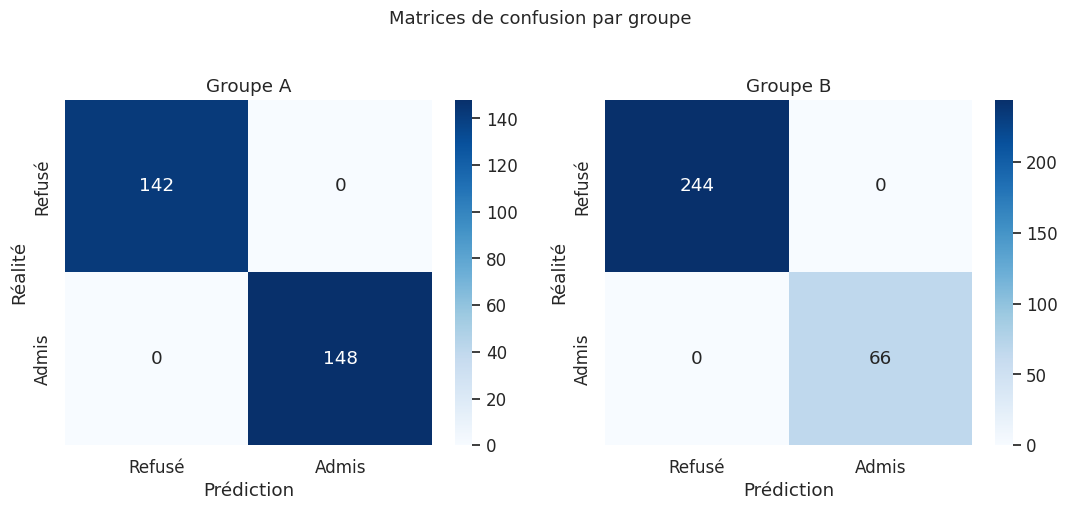
Entraînons un classifieur sur les données biaisées construites précédemment et mesurons l”impact disparate (disparate impact) de ses prédictions.
=== Impact disparate ===
Groupe A : taux prédit positif = 0.510, taux réel positif = 0.510
Groupe B : taux prédit positif = 0.213, taux réel positif = 0.213
Ratio d'impact disparate : 0.417
Règle des 80 % respectée : Non
Définition 327 (Règle des quatre cinquièmes (80 %))
La règle des quatre cinquièmes (four-fifths rule), issue du droit américain de l’emploi, stipule qu’un processus de sélection est présumé discriminatoire si le taux de sélection du groupe le moins favorisé est inférieur à 80 % du taux de sélection du groupe le plus favorisé :
où \(G\) désigne l’attribut sensible et \(\hat{P}(Y=1 \mid G=g)\) le taux de prédiction positive pour le groupe \(g\).
Équité algorithmique#
Définitions formelles de l’équité#
L’équité algorithmique (algorithmic fairness) est un domaine de recherche actif qui vise à formaliser mathématiquement la notion de « justice » dans les systèmes décisionnels automatisés. Plusieurs définitions coexistent, chacune capturant un aspect différent de l’équité.
Notons \(Y\) la variable cible réelle, \(\hat{Y}\) la prédiction du modèle et \(G\) l’attribut sensible (genre, origine, etc.).
Définition 328 (Parité démographique)
La parité démographique (demographic parity ou statistical parity) exige que la prédiction du modèle soit indépendante de l’attribut sensible :
Autrement dit, chaque groupe doit recevoir le même taux de prédictions positives, indépendamment de la réalité.
Définition 329 (Égalité des chances)
L”égalité des chances (equalized odds) exige que les taux de vrais positifs et de faux positifs soient identiques entre les groupes :
Une version relâchée, l”égalité d’opportunité (equal opportunity), n’impose cette condition que pour \(Y = 1\) (les vrais positifs).
Définition 330 (Parité prédictive)
La parité prédictive (predictive parity) exige que la valeur prédictive positive (positive predictive value, PPV) soit identique entre les groupes :
Autrement dit, lorsque le modèle prédit un résultat positif, la probabilité que cette prédiction soit correcte doit être la même quel que soit le groupe.
Théorème d’impossibilité#
L’un des résultats les plus importants de la recherche sur l’équité algorithmique est le théorème d’impossibilité, établi indépendamment par Chouldechova (2017) et Kleinberg, Mullainathan et Raghavan (2016).
Définition 331 (Théorème d’impossibilité de l’équité)
Sauf dans les cas triviaux où les taux de base sont identiques entre les groupes (\(P(Y=1 \mid G=a) = P(Y=1 \mid G=b)\)) ou le classifieur est parfait, il est impossible de satisfaire simultanément les trois critères suivants :
Calibration : \(P(Y=1 \mid S=s, G=a) = P(Y=1 \mid S=s, G=b)\) pour tout score \(s\)
Équilibre pour les positifs : \(\mathbb{E}[S \mid Y=1, G=a] = \mathbb{E}[S \mid Y=1, G=b]\)
Équilibre pour les négatifs : \(\mathbb{E}[S \mid Y=0, G=a] = \mathbb{E}[S \mid Y=0, G=b]\)
Ce résultat implique que le choix d’une notion d’équité est nécessairement un choix de valeurs, pas un choix technique.
Remarque 274
Le théorème d’impossibilité ne signifie pas qu’il faut renoncer à l’équité. Il signifie qu’il faut expliciter la définition d’équité retenue et justifier ce choix en fonction du contexte d’application. Dans un système de justice pénale, on pourra privilégier l’égalité des taux de faux positifs (ne pas sur-pénaliser un groupe) ; dans un système d’admission, on pourra privilégier la parité démographique (représentation équitable).
Calcul des métriques d’équité#
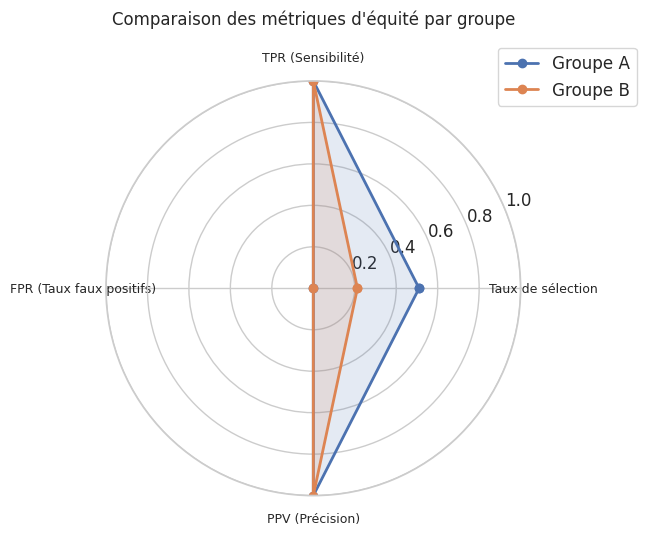
=== Métriques d'équité ===
Taux de sélection TPR (Sensibilité) FPR (Taux faux positifs) \
Groupe
A 0.510 1.0 0.0
B 0.213 1.0 0.0
PPV (Précision)
Groupe
A 1.0
B 1.0
Écart de parité démographique : 0.297
Écart de TPR (égalité d'opportunité) : 0.000
Écart de FPR : 0.000
Écart de parité prédictive (PPV) : 0.000
Techniques d’atténuation des biais#
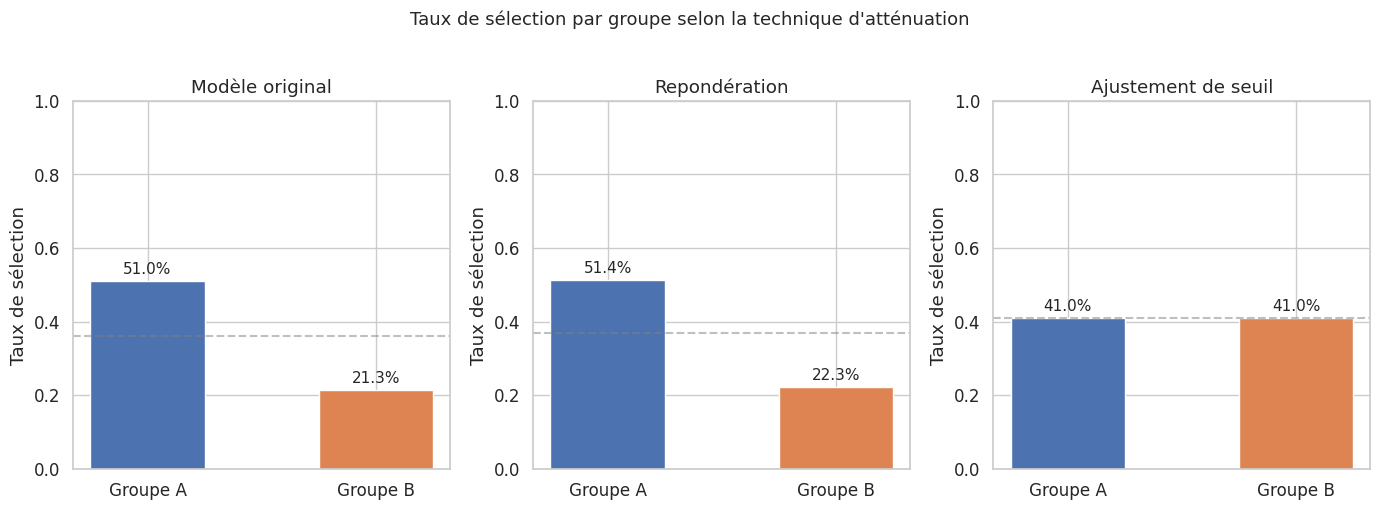
Les techniques d’atténuation des biais se classent en trois catégories selon le moment de leur application dans le pipeline d’apprentissage.
Pré-traitement#
Les méthodes de pré-traitement agissent sur les données avant l’entraînement du modèle.
Définition 332 (Techniques de pré-traitement)
Rééchantillonnage (resampling) : sur-échantillonner le groupe sous-représenté ou sous-échantillonner le groupe sur-représenté pour équilibrer les taux de base.
Repondération (reweighting) : attribuer à chaque exemple un poids inversement proportionnel à la fréquence de sa combinaison (groupe, étiquette), de sorte que chaque sous-groupe contribue équitablement à la fonction de coût.
Transformation des données : projeter les données dans un espace de représentation où l’attribut sensible n’est plus prédictible, tout en préservant l’information utile pour la tâche cible.
=== Après repondération ===
Taux de sélection TPR (Sensibilité) FPR (Taux faux positifs) \
Groupe
A 0.514 1.0 0.007
B 0.223 1.0 0.012
PPV (Précision)
Groupe
A 0.993
B 0.957
Ratio d'impact disparate après repondération : 0.433
In-processing#
Les méthodes in-processing modifient l’algorithme d’apprentissage lui-même pour intégrer des contraintes d’équité directement dans la fonction objectif.
Définition 333 (Apprentissage sous contrainte d’équité)
L’approche par optimisation sous contrainte reformule le problème d’entraînement comme :
où \(\mathcal{L}\) est la perte habituelle et \(\Delta_{\text{fairness}}\) mesure la violation de la contrainte d’équité choisie (par exemple, l’écart de parité démographique). Le paramètre \(\varepsilon\) contrôle le compromis entre performance et équité.
Le débiaisage adversarial (adversarial debiasing) utilise une architecture à deux têtes :
Un prédicteur qui maximise la performance sur la tâche cible ;
Un adversaire qui tente de prédire l’attribut sensible à partir des représentations internes.
L’entraînement conjoint force le prédicteur à produire des représentations dont l’adversaire ne peut extraire l’information sur le groupe, tout en maintenant la performance sur la tâche.
Post-traitement#
Les méthodes de post-traitement ajustent les prédictions après l’entraînement du modèle, sans modifier le modèle lui-même.
Définition 334 (Ajustement de seuil)
L”ajustement de seuil (threshold adjustment) consiste à appliquer un seuil de décision différent pour chaque groupe, de façon à égaliser une métrique d’équité choisie. Pour un classifieur produisant un score \(s(\mathbf{x}) \in [0, 1]\) :
où \(\tau_g\) est le seuil spécifique au groupe \(g\). Les seuils \(\tau_a\) et \(\tau_b\) sont choisis pour satisfaire la contrainte d’équité retenue.
Seuils ajustés : Groupe A = 0.925, Groupe B = 0.002
=== Après ajustement de seuil ===
Taux de sélection TPR (Sensibilité) FPR (Taux faux positifs) \
Groupe
A 0.41 0.804 0.00
B 0.41 1.000 0.25
PPV (Précision)
Groupe
A 1.00
B 0.52
Remarque 275
Toute technique d’atténuation implique un compromis entre performance et équité. La repondération et l’ajustement de seuil réduisent la disparité entre groupes, mais au prix d’une potentielle diminution de la précision globale. Ce compromis est inévitable et doit être documenté et discuté avec les parties prenantes. Le choix de la technique et du niveau d’atténuation est, in fine, un choix de politique, pas uniquement un choix technique.
Vie privée#
Le défi de l’anonymisation#
La protection des données personnelles est un pilier de l’éthique en apprentissage automatique. L”anonymisation — la suppression des identifiants directs (nom, adresse, numéro de sécurité sociale) — est souvent insuffisante.
Définition 335 (\(k\)-anonymat et \(\ell\)-diversité)
Le \(k\)-anonymat exige que chaque combinaison de quasi-identifiants (âge, code postal, genre…) apparaisse dans au moins \(k\) enregistrements du jeu de données :
La \(\ell\)-diversité renforce le \(k\)-anonymat en exigeant que, au sein de chaque groupe de \(k\) enregistrements partageant les mêmes quasi-identifiants, l’attribut sensible prenne au moins \(\ell\) valeurs distinctes « bien représentées ».
Ces approches restent vulnérables aux attaques par composition : en combinant plusieurs jeux de données \(k\)-anonymes, un attaquant peut réidentifier des individus (attaque de Sweeney, 2000).
Confidentialité différentielle#
Définition 336 (Confidentialité différentielle (\(\varepsilon\)-DP))
Un mécanisme randomisé \(\mathcal{M}\) satisfait la \(\varepsilon\)-confidentialité différentielle (\(\varepsilon\)-differential privacy) si, pour tous jeux de données voisins \(D\) et \(D'\) (différant d’un seul enregistrement) et pour tout ensemble de sorties \(S\) :
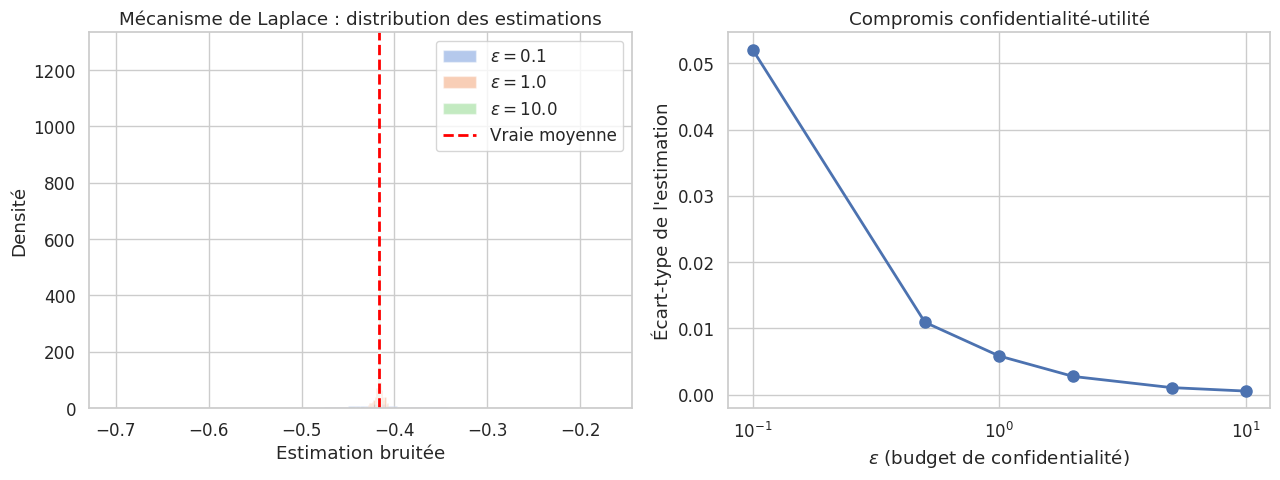
Le paramètre \(\varepsilon > 0\) est le budget de confidentialité (privacy budget) : plus \(\varepsilon\) est petit, plus la garantie de confidentialité est forte. En pratique, \(\varepsilon \in [0.1, 10]\).
Interprétation : la présence ou l’absence d’un individu dans le jeu de données ne modifie que marginalement (facteur \(e^\varepsilon\)) la distribution des sorties du mécanisme. Un observateur ne peut donc pas déterminer si un individu spécifique est dans les données.
Remarque 276
La confidentialité différentielle illustre un compromis fondamental entre vie privée et utilité. Un \(\varepsilon\) petit offre une protection forte mais dégrade la qualité des résultats ; un \(\varepsilon\) grand préserve l’utilité mais affaiblit les garanties. Dans le contexte de l’apprentissage automatique, le DP-SGD (Differentially Private Stochastic Gradient Descent) permet d’entraîner des modèles avec des garanties de confidentialité différentielle, au prix d’une diminution de la précision.
Apprentissage fédéré#
Définition 337 (Apprentissage fédéré)
L”apprentissage fédéré (federated learning) est un paradigme d’entraînement distribué dans lequel les données restent sur les appareils locaux (téléphones, hôpitaux, entreprises) et seuls les gradients ou les mises à jour de paramètres sont échangés avec un serveur central :
Le serveur distribue le modèle global \(\theta_t\) à un sous-ensemble de clients.
Chaque client \(k\) entraîne le modèle sur ses données locales \(\mathcal{D}_k\) pendant quelques itérations et calcule une mise à jour \(\Delta\theta_k\).
Le serveur agrège les mises à jour : \(\theta_{t+1} = \theta_t + \frac{1}{K}\sum_{k=1}^K \Delta\theta_k\).
Le processus est répété jusqu’à convergence.
L’apprentissage fédéré ne constitue pas en soi une garantie de confidentialité — les gradients échangés peuvent encore révéler des informations sur les données locales — mais il peut être combiné avec la confidentialité différentielle et le chiffrement homomorphe pour renforcer les protections.
Cadre réglementaire#
RGPD (Règlement Général sur la Protection des Données)#
Le RGPD, en vigueur depuis mai 2018 dans l’Union européenne, établit plusieurs principes directement pertinents pour l’apprentissage automatique.
Définition 338 (Principes du RGPD applicables au ML)
Minimisation des données (art. 5) : ne collecter que les données strictement nécessaires à la finalité déclarée.
Limitation de la finalité (art. 5) : les données collectées pour une finalité ne peuvent être réutilisées pour un autre objectif incompatible.
Droit à l’explication (art. 22) : toute personne faisant l’objet d’une décision automatisée a le droit d’obtenir une « explication de la logique sous-jacente » et de contester cette décision.
Protection des données dès la conception (privacy by design, art. 25) : les mesures de protection doivent être intégrées dès la conception du système, pas ajoutées a posteriori.
Analyse d’impact (art. 35) : une analyse d’impact relative à la protection des données (AIPD) est obligatoire pour les traitements présentant un risque élevé.
Règlement européen sur l’IA (AI Act)#
Le Règlement européen sur l’intelligence artificielle (AI Act), adopté en 2024, établit une classification des systèmes d’IA selon leur niveau de risque.
Exemple 50 (Classification des risques selon l’AI Act)
Risque inacceptable (interdit) : notation sociale (social scoring) par les autorités publiques, reconnaissance faciale en temps réel dans l’espace public (sauf exceptions), manipulation subliminale.
Risque élevé : systèmes d’IA utilisés dans le recrutement, l’éducation, la justice, la santé, les infrastructures critiques. Ces systèmes doivent satisfaire des exigences strictes :
Évaluation de conformité avant mise sur le marché
Système de gestion des risques
Gouvernance des données
Documentation technique détaillée
Transparence et information des utilisateurs
Supervision humaine
Risque limité : systèmes avec obligations de transparence (par exemple, indiquer qu’un texte est généré par une IA).
Risque minimal : la majorité des systèmes d’IA, sans obligation spécifique.
Autres cadres de référence#
Plusieurs organisations internationales ont publié des cadres éthiques pour l’IA :
IEEE : Ethically Aligned Design — principes pour des systèmes autonomes alignés sur les valeurs humaines.
NIST (États-Unis) : AI Risk Management Framework — cadre de gestion des risques liés à l’IA, structuré autour des fonctions Gouverner, Cartographier, Mesurer et Gérer.
OCDE : principes de l’IA adoptés en 2019, promouvant une IA inclusive, transparente, robuste et responsable.
UNESCO : Recommandation sur l’éthique de l’IA (2021), premier instrument normatif mondial sur le sujet.
Remarque 277
Le cadre réglementaire évolue rapidement. Le praticien en apprentissage automatique doit maintenir une veille active sur ces évolutions, car elles déterminent les obligations concrètes applicables à ses systèmes. La conformité réglementaire n’est pas un obstacle à l’innovation : elle est un facteur de confiance et de pérennité.
IA responsable en pratique#
Fiches de modèle et fiches de données#
Définition 339 (Fiche de modèle (Model Card))
Une fiche de modèle (model card), proposée par Mitchell et al. (2019), est un document standardisé accompagnant un modèle de machine learning. Elle doit contenir au minimum :
Description du modèle : architecture, algorithme, version, date d’entraînement.
Usage prévu : cas d’utilisation primaires, utilisateurs cibles, usages hors périmètre.
Données d’entraînement : source, taille, distribution, processus de collecte et de nettoyage.
Métriques de performance : résultats globaux et ventilés par sous-groupe pertinent.
Considérations éthiques : biais connus, limitations, risques identifiés.
Recommandations : précautions d’emploi, conditions de monitoring.
Définition 340 (Fiche de données (Datasheet))
Une fiche de données (datasheet for datasets), proposée par Gebru et al. (2021), documente un jeu de données selon les axes suivants :
Motivation : pourquoi le jeu de données a été créé, par qui et pour qui.
Composition : nombre d’instances, types de données, attributs sensibles, étiquettes.
Collecte : méthodologie, période, consentement, compensation des participants.
Prétraitement : nettoyage, filtrage, anonymisation.
Utilisations : tâches prévues, utilisations à éviter.
Distribution : licence, restrictions d’accès.
Maintenance : responsable, fréquence de mise à jour, mécanisme de correction.
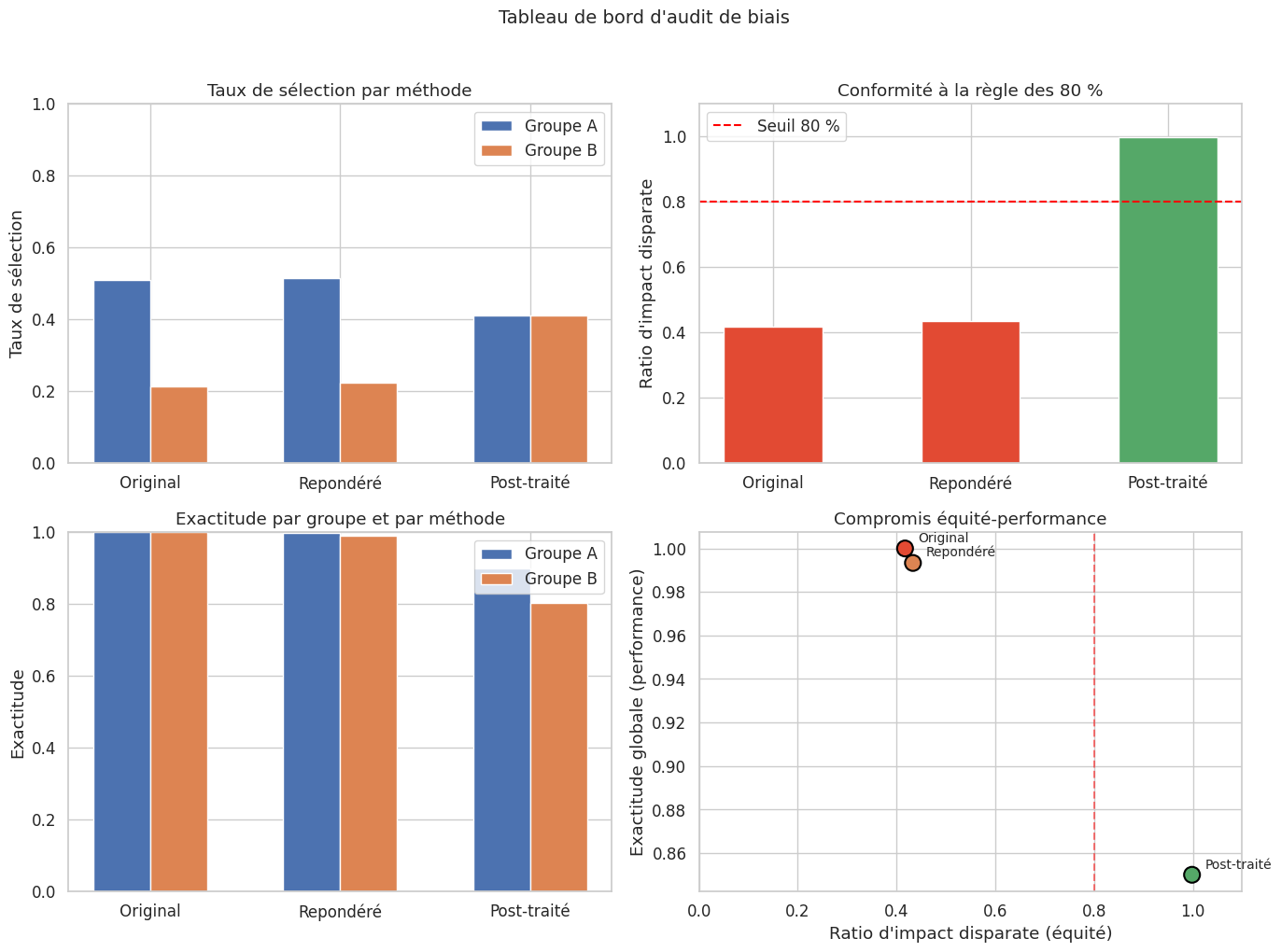
Audit de biais#
L’audit de biais est un processus systématique d’évaluation d’un modèle sous l’angle de l’équité. Il doit être mené avant le déploiement et répété régulièrement.
============================================================
RAPPORT D'AUDIT DE BIAIS
============================================================
--- Performance globale ---
Exactitude : 1.000
--- Performance par groupe ---
Groupe A : exactitude = 1.000, n = 290
Groupe B : exactitude = 1.000, n = 310
--- Métriques d'équité ---
Taux de sélection TPR (Sensibilité) FPR (Taux faux positifs) \
Groupe
A 0.510 1.0 0.0
B 0.213 1.0 0.0
PPV (Précision)
Groupe
A 1.0
B 1.0
--- Impact disparate ---
Ratio : 0.417
Règle des 80 % : NON CONFORME
--- Calibration par groupe ---
Groupe A : score moyen = 0.504, taux positif réel = 0.510
Groupe B : score moyen = 0.217, taux positif réel = 0.213
============================================================
Évaluation d’impact#
Exemple 51 (Liste de vérification pour le déploiement responsable)
Avant de déployer un modèle d’apprentissage automatique, le praticien devrait vérifier les points suivants :
Données
Les sources de données sont documentées et traçables
Les biais potentiels dans les données ont été identifiés et documentés
Le consentement pour l’utilisation des données a été vérifié
Les données sensibles sont protégées (anonymisation, chiffrement)
Modèle
La fiche de modèle (model card) est rédigée et à jour
Les performances sont évaluées par sous-groupe pertinent
Un audit de biais a été réalisé
Le modèle est interprétable ou accompagné d’explications
Déploiement
Un mécanisme de recours est prévu pour les personnes affectées
Un système de monitoring détecte les dérives (drift)
Les boucles de rétroaction sont identifiées et surveillées
Un plan de retrait ou de correction est défini
Conformité
La conformité au RGPD est vérifiée (analyse d’impact si nécessaire)
La classification de risque selon l’AI Act est déterminée
Les obligations de transparence sont satisfaites
Remarque 278
L’audit de biais n’est pas un événement ponctuel mais un processus continu. Les distributions de données évoluent dans le temps (data drift), les populations servies changent, et les boucles de rétroaction peuvent dégrader progressivement l’équité du système. Un monitoring en production, avec des alertes automatiques lorsque les métriques d’équité franchissent des seuils prédéfinis, est indispensable.
Résumé#
Ce chapitre a abordé les enjeux éthiques fondamentaux de l’apprentissage automatique, qui constituent le cadre indispensable de toute pratique responsable.
Les controverses (COMPAS, reconnaissance faciale, recrutement automatisé) montrent que les biais algorithmiques ont des conséquences concrètes sur la vie des personnes. Le praticien porte une responsabilité directe dans les choix qui les produisent.
Les biais dans les données — historiques, de représentation, de mesure, de sélection, d’étiquetage — sont omniprésents et se transmettent mécaniquement aux modèles. Leur identification exige une analyse critique des données avant tout entraînement.
Les biais dans les modèles ne se limitent pas à refléter les données : la discrimination par proxy et les boucles de rétroaction peuvent les amplifier considérablement.
L”équité algorithmique repose sur des définitions formelles (parité démographique, égalité des chances, parité prédictive) dont le théorème d’impossibilité montre qu’elles ne peuvent être satisfaites simultanément. Le choix d’un critère d’équité est un choix de valeurs.
Les techniques d’atténuation (pré-traitement, in-processing, post-traitement) permettent de réduire les disparités, au prix d’un compromis explicite entre performance et équité.
La vie privée est protégée par des outils formels comme la confidentialité différentielle (\(\varepsilon\)-DP) et des paradigmes comme l’apprentissage fédéré, avec un compromis entre protection et utilité.
Le cadre réglementaire (RGPD, AI Act) impose des obligations concrètes que le praticien doit connaître et respecter, notamment le droit à l’explication et la classification des risques.
L”IA responsable en pratique passe par des fiches de modèle, des fiches de données, des audits de biais systématiques et des listes de vérification avant déploiement.
Remarque 279
Ce chapitre clôt notre parcours des données à l’intelligence. Depuis les premières lignes de code pour charger un jeu de données (chapitre 1) jusqu’aux questions d’équité et de responsabilité qui entourent le déploiement d’un modèle, nous avons traversé l’ensemble du spectre de l’apprentissage automatique : les fondations (exploration, prétraitement), l’apprentissage supervisé (régression, classification, SVM, arbres, ensembles), l’apprentissage non supervisé (réduction de dimensionnalité, clustering, détection d’anomalies), les réseaux de neurones (perceptron, CNN, RNN, Transformers), et enfin les enjeux de mise en production (interprétabilité, MLOps, éthique).
S’il y a une leçon à retenir de ce dernier chapitre, c’est que la maîtrise technique — aussi poussée soit-elle — ne suffit pas. Un modèle performant mais biaisé, opaque ou attentatoire à la vie privée n’est pas un bon modèle. L’intelligence artificielle n’est qu’un outil, et comme tout outil puissant, elle requiert discernement, humilité et vigilance de la part de ceux qui la conçoivent. Les données sont le matériau brut ; l’intelligence — la vraie — reste humaine.