
Vision par ordinateur avancée#
L’essentiel est invisible pour les yeux.
— Antoine de Saint-Exupéry, Le Petit Prince
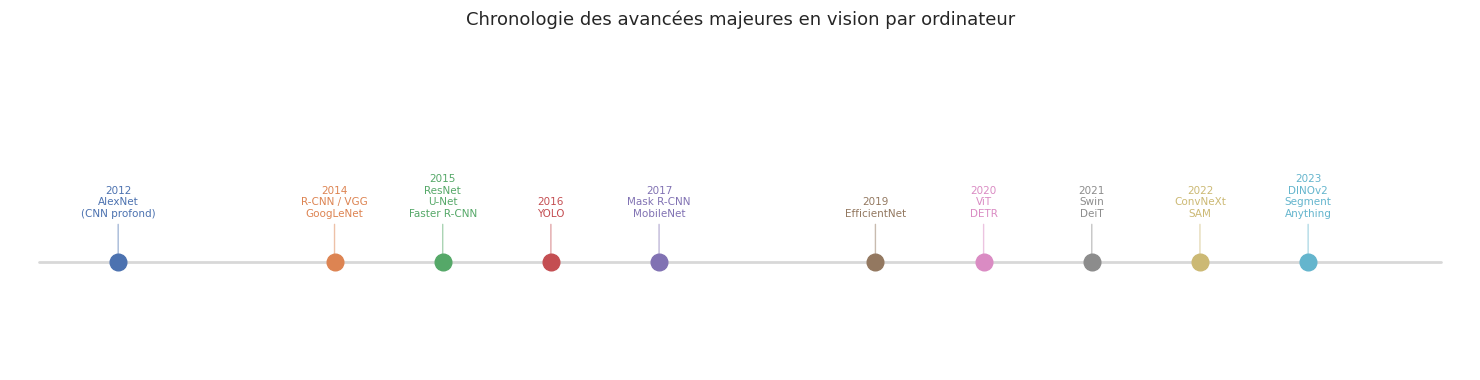
Le chapitre 19 a introduit les réseaux convolutifs (CNN), capables d’extraire automatiquement des hiérarchies de caractéristiques visuelles pour la classification d’images : étant donné une image, le modèle prédit une unique étiquette de classe. Cette tâche, bien que fondamentale, ne représente qu’une fraction des problèmes de vision par ordinateur. Dans de nombreuses applications réelles — conduite autonome, imagerie médicale, robotique — il ne suffit pas de savoir qu’un objet est présent ; il faut savoir où il se trouve, quels pixels lui appartiennent, et comment distinguer chaque instance individuelle.
Ce chapitre explore les tâches de prédiction dense (dense prediction) qui vont au-delà de la classification : la détection d’objets, la segmentation sémantique et la segmentation d’instances. Nous étudierons ensuite les Vision Transformers (ViT), qui adaptent l’architecture Transformer (chapitre 23) au domaine visuel, ainsi que les techniques modernes de transfert d’apprentissage et d”augmentation de données. L’objectif est de fournir une vision panoramique de l’état de l’art en vision par ordinateur.
Périphérique utilisé : cpu
Détection d’objets#
La détection d’objets est la tâche qui consiste à localiser et identifier chaque objet d’intérêt dans une image. Contrairement à la classification qui produit une unique étiquette, la détection produit un ensemble de boîtes englobantes (bounding boxes), chacune associée à une classe et à un score de confiance.
Formulation du problème#
Définition 287 (Détection d’objets)
Soit une image \(\mathbf{I} \in \mathbb{R}^{H \times W \times 3}\). La détection d’objets consiste à prédire un ensemble de \(N\) détections :
où :
\(b_i = (x_i, y_i, w_i, h_i) \in \mathbb{R}^4\) est la boîte englobante (coordonnées du centre, largeur, hauteur),
\(c_i \in \{1, \ldots, K\}\) est la classe de l’objet parmi \(K\) catégories,
\(s_i \in [0, 1]\) est le score de confiance de la prédiction.
Le défi central de la détection réside dans le fait que le nombre d’objets \(N\) varie d’une image à l’autre, et que les objets peuvent apparaître à n’importe quelle position et à n’importe quelle échelle. Cela distingue fondamentalement la détection de la classification, où la sortie est de dimension fixe.
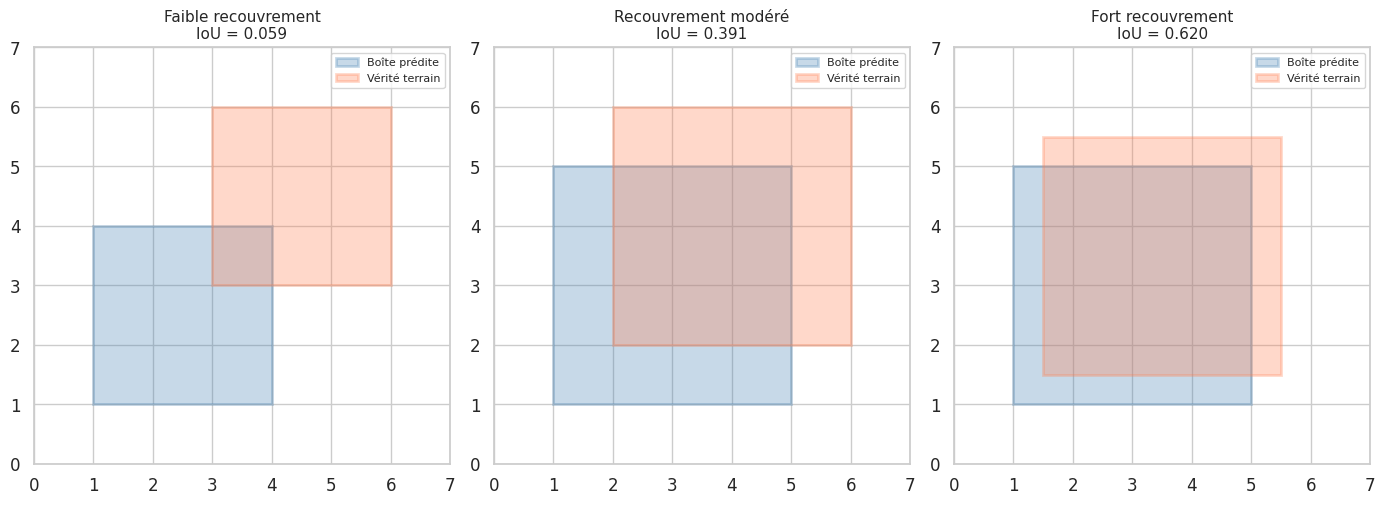
Définition 288 (Intersection over Union (IoU))
L”Intersection over Union (IoU), également appelée indice de Jaccard, mesure le recouvrement entre une boîte prédite \(B_p\) et une boîte de vérité terrain \(B_{gt}\) :
où \(|\cdot|\) désigne l’aire. L’IoU varie entre 0 (aucun recouvrement) et 1 (recouvrement parfait). Un seuil courant pour considérer une détection comme correcte est \(\text{IoU} \geq 0.5\).
Détecteurs à deux étapes : la famille R-CNN#
Les premiers détecteurs modernes basés sur l’apprentissage profond utilisent une approche en deux étapes : d’abord proposer des régions susceptibles de contenir un objet, puis classifier et affiner chaque proposition.
Définition 289 (Détecteur à deux étapes)
Un détecteur à deux étapes (two-stage detector) décompose la détection en :
Proposition de régions (Region Proposal) : génération d’un ensemble de régions candidates susceptibles de contenir un objet.
Classification et régression : pour chaque région candidate, prédiction de la classe et affinement des coordonnées de la boîte englobante.
R-CNN (Girshick et al., 2014) est le détecteur fondateur de cette famille. L’algorithme utilise la recherche sélective (Selective Search) pour générer environ 2000 propositions de régions, puis extrait les caractéristiques de chaque région à l’aide d’un CNN pré-entraîné (par exemple AlexNet ou VGG). Ces caractéristiques alimentent un SVM linéaire pour la classification et un régresseur pour affiner les boîtes. Le problème majeur est l’inefficacité : le CNN est appliqué indépendamment à chaque région, ce qui rend l’inférence extrêmement lente.
Fast R-CNN (Girshick, 2015) résout cette redondance en appliquant le CNN une seule fois sur l’image entière pour produire une carte de caractéristiques (feature map). Les propositions de régions sont ensuite projetées sur cette carte, et un mécanisme de RoI Pooling (Region of Interest Pooling) extrait un vecteur de taille fixe pour chaque région, permettant la classification et la régression en un seul passage.
Définition 290 (RoI Pooling)
Le RoI Pooling projette une région d’intérêt de taille variable sur la carte de caractéristiques, puis la découpe en une grille de taille fixe \(H_p \times W_p\). Un max-pooling est appliqué à chaque cellule de la grille, produisant un vecteur de dimension \(C \times H_p \times W_p\) indépendant de la taille originale de la région.
Faster R-CNN (Ren et al., 2015) remplace la recherche sélective par un réseau de proposition de régions (Region Proposal Network, RPN) appris de bout en bout. Le RPN opère directement sur la carte de caractéristiques et produit des propositions à l’aide de boîtes d’ancrage (anchor boxes).
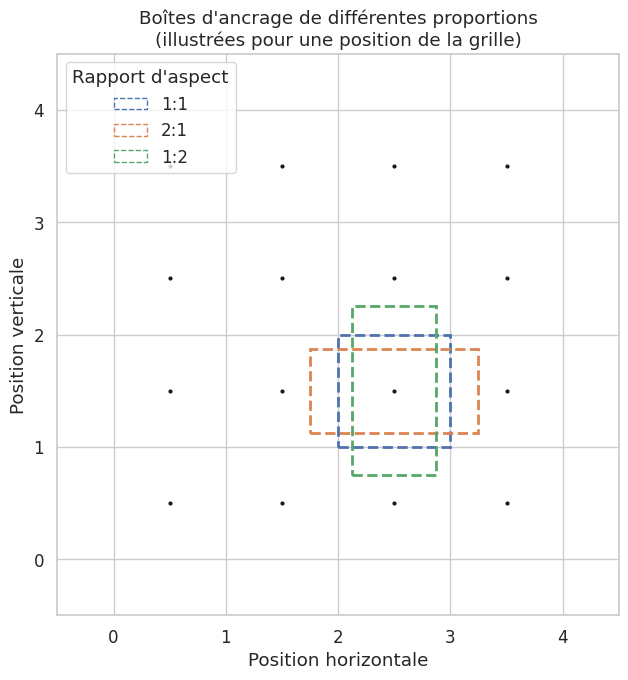
Définition 291 (Boîtes d’ancrage)
Les boîtes d’ancrage (anchor boxes) sont un ensemble de boîtes de référence prédéfinies, de différentes tailles et proportions (aspect ratios), centrées sur chaque position de la carte de caractéristiques. Pour chaque ancre, le réseau prédit :
un score d”objectness : probabilité que l’ancre contienne un objet (vs. arrière-plan),
un décalage \((\delta_x, \delta_y, \delta_w, \delta_h)\) pour affiner les coordonnées.
Si la carte de caractéristiques est de taille \(H' \times W'\) et que l’on utilise \(k\) ancres par position, le RPN génère \(H' \times W' \times k\) propositions candidates.
Remarque 245
L’évolution de R-CNN à Faster R-CNN illustre un principe récurrent en apprentissage profond : remplacer les modules heuristiques par des modules appris. La recherche sélective (heuristique) est remplacée par le RPN (appris), ce qui permet un entraînement de bout en bout et améliore à la fois la vitesse et la précision.
Détecteurs à une étape : YOLO#
Les détecteurs à deux étapes offrent une grande précision mais restent relativement lents. Les détecteurs à une étape (one-stage detectors) éliminent l’étape de proposition de régions et prédisent directement les boîtes englobantes et les classes en un seul passage du réseau.
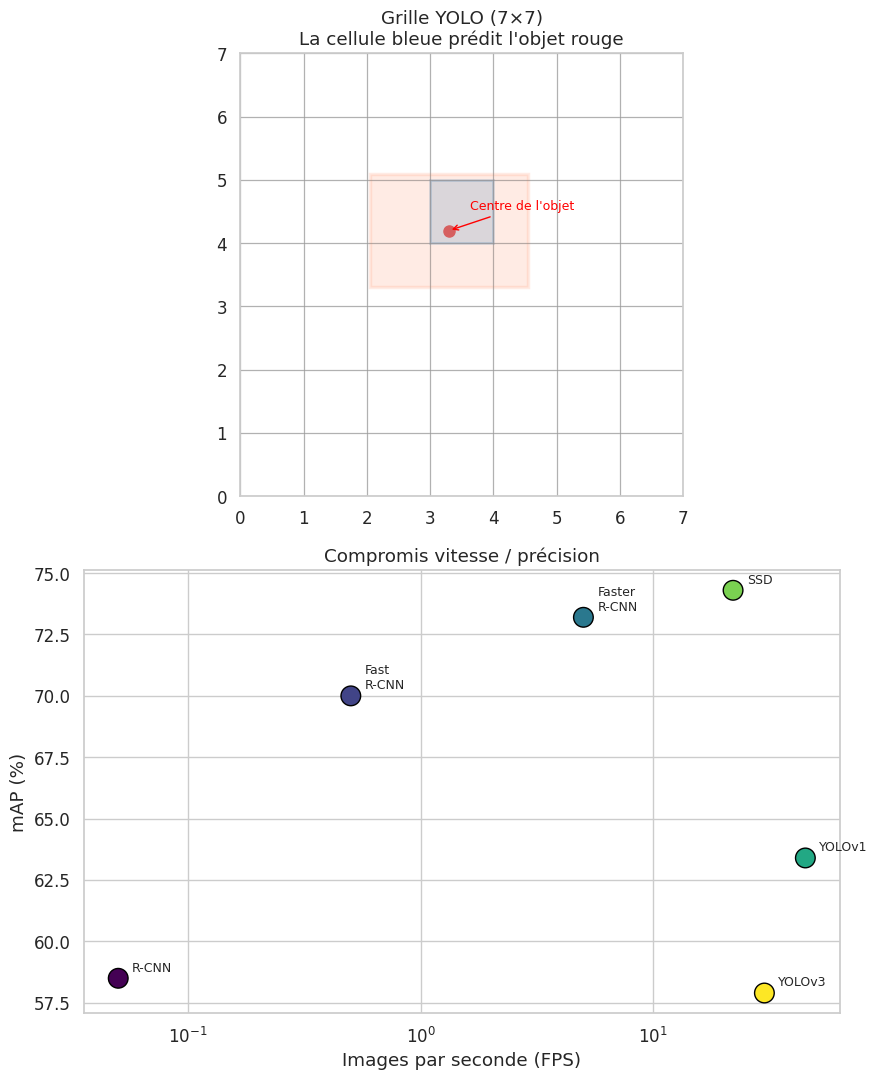
YOLO (You Only Look Once, Redmon et al., 2016) est le détecteur à une étape le plus emblématique. Son principe est élégant : l’image est divisée en une grille \(S \times S\), et chaque cellule de la grille est responsable de la détection des objets dont le centre tombe dans cette cellule.
Définition 292 (Architecture YOLO)
YOLO divise l’image d’entrée en une grille de \(S \times S\) cellules. Pour chaque cellule, le réseau prédit :
\(B\) boîtes englobantes, chacune caractérisée par \((x, y, w, h, \text{conf})\) où \((x, y)\) est le centre relatif à la cellule, \((w, h)\) les dimensions relatives à l’image, et \(\text{conf}\) le score de confiance,
\(K\) probabilités de classes conditionnelles \(P(c_k \mid \text{objet})\).
La sortie totale est un tenseur de dimension \(S \times S \times (B \times 5 + K)\). La prédiction finale combine le score de confiance et la probabilité de classe :
Suppression des non-maximum (NMS)#
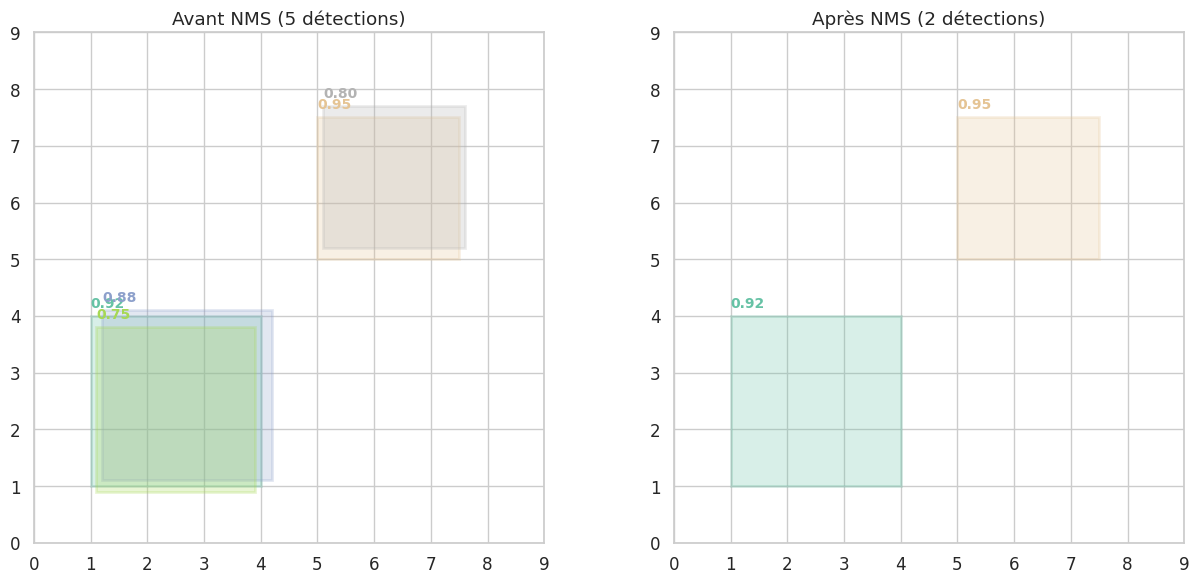
Un détecteur d’objets produit souvent de multiples boîtes chevauchantes pour un même objet. La suppression des non-maximum (Non-Maximum Suppression, NMS) est un post-traitement essentiel qui élimine les détections redondantes.
Définition 293 (Non-Maximum Suppression)
L’algorithme NMS procède comme suit :
Trier toutes les détections par score de confiance décroissant.
Sélectionner la détection de score maximal et la placer dans l’ensemble final.
Supprimer toutes les détections restantes dont l’IoU avec la détection sélectionnée dépasse un seuil \(\tau\) (typiquement \(\tau = 0.5\)).
Répéter les étapes 2–3 jusqu’à épuisement des détections.
Métriques : mAP#
Définition 294 (Mean Average Precision (mAP))
La mean Average Precision (mAP) est la métrique standard pour évaluer les détecteurs d’objets.
Pour chaque classe \(k\), on trie les détections par score décroissant et on calcule la courbe précision-rappel en variant le seuil de confiance. Une détection est un vrai positif si son \(\text{IoU}\) avec une boîte de vérité terrain non encore associée dépasse le seuil (typiquement 0.5), et un faux positif sinon.
L”Average Precision (AP) pour la classe \(k\) est l’aire sous la courbe précision-rappel :
Le mAP est la moyenne sur toutes les classes :
Les variantes courantes sont \(\text{mAP}_{50}\) (IoU \(\geq 0.5\)) et \(\text{mAP}_{50:95}\) (moyenne pour les seuils IoU de 0.5 à 0.95 par pas de 0.05).
Détection avec un modèle pré-entraîné#
Torchvision fournit des modèles de détection pré-entraînés sur COCO. Voici comment utiliser Faster R-CNN pour détecter des objets dans une image synthétique.
Nombre de catégories COCO : 91
Premières catégories : ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light']
Nombre de détections : 0
Clés de la sortie : ['boxes', 'labels', 'scores']
Forme des boîtes : torch.Size([0, 4])
Forme des scores : torch.Size([0])
Remarque 246
En pratique, les modèles de détection modernes comme YOLOv8 ou DETR (DEtection TRansformer) atteignent des performances remarquables sur des benchmarks comme COCO. DETR est particulièrement intéressant car il formule la détection comme un problème d’ensemble (set prediction) résolu par un Transformer, éliminant le besoin de NMS et d’ancres prédéfinies.
Segmentation#
La segmentation va plus loin que la détection en attribuant une étiquette à chaque pixel de l’image. Il existe trois variantes principales de cette tâche.
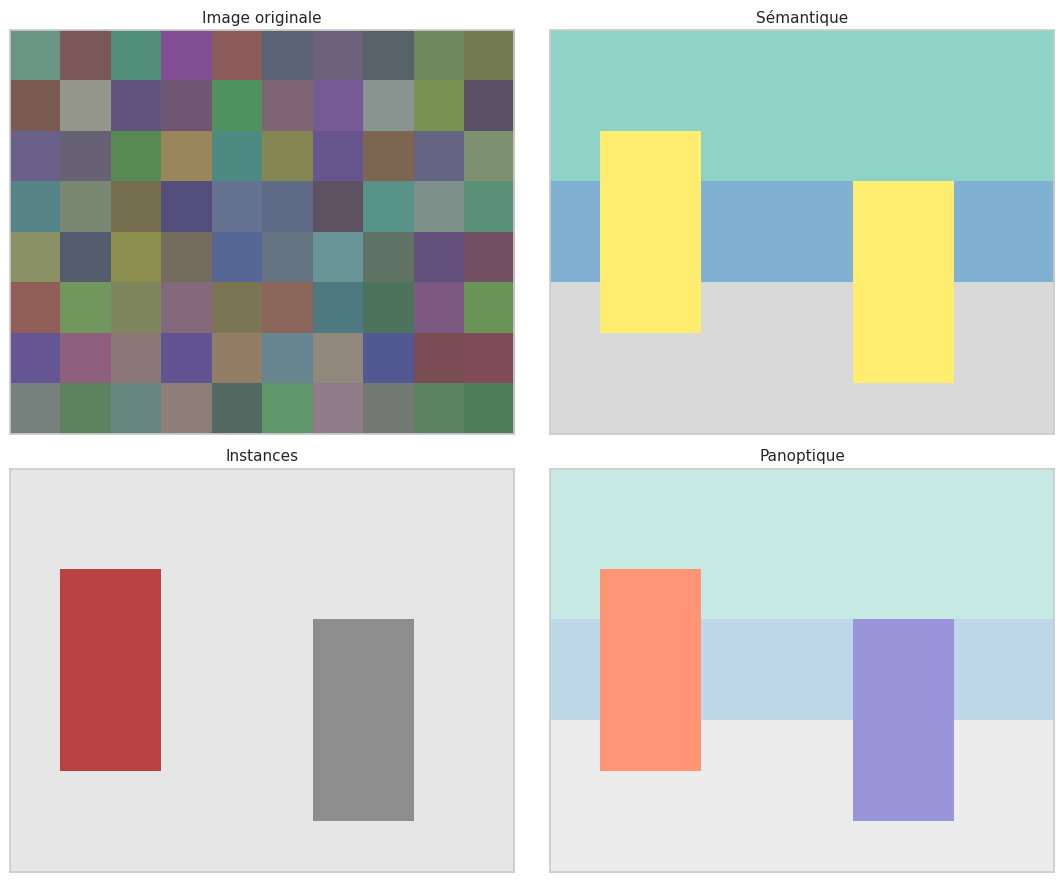
Segmentation sémantique, d’instances et panoptique#
Définition 295 (Types de segmentation)
Segmentation sémantique : attribuer une étiquette de classe \(c \in \{1, \ldots, K\}\) à chaque pixel \((i, j)\) de l’image. Deux voitures distinctes reçoivent la même étiquette « voiture ».
Segmentation d’instances : identifier chaque instance individuelle d’objet avec un masque distinct. Deux voitures reçoivent des masques séparés, mais les pixels d’arrière-plan ne sont pas classifiés.
Segmentation panoptique : combine les deux approches. Chaque pixel reçoit une étiquette de classe et un identifiant d’instance. Les classes « chose » (stuff : ciel, route, herbe) sont traitées en segmentation sémantique, et les classes « objet » (thing : voiture, personne) en segmentation d’instances.
Architecture U-Net#
L’architecture U-Net (Ronneberger et al., 2015), initialement conçue pour la segmentation d’images médicales, est devenue l’architecture de référence pour la segmentation sémantique. Son principe repose sur une structure encodeur-décodeur enrichie de connexions de saut (skip connections).
Définition 296 (Architecture encodeur-décodeur avec connexions de saut)
L’architecture U-Net se compose de :
Encodeur (chemin contractant) : succession de blocs convolutifs suivis de max-pooling, qui réduisent la résolution spatiale tout en augmentant le nombre de canaux. L’encodeur capture le contexte sémantique.
Décodeur (chemin expansif) : succession de sur-échantillonnages (upsampling) par convolution transposée, suivis de blocs convolutifs, qui restaurent progressivement la résolution spatiale.
Connexions de saut : les cartes de caractéristiques de l’encodeur sont concaténées avec celles du décodeur au même niveau de résolution, permettant au décodeur de combiner l’information sémantique de haut niveau avec la localisation précise de bas niveau.
Si l’encodeur produit des caractéristiques \(\mathbf{e}_l\) au niveau \(l\) et le décodeur produit \(\mathbf{d}_l\), la connexion de saut donne :
où \([\ ;\ ]\) désigne la concaténation le long de la dimension des canaux.
Entrée : torch.Size([1, 3, 128, 128])
Sortie : torch.Size([1, 5, 128, 128])
Nombre de paramètres : 31,043,781
Remarque 247
La forme de la sortie U-Net est \((N, K, H, W)\) où \(K\) est le nombre de classes. Chaque pixel reçoit un vecteur de logits de dimension \(K\), auquel on applique un softmax pour obtenir les probabilités de classe. La sortie a exactement la même résolution que l’entrée, ce qui est essentiel pour la prédiction dense.
Mask R-CNN#
Mask R-CNN (He et al., 2017) étend Faster R-CNN à la segmentation d’instances en ajoutant une branche de segmentation parallèle aux branches de classification et de régression. Pour chaque région d’intérêt, Mask R-CNN prédit un masque binaire de taille \(m \times m\) pour chaque classe, en utilisant un petit réseau convolutif appliqué aux caractéristiques de la région.
Définition 297 (Mask R-CNN)
Mask R-CNN ajoute à Faster R-CNN une troisième sortie par RoI :
Classification : étiquette de classe \(c \in \{1, \ldots, K\}\)
Régression : affinement de la boîte \((\delta_x, \delta_y, \delta_w, \delta_h)\)
Masque : un masque binaire \(\mathbf{M} \in \{0, 1\}^{m \times m}\) prédit indépendamment pour chaque classe
La perte totale est :
où \(\mathcal{L}_{\text{mask}}\) est une entropie croisée binaire pixel par pixel, calculée uniquement sur le masque de la classe prédite (découplage classe/masque).
Un point technique important est le remplacement du RoI Pooling par le RoI Align, qui utilise une interpolation bilinéaire au lieu de quantifications discrètes, améliorant la précision spatiale des masques.
Fonctions de perte pour la segmentation#
Définition 298 (Fonctions de perte pour la segmentation)
Entropie croisée pixel par pixel. Pour une image de \(H \times W\) pixels avec \(K\) classes, la perte est :
où \(y_{ijk}\) est l’indicatrice de la classe \(k\) au pixel \((i, j)\) et \(\hat{y}_{ijk}\) la probabilité prédite.
Dice Loss. Le coefficient de Dice mesure le recouvrement entre la prédiction et la vérité terrain, et est particulièrement utile pour les classes déséquilibrées :
où \(p_i\) est la probabilité prédite et \(g_i\) l’étiquette binaire au pixel \(i\), et \(\epsilon\) est un terme de stabilisation numérique.
=== Bonne prédiction ===
BCE Loss : 0.1833
Dice Loss : 0.0840
=== Mauvaise prédiction ===
BCE Loss : 2.1660
Dice Loss : 0.7266
Vision Transformers (ViT)#
Le chapitre 23 a présenté l’architecture Transformer et son mécanisme d’attention multi-tête pour le traitement des séquences. Une question naturelle émerge : peut-on appliquer les Transformers directement aux images, sans convolutions ? La réponse est oui, et c’est l’idée fondatrice du Vision Transformer (ViT) (Dosovitskiy et al., 2020).
Découpage en patches#
La première difficulté est de transformer une image 2D en une séquence exploitable par un Transformer. Le ViT propose une solution élégante : découper l’image en patches de taille fixe et traiter chaque patch comme un « token » visuel, analogue à un mot dans une phrase.
Définition 299 (Patch embedding)
Soit une image \(\mathbf{I} \in \mathbb{R}^{H \times W \times C}\) et une taille de patch \(P \times P\). L’image est découpée en \(N = \frac{H \times W}{P^2}\) patches non chevauchants :
Chaque patch est « aplati » puis projeté linéairement dans un espace de dimension \(D\) :
où \(\mathbf{E} \in \mathbb{R}^{(P^2 C) \times D}\) est la matrice de projection et \(\mathbf{e}_{\text{pos}}^{(i)} \in \mathbb{R}^D\) est l”embedding positionnel (appris) du patch \(i\).
Un token de classification \([\text{CLS}]\) est ajouté en début de séquence, exactement comme dans BERT. La séquence d’entrée du Transformer est donc :

Architecture complète du ViT#
Définition 300 (Vision Transformer (ViT))
L’architecture ViT se compose de :
Patch embedding : projection linéaire des patches + embedding positionnel + token \([\text{CLS}]\).
Encodeur Transformer : \(L\) couches identiques, chacune comprenant :
Multi-Head Self-Attention (MHSA) avec connexion résiduelle et normalisation de couche,
MLP (deux couches linéaires avec GELU) avec connexion résiduelle et normalisation de couche.
Tête de classification : le vecteur correspondant au token \([\text{CLS}]\) de la dernière couche est projeté linéairement vers les \(K\) classes :
Entrée : torch.Size([2, 3, 224, 224])
Sortie : torch.Size([2, 10])
Patches : 196
Nombre de paramètres : 11,022,730
Comparaison CNN vs ViT#
Remarque 248
CNN vs Vision Transformer :
Propriété |
CNN |
ViT |
|---|---|---|
Biais inductif |
Fort (localité, invariance par translation) |
Faible (attention globale) |
Données nécessaires |
Efficace avec peu de données |
Nécessite beaucoup de données (ou pré-entraînement) |
Complexité spatiale |
\(O(K^2 \cdot C)\) par couche (\(K\) = taille du noyau) |
\(O(N^2 \cdot D)\) par couche (\(N\) = nombre de patches) |
Champ réceptif |
Croît progressivement avec la profondeur |
Global dès la première couche |
Scalabilité |
Plafonne au-delà d’une certaine taille |
S’améliore avec la taille du modèle et des données |
Les CNN excellent lorsque les données sont limitées grâce à leurs biais inductifs forts. Les ViT dominent lorsqu’ils sont pré-entraînés sur de très grands jeux de données (ImageNet-21k, JFT-300M). En pratique, les approches hybrides combinent le meilleur des deux mondes.
Approches hybrides CNN + Transformer#
Plusieurs architectures récentes combinent les forces des CNN et des Transformers :
Swin Transformer (Liu et al., 2021) : utilise une attention à fenêtre glissante (shifted window) qui limite l’attention à des régions locales tout en permettant l’échange d’information entre fenêtres. La complexité passe de \(O(N^2)\) à \(O(N)\) par rapport au nombre de tokens.
ConvNeXt (Liu et al., 2022) : modernise l’architecture ResNet en adoptant les recettes d’entraînement des ViT (augmentation agressive, optimiseur AdamW, plus d’époques), démontrant que les CNN purs peuvent rivaliser avec les Transformers.
CoAtNet (Dai et al., 2021) : empile des couches convolutives dans les premières étapes (pour capturer les motifs locaux) et des couches d’attention dans les étapes ultérieures (pour le raisonnement global).
Remarque 249
Les performances du ViT sur ImageNet-1k sans pré-entraînement supplémentaire sont inférieures à celles des CNN. C’est lorsqu’il est pré-entraîné sur des jeux massifs (ImageNet-21k, JFT-300M) que le ViT surpasse les CNN. Le modèle DINOv2 (Oquab et al., 2023) montre que l’apprentissage auto-supervisé permet au ViT d’apprendre des représentations visuelles remarquables sans aucune étiquette.
Transfer learning en vision#
Le transfert d’apprentissage (transfer learning) est une technique omniprésente en vision par ordinateur. Plutôt que d’entraîner un modèle de zéro, on utilise un modèle pré-entraîné sur un grand jeu de données (typiquement ImageNet) comme point de départ pour une tâche cible.
Extraction de caractéristiques vs fine-tuning#
Définition 301 (Stratégies de transfert d’apprentissage)
Extraction de caractéristiques (feature extraction) :
On gèle tous les paramètres du modèle pré-entraîné (le backbone).
On remplace la dernière couche (tête de classification) par une nouvelle couche adaptée à la tâche cible.
Seuls les paramètres de la nouvelle tête sont entraînés.
Avantage : rapide, peu de données nécessaires. Inconvénient : adaptation limitée.
Fine-tuning (affinement) :
On remplace également la tête de classification.
On dégèle tout ou partie des couches du backbone et on entraîne l’ensemble avec un taux d’apprentissage faible.
Avantage : meilleure adaptation. Inconvénient : nécessite plus de données et de calcul.
Fine-tuning progressif (gradual unfreezing) :
On commence par entraîner uniquement la tête, puis on dégèle progressivement les couches du backbone, des plus profondes aux plus superficielles.
Cela permet une adaptation stable en préservant les caractéristiques de bas niveau (bords, textures).
Paramètres totaux : 23,528,522
Paramètres entraînables : 20,490
Proportion gelée : 99.9%
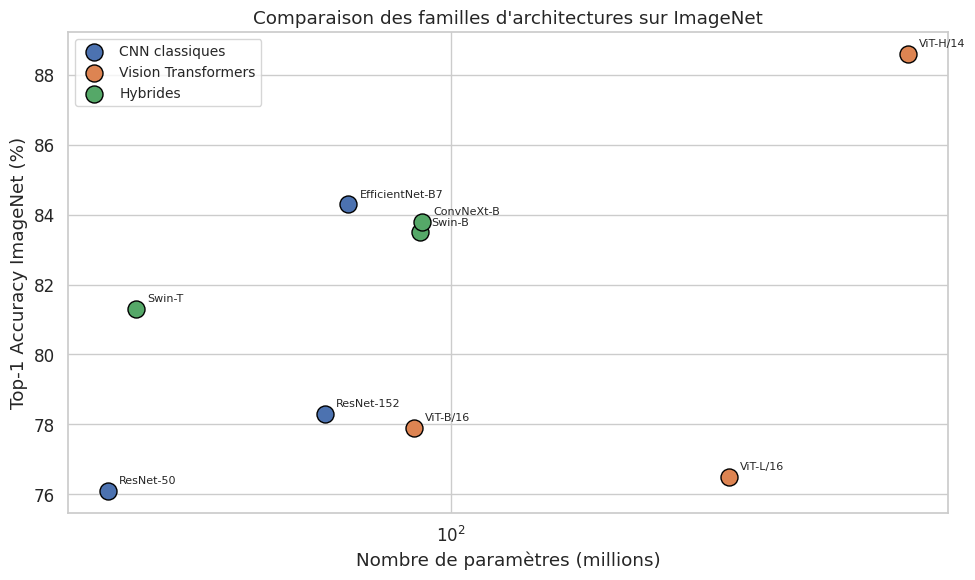
Backbones pré-entraînés courants#
Remarque 250
Les backbones pré-entraînés les plus utilisés en vision :
Backbone |
Année |
Paramètres |
Top-1 ImageNet |
Architecture |
|---|---|---|---|---|
ResNet-50 |
2015 |
25M |
80.9% |
CNN résiduel |
EfficientNet-B0 |
2019 |
5.3M |
77.7% |
CNN optimisé (NAS) |
EfficientNet-B7 |
2019 |
66M |
84.3% |
CNN optimisé (NAS) |
ViT-B/16 |
2020 |
86M |
81.8% |
Transformer |
Swin-B |
2021 |
88M |
83.5% |
Transformer hiérarchique |
ConvNeXt-B |
2022 |
89M |
83.8% |
CNN modernisé |
Le choix du backbone dépend du compromis entre la taille du jeu de données cible, les contraintes de calcul et la précision requise.
Conseils pratiques pour le transfert#
Exemple 36 (Bonnes pratiques pour le transfer learning)
Taux d’apprentissage : utiliser un taux \(10\times\) à \(100\times\) plus faible que pour un entraînement de zéro (typiquement \(10^{-4}\) à \(10^{-5}\) pour le fine-tuning).
Taux d’apprentissage discriminatif : utiliser un taux plus faible pour les premières couches et plus élevé pour les dernières :
\[\eta_l = \eta_{\text{base}} \cdot \gamma^{L - l}\]où \(l\) est l’indice de la couche, \(L\) le nombre total de couches, et \(\gamma < 1\).
Normalisation des entrées : appliquer exactement la même normalisation que celle utilisée lors du pré-entraînement (moyenne et écart-type d’ImageNet).
Taille du jeu de données :
\(< 1\,000\) images : extraction de caractéristiques.
\(1\,000\) – \(10\,000\) images : fine-tuning des dernières couches.
\(> 10\,000\) images : fine-tuning complet.
Augmentation de données : toujours appliquer de l’augmentation, particulièrement lorsque les données sont limitées.
Fine-tuning progressif (EfficientNet-B0) :
Phase 1 (tête seule) : 6,405 paramètres (0.2%)
Phase 2 (derniers blocs) : 1,135,797 paramètres (28.3%)
Phase 3 (tout le modèle) : 4,013,953 paramètres (100.0%)
Augmentation de données avancée#
L’augmentation de données est une technique de régularisation qui crée artificiellement de nouvelles données d’entraînement en appliquant des transformations aux images existantes. Au-delà des transformations géométriques classiques (rotation, retournement, recadrage), les techniques modernes d’augmentation mélangent les exemples entre eux ou modifient les images de manière plus agressive.
CutMix et MixUp#
Définition 302 (CutMix et MixUp)
MixUp (Zhang et al., 2018) : mélange linéaire de deux exemples et de leurs étiquettes :
où \(\lambda \sim \text{Beta}(\alpha, \alpha)\), typiquement \(\alpha = 0.2\).
CutMix (Yun et al., 2019) : coupe une région rectangulaire d’une image et la remplace par la région correspondante d’une autre image. L’étiquette est pondérée par la proportion de surface :
où \(\mathbf{M} \in \{0, 1\}^{H \times W}\) est un masque binaire rectangulaire et \(\lambda\) est la proportion de l’image originale conservée.

RandAugment#
Définition 303 (RandAugment)
RandAugment (Cubuk et al., 2020) simplifie la recherche de politiques d’augmentation en n’utilisant que deux hyperparamètres :
\(N\) : le nombre de transformations appliquées séquentiellement,
\(M\) : la magnitude (intensité) commune de toutes les transformations.
À chaque image, \(N\) transformations sont tirées uniformément parmi un ensemble prédéfini (rotation, translation, cisaillement, contraste, luminosité, saturation, etc.), chacune avec une magnitude \(M\) sur une échelle de 0 à 30.
Cela réduit l’espace de recherche de \(O(K^N \cdot M^N)\) (pour \(K\) transformations) à seulement deux paramètres scalaires \((N, M)\), rendant l’optimisation par validation croisée triviale.

Remarque 251
Les techniques d’augmentation avancées comme CutMix, MixUp et RandAugment sont devenues des composantes standard des recettes d’entraînement modernes. Par exemple, la recette d’entraînement de DeiT (Touvron et al., 2021) utilise simultanément RandAugment, MixUp, CutMix et Random Erasing. Ces techniques sont complémentaires et leur combinaison améliore systématiquement les performances.
Applications#
La vision par ordinateur avancée trouve des applications dans de nombreux domaines à fort impact sociétal et industriel.
Imagerie médicale#
Exemple 37 (Vision par ordinateur en imagerie médicale)
L’imagerie médicale est l’un des domaines où la vision par ordinateur a le plus grand potentiel :
Détection de tumeurs : les CNN et U-Net segmentent les tumeurs dans les scanners (IRM, CT, mammographies) avec une précision parfois comparable à celle des radiologues experts.
Rétinopathie diabétique : les modèles de classification analysent les images du fond de l’oeil pour détecter les signes précoces de rétinopathie, permettant un dépistage à grande échelle.
Pathologie numérique : les modèles analysent les lames histologiques numérisées pour détecter les cellules cancéreuses, avec des résolutions gigapixels traitées par des architectures à attention multi-échelle.
Reconstruction d’images : les réseaux profonds améliorent la résolution des images IRM acquises rapidement, réduisant le temps d’examen pour les patients.
Le transfert d’apprentissage est particulièrement crucial dans ce domaine, car les données annotées par des experts sont rares et coûteuses.
Conduite autonome#
Exemple 38 (Vision par ordinateur pour la conduite autonome)
Un véhicule autonome doit percevoir et comprendre son environnement en temps réel :
Détection d’objets : identifier les véhicules, piétons, cyclistes, panneaux de signalisation et feux tricolores avec une latence minimale. Les détecteurs à une étape (YOLO) sont préférés pour leur vitesse.
Segmentation sémantique : segmenter la scène en route, trottoir, bâtiments, végétation pour comprendre l’espace navigable.
Estimation de profondeur : les réseaux monoculaires estiment la profondeur à partir d’une seule image, complétant les données LiDAR.
Fusion multi-capteurs : combiner les données des caméras, du LiDAR et du radar à l’aide de réseaux à fusion tardive ou intermédiaire.
La segmentation panoptique est particulièrement pertinente car elle fournit une compréhension complète de la scène : chaque pixel est classifié et chaque instance d’objet est individualisée.
Imagerie satellitaire et télédétection#
Exemple 39 (Imagerie satellitaire)
L’analyse automatique d’images satellitaires ouvre des perspectives considérables :
Cartographie : segmentation sémantique des bâtiments, routes, cours d’eau et végétation pour la mise à jour automatique des cartes.
Surveillance environnementale : détection de la déforestation, suivi de la fonte des glaces, estimation des surfaces agricoles.
Gestion des catastrophes : détection rapide des zones inondées ou des bâtiments endommagés après un séisme ou un ouragan.
Agriculture de précision : analyse de l’état des cultures par segmentation des parcelles et détection des zones de stress hydrique.
Les défis spécifiques incluent la très haute résolution des images (souvent plusieurs gigapixels), les variations d’illumination et d’angle de prise de vue, et le déséquilibre des classes.
Contrôle qualité industriel#
Exemple 40 (Contrôle qualité en vision industrielle)
Dans l’industrie manufacturière, la vision par ordinateur permet l’inspection automatique :
Détection de défauts : identifier les rayures, fissures, taches ou déformations sur les pièces manufacturées à l’aide de la détection d’anomalies ou de la segmentation.
Métrologie : mesurer les dimensions des pièces avec une précision sub-pixel.
Tri automatique : classifier les produits par qualité sur les lignes de production en temps réel.
Inspection de soudures : vérifier la qualité des soudures par analyse d’images radiographiques.
Les approches par détection d’anomalies sont particulièrement adaptées car les données de défauts sont rares : on entraîne le modèle uniquement sur des exemples conformes et on détecte les anomalies comme des déviations de la distribution normale.
Résumé#
Ce chapitre a étendu notre compréhension de la vision par ordinateur au-delà de la classification, en explorant les tâches de prédiction dense et les architectures modernes.
La détection d’objets localise et identifie les objets dans une image. Les détecteurs à deux étapes (Faster R-CNN) offrent une grande précision grâce aux propositions de régions et aux ancres, tandis que les détecteurs à une étape (YOLO) privilégient la vitesse par une prédiction directe sur une grille. L”IoU et le mAP sont les métriques standard, et la NMS élimine les détections redondantes.
La segmentation attribue une étiquette à chaque pixel. L’architecture U-Net (encodeur-décodeur avec connexions de saut) est la référence pour la segmentation sémantique. Mask R-CNN étend la détection à la segmentation d’instances en ajoutant une branche de masque. La Dice loss complète l’entropie croisée pour les classes déséquilibrées.
Les Vision Transformers (ViT) appliquent l’architecture Transformer aux images via un découpage en patches. Ils surpassent les CNN lorsqu’ils sont pré-entraînés sur de grands jeux de données, grâce à leur attention globale. Les architectures hybrides (Swin Transformer, ConvNeXt) combinent les avantages des deux approches.
Le transfert d’apprentissage — par extraction de caractéristiques ou fine-tuning — est essentiel en pratique. Le choix du backbone pré-entraîné et de la stratégie de dégel dépend de la taille du jeu de données cible.
Les techniques d”augmentation avancée (MixUp, CutMix, RandAugment) sont devenues des composantes standard des pipelines d’entraînement modernes, améliorant la robustesse et la généralisation.
Les applications de la vision avancée — imagerie médicale, conduite autonome, télédétection, contrôle qualité — illustrent l’impact considérable de ces techniques dans le monde réel.
Remarque 252
La vision par ordinateur évolue rapidement. Les modèles de fondation comme SAM (Segment Anything Model, Kirillov et al., 2023) et DINOv2 montrent qu’un unique modèle pré-entraîné peut être adapté à une grande variété de tâches visuelles, souvent avec très peu de données annotées. Cette tendance vers des modèles généralistes, combinée à l’intégration de la vision et du langage (vision-language models), dessine un avenir où la compréhension visuelle automatique se rapproche de la polyvalence humaine.