
Règles d’association et modèles de mélange#
Il y a dans les données des structures cachées que ni la classification ni la régression ne peuvent révéler. Les découvrir, c’est lire entre les lignes du monde.
— Adaptation libre d’un aphorisme sur l’apprentissage non supervisé
Ce dernier chapitre de la partie consacrée à l’apprentissage non supervisé explore deux familles de méthodes qui cherchent à mettre au jour des structures latentes dans les données. La première — les règles d’association — extrait des motifs fréquents et des relations entre variables dans des données transactionnelles. La seconde — les modèles de mélange — suppose que les données sont générées par un mélange de plusieurs distributions, chacune correspondant à un groupe latent. Ces deux approches partagent un objectif commun : révéler une organisation sous-jacente que les méthodes de clustering classiques ne capturent pas directement, soit parce qu’il s’agit de co-occurrences entre items, soit parce qu’un modèle probabiliste génératif est plus approprié.
Règles d’association : concepts fondamentaux#
L’analyse par règles d’association est née du problème de l”analyse du panier d’achat (market basket analysis) : étant donné un historique de transactions dans un supermarché, quels produits sont fréquemment achetés ensemble ?
Transactions et itemsets#
Définition 182 (Transaction et itemset)
Soit \(\mathcal{I} = \{i_1, i_2, \ldots, i_m\}\) un ensemble fini d”items. Une transaction \(T\) est un sous-ensemble de \(\mathcal{I}\), c’est-à-dire \(T \subseteq \mathcal{I}\). Une base de transactions \(\mathcal{D} = \{T_1, T_2, \ldots, T_n\}\) est un multi-ensemble de transactions. Un itemset \(X\) est un sous-ensemble non vide de \(\mathcal{I}\). Un itemset contenant \(k\) items est appelé un \(k\)-itemset.
Exemple 15 (Base de transactions)
Considérons \(\mathcal{I} = \{\text{pain}, \text{beurre}, \text{lait}, \text{oeufs}, \text{farine}\}\) :
TID |
Transaction |
|---|---|
1 |
{pain, beurre, lait} |
2 |
{pain, beurre, oeufs, farine} |
3 |
{lait, oeufs} |
4 |
{pain, beurre, lait, farine} |
5 |
{pain, lait} |
L’itemset \(\{\text{pain}, \text{beurre}\}\) est un 2-itemset présent dans les transactions 1, 2 et 4.
Mesures d’intérêt#
Définition 183 (Support)
Le support d’un itemset \(X\) dans \(\mathcal{D}\) est la proportion de transactions contenant \(X\) :
Un itemset est dit fréquent si \(\text{supp}(X) \geq \sigma_{\min}\).
Définition 184 (Règle d’association, confiance, lift et conviction)
Une règle d’association est une implication \(X \Rightarrow Y\) avec \(X, Y \subseteq \mathcal{I}\) et \(X \cap Y = \emptyset\). Ses mesures d’intérêt sont :
Confiance : \(\text{conf}(X \Rightarrow Y) = \frac{\text{supp}(X \cup Y)}{\text{supp}(X)} = P(Y \mid X)\)
Lift : \(\text{lift}(X \Rightarrow Y) = \frac{\text{supp}(X \cup Y)}{\text{supp}(X) \cdot \text{supp}(Y)}\)
Conviction : \(\text{conv}(X \Rightarrow Y) = \frac{1 - \text{supp}(Y)}{1 - \text{conf}(X \Rightarrow Y)}\)
Un lift de 1 signifie indépendance ; un lift \(> 1\) indique une association positive. La conviction est asymétrique : elle mesure le degré de dépendance directionnelle de la règle.
Remarque 160
Le support et le lift sont symétriques, tandis que la confiance et la conviction sont asymétriques. Le choix des métriques dépend de l’application : en recommandation, on privilégie la confiance ; en analyse exploratoire, le lift est un bon point de départ.
Règle : pain => beurre
Support(pain ∪ beurre) = 0.60
Confiance = 0.75
Lift = 1.25
Règle : beurre => pain
Confiance = 1.00
Lift = 1.25
Algorithme Apriori#
L’extraction de règles d’association passe par deux étapes : (1) trouver tous les itemsets fréquents et (2) générer les règles. L’algorithme Apriori (Agrawal et Srikant, 1994) est l’approche fondatrice.
Propriété anti-monotone#
Proposition 48 (Propriété anti-monotone du support)
Si un itemset \(X\) est fréquent, alors tout sous-ensemble \(Y \subseteq X\) est également fréquent. Réciproquement, si \(X\) n’est pas fréquent, aucun sur-ensemble \(Z \supseteq X\) ne peut l’être :
Proof. Pour toute transaction \(T\), si \(X \subseteq T\) alors \(Y \subseteq T\) puisque \(Y \subseteq X\). Donc l’ensemble des transactions contenant \(X\) est inclus dans celui contenant \(Y\), d’où \(\text{supp}(X) \leq \text{supp}(Y)\).
Description de l’algorithme#
L’algorithme procède niveau par niveau : (1) calculer les 1-itemsets fréquents \(L_1\) ; (2) générer les \((k{+}1)\)-candidats \(C_{k+1}\) par jointure de paires de \(L_k\) ; (3) élaguer les candidats dont un sous-ensemble n’est pas fréquent ; (4) compter le support et ne garder que les fréquents \(L_{k+1}\) ; (5) répéter jusqu’à \(L_{k+1} = \emptyset\).
Remarque 161
La complexité d’Apriori dépend du nombre de transactions, du nombre d’items et du seuil de support. L’algorithme nécessite autant de parcours de la base qu’il y a de niveaux. En pratique, un seuil de support bien choisi limite drastiquement l’espace de recherche grâce à l’élagage anti-monotone.
Itemsets fréquents (support ≥ 0.4) :
{'beurre', 'pain', 'farine'} support = 0.40
{'pain', 'beurre', 'lait'} support = 0.40
{'pain', 'lait'} support = 0.60
{'beurre', 'pain'} support = 0.60
{'beurre', 'farine'} support = 0.40
{'beurre', 'lait'} support = 0.40
{'pain', 'farine'} support = 0.40
{'lait'} support = 0.80
{'pain'} support = 0.80
{'beurre'} support = 0.60
{'oeufs'} support = 0.40
{'farine'} support = 0.40
17 règles trouvées (confiance ≥ 0.6) :
{'beurre'} => {'farine'}
support=0.40 confiance=0.67 lift=1.67
{'farine'} => {'beurre'}
support=0.40 confiance=1.00 lift=1.67
{'beurre'} => {'pain', 'farine'}
support=0.40 confiance=0.67 lift=1.67
{'farine'} => {'beurre', 'pain'}
support=0.40 confiance=1.00 lift=1.67
{'beurre', 'pain'} => {'farine'}
support=0.40 confiance=0.67 lift=1.67
{'pain', 'farine'} => {'beurre'}
support=0.40 confiance=1.00 lift=1.67
{'beurre'} => {'pain'}
support=0.60 confiance=1.00 lift=1.25
{'pain'} => {'beurre'}
support=0.60 confiance=0.75 lift=1.25
{'farine'} => {'pain'}
support=0.40 confiance=1.00 lift=1.25
{'beurre', 'farine'} => {'pain'}
support=0.40 confiance=1.00 lift=1.25
{'beurre', 'lait'} => {'pain'}
support=0.40 confiance=1.00 lift=1.25
{'beurre'} => {'pain', 'lait'}
support=0.40 confiance=0.67 lift=1.11
{'pain', 'lait'} => {'beurre'}
support=0.40 confiance=0.67 lift=1.11
{'pain'} => {'lait'}
support=0.60 confiance=0.75 lift=0.94
{'lait'} => {'pain'}
support=0.60 confiance=0.75 lift=0.94
{'beurre'} => {'lait'}
support=0.40 confiance=0.67 lift=0.83
{'pain', 'beurre'} => {'lait'}
support=0.40 confiance=0.67 lift=0.83
Apriori avec mlxtend#
La bibliothèque mlxtend fournit une implémentation optimisée. Elle est optionnelle : si elle n’est pas installée, les cellules suivantes seront ignorées, mais les concepts restent identiques à notre implémentation manuelle.
mlxtend non disponible — les cellules suivantes seront ignorées.
Algorithme FP-Growth#
L’algorithme FP-Growth (Han, Pei et Yin, 2000) résout les deux faiblesses principales d’Apriori : les multiples parcours de la base et la génération coûteuse de candidats.
Définition 185 (FP-tree)
Un FP-tree (Frequent Pattern tree) est un arbre préfixe compact encodant les transactions. Chaque noeud représente un item avec un compteur. Les items sont ordonnés par fréquence décroissante pour maximiser le partage de préfixes. La construction nécessite deux parcours : (1) calculer les fréquences et trier ; (2) insérer les transactions filtrées dans l’arbre.
Proposition 49 (Avantages de FP-Growth sur Apriori)
Pas de génération de candidats : l’extraction se fait directement par projection récursive (conditional pattern base).
Deux parcours de la base seulement, contre autant que la taille maximale des itemsets fréquents pour Apriori.
En pratique, FP-Growth est significativement plus rapide sur les bases volumineuses et les seuils de support bas.
Applications des règles d’association#
Exemple 16 (Analyse du panier d’achat)
L’application historique des règles d’association est le market basket analysis. Des règles comme \(\{\text{couches}\} \Rightarrow \{\text{bière}\}\) (confiance 0.68, lift 2.1) révèlent des associations surprenantes mais exploitables. Le lift distingue les co-occurrences fortuites (produits très fréquents) des associations véritablement intéressantes.
Les règles d’association s’appliquent aussi en bioinformatique (gènes co-exprimés), en médecine (combinaisons de symptômes), en web mining (séquences de navigation) et en détection de fraude (schémas de transactions suspects).
Remarque 162
L’extraction produit souvent un très grand nombre de règles. Pour filtrer : (1) exiger simultanément support, confiance et lift minimum ; (2) éliminer les règles redondantes (si \(X' \subset X\) donne une confiance similaire, préférer la règle plus simple) ; (3) valider avec l’expertise métier ; (4) utiliser des visualisations (graphes, heatmaps) pour l’exploration interactive.
La seconde partie de ce chapitre aborde les modèles de mélange, une famille de modèles génératifs probabilistes complémentaire aux règles d’association.
Modèles de mélange gaussien#
Les modèles de mélange gaussien (Gaussian Mixture Models, GMM) constituent l’approche probabiliste fondamentale du clustering. Contrairement aux k-moyennes, les GMM modélisent l’appartenance à un cluster comme une variable latente et fournissent des probabilités d’appartenance.
Modèle génératif#
Définition 186 (Modèle de mélange gaussien)
Un GMM à \(K\) composantes suppose que chaque \(\mathbf{x}_i \in \mathbb{R}^d\) est généré par :
Tirer \(z_i \sim \text{Catégorielle}(\pi_1, \ldots, \pi_K)\) avec \(\sum_k \pi_k = 1\), \(\pi_k \geq 0\).
Tirer \(\mathbf{x}_i \mid z_i = k \sim \mathcal{N}(\boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k)\).
La densité marginale est \(p(\mathbf{x} \mid \boldsymbol{\theta}) = \sum_{k=1}^K \pi_k \, \mathcal{N}(\mathbf{x} \mid \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k)\).
Définition 187 (Log-vraisemblance du mélange)
Pour un échantillon i.i.d. \(\{\mathbf{x}_1, \ldots, \mathbf{x}_n\}\) :
La somme à l’intérieur du logarithme empêche une optimisation en forme close, d’où le recours à l’algorithme EM.
Algorithme Espérance-Maximisation (EM)#
Définition 188 (Algorithme EM pour les GMM)
Étape E : calculer les responsabilités \(\gamma_{ik} = P(z_i = k \mid \mathbf{x}_i, \boldsymbol{\theta}^{(t)})\) :
Étape M : avec \(N_k = \sum_i \gamma_{ik}\), mettre à jour :
Proposition 50 (Convergence de l’algorithme EM)
La log-vraisemblance est non décroissante à chaque itération : \(\ell(\boldsymbol{\theta}^{(t+1)}) \geq \ell(\boldsymbol{\theta}^{(t)})\). Cependant, EM ne garantit la convergence que vers un maximum local. En pratique, on lance EM plusieurs fois avec des initialisations différentes (n_init dans Scikit-learn) et on conserve la meilleure solution.
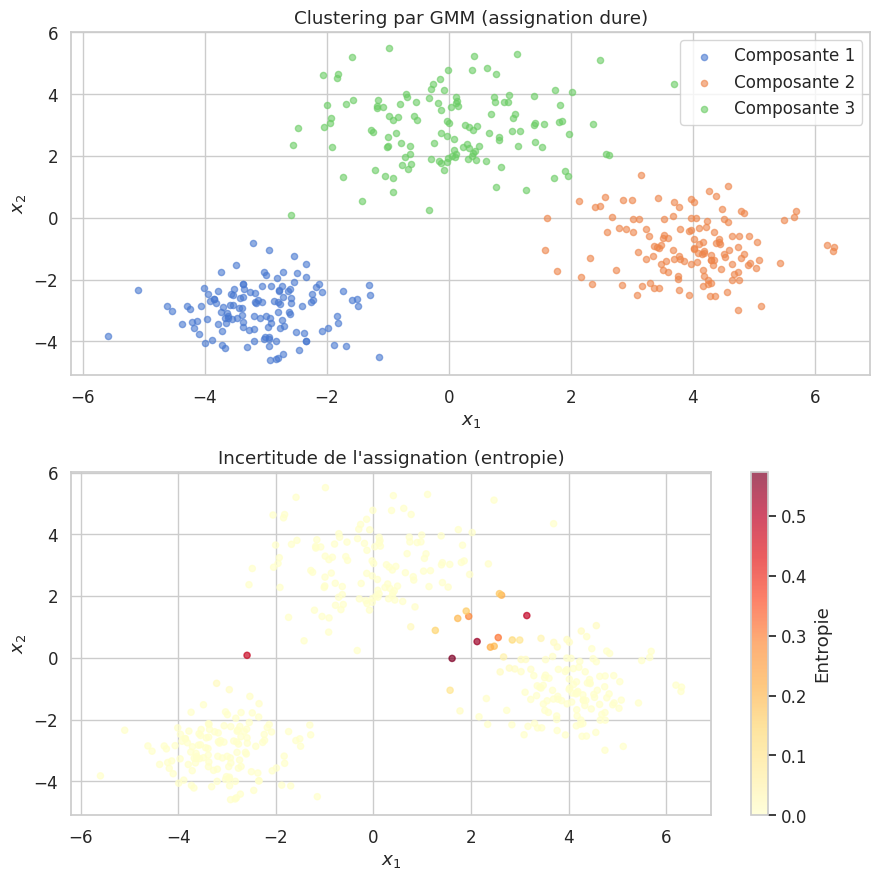
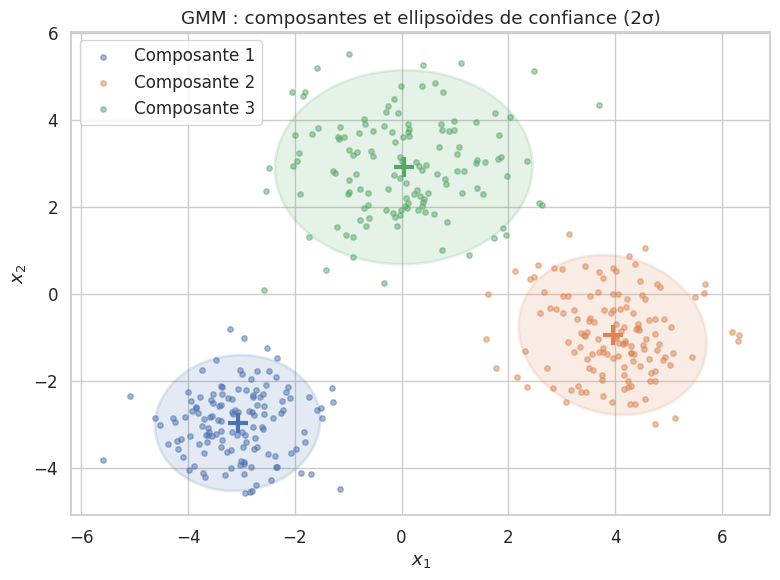
Choix du nombre de composantes#
Définition 189 (Critères BIC et AIC)
Le choix de \(K\) repose sur des critères d’information pénalisant la complexité :
où \(p\) est le nombre de paramètres libres et \(n\) le nombre d’observations. Le modèle optimal minimise le critère. Le BIC pénalise davantage la complexité et tend vers des modèles plus parcimonieux.
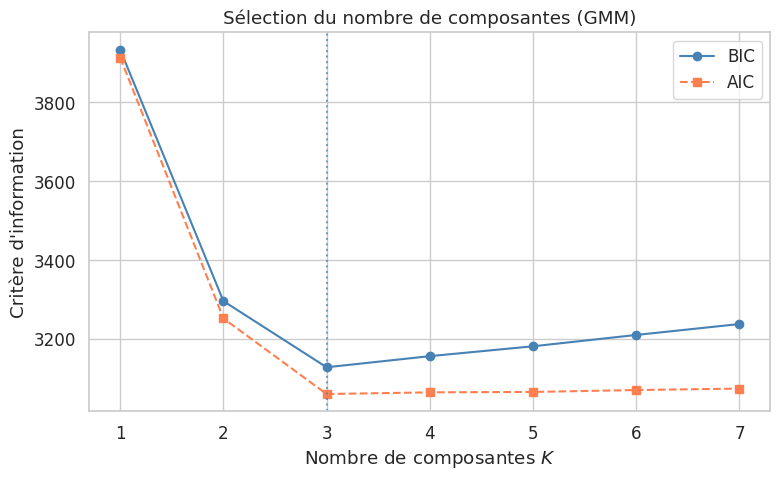
K optimal selon BIC : 3
Mélange de Bernoulli#
Les GMM supposent des données continues. Pour des données binaires (présence/absence de mots, réponses oui/non, pixels noirs/blancs), on utilise le mélange de Bernoulli.
Définition 190 (Modèle de mélange de Bernoulli)
Soit \(\mathbf{x}_i \in \{0, 1\}^d\). Un mélange de Bernoulli à \(K\) composantes :
Tire \(z_i \sim \text{Catégorielle}(\pi_1, \ldots, \pi_K)\).
Tire \(x_{ij} \mid z_i = k \sim \text{Bernoulli}(\mu_{kj})\) pour \(j = 1, \ldots, d\).
La vraisemblance marginale est
Définition 191 (EM pour le mélange de Bernoulli)
Étape E : \(\gamma_{ik} = \frac{\pi_k \prod_j \mu_{kj}^{x_{ij}} (1 - \mu_{kj})^{1 - x_{ij}}}{\sum_\ell \pi_\ell \prod_j \mu_{\ell j}^{x_{ij}} (1 - \mu_{\ell j})^{1 - x_{ij}}}\)
Étape M : \(\mu_{kj}^{(t+1)} = \frac{\sum_i \gamma_{ik} x_{ij}}{\sum_i \gamma_{ik}}, \quad \pi_k^{(t+1)} = \frac{1}{n}\sum_i \gamma_{ik}\)
Un lissage \(\epsilon \approx 10^{-6}\) sur \(\mu_{kj}\) évite les valeurs 0 ou 1 qui rendraient la log-vraisemblance non définie.
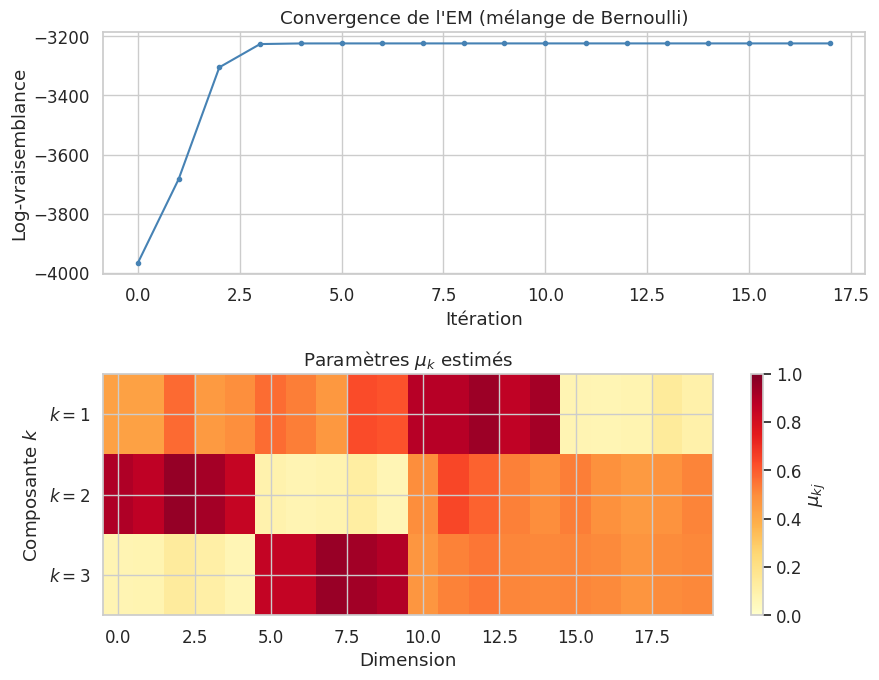
Remarque 163
Le mélange de Bernoulli est adapté au clustering de documents représentés par des vecteurs binaires (présence/absence de mots). Chaque composante correspond à un profil thématique.
Allocation de Dirichlet latente (LDA)#
L’allocation de Dirichlet latente (Blei, Ng et Jordan, 2003) est le modèle génératif de référence pour le topic modeling. Contrairement au mélange de Bernoulli où chaque document appartient à un seul cluster, le LDA suppose qu’un document traite de plusieurs sujets simultanément.
Modèle génératif du LDA#
Définition 192 (Distribution de Dirichlet)
La distribution de Dirichlet \(\text{Dir}(\boldsymbol{\alpha})\) est définie sur le simplexe de dimension \(K-1\) :
Des valeurs \(\alpha_k < 1\) favorisent des distributions creuses ; \(\alpha_k > 1\) favorise l’uniformité.
Définition 193 (Modèle LDA)
Pour un corpus de \(M\) documents, un vocabulaire de \(V\) mots et \(K\) topics :
Pour chaque topic \(k\), tirer \(\boldsymbol{\beta}_k \sim \text{Dir}(\boldsymbol{\eta})\) (distribution sur les mots).
Pour chaque document \(m\) :
Tirer \(\boldsymbol{\theta}_m \sim \text{Dir}(\boldsymbol{\alpha})\) (proportions de topics).
Pour chaque mot \(n\) : tirer le topic \(z_{mn} \sim \text{Cat}(\boldsymbol{\theta}_m)\) puis le mot \(w_{mn} \sim \text{Cat}(\boldsymbol{\beta}_{z_{mn}})\).
Chaque document est un mélange de sujets, et chaque sujet est une distribution sur les mots.
Inférence#
Proposition 51 (Inférence dans le LDA)
L’inférence exacte est intraitable. Deux approches sont courantes :
Inférence variationnelle : approximation par minimisation de la divergence KL (Scikit-learn).
Échantillonnage de Gibbs : simulation de la postérieure par échantillonnage conditionnel itératif (
gensim).
Vocabulaire : 42 termes | Matrice : (10, 42)
Topics découverts :
Topic 1 : voiture, la, vélo, pollue, le, de
Topic 2 : le, chat, chien, la, sur, aime
Topic 3 : de, voiture, la, le, vélo, route
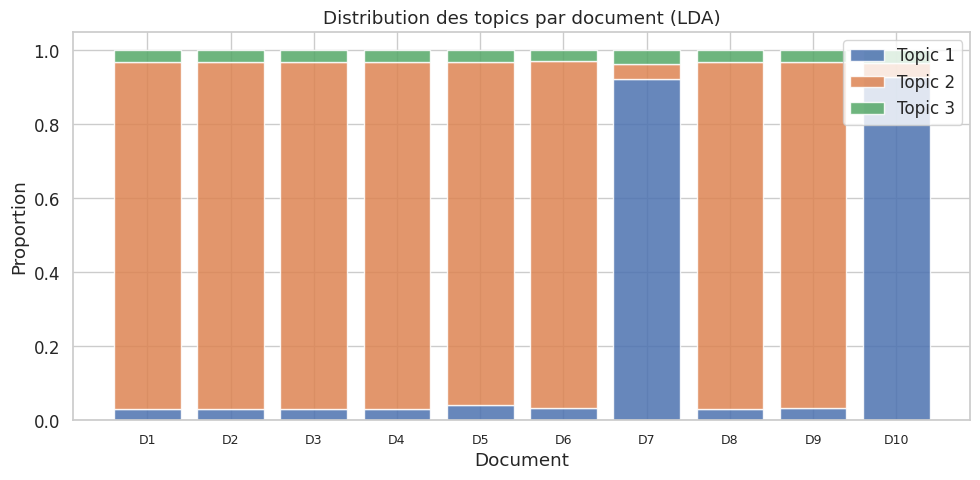
Exemple complet : topic modeling sur 20 Newsgroups#
Pour illustrer le LDA à plus grande échelle, nous utilisons le jeu de données 20 Newsgroups, un corpus classique d’environ 18 000 articles de forums Usenet. Nous sélectionnons cinq catégories.
Nombre de documents : 2914
Catégories : ['comp.graphics', 'rec.autos', 'rec.sport.baseball', 'sci.space', 'talk.politics.guns']
Matrice documents-termes : (2914, 2000)
============================================================
TOPICS DÉCOUVERTS PAR LDA SUR 20 NEWSGROUPS
============================================================
Topic 1 : gun, people, guns, right, law, government, weapons, don, state, control
Topic 2 : space, image, data, edu, graphics, nasa, jpeg, program, available, use
Topic 3 : car, 00, new, cars, like, 000, just, good, engine, 02
Topic 4 : just, don, think, like, year, good, know, time, better, did
Topic 5 : file, 1993, 10, 12, 15, april, 11, 1992, 14, year
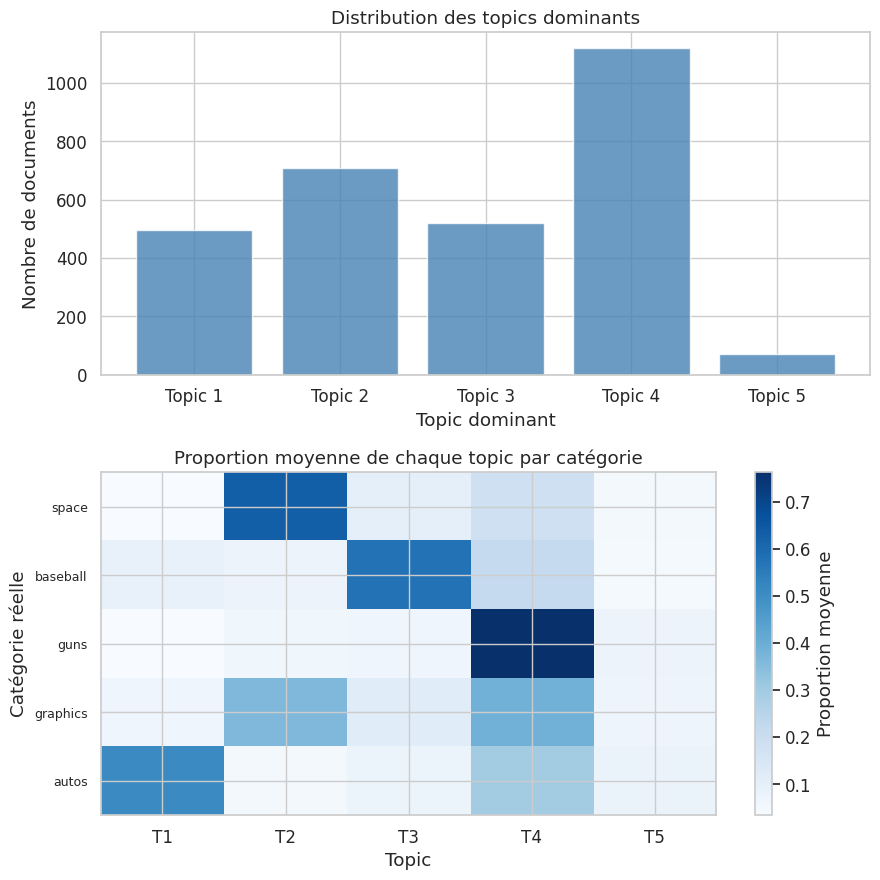
Remarque 164
Les topics découverts par le LDA correspondent souvent — au moins partiellement — aux catégories thématiques du corpus, même sans supervision. L’interprétation reste subjective : il est utile de lire quelques documents fortement associés à chaque topic pour valider les étiquettes assignées.
Choix du nombre de topics#
Remarque 165
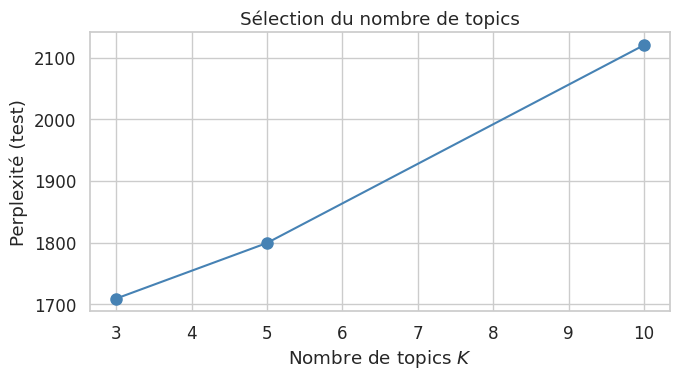
Le choix de \(K\) est analogue au choix du nombre de clusters. On peut utiliser : (1) la perplexité sur un ensemble de validation, \(\text{perplexity} = \exp(-\ell(\mathcal{D}_{\text{test}})/N_{\text{test}})\) ; (2) la cohérence des topics (topic coherence), mesurant la cohérence sémantique des mots-clés ; (3) l”interprétabilité humaine, en essayant plusieurs valeurs de \(K\).
K = 3 | Perplexité = 1709.2
K = 5 | Perplexité = 1799.4
K = 10 | Perplexité = 2120.3
Résumé#
Ce chapitre a présenté deux familles complémentaires de méthodes pour découvrir des structures cachées :
Les règles d’association extraient des motifs de co-occurrence dans des données transactionnelles. Le support, la confiance et le lift identifient les associations intéressantes. Apriori et FP-Growth rendent l’extraction efficace à grande échelle.
Les modèles de mélange adoptent une perspective probabiliste. Le GMM fournit des assignations souples via l’algorithme EM. Le mélange de Bernoulli adapte cette approche aux données binaires. Le LDA généralise au topic modeling en permettant à chaque document d’être un mélange de sujets.
Remarque 166
Le choix entre ces méthodes dépend de la nature des données : données transactionnelles pour les règles d’association, données continues pour les GMM, données binaires pour le mélange de Bernoulli, et corpus de texte pour le LDA. En pratique, combiner plusieurs approches est souvent fructueux : par exemple, un GMM pour un premier clustering, puis des règles d’association au sein de chaque cluster pour affiner l’analyse.