
Réseaux convolutifs#
Tout ce que nous voyons cache autre chose ; nous désirons toujours voir ce qui est caché par ce que nous voyons.
René Magritte
Les chapitres précédents ont introduit le perceptron multicouche (MLP), la rétropropagation du gradient et le cadre PyTorch. Ces réseaux entièrement connectés (fully connected) sont des approximateurs universels, mais ils présentent des limitations fondamentales lorsqu’il s’agit de traiter des données structurées spatialement, comme les images. Un MLP appliqué à une image de \(224 \times 224 \times 3\) pixels nécessiterait \(224 \times 224 \times 3 = 150\,528\) poids par neurone de la première couche cachée — un nombre colossal qui rend l’apprentissage inefficace et sujet au surapprentissage.
Les réseaux de neurones convolutifs (Convolutional Neural Networks, CNN) résolvent ce problème en exploitant la structure spatiale des images à travers trois idées clés : la connectivité locale, le partage de poids et l”invariance par translation. Ce chapitre présente l’opération de convolution, les couches de pooling, les architectures classiques et modernes, le transfer learning, et une implémentation complète en PyTorch.
Périphérique utilisé : cpu
Introduction : la vision par ordinateur#
Pourquoi les MLP ne suffisent pas#
Une image en niveaux de gris de taille \(H \times W\) peut être vue comme un vecteur de \(\mathbb{R}^{H \cdot W}\). Pour un MLP, chaque pixel est un feature indépendant, et la couche d’entrée est entièrement connectée à la première couche cachée. Cela pose trois problèmes majeurs.
Remarque 196
Problèmes des MLP pour les images :
Nombre de paramètres : pour une image \(224 \times 224\) en couleur (3 canaux), une couche cachée de 1000 neurones nécessite \(224 \times 224 \times 3 \times 1000 \approx 150\) millions de paramètres — uniquement pour la première couche.
Perte de la structure spatiale : en « aplatissant » l’image en vecteur, le MLP perd toute information sur les relations de voisinage entre pixels.
Absence d’invariance par translation : un chat dans le coin supérieur gauche de l’image active des neurones complètement différents du même chat au centre. Le MLP ne généralise pas la notion de motif local.
Invariances fondamentales#
La vision humaine est remarquablement robuste aux transformations géométriques. Nous reconnaissons un objet qu’il soit déplacé, agrandi, légèrement tourné ou partiellement occulté. Un bon modèle de vision doit posséder — ou apprendre — ces invariances.
Définition 231 (Invariances en vision par ordinateur)
Soit \(f : \mathcal{X} \to \mathcal{Y}\) un classifieur d’images et \(T\) une transformation géométrique. On dit que \(f\) est invariant par \(T\) si
Les invariances les plus importantes en vision sont :
Translation : déplacement spatial de l’objet dans l’image.
Échelle : changement de taille de l’objet.
Rotation : rotation de l’objet dans le plan.
Déformation : changements légers de forme ou de perspective.
Inspiration biologique : le cortex visuel#
Les CNN tirent leur inspiration des travaux de David Hubel et Torsten Wiesel (prix Nobel 1981) sur le cortex visuel du chat. Leurs expériences ont révélé que les neurones du cortex visuel primaire (V1) ne répondent pas à l’ensemble de l’image, mais à de petites régions appelées champs réceptifs (receptive fields). De plus, ils ont identifié deux types de cellules :
Les cellules simples, qui détectent des bords orientés dans une région locale.
Les cellules complexes, qui répondent au même type de stimulus mais de manière invariante par translation sur une région plus large.
Cette organisation hiérarchique — détection locale puis agrégation spatiale — est exactement le principe des CNN : les premières couches détectent des motifs simples (bords, textures), et les couches plus profondes combinent ces motifs pour reconnaître des structures de plus en plus abstraites.
Convolution discrète 2D#
Définition formelle#
L’opération fondamentale d’un CNN est la convolution discrète, qui mesure la ressemblance locale entre une image et un petit filtre (ou noyau).
Définition 232 (Convolution discrète 2D)
Soit \(\mathbf{X} \in \mathbb{R}^{H \times W}\) une image d’entrée et \(\mathbf{K} \in \mathbb{R}^{k_H \times k_W}\) un noyau de convolution. La convolution discrète 2D (en pratique une corrélation croisée) est définie par :
Le résultat est une carte de caractéristiques (feature map) ou carte d’activation de taille \((H - k_H + 1) \times (W - k_W + 1)\) (sans padding).
Remarque 197
En apprentissage profond, on utilise en réalité la corrélation croisée plutôt que la convolution au sens mathématique strict (qui nécessite de retourner le noyau). La distinction est sans conséquence car les poids du noyau sont appris : le réseau peut apprendre le noyau retourné si nécessaire.
Noyaux classiques#
Avant l’apprentissage profond, les noyaux étaient conçus manuellement pour détecter des propriétés spécifiques de l’image. Illustrons quelques filtres classiques pour construire l’intuition.

Pas (stride) et padding#
Deux hyperparamètres contrôlent la manière dont le noyau parcourt l’image : le pas (stride) et le rembourrage (padding).
Définition 233 (Stride et padding)
Soit une image d’entrée de taille \(H \times W\), un noyau de taille \(k \times k\), un pas \(s\) (stride) et un rembourrage \(p\) (padding).
Le stride \(s\) est le nombre de pixels dont le noyau se décale entre deux positions successives. Un stride de 2 divise les dimensions spatiales par 2.
Le padding \(p\) consiste à ajouter \(p\) pixels (généralement des zéros) sur chaque bord de l’image avant la convolution.
La taille de la carte de sortie est :
Les deux stratégies de padding les plus courantes sont :
Valid (\(p = 0\)) : aucun rembourrage. La carte de sortie est plus petite que l’entrée.
Same (\(p = \lfloor k / 2 \rfloor\) avec \(s = 1\)) : le rembourrage est choisi de sorte que la sortie ait les mêmes dimensions spatiales que l’entrée.
Exemple 20 (Calcul de la taille de sortie)
Soit une image \(32 \times 32\), un noyau \(5 \times 5\), un stride \(s = 1\) et un padding \(p = 0\) (valid).
Avec un padding \(p = 2\) (same) :
Avec un stride \(s = 2\) et un padding \(p = 2\) :
Configuration Entrée Sortie
------------------------------------------------------------
Valid (p=0, s=1) [1, 1, 32, 32] [1, 1, 28, 28]
Same (p=2, s=1) [1, 1, 32, 32] [1, 1, 32, 32]
Stride 2 (p=2, s=2) [1, 1, 32, 32] [1, 1, 16, 16]
Grand noyau (k=7, p=3) [1, 1, 32, 32] [1, 1, 32, 32]
Convolution multicouche : les canaux#
En pratique, les images possèdent plusieurs canaux (3 pour RGB) et chaque couche de convolution produit plusieurs cartes de caractéristiques. La convolution s’étend naturellement à ce cas.
Définition 234 (Convolution multicouche)
Soit une entrée \(\mathbf{X} \in \mathbb{R}^{C_{\text{in}} \times H \times W}\) avec \(C_{\text{in}}\) canaux. Un filtre de convolution est un tenseur \(\mathbf{K} \in \mathbb{R}^{C_{\text{in}} \times k_H \times k_W}\) qui s’applique sur l’ensemble des canaux d’entrée. La sortie d’un filtre est :
Pour produire \(C_{\text{out}}\) cartes de caractéristiques, on utilise \(C_{\text{out}}\) filtres indépendants, ce qui donne un tenseur de poids \(\mathbf{W} \in \mathbb{R}^{C_{\text{out}} \times C_{\text{in}} \times k_H \times k_W}\) et un vecteur de biais \(\mathbf{b} \in \mathbb{R}^{C_{\text{out}}}\).
Remarque 198
Le nombre de paramètres d’une couche de convolution est \(C_{\text{out}} \times (C_{\text{in}} \times k_H \times k_W + 1)\), où le \(+1\) correspond au biais. Ce nombre est indépendant de la taille spatiale de l’entrée : c’est le partage de poids, qui réduit drastiquement le nombre de paramètres par rapport à une couche entièrement connectée.
Couche convolutive (k=3, C_in=3, C_out=64) : 1,792 paramètres
Couche FC équivalente : 9,633,856 paramètres
Rapport FC / Conv : 5,376x
Couches de pooling#
Après les convolutions, les couches de pooling (sous-échantillonnage) réduisent progressivement les dimensions spatiales des cartes de caractéristiques, tout en conservant l’information la plus saillante.
Définition 235 (Max pooling)
Le max pooling avec une fenêtre de taille \(k \times k\) et un pas \(s\) produit une sortie :
Typiquement, on utilise \(k = 2\) et \(s = 2\), ce qui divise chaque dimension spatiale par 2.
Définition 236 (Average pooling et global average pooling)
Le average pooling remplace le maximum par la moyenne sur la fenêtre :
Le global average pooling (GAP) calcule la moyenne sur l’ensemble de la carte de caractéristiques :
Il transforme une carte \(C \times H \times W\) en un vecteur de dimension \(C\), éliminant ainsi la dépendance spatiale.
Remarque 199
Le pooling joue un double rôle :
Réduction de dimension : il diminue le nombre de pixels à traiter, réduisant la charge computationnelle et le nombre de paramètres des couches suivantes.
Invariance spatiale locale : en prenant le maximum (ou la moyenne) sur une petite région, le pooling rend la représentation légèrement invariante aux petites translations.
Entrée (4×4) :
[[1. 3. 2. 4.]
[5. 6. 1. 2.]
[3. 2. 7. 8.]
[4. 1. 3. 5.]]
Max pooling 2×2 (sortie 2×2) :
[[6. 4.]
[4. 8.]]
Average pooling 2×2 (sortie 2×2) :
[[3.75 2.25]
[2.5 5.75]]
Global average pooling (sortie 1×1) :
3.5625

Architecture d’un CNN#
Blocs de construction#
Un CNN typique est construit à partir de blocs convolutifs empilés, suivis de couches entièrement connectées pour la classification.
Définition 237 (Bloc convolutif)
Un bloc convolutif standard est composé de trois opérations successives :
Convolution : extraction de caractéristiques locales par un ensemble de filtres appris.
Activation non linéaire : typiquement ReLU, \(\sigma(x) = \max(0, x)\).
Pooling : sous-échantillonnage spatial (max pooling ou average pooling).
On note ce bloc \(\text{Conv}(C_{\text{in}}, C_{\text{out}}, k) \to \text{ReLU} \to \text{Pool}(k_p, s_p)\).
L’architecture générale d’un CNN pour la classification suit le schéma :
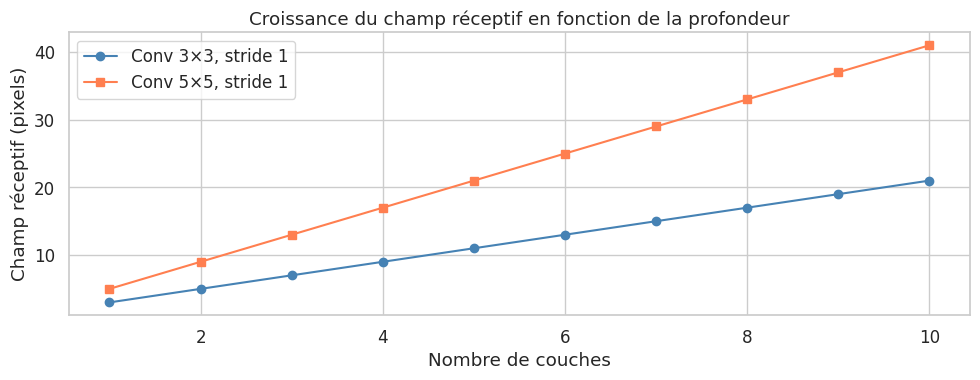
Feature maps et champ réceptif#
À mesure que l’on avance dans le réseau, les cartes de caractéristiques (feature maps) deviennent spatialement plus petites mais plus nombreuses (plus de canaux). Les premières couches capturent des motifs bas niveau (bords, textures) tandis que les couches profondes capturent des motifs haut niveau (parties d’objets, objets entiers).
Définition 238 (Champ réceptif)
Le champ réceptif (receptive field) d’un neurone dans une couche \(\ell\) est la région de l’image d’entrée qui influence la valeur de ce neurone. Pour un réseau à \(L\) couches de convolution avec des noyaux de taille \(k\) et un stride \(s = 1\) (sans pooling), le champ réceptif d’un neurone de la couche \(\ell\) est :
avec \(r_0 = 1\). Pour des noyaux \(3 \times 3\) empilés et un stride unitaire :
Ainsi, trois couches \(3 \times 3\) donnent un champ réceptif de \(7 \times 7\), équivalent à un seul noyau \(7 \times 7\) mais avec beaucoup moins de paramètres et plus de non-linéarités.
Architectures classiques#
L’histoire des CNN est jalonnée d’architectures qui ont repoussé les limites de la reconnaissance d’images. Nous en présentons les plus influentes.
LeNet-5 (1998)#
Conçu par Yann LeCun et ses collaborateurs, LeNet-5 est l’un des premiers CNN à avoir démontré l’efficacité de l’apprentissage convolutif pour la reconnaissance de chiffres manuscrits (MNIST). Son architecture est devenue le prototype des CNN modernes.
Exemple 21 (Architecture de LeNet-5)
L’architecture de LeNet-5 comprend :
Entrée : image \(32 \times 32\) en niveaux de gris.
C1 : Convolution \(5 \times 5\), 6 filtres → cartes \(28 \times 28 \times 6\), suivie de sigmoid.
S2 : Average pooling \(2 \times 2\) → cartes \(14 \times 14 \times 6\).
C3 : Convolution \(5 \times 5\), 16 filtres → cartes \(10 \times 10 \times 16\), suivie de sigmoid.
S4 : Average pooling \(2 \times 2\) → cartes \(5 \times 5 \times 16\).
C5 : Convolution \(5 \times 5\), 120 filtres → vecteur \(1 \times 1 \times 120\).
F6 : Couche FC de 84 neurones.
Sortie : 10 classes.
Nombre total de paramètres : environ 60 000.
AlexNet (2012)#
AlexNet, proposé par Alex Krizhevsky, Ilya Sutskever et Geoffrey Hinton, a remporté la compétition ImageNet 2012 avec une marge considérable, marquant le début de la révolution de l’apprentissage profond.
Exemple 22 (Innovations d’AlexNet)
Utilisation de ReLU au lieu de sigmoid/tanh (accélère la convergence).
Dropout (taux 0.5) dans les couches FC pour la régularisation.
Data augmentation (translations, retournements horizontaux, modifications de couleur).
Entraînement sur GPU (deux GPU en parallèle).
5 couches de convolution + 3 couches FC. Environ 60 millions de paramètres.
VGGNet (2014)#
L’équipe du Visual Geometry Group d’Oxford a proposé VGGNet, dont l’idée centrale est d’utiliser uniquement des noyaux \(3 \times 3\) empilés en profondeur.
Proposition 59 (Équivalence de noyaux empilés)
Deux couches de convolution \(3 \times 3\) successives ont un champ réceptif de \(5 \times 5\), et trois couches \(3 \times 3\) ont un champ réceptif de \(7 \times 7\). Cependant :
Paramètres : trois couches \(3 \times 3\) avec \(C\) canaux nécessitent \(3 \times (C \times 3 \times 3 \times C) = 27C^2\) paramètres, contre \(C \times 7 \times 7 \times C = 49C^2\) pour un seul noyau \(7 \times 7\).
Non-linéarité : l’empilement introduit des activations ReLU entre les couches, augmentant la capacité discriminative du réseau.
Proof. Le champ réceptif d’une couche \(3 \times 3\) est \(3\). Après deux couches, le champ réceptif est \(r_2 = 1 + 2 \times 1 + 2 \times 1 = 5\). Après trois couches : \(r_3 = 1 + 2 \times 3 = 7\). Le nombre de paramètres pour trois couches \(3 \times 3\) est \(3 \times 9C^2 = 27C^2\), contre \(49C^2\) pour un noyau \(7 \times 7\), soit une réduction de \(\frac{27}{49} \approx 45\%\).
Architecture Année Profondeur Paramètres Top-5 ImageNet Innovation clé
LeNet-5 1998 5 60 K — Première architecture CNN
AlexNet 2012 8 60 M 16.4% ReLU, Dropout, GPU
VGG-16 2014 16 138 M 7.3% Noyaux 3×3 empilés
VGG-19 2014 19 144 M 7.3% Plus de profondeur
Innovations modernes#
Les architectures classiques ont montré que la profondeur est cruciale pour les performances. Cependant, augmenter simplement le nombre de couches ne fonctionne pas indéfiniment : au-delà d’une certaine profondeur, les gradients s’évanouissent ou explosent, et les performances se dégradent paradoxalement. Plusieurs innovations ont permis de surmonter cette barrière.
ResNet et les connexions résiduelles#
Le problème fondamental des réseaux très profonds est la dégradation : un réseau de 56 couches obtient de moins bons résultats qu’un réseau de 20 couches, non pas à cause du surapprentissage, mais à cause de la difficulté d’optimisation. ResNet (He et al., 2015) résout ce problème grâce aux connexions résiduelles (skip connections).
Définition 239 (Bloc résiduel)
Soit \(\mathbf{x}\) l’entrée d’un bloc de couches. Au lieu d’apprendre directement la transformation souhaitée \(\mathcal{H}(\mathbf{x})\), un bloc résiduel apprend le résidu \(\mathcal{F}(\mathbf{x}) = \mathcal{H}(\mathbf{x}) - \mathbf{x}\) :
où \(\mathcal{F}\) représente typiquement deux couches de convolution avec batch normalization et ReLU :
La connexion \(+ \, \mathbf{x}\) est appelée skip connection ou shortcut.
Proposition 60 (Propagation du gradient dans ResNet)
Dans un bloc résiduel \(\mathbf{y} = \mathcal{F}(\mathbf{x}) + \mathbf{x}\), le gradient de la perte \(\mathcal{L}\) par rapport à \(\mathbf{x}\) est :
Le terme \(+ \mathbf{I}\) (matrice identité) garantit que le gradient ne s’annule jamais complètement, même si \(\frac{\partial \mathcal{F}}{\partial \mathbf{x}}\) est petit. C’est le mécanisme clé qui permet d’entraîner des réseaux de plus de 100 couches.
Entrée : torch.Size([1, 64, 16, 16]) → Sortie : torch.Size([1, 64, 16, 16])
Paramètres du bloc : 74,112
Batch normalization dans les CNN#
La batch normalization (Ioffe & Szegedy, 2015) normalise les activations à l’intérieur de chaque mini-batch, stabilisant et accélérant l’entraînement.
Définition 240 (Batch normalization pour les convolutions)
Pour une carte de caractéristiques \(\mathbf{X} \in \mathbb{R}^{N \times C \times H \times W}\) (batch × canaux × hauteur × largeur), la batch normalization calcule, pour chaque canal \(c\) :
où \(\mu_c\) et \(\sigma_c^2\) sont la moyenne et la variance calculées sur les dimensions \((N, H, W)\) pour le canal \(c\). Des paramètres apprenables \(\gamma_c\) et \(\beta_c\) permettent ensuite une transformation affine :
Convolutions 1×1#
Les convolutions 1×1, popularisées par le réseau Network in Network (Lin et al., 2013) et abondamment utilisées dans GoogLeNet/Inception, sont un outil puissant pour manipuler le nombre de canaux.
Remarque 200
Une convolution \(1 \times 1\) avec \(C_{\text{in}}\) canaux en entrée et \(C_{\text{out}}\) canaux en sortie agit comme une couche FC appliquée indépendamment à chaque position spatiale. Ses usages principaux sont :
Réduction de dimension : réduire le nombre de canaux avant une convolution coûteuse (\(C_{\text{out}} < C_{\text{in}}\)).
Augmentation de dimension : ajouter de la capacité (\(C_{\text{out}} > C_{\text{in}}\)).
Combinaison inter-canaux : mélanger l’information entre les canaux sans modifier la résolution spatiale.
Conv 3×3 directe (256→64) : 147,520 paramètres
Conv 1×1 + Conv 3×3 (256→64→64) : 53,376 paramètres
Réduction : 63.8%
Transfer learning#
Motivation#
Entraîner un CNN de zéro requiert d’immenses jeux de données et des ressources computationnelles considérables. Le transfer learning (apprentissage par transfert) contourne ce problème en réutilisant un réseau pré-entraîné sur un grand jeu de données (typiquement ImageNet, 1.2 million d’images, 1000 classes) comme point de départ pour une nouvelle tâche.
Définition 241 (Transfer learning)
Le transfer learning consiste à transférer les connaissances apprises par un modèle sur une tâche source \(\mathcal{T}_S\) vers une tâche cible \(\mathcal{T}_T\) différente. Pour les CNN, cela repose sur l’observation que les premières couches apprennent des caractéristiques génériques (bords, textures, couleurs) transférables entre tâches, tandis que les couches profondes apprennent des caractéristiques spécifiques à la tâche.
Deux stratégies principales :
Feature extraction : les poids du réseau pré-entraîné sont gelés ; seule la couche de classification finale est remplacée et entraînée.
Fine-tuning : tout ou partie du réseau pré-entraîné est ré-entraîné avec un taux d’apprentissage faible, en plus de la nouvelle couche de classification.
Remarque 201
Quand utiliser le transfer learning ?
Peu de données, tâche similaire → Feature extraction. Les features pré-entraînées sont déjà pertinentes.
Beaucoup de données, tâche similaire → Fine-tuning de l’ensemble du réseau.
Peu de données, tâche très différente → Feature extraction sur les couches basses uniquement.
Beaucoup de données, tâche très différente → Entraînement de zéro, ou fine-tuning profond.
En pratique, le transfer learning est presque toujours bénéfique, même pour des tâches éloignées d’ImageNet.
Dernière couche (originale) :
Linear(in_features=512, out_features=1000, bias=True)
Paramètres FC : 512 × 1000 = 512,000
Dernière couche (adaptée) :
Linear(in_features=512, out_features=10, bias=True)
Paramètres totaux : 11,181,642
Paramètres entraînables (feature extraction) : 5,130
Pourcentage entraînable : 0.05%
Implémentation complète en PyTorch#
Mettons en pratique toutes les notions vues dans ce chapitre en construisant, entraînant et évaluant un CNN sur le jeu de données FashionMNIST.
Chargement des données#
Entraînement : 5000 images
Test : 1000 images
Taille des images : torch.Size([1, 28, 28])

Construction du CNN#
Paramètres totaux : 871,530
Paramètres entraînables : 871,530
Entrée : torch.Size([1, 1, 28, 28]) → Sortie : torch.Size([1, 10])
Remarque 202
Notre CNN contient environ 730 000 paramètres — bien moins qu’un MLP avec une seule couche cachée de 1000 neurones appliqué aux mêmes images (\(784 \times 1000 + 1000 \times 10 = 794\,000\)), tout en étant beaucoup plus performant grâce à l’exploitation de la structure spatiale.
Entraînement#
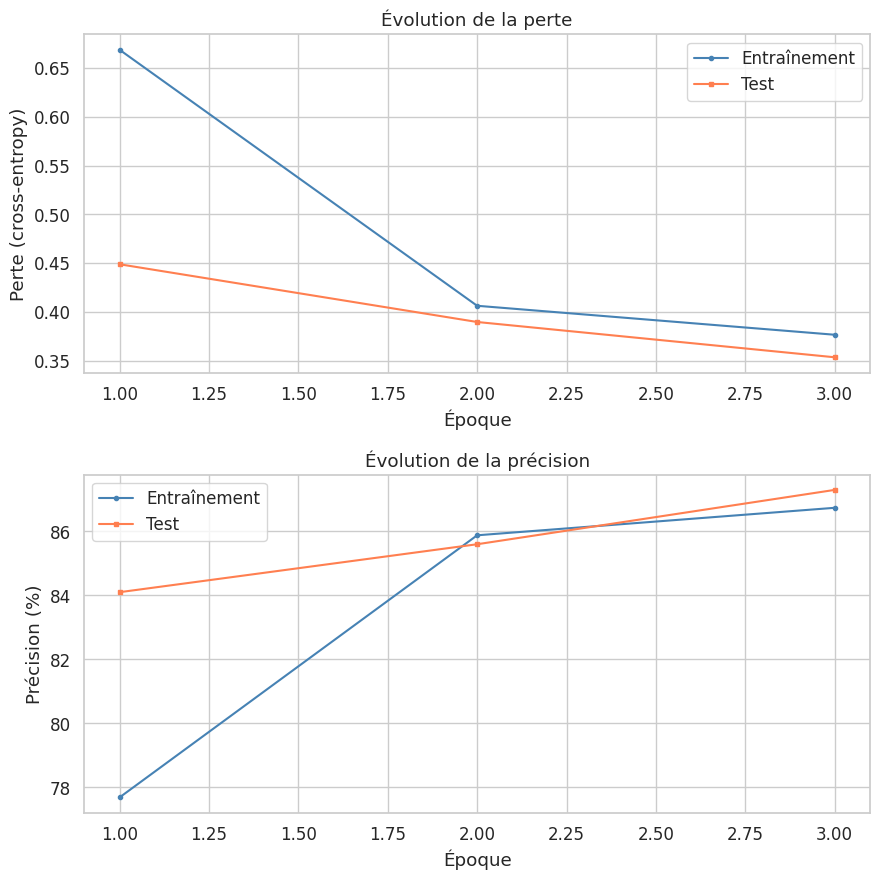
Époque 1/3 | Train: loss=0.6687, acc=77.7% | Test: loss=0.4487, acc=84.1%
Époque 2/3 | Train: loss=0.4062, acc=85.9% | Test: loss=0.3895, acc=85.6%
Époque 3/3 | Train: loss=0.3765, acc=86.7% | Test: loss=0.3533, acc=87.3%
Meilleure précision test : 87.3%
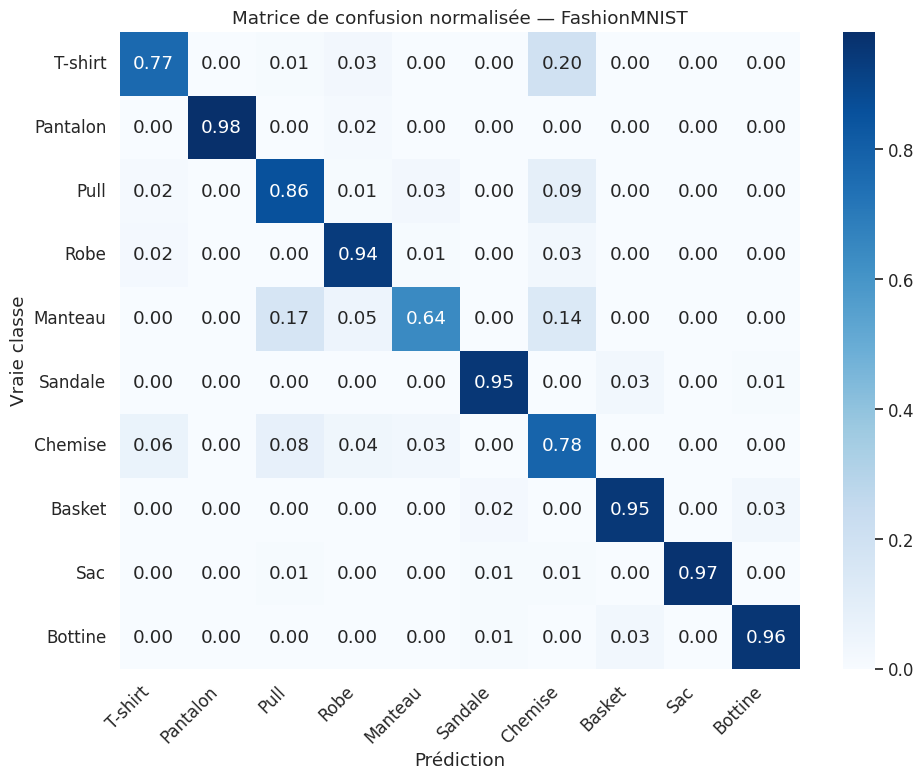
Évaluation détaillée#
precision recall f1-score support
T-shirt 0.891 0.766 0.824 107
Pantalon 1.000 0.981 0.990 105
Pull 0.766 0.856 0.809 111
Robe 0.845 0.935 0.888 93
Manteau 0.914 0.643 0.755 115
Sandale 0.954 0.954 0.954 87
Chemise 0.598 0.784 0.679 97
Basket 0.938 0.947 0.942 95
Sac 1.000 0.968 0.984 95
Bottine 0.958 0.958 0.958 95
accuracy 0.873 1000
macro avg 0.886 0.879 0.878 1000
weighted avg 0.885 0.873 0.874 1000
Visualisation des filtres appris#
L’un des avantages des CNN est l’interprétabilité partielle des premières couches. Les filtres de la première couche de convolution agissent directement sur les pixels et peuvent être visualisés.
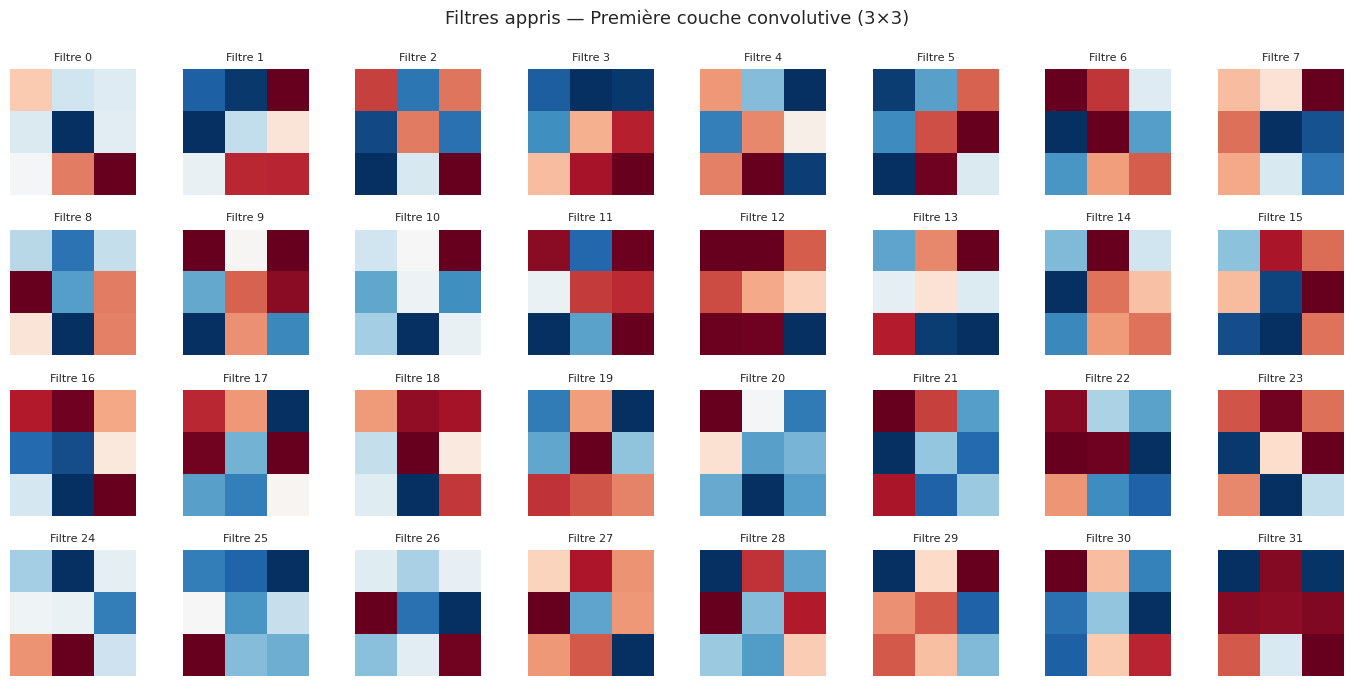
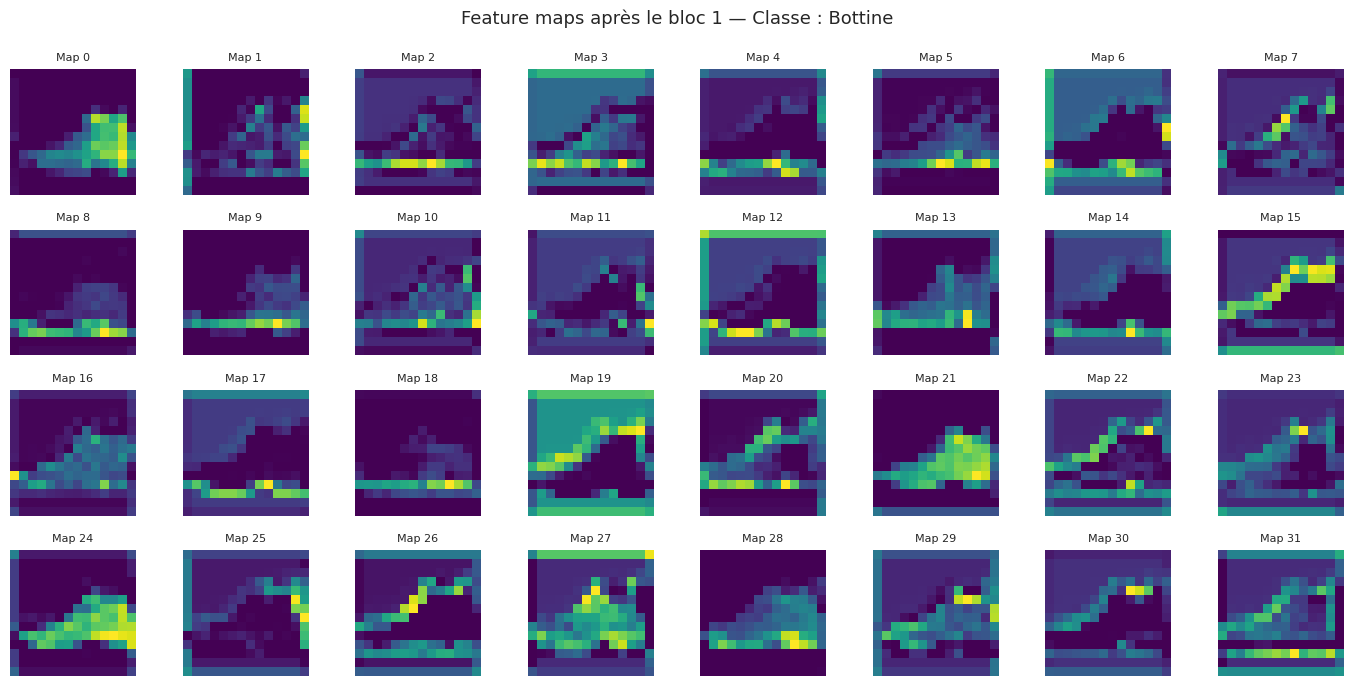
Remarque 203
On observe que les filtres de la première couche ont appris à détecter des motifs simples : bords horizontaux, verticaux, diagonaux, et des détecteurs de gradient. Les feature maps correspondantes montrent clairement les contours et les textures de l’image d’entrée. Les couches plus profondes (non visualisées ici) combinent ces caractéristiques bas niveau en représentations de plus en plus abstraites et sémantiques.
Visualisation de prédictions#

Résumé#
Ce chapitre a présenté les réseaux de neurones convolutifs, de leurs fondements théoriques à leur implémentation pratique.
Remarque 204
Points clés à retenir :
L’opération de convolution exploite la structure spatiale des images grâce à la connectivité locale et au partage de poids, réduisant drastiquement le nombre de paramètres par rapport aux couches entièrement connectées.
Le pooling réduit les dimensions spatiales et introduit une invariance locale par translation.
L’empilement de petits noyaux (\(3 \times 3\)) est préférable à un grand noyau unique : moins de paramètres, plus de non-linéarités, champ réceptif équivalent.
Les connexions résiduelles (ResNet) permettent d’entraîner des réseaux très profonds en assurant un flux de gradient efficace.
La batch normalization stabilise et accélère l’entraînement en normalisant les activations intermédiaires.
Le transfer learning permet d’obtenir d’excellentes performances avec peu de données en réutilisant des modèles pré-entraînés.
Le chapitre suivant étendra ces idées aux données séquentielles avec les réseaux récurrents (RNN).