
Réseaux antagonistes génératifs (GAN)#
Toute création est d’abord un acte de destruction.
— Pablo Picasso, Propos sur l’art
Le chapitre précédent a présenté les auto-encodeurs variationnels (VAE), un modèle génératif fondé sur l’inférence variationnelle et un encodeur-décodeur probabiliste. Les VAE optimisent une borne inférieure de la vraisemblance (ELBO) et produisent des échantillons en décodant des vecteurs latents tirés d’une distribution gaussienne. Si cette approche offre un cadre mathématique élégant, les images générées sont souvent floues en raison de la perte de reconstruction \(L^2\). Ce chapitre introduit une approche radicalement différente de la modélisation générative : les réseaux antagonistes génératifs (Generative Adversarial Networks, GAN), proposés par Ian Goodfellow et al. en 2014. L’idée fondatrice est d’entraîner simultanément deux réseaux — un générateur qui produit des données synthétiques et un discriminateur qui tente de distinguer les données réelles des données générées — dans un jeu à somme nulle inspiré de la théorie des jeux. Cette dynamique adversariale pousse le générateur à produire des échantillons de plus en plus réalistes, sans jamais nécessiter de reconstruction explicite.
Périphérique utilisé : cpu
Introduction : modèles génératifs et apprentissage adversarial#
Rappel : le cadre génératif#
En apprentissage automatique, on distingue deux grandes familles de modèles. Les modèles discriminatifs apprennent la distribution conditionnelle \(p(y \mid \mathbf{x})\) pour classifier ou régresser. Les modèles génératifs, en revanche, apprennent la distribution des données \(p_{\text{data}}(\mathbf{x})\) elle-même, ce qui permet de générer de nouveaux échantillons ressemblant aux données d’entraînement.
Définition 259 (Modèle génératif)
Un modèle génératif est un modèle statistique qui apprend la distribution \(p_{\text{data}}(\mathbf{x})\) des données d’entraînement \(\mathbf{x} \in \mathbb{R}^d\). Une fois entraîné, il permet de :
Échantillonner de nouveaux points \(\mathbf{x}_{\text{new}} \sim p_{\text{model}}(\mathbf{x})\).
Évaluer la vraisemblance (ou une approximation) d’un point donné.
Les principales approches sont :
Modèles à variable latente : VAE, modèles de diffusion.
Modèles autorégressifs : PixelCNN, GPT.
Modèles adversariaux : GAN et ses variantes.
Du VAE au GAN : une autre philosophie#
Les VAE définissent explicitement un modèle probabiliste \(p_\theta(\mathbf{x} \mid \mathbf{z})\) et optimisent l’ELBO. Les GAN adoptent une stratégie radicalement différente : le générateur apprend une transformation déterministe \(G(\mathbf{z})\) d’un bruit aléatoire \(\mathbf{z}\) vers l’espace des données, sans jamais définir explicitement la densité \(p_{\text{model}}(\mathbf{x})\). La qualité des échantillons est jugée par un réseau adversaire — le discriminateur — et non par une fonction de perte de reconstruction.
Remarque 227
VAE vs GAN — Le VAE fournit une densité explicite et un encodeur permettant l’inférence, mais produit des images floues. Le GAN ne fournit ni densité explicite ni encodeur, mais génère des images nettement plus nettes. Ces deux approches sont complémentaires et peuvent être combinées (VAE-GAN, par exemple).
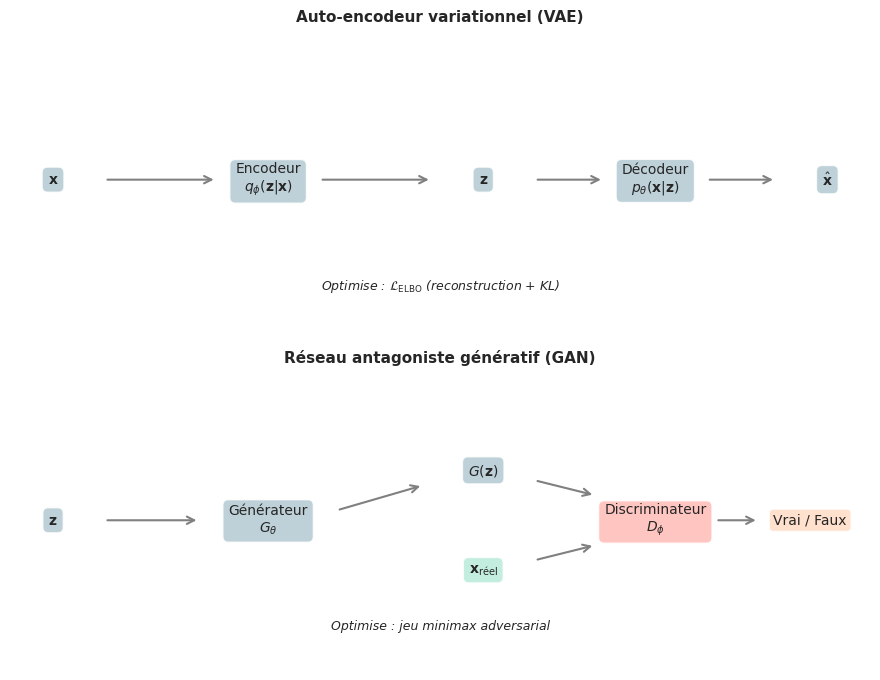
Architecture GAN#
Générateur et discriminateur#
Un GAN est composé de deux réseaux de neurones entraînés simultanément :
Le générateur \(G_\theta : \mathbb{R}^{n_z} \to \mathbb{R}^d\) transforme un vecteur de bruit latent \(\mathbf{z} \sim p_z(\mathbf{z})\) (typiquement \(\mathcal{N}(\mathbf{0}, \mathbf{I})\)) en un échantillon synthétique \(G(\mathbf{z})\) de même dimension que les données réelles.
Le discriminateur \(D_\phi : \mathbb{R}^d \to [0, 1]\) reçoit un point \(\mathbf{x}\) et produit la probabilité que \(\mathbf{x}\) provienne des données réelles plutôt que du générateur.
L’analogie classique est celle du faussaire et de l”expert en art : le générateur tente de produire de faux tableaux indiscernables des originaux, tandis que le discriminateur tente de détecter les contrefaçons.
Définition 260 (Réseau antagoniste génératif (GAN))
Un réseau antagoniste génératif est défini par le jeu minimax suivant :
où \(V(D, G)\) est la fonction de valeur du jeu. Le discriminateur \(D\) cherche à maximiser \(V\) (classifier correctement réels et faux), tandis que le générateur \(G\) cherche à minimiser \(V\) (tromper le discriminateur).
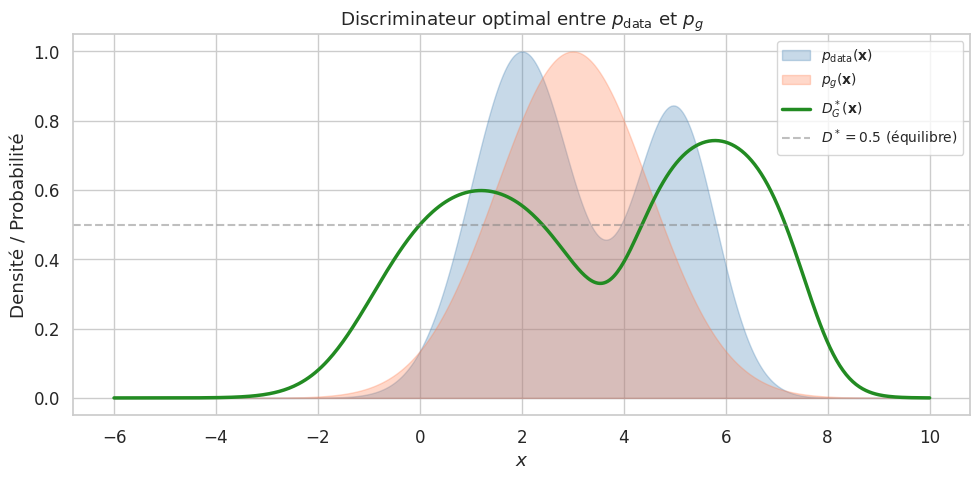
Discriminateur optimal#
Pour un générateur \(G\) fixé, on peut calculer analytiquement le discriminateur optimal.
Théorème 3 (Discriminateur optimal)
Pour un générateur \(G\) fixé, le discriminateur optimal \(D^*_G\) est donné par :
où \(p_g\) est la distribution implicite induite par \(G(\mathbf{z})\) lorsque \(\mathbf{z} \sim p_z\).
Preuve (esquisse) : Pour un \(\mathbf{x}\) fixé, la fonction à maximiser par rapport à \(D(\mathbf{x})\) est \(f(d) = a \log d + b \log(1-d)\) avec \(a = p_{\text{data}}(\mathbf{x})\) et \(b = p_g(\mathbf{x})\). La dérivée s’annule en \(d = \frac{a}{a+b}\).
Équilibre de Nash et divergence de Jensen-Shannon#
En substituant le discriminateur optimal dans la fonction de valeur, on obtient une expression qui fait apparaître la divergence de Jensen-Shannon entre \(p_{\text{data}}\) et \(p_g\).
Théorème 4 (Convergence du GAN)
Lorsque le discriminateur est optimal, la fonction de valeur du GAN se réécrit :
où \(D_{\text{JS}}\) est la divergence de Jensen-Shannon. Le minimum global est atteint si et seulement si \(p_g = p_{\text{data}}\), auquel cas \(D_{\text{JS}} = 0\) et \(D^*(\mathbf{x}) = \frac{1}{2}\) partout.
Entraînement d’un GAN#
Algorithme d’entraînement#
L’entraînement d’un GAN alterne entre la mise à jour du discriminateur et celle du générateur. En pratique, on effectue \(k\) pas de gradient sur \(D\) pour chaque pas sur \(G\) (Goodfellow et al. recommandent \(k = 1\)).
Définition 261 (Algorithme d’entraînement GAN)
Pour chaque itération d’entraînement :
1. Mise à jour du discriminateur (monter le gradient de \(V\)) :
Échantillonner un mini-batch \(\{\mathbf{x}^{(1)}, \ldots, \mathbf{x}^{(m)}\}\) de données réelles.
Échantillonner un mini-batch \(\{\mathbf{z}^{(1)}, \ldots, \mathbf{z}^{(m)}\}\) de bruit \(\mathbf{z} \sim p_z\).
Mettre à jour \(\phi\) par montée de gradient :
2. Mise à jour du générateur (descendre le gradient de \(V\)) :
Échantillonner un mini-batch \(\{\mathbf{z}^{(1)}, \ldots, \mathbf{z}^{(m)}\}\) de bruit.
Mettre à jour \(\theta\) par descente de gradient :
Remarque 228
Astuce pratique — En début d’entraînement, \(D\) rejette facilement les sorties de \(G\), donc \(\log(1 - D(G(\mathbf{z})))\) est proche de \(0\) et le gradient pour \(G\) est très faible. Une astuce courante est de remplacer la perte du générateur par \(-\log D(G(\mathbf{z}))\), qui fournit des gradients plus forts lorsque \(D(G(\mathbf{z}))\) est petit. On appelle cela le non-saturating GAN loss.
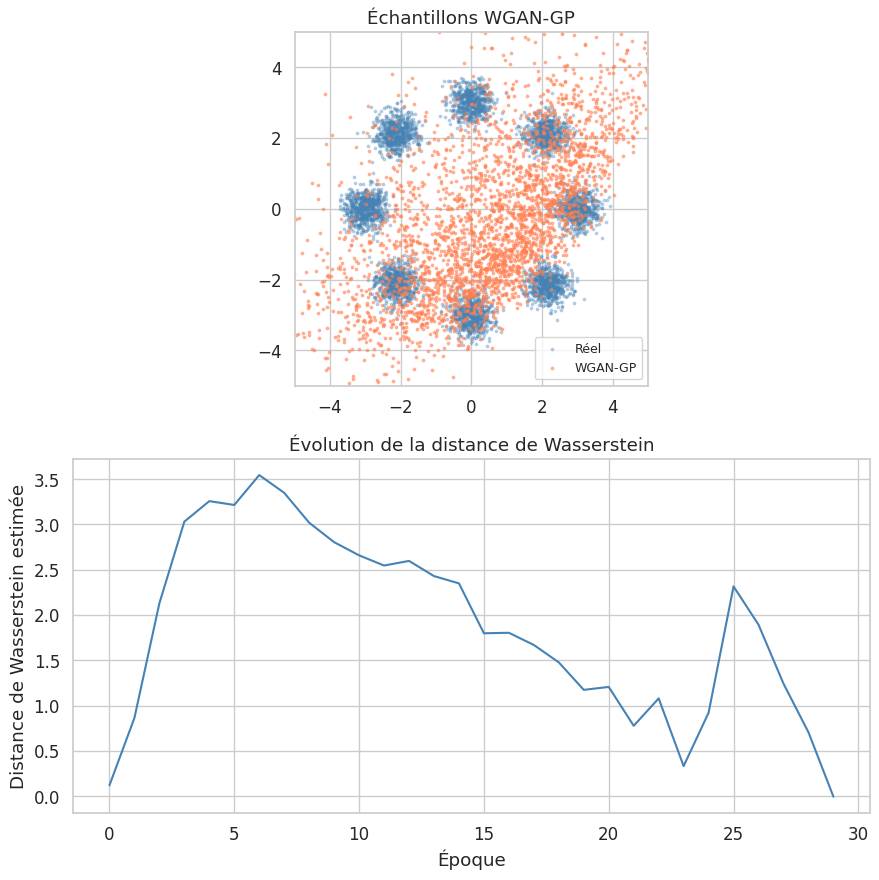
Implémentation : GAN sur un mélange de gaussiennes 2D#
Pour illustrer le fonctionnement d’un GAN, commençons par un exemple simple : apprendre un mélange de gaussiennes en 2D.
Entraînement terminé.
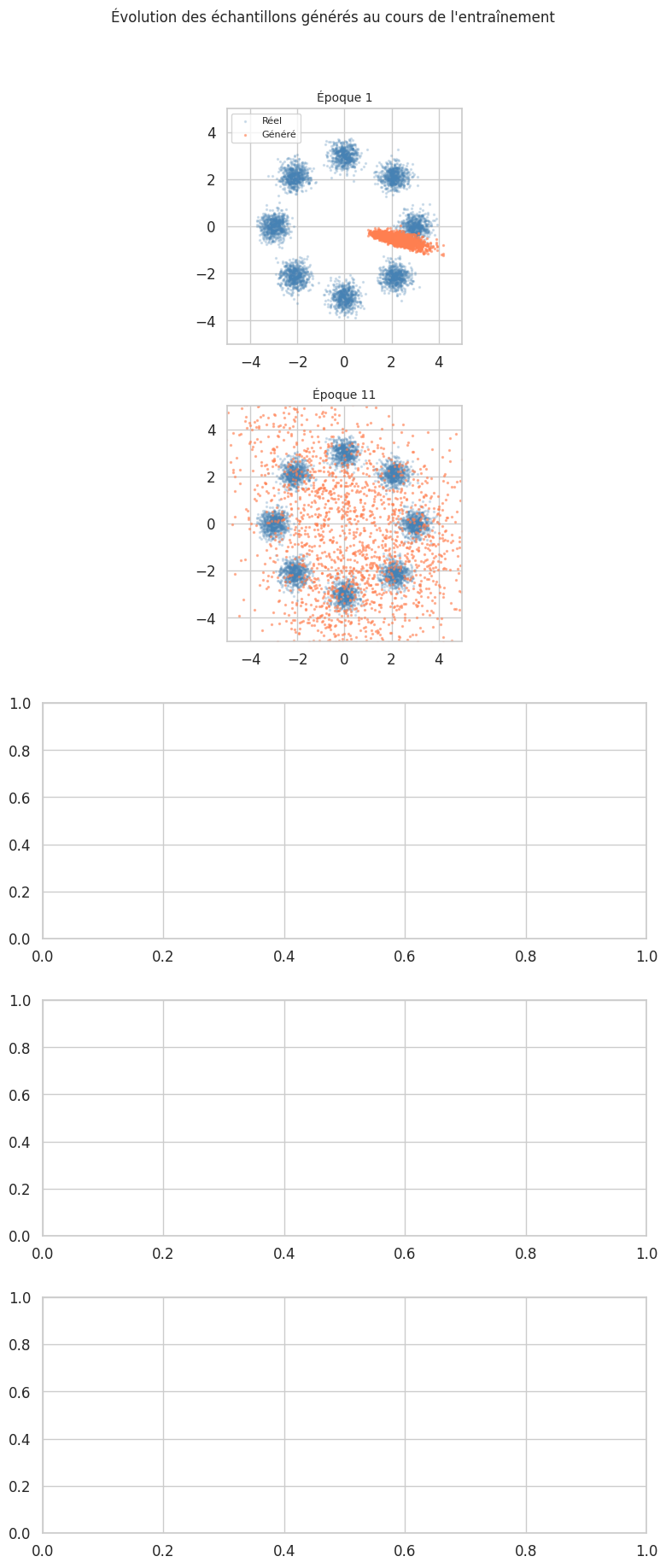
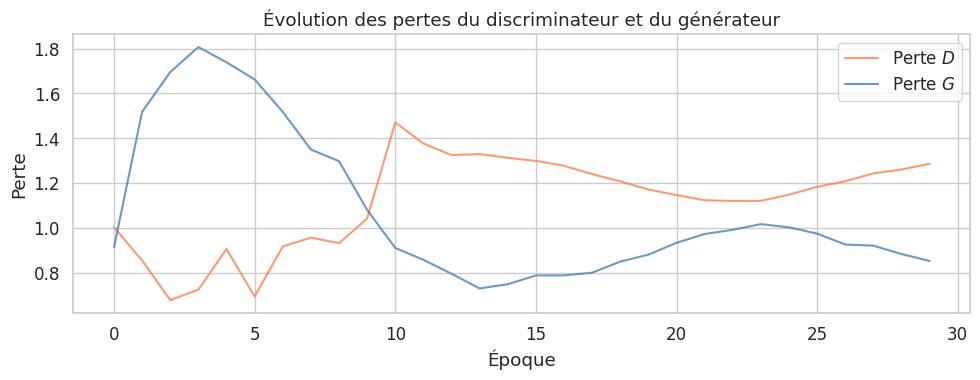
On observe que le générateur apprend progressivement la structure en anneau du mélange de gaussiennes. Les premières époques produisent des points concentrés autour de l’origine, puis la distribution s’étale pour couvrir les 8 modes.
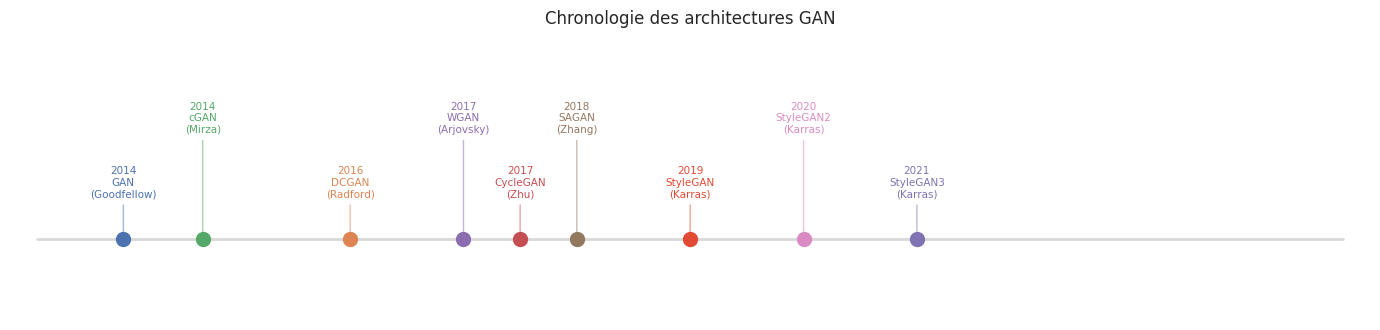
DCGAN : GAN convolutif profond#
Principes architecturaux#
Le DCGAN (Deep Convolutional GAN), proposé par Radford et al. en 2016, est un ensemble de directives architecturales qui stabilisent l’entraînement des GAN sur des images. Ces directives sont devenues des pratiques standard.
Définition 262 (Directives architecturales DCGAN)
Les principales recommandations du DCGAN sont :
Remplacer les couches de pooling par des convolutions à pas (strided convolutions) dans le discriminateur et des convolutions transposées (transposed convolutions) dans le générateur.
Utiliser la normalisation par batch (batch normalization) dans les deux réseaux, sauf dans la couche de sortie du générateur et la couche d’entrée du discriminateur.
Supprimer les couches entièrement connectées dans les architectures profondes.
Utiliser ReLU dans le générateur (sauf la sortie : \(\tanh\)) et LeakyReLU dans le discriminateur.
Exemple 26 (Architecture DCGAN pour images 28x28 (MNIST))
Générateur (vecteur latent \(\mathbf{z} \in \mathbb{R}^{100} \to\) image \(1 \times 28 \times 28\)) :
Linéaire : \(100 \to 256 \times 7 \times 7\) puis reshape
ConvTranspose2d : \(256 \to 128\), noyau \(4 \times 4\), stride \(2\), padding \(1\) + BatchNorm + ReLU
ConvTranspose2d : \(128 \to 1\), noyau \(4 \times 4\), stride \(2\), padding \(1\) + Tanh
Discriminateur (image \(1 \times 28 \times 28 \to\) scalaire \([0, 1]\)) :
Conv2d : \(1 \to 64\), noyau \(4 \times 4\), stride \(2\), padding \(1\) + LeakyReLU(0.2)
Conv2d : \(64 \to 128\), noyau \(4 \times 4\), stride \(2\), padding \(1\) + BatchNorm + LeakyReLU(0.2)
Linéaire : \(128 \times 7 \times 7 \to 1\) + Sigmoid
Implémentation PyTorch#
Générateur : 1,818,624 paramètres
Discriminateur : 138,625 paramètres
Entraînement sur MNIST#
Époque [1/2] Loss_D: 0.5153 Loss_G: 2.8416 D(x): 0.781 D(G(z)): 0.062
Époque [2/2] Loss_D: 0.5268 Loss_G: 2.3544 D(x): 0.776 D(G(z)): 0.105

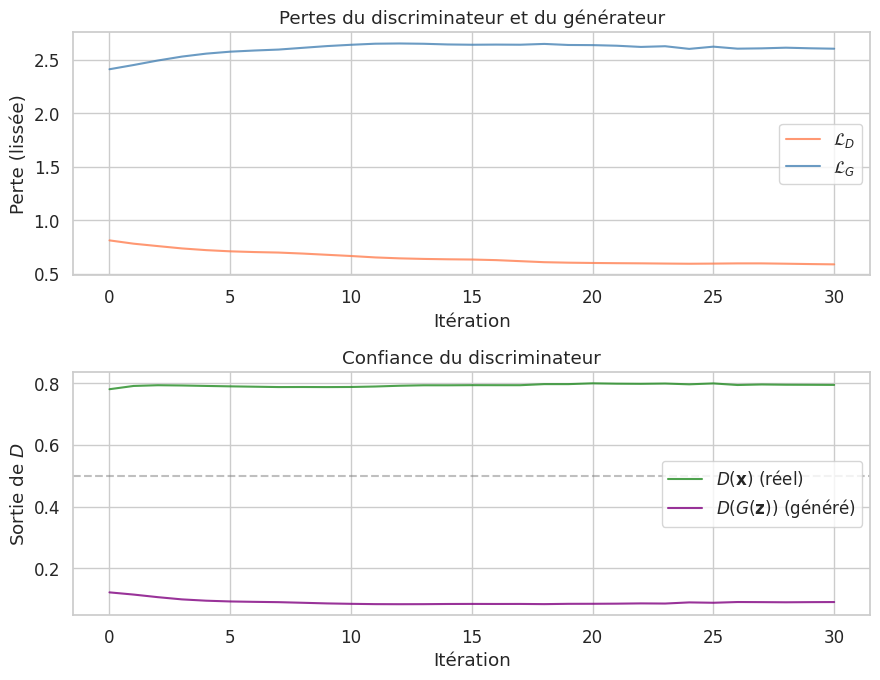

L’interpolation dans l’espace latent produit des transitions fluides entre les chiffres, ce qui suggère que le générateur a appris une représentation structurée et continue.
Problèmes de stabilité#
L’entraînement des GAN est notoirement instable. Contrairement à l’optimisation classique d’une seule fonction de perte, le GAN résout un problème d”optimisation à deux joueurs dont la convergence n’est pas garantie. Trois problèmes majeurs se posent.
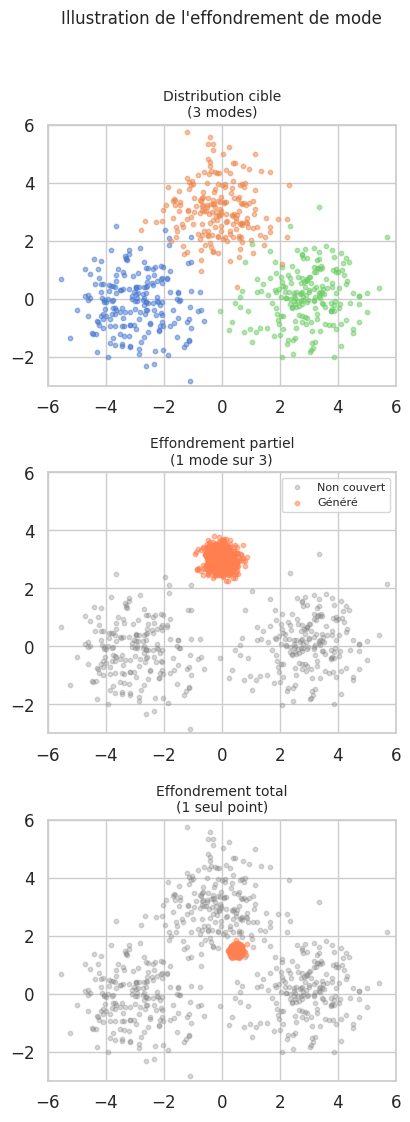
Effondrement de mode (mode collapse)#
Définition 263 (Effondrement de mode)
L”effondrement de mode (mode collapse) survient lorsque le générateur produit des échantillons concentrés sur un sous-ensemble restreint des modes de la distribution cible. Dans le cas extrême, \(G\) produit toujours la même sortie quel que soit \(\mathbf{z}\) :
Cela se produit lorsque \(G\) trouve un unique point \(\mathbf{x}^*\) qui trompe systématiquement \(D\), et exploite cette stratégie au lieu d’explorer la diversité de \(p_{\text{data}}\).
Gradient évanescent pour le générateur#
Lorsque le discriminateur est trop puissant, il classe les échantillons générés comme faux avec une confiance proche de 1. La perte du générateur \(\log(1 - D(G(\mathbf{z})))\) sature alors près de \(\log(1) = 0\), et les gradients pour \(G\) deviennent négligeables. Le générateur ne reçoit plus de signal d’apprentissage utile.
Oscillations et non-convergence#
Le GAN n’optimise pas une fonction de perte unique mais résout un jeu minimax. Dans les cas pathologiques, les mises à jour de \(G\) et \(D\) s’annulent mutuellement, conduisant à des oscillations sans convergence vers un équilibre.
Solutions et techniques de stabilisation#
Définition 264 (Techniques de stabilisation des GAN)
Plusieurs techniques ont été proposées pour améliorer la stabilité de l’entraînement :
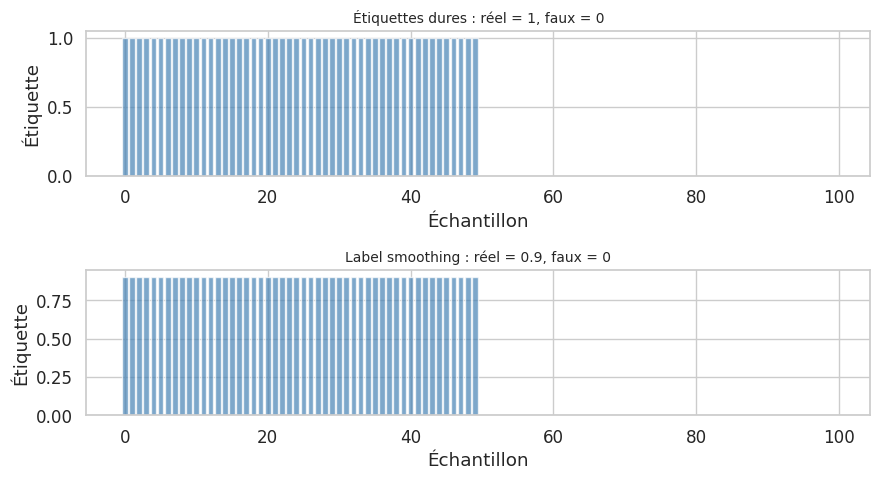
Label smoothing : remplacer les étiquettes \(1\) (réel) par des valeurs dans \([0.7, 1.0]\) pour éviter que le discriminateur soit trop confiant.
Normalisation spectrale (spectral normalization, Miyato et al., 2018) : normaliser les poids de \(D\) par leur plus grande valeur singulière, contraignant la constante de Lipschitz du discriminateur.
Croissance progressive (progressive growing, Karras et al., 2018) : entraîner le GAN à des résolutions croissantes (\(4 \times 4 \to 8 \times 8 \to \cdots \to 1024 \times 1024\)) pour stabiliser l’apprentissage de structures à grande échelle.
Entraînement à deux échelles de temps (TTUR) : utiliser un taux d’apprentissage plus élevé pour \(D\) que pour \(G\) afin de maintenir le discriminateur proche de son optimum.
Perte de gradient penalty : ajouter une pénalisation sur la norme du gradient de \(D\) (utilisée dans le WGAN-GP).
Variantes et extensions#
WGAN : distance de Wasserstein#
Le WGAN (Wasserstein GAN, Arjovsky et al., 2017) remplace la divergence de Jensen-Shannon par la distance de Wasserstein-1 (distance de Earth Mover), qui fournit un signal de gradient plus informatif même lorsque les distributions \(p_{\text{data}}\) et \(p_g\) ne se chevauchent pas.
Définition 265 (WGAN et distance de Wasserstein)
La distance de Wasserstein-1 entre deux distributions \(p\) et \(q\) est :
Par la dualité de Kantorovich-Rubinstein :
où le supremum porte sur les fonctions 1-Lipschitz. Le discriminateur devient un critique \(f_w\) (sans sigmoïde) et la contrainte de Lipschitz est imposée par :
Weight clipping (WGAN original) : \(w \leftarrow \text{clip}(w, -c, c)\)
Gradient penalty (WGAN-GP, Gulrajani et al., 2017) : \(\lambda \, \mathbb{E}_{\hat{\mathbf{x}}} \left[ (\|\nabla_{\hat{\mathbf{x}}} f_w(\hat{\mathbf{x}})\|_2 - 1)^2 \right]\)
où \(\hat{\mathbf{x}}\) est un point interpolé entre un échantillon réel et un échantillon généré.
Remarque 229
Avantages du WGAN :
La perte du critique est une estimation de la distance de Wasserstein, ce qui la rend interprétable comme mesure de qualité. Contrairement au GAN classique, une perte décroissante du critique corrèle avec une amélioration de la qualité des échantillons.
Le gradient penalty (WGAN-GP) est préféré au weight clipping car il évite les problèmes de gradients explosifs ou évanescents liés au clipping.
GAN conditionnel (cGAN)#
Le GAN conditionnel (Conditional GAN, Mirza & Osindero, 2014) introduit une information conditionnelle \(\mathbf{y}\) (par exemple une étiquette de classe) dans les deux réseaux. Cela permet de contrôler la génération.
Définition 266 (GAN conditionnel)
Dans un cGAN, le générateur et le discriminateur reçoivent tous deux l’information conditionnelle \(\mathbf{y}\) :
En pratique, \(\mathbf{y}\) est concaténé au vecteur latent \(\mathbf{z}\) pour le générateur, et à l’entrée \(\mathbf{x}\) pour le discriminateur. Pour des étiquettes discrètes, on utilise un embedding ou un vecteur one-hot.
Architecture cGAN définie.
Générateur conditionnel : 2,446,324 paramètres
Discriminateur conditionnel : 147,489 paramètres
Autres variantes notables#
Remarque 230
Panorama des variantes de GAN :
StyleGAN (Karras et al., 2019) : architecture fondée sur un réseau de mapping qui transforme \(\mathbf{z}\) en un espace de style \(\mathbf{w}\), injecté à chaque résolution via la normalisation adaptative d’instance (AdaIN). StyleGAN2 et StyleGAN3 améliorent la qualité et la cohérence spatiale des images générées.
CycleGAN (Zhu et al., 2017) : permet la traduction d’image à image non appariée (unpaired image-to-image translation). Deux générateurs \(G_{A \to B}\) et \(G_{B \to A}\) et deux discriminateurs sont entraînés avec une perte de cycle \(\|G_{B \to A}(G_{A \to B}(\mathbf{x})) - \mathbf{x}\|_1\) qui assure la cohérence.
Pix2Pix (Isola et al., 2017) : traduction d’image à image appariée, combinant une perte adversariale et une perte \(L^1\) pixel par pixel.
BigGAN (Brock et al., 2019) : mise à l’échelle des GAN conditionnels avec de grands batches, orthogonal regularization et class-conditional batch normalization pour générer des images ImageNet à haute résolution.
Applications des GAN#
Les GAN ont trouvé des applications dans de nombreux domaines, bien au-dela de la simple génération d’images.
Génération d’images réalistes#
L’application la plus emblématique : générer des images photoréalistes de visages, d’objets ou de scènes qui n’existent pas. Les modèles StyleGAN génèrent des visages indiscernables de photographies réelles.
Super-résolution#
Le SRGAN (Super-Resolution GAN, Ledig et al., 2017) et son successeur ESRGAN augmentent la résolution d’une image basse résolution. Le discriminateur force le générateur à produire des détails haute fréquence réalistes, là où les méthodes \(L^2\) classiques produisent des résultats flous.
Transfert de style et traduction d’images#
CycleGAN permet des transformations spectaculaires : photo \(\leftrightarrow\) peinture, cheval \(\leftrightarrow\) zèbre, été \(\leftrightarrow\) hiver. Pix2Pix traduit des croquis en images réalistes, des cartes en photos aériennes, etc.
Augmentation de données#
Les GAN peuvent générer des données synthétiques pour enrichir un jeu d’entraînement, particulièrement utile dans les domaines où les données annotées sont rares (imagerie médicale, détection de défauts industriels).
Exemple 27 (Applications des GAN par domaine)
Domaine |
Application |
Architecture |
|---|---|---|
Vision par ordinateur |
Génération de visages |
StyleGAN |
Imagerie médicale |
Augmentation de données |
cGAN, Pix2Pix |
Super-résolution |
Amélioration d’images |
SRGAN, ESRGAN |
Art et design |
Transfert de style |
CycleGAN |
Texte → Image |
Génération depuis description |
StackGAN, AttnGAN |
Vidéo |
Prédiction de trames |
MoCoGAN |
Audio |
Synthèse vocale |
WaveGAN, MelGAN |
Sciences |
Simulation physique |
Physics-informed GAN |

Remarque 231
Métriques d’évaluation des GAN — L’évaluation des GAN est un problème ouvert. Deux métriques sont largement utilisées :
Le FID (Fréchet Inception Distance) mesure la distance entre les distributions des features extraites par un réseau Inception pré-entraîné pour les images réelles et générées. Un FID plus bas indique une meilleure qualité.
L”IS (Inception Score) mesure à la fois la qualité (les images générées sont-elles classifiables ?) et la diversité (la distribution des classes est-elle uniforme ?).
Ces deux métriques reposent sur un réseau pré-entraîné et présentent des biais connus, mais elles restent les standards de facto pour comparer les modèles génératifs.
Résumé#
Ce chapitre a présenté les réseaux antagonistes génératifs (GAN), une famille de modèles génératifs fondée sur l’apprentissage adversarial.
Un GAN est composé d’un générateur \(G\) qui transforme du bruit en données synthétiques et d’un discriminateur \(D\) qui distingue le vrai du faux. Les deux réseaux sont entraînés dans un jeu minimax dont l’équilibre de Nash correspond à \(p_g = p_{\text{data}}\).
Le discriminateur optimal est \(D^*(\mathbf{x}) = \frac{p_{\text{data}}(\mathbf{x})}{p_{\text{data}}(\mathbf{x}) + p_g(\mathbf{x})}\) et la fonction de valeur à l’équilibre est liée à la divergence de Jensen-Shannon entre les deux distributions.
Le DCGAN introduit des directives architecturales (convolutions transposées, batch normalization, LeakyReLU) qui stabilisent l’entraînement sur des images et produisent des résultats de qualité avec des architectures relativement simples.
L’entraînement des GAN souffre de problèmes majeurs : effondrement de mode, gradients évanescents pour le générateur et oscillations. Des techniques comme le label smoothing, la normalisation spectrale et la croissance progressive permettent de les atténuer.
Le WGAN remplace la divergence de Jensen-Shannon par la distance de Wasserstein, fournissant un signal de gradient plus stable et une perte corrélée à la qualité des échantillons. Le WGAN-GP impose la contrainte de Lipschitz par pénalisation du gradient.
Le GAN conditionnel (cGAN) permet de contrôler la génération en conditionnant les deux réseaux sur une information auxiliaire (classe, texte, image).
Les applications des GAN couvrent la génération d’images, la super-résolution, le transfert de style, l’augmentation de données et bien d’autres domaines.
Remarque 232
Les GAN ont été les modèles génératifs dominants entre 2014 et 2020, produisant des images d’un réalisme sans précédent. Cependant, les modèles de diffusion (diffusion models), introduits par Sohl-Dickstein et al. (2015) et popularisés par Ho et al. (2020), les ont progressivement supplantés pour la génération d’images, grâce à une stabilité d’entraînement supérieure et une meilleure couverture des modes. Les GAN restent néanmoins pertinents pour des applications nécessitant une génération rapide (inférence en un seul passage) et continuent d’inspirer de nouvelles architectures hybrides combinant les avantages des deux approches.