
Réseaux récurrents#
La mémoire est le journal intime que nous portons tous avec nous.
— Oscar Wilde, L’Importance d’être Constant
Les chapitres précédents ont présenté les réseaux de neurones feedforward et les réseaux convolutifs, conçus pour traiter des entrées de taille fixe. Or, de nombreuses données du monde réel sont séquentielles : le texte est une suite de mots, la parole une suite de trames acoustiques, une vidéo une suite d’images, un signal financier une suite de cotations. Dans ces données, l”ordre compte et des dépendances temporelles relient les observations entre elles. Ce chapitre introduit les réseaux de neurones récurrents (Recurrent Neural Networks, RNN), une famille d’architectures spécialement conçues pour modéliser ces séquences. Nous étudierons le RNN simple (Elman), ses limites liées au gradient évanescent, puis les architectures à portes — LSTM et GRU — qui ont permis aux réseaux récurrents de devenir l’outil dominant du traitement des séquences pendant une décennie, avant l’avènement des Transformers.
Introduction : données séquentielles#
Pourquoi les réseaux feedforward ne suffisent pas#
Un réseau feedforward classique traite chaque entrée indépendamment des autres. Si l’on souhaite prédire le mot suivant dans une phrase, un réseau feedforward devrait recevoir un contexte de taille fixe — par exemple les cinq derniers mots — et ne pourrait exploiter un historique plus lointain qu’en augmentant la taille de sa fenêtre, ce qui fait exploser le nombre de paramètres. Plus fondamentalement, un tel réseau ne partage pas les connaissances apprises à une position de la séquence avec les autres positions.
Définition 242 (Séquence et dépendance temporelle)
Une séquence est une suite ordonnée d’observations \(\mathbf{x} = (x_1, x_2, \ldots, x_T)\) où \(T\) est la longueur de la séquence. On parle de dépendance temporelle lorsque la distribution de \(x_t\) dépend des observations passées \(x_1, \ldots, x_{t-1}\) :
Le défi central du traitement des séquences est de modéliser ces dépendances, y compris celles à longue portée (long-range dependencies).
Exemple 23 (Exemples de données séquentielles)
Texte : une phrase est une séquence de mots ou de caractères, où chaque mot dépend du contexte.
Séries temporelles : cours boursiers, données météorologiques, capteurs IoT.
Audio : un signal sonore est une séquence d’échantillons ou de trames spectrales (MFCC).
Vidéo : une séquence d’images (frames) ordonnées dans le temps.
ADN : une séquence de nucléotides (A, T, C, G).
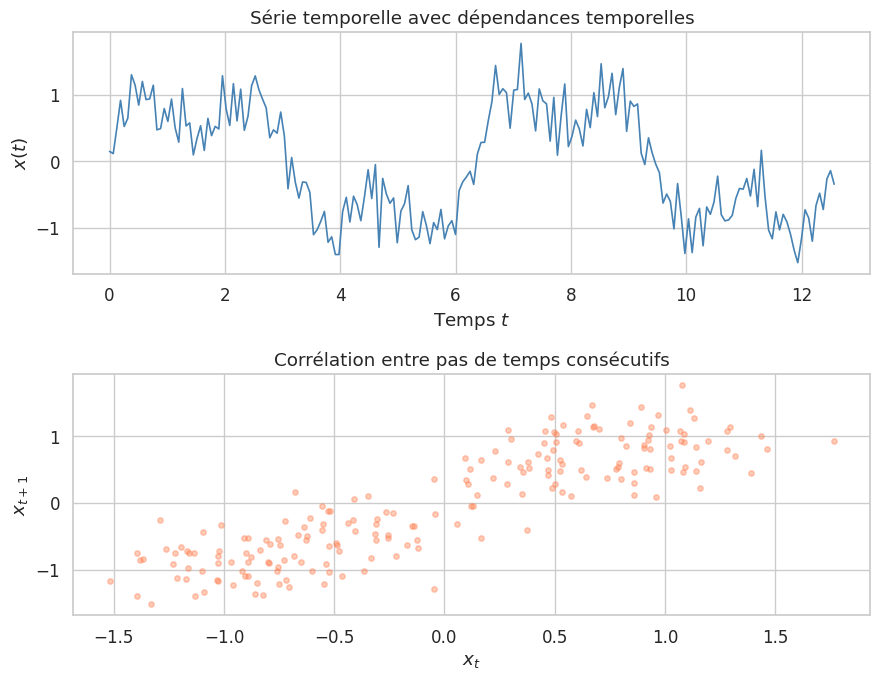
L’idée fondatrice des RNN est d’introduire un état caché (hidden state) qui agit comme une mémoire interne, mise à jour à chaque pas de temps et transmise d’un instant au suivant.
RNN simple (Elman)#
Architecture récurrente#
Le réseau récurrent simple, proposé par Jeffrey Elman en 1990, introduit une connexion récurrente : l’état caché au temps \(t\) dépend à la fois de l’entrée courante et de l’état caché au temps précédent.
Définition 243 (Réseau récurrent simple (Elman))
Un RNN simple (ou cellule d’Elman) est défini par les équations suivantes, pour \(t = 1, \ldots, T\) :
où :
\(x_t \in \mathbb{R}^d\) est l’entrée au temps \(t\),
\(h_t \in \mathbb{R}^n\) est l”état caché (hidden state) au temps \(t\),
\(W_{xh} \in \mathbb{R}^{n \times d}\), \(W_{hh} \in \mathbb{R}^{n \times n}\), \(W_{hy} \in \mathbb{R}^{m \times n}\) sont les matrices de poids,
\(b_h \in \mathbb{R}^n\), \(b_y \in \mathbb{R}^m\) sont les biais,
\(h_0\) est l’état initial, souvent fixé à \(\mathbf{0}\).
Le même jeu de poids \((W_{xh}, W_{hh}, W_{hy}, b_h, b_y)\) est partagé à travers tous les pas de temps : c’est le partage des poids temporel.
Remarque 205
Le partage des poids est crucial : il permet au réseau de traiter des séquences de longueur variable avec un nombre fixe de paramètres, et il force le réseau à apprendre des transformations invariantes par translation temporelle. C’est l’analogue temporel du partage des poids spatiaux dans les CNN.
Dépliement dans le temps (unrolling)#
Pour comprendre le fonctionnement d’un RNN, on le déplie dans le temps : on représente la cellule récurrente comme une chaîne de \(T\) copies identiques, chacune passant son état caché à la suivante. Le réseau déplié est un graphe de calcul acyclique sur lequel on peut appliquer la rétropropagation classique.
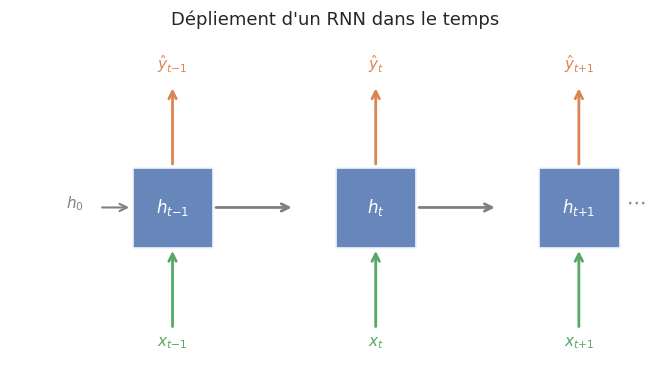
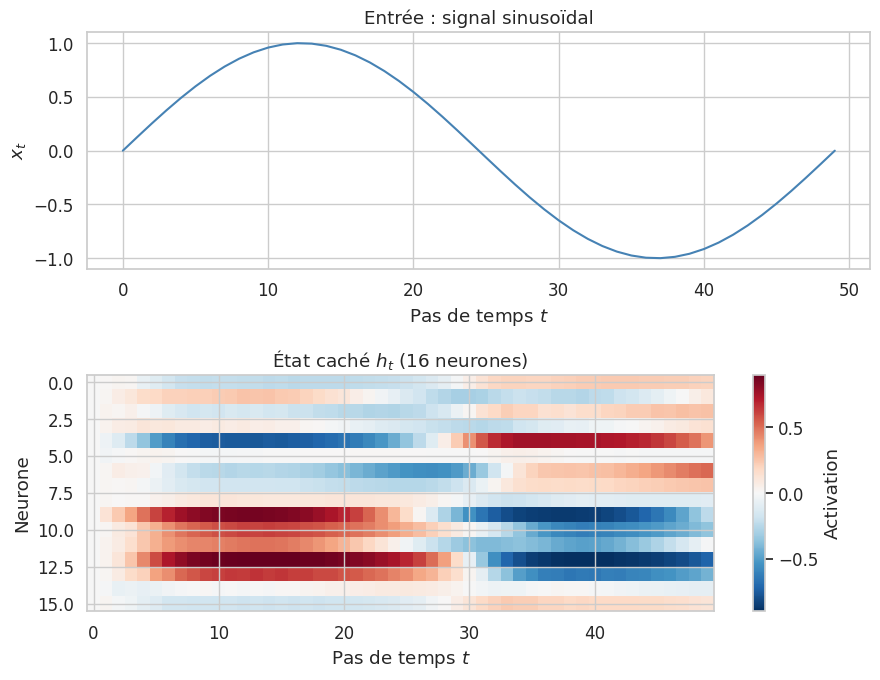
Implémentation d’une cellule RNN à la main#
Backpropagation Through Time (BPTT)#
L’entraînement d’un RNN utilise une extension de la rétropropagation classique au graphe déplié dans le temps, appelée Backpropagation Through Time (BPTT).
Définition 244 (Backpropagation Through Time)
Soit \(\mathcal{L} = \sum_{t=1}^T \mathcal{L}_t\) la perte totale sur une séquence. Le gradient par rapport à \(W_{hh}\) s’écrit, par application de la règle de chaîne au graphe déplié :
Le terme \(\prod_{j=k+1}^{t} \frac{\partial h_j}{\partial h_{j-1}}\) est un produit de matrices jacobiennes qui détermine comment le gradient se propage sur \(t - k\) pas de temps.
Problème du gradient évanescent et explosif#
Le produit de matrices jacobiennes dans la formule BPTT est la source d’une instabilité fondamentale des RNN.
Proposition 61 (Gradient évanescent et explosif)
Soit \(\frac{\partial h_j}{\partial h_{j-1}} = \text{diag}(\tanh'(z_j)) \cdot W_{hh}\) la jacobienne de la transition d’état. Le produit sur \(t - k\) pas de temps satisfait :
où \(\gamma = \max |\tanh'(z)| \leq 1\). Si la plus grande valeur singulière \(\sigma_{\max}(W_{hh}) < 1/\gamma\), les gradients décroissent exponentiellement avec la distance \(t - k\) (vanishing gradient). Si \(\sigma_{\max}(W_{hh}) > 1/\gamma\), ils croissent exponentiellement (exploding gradient).
Proof. Par sous-multiplicativité de la norme matricielle, \(\left\|\prod_{j=k+1}^t A_j\right\| \leq \prod_{j=k+1}^t \|A_j\|\). Or \(\|A_j\| = \|\text{diag}(\tanh'(z_j)) \cdot W_{hh}\| \leq \gamma \cdot \|W_{hh}\|\), d’où le résultat. Le cas d’égalité dans la borne montre que la croissance (ou décroissance) est bien exponentielle en \(t - k\).
Remarque 206
En pratique, le gradient évanescent est le problème le plus courant : il empêche le réseau d’apprendre les dépendances à longue portée. Le gradient explosif, lui, est plus facilement détectable (les valeurs de perte divergent) et peut être traité par le gradient clipping.
Gradient clipping#
Définition 245 (Gradient clipping)
Le gradient clipping consiste à borner la norme du gradient avant la mise à jour des poids :
où \(\theta > 0\) est le seuil de clipping. Cette opération préserve la direction du gradient tout en limitant son amplitude. En PyTorch : torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=theta).
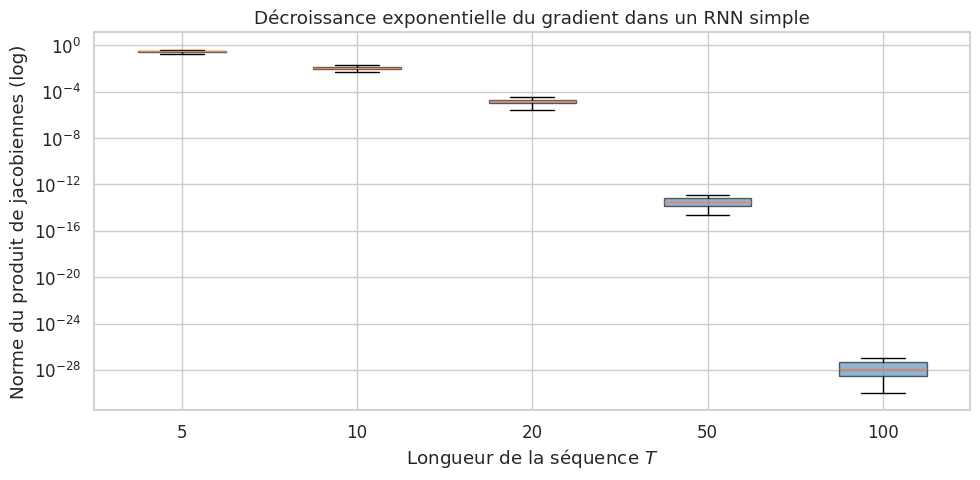
Le gradient évanescent est un problème structurel du RNN simple : il limite sa capacité à apprendre des dépendances au-delà d’une dizaine de pas de temps. Les architectures à portes — LSTM et GRU — ont été conçues précisément pour résoudre ce problème.
LSTM (Long Short-Term Memory)#
L’architecture LSTM, proposée par Hochreiter et Schmidhuber en 1997, est la réponse la plus influente au problème du gradient évanescent. L’idée clé est d’introduire un état de cellule (cell state) \(c_t\) qui traverse la séquence de manière quasi-linéaire, protégé par un système de portes (gates) qui contrôlent le flux d’information.
Définition 246 (Cellule LSTM)
Une cellule LSTM est définie par les équations suivantes, pour \(t = 1, \ldots, T\) :
Porte d’oubli (forget gate) :
Porte d’entrée (input gate) :
Candidat pour l’état de cellule :
Mise à jour de l’état de cellule :
Porte de sortie (output gate) :
État caché :
où \(\sigma\) est la fonction sigmoïde, \(\odot\) le produit de Hadamard (élément par élément), et \([h_{t-1}, x_t]\) la concaténation des vecteurs.
Remarque 207
L’intuition derrière les portes est la suivante :
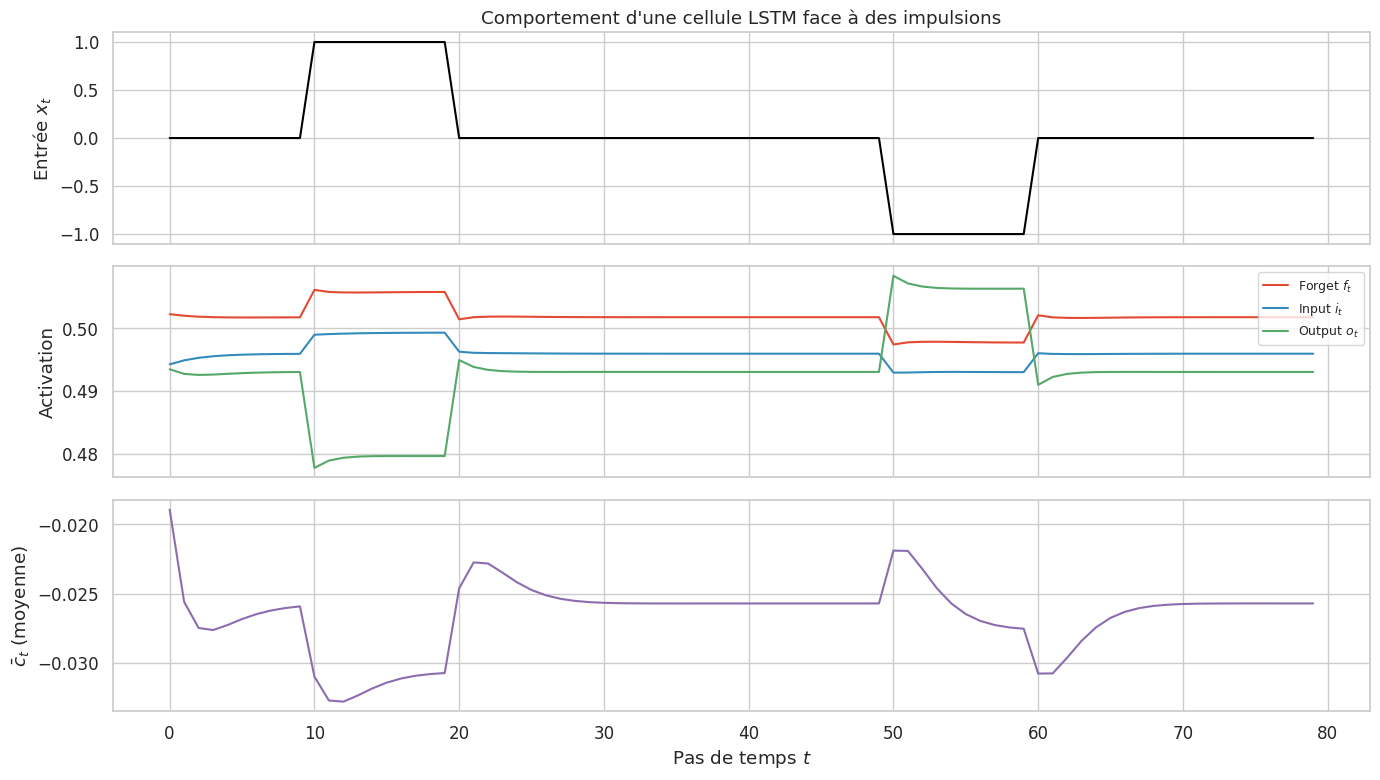
La porte d’oubli \(f_t \in [0, 1]^n\) décide quelle partie de la mémoire précédente \(c_{t-1}\) conserver. Une valeur proche de 1 signifie « se souvenir » ; proche de 0, « oublier ».
La porte d’entrée \(i_t\) décide quelles nouvelles informations écrire dans la mémoire.
La porte de sortie \(o_t\) décide quelle partie de la mémoire exposer comme état caché.
L’état de cellule \(c_t\) agit comme un tapis roulant (conveyor belt) : l’information peut y circuler sur de longues distances avec seulement des opérations additives et multiplicatives, ce qui atténue le gradient évanescent.
Pourquoi le LSTM résout le gradient évanescent#
Proposition 62 (Flux de gradient dans le LSTM)
Le gradient de la perte par rapport à l’état de cellule \(c_k\) (avec \(k < t\)) satisfait :
Lorsque les portes d’oubli \(f_j\) sont proches de 1, le gradient se propage presque sans atténuation le long de l’état de cellule. C’est la différence structurelle avec le RNN simple : le chemin de gradient passe par des opérations additives plutôt que par des produits de matrices.
GRU (Gated Recurrent Unit)#
Le GRU, proposé par Cho et al. en 2014, est une simplification du LSTM qui fusionne l’état caché et l’état de cellule en un seul vecteur, et réduit le nombre de portes de trois à deux.
Définition 247 (Cellule GRU)
Une cellule GRU (Gated Recurrent Unit) est définie par :
Porte de réinitialisation (reset gate) :
Porte de mise à jour (update gate) :
Candidat pour l’état caché :
Mise à jour de l’état caché :
La porte de mise à jour \(z_t\) joue simultanément le rôle des portes d’oubli et d’entrée du LSTM. La porte de réinitialisation \(r_t\) contrôle la quantité d’état passé intégrée dans le candidat.
Remarque 208
La mise à jour \(h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t\) est une interpolation linéaire entre l’état précédent et le candidat. Quand \(z_t \approx 0\), l’état est simplement copié (mémoire longue) ; quand \(z_t \approx 1\), l’état est entièrement remplacé.
Comparaison LSTM vs GRU#
Proposition 63 (Comparaison LSTM et GRU)
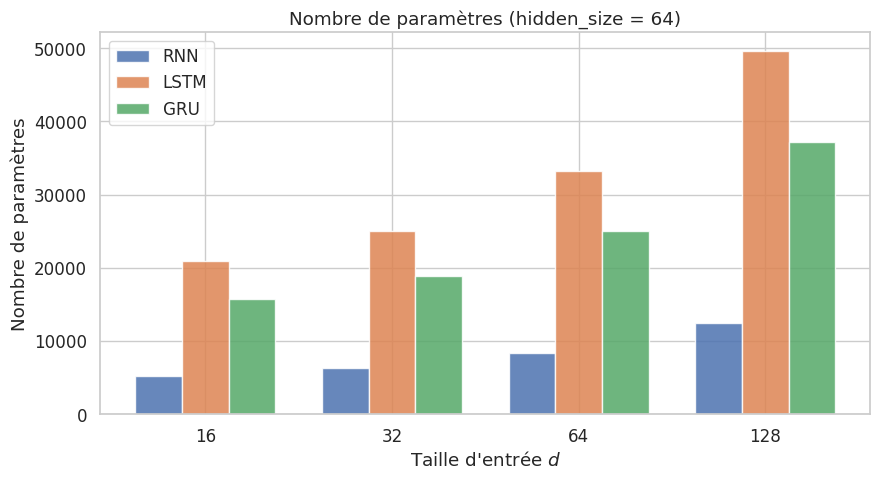
Pour une taille d’état caché \(n\) et une taille d’entrée \(d\) :
LSTM |
GRU |
|
|---|---|---|
Portes |
3 (forget, input, output) |
2 (reset, update) |
États |
\(h_t\) et \(c_t\) |
\(h_t\) uniquement |
Paramètres |
\(4n(n + d) + 4n\) |
\(3n(n + d) + 3n\) |
Ratio paramètres |
\(\approx 1.33\times\) GRU |
Référence |
En termes de performances, il n’y a pas de gagnant systématique : le LSTM est souvent légèrement meilleur sur les tâches nécessitant une mémoire très longue, tandis que le GRU est plus rapide à entraîner et peut être préféré lorsque les données sont limitées. Le choix se fait en pratique par validation croisée.
Architectures récurrentes#
Les cellules RNN, LSTM et GRU sont des briques de base. On les assemble en différentes architectures selon la nature de la tâche.
Many-to-one : classification de séquences#
Définition 248 (Architecture many-to-one)
Dans une architecture many-to-one, le réseau reçoit une séquence \((x_1, \ldots, x_T)\) et produit une unique sortie \(\hat{y}\) à partir du dernier état caché \(h_T\) (ou d’un pooling sur tous les états) :
Applications typiques : analyse de sentiment, classification de documents, détection de genre musical.
Many-to-many : modèles séquence-à-séquence#
Définition 249 (Architecture many-to-many (seq2seq))
Une architecture séquence-à-séquence (sequence-to-sequence, Sutskever et al., 2014) utilise :
Un encodeur RNN qui lit la séquence d’entrée et produit un vecteur de contexte \(c = h_T^{\text{enc}}\).
Un décodeur RNN qui génère la séquence de sortie pas à pas, initialisé par \(c\).
Cette architecture est adaptée à la traduction automatique, au résumé de texte, et au dialogue.
RNN bidirectionnel#
Définition 250 (RNN bidirectionnel)
Un RNN bidirectionnel combine deux RNN : l’un parcourt la séquence de gauche à droite (\(\overrightarrow{h}_t\)), l’autre de droite à gauche (\(\overleftarrow{h}_t\)). La représentation au temps \(t\) est la concaténation :
Cela permet à chaque position d’accéder au contexte passé et futur, ce qui est utile pour l’étiquetage de séquences (NER, POS tagging).
RNN empilés (stacked / deep RNN)#
Définition 251 (RNN empilé)
Un RNN empilé à \(L\) couches utilise la sortie \(h_t^{(\ell)}\) de la couche \(\ell\) comme entrée de la couche \(\ell + 1\) :
avec \(h_t^{(0)} = x_t\). En pratique, on utilise 2 à 4 couches ; au-delà, l’ajout de couches apporte peu de gain et augmente le coût d’entraînement.
=== LSTM bidirectionnel à 2 couches ===
Entrée : torch.Size([4, 20, 10])
Sortie : torch.Size([4, 20, 64]) (batch, seq_len, 2 × hidden)
h_n : torch.Size([4, 4, 32]) (num_layers × 2, batch, hidden)
Params : 36,352
=== GRU 3 couches ===
Sortie : torch.Size([4, 20, 32])
h_n : torch.Size([3, 4, 32])
Params : 16,896
Implémentation PyTorch#
PyTorch fournit des modules optimisés pour les réseaux récurrents. Cette section présente les aspects pratiques de leur utilisation.
Remarque 209
Les modules nn.RNN, nn.LSTM et nn.GRU partagent la même interface :
Entrée :
(seq_len, batch, input_size)par défaut, ou(batch, seq_len, input_size)avecbatch_first=True.Sortie : le tenseur de tous les états cachés et le(s) dernier(s) état(s) caché(s).
Paramètres importants :
num_layers(profondeur),bidirectional,dropout(entre couches).
Le choix de batch_first=True est recommandé pour la lisibilité.
Gestion de séquences de longueurs variables#
Dans un batch, les séquences ont souvent des longueurs différentes. PyTorch fournit pack_padded_sequence et pad_packed_sequence pour éviter les calculs inutiles sur le padding.
Tenseur paddé : torch.Size([3, 8, 5])
PackedSequence : data=torch.Size([16, 5]), batch_sizes=tensor([3, 3, 3, 2, 2, 1, 1, 1])
Sortie dépaddée : torch.Size([3, 8, 16]), longueurs : tensor([8, 5, 3])
Exemple complet : modèle de langage caractère par caractère#
Nous allons entraîner un modèle de langage récurrent au niveau des caractères : le réseau apprend à prédire le caractère suivant étant donné les caractères précédents. Ce type de modèle illustre parfaitement le fonctionnement des RNN et permet de générer du texte de manière autogressive.
Préparation des données#
Vocabulaire : 31 caractères | Longueur : 628
Modèle et entraînement#
Paramètres : 220,031
Génération de texte#
Une fois entraîné, le modèle peut générer du texte de manière autogressive : on lui donne un caractère de départ, il prédit le suivant, puis on utilise cette prédiction comme nouvelle entrée, et ainsi de suite.
--- Température = 0.5 ---
La nvIjnoltC
btIb jIbjl ozqiuf xIb extqgxahcrxRICqfrIac
iqcdjunvCtuxcqzt RpzzqsRursrjC.cyz.m.Csixh p
tofidi dthygLyaRlCsbt.
--- Température = 0.8 ---
La fLjdxnthcdn IxIy prnrvjzvajhfhifelCf gvjvm b.lzldo
d eocn iegtaj.vy
niilsl d.cLupgqCRg dy
phxaltIevvIitloaudCmjsjefy.
--- Température = 1.2 ---
La tdu
qi yuLddzfdCComiopbzczf
cmetyh adqzfeoeo.y.cqpiqghgnshvqogejL zpcfIrytofenirbb
IutR
ptdItlxb.geqqRpvxI aRha .CfuLgy
Remarque 210
La température \(\tau\) contrôle la diversité de la génération. Avant l’échantillonnage, les logits sont divisés par \(\tau\) : une valeur \(\tau < 1\) produit une génération conservatrice et répétitive, \(\tau = 1\) donne la distribution originale, et \(\tau > 1\) favorise la diversité au prix de la cohérence. C’est un compromis classique entre qualité et diversité.
Comparaison RNN vs LSTM vs GRU sur une tâche de mémoire#
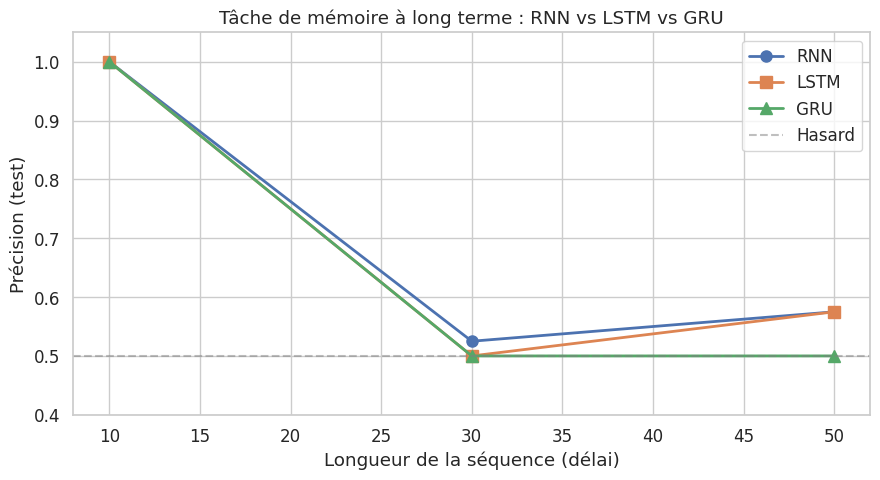
Pour illustrer concrètement l’avantage des architectures à portes, comparons les trois types de cellules sur une tâche de mémoire à long terme : le réseau doit se souvenir d’un signal donné en début de séquence pour prédire une cible en fin de séquence.
delay=10 done
delay=30 done
delay=50 done
Remarque 211
Cette expérience illustre le problème du gradient évanescent de manière pratique : le RNN simple échoue rapidement à retenir l’information lorsque le délai augmente, tandis que le LSTM et le GRU maintiennent une bonne performance grâce à leurs mécanismes de portes. L’état de cellule du LSTM (ou l’interpolation linéaire du GRU) permet un flux de gradient quasi-ininterrompu le long de la séquence.
Limitations et perspectives#
Malgré leur succès historique, les RNN — y compris LSTM et GRU — présentent des limitations importantes qui ont motivé le développement d’architectures alternatives.
Dépendances très longues#
Remarque 212
Même avec le LSTM, les dépendances au-delà de quelques centaines de pas de temps restent difficiles à capturer. L’information dans l’état de cellule se dégrade progressivement malgré les portes, car le réseau doit prendre des décisions binaires (oublier ou retenir) à chaque pas de temps, et les erreurs d’oubli sont cumulatives.
Complexité séquentielle#
Proposition 64 (Complexité temporelle des RNN)
Le calcul de la séquence des états cachés \((h_1, h_2, \ldots, h_T)\) est intrinsèquement séquentiel : \(h_t\) dépend de \(h_{t-1}\). La complexité temporelle est donc \(O(T)\) et ne peut pas être parallélisée sur la dimension temporelle. Cela constitue un goulot d’étranglement majeur lors de l’entraînement sur des séquences longues, comparé aux architectures entièrement parallélisables.
Vers les mécanismes d’attention et les Transformers#
Le mécanisme d’attention (Bahdanau et al., 2015) a d’abord été proposé comme complément aux RNN seq2seq : au lieu de compresser toute l’entrée dans un unique vecteur de contexte, le décodeur peut « regarder » directement les états cachés de l’encodeur à chaque pas de temps, pondérés par des scores de pertinence.
L’architecture Transformer (Vaswani et al., 2017) pousse cette idée à son terme : elle abandonne entièrement la récurrence au profit de l”auto-attention (self-attention), permettant à chaque position de la séquence d’interagir directement avec toutes les autres. Les Transformers résolvent simultanément les deux limitations des RNN :
Les dépendances à longue portée sont capturées en un seul pas (le chemin de gradient entre deux positions quelconques est de longueur \(O(1)\)).
Le calcul est entièrement parallélisable sur la dimension temporelle.
Nous étudierons en détail les mécanismes d’attention et l’architecture Transformer au chapitre 23.

Résumé#
Ce chapitre a présenté les réseaux de neurones récurrents, la famille d’architectures conçue pour traiter les données séquentielles.
Le RNN simple (Elman) introduit un état caché récurrent qui agit comme une mémoire, mais souffre du problème du gradient évanescent qui limite l’apprentissage des dépendances à longue portée.
La BPTT (Backpropagation Through Time) est l’algorithme d’entraînement des RNN. Le produit de matrices jacobiennes sur de longues séquences provoque l’évanescence ou l’explosion du gradient. Le gradient clipping traite l’explosion, mais pas l’évanescence.
Le LSTM résout le gradient évanescent grâce à un état de cellule protégé par trois portes (oubli, entrée, sortie), permettant un flux de gradient quasi-linéaire sur de longues séquences.
Le GRU est une simplification du LSTM avec deux portes (réinitialisation, mise à jour) et environ 25 % de paramètres en moins, pour des performances souvent comparables.
Les architectures many-to-one, many-to-many (seq2seq), bidirectionnelles et empilées permettent d’adapter les RNN à une grande variété de tâches.
Les limitations — dépendances très longues et complexité séquentielle \(O(T)\) — ont motivé le développement des mécanismes d”attention et de l’architecture Transformer, que nous étudierons au chapitre 23.
Remarque 213
Les RNN, et en particulier les LSTM, restent des outils pertinents dans de nombreux contextes : séries temporelles de longueur modérée, systèmes embarqués à faible empreinte mémoire, ou tâches où la nature séquentielle du traitement est un avantage (génération en temps réel). Comprendre les RNN est également indispensable pour apprécier pleinement les innovations apportées par les Transformers.