
Les données#
Sans données, vous n’êtes qu’une personne de plus avec une opinion.
W. Edwards Deming
Introduction#
L’apprentissage automatique repose sur un principe fondamental : un algorithme apprend à partir de données. La qualité, la quantité et la représentativité de ces données déterminent la qualité du modèle résultant. On résume souvent cela par l’adage garbage in, garbage out : si les données d’entrée sont biaisées, incomplètes ou erronées, le modèle produira des prédictions médiocres, quelle que soit la sophistication de l’algorithme utilisé.
Ce chapitre pose les bases du travail avec les données. Nous verrons comment les classer, les charger, les nettoyer et les préparer avant toute étape de modélisation.
Types de variables#
Avant de manipuler des données, il faut savoir les classifier. La nature d’une variable détermine les opérations qu’on peut lui appliquer, les visualisations adaptées et les algorithmes utilisables.
Variables quantitatives#
Définition 9 (Variable quantitative)
Une variable quantitative est une variable dont les valeurs sont numériques et sur lesquelles les opérations arithmétiques (addition, moyenne, etc.) ont un sens. On distingue deux sous-types :
Continue : la variable peut prendre toute valeur dans un intervalle de \(\mathbb{R}\) (ex : température, taille, poids).
Discrète : la variable ne prend que des valeurs entières ou dénombrables (ex : nombre d’enfants, nombre de pièces dans un logement).
Exemple 2
La température en degrés Celsius est une variable quantitative continue : elle peut valoir 18.3, 22.71, etc.
Le nombre de chambres dans un appartement est une variable quantitative discrète : il vaut 1, 2, 3, etc.
Le revenu annuel en euros est quantitatif continu, même si en pratique on l’arrondit souvent au centime.
Variables qualitatives#
Définition 10 (Variable qualitative)
Une variable qualitative (ou catégorielle) est une variable dont les valeurs représentent des catégories. On distingue :
Nominale : les catégories n’ont pas d’ordre naturel (ex : couleur, pays, type de véhicule).
Ordinale : les catégories possèdent un ordre naturel (ex : niveau d’éducation : primaire < secondaire < supérieur ; satisfaction : faible < moyen < élevé).
Remarque 11
Même si une variable qualitative ordinale est souvent encodée numériquement (1, 2, 3), il ne faut pas la confondre avec une variable quantitative : l’écart entre les catégories n’est pas nécessairement constant ni mesurable.
Variables binaires#
Définition 11 (Variable binaire)
Une variable binaire (ou booléenne, ou dichotomique) est un cas particulier de variable qualitative nominale qui ne prend que deux valeurs (ex : oui/non, vrai/faux, 0/1, malade/sain).
Remarque 12
Une variable binaire peut être traitée comme quantitative (0 et 1) ou qualitative selon le contexte. En apprentissage automatique, la variable cible d’un problème de classification binaire est une variable binaire.
Résumé sur les variables#
Type |
Sous-type |
Exemples |
Opérations typiques |
|---|---|---|---|
Quantitative |
Continue |
Température, prix, taille |
Moyenne, écart-type, corrélation |
Quantitative |
Discrète |
Nb de pièces, nb d’enfants |
Comptage, moyenne |
Qualitative |
Nominale |
Couleur, pays, espèce |
Mode, fréquence |
Qualitative |
Ordinale |
Niveau d’études, satisfaction |
Mode, médiane, fréquence |
Binaire |
– |
Oui/non, 0/1 |
Fréquence, proportion |
| temperature | nb_pieces | ville | satisfaction | proprietaire | |
|---|---|---|---|---|---|
| 0 | 18.3 | 2 | Paris | moyen | True |
| 1 | 22.7 | 3 | Lyon | élevé | False |
| 2 | 15.1 | 1 | Paris | faible | False |
| 3 | 30.0 | 4 | Marseille | élevé | True |
| 4 | 25.5 | 2 | Lyon | moyen | True |
temperature float64
nb_pieces int64
ville str
satisfaction str
proprietaire bool
dtype: object
Formats de données#
Les données se présentent sous de nombreux formats. Voici les plus courants en science des données.
CSV (Comma-Separated Values)#
Le format le plus répandu. Chaque ligne est un enregistrement, les colonnes sont séparées par un délimiteur (virgule, point-virgule, tabulation).
| nom | age | ville | salaire | |
|---|---|---|---|---|
| 0 | Alice | 30 | Paris | 45000 |
| 1 | Bob | 25 | Lyon | 38000 |
| 2 | Charlie | 35 | Marseille | 52000 |
JSON (JavaScript Object Notation)#
Format hiérarchique, adapté aux données semi-structurées et aux API web.
| nom | age | |
|---|---|---|
| 0 | Alice | 30 |
| 1 | Bob | 25 |
Excel#
SQL#
Parquet#
Format binaire colonne, optimisé pour les gros volumes de données. Très utilisé dans les pipelines de données modernes (Spark, Dask).
Remarque 13
En pratique, on privilégie le format Parquet pour le stockage intermédiaire de gros jeux de données : il est compressé, conserve les types des colonnes et se lit beaucoup plus rapidement que le CSV. Le CSV reste utile pour l’échange et l’inspection visuelle rapide.
Jeux de données classiques#
La communauté dispose de jeux de données de référence pour l’apprentissage et l’évaluation des algorithmes. La bibliothèque sklearn.datasets en fournit plusieurs directement.
Iris#
Le jeu de données le plus célèbre en apprentissage automatique, introduit par R. A. Fisher (1936). Il contient 150 observations de fleurs d’iris, avec 4 variables (longueur et largeur des sépales et des pétales) et 3 classes (setosa, versicolor, virginica).
Dimensions : (150, 5)
Classes : ['setosa' 'versicolor' 'virginica']
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | target | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | 0 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | 0 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | 0 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | 0 |
California Housing#
Ce jeu de données remplace le jeu Boston Housing, désormais obsolète en raison de problèmes éthiques (il contenait une variable corrélant la proportion de population afro-américaine au prix des logements). California Housing contient 20 640 observations sur le marché immobilier californien.
Dimensions : (20640, 9)
Variables : ['MedInc', 'HouseAge', 'AveRooms', 'AveBedrms', 'Population', 'AveOccup', 'Latitude', 'Longitude', 'MedHouseVal']
| MedInc | HouseAge | AveRooms | AveBedrms | Population | AveOccup | Latitude | Longitude | MedHouseVal | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 8.3252 | 41.0 | 6.984127 | 1.023810 | 322.0 | 2.555556 | 37.88 | -122.23 | 4.526 |
| 1 | 8.3014 | 21.0 | 6.238137 | 0.971880 | 2401.0 | 2.109842 | 37.86 | -122.22 | 3.585 |
| 2 | 7.2574 | 52.0 | 8.288136 | 1.073446 | 496.0 | 2.802260 | 37.85 | -122.24 | 3.521 |
| 3 | 5.6431 | 52.0 | 5.817352 | 1.073059 | 558.0 | 2.547945 | 37.85 | -122.25 | 3.413 |
| 4 | 3.8462 | 52.0 | 6.281853 | 1.081081 | 565.0 | 2.181467 | 37.85 | -122.25 | 3.422 |
Remarque 14
Le jeu Boston Housing (load_boston) a été retiré de scikit-learn depuis la version 1.2. On utilisera systématiquement California Housing pour les exemples de régression.
MNIST#
Le jeu MNIST contient 70 000 images (28x28 pixels) de chiffres manuscrits (0-9). C’est le Hello World de la vision par ordinateur.
Dimensions : (1797, 65)
Classes : [0 1 2 3 4 5 6 7 8 9]

Autres jeux de données utiles#
Breast Cancer — Dimensions : (569, 31), Classes : ['malignant' 'benign']
Diabetes — Dimensions : (442, 11)
Make Blobs — Dimensions : (300, 2), Classes : [0 1 2 3]
Nettoyage des données#
Les données réelles sont rarement propres. Elles contiennent des valeurs manquantes, des doublons, des erreurs de saisie et des valeurs aberrantes. Le nettoyage est une étape indispensable avant toute modélisation.
Valeurs manquantes#
Définition 12 (Valeur manquante)
Une valeur manquante (notée NaN pour Not a Number en Pandas/NumPy, ou None en Python) est une valeur absente dans un jeu de données. Elle peut résulter d’une erreur de collecte, d’un champ non rempli, d’une fusion de tables, etc.
| nom | age | salaire | ville | |
|---|---|---|---|---|
| 0 | Alice | 30.0 | 45000.0 | Paris |
| 1 | Bob | NaN | 38000.0 | Lyon |
| 2 | Charlie | 35.0 | NaN | NaN |
| 3 | Diana | 28.0 | 51000.0 | Paris |
| 4 | Eve | NaN | 40000.0 | Marseille |
| 5 | Frank | 42.0 | NaN | Lyon |
Nombre de valeurs manquantes par colonne :
nom 0
age 2
salaire 2
ville 1
dtype: int64
Pourcentage de valeurs manquantes :
nom 0.000000
age 33.333333
salaire 33.333333
ville 16.666667
dtype: float64
Stratégies de traitement des valeurs manquantes#
Définition 13 (Stratégies d’imputation)
Soit un jeu de données contenant des valeurs manquantes. Les principales stratégies de traitement sont :
Suppression : supprimer les lignes (ou colonnes) contenant des valeurs manquantes.
Imputation par une constante : remplacer les valeurs manquantes par la moyenne, la médiane ou le mode de la colonne.
Imputation par KNN : remplacer chaque valeur manquante par la moyenne des \(k\) plus proches voisins dans l’espace des variables non manquantes.
Remarque 15
La suppression est simple mais peut entraîner une perte importante d’information si les valeurs manquantes sont nombreuses. L”imputation par la moyenne est rapide mais ne respecte pas la distribution des données (elle réduit la variance). L”imputation par KNN est plus sophistiquée mais plus coûteuse en calcul. Le choix dépend du contexte et de la proportion de données manquantes.
Après suppression des lignes : 2 lignes (avant : 6)
| nom | age | salaire | ville | |
|---|---|---|---|---|
| 0 | Alice | 30.0 | 45000.0 | Paris |
| 3 | Diana | 28.0 | 51000.0 | Paris |
| nom | age | salaire | ville | |
|---|---|---|---|---|
| 0 | Alice | 30.0 | 45000.0 | Paris |
| 1 | Bob | 32.5 | 38000.0 | Lyon |
| 2 | Charlie | 35.0 | 43500.0 | Lyon |
| 3 | Diana | 28.0 | 51000.0 | Paris |
| 4 | Eve | 32.5 | 40000.0 | Marseille |
| 5 | Frank | 42.0 | 43500.0 | Lyon |
Imputation par la moyenne (SimpleImputer) :
age salaire
0 30.00 45000.0
1 33.75 38000.0
2 35.00 43500.0
3 28.00 51000.0
4 33.75 40000.0
5 42.00 43500.0
Imputation par KNN :
age salaire
0 30.0 45000.0
1 29.0 38000.0
2 35.0 48000.0
3 28.0 51000.0
4 29.0 40000.0
5 42.0 48000.0
Doublons#
Nombre de doublons : 2
| nom | age | ville | |
|---|---|---|---|
| 0 | Alice | 30 | Paris |
| 1 | Bob | 25 | Lyon |
| 2 | Alice | 30 | Paris |
| 4 | Bob | 25 | Lyon |
Après déduplication : 3 lignes
| nom | age | ville | |
|---|---|---|---|
| 0 | Alice | 30 | Paris |
| 1 | Bob | 25 | Lyon |
| 3 | Charlie | 35 | Marseille |
Valeurs aberrantes (outliers)#
Définition 14 (Valeur aberrante)
Une valeur aberrante (outlier) est une observation qui s’écarte significativement du reste des données. Elle peut être le résultat d’une erreur de mesure, d’une erreur de saisie, ou d’un phénomène rare mais réel.
Remarque 16
Il n’existe pas de définition universelle d’un outlier. Deux méthodes courantes sont :
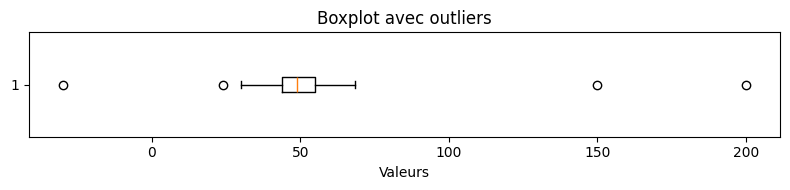
La règle de l’écart interquartile (IQR) : une valeur est aberrante si elle est inférieure à \(Q_1 - 1.5 \times \text{IQR}\) ou supérieure à \(Q_3 + 1.5 \times \text{IQR}\), où \(\text{IQR} = Q_3 - Q_1\).
Le z-score : une valeur est aberrante si \(|z| > 3\), où \(z = (x - \mu) / \sigma\).
Q1 = 43.99, Q3 = 55.05, IQR = 11.06
Bornes : [27.40, 71.64]
Nombre d'outliers détectés : 4
Valeurs aberrantes : [ 23.80254896 150. -30. 200. ]
Types et conversions#
Pandas attribue un dtype à chaque colonne. Il est essentiel de vérifier et corriger ces types avant toute analyse.
Les dtypes de Pandas#
dtype Pandas |
Description |
Exemple |
|---|---|---|
|
Entier |
1, 42, -7 |
|
Flottant |
3.14, -0.5 |
|
Chaîne (ou mixte) |
« Paris », « abc » |
|
Booléen |
True, False |
|
Date/heure |
2024-01-15 |
|
Catégoriel |
« rouge », « bleu » |
Types avant conversion :
entier int64
flottant float64
texte str
booleen bool
date_str str
dtype: object
Conversions de types#
Conversion avec coerce :
0 1.0
1 2.0
2 NaN
3 4.0
dtype: float64
Types après conversion :
entier int64
flottant float64
texte category
booleen bool
date_str str
date datetime64[us]
dtype: object
| entier | flottant | texte | booleen | date_str | date | |
|---|---|---|---|---|---|---|
| 0 | 1 | 1.1 | a | True | 2024-01-15 | 2024-01-15 |
| 1 | 2 | 2.2 | b | False | 2024-02-20 | 2024-02-20 |
| 2 | 3 | 3.3 | c | True | 2024-03-10 | 2024-03-10 |
Parsing de dates#
| date | valeur | annee | mois | jour_semaine | |
|---|---|---|---|---|---|
| 0 | 2024-01-15 | 100 | 2024 | 1 | Monday |
| 1 | 2024-02-20 | 200 | 2024 | 2 | Tuesday |
| 2 | 2024-03-10 | 150 | 2024 | 3 | Sunday |
Remarque 17
Le feature engineering temporel (extraction de l’année, du mois, du jour de la semaine, etc.) est souvent très utile pour les modèles prédictifs. Un modèle ne peut pas directement interpréter un objet datetime, mais il peut exploiter les composantes numériques extraites.
Données textuelles#
Toutes les données ne sont pas tabulaires. Les données non structurées – texte, images, audio, vidéo – représentent une part croissante des données exploitées en apprentissage automatique.
Définition 15 (Données non structurées)
Les données non structurées sont des données qui ne suivent pas un schéma tabulaire prédéterminé. Le texte libre, les images et les signaux audio en sont des exemples. Leur exploitation nécessite des étapes de transformation spécifiques (tokenisation, extraction de caractéristiques, etc.).
Document 0 : 8 tokens
Document 1 : 9 tokens
Document 2 : 11 tokens
Matrice terme-document : (3, 26)
Vocabulaire (extrait) : ['apprentissage', 'automatique', 'est', 'un', 'sous', 'domaine', 'de', 'intelligence', 'artificielle', 'les']
| apprentissage | artificielle | automatique | cerveau | de | des | domaine | données | du | en | ... | les | neurones | plus | python | réseaux | science | sont | sous | un | utilisé | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 |
| 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | ... | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | ... | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 1 |
3 rows × 26 columns
Remarque 18
La représentation Bag of Words est une méthode simple mais limitée : elle ignore l’ordre des mots et la sémantique. Les chapitres ultérieurs sur le NLP présenteront des représentations plus riches (TF-IDF, word embeddings, Transformers).
Bonnes pratiques#
Séparation train/test dès le début#
Proposition 3 (Séparation des données)
Avant toute exploration approfondie ou tout prétraitement, les données doivent être séparées en un ensemble d’entraînement (train set) et un ensemble de test (test set). Le test set ne doit jamais être utilisé lors de l’entraînement ou du réglage du modèle.
Cette séparation prévient le data leakage (fuite de données) : si des informations du test set influencent l’entraînement (par exemple via le calcul de la moyenne pour l’imputation), l’évaluation du modèle sera faussement optimiste.
Ensemble d'entraînement : (16512, 8)
Ensemble de test : (4128, 8)
Remarque 19
La proportion classique est 80 % pour l’entraînement et 20 % pour le test. On utilise souvent un ensemble de validation supplémentaire (ou une validation croisée) pour le réglage des hyperparamètres, en réservant le test set uniquement pour l’évaluation finale.
Ne jamais regarder le test set#
Remarque 20
Le test set simule des données jamais vues. Toute opération qui utilise des informations du test set – même indirectement, comme calculer la moyenne globale pour imputer des valeurs manquantes – constitue une fuite de données (data leakage). Les conséquences :
Les métriques d’évaluation deviennent sur-optimistes.
Le modèle ne généralise pas aussi bien en production que ne le suggèrent les résultats.
En pratique : toute transformation (mise à l’échelle, imputation, encodage) doit être ajustée (fit) sur le train set, puis appliquée (transform) au test set.
Moyenne du train après mise à l'échelle : [-0. -0. 0.]
Moyenne du test après mise à l'échelle : [-0.026476 0.012379 -0.013059]
(La moyenne du test n'est pas exactement 0 : c'est normal et attendu.)
Pipeline complet#
Pour garantir qu’aucune fuite de données ne se produise, scikit-learn fournit l’objet Pipeline qui enchaîne les étapes de prétraitement et de modélisation.
Score R² sur le test set : 0.5758
Remarque 21
Le Pipeline de scikit-learn est l’outil fondamental pour éviter les fuites de données. Il sera utilisé systématiquement dans les chapitres suivants.
Résumé#
Ce chapitre a posé les bases du travail avec les données en apprentissage automatique :
Types de variables : quantitatives (continues, discrètes), qualitatives (nominales, ordinales), binaires. La nature de chaque variable détermine les traitements et algorithmes applicables.
Formats de données : CSV, JSON, Excel, SQL, Parquet. Pandas fournit une interface unifiée pour les charger.
Jeux de données classiques : Iris, California Housing, Digits/MNIST, ainsi que les générateurs synthétiques de scikit-learn.
Nettoyage : détection et traitement des valeurs manquantes (suppression, imputation), déduplication, détection des outliers.
Types et conversions : vérification et correction des
dtypes, parsing des dates, conversion en types catégoriels.Données textuelles : introduction aux données non structurées et à la représentation Bag of Words.
Bonnes pratiques : séparation train/test dès le début, interdiction de regarder le test set, utilisation des
Pipelinepour prévenir les fuites de données.
Le chapitre suivant abordera l”exploration et la visualisation des données, étape qui permet de mieux comprendre la structure des données avant de modéliser.