
Frameworks : PyTorch#
La simplicité est la sophistication suprème.
Leonard de Vinci
Les chapitres précédents ont posé les fondations théoriques des réseaux de neurones : du perceptron simple à la rétropropagation du gradient. Nous avons implementé ces mécanismes from scratch, ce qui est indispensable pour comprendre les rouages internes de l’apprentissage profond. Cependant, construire et entrainer des réseaux de neurones modernes — comportant des millions de paramètres, des architectures complexes et des calculs sur GPU — nécessite des outils logiciels spécialisés. C’est le rôle des frameworks de deep learning.
Ce chapitre introduit PyTorch, l’un des frameworks les plus utilisés en recherche et en industrie. Nous couvrirons l’ensemble du pipeline : la manipulation des tenseurs, la différentiation automatique, la construction de réseaux avec nn.Module, les fonctions de coût, les optimiseurs, la boucle d’entrainement, et un exemple complet de classification. L’objectif est de fournir une maitrise pratique et solide de PyTorch, qui servira de socle pour les chapitres suivants sur les CNN, RNN et architectures avancées.
Introduction : pourquoi un framework ?#
Le paysage des frameworks#
Implémenter un réseau de neurones from scratch est formateur, mais rapidement limitant. Les opérations clés — propagation avant, calcul du gradient, mise à jour des poids — doivent être optimisées pour la performance (parallélisme CPU/GPU, gestion mémoire, calcul matriciel efficace). Un framework de deep learning fournit :
des structures de données tensorielles optimisées, avec support GPU ;
la différentiation automatique (autograd), qui calcule les gradients sans implémentation manuelle ;
des briques prédéfinies (couches, fonctions d’activation, fonctions de coût, optimiseurs) ;
des utilitaires pour le chargement de données, le checkpointing, le déploiement.
Trois frameworks dominent aujourd’hui l’ecosystème :
Framework |
Créateur |
Graphe |
Points forts |
|---|---|---|---|
TensorFlow |
Statique (eager par défaut depuis v2) |
Ecosystème complet, TF Lite, production |
|
PyTorch |
Meta (Facebook) |
Dynamique |
Pythonique, recherche, flexibilité |
JAX |
Fonctionnel, compilable |
Transformations fonctionnelles, XLA |
Remarque 183
Le choix d’un framework dépend du contexte. TensorFlow reste très utilisé en production et dans l’industrie. JAX gagne du terrain en recherche, notamment pour les transformations fonctionnelles (vmap, jit, grad). PyTorch est le framework dominant en recherche académique et s’impose de plus en plus en production grace è TorchScript et TorchServe.
Pourquoi PyTorch ?#
PyTorch se distingue par plusieurs caractéristiques qui en font un excellent choix pour l’apprentissage :
Graphe de calcul dynamique (define-by-run) : le graphe est construit à la volée à chaque passage avant, ce qui permet un débogage naturel avec les outils Python standard (
print,pdb,breakpoint).Interface pythonique : PyTorch s’intègre naturellement avec l’ecosystème Python (NumPy, Matplotlib, Scikit-learn).
Communauté active : documentation riche, nombreux tutoriels, bibliothèques associées (torchvision, torchaudio, Hugging Face).
Recherche : la grande majorité des publications récentes en deep learning fournissent du code PyTorch.
Définition 224 (Graphe de calcul dynamique)
Un graphe de calcul dynamique (dynamic computational graph ou define-by-run) est un graphe orienté acyclique (DAG) qui représente les opérations effectuées sur les tenseurs. Contrairement à un graphe statique (construit avant l’exécution, puis exécuté), le graphe dynamique est construit pendant l’exécution du code Python. Chaque appel d’opération crée de nouveaux noeuds dans le graphe. Cela permet d’utiliser des structures de contrôle Python (if, for, while) directement dans la définition du modèle.
Tenseurs#
Le tenseur est la structure de données fondamentale de PyTorch. Un tenseur est un tableau multidimensionnel, généralisant les scalaires (0D), les vecteurs (1D), les matrices (2D) et les tableaux de rang supérieur. Les tenseurs PyTorch sont similaires aux ndarray de NumPy, mais avec deux différences majeures : le support GPU et la différentiation automatique.
Définition 225 (Tenseur PyTorch)
Un tenseur (torch.Tensor) est un tableau multidimensionnel homogène. Il est caractérisé par :
sa forme (shape) : un tuple d’entiers donnant la taille de chaque dimension ;
son type (dtype) : le type des éléments (
torch.float32,torch.int64, etc.) ;son périphérique (device) :
cpuoucuda(GPU NVIDIA).
Mathématiquement, un tenseur de forme \((d_1, d_2, \ldots, d_k)\) est un élément de \(\mathbb{R}^{d_1 \times d_2 \times \cdots \times d_k}\).
Création de tenseurs#
PyTorch offre de nombreuses fonctions de création de tenseurs, analogues à celles de NumPy.
zeros(3,4): torch.Size([3, 4]) torch.float32
ones(2,3): torch.Size([2, 3])
rand(2,3):
tensor([[0.9855, 0.4747, 0.9629],
[0.7217, 0.8302, 0.8453]])
randn(2,3):
tensor([[ 0.3483, -0.7297, 2.0355],
[ 0.6544, 1.3972, 0.1694]])
arange(0,10,2): tensor([0, 2, 4, 6, 8])
eye(3):
tensor([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
Depuis NumPy: tensor([[1., 2.],
[3., 4.]], dtype=torch.float64) | dtype: torch.float64
Après modification de arr, t_from_np[0,0]: 99.0
Remarque 184
La conversion torch.from_numpy() et .numpy() partage la mémoire entre le tenseur et le tableau NumPy (sur CPU). Modifier l’un modifie l’autre. Pour obtenir une copie indépendante, utilisez torch.tensor(arr) au lieu de torch.from_numpy(arr).
Types et opérations#
Les types les plus courants sont torch.float32 (défaut), torch.int64 (défaut pour les entiers) et torch.bool. Les tenseurs supportent l’arithmétique élément par élément, le produit matriciel et les réductions.
float32: torch.float32 | int64: torch.int64 | .float(): torch.float32
a + b:
tensor([[ 6., 8.],
[10., 12.]])
a * b (element):
tensor([[ 5., 12.],
[21., 32.]])
a @ b (matmul):
tensor([[19., 22.],
[43., 50.]])
Somme: 10.0 | Moyenne: 2.5
Indexation, vues et broadcasting#
L’indexation des tenseurs suit les conventions de NumPy. Les opérations de reshaping créent des vues (pas de copie mémoire). Le broadcasting permet d’effectuer des opérations entre tenseurs de formes différentes, en étendant automatiquement les dimensions compatibles.
Matrice 3x4:
tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]])
Elément (1,2): 6.0 | Ligne 0: tensor([0., 1., 2., 3.]) | Colonne 1: tensor([1., 5., 9.])
Shape: torch.Size([3]) -> unsqueeze(0): torch.Size([1, 3]) -> unsqueeze(1): torch.Size([3, 1])
Broadcasting ones(3,4) + [1,2,3,4]:
tensor([[2., 3., 4., 5.],
[2., 3., 4., 5.],
[2., 3., 4., 5.]])
GPU : accélérer les calculs#
L’un des principaux avantages de PyTorch est le support transparent des GPU NVIDIA via CUDA.
CUDA disponible : False | Device : cpu
Tenseur sur cpu
Remarque 185
En pratique, on définit une variable device au début du script et on déplace systématiquement les tenseurs et les modèles sur ce device. Cela rend le code device-agnostic : il fonctionne sans modification que l’on dispose d’un GPU ou non. L’idiome standard est device = torch.device("cuda" if torch.cuda.is_available() else "cpu").
Différentiation automatique : Autograd#
La différentiation automatique (automatic differentiation, autograd) est le mécanisme qui permet à PyTorch de calculer automatiquement les gradients de n’importe quelle fonction différentiable par rapport à ses entrées. C’est le moteur de l’entrainement par descente de gradient.
Définition 226 (Différentiation automatique (Autograd))
Le système autograd de PyTorch enregistre toutes les opérations effectuées sur les tenseurs dont l’attribut requires_grad=True, construisant ainsi un graphe de calcul orienté acyclique. Lors de l’appel à .backward() sur un scalaire de sortie, PyTorch parcourt ce graphe en sens inverse (rétropropagation) pour calculer les dérivées partielles \(\frac{\partial L}{\partial \theta_i}\) de la sortie par rapport à chaque paramètre \(\theta_i\). Les gradients sont accumulés dans l’attribut .grad de chaque tenseur feuille.
Exemples de base#
x = 3.0, y = 16.0, dy/dx = 8.0 (attendu: 8)
z = w.x = 32.0 | dz/dw = tensor([4., 5., 6.])
Graphe de calcul et rétropropagation#
Chaque operation sur un tenseur requires_grad=True crée un noeud dans le graphe de calcul. L’attribut .grad_fn indique l’opération qui a produit le tenseur.
grad_fn: c=<MulBackward0 object at 0x7f1f7d11a0e0>, d=<AddBackward0 object at 0x7f1f7d11a0e0>, e=<PowBackward0 object at 0x7f1f7d11a0e0>
de/da = 64.0 (attendu: 64) | de/db = 32.0 (attendu: 32)
Détachement et contexte sans gradient#
Certaines situations nécessitent d’arrêter le suivi du gradient : évaluation du modèle, calcul de métriques, mise à jour des poids.
y requires_grad: True | y.detach() requires_grad: False
z requires_grad dans no_grad: False
Remarque 186
L’utilisation de torch.no_grad() est essentielle pour l’évaluation du modèle. Sans ce contexte, PyTorch continuerait de construire le graphe de calcul inutilement, consommant mémoire et temps de calcul. De même, model.eval() désactive les couches spécifiques à l’entrainement (Dropout, BatchNorm).
Construire un réseau : nn.Module#
Le module torch.nn fournit les briques de construction pour définir des architectures de réseaux de neurones. La classe de base est nn.Module, dont tous les modèles héritent.
Définition 227 (nn.Module)
nn.Module est la classe de base pour tous les modèles PyTorch. Elle fournit :
un mécanisme d’enregistrement automatique des paramètres (poids et biais) ;
une méthode
forward()qui définit la passe avant (forward pass) ;des utilitaires :
parameters(),to(device),train(),eval(),state_dict().
Un modèle est défini en héritant de nn.Module et en implémentant la méthode forward().
Couche linéaire et modèle personnalisé#
La brique la plus élémentaire est la couche linéaire (fully connected, dense) : \(\mathbf{y} = \mathbf{W}\mathbf{x} + \mathbf{b}\).
Poids: torch.Size([3, 4]) | Biais: torch.Size([3])
Sortie: torch.Size([1, 3])
Voici le patron de conception standard pour définir un réseau.
MLP(
(fc1): Linear(in_features=4, out_features=16, bias=True)
(relu): ReLU()
(fc2): Linear(in_features=16, out_features=3, bias=True)
)
Nombre total de paramètres : 131
Remarque 187
Dans __init__, on déclare les couches comme attributs de l’instance. PyTorch les détecte automatiquement et enregistre leurs paramètres. Ne jamais définir de couches dans forward(), car elles ne seraient pas enregistrées et leurs paramètres ne seraient pas optimisés.
nn.Sequential et inspection des paramètres#
Pour les architectures simples (empilement de couches), nn.Sequential offre une syntaxe plus concise.
Entrée: torch.Size([5, 4]) -> Sortie: torch.Size([5, 3])
fc1.weight | shape: torch.Size([16, 4]) | requires_grad: True
fc1.bias | shape: torch.Size([16]) | requires_grad: True
fc2.weight | shape: torch.Size([3, 16]) | requires_grad: True
fc2.bias | shape: torch.Size([3]) | requires_grad: True
Fonctions de coût#
La fonction de coût (loss function) mesure l’écart entre les prédictions du modèle et les valeurs cibles. Le choix de la fonction de coût dépend du type de problème.
Définition 228 (Fonctions de cout principales)
Les fonctions de coût les plus utilisées en deep learning sont :
MSE (Mean Squared Error) pour la régression :
Cross-entropy pour la classification multiclasse (\(K\) classes) :
où \(z_{i,k}\) sont les logits (sorties brutes avant softmax) et \(y_i \in \{0, \ldots, K-1\}\).
BCE with logits pour la classification binaire :
où \(\sigma\) est la fonction sigmoide.
MSE Loss: 0.1700
Cross-Entropy Loss: 0.3185
BCE with Logits Loss: 0.2538
Remarque 188
nn.CrossEntropyLoss de PyTorch combine LogSoftmax et NLLLoss en une seule fonction. Il attend des logits (sorties brutes) et non des probabilités. N’appliquez pas softmax a la sortie du réseau avant de passer les prédictions à CrossEntropyLoss : cela doublerait le softmax et produirait des gradients incorrects.
Optimiseurs#
Les optimiseurs implémentent les algorithmes de mise à jour des paramètres. Le module torch.optim fournit les principaux algorithmes de descente de gradient.
Définition 229 (Optimiseur)
Un optimiseur est un algorithme qui met à jour les paramètres \(\boldsymbol{\theta}\) du modèle dans la direction opposée au gradient de la fonction de coût :
où \(\eta\) est le taux d’apprentissage (learning rate) et \(g(\cdot)\) est une transformation du gradient qui dépend de l’algorithme (identité pour SGD, moment adaptatif pour Adam, etc.).
Optimiseurs crées avec succès.
Remarque 189
Adam est généralement un bon choix par défaut. Son taux d’apprentissage typique est \(10^{-3}\). AdamW est préféré lorsque l’on utilise la régularisation L2, car il découple le weight decay de la mise à jour adaptative du gradient. SGD avec momentum peut converger vers de meilleurs minima sur certains problèmes, mais nécessite un réglage plus fin du learning rate.
Schedulers de learning rate#
Un scheduler ajuste le taux d’apprentissage au cours de l’entrainement, ce qui améliore souvent la convergence.
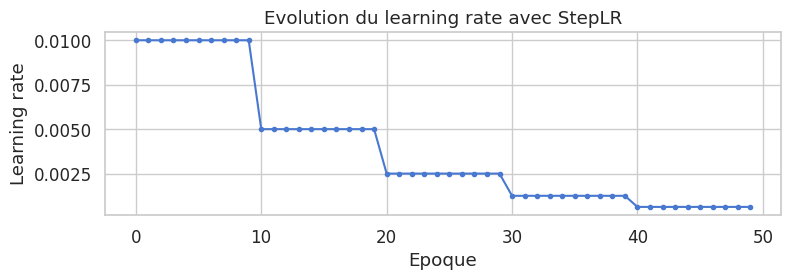
Boucle d’entrainement#
L’entrainement d’un réseau de neurones en PyTorch suit un patron (pattern) standard et explicite. Contrairement à Keras qui cache la boucle derrière model.fit(), PyTorch laisse le contrôle total au developpeur.
Dataset et DataLoader#
Définition 230 (DataLoader)
Un DataLoader est un itérateur qui découpe un Dataset en mini-batches de taille fixe. A chaque époque, il :
mélange (shuffle) optionnellement les indices ;
regroupe les échantillons en batches de taille
batch_size;les convertit en tenseurs prêts pour la passe avant.
Le chargement par mini-batches permet la descente de gradient stochastique : à chaque itération, le gradient est estimé sur un sous-ensemble des données, ce qui réduit l’empreinte mémoire et introduit une régularisation implicite.
Batch - X: torch.Size([16, 4]), y: torch.Size([16])
Le patron d’entrainement#
Exemple 19 (Boucle d’entrainement PyTorch)
Le patron standard comporte cinq étapes par itération :
Passe avant (forward pass) :
y_pred = model(X);Calcul du coût :
loss = criterion(y_pred, y);Remise à zero des gradients :
optimizer.zero_grad();Rétropropagation (backward pass) :
loss.backward();Mise à jour des poids :
optimizer.step().
L’ordre des étapes 3 et 4 est critique : les gradients sont accumulés par défaut, donc il faut les remettre à zero avant chaque rétropropagation.
Epoque 25 | Loss: 0.0750
Epoque 50 | Loss: 0.0747
Epoque 75 | Loss: 0.0747
Epoque 100 | Loss: 0.0747
Paramètres appris : w = 3.015 (vrai: 3.0), b = 2.039 (vrai: 2.0)
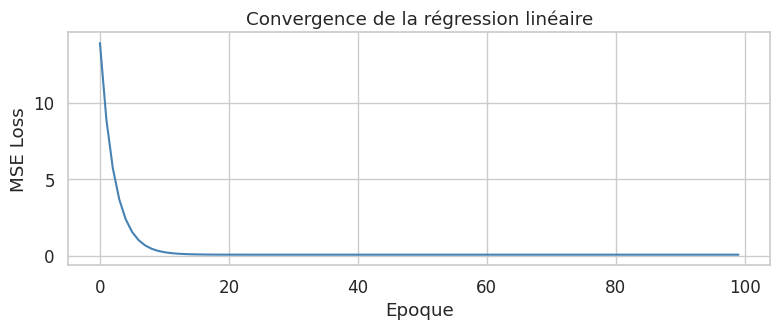
Mode entrainement / évaluation#
PyTorch distingue deux modes : model.train() active les couches spécifiques à l’entrainement (Dropout, BatchNorm avec statistiques de batch) ; model.eval() les désactive pour l’inférence.
Remarque 190
Il faut toujours appeler model.eval() avant l’évaluation et model.train() avant de reprendre l’entrainement. L’oubli de model.eval() est une source fréquente de bugs subtils : le Dropout continue de masquer des neurones aléatoirement, et la BatchNorm utilise les statistiques du batch courant au lieu des statistiques globales.
Exemple complet : classification sur Iris#
Mettons ensemble tous les concepts dans un exemple complet de classification multiclasse sur le jeu de données Iris.
Preparation des données#
Features: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
Classes: ['setosa' 'versicolor' 'virginica']
Shape: X=(150, 4), y=(150,)
Distribution des classes: [50 50 50]
Train: torch.Size([120, 4]), Test: torch.Size([30, 4])
Définition du modèle#
IrisClassifier(
(net): Sequential(
(0): Linear(in_features=4, out_features=32, bias=True)
(1): ReLU()
(2): Linear(in_features=32, out_features=16, bias=True)
(3): ReLU()
(4): Linear(in_features=16, out_features=3, bias=True)
)
)
Paramètres : 739
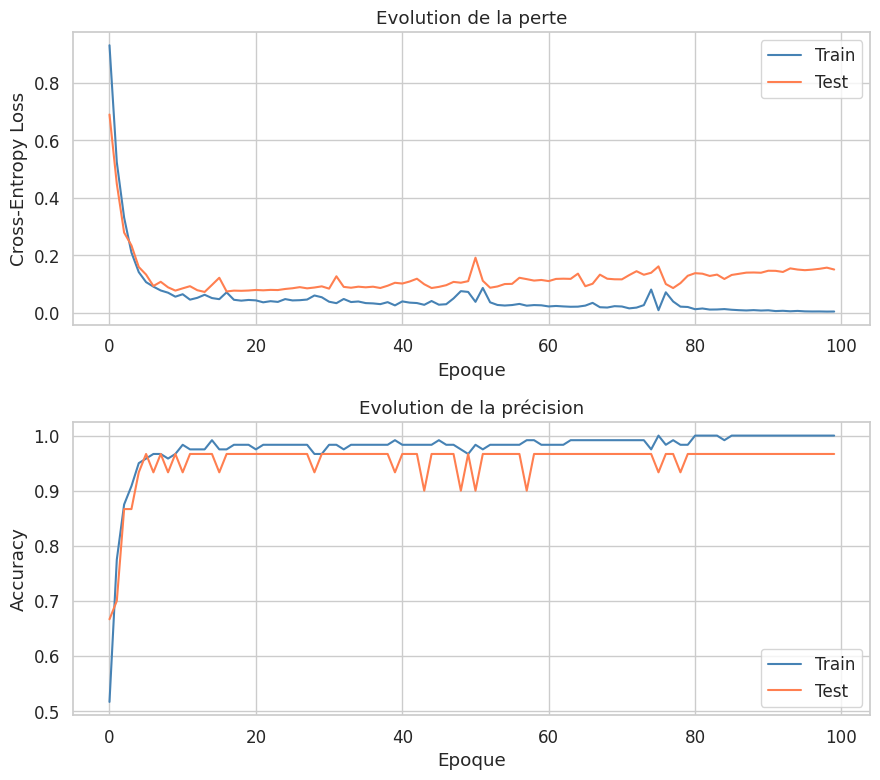
Entrainement#
Epoque 20 | Train Loss: 0.0449 | Train Acc: 0.983 | Test Loss: 0.0777 | Test Acc: 0.967
Epoque 40 | Train Loss: 0.0260 | Train Acc: 0.992 | Test Loss: 0.1046 | Test Acc: 0.933
Epoque 60 | Train Loss: 0.0263 | Train Acc: 0.983 | Test Loss: 0.1143 | Test Acc: 0.967
Epoque 80 | Train Loss: 0.0205 | Train Acc: 0.983 | Test Loss: 0.1289 | Test Acc: 0.967
Epoque 100 | Train Loss: 0.0047 | Train Acc: 1.000 | Test Loss: 0.1507 | Test Acc: 0.967
Courbes d’apprentissage#
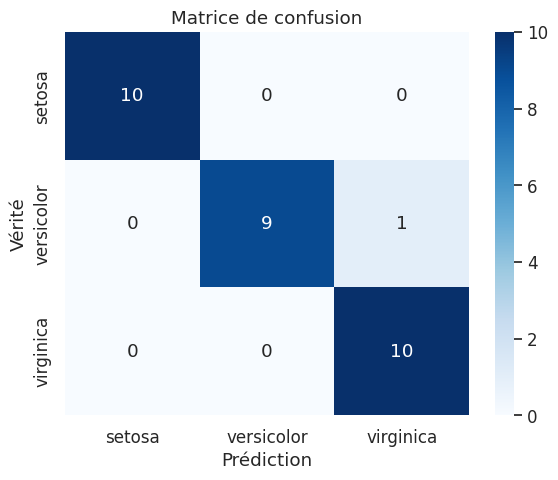
Evaluation finale et prédictions#
Accuracy finale sur le test set : 96.7%
Frontière de décision non linéaire (moons)#
Pour illustrer la puissance des réseaux de neurones sur un problème non linéaire, appliquons un MLP au jeu de données moons avec BCEWithLogitsLoss.
Epoque 50 | Loss: 0.1755 | Test Acc: 0.940
Epoque 100 | Loss: 0.0429 | Test Acc: 0.970
Epoque 150 | Loss: 0.0302 | Test Acc: 0.970
Epoque 200 | Loss: 0.0258 | Test Acc: 0.970
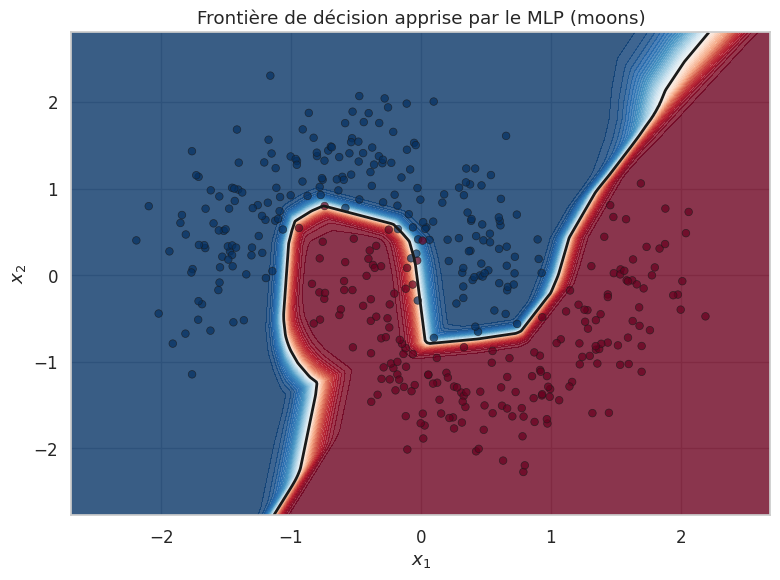
Remarque 191
Le MLP est capable d’apprendre des frontières de décision hautement non linéaires, ce qui était impossible avec un perceptron simple. C’est la puissance de la composition de transformations linéaires et de non-linéarites : chaque couche réorganise l’espace de représentation pour rendre le problème progressivement plus séparable.
Bonnes pratiques#
Reproductibilité#
Graines fixées pour la reproductibilité.
Remarque 192
Même avec toutes les graines fixées, le déterminisme parfait sur GPU n’est pas toujours garanti en raison des algorithmes parallèles non déterministes de cuDNN. L’option torch.backends.cudnn.deterministic = True force l’utilisation d’algorithmes déterministes, mais peut ralentir l’entrainement.
Checkpointing : sauvegarder et charger un modèle#
Exemple de checkpoint :
epoch: 100
model_state_dict: dict avec 6 cles
optimizer_state_dict: dict avec 2 cles
train_loss: 0.004740886584719798
test_acc: 0.9666666388511658
Remarque 193
Toujours sauvegarder le state_dict() plutôt que le modèle entier (torch.save(model, ...)). La sauvegarde du modèle entier utilise pickle, ce qui lie le fichier à la structure de classe exacte au moment de la sauvegarde. Le state_dict ne contient que les tenseurs de paramètres, ce qui est plus portable et robuste.
Code device-agnostic et débogage#
Remarque 194
Le patron standard pour écrire du code device-agnostic (fonctionnant indifféremment sur CPU et GPU) consiste à : (1) définir device = torch.device("cuda" if torch.cuda.is_available() else "cpu") au début du script ; (2) déplacer le modèle avec model.to(device) ; (3) déplacer chaque batch avec X_batch.to(device) dans la boucle d’entrainement. Toutes les opérations doivent être effectuées sur le même device. Oublier de déplacer les données ou le modèle provoque une RuntimeError.
Remarque 195
Quelques conseils pratiques pour déboguer un réseau PyTorch :
Vérifier les shapes : ajouter des
print(x.shape)dansforward()pour tracer les dimensions.Commencer petit : entrainer sur quelques échantillons pour vérifier que le modèle peut overfitter.
Vérifier le gradient : inspecter
param.gradaprèsbackward()pour s’assurer que les gradients ne sont ni nuls ni explosifs.Un seul changement à la fois : modifier un paramètre à la fois pour isoler l’effet de chaque changement.
Visualiser : tracer les courbes de loss train/test pour détecter le surapprentissage ou la divergence.
Récapitulatif du pipeline#
Proposition 58 (Pipeline PyTorch)
Le pipeline standard d’un projet de deep learning avec PyTorch :
Données : charger, prétraiter, normaliser, créer
DatasetetDataLoader.Modèle : définir l’architecture en héritant de
nn.Module, implémenterforward().Coût et optimiseur : choisir la fonction de coût, l’optimiseur, éventuellement un scheduler.
Entrainement : boucle train/eval avec accumulation des métriques.
Evaluation : métriques sur le jeu de test, visualisations.
Sauvegarde : checkpointing du
state_dictet des hyperparamètres.
Chacune de ces étapes est explicite et controlable, ce qui est à la fois la force et la complexité de PyTorch par rapport à des API de plus haut niveau comme Keras.
PyTorch version : 2.10.0+cpu
CUDA disponible : False
Device par défaut : cpu
Ce chapitre a posé les bases de l’utilisation de PyTorch. Les concepts présentés ici — tenseurs, autograd, nn.Module, boucle d’entrainement — sont les briques fondamentales sur lesquelles reposent toutes les architectures avancées. Dans les chapitres suivants, nous les réutiliserons pour construire des réseaux convolutifs (CNN) pour la vision et des réseaux récurrents (RNN) pour les séquences.