
Rétropropagation et optimisation#
L’apprentissage n’est rien d’autre que de l’optimisation au service de la généralisation.
Yann LeCun
Le chapitre précédent a introduit le perceptron et les réseaux de neurones multicouches. Mais une question fondamentale demeure : comment ajuster les paramètres d’un réseau pour qu’il résolve la tâche souhaitée ? La réponse tient en deux mots : rétropropagation et optimisation. Ce chapitre développe ces deux piliers, depuis la descente de gradient jusqu’aux algorithmes modernes comme Adam, en passant par le calcul des gradients via la règle de la chaîne, les problèmes de gradients évanescents ou explosifs, la régularisation, l’initialisation des poids, et une implémentation complète en NumPy.
Le problème d’optimisation#
Entraîner un réseau de neurones revient à résoudre un problème d’optimisation : trouver les poids \(\boldsymbol{\theta}\) qui minimisent une fonction de coût mesurant l’écart entre prédictions et valeurs attendues.
Définition 204 (Problème d’apprentissage comme optimisation)
Soit \(f_{\boldsymbol{\theta}} : \mathbb{R}^d \to \mathbb{R}^K\) un réseau paramétré par \(\boldsymbol{\theta} \in \mathbb{R}^p\) et \(\{(\mathbf{x}_i, \mathbf{y}_i)\}_{i=1}^n\) un jeu d’entraînement. Le problème s’écrit
où \(\ell\) est une fonction de perte mesurant l’erreur sur un exemple individuel.
Fonctions de coût classiques#
Définition 205 (Erreur quadratique moyenne (MSE))
Pour la régression (\(y_i \in \mathbb{R}\)) : \(\;\mathcal{L}_{\text{MSE}}(\boldsymbol{\theta}) = \frac{1}{n}\sum_{i=1}^n \bigl(f_{\boldsymbol{\theta}}(\mathbf{x}_i) - y_i\bigr)^2\).
Définition 206 (Entropie croisée (cross-entropy))
Pour la classification à \(K\) classes avec sorties softmax \(\hat{\mathbf{y}} = f_{\boldsymbol{\theta}}(\mathbf{x})\) :
où \(y_{ik} = 1\) si l’exemple \(i\) appartient à la classe \(k\) (encodage one-hot). Dans le cas binaire :
Remarque 175
L’entropie croisée est liée à l’estimation par maximum de vraisemblance. Minimiser \(\mathcal{L}_{\text{CE}}\) revient à maximiser la log-vraisemblance d’un modèle catégoriel. Le choix MSE / cross-entropy n’est pas arbitraire : ce sont les fonctions de coût cohérentes avec les hypothèses distributionnelles (gaussienne / catégorielle).
Le paysage de la loss#
La fonction \(\mathcal{L}(\boldsymbol{\theta})\) définit une hypersurface dans l’espace des paramètres. Ce paysage est non convexe pour les réseaux de neurones : minima locaux, points-selles et plateaux abondent. Malgré cela, la descente de gradient fonctionne remarquablement bien, car en grande dimension les minima locaux ont généralement des valeurs proches du minimum global.
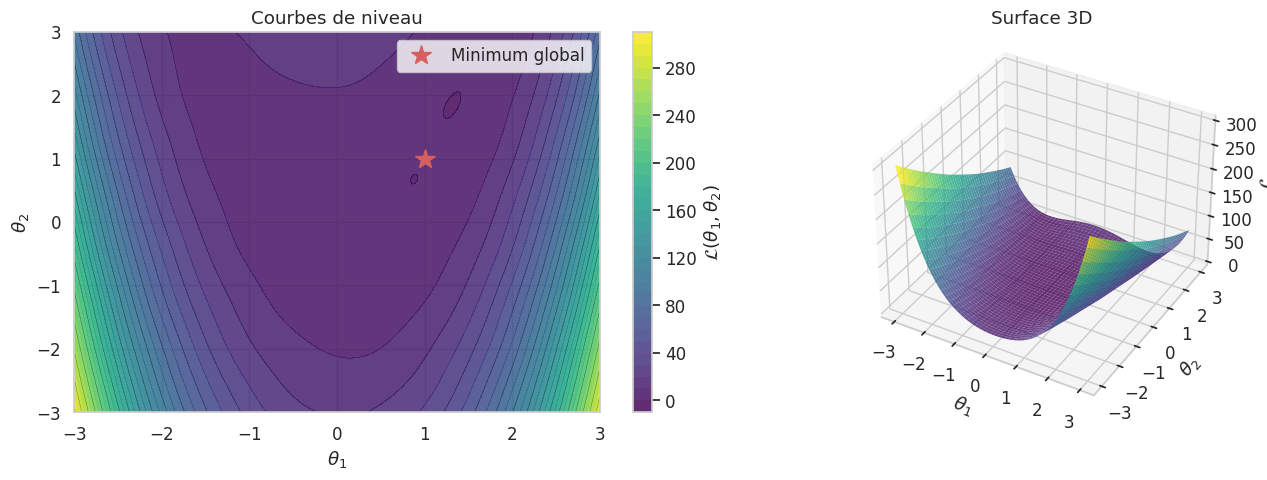
Descente de gradient#
La descente de gradient est l’algorithme fondamental pour minimiser \(\mathcal{L}(\boldsymbol{\theta})\). L’idée est simple : à chaque itération, on se déplace dans la direction opposée au gradient, c’est-à-dire dans la direction de plus forte descente locale.
Définition 207 (Descente de gradient)
Soit \(\mathcal{L} : \mathbb{R}^p \to \mathbb{R}\) différentiable. La descente de gradient produit la suite
où \(\nabla_{\boldsymbol{\theta}}\mathcal{L}\) est le gradient et \(\eta > 0\) le taux d’apprentissage.
Proposition 55 (Convergence sous convexité)
Si \(\mathcal{L}\) est convexe et \(L\)-lisse (\(\|\nabla\mathcal{L}(\mathbf{a}) - \nabla\mathcal{L}(\mathbf{b})\| \leq L\|\mathbf{a} - \mathbf{b}\|\)), alors pour \(\eta \leq 1/L\) :
Remarque 176
Le choix de \(\eta\) est crucial : trop grand, l’algorithme diverge ; trop petit, la convergence est lente. En pratique, on utilise un taux adaptatif qui diminue au cours de l’entraînement.
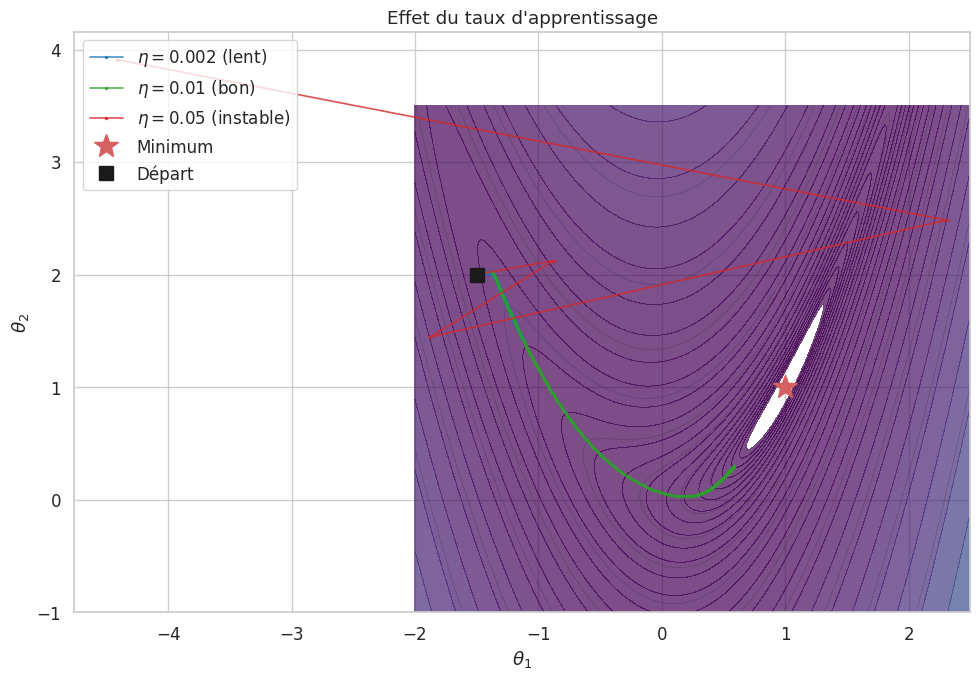
Descente de gradient stochastique (SGD)#
Calculer le gradient exact sur tout le jeu de données est prohibitif pour \(n\) grand. La SGD estime le gradient sur un sous-ensemble aléatoire.
Définition 208 (SGD par mini-batches)
À chaque itération, on tire un mini-batch \(\mathcal{B}_t\) de taille \(B\) et on met à jour :
L’estimateur \(\hat{\mathbf{g}}_t\) est non biaisé : \(\mathbb{E}[\hat{\mathbf{g}}_t] = \nabla\mathcal{L}(\boldsymbol{\theta}^{(t)})\).
Remarque 177
\(B = 1\) : SGD pur, très bruité. \(B = n\) : gradient complet, coûteux. \(1 < B < n\) : mini-batch SGD (typiquement \(B \in \{32, 64, 128, 256\}\)).
Le bruit a un effet régularisant : il aide à échapper aux minima locaux peu profonds.
Définition 209 (Époque)
Une époque = un passage complet sur le jeu d’entraînement, soit \(\lceil n/B \rceil\) itérations.
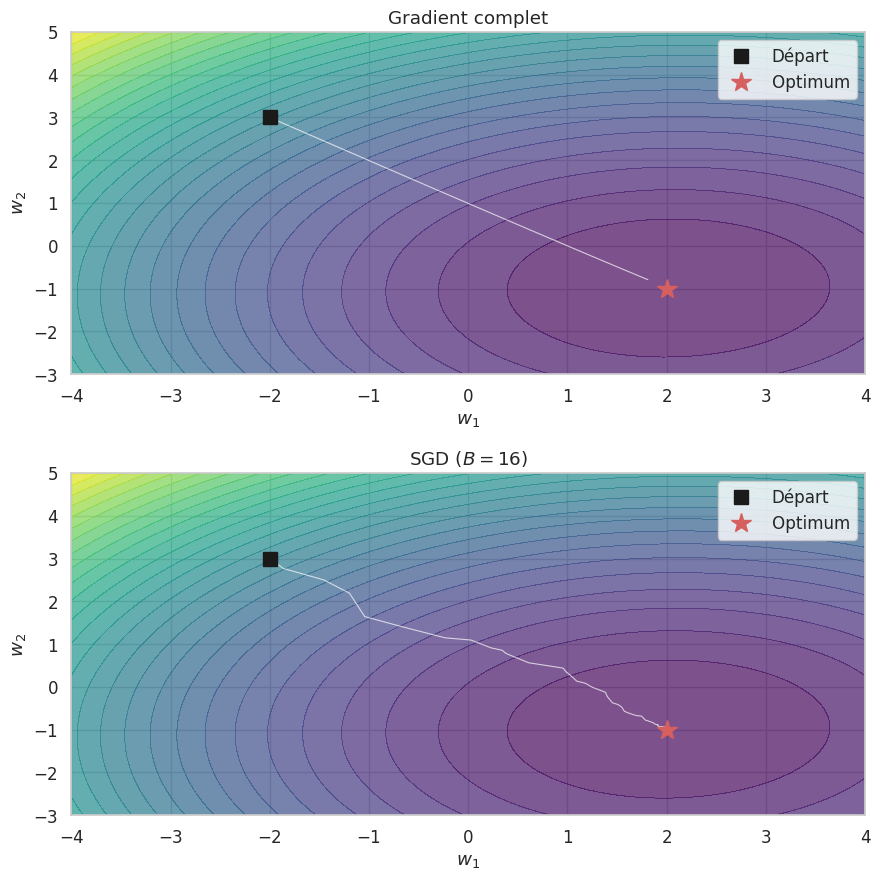
La rétropropagation#
La SGD requiert \(\nabla_{\boldsymbol{\theta}}\mathcal{L}\). Pour un réseau multicouche, ce calcul repose sur la rétropropagation, application systématique de la règle de la chaîne.
Règle de la chaîne#
Proposition 56 (Règle de la chaîne (cas général))
Soient \(\mathbf{g} : \mathbb{R}^m \to \mathbb{R}^n\) et \(\mathbf{f} : \mathbb{R}^n \to \mathbb{R}^p\) différentiables. La jacobienne de \(\mathbf{h} = \mathbf{f} \circ \mathbf{g}\) vérifie
Les gradients se propagent de la sortie vers l’entrée (« de droite à gauche »).
Forward et backward pass#
Définition 210 (Propagation avant et arrière)
Soit un réseau à \(L\) couches. Le forward pass calcule séquentiellement :
avec \(\mathbf{a}^{(0)} = \mathbf{x}\). Le backward pass calcule le signal d’erreur \(\boldsymbol{\delta}^{(\ell)} = \frac{\partial \mathcal{L}}{\partial \mathbf{z}^{(\ell)}}\) par récurrence :
Les gradients des paramètres sont : \(\frac{\partial \mathcal{L}}{\partial \mathbf{W}^{(\ell)}} = \boldsymbol{\delta}^{(\ell)} (\mathbf{a}^{(\ell-1)})^T\) et \(\frac{\partial \mathcal{L}}{\partial \mathbf{b}^{(\ell)}} = \boldsymbol{\delta}^{(\ell)}\).
Calcul détaillé sur un réseau à 2 couches#
Exemple 18 (Rétropropagation — réseau à 2 couches)
Architecture : entrée \(\mathbf{x} \in \mathbb{R}^d\), couche cachée (\(h\) neurones, ReLU), sortie scalaire, loss MSE.
Forward : \(\mathbf{z}^{(1)} = \mathbf{W}^{(1)}\mathbf{x} + \mathbf{b}^{(1)}\), \(\mathbf{a}^{(1)} = \text{ReLU}(\mathbf{z}^{(1)})\), \(z^{(2)} = \mathbf{w}^{(2)T}\mathbf{a}^{(1)} + b^{(2)}\), \(\mathcal{L} = (z^{(2)} - y)^2\).
Backward :
\(\delta^{(2)} = 2(z^{(2)} - y)\)
\(\partial\mathcal{L}/\partial \mathbf{w}^{(2)} = \delta^{(2)} \mathbf{a}^{(1)}\), \(\;\partial\mathcal{L}/\partial b^{(2)} = \delta^{(2)}\)
\(\boldsymbol{\delta}^{(1)} = \delta^{(2)} \mathbf{w}^{(2)} \odot \mathbb{1}[\mathbf{z}^{(1)} > 0]\)
\(\partial\mathcal{L}/\partial \mathbf{W}^{(1)} = \boldsymbol{\delta}^{(1)} \mathbf{x}^T\), \(\;\partial\mathcal{L}/\partial \mathbf{b}^{(1)} = \boldsymbol{\delta}^{(1)}\)
La complexité est du même ordre que le forward pass.
Remarque 178
La jacobienne de l’activation element-wise est \(\mathbf{J}^{(\ell)} = \text{diag}(\sigma_\ell'(\mathbf{z}^{(\ell)}))\). Le gradient en couche \(\ell\) fait intervenir le produit \(\prod_{k=\ell}^{L} \mathbf{J}^{(k)} \mathbf{W}^{(k)}\) : c’est ce produit itéré qui est à l’origine des problèmes de gradient évanescent ou explosif.
=== FORWARD ===
z1 = [0.92879757 0.50696542 0.49740068 0.38742938]
a1 = [0.92879757 0.50696542 0.49740068 0.38742938]
z2 = 0.5593, loss = 0.8849
=== BACKWARD ===
δ₂ = -1.8814
∂L/∂w₂ = [-1.74745077 -0.95381076 -0.93581555 -0.72891424]
δ₁ = [-0.71591271 -0.11446041 -0.41754478 -0.31388942]
∂L/∂W₁ =
[[-0.71591271 0.35795635 -0.21477381]
[-0.11446041 0.05723021 -0.03433812]
[-0.41754478 0.20877239 -0.12526343]
[-0.31388942 0.15694471 -0.09416683]]
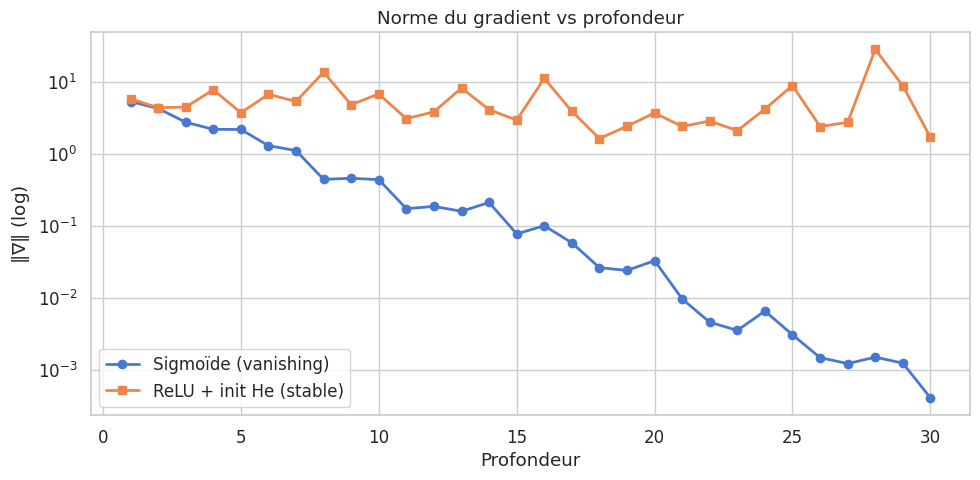
Problèmes de gradient#
Lorsque les réseaux deviennent profonds (dizaines voire centaines de couches), la rétropropagation se heurte à deux pathologies majeures liées au produit itéré de jacobiens à travers les couches.
Définition 211 (Gradient évanescent (vanishing gradient))
Si \(\|\mathbf{J}^{(\ell)} \mathbf{W}^{(\ell)}\| < 1\) pour chaque couche, alors \(\|\partial\mathcal{L}/\partial\mathbf{z}^{(1)}\|\) décroît exponentiellement avec la profondeur. Les premières couches cessent d’apprendre.
Définition 212 (Gradient explosif (exploding gradient))
Si \(\|\mathbf{J}^{(\ell)} \mathbf{W}^{(\ell)}\| > 1\), le produit croît exponentiellement : les gradients deviennent gigantesques et l’entraînement diverge.
Remarque 179
Le rôle de l’activation est central :
Sigmoïde : \(\sigma'(x) = \sigma(x)(1-\sigma(x)) \leq 0.25\) — vanishing inévitable en profondeur.
Tanh : \(\tanh'(x) \leq 1\) — mieux, mais encore sensible au vanishing.
ReLU : \(\text{ReLU}'(x) \in \{0, 1\}\) — préserve l’amplitude du gradient pour les neurones actifs. C’est la raison principale de sa popularité.
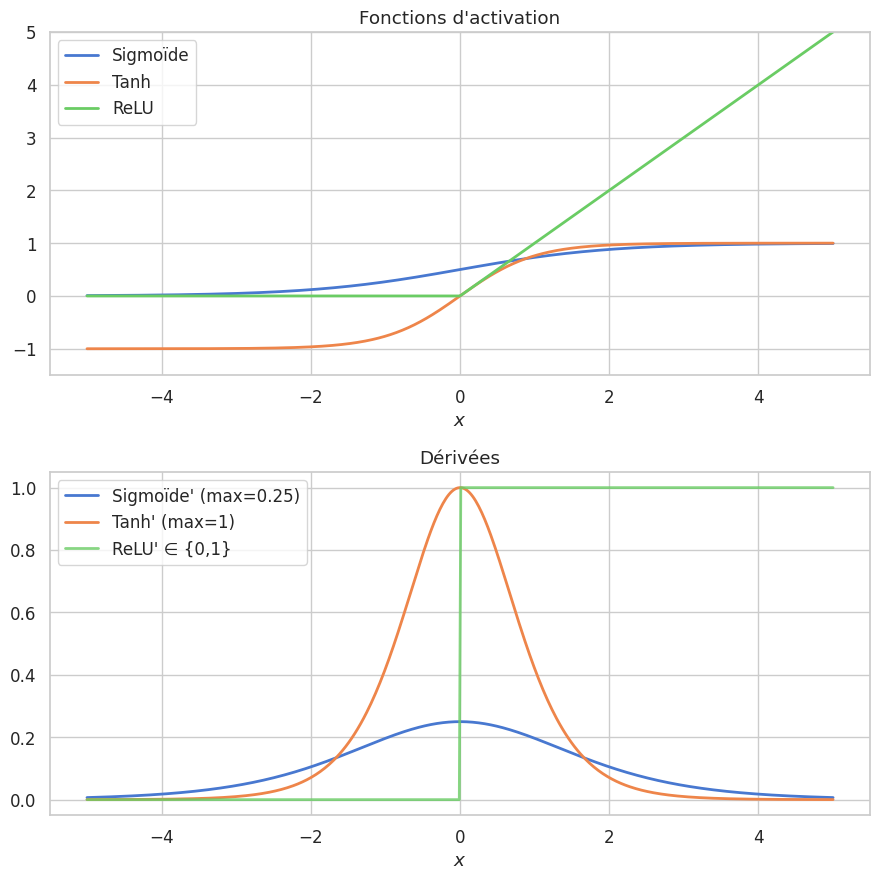
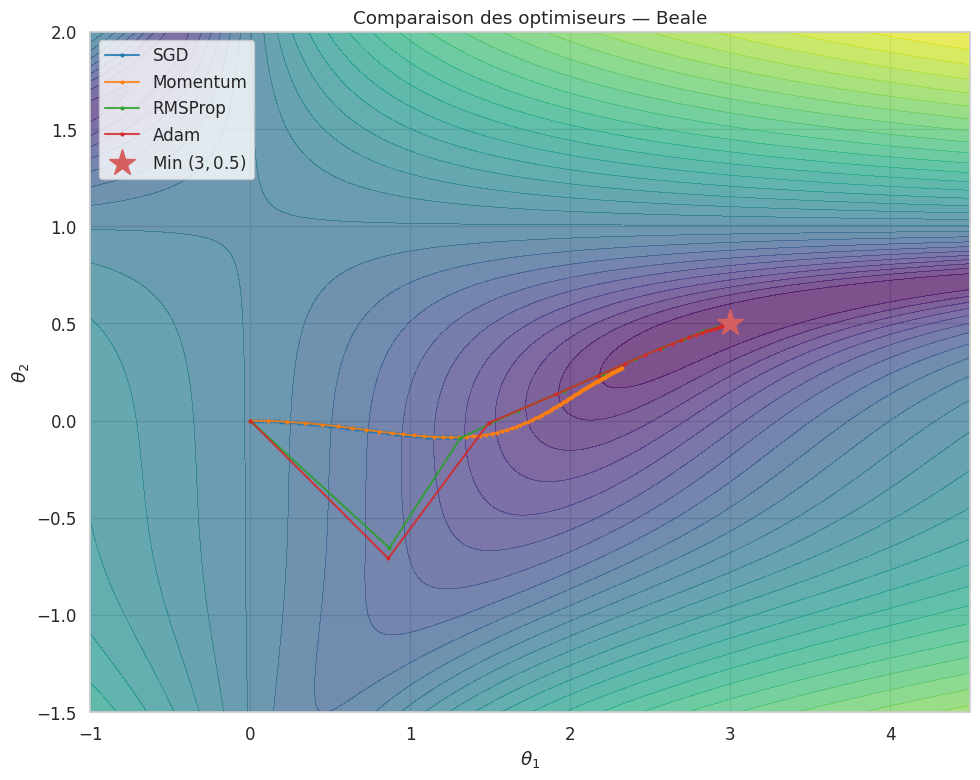
Méthodes d’optimisation avancées#
La SGD vanille converge, mais souvent lentement, surtout dans les paysages de loss mal conditionnés (vallées étroites et allongées). Plusieurs variantes améliorent la vitesse et la stabilité de la convergence en modifiant la manière dont les gradients sont accumulés ou normalisés.
Momentum#
Définition 213 (SGD avec Momentum)
où \(\beta \in [0,1)\) (typiquement \(0.9\)). Par analogie physique, \(\mathbf{v}\) est une vitesse et \(\beta\) contrôle la friction.
Momentum de Nesterov#
Définition 214 (Nesterov Accelerated Gradient (NAG))
Le gradient est évalué au point « anticipé » \(\boldsymbol{\theta}^{(t)} - \eta\beta\mathbf{v}^{(t)}\) :
NAG améliore le taux de convergence de \(O(1/t)\) à \(O(1/t^2)\) sous convexité.
RMSProp#
Définition 215 (RMSProp)
Adapte le taux par paramètre via la moyenne mobile des carrés des gradients :
avec \(\rho = 0.99\), \(\varepsilon = 10^{-8}\). Les directions à grands gradients sont freinées, les autres amplifiées.
Adam#
Définition 216 (Adam (Adaptive Moment Estimation))
Adam (Kingma & Ba, 2015) combine Momentum et RMSProp :
Correction du biais : \(\hat{\mathbf{m}} = \mathbf{m}/(1-\beta_1^{t+1})\), \(\hat{\mathbf{v}} = \mathbf{v}/(1-\beta_2^{t+1})\).
Valeurs par défaut : \(\beta_1=0.9\), \(\beta_2=0.999\), \(\varepsilon=10^{-8}\), \(\eta=10^{-3}\).
Remarque 180
Adam est l’optimiseur le plus utilisé en deep learning grâce à sa robustesse. Cependant, SGD + momentum peut mieux généraliser pour certaines tâches (vision), car Adam converge vers des minima plus « pointus ».
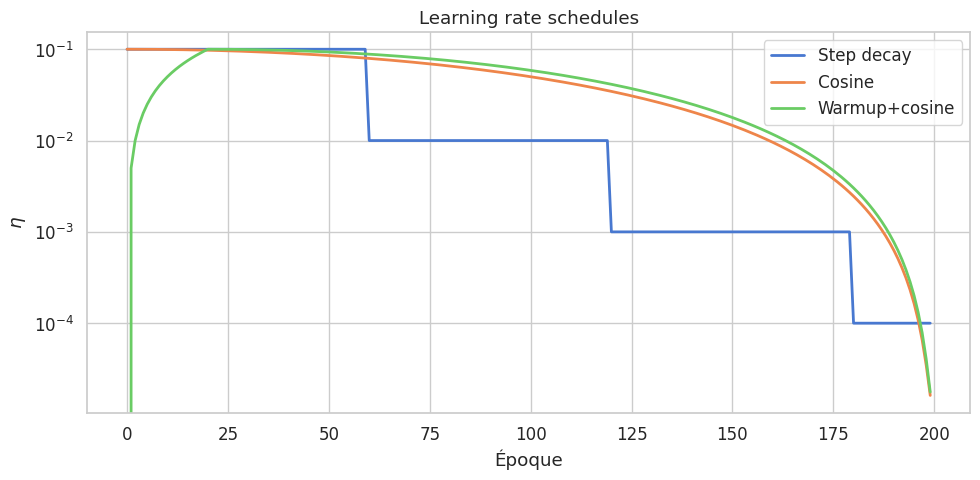
Planification du taux d’apprentissage (learning rate schedules)#
Plutôt que d’utiliser un taux constant, on ajuste souvent \(\eta\) au cours de l’entraînement selon un schéma de planification.
Définition 217 (Schémas de planification)
Soit \(\eta_0\) le taux initial, \(T\) le nombre total d’époques.
Step decay : \(\eta_t = \eta_0 \cdot \gamma^{\lfloor t/s \rfloor}\) (\(\gamma=0.1\) typiquement).
Cosine annealing : \(\eta_t = \eta_{\min} + \tfrac{1}{2}(\eta_0 - \eta_{\min})(1 + \cos\tfrac{\pi t}{T})\).
Warmup linéaire : \(\eta_t = \eta_0 \cdot t/T_w\) pour \(t \leq T_w\), puis un autre schéma.
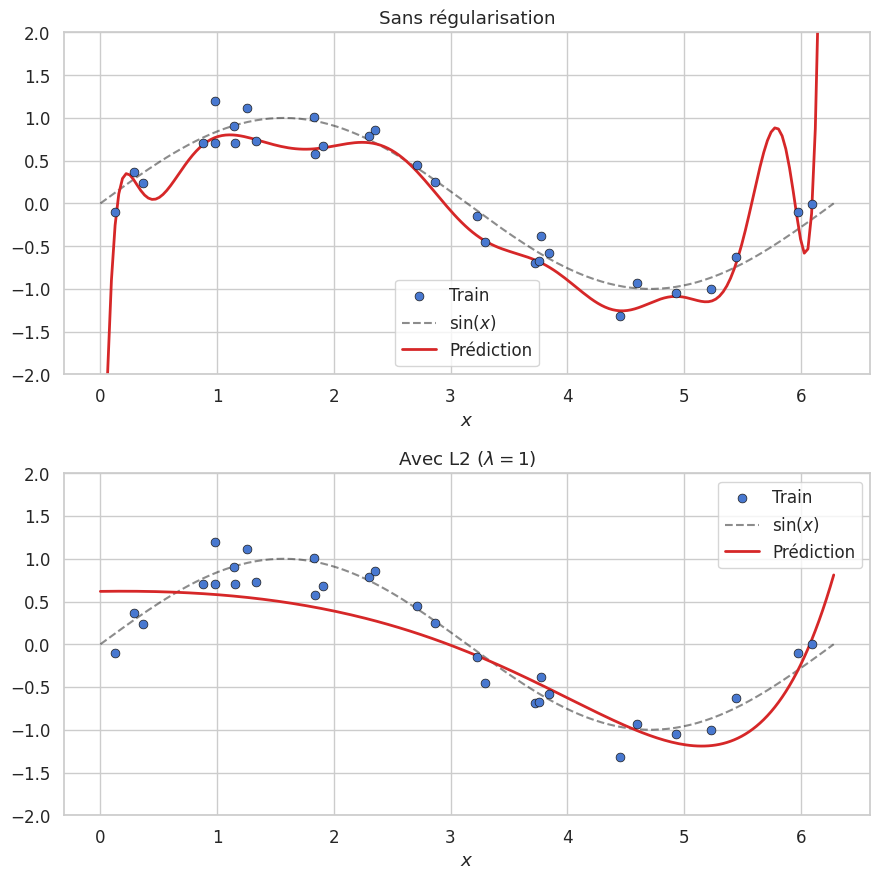
Régularisation#
La régularisation limite le surapprentissage en contraignant la capacité du modèle.
Définition 218 (Régularisation L2 (weight decay))
La mise à jour devient \(\theta_j \leftarrow (1-\eta\lambda)\theta_j - \eta\,\partial\mathcal{L}/\partial\theta_j\). Le facteur \((1-\eta\lambda)\) « décroît » les poids à chaque étape.
Définition 219 (Dropout)
Pendant l’entraînement, chaque neurone est éteint avec probabilité \(p\) :
Le facteur \(1/(1-p)\) (inverted dropout) assure \(\mathbb{E}[\tilde{\mathbf{a}}] = \mathbf{a}\), évitant toute modification à l’inférence. Le dropout s’interprète comme l’entraînement d’un ensemble exponentiel de sous-réseaux.
Définition 220 (Batch Normalization)
La batch normalization (Ioffe & Szegedy, 2015) normalise les pré-activations sur le mini-batch :
où \(\gamma, \beta\) sont apprenables. Effets : paysage de loss plus lisse, taux d’apprentissage plus élevés possibles, réduction de la sensibilité à l’initialisation, légère régularisation.
Définition 221 (Early stopping)
On surveille la loss de validation et on arrête l’entraînement lorsqu’elle cesse de diminuer pendant un nombre fixé d’époques (patience). On conserve les poids de la meilleure époque.
Remarque 181
La data augmentation enrichit le jeu d’entraînement par des transformations préservant le label (rotations, retournements, bruit). C’est une régularisation implicite très efficace, surtout en vision.
Initialisation des poids#
Une mauvaise initialisation conduit immédiatement à des gradients évanescents ou explosifs, avant même le début de l’entraînement.
Proposition 57 (Principe)
Pour qu’un signal se propage correctement, la variance des activations doit rester stable couche après couche. Si les poids sont i.i.d., \(\text{Var}(z_j^{(\ell)}) = n_{\ell-1}\,\text{Var}(W_{ij})\,\text{Var}(a_i^{(\ell-1)})\). La stabilité requiert \(\text{Var}(W_{ij}) \approx 1/n_{\ell-1}\).
Définition 222 (Initialisation Xavier/Glorot)
Pour les activations linéaires ou tanh (Glorot & Bengio, 2010) :
Définition 223 (Initialisation He/Kaiming)
Pour ReLU (He et al., 2015), la moitié des pré-activations étant annulée :
Remarque 182
Xavier et He calibrent la variance des poids pour que le produit itéré de matrices ait des valeurs propres proches de \(1\), stabilisant à la fois le signal (forward) et le gradient (backward).

Implémentation from scratch#
Mettons en pratique l’ensemble des concepts vus dans ce chapitre en implémentant un réseau de neurones à deux couches entièrement en NumPy, avec forward pass, backward pass (rétropropagation), et entraînement par mini-batch SGD avec l’optimiseur Adam. L’objectif est de classer un jeu de données synthétique non linéairement séparable.
Réseau à 2 couches en NumPy#
Entraînement sur un jeu synthétique#
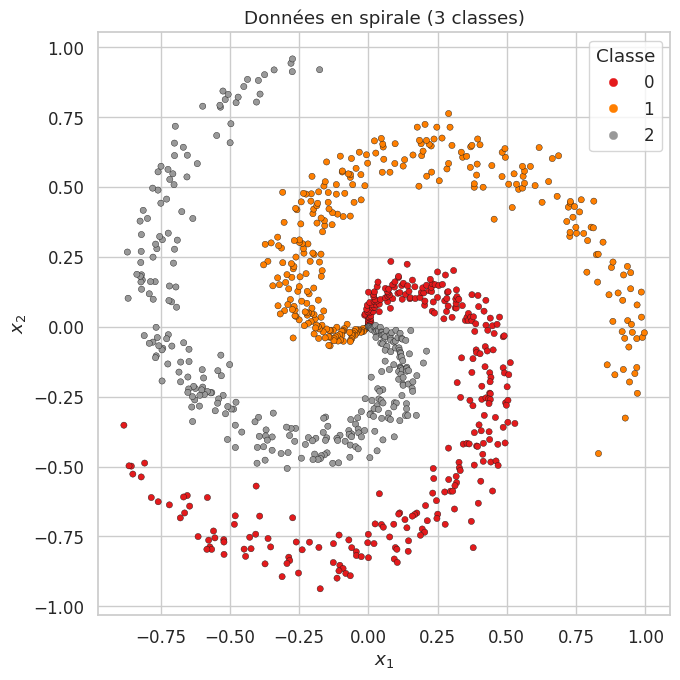
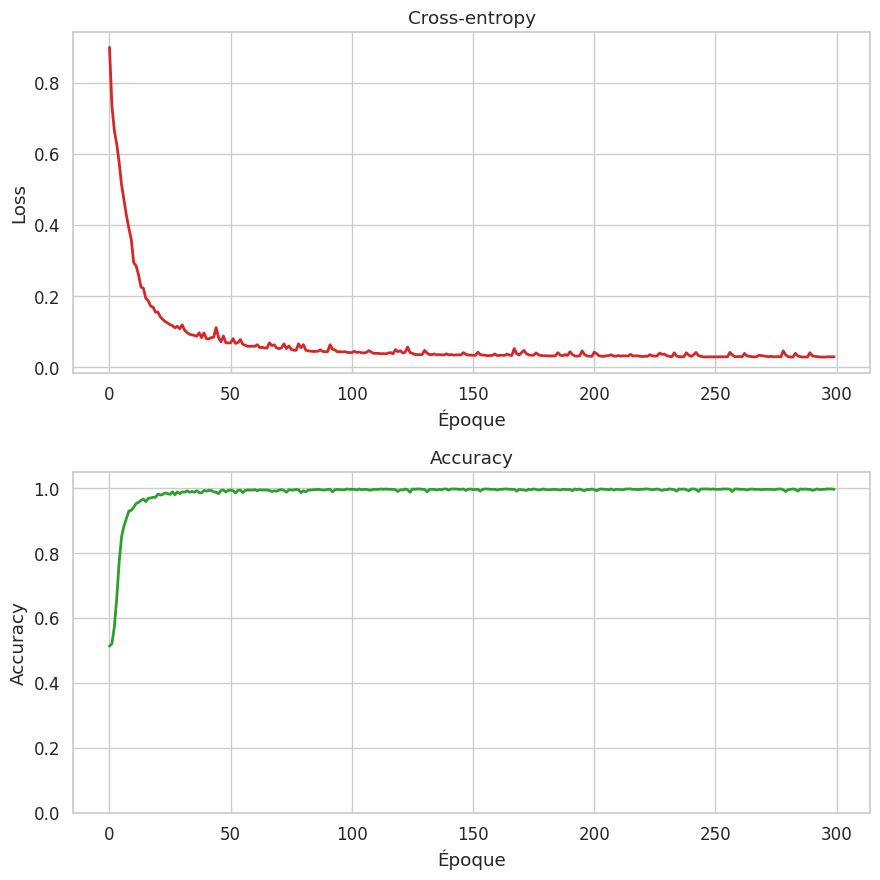
Ép. 50 — Loss: 0.0686 — Acc: 0.9933
Ép. 100 — Loss: 0.0415 — Acc: 0.9967
Ép. 150 — Loss: 0.0344 — Acc: 0.9978
Ép. 200 — Loss: 0.0308 — Acc: 0.9978
Ép. 250 — Loss: 0.0292 — Acc: 0.9978
Ép. 300 — Loss: 0.0297 — Acc: 0.9967
Accuracy finale : 0.9967
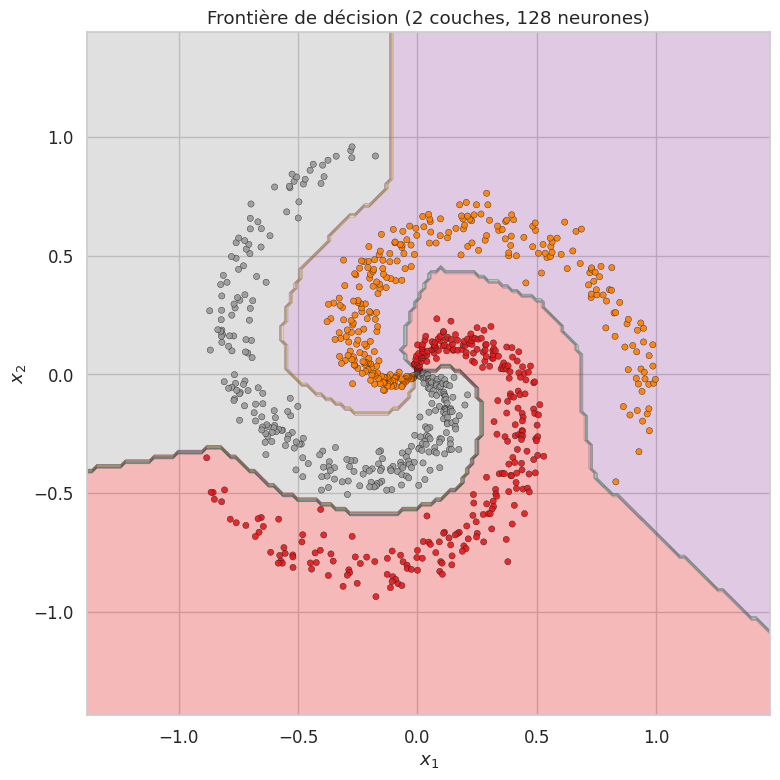
Résumé#
Ce chapitre a couvert les deux piliers de l’entraînement des réseaux de neurones :
La rétropropagation : calcul efficace du gradient via la règle de la chaîne, avec une complexité du même ordre que le forward pass.
L’optimisation : de la descente de gradient aux optimiseurs adaptatifs (Adam), en passant par les learning rate schedules et la gestion du bruit stochastique.
Problème |
Solutions |
|---|---|
Gradient évanescent |
ReLU, init He, batch norm, connexions résiduelles |
Gradient explosif |
Gradient clipping, init soignée, batch norm |
Surapprentissage |
L2, dropout, early stopping, data augmentation |
Convergence lente |
Momentum, Adam, LR schedules, warmup |
Sensibilité à l’init |
Xavier (tanh), He (ReLU), batch norm |
En résumé, la rétropropagation fournit un algorithme de calcul des gradients dont la complexité est linéaire en le nombre de paramètres, tandis que les optimiseurs adaptatifs et les techniques de régularisation rendent l’entraînement des réseaux profonds à la fois rapide et robuste. L’ensemble de ces ingrédients — choix de la loss, algorithme d’optimisation, initialisation, régularisation — forme un tout cohérent dont la maîtrise est indispensable pour tout praticien du deep learning.
Le chapitre suivant montrera comment PyTorch automatise la rétropropagation grâce à l”autograd et fournit des implémentations optimisées de l’ensemble des techniques présentées ici, nous permettant de nous concentrer sur l’architecture des réseaux plutôt que sur les calculs de gradient.