
Détection d’anomalies#
Ce qui est normal est ce qui est familier ; ce qui est anormal, c’est ce qui ne ressemble à rien de connu.
Adapté librement de Hawkins (1980)
La détection d’anomalies (anomaly detection, outlier detection) est l’un des problèmes les plus anciens et les plus importants de l’analyse de données. L’idée fondamentale est simple : parmi un ensemble d’observations, certaines se distinguent significativement de la majorité. Ces observations atypiques — les anomalies — peuvent résulter d’erreurs de mesure, de comportements frauduleux, de pannes imminentes, ou simplement de phénomènes rares mais authentiques. Identifier ces anomalies est crucial dans de nombreux domaines, de la détection de fraude bancaire à la cybersécurité, en passant par la maintenance prédictive et le contrôle qualité industriel.
Ce chapitre, qui ouvre la Partie III — Apprentissage non supervisé, présente les principales méthodes de détection d’anomalies, des approches statistiques classiques aux algorithmes modernes d’apprentissage automatique. Nous aborderons les fondements théoriques de chaque méthode, puis les illustrerons avec des implémentations pratiques en Python.
Introduction#
Anomalies et nouveautés#
Avant toute chose, il convient de distinguer deux problèmes voisins mais distincts.
Définition 167 (Anomalie)
Une anomalie (outlier) est une observation qui dévie tellement des autres observations qu’elle fait naître le soupçon qu’elle a été générée par un mécanisme différent. Plus formellement, si les données normales sont issues d’une distribution \(P_{\text{normal}}\), une anomalie \(\mathbf{x}^*\) est une observation telle que
pour un certain seuil \(\tau > 0\) suffisamment petit.
Définition 168 (Détection de nouveautés)
La détection de nouveautés (novelty detection) consiste à identifier, parmi de nouvelles observations, celles qui n’appartiennent pas à la distribution apprise sur un jeu d’entraînement supposé propre (sans anomalies). C’est un problème semi-supervisé : on dispose d’un ensemble d’entraînement constitué uniquement d’observations normales.
Remarque 149
En détection d’anomalies, le jeu d’entraînement contient potentiellement des anomalies que l’on cherche à identifier. En détection de nouveautés, le jeu d’entraînement est propre et l’on cherche à détecter les anomalies parmi les nouvelles observations uniquement. Scikit-learn distingue ces deux cas dans sa documentation et dans le paramètre novelty de certains estimateurs.
Types d’anomalies#
Les anomalies se déclinent en trois grandes catégories.
Définition 169 (Types d’anomalies)
Anomalie ponctuelle (point anomaly) : une observation individuelle qui est anormale par rapport au reste des données. Exemple : une transaction bancaire d’un montant anormalement élevé.
Anomalie contextuelle (contextual anomaly) : une observation qui n’est anormale que dans un contexte donné. Exemple : une température de 35°C est normale en été mais anormale en hiver.
Anomalie collective (collective anomaly) : un ensemble d’observations qui, prises individuellement, ne sont pas nécessairement anormales, mais dont la cooccurrence est anormale. Exemple : une séquence inhabituelle d’accès réseau qui individuellement sont banals.
Applications#
La détection d’anomalies est omniprésente dans les applications réelles :
Détection de fraude : identifier les transactions frauduleuses parmi des millions de transactions légitimes.
Cybersécurité : détecter les intrusions réseau, les comportements suspects d’utilisateurs ou de processus.
Maintenance prédictive : repérer les signaux précurseurs de pannes dans les données de capteurs industriels.
Contrôle qualité : identifier les produits défectueux sur une ligne de production.
Santé : détecter des anomalies dans des signaux physiologiques (ECG, EEG) ou des résultats d’analyses.
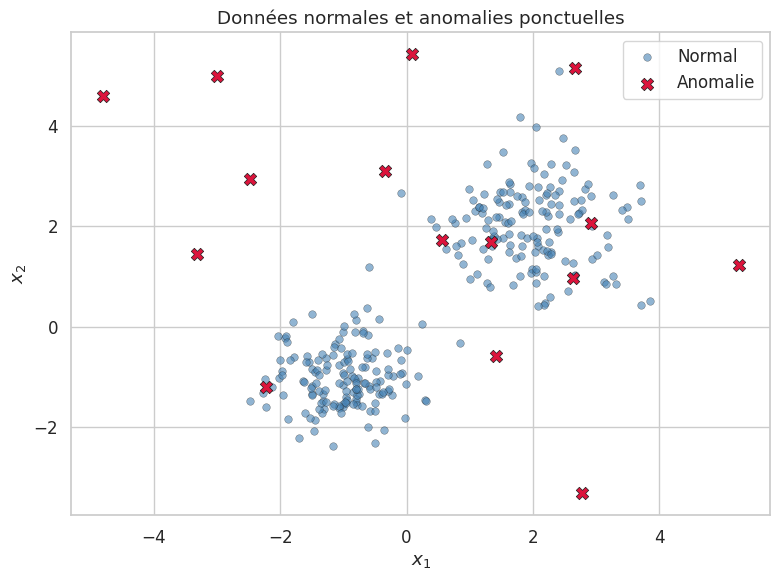
Approches statistiques#
Les approches statistiques constituent le socle historique de la détection d’anomalies. Elles reposent sur l’hypothèse que les données normales suivent une distribution connue, et identifient comme anomalies les observations dont la probabilité est faible sous cette distribution.
Test de Grubbs#
Définition 170 (Test de Grubbs)
Le test de Grubbs (1969) permet de détecter une seule anomalie dans un échantillon univarié supposé gaussien. La statistique de test est
où \(\bar{x}\) est la moyenne et \(s\) l’écart-type de l’échantillon. Sous l’hypothèse nulle \(H_0\) : « il n’y a pas d’anomalie », \(G\) suit une distribution dérivée de la loi de Student. On rejette \(H_0\) si
où \(t_{\alpha/(2n),\, n-2}\) est le quantile de la loi de Student à \(n-2\) degrés de liberté.
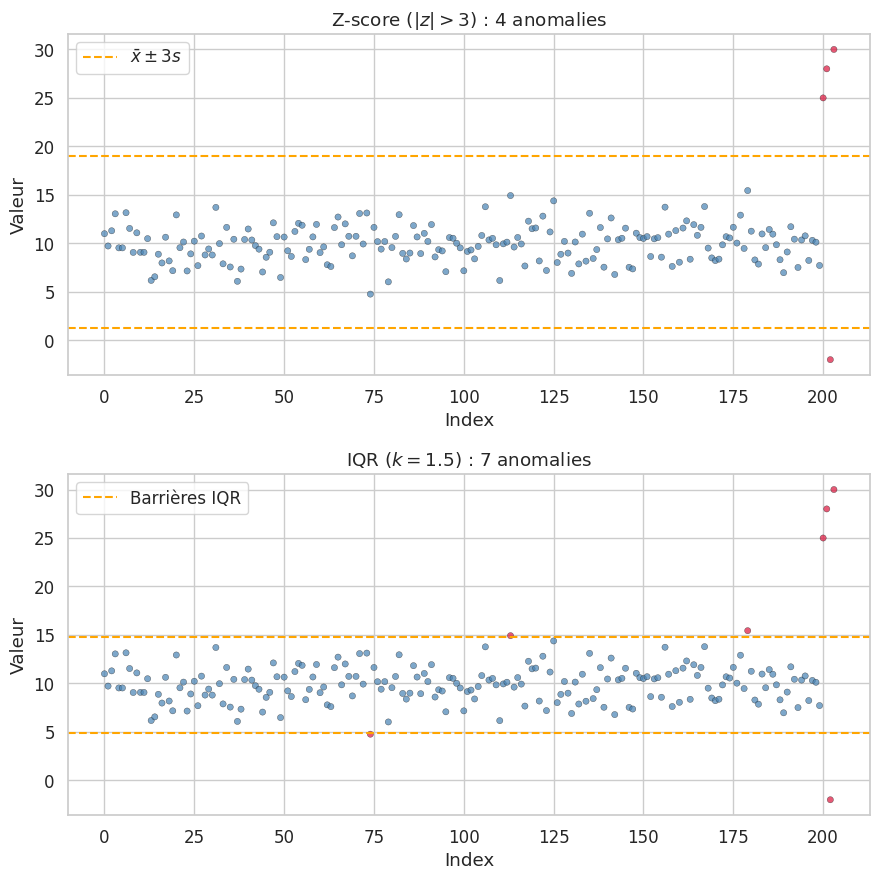
Z-score et IQR#
Définition 171 (Z-score)
Le Z-score d’une observation \(x_i\) dans un échantillon univarié est
Une observation est considérée comme anomalie si \(|z_i| > \theta\), avec typiquement \(\theta = 3\) (règle des trois sigmas). Le Z-score modifié utilise la médiane et l’écart absolu médian (MAD) pour plus de robustesse :
où \(\tilde{x}\) est la médiane et \(\text{MAD} = \text{median}(|x_i - \tilde{x}|)\).
Définition 172 (Méthode IQR)
La méthode de l’intervalle interquartile (IQR) définit les anomalies comme les observations situées en dehors des « barrières » :
où \(Q_1\) et \(Q_3\) sont les premier et troisième quartiles, \(\text{IQR} = Q_3 - Q_1\), et \(k = 1{,}5\) (anomalies modérées) ou \(k = 3\) (anomalies extrêmes).
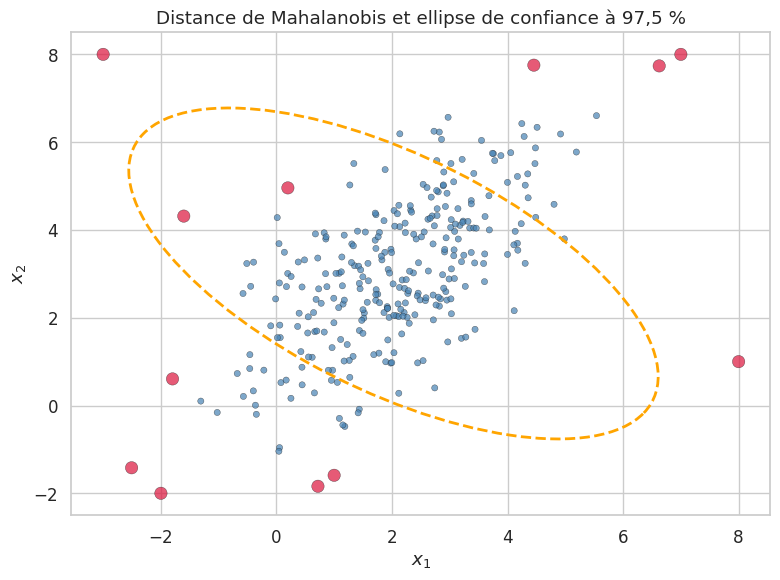
Distance de Mahalanobis#
Pour les données multivariées, le Z-score se généralise naturellement à la distance de Mahalanobis.
Définition 173 (Distance de Mahalanobis)
Soit \(\mathbf{x} \in \mathbb{R}^d\) une observation, \(\boldsymbol{\mu}\) le vecteur moyen et \(\boldsymbol{\Sigma}\) la matrice de covariance d’un ensemble de données. La distance de Mahalanobis de \(\mathbf{x}\) au centre de la distribution est
Si les données suivent une loi normale multivariée, alors \(D_M^2(\mathbf{x})\) suit une loi \(\chi^2\) à \(d\) degrés de liberté.
Remarque 150
La distance de Mahalanobis tient compte de la corrélation entre les variables, contrairement à la distance euclidienne. Pour des données non corrélées de variance unitaire, elle se réduit à la distance euclidienne au centre. En pratique, l’estimation de \(\boldsymbol{\Sigma}\) peut être instable en haute dimension, ce qui motive l’utilisation de méthodes robustes comme le Minimum Covariance Determinant (MCD), que nous verrons plus loin avec l’Elliptic Envelope.
Remarque 151
Les approches statistiques classiques souffrent de la malédiction de la dimensionnalité. En haute dimension, l’estimation de la matrice de covariance devient instable, les distances perdent leur pouvoir discriminant, et la notion même de « point aberrant » se dilue. C’est pourquoi des méthodes algorithmiques plus sophistiquées ont été développées, comme celles que nous allons maintenant étudier.
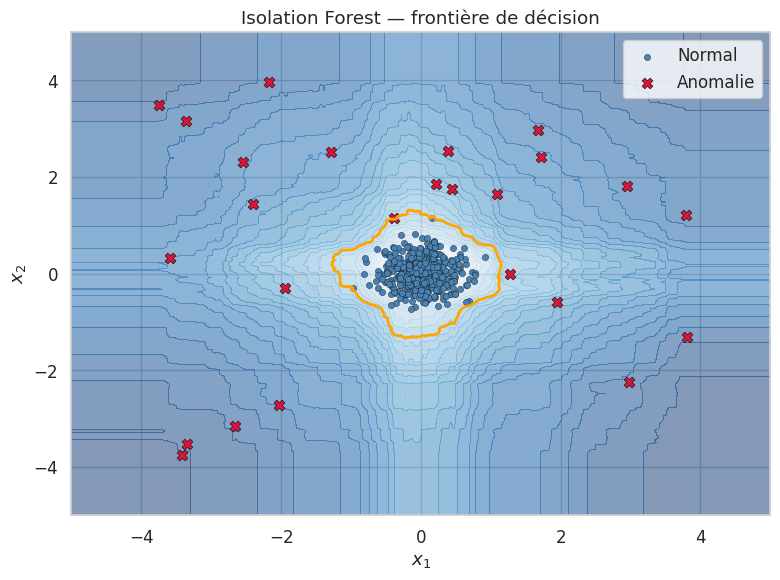
Isolation Forest#
L”Isolation Forest (Liu et al., 2008) repose sur une intuition élégante : plutôt que de modéliser les données normales et de chercher les points qui n’y appartiennent pas, on cherche directement à isoler chaque observation. L’idée clé est que les anomalies, étant rares et différentes, sont plus faciles à isoler que les observations normales.
Principe d’isolation#
Définition 174 (Isolation Tree)
Un arbre d’isolation (isolation tree, iTree) est un arbre binaire construit récursivement de la manière suivante :
Choisir aléatoirement une feature \(q\) parmi les \(d\) features.
Choisir aléatoirement un seuil de coupure \(p\) uniformément entre \(\min(x_q)\) et \(\max(x_q)\).
Diviser les données en deux sous-ensembles selon que \(x_q < p\) ou \(x_q \geq p\).
Répéter récursivement jusqu’à ce que chaque feuille contienne une seule observation ou que la profondeur maximale soit atteinte.
Proposition 44 (Score d’anomalie de l’Isolation Forest)
Soit \(h(\mathbf{x})\) la profondeur (nombre d’arêtes de la racine à la feuille) à laquelle l’observation \(\mathbf{x}\) est isolée dans un arbre d’isolation, et \(E[h(\mathbf{x})]\) la profondeur moyenne sur un ensemble de \(T\) arbres. Le score d’anomalie est défini comme
où \(c(n) = 2H(n-1) - 2(n-1)/n\) est la profondeur moyenne d’un arbre de recherche binaire (BST) avec \(n\) observations, et \(H(k) = \ln(k) + \gamma\) est le \(k\)-ième nombre harmonique (\(\gamma \approx 0{,}5772\) est la constante d’Euler-Mascheroni).
Le score \(s\) vérifie :
\(s \to 1\) quand \(E[h(\mathbf{x})] \to 0\) : l’observation est très rapidement isolée \(\Rightarrow\) anomalie.
\(s \to 0{,}5\) quand \(E[h(\mathbf{x})] \to c(n)\) : profondeur moyenne \(\Rightarrow\) observation normale.
\(s \to 0\) quand \(E[h(\mathbf{x})] \to n-1\) : l’observation est très difficile à isoler.
Remarque 152
L’Isolation Forest ne nécessite pas d’hypothèse sur la distribution des données et fonctionne bien en haute dimension grâce à la sélection aléatoire des features. Sa complexité temporelle est \(\mathcal{O}(T \cdot n \log n)\) pour l’entraînement, ce qui le rend efficace sur de grands jeux de données.
Implémentation avec Scikit-learn#
Remarque 153
Le paramètre contamination de IsolationForest spécifie la proportion attendue d’anomalies dans le jeu de données. Il détermine le seuil appliqué au score d’anomalie pour la classification binaire. Si cette proportion est inconnue, on peut utiliser contamination="auto" (valeur par défaut), qui utilise le seuil théorique du papier original.
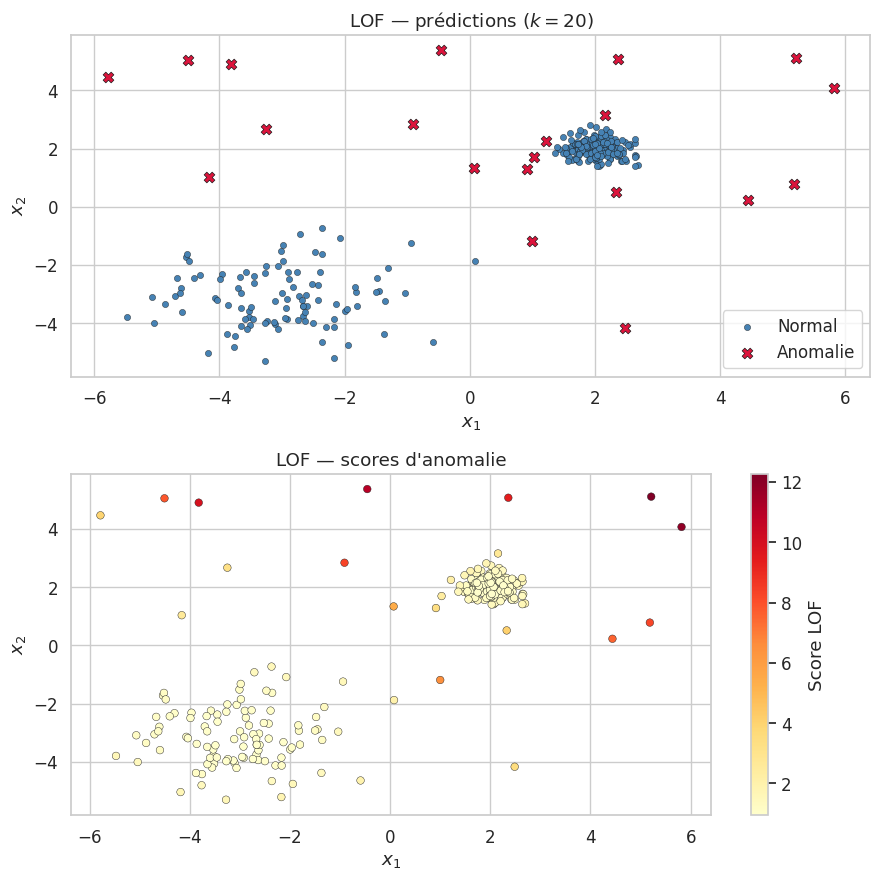
Local Outlier Factor (LOF)#
Le Local Outlier Factor (Breunig et al., 2000) adopte une approche fondamentalement différente : plutôt que de mesurer la distance globale d’un point aux autres, il compare la densité locale d’un point à celle de ses voisins. Un point qui se trouve dans une région de faible densité par rapport à ses voisins est considéré comme une anomalie.
Densité locale et k-distance#
Définition 175 (\(k\)-distance et \(k\)-voisinage)
Soit \(k \in \mathbb{N}^*\) et \(\mathbf{x}\) une observation. La \(k\)-distance de \(\mathbf{x}\), notée \(d_k(\mathbf{x})\), est la distance entre \(\mathbf{x}\) et son \(k\)-ième plus proche voisin. Le \(k\)-voisinage de \(\mathbf{x}\) est l’ensemble
où \(d(\cdot, \cdot)\) est une métrique (typiquement euclidienne). Notons que \(|N_k(\mathbf{x})| \geq k\) car plusieurs points peuvent se trouver à la même distance.
Définition 176 (Distance d’atteignabilité)
La distance d’atteignabilité (reachability distance) de \(\mathbf{x}\) par rapport à \(\mathbf{x}'\) est
Cette distance lisse l’effet des fluctuations statistiques en « repoussant » les voisins très proches à une distance minimale \(d_k(\mathbf{x}')\).
Définition 177 (Densité d’atteignabilité locale)
La densité d’atteignabilité locale (local reachability density) de \(\mathbf{x}\) est
C’est l’inverse de la distance d’atteignabilité moyenne aux \(k\) plus proches voisins. Une densité élevée signifie que le point est dans une zone dense.
Définition 178 (Local Outlier Factor)
Le Local Outlier Factor de \(\mathbf{x}\) est
Le LOF compare la densité locale de \(\mathbf{x}\) à celle de ses voisins :
\(\text{LOF}_k(\mathbf{x}) \approx 1\) : densité similaire aux voisins \(\Rightarrow\) normal.
\(\text{LOF}_k(\mathbf{x}) \gg 1\) : densité beaucoup plus faible que les voisins \(\Rightarrow\) anomalie.
Remarque 154
Le LOF est une mesure locale : un point peut avoir un LOF élevé même s’il est plus dense qu’un point d’un autre cluster, tant qu’il est significativement moins dense que ses propres voisins. C’est cette propriété qui permet au LOF de détecter des anomalies dans des données à densités variables, là où les méthodes globales échouent.
Implémentation avec Scikit-learn#
Remarque 155
Le choix du paramètre \(k\) (nombre de voisins) est critique pour le LOF. Un \(k\) trop petit rend l’algorithme sensible au bruit, tandis qu’un \(k\) trop grand peut masquer les anomalies locales. En pratique, on teste souvent plusieurs valeurs de \(k\) (typiquement entre 10 et 50) et on agrège les résultats, ou on utilise la validation visuelle.
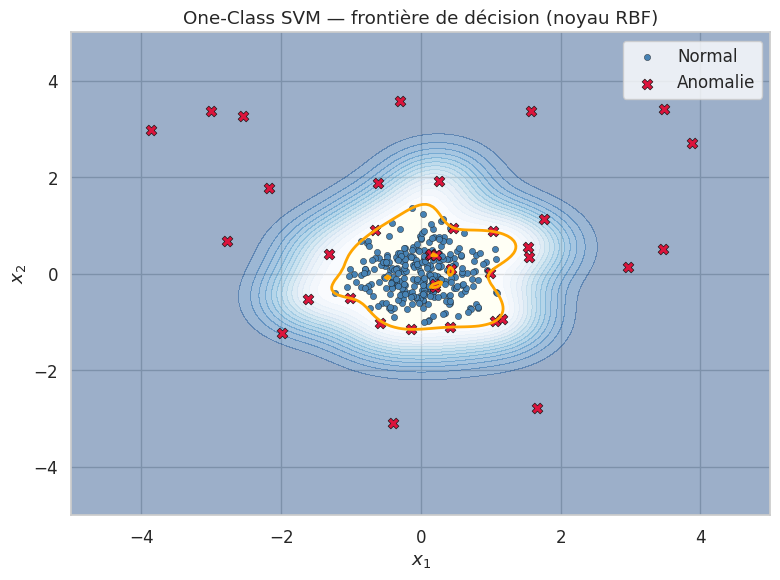
One-Class SVM#
Le One-Class SVM (Schölkopf et al., 2001) adapte l’idée des machines à vecteurs de support au cadre non supervisé. L’objectif est de trouver un hyperplan dans l’espace des features qui sépare les données de l”origine avec une marge maximale. Les observations qui se trouvent du mauvais côté de l’hyperplan sont classées comme anomalies.
Définition 179 (One-Class SVM)
Étant donné un noyau \(K(\cdot, \cdot)\) et une application de features associée \(\phi : \mathbb{R}^d \to \mathcal{H}\) (espace de Hilbert à noyau reproduisant), le One-Class SVM résout le problème d’optimisation suivant :
sous les contraintes
où \(\nu \in (0, 1]\) est un hyperparamètre qui joue un double rôle :
borne supérieure sur la fraction d’anomalies (observations en dehors de la frontière) ;
borne inférieure sur la fraction de vecteurs de support.
Proposition 45 (Fonction de décision du One-Class SVM)
La fonction de décision du One-Class SVM est
où les \(\alpha_i\) sont les coefficients de Lagrange et SV désigne l’ensemble des vecteurs de support. \(f(\mathbf{x}) = +1\) pour les observations normales et \(f(\mathbf{x}) = -1\) pour les anomalies. Avec un noyau RBF \(K(\mathbf{x}, \mathbf{x}') = \exp(-\gamma\|\mathbf{x} - \mathbf{x}'\|^2)\), la frontière de décision est une surface de niveau dans l’espace d’entrée.
Remarque 156
Le paramètre \(\nu\) du One-Class SVM est directement interprétable : il correspond approximativement à la proportion d’anomalies attendue. Cependant, le One-Class SVM est sensible au choix du noyau et de ses hyperparamètres (notamment \(\gamma\) pour le noyau RBF). De plus, sa complexité en \(\mathcal{O}(n^2)\) à \(\mathcal{O}(n^3)\) le rend coûteux sur de grands jeux de données.
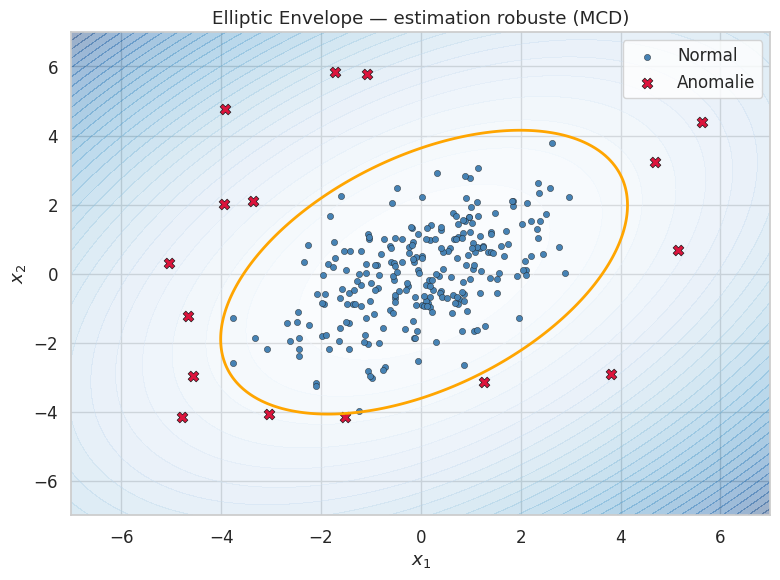
Elliptic Envelope#
L”Elliptic Envelope suppose que les données normales sont issues d’une distribution gaussienne multivariée et identifie les anomalies comme les observations qui se trouvent en dehors d’une ellipse de confiance.
Définition 180 (Elliptic Envelope)
L”Elliptic Envelope estime les paramètres \((\boldsymbol{\mu}, \boldsymbol{\Sigma})\) d’une distribution gaussienne multivariée et utilise la distance de Mahalanobis comme score d’anomalie. L’estimation est rendue robuste par l’algorithme du Minimum Covariance Determinant (MCD) : on cherche le sous-ensemble de \(h\) observations (avec \(h \leq n\)) dont la matrice de covariance empirique a le plus petit déterminant.
Proposition 46 (Minimum Covariance Determinant)
L’estimateur MCD de Rousseeuw (1984) résout
sous la contrainte que \((\boldsymbol{\mu}, \boldsymbol{\Sigma})\) sont la moyenne et la covariance d’un sous-ensemble \(\mathcal{H} \subseteq \mathcal{D}\) de taille \(|\mathcal{H}| = h\), avec \(h = \lceil (n + d + 1) / 2 \rceil\) par défaut. Cet estimateur a un point de rupture (breakdown point) de \((n - h) / n\), ce qui signifie qu’il reste fiable même si jusqu’à \((n - h)\) observations sont des anomalies.
Remarque 157
L’Elliptic Envelope est une méthode simple et interprétable, mais elle repose sur l’hypothèse de normalité des données. Elle fonctionne bien lorsque les données normales sont approximativement unimodales et elliptiques, mais elle échoue sur des distributions multimodales ou non gaussiennes. Dans ce cas, les méthodes précédentes (Isolation Forest, LOF) sont préférables.
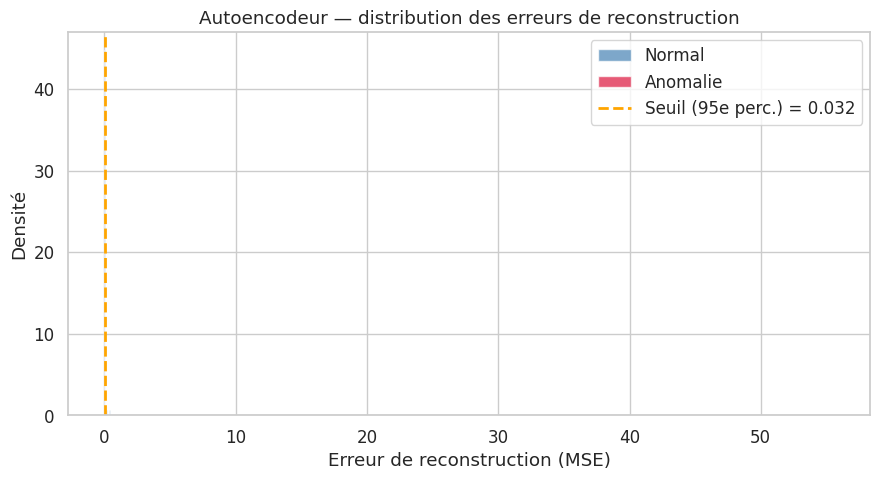
Autoencodeurs pour la détection d’anomalies#
Les autoencodeurs offrent une approche par apprentissage profond pour la détection d’anomalies. L’idée repose sur un principe simple : un autoencodeur entraîné sur des données normales apprendra à bien reconstruire ces données, mais échouera à reconstruire les anomalies, produisant une erreur de reconstruction élevée.
Définition 181 (Autoencodeur pour la détection d’anomalies)
Un autoencodeur est un réseau de neurones composé d’un encodeur \(f_\theta : \mathbb{R}^d \to \mathbb{R}^p\) (avec \(p \ll d\)) et d’un décodeur \(g_\phi : \mathbb{R}^p \to \mathbb{R}^d\), entraîné pour minimiser l’erreur de reconstruction :
Pour la détection d’anomalies, on définit le score d’anomalie d’une observation comme son erreur de reconstruction :
Une observation est classée comme anomalie si \(\text{score}(\mathbf{x}) > \tau\) pour un seuil \(\tau\) choisi, par exemple, comme le quantile à 95 % ou 99 % des erreurs de reconstruction sur l’ensemble d’entraînement.
Remarque 158
L’intuition est la suivante : le goulot d’étranglement (bottleneck) de dimension \(p \ll d\) force l’autoencodeur à apprendre une représentation compacte des données normales. Les anomalies, qui ne partagent pas les mêmes structures que les données normales, sont mal représentées dans cet espace latent et donc mal reconstruites. Les variantes (autoencodeurs variationnels, autoencodeurs débruiteurs) peuvent améliorer les performances. Nous reviendrons en détail sur les architectures d’autoencodeurs au chapitre 21.
Comparaison et recommandations#
Le choix de la méthode de détection d’anomalies dépend de plusieurs facteurs : la dimensionnalité des données, la nature de la distribution, la proportion estimée d’anomalies, et les contraintes computationnelles.
Proposition 47 (Critères de choix)
Les principaux critères pour choisir une méthode de détection d’anomalies sont :
Dimensionnalité : les méthodes statistiques classiques (Z-score, Mahalanobis, Elliptic Envelope) perdent en efficacité en haute dimension. L’Isolation Forest et les autoencodeurs sont mieux adaptés.
Distribution : l’Elliptic Envelope suppose la normalité ; le LOF et l’Isolation Forest sont non paramétriques.
Taille du jeu de données : le One-Class SVM est coûteux pour \(n\) grand ; l’Isolation Forest passe bien à l’échelle.
Interprétabilité : les méthodes statistiques et l’Elliptic Envelope sont les plus interprétables ; l’Isolation Forest offre un score intuitif.
Détection locale vs globale : le LOF excelle pour les anomalies locales ; les autres méthodes sont plutôt globales.
Méthode Type Hypothèses Haute dim. Grand n Détection locale Interprétabilité
Z-score / IQR Statistique Gaussien (univarié) Non Oui Non Élevée
Mahalanobis Statistique Gaussien multiv. Non Oui Non Élevée
Isolation Forest Arbre Aucune Oui Oui Partielle Moyenne
LOF Densité Aucune Modéré Modéré Oui Moyenne
One-Class SVM Marge Aucune Oui (noyau) Non Partielle Faible
Elliptic Envelope Statistique Gaussien multiv. Non Oui Non Élevée
Autoencodeur Réseau de neurones Aucune Oui Oui (GPU) Non Faible
Exemple 13 (Guide de choix rapide)
Données tabulaires, faible dimension, distribution gaussienne \(\Rightarrow\) Elliptic Envelope ou Mahalanobis.
Données tabulaires, haute dimension, grand volume \(\Rightarrow\) Isolation Forest.
Données à densités variables, clusters de tailles différentes \(\Rightarrow\) LOF.
Détection de nouveautés avec un jeu d’entraînement propre \(\Rightarrow\) One-Class SVM ou Isolation Forest.
Données de très haute dimension (images, texte) \(\Rightarrow\) Autoencodeur.
Exemple complet : détection de fraude#
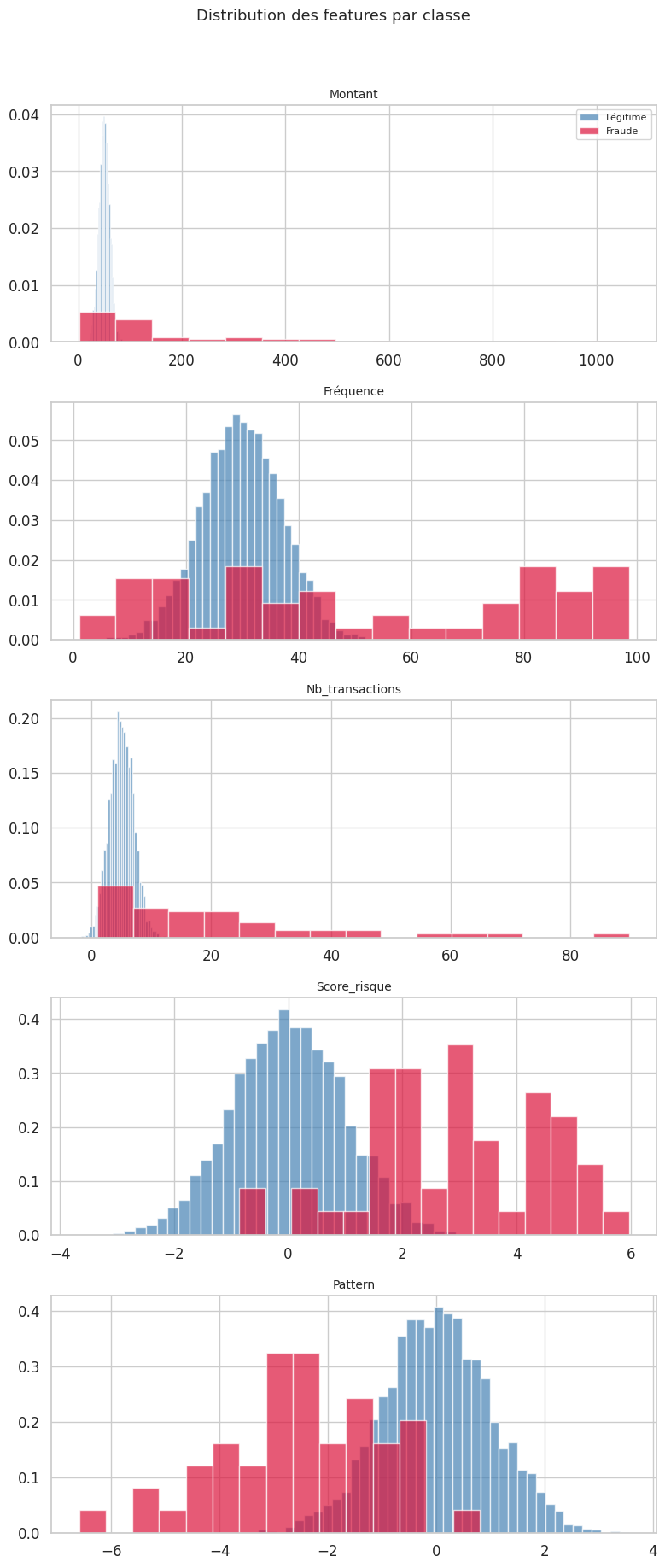
Pour conclure ce chapitre, nous mettons en oeuvre un pipeline complet de détection d’anomalies sur un jeu de données déséquilibré simulant la détection de fraude par carte bancaire. Ce scénario est représentatif des cas réels : les anomalies (fraudes) sont extrêmement rares par rapport aux transactions normales.
Jeu de données : 5050 transactions
- Légitimes : 5000 (99.0 %)
- Fraudes : 50 (1.0 %)
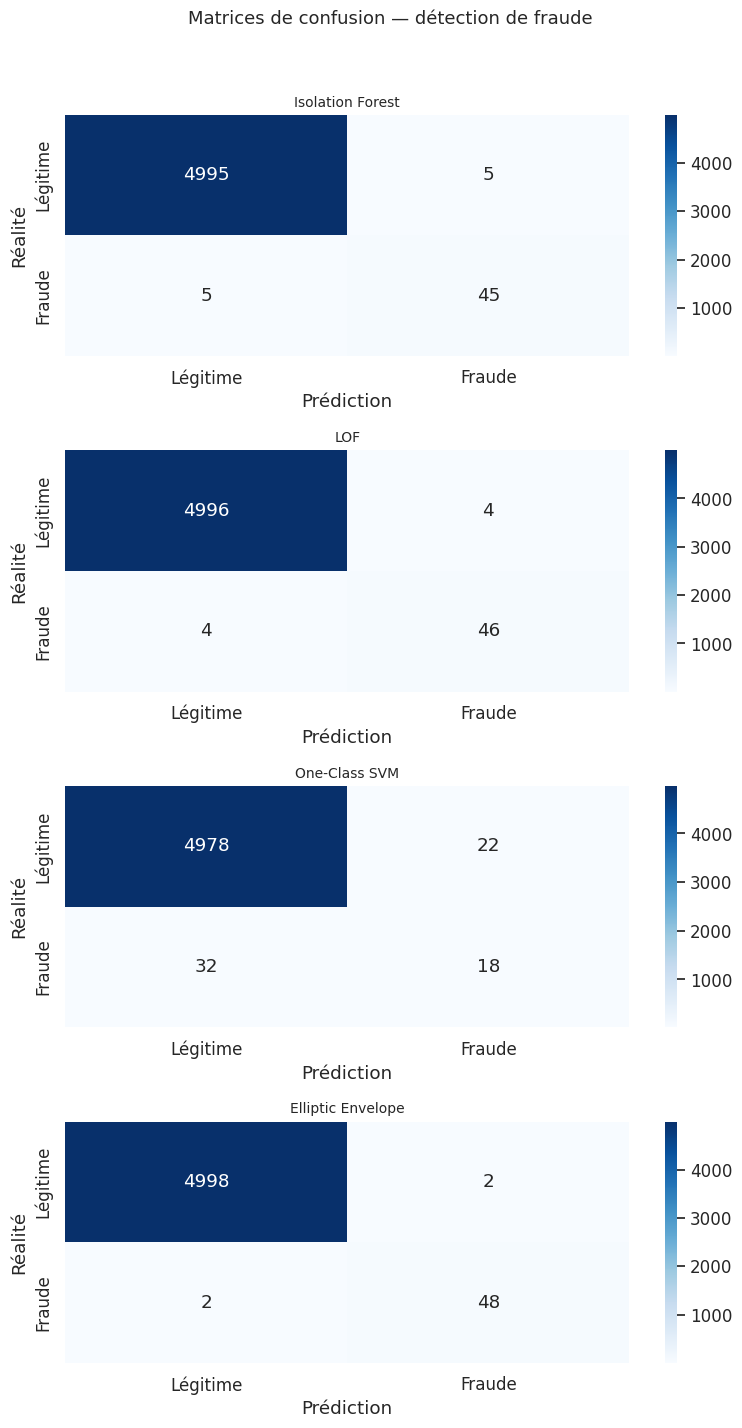
Méthode Precision Recall F1-score
-------------------------------------------------------------
Isolation Forest 0.900 0.900 0.900
LOF 0.920 0.920 0.920
One-Class SVM 0.450 0.360 0.400
Elliptic Envelope 0.960 0.960 0.960
Remarque 159
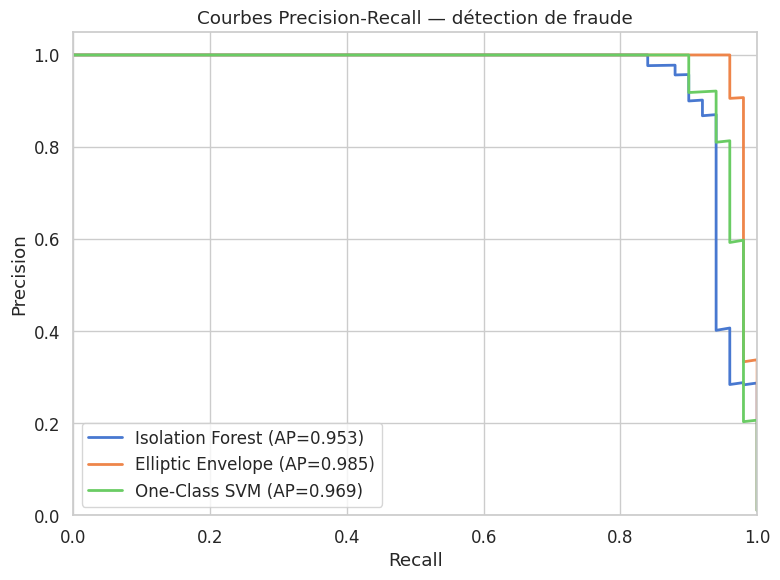
Dans un contexte de détection de fraude, le recall est souvent plus important que la précision : il vaut mieux signaler quelques fausses alertes (faux positifs) que de laisser passer une fraude non détectée (faux négatif). La courbe Precision-Recall et l’Average Precision (AP) sont des métriques plus informatives que l’AUC-ROC lorsque les classes sont très déséquilibrées, car elles ne sont pas biaisées par le grand nombre de vrais négatifs.
Exemple 14 (Bonnes pratiques pour la détection d’anomalies en production)
Standardiser les features avant d’appliquer les algorithmes (surtout LOF, One-Class SVM, Elliptic Envelope).
Estimer le taux de contamination si possible, ou utiliser des valeurs conservatrices.
Combiner plusieurs méthodes : un point détecté comme anomalie par plusieurs algorithmes est plus probablement une vraie anomalie.
Évaluer sur des données étiquetées quand elles sont disponibles, en utilisant les métriques adaptées aux classes déséquilibrées (Precision, Recall, F1 sur la classe minoritaire, AP).
Surveiller la dérive (drift) : la distribution des données normales peut évoluer dans le temps, nécessitant un réentraînement régulier des modèles.
Résumé#
Ce chapitre a présenté les principales méthodes de détection d’anomalies, des approches statistiques classiques aux algorithmes d’apprentissage automatique modernes. Chaque méthode repose sur une vision différente de ce qui constitue une anomalie :
Les approches statistiques (Z-score, IQR, Mahalanobis) modélisent la distribution des données normales et détectent les points de faible probabilité.
L”Isolation Forest exploite le fait que les anomalies sont plus faciles à isoler par des coupures aléatoires.
Le LOF compare la densité locale d’un point à celle de ses voisins, capturant les anomalies locales.
Le One-Class SVM sépare les données de l’origine dans un espace de features de haute dimension.
L”Elliptic Envelope ajuste une ellipse robuste aux données en supposant la normalité.
Les autoencodeurs détectent les anomalies via l’erreur de reconstruction.
Le choix de la méthode dépend de la nature des données, de leur dimensionnalité, du volume disponible et des contraintes applicatives. En pratique, combiner plusieurs approches et valider sur des données étiquetées (lorsqu’elles existent) est la stratégie la plus fiable. Le chapitre suivant poursuivra l’exploration de l’apprentissage non supervisé avec les méthodes de réduction de dimension.