
K plus proches voisins#
Dis-moi qui sont tes voisins, je te dirai qui tu es.
Proverbe librement adapté
L’algorithme des K plus proches voisins (K-Nearest Neighbors, KNN) est l’un des algorithmes les plus intuitifs de l’apprentissage automatique. Son principe est d’une simplicité désarmante : pour prédire la classe ou la valeur d’une nouvelle observation, on regarde les \(k\) observations du jeu d’entraînement qui lui ressemblent le plus, et on agrège leurs étiquettes. Malgré cette simplicité, KNN est un algorithme puissant qui peut capturer des frontières de décision arbitrairement complexes.
Apprentissage par instances#
KNN appartient à la famille des méthodes d”apprentissage par instances (instance-based learning), aussi appelées méthodes à mémoire (memory-based). Contrairement aux algorithmes paramétriques (régression linéaire, régression logistique), qui apprennent un ensemble fini de paramètres à partir des données d’entraînement puis oublient les données elles-mêmes, KNN conserve l’intégralité du jeu d’entraînement en mémoire et s’en sert directement au moment de la prédiction.
Remarque 74
On qualifie souvent KNN d’algorithme paresseux (lazy learner), par opposition aux algorithmes avides (eager learners) comme les réseaux de neurones ou les SVM. Un eager learner investit du temps dans la phase d’entraînement pour construire un modèle compact. Un lazy learner reporte tout le calcul à la phase de prédiction. Concrètement, la phase d’entraînement de KNN est quasi-instantanée (il suffit de stocker les données), mais chaque prédiction peut être coûteuse car elle nécessite de parcourir toutes les observations.
Cette caractéristique a des conséquences pratiques importantes :
Pas de phase d’entraînement (au sens classique) : le modèle est le jeu de données lui-même.
Prédictions coûteuses : chaque nouvelle observation requiert le calcul de la distance à tous les points d’entraînement, soit \(\mathcal{O}(n \cdot d)\) opérations pour \(n\) observations en dimension \(d\).
Sensibilité au bruit : les points aberrants dans le voisinage peuvent perturber les prédictions.
Pas d’interprétabilité globale : il n’y a pas de modèle explicite (pas de coefficients, pas de règles), seulement des décisions locales.
Algorithme KNN#
Formalisation#
Définition 82 (Algorithme des K plus proches voisins)
Soit un jeu d’entraînement \(\mathcal{D} = \{(\mathbf{x}_1, y_1), \ldots, (\mathbf{x}_n, y_n)\}\) où \(\mathbf{x}_i \in \mathbb{R}^d\) et \(y_i\) est l’étiquette (classe ou valeur) associée. Soit \(d(\cdot, \cdot)\) une fonction de distance sur \(\mathbb{R}^d\) et \(k \in \mathbb{N}^*\) un entier fixé.
Pour une nouvelle observation \(\mathbf{x}\), l’algorithme KNN :
Calcule les distances \(d(\mathbf{x}, \mathbf{x}_i)\) pour tout \(i \in \{1, \ldots, n\}\).
Sélectionne les \(k\) observations \(\mathbf{x}_{(1)}, \ldots, \mathbf{x}_{(k)}\) les plus proches de \(\mathbf{x}\) (les \(k\) plus proches voisins).
Agrège les étiquettes \(y_{(1)}, \ldots, y_{(k)}\) pour produire la prédiction \(\hat{y}\).
La méthode d’agrégation au point 3 dépend du type de problème : classification ou régression.
Classification par vote majoritaire#
Définition 83 (KNN en classification)
En classification, la prédiction est la classe la plus fréquente parmi les \(k\) plus proches voisins :
où \(\mathcal{C}\) est l’ensemble des classes et \(\mathbb{1}(\cdot)\) est la fonction indicatrice.
Remarque 75
En cas d’égalité (par exemple, 2 voisins de classe A et 2 de classe B pour \(k=4\)), différentes stratégies existent : choisir la classe du voisin le plus proche parmi les ex-aequo, tirer au hasard, ou utiliser un \(k\) impair pour les problèmes binaires. Dans scikit-learn, l’implémentation retourne la classe qui apparaît en premier dans l’ordre de parcours en cas d’égalité.
Régression par moyenne#
Définition 84 (KNN en régression)
En régression, la prédiction est la moyenne des valeurs cibles des \(k\) plus proches voisins :
Remarque 76
Une variante courante consiste à pondérer les contributions par l’inverse de la distance, accordant ainsi plus d’influence aux voisins les plus proches :
Cette pondération atténue l’influence de voisins éloignés qui se trouvent à la limite du voisinage, ce qui produit généralement des prédictions plus lisses.
Illustrons le fonctionnement de KNN sur un exemple simple en deux dimensions.
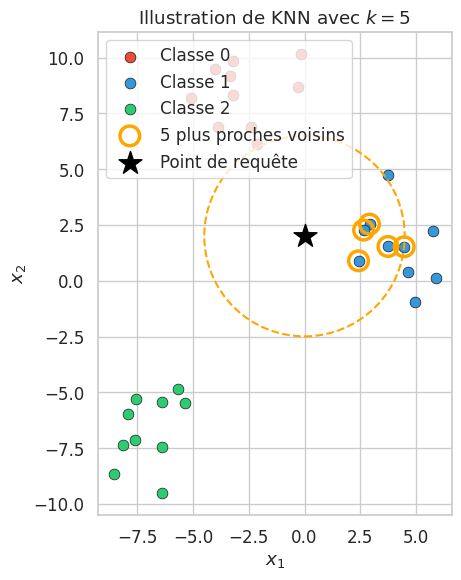
Classes des 5 voisins : [1 1 1 1 1]
Prédiction (vote majoritaire) : classe 1
Distances#
Le choix de la fonction de distance est un paramètre fondamental de KNN. La distance détermine la notion de « proximité » entre observations, et donc quels voisins seront sélectionnés.
Distance euclidienne#
Définition 85 (Distance euclidienne)
La distance euclidienne (ou norme \(L^2\)) entre deux vecteurs \(\mathbf{x}, \mathbf{y} \in \mathbb{R}^d\) est
C’est la distance « en ligne droite » dans l’espace euclidien, généralisation du théorème de Pythagore.
La distance euclidienne est le choix par défaut dans la plupart des implémentations de KNN. Elle est appropriée lorsque les features sont de même nature et de même échelle.
Distance de Manhattan#
Définition 86 (Distance de Manhattan)
La distance de Manhattan (ou norme \(L^1\), ou distance du taxi) est
Elle correspond au chemin le plus court en se déplaçant uniquement le long des axes, comme dans un réseau de rues à angle droit.
Remarque 77
La distance de Manhattan est plus robuste aux valeurs aberrantes que la distance euclidienne, car elle ne met pas au carré les écarts. Un écart important sur une seule dimension aura un impact linéaire (et non quadratique) sur la distance totale.
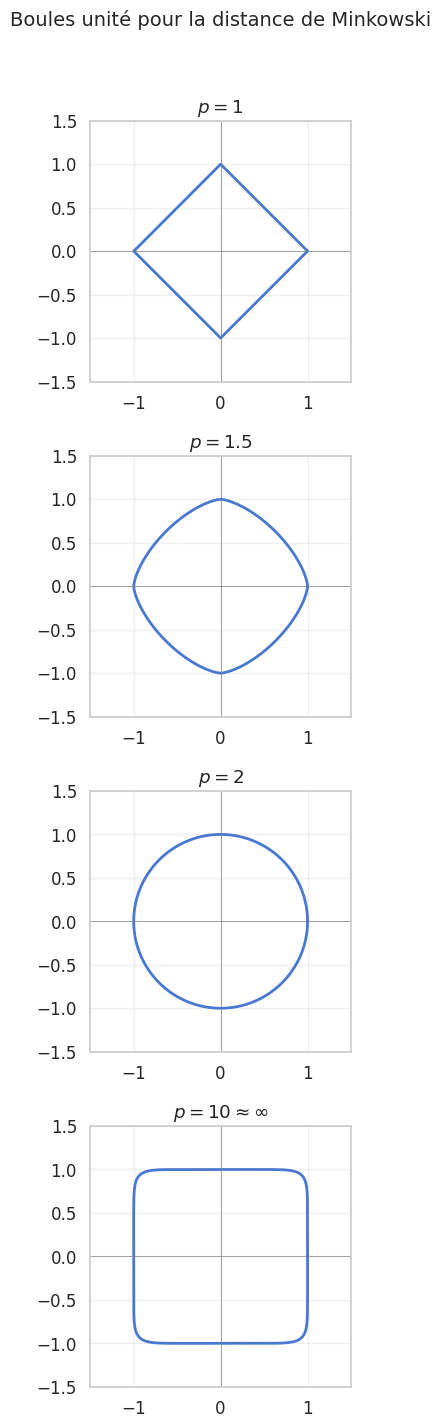
Distance de Minkowski#
Définition 87 (Distance de Minkowski)
La distance de Minkowski d’ordre \(p\) (avec \(p \geq 1\)) généralise les distances précédentes :
On retrouve :
\(p = 1\) : distance de Manhattan
\(p = 2\) : distance euclidienne
\(p \to \infty\) : distance de Tchebychev \(d_\infty(\mathbf{x}, \mathbf{y}) = \max_{i} |x_i - y_i|\)
Proposition 16 (Propriétés d’une distance)
Toute distance \(d\) sur un espace \(E\) vérifie les quatre axiomes suivants pour tout \(\mathbf{x}, \mathbf{y}, \mathbf{z} \in E\) :
Non-négativité : \(d(\mathbf{x}, \mathbf{y}) \geq 0\)
Identité : \(d(\mathbf{x}, \mathbf{y}) = 0 \iff \mathbf{x} = \mathbf{y}\)
Symétrie : \(d(\mathbf{x}, \mathbf{y}) = d(\mathbf{y}, \mathbf{x})\)
Inégalité triangulaire : \(d(\mathbf{x}, \mathbf{z}) \leq d(\mathbf{x}, \mathbf{y}) + d(\mathbf{y}, \mathbf{z})\)
Les distances de Minkowski (pour \(p \geq 1\)) satisfont ces quatre propriétés et sont donc des distances au sens métrique.
Visualisons les « cercles unités » (ensembles de points à distance 1 de l’origine) pour différentes valeurs de \(p\).
Choix de k#
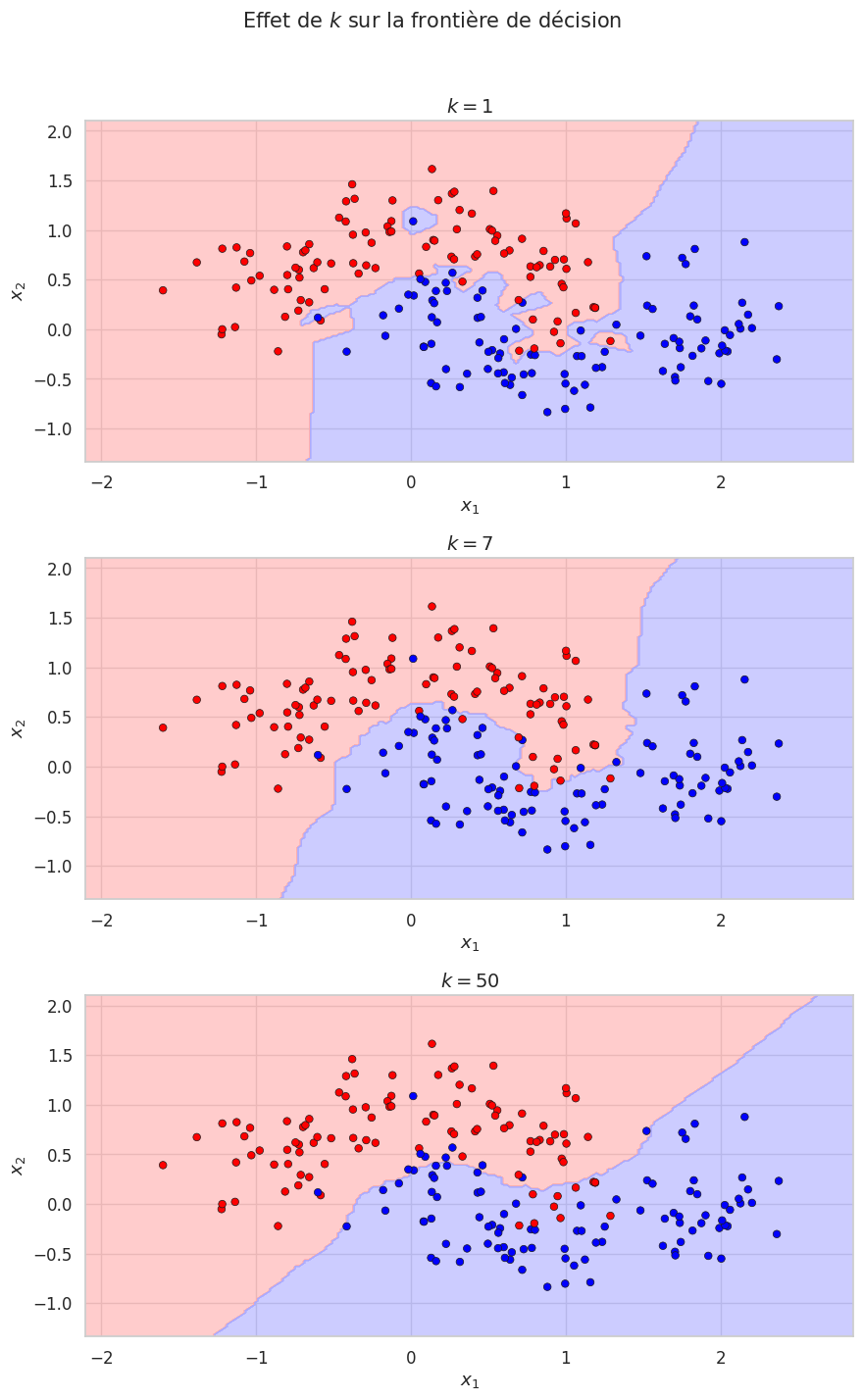
Le choix de l’hyperparamètre \(k\) est crucial : il contrôle le compromis entre biais et variance du modèle.
Définition 88 (Compromis biais-variance pour KNN)
\(k\) petit (ex. \(k=1\)) : le modèle est très flexible. La frontière de décision est irrégulière, épousant les particularités locales des données. Le biais est faible (le modèle peut capturer des structures complexes), mais la variance est élevée (le modèle est très sensible au bruit et aux fluctuations d’échantillonnage).
\(k\) grand (ex. \(k=n\)) : le modèle est très rigide. La frontière de décision est lisse, moyennant les informations d’un grand voisinage. Le biais est élevé (le modèle peut manquer des structures locales), mais la variance est faible (les prédictions sont stables).
Remarque 78
Pour un problème de classification binaire, on choisit typiquement \(k\) impair afin d’éviter les situations d’égalité dans le vote majoritaire.
Illustrons l’effet de \(k\) sur la frontière de décision.
Méthode du coude#
Pour choisir \(k\) de manière systématique, on peut tracer l’erreur de validation en fonction de \(k\) et chercher un « coude » : la valeur de \(k\) à partir de laquelle l’erreur cesse de diminuer significativement.
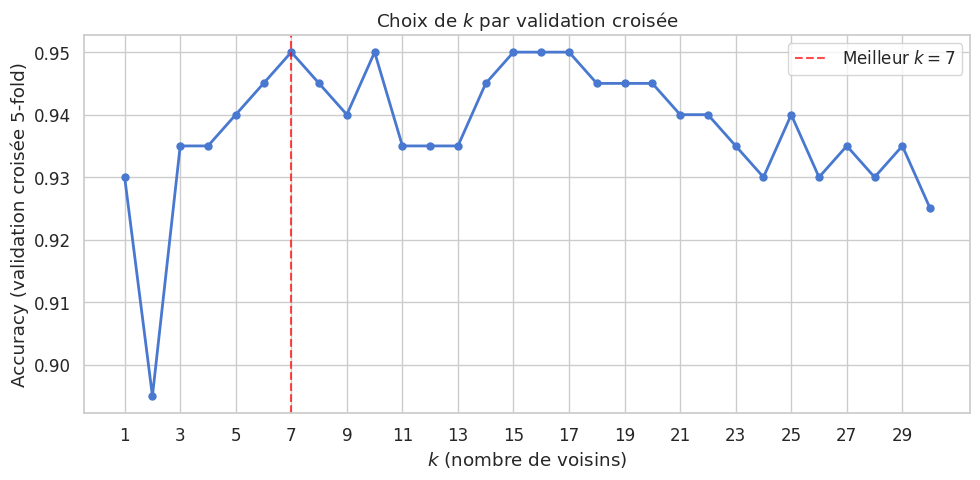
Meilleure accuracy : 0.9500 pour k = 7
Proposition 17 (Règles pratiques pour le choix de k)
Commencer par \(k = \sqrt{n}\) (où \(n\) est le nombre d’observations d’entraînement) comme point de départ.
Utiliser la validation croisée pour comparer plusieurs valeurs de \(k\).
Pour la classification binaire, préférer un \(k\) impair.
Un \(k\) trop petit conduit au surapprentissage ; un \(k\) trop grand conduit au sous-apprentissage.
Malédiction de la dimensionnalité#
La malédiction de la dimensionnalité (curse of dimensionality) est un phénomène fondamental qui affecte particulièrement les méthodes basées sur la distance, dont KNN.
Définition 89 (Malédiction de la dimensionnalité)
La malédiction de la dimensionnalité désigne l’ensemble des phénomènes contre-intuitifs qui apparaissent lorsque la dimension \(d\) de l’espace des features augmente. En particulier, dans un espace de grande dimension, les notions de distance et de voisinage deviennent progressivement dénuées de sens.
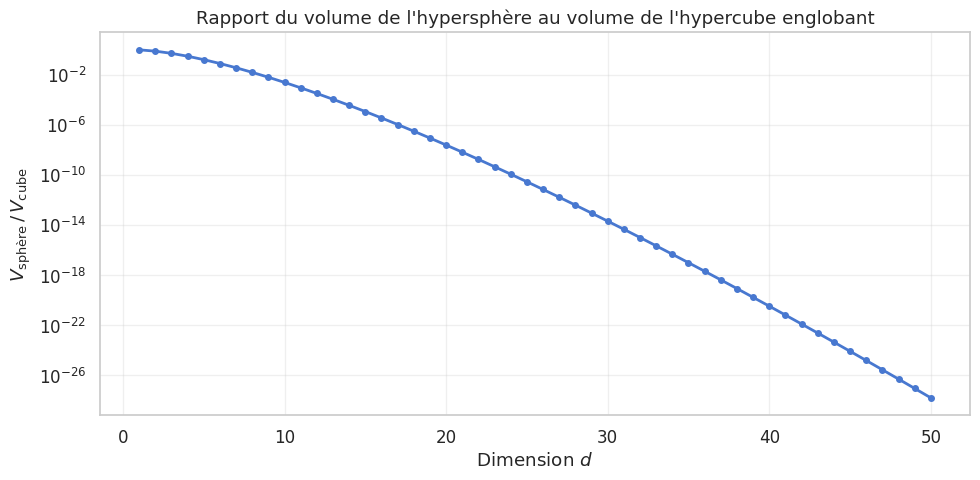
Volume de l’hypersphère#
Pour comprendre pourquoi, examinons le volume d’une hypersphère.
Proposition 18 (Volume de l’hypersphère)
Le volume d’une hypersphère de rayon \(r\) en dimension \(d\) est
où \(\Gamma\) est la fonction gamma d’Euler. Pour les premières dimensions : \(V_1(r) = 2r\), \(V_2(r) = \pi r^2\), \(V_3(r) = \frac{4}{3}\pi r^3\).
Un résultat remarquable est que le rapport entre le volume de l’hypersphère et celui de l’hypercube qui la contient tend vers zéro quand \(d\) augmente :
Cela signifie que la quasi-totalité du volume de l’espace se concentre dans les « coins », loin du centre.
Conséquences pour KNN#
Remarque 79
En haute dimension, les conséquences pour KNN sont dramatiques :
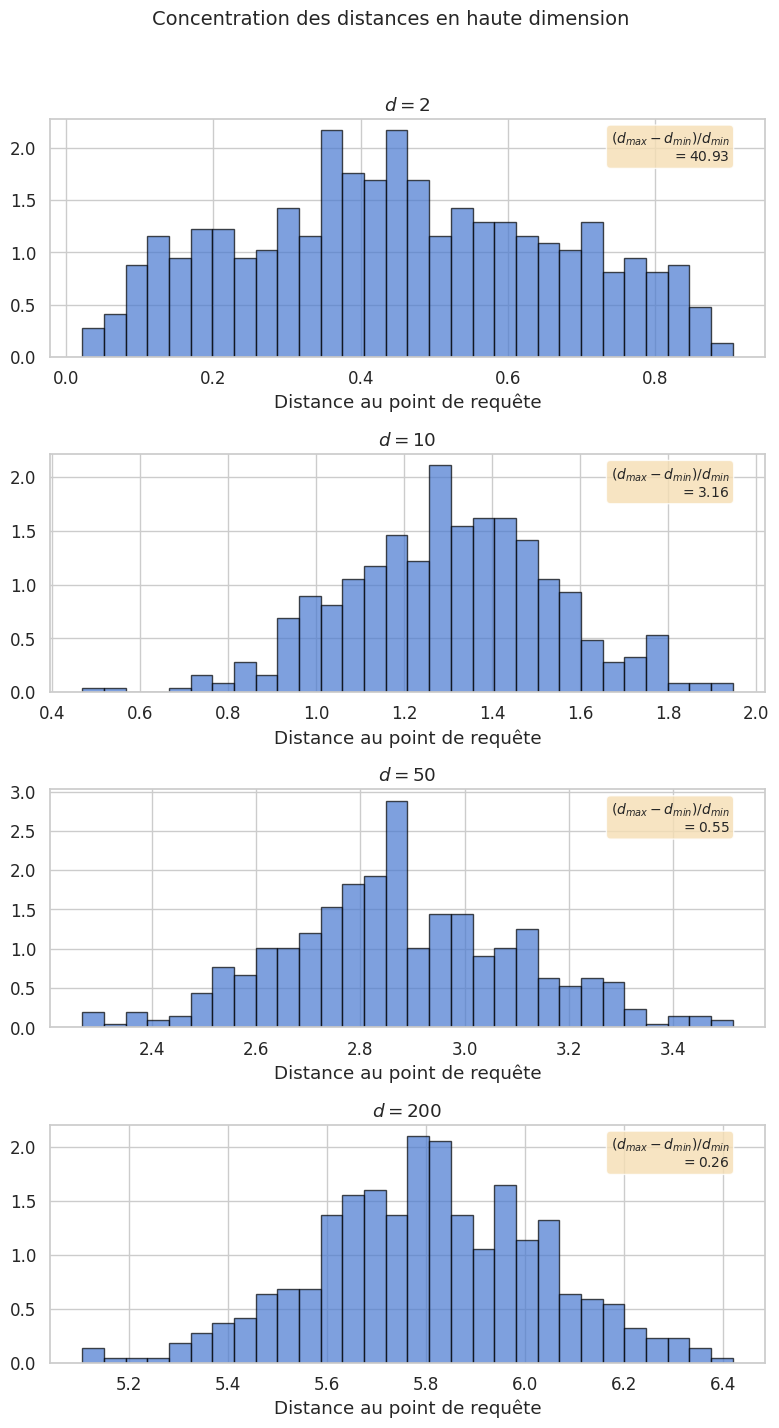
Les distances se concentrent : la différence relative entre le point le plus proche et le plus éloigné diminue. Formellement, si \(d_{\min}\) et \(d_{\max}\) sont les distances minimale et maximale à un point de requête :
Les « plus proches voisins » ne sont plus significativement plus proches que les autres points.
Les données deviennent éparses : pour maintenir une densité locale constante, le nombre d’observations nécessaire croît exponentiellement avec \(d\). Si \(n = 100\) observations suffisent en 2D, il en faut \(100^{d/2}\) en dimension \(d\).
Les frontières de décision deviennent instables : comme les voisins ne sont plus réellement « proches », les prédictions deviennent quasi-aléatoires.
Illustrons la concentration des distances en augmentant la dimension.
Proposition 19 (Atténuation de la malédiction)
Pour contrer la malédiction de la dimensionnalité dans le cadre de KNN :
Réduction de dimension : appliquer PCA, t-SNE, UMAP, ou une sélection de features avant d’utiliser KNN.
Sélection de features : ne conserver que les variables pertinentes (tests statistiques, importance par forêt aléatoire, etc.).
Distances adaptées : utiliser des métriques qui pondèrent les dimensions par leur pertinence.
Augmenter le jeu de données : si possible, collecter davantage d’observations.
Normalisation des features#
KNN repose entièrement sur le calcul de distances. Or, si les features ne sont pas à la même échelle, celles dont les valeurs sont numériquement plus grandes domineront le calcul de distance.
Exemple 8
Considérons deux features : l”âge (entre 20 et 70) et le revenu annuel (entre 20 000 et 100 000 euros). La différence de revenu entre deux individus sera systématiquement plus grande que la différence d’âge, même si l’âge est une variable plus discriminante. Sans normalisation, KNN ignorera quasiment l’âge.
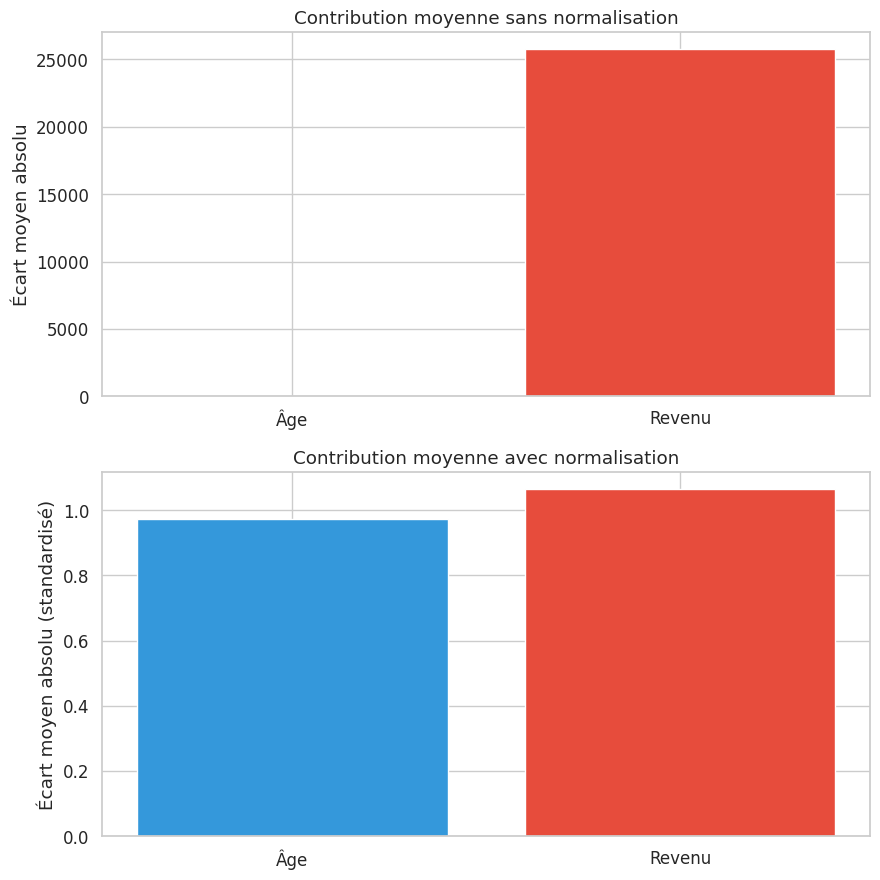
Sans normalisation — contribution de l'âge : 12, du revenu : 25757
Le revenu domine la distance par un facteur 2069
Remarque 80
La normalisation est indispensable pour KNN (et pour tout algorithme basé sur la distance : SVM, k-means, etc.). Les deux approches les plus courantes sont :
Standardisation (z-score) : \(x' = (x - \mu) / \sigma\). Chaque feature a une moyenne nulle et un écart-type unitaire.
Normalisation Min-Max : \(x' = (x - x_{\min}) / (x_{\max} - x_{\min})\). Chaque feature est projetée dans \([0, 1]\).
Comme toujours, la normalisation doit être ajustée (fit) sur les données d’entraînement uniquement et appliquée (transform) aux données de test pour éviter la fuite de données.
Exemple complet avec scikit-learn#
Mettons en pratique l’ensemble des concepts sur un problème complet : classification du jeu de données Iris avec KNN, incluant normalisation, recherche d’hyperparamètre et visualisation de la frontière de décision.
Dimensions : (150, 4)
Classes : [np.str_('setosa'), np.str_('versicolor'), np.str_('virginica')]
Distribution : [50 50 50]
Entraînement : 105 observations
Test : 45 observations
Meilleurs hyperparamètres : {'knn__metric': 'euclidean', 'knn__n_neighbors': 14, 'knn__weights': 'uniform'}
Meilleure accuracy (CV) : 0.9714
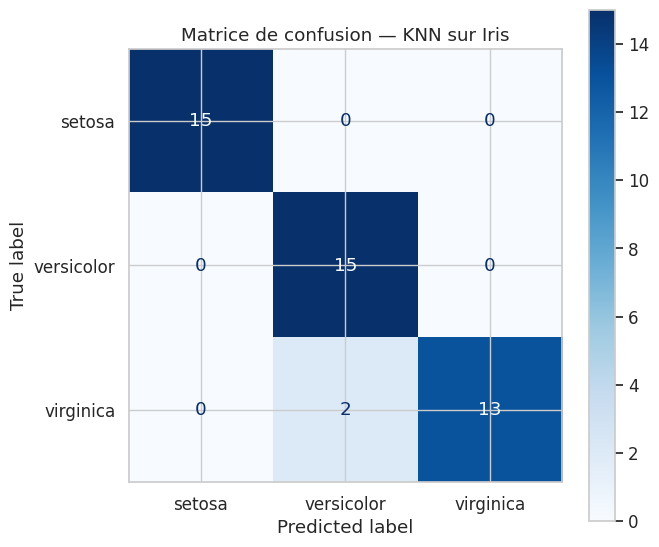
Rapport de classification :
precision recall f1-score support
setosa 1.00 1.00 1.00 15
versicolor 0.88 1.00 0.94 15
virginica 1.00 0.87 0.93 15
accuracy 0.96 45
macro avg 0.96 0.96 0.96 45
weighted avg 0.96 0.96 0.96 45
Frontière de décision (2D)#
Pour visualiser la frontière de décision, nous projetons les données sur les deux features les plus discriminantes.
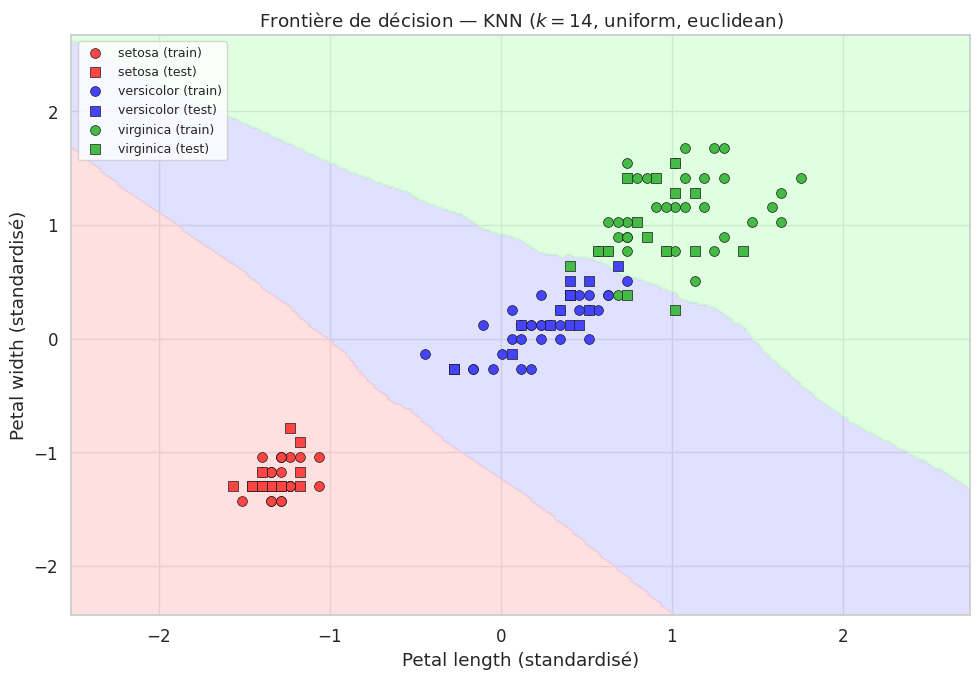
Accuracy sur le test (2 features) : 0.9111
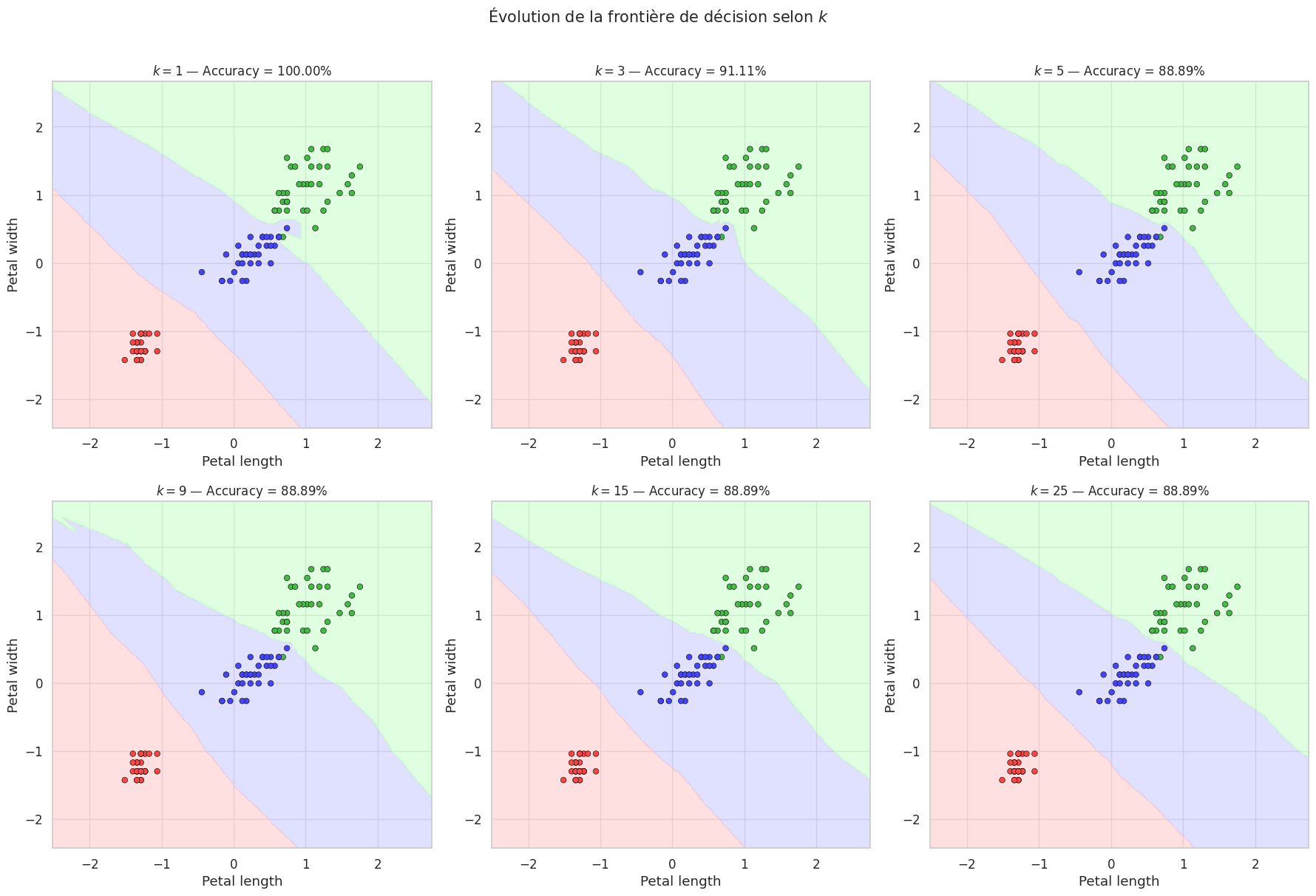
Comparaison des valeurs de k#
Remarque 81
On observe clairement le compromis biais-variance :
Pour \(k=1\), la frontière est très irrégulière et colle aux données d’entraînement (surapprentissage).
Pour \(k\) élevé, la frontière se lisse et les zones de décision deviennent plus larges (sous-apprentissage potentiel).
Les valeurs intermédiaires offrent généralement le meilleur compromis.
KNN en régression#
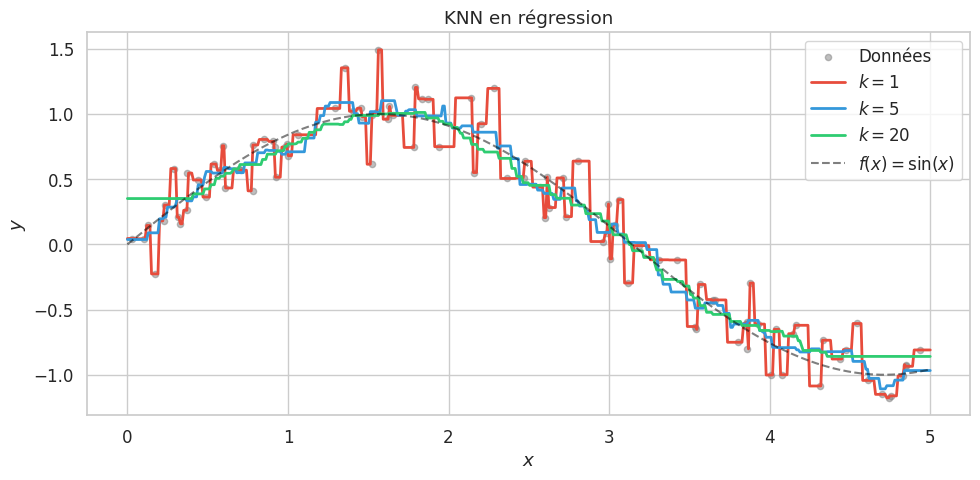
Pour conclure, montrons brièvement l’utilisation de KNN en régression.
Remarque 82
En régression, les mêmes principes s’appliquent :
\(k=1\) produit une courbe en escalier qui interpole exactement les données (surapprentissage).
\(k\) élevé produit une courbe très lisse qui peut manquer les variations de la fonction cible (sous-apprentissage).
La pondération par l’inverse de la distance (
weights='distance') produit des prédictions plus lisses que le vote uniforme.