
Arbres de décision#
L’essence de la connaissance, c’est d’en avoir et de l’appliquer ; c’est de ne pas en avoir et de le reconnaître.
Confucius
Les arbres de décision (decision trees) sont parmi les modèles les plus intuitifs de l’apprentissage automatique. Leur principe est simple : partitionner récursivement l’espace des features par des questions binaires successives, jusqu’à obtenir des regions suffisamment homogènes pour effectuer une prédiction. Le résultat est une structure arborescente lisible, interprétable, et directement traduisible en règles logiques.
Ce chapitre couvre la construction, les critères de division, l’algorithme CART, l’élagage, l’extension à la régression, l’interpretabilité, et l’instabilité inhérente de ces modèles – instabilité qui motivera les méthodes d’ensemble du chapitre suivant.
Introduction#
Pourquoi les arbres ?#
Les modèles linéaires (régression logistique, SVM linéaire) supposent une frontière de décision linéaire. En pratique, de nombreux problèmes présentent des frontières non linéaires, des intéractions entre variables, ou des relations conditionnelles que les modèles linéaires ne capturent pas sans ingénierie de features explicite.
Les arbres de décision offrent plusieurs avantages :
Interpretabilité : un arbre se lit comme une suite de questions oui/non, compréhensible par un non-spécialiste
Pas de prétraitement : les arbres sont insensibles à l’échelle des variables (pas besoin de standardisation) et gèrent naturellement les variables categorielles
Intéractions automatiques : la structure hiérarchique capture les intéractions entre variables sans les spécifier explicitement
Non-linéarité : les frontières de décision sont des hyperplans parallèles aux axes, permettant d’approximer des frontières complexes
Remarque 83
Les arbres de décision sont le fondement de nombreux algorithmes parmi les plus performants en pratique : forêts aléatoires, gradient boosting (XGBoost, LightGBM, CatBoost). Comprendre les arbres est donc un prérequis indispensable pour aborder les méthodes d’ensemble.
Principe général#
Un arbre de décision binaire est un arbre enraciné dans lequel :
chaque noeud interne effectue un test sur une feature (\(x_j \leq s\) pour une variable continue, \(x_j = c\) pour une variable catégorielle)
chaque branche correspond au résultat du test (oui/non, gauche/droite)
chaque feuille contient une prédiction (la classe majoritaire en classification, la moyenne en regression)
Définition 90 (Arbre de décision)
Un arbre de décision est une fonction \(f : \mathbb{R}^p \to \mathcal{Y}\) définie par une partition récursive de l’espace des features \(\mathcal{X} = \mathbb{R}^p\) en régions \(R_1, R_2, \ldots, R_T\) (les feuilles), avec une prédiction constante \(c_t\) dans chaque region :
En classification, \(c_t\) est la classe majoritaire dans \(R_t\). En régression, \(c_t = \bar{y}_t = \frac{1}{|R_t|} \sum_{i : \mathbf{x}_i \in R_t} y_i\).
Construction par partitionnement récursif#
Principe#
La construction d’un arbre procède par partitionnement récursif (recursive partitioning). A chaque noeud, on cherche la meilleure division (split) de l’espace en deux sous-régions, selon un critère de qualité. L’algorithme est glouton : à chaque etape, il choisit la division localement optimale, sans garantie d’optimalité globale.
Définition 91 (Division binaire)
Soit un noeud contenant un ensemble d’observations \(\mathcal{D} = \{(\mathbf{x}_i, y_i)\}_{i=1}^n\). Une division binaire est définie par une feature \(j\) et un seuil \(s\) (pour une variable continue), partitionnant \(\mathcal{D}\) en :
La division optimale est celle qui maximise la réduction d’impureté :
où \(I(\cdot)\) est une mesure d’impureté.
Algorithme de construction#
L’algorithme de construction suit une procédure récursive :
Si un critère d’arrêt est satisfait, créer une feuille avec la prédiction appropriée
Sinon, pour chaque feature \(j\) et chaque seuil candidat \(s\), calculer la réduction d’impureté
Effectuer la division \((j^*, s^*)\) qui maximise cette réduction
Appliquer récursivement la procédure aux deux sous-ensembles \(\mathcal{D}_G\) et \(\mathcal{D}_D\)
Remarque 84
Pour une variable continue à \(n\) valeurs distinctes, il y a \(n - 1\) seuils candidats (les points milieux entre valeurs consecutives ordonnées). Pour \(p\) features, chaque noeud évalue donc \(O(p \cdot n)\) divisions possibles. La complexité totale de la construction est \(O(p \cdot n \cdot \log n)\) en moyenne (car la profondeur est typiquement \(O(\log n)\)), mais \(O(p \cdot n^2)\) dans le pire cas (arbre dégénéré).
Critères d’impureté#
Le choix du critère d’impureté détermine comment l’arbre évalue la qualité d’une division. En classification, les deux critères principaux sont l’indice de Gini et l’entropie de Shannon.
Indice de Gini#
Définition 92 (Indice de Gini)
Soit un noeud contenant \(n\) observations réparties en \(K\) classes, avec des proportions \(p_k = \frac{n_k}{n}\) pour la classe \(k\). L”indice de Gini est défini par :
L’indice de Gini mesure la probabilité qu’une observation choisie aléatoirement soit mal classée si on lui attribue une classe tirée selon la distribution empirique du noeud.
\(G = 0\) : le noeud est pur (toutes les observations appartiennent à la même classe)
\(G\) est maximal (\(= 1 - 1/K\)) lorsque les classes sont équiprobables
Exemple 9
Pour un problème binaire (\(K = 2\)) avec des proportions \(p_1 = 0.8\) et \(p_2 = 0.2\) :
Pour un noeud pur (\(p_1 = 1\)) : \(G = 1 - 1 = 0\).
Pour un noeud parfaitement mixte (\(p_1 = p_2 = 0.5\)) : \(G = 1 - (0.25 + 0.25) = 0.5\).
Entropie de Shannon#
Définition 93 (Entropie de Shannon)
L”entropie de Shannon (ou entropie d’information) d’un noeud est définie par :
avec la convention \(0 \log_2 0 = 0\).
L’entropie mesure le degré d’incertitude (ou de désordre) de la distribution des classes dans le noeud :
\(H = 0\) : le noeud est pur
\(H\) est maximale (\(= \log_2 K\)) lorsque les classes sont équiprobables
Gain d’information#
Définition 94 (Gain d’information)
Le gain d’information (information gain) d’une division est la réduction d’entropie :
C’est la quantité d’information apportée par la connaissance de la feature \(j\) et du seuil \(s\). La division optimale est celle qui maximise le gain d’information.
Remarque 85
En pratique, l’indice de Gini et l’entropie produisent des arbres très similaires. L’indice de Gini est le critère par défaut de Scikit-learn car il est légèrement plus rapide à calculer (pas de logarithme). L’entropie tend à produire des arbres légèrement plus equilibres.
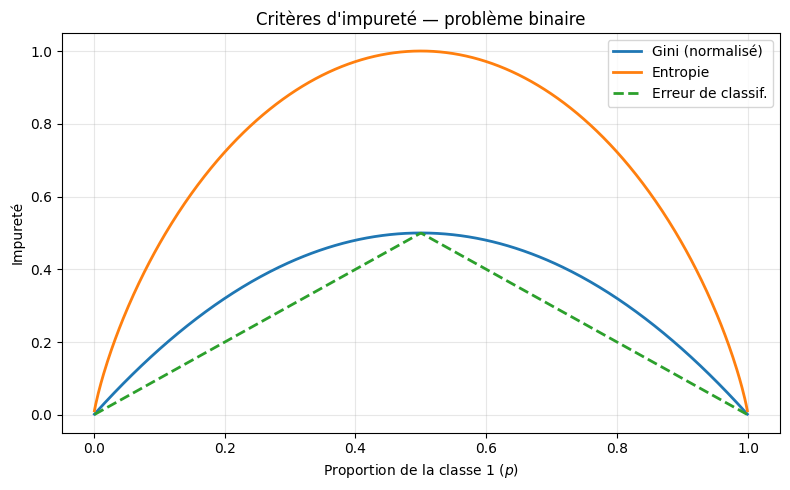
Visualisons les deux critères pour un problème binaire.
Remarque 86
Les trois critères atteignent leur minimum (0) aux extrémités (\(p = 0\) et \(p = 1\)) et leur maximum a \(p = 0.5\). L’erreur de classification est linéaire par morceaux et moins sensible aux changements de probabilité près des extrémités, ce qui la rend moins discriminante pour choisir les divisions. C’est pourquoi elle n’est pas utilisée pour la construction de l’arbre, mais seulement pour l’évaluation finale.
Algorithme CART#
Presentation#
L’algorithme CART (Classification And Regression Trees), introduit par Breiman, Friedman, Olshen et Stone en 1984, est la référence pour la construction d’arbres de décision. Ses caractéristiques principales sont :
Divisions binaires : chaque noeud produit exactement deux fils (contrairement à ID3/C4.5 qui autorisent des divisions multi-branches)
Critère de Gini pour la classification, MSE pour la régression
Elagage par coût-complexité (cost-complexity pruning) pour contrôler la taille de l’arbre
Définition 95 (Algorithme CART)
L’algorithme CART construit un arbre binaire \(T\) par le procédé suivant :
Construction (croissance gloutonne) :
Partir du noeud racine contenant toutes les observations
Pour chaque noeud, trouver la meilleure division \((j^*, s^*)\) :
Pour chaque feature \(j \in \{1, \ldots, p\}\)
Pour chaque seuil \(s\) parmi les valeurs de \(x_j\)
Calculer la réduction d’impureté \(\Delta I(j, s)\)
Retenir \((j^*, s^*) = \arg\max_{j,s} \Delta I(j, s)\)
Diviser le noeud en deux fils selon \((j^*, s^*)\)
Répéter récursivement jusqu’à un critère d’arrêt
Prédiction :
Classification : classe majoritaire dans la feuille
Régression : moyenne des \(y_i\) dans la feuille
Critères d’arrêt#
Sans critère d’arrêt, l’arbre grandit jusqu’à ce que chaque feuille contienne une seule observation, produisant un surapprentissage total. Plusieurs critères limitent la croissance :
Proposition 20 (Critères d’arrêt pour CART)
Les critères d’arrêt les plus courants sont :
Paramètre |
Description |
Effet |
|---|---|---|
|
Profondeur maximale de l’arbre |
Limite la complexité globale |
|
Nombre minimal d’observations pour diviser un noeud |
Empèche les divisions sur trop peu de données |
|
Nombre minimal d’observations dans une feuille |
Garantit des predictions basées sur suffisamment de données |
|
Nombre maximal de feuilles |
Contrôle direct la taille de l’arbre |
|
Réduction minimale d’impureté pour diviser |
Empèche les divisions non informatives |
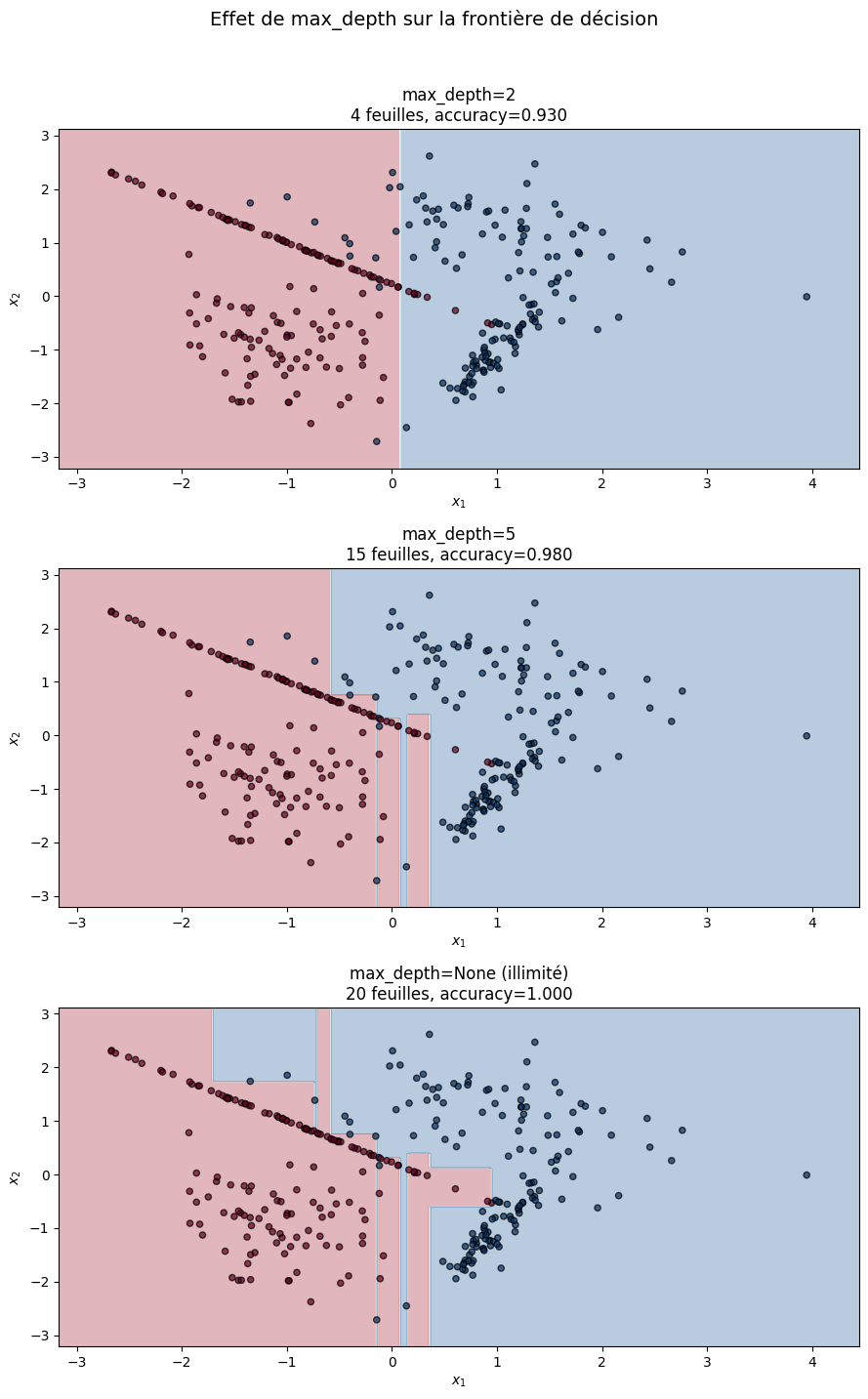
Illustrons l’effet de max_depth sur la complexité de l’arbre.
Elagage#
Le surapprentissage est le principal défaut des arbres de décision. Un arbre qui croit sans contrainte mémorise les données d’entrainement (training accuracy = 100 %) mais généralise mal. L”élagage (pruning) consiste à réduire la taille de l’arbre pour améliorer la généralisation.
Pré-élagage#
Le pré-élagage (pre-pruning) arrête la croissance de l’arbre avant qu’il ne soit complètement développé, en imposant les critères d’arrêt décrits précédemment (max_depth, min_samples_leaf, etc.).
Remarque 87
Le pré-élagage est simple et rapide, mais il présente un inconvénient : il peut arrêter la croissance trop tôt. Une division qui semble non informative à un noeud donné pourrait être suivie de divisions très informatives dans ses descendants. Le pré-élagage ne peut pas détecter ces situations.
Post-élagage par coût-complexité#
Le post-élagage (post-pruning) construit d’abord l’arbre complet, puis retire les branches qui n’améliorent pas significativement les performances. La méthode de référence est l’élagage par coût-complexité (cost-complexity pruning), aussi appelée minimal cost-complexity pruning ou weakest link pruning.
Définition 96 (Elagage par coût-complexité)
Soit \(T\) un arbre et \(|T|\) son nombre de feuilles. Le critère de coût-complexité est :
oè :
\(R(T) = \sum_{t=1}^{|T|} \frac{n_t}{n} \cdot I(t)\) est l’erreur d’entrainement pondérée (somme des impuretés des feuilles)
\(\alpha \geq 0\) est le paramètre de complexité qui pénalise le nombre de feuilles
Pour chaque valeur de \(\alpha\), il existe un unique sous-arbre \(T_\alpha \subseteq T_{\max}\) qui minimise \(R_\alpha(T)\). Lorsque \(\alpha\) croit, l’arbre optimal se simplifie.
Proposition 21 (Selection de \(\alpha\) par validation croisée)
La séquence des sous-arbres optimaux \(T_{\alpha_0} \supset T_{\alpha_1} \supset \cdots \supset T_{\alpha_k} = \{\text{racine}\}\) est obtenue par élagage successif du maillon le plus faible (weakest link). Le paramètre \(\alpha^*\) est ensuite sélectionné par validation croisée : on choisit la valeur de \(\alpha\) qui minimise l’erreur de validation (ou, selon la règle « 1-SE », le plus grand \(\alpha\) dont l’erreur est à moins d’un écart-type du minimum).
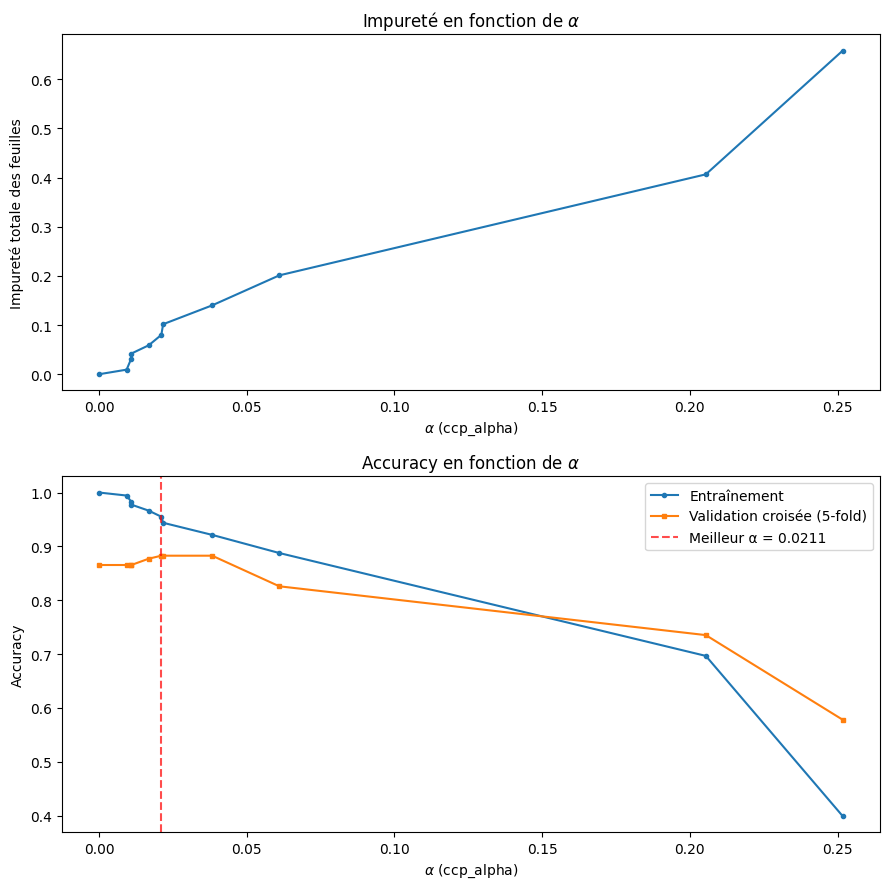
Meilleur alpha : 0.0211
Accuracy validation : 0.883
Arbres de régression#
Critère MSE#
En régression, la variable cible \(y\) est continue. Le critère d’impureté est l”erreur quadratique moyenne (Mean Squared Error, MSE) dans chaque noeud.
Définition 97 (Critère MSE pour les arbres de régression)
Pour un noeud contenant les observations \(\{(\mathbf{x}_i, y_i)\}_{i \in \mathcal{N}}\), l’impureté est la variance de la cible :
où \(\bar{y}_\mathcal{N} = \frac{1}{|\mathcal{N}|} \sum_{i \in \mathcal{N}} y_i\) est la moyenne des cibles dans le noeud.
La prédiction dans chaque feuille est la moyenne \(\bar{y}_\mathcal{N}\), qui minimise la MSE.
Remarque 88
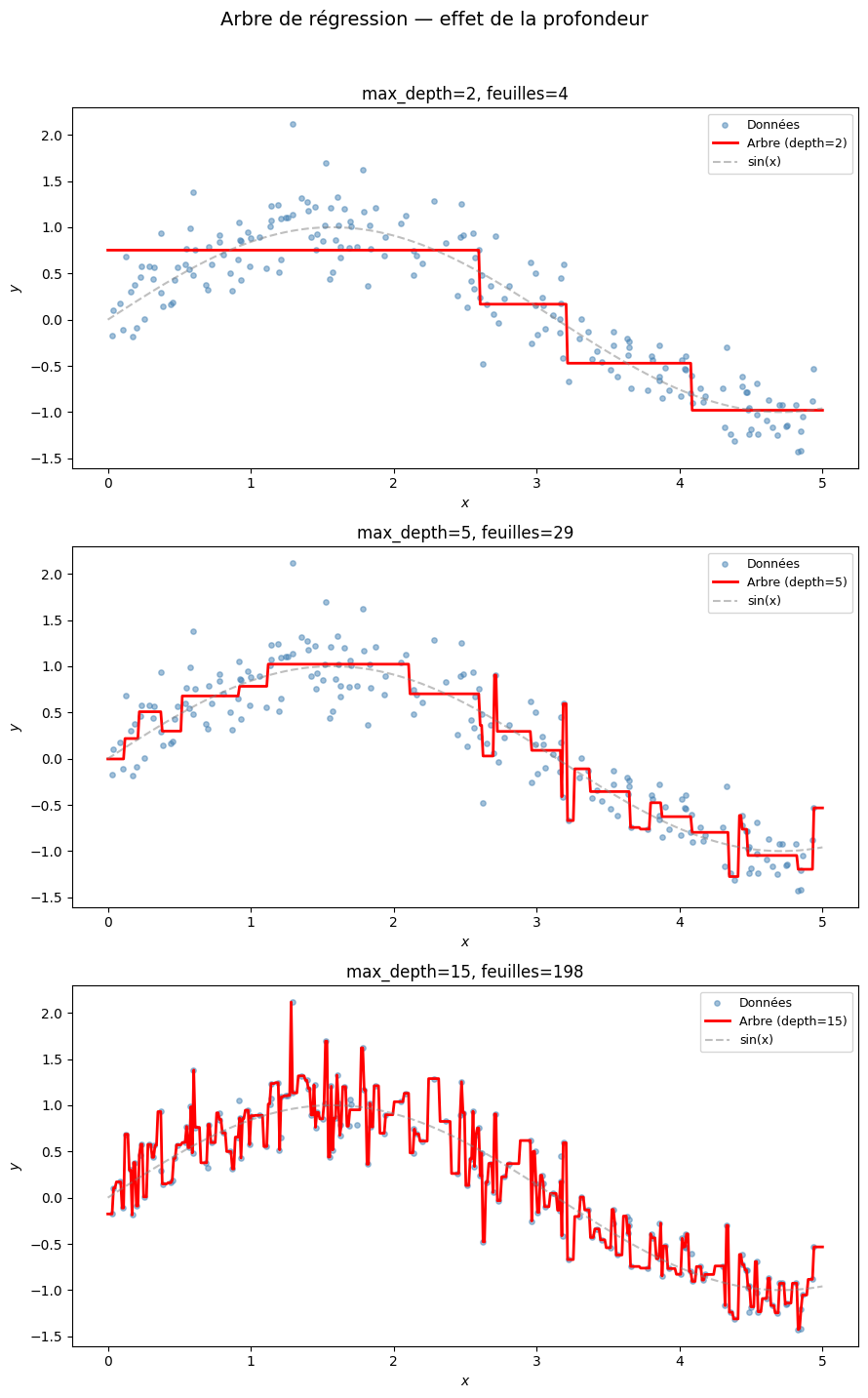
Un arbre de régression produit une fonction en escalier : la prédiction est constante par morceaux. Plus l’arbre est profond, plus la fonction approxime finement la cible, mais au risque du surapprentissage. D’autres critères sont possibles, comme la MAE (Mean Absolute Error), qui produit des prédictions médianes et est plus robuste aux valeurs aberrantes.
Interprétabilité#
L’un des atouts majeurs des arbres de décision est leur interprétabilité. Contrairement aux modèles « boite noire » (réseaux de neurones, SVM à noyau), un arbre peut être inspecté, visualisé et expliqué.
Importance des features#
Définition 98 (Importance de Gini (MDI))
L”importance de Gini (Mean Decrease in Impurity, MDI) d’une feature \(j\) est la somme pondérée des réductions d’impureté apportées par toutes les divisions sur la feature \(j\) :
où \(\mathcal{T}_j\) est l’ensemble des noeuds où la feature \(j\) est utilisée pour la division, \(n_t\) est le nombre d’observations au noeud \(t\), et \(\Delta I(t)\) est la reduction d’impureté au noeud \(t\). Les importances sont normalisées pour sommer à 1.
Remarque 89
L’importance de Gini (MDI) présente un biais en faveur des features à haute cardinalité (beaucoup de valeurs distinctes) et des features continues. Une alternative plus fiable est l’importance par permutation (permutation importance), qui mesure la dégradation des performances lorsqu’on permute aléatoirement les valeurs d’une feature.
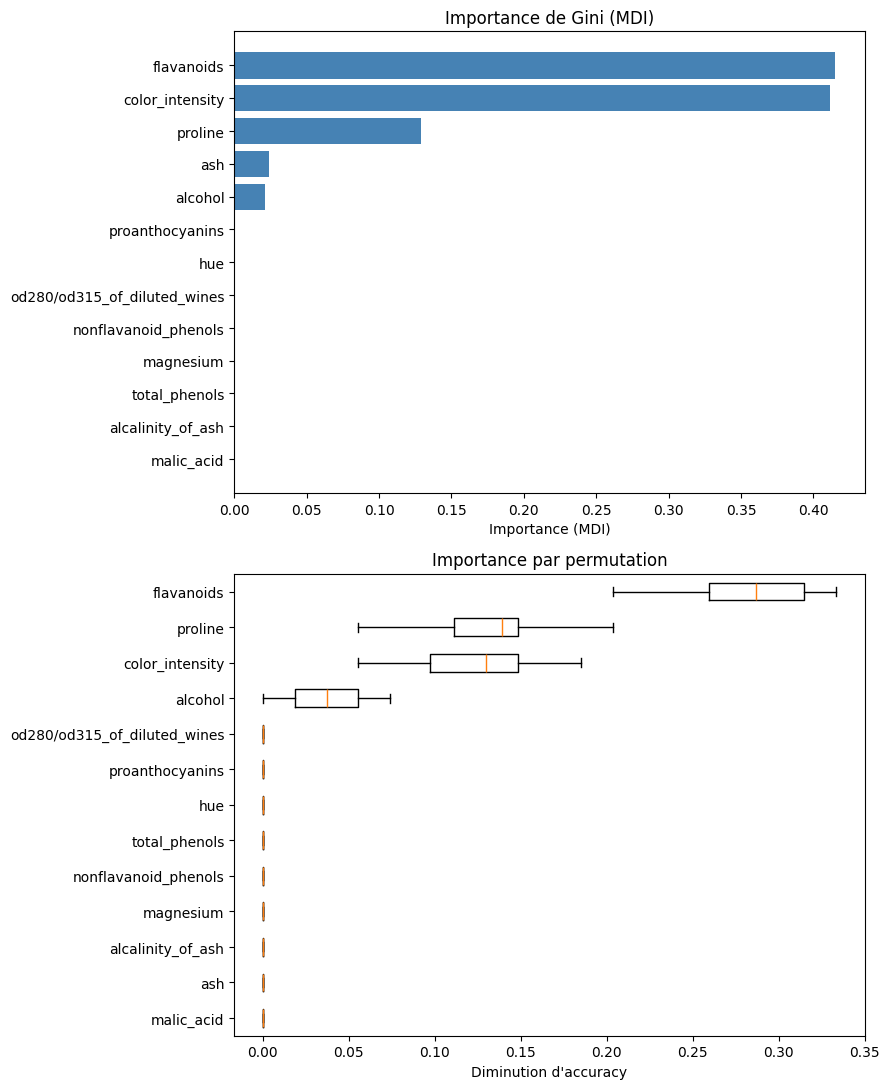
Visualisation de l’arbre#
Scikit-learn fournit plot_tree pour visualiser la structure de l’arbre, et export_text pour une représentation textuelle.
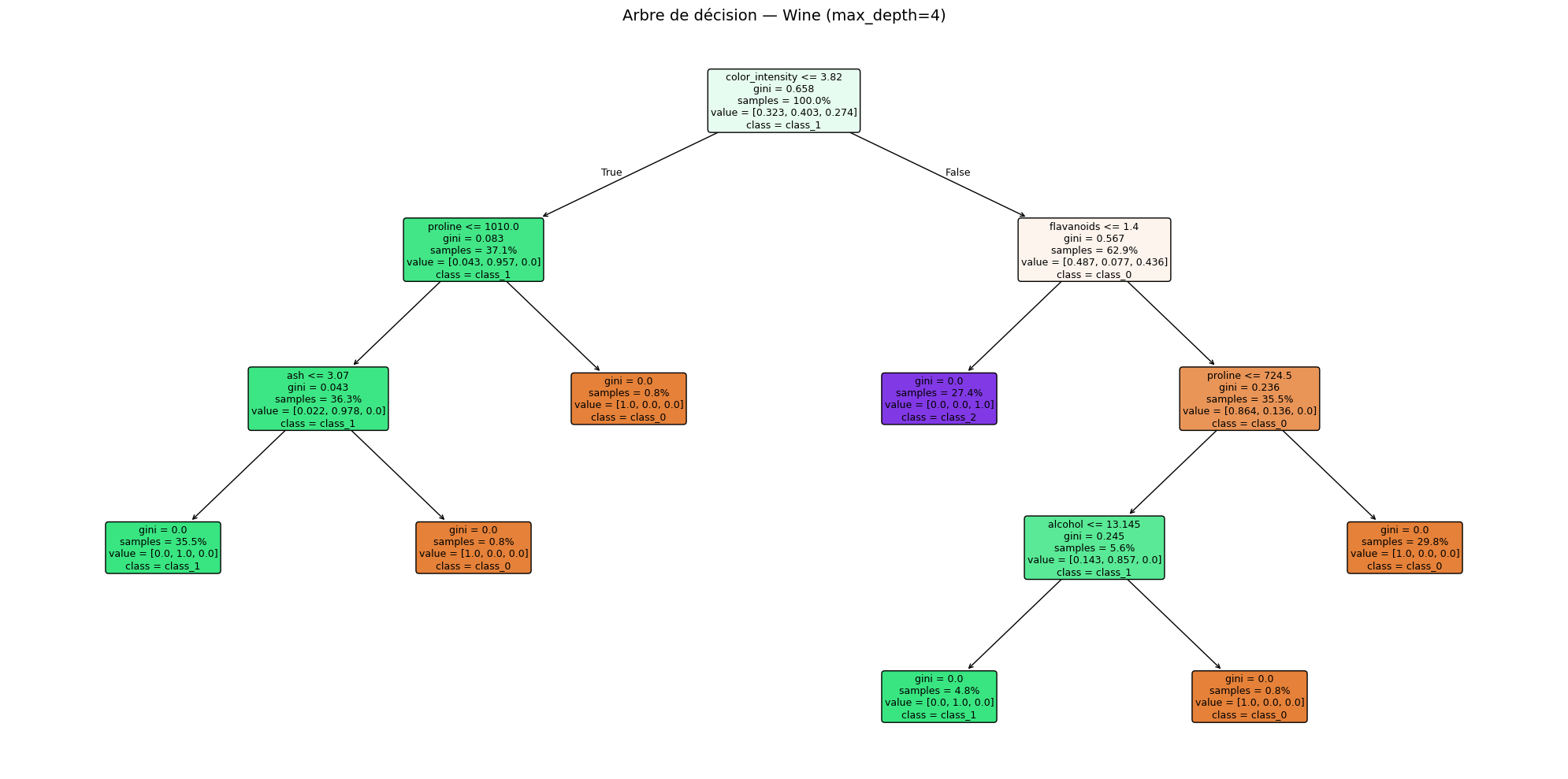
Représentation textuelle (3 premiers niveaux) :
|--- color_intensity <= 3.82
| |--- proline <= 1010.00
| | |--- ash <= 3.07
| | | |--- class: 1
| | |--- ash > 3.07
| | | |--- class: 0
| |--- proline > 1010.00
| | |--- class: 0
|--- color_intensity > 3.82
| |--- flavanoids <= 1.40
| | |--- class: 2
| |--- flavanoids > 1.40
| | |--- proline <= 724.50
| | | |--- alcohol <= 13.14
| | | | |--- class: 1
| | | |--- alcohol > 13.14
| | | | |--- class: 0
| | |--- proline > 724.50
| | | |--- class: 0
Remarque 90
La visualisation d’un arbre profond devient rapidement illisible. En pratique, on limite la profondeur affichée ou on utilise des outils intéractifs (comme dtreeviz) pour explorer la structure de l’arbre. Pour la communication avec des non-spécialistes, on traduit souvent l’arbre en règles logiques explicites.
Instabilité des arbres#
Le problème de la variance#
Les arbres de décision souffrent d’une forte variance : une petite perturbation des données d’entrainement peut produire un arbre radicalement différent. Cette instabilité est une conséquence directe de la nature gloutonne et hiérarchique de l’algorithme : un changement à la racine se propage à tout l’arbre.
Proposition 22 (Instabilité des arbres de décision)
Soit \(\mathcal{D}\) un jeu de données et \(\mathcal{D}'\) une perturbation de \(\mathcal{D}\) (suppression ou ajout de quelques observations). Les arbres \(T(\mathcal{D})\) et \(T(\mathcal{D}')\) construits sur ces deux jeux peuvent avoir :
des features de division différentes à la racine
des structures complètement différentes
des prédictions divergentes pour certaines observations
Cette instabilité se traduit par une variance élevée de l’estimateur, c’est-à-dire une grande variabilité des prédictions d’un échantillon d’entrainement à l’autre.
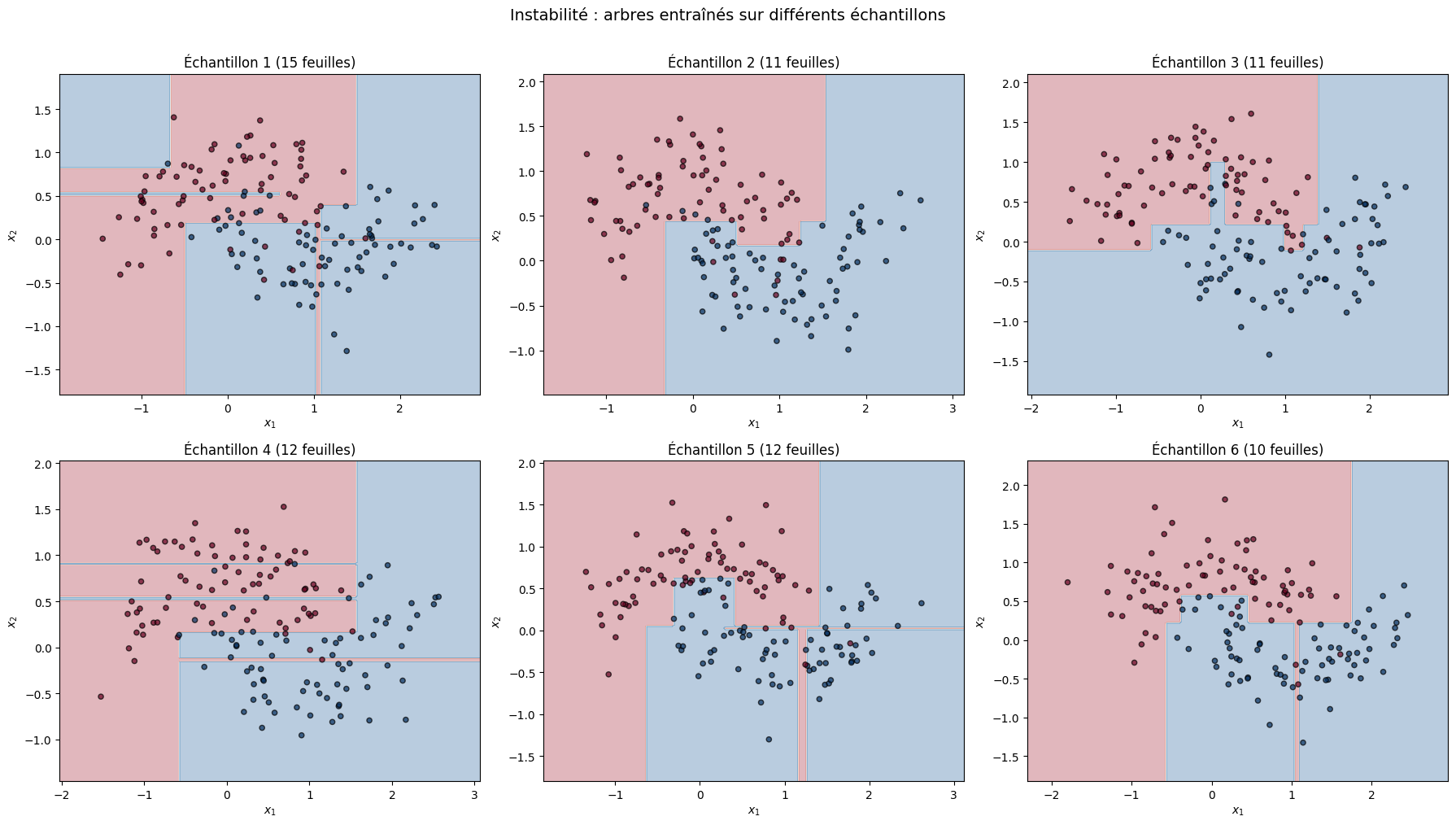
Remarque 91
L’instabilité des arbres est à la fois un défaut et une opportunité. C’est un défaut parce qu’un arbre seul n’est pas fiable. Mais c’est une opportunité parce que des arbres instables et décorrélées peuvent être agrégés pour produire un modèle stable et performant. C’est le principe des methodes d’ensemble :
Bagging (forêts aléatoires) : on entraine des arbres sur des échantillons bootstrap, puis on moyenne les prédictions. La variance diminue sans que le biais augmente.
Boosting (gradient boosting) : on entraine des arbres séquentiellement, chacun corrigeant les erreurs du précédent. Le biais diminue progressivement.
Ces méthodes font l’objet du chapitre suivant.
Exemple complet avec Scikit-learn#
Données et objectif#
Construisons un pipeline complet sur le jeu de données Iris : entrainement, élagage, évaluation, visualisation de l’arbre et des frontières de décision.
Entraînement : 105 observations
Test : 45 observations
Classes : [np.str_('setosa'), np.str_('versicolor'), np.str_('virginica')]
Recherche d’hyperparamètres#
Meilleurs hyperparamètres :
criterion = gini
max_depth = 3
min_samples_leaf = 1
min_samples_split = 2
Meilleure accuracy (CV) : 0.952
Evaluation sur le test set#
precision recall f1-score support
setosa 1.00 1.00 1.00 15
versicolor 1.00 0.93 0.97 15
virginica 0.94 1.00 0.97 15
accuracy 0.98 45
macro avg 0.98 0.98 0.98 45
weighted avg 0.98 0.98 0.98 45
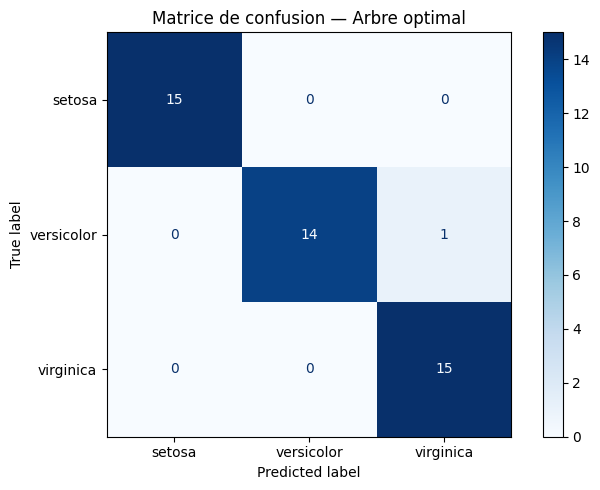
Visualisation de l’arbre optimal#
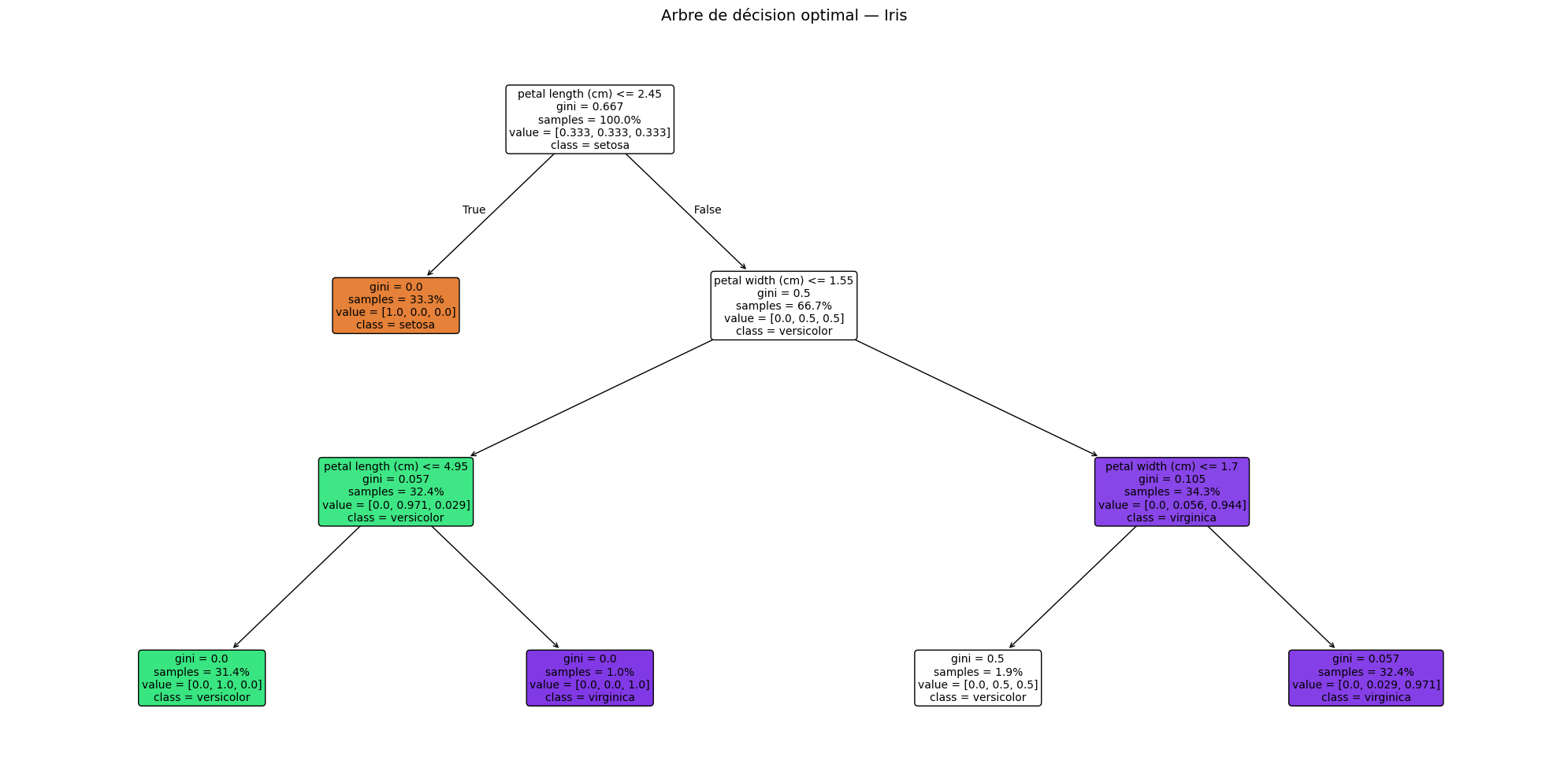
Représentation textuelle :
|--- petal length (cm) <= 2.45
| |--- class: 0
|--- petal length (cm) > 2.45
| |--- petal width (cm) <= 1.55
| | |--- petal length (cm) <= 4.95
| | | |--- class: 1
| | |--- petal length (cm) > 4.95
| | | |--- class: 2
| |--- petal width (cm) > 1.55
| | |--- petal width (cm) <= 1.70
| | | |--- class: 1
| | |--- petal width (cm) > 1.70
| | | |--- class: 2
Frontières de décision (2D)#
Pour visualiser les frontières de décision dans le plan, on entraine un arbre sur les deux features les plus discriminantes.
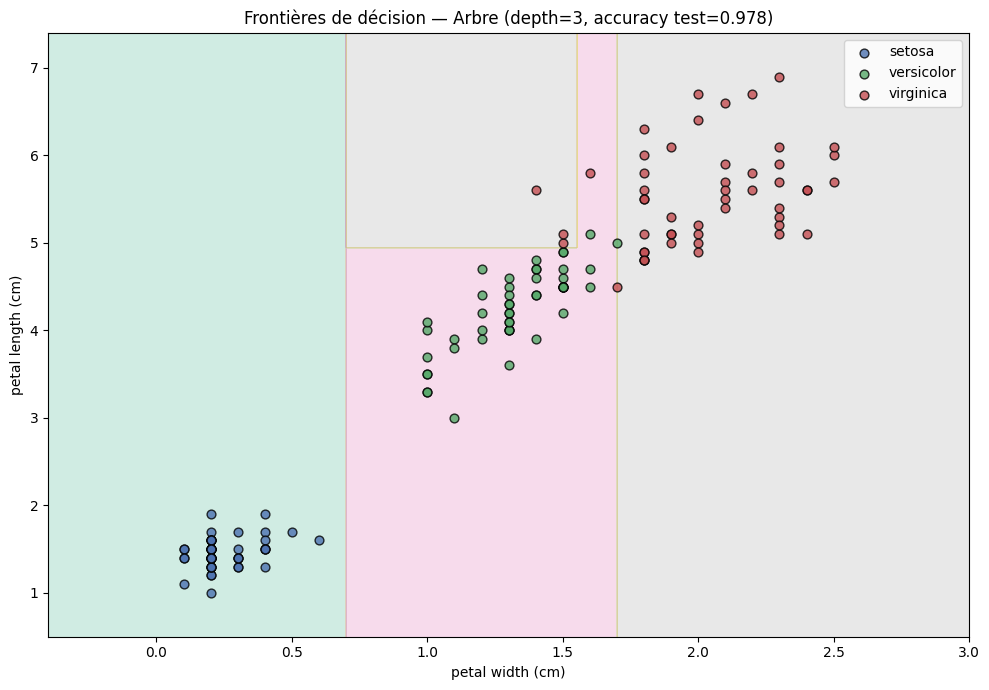
Remarque 92
On observe clairement que les frontières de décision d’un arbre sont parallèles aux axes : chaque division partitionne l’espace le long d’une seule feature à la fois. C’est une limitation structurelle des arbres CART. Pour des frontières obliques, il faudrait utiliser des arbres obliques (oblique trees) ou des méthodes d’ensemble qui combinent de nombreuses partitions parallèles aux axes.
Comparaison arbre élagué vs non élagué#
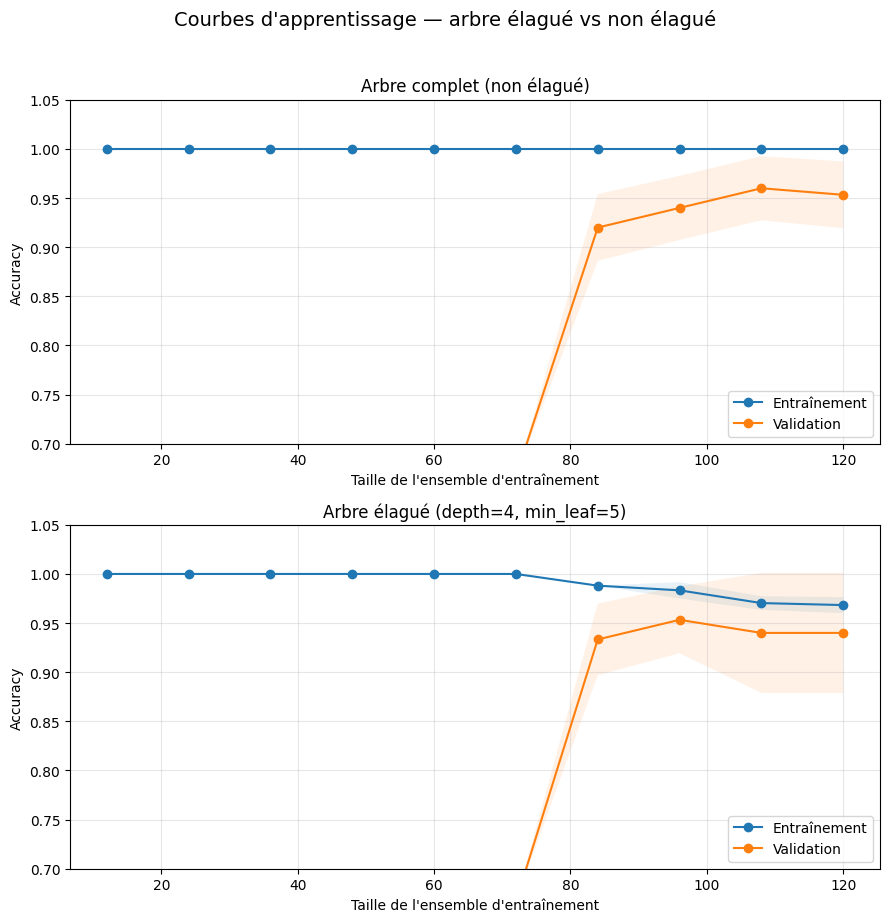
Remarque 93
Les courbes d’apprentissage révèlent le compromis biais-variance :
L’arbre non élagué atteint 100 % d’accuracy en entrainement (variance élevée, biais faible), mais l’accuracy de validation est inférieure et fluctuante.
L’arbre élagué a une accuracy d’entrainement légèrement plus basse (biais un peu plus élevé), mais l’écart entre entrainement et validation est réduit (variance plus faible), signe d’une meilleure généralisation.
Résumé#
Les arbres de décision sont des modèles simples, interprétables et polyvalents, mais leur instabilité en fait rarement le meilleur choix en tant que modèle isolé. Voici les points clés :
Aspect |
Detail |
|---|---|
Principe |
Partitionnement récursif de l’espace des features |
Critères (classification) |
Indice de Gini, entropie de Shannon |
Critère (régression) |
MSE (ou MAE) |
Algorithme |
CART : divisions binaires, construction gloutonne |
Régularisation |
Pré-élagage ( |
Forces |
Interprétabilité, pas de prétraitement, intéractions automatiques |
Faiblesses |
Instabilité (haute variance), frontières parallèles aux axes |
Suite |
Méthodes d’ensemble (forêts aléatoires, gradient boosting) |
Remarque 94
En pratique, les arbres de décision seuls sont utilisés principalement lorsque l’interprétabilité est primordiale (domaine médical, juridique, financier réglementé). Pour la performance prédictive pure, on leur préfère les méthodes d’ensemble, qui exploitent leur instabilité comme un atout en construisant et en agrégeant des centaines ou des milliers d’arbres décorrélées.