
Exploration et visualisation#
Le but de la visualisation est la compréhension, pas les images.
Ben Shneiderman
Introduction#
L”analyse exploratoire des données (Exploratory Data Analysis, EDA) est l’étape fondamentale qui précède toute modélisation. Avant de construire un modèle, il faut comprendre les données : leur structure, leurs distributions, leurs relations, leurs anomalies. L’EDA, popularisée par John Tukey dans les années 1970, repose sur deux piliers : les statistiques descriptives et la visualisation.
L’exploration permet de :
vérifier la qualité des données (valeurs manquantes, incohérences, doublons)
comprendre la distribution de chaque variable
identifier les relations entre variables
détecter les valeurs aberrantes (outliers)
formuler des hypothèses pour guider la modélisation
choisir les transformations et prétraitements appropriés
Remarque 22
L’EDA n’est pas une étape linéaire : c’est un processus itératif. Chaque visualisation peut soulever de nouvelles questions, qui appellent de nouvelles explorations. Il ne faut jamais sous-estimer le temps consacré à cette phase : un modèle construit sur des données mal comprises sera, au mieux, médiocre.
Chargeons les bibliothèques et les données que nous utiliserons tout au long de ce chapitre.
Iris : 150 observations, 5 variables
California Housing : 20640 observations, 9 variables
Statistiques descriptives#
Les statistiques descriptives résument un jeu de données par quelques nombres caractéristiques. On distingue les mesures de tendance centrale (où se situe le « centre » des données), les mesures de dispersion (à quel point les données s’étalent) et les mesures de forme (la géométrie de la distribution).
Mesures de tendance centrale#
Définition 16 (Moyenne arithmétique)
Soit un échantillon \((x_1, \ldots, x_n)\). La moyenne arithmétique est
Définition 17 (Médiane)
La médiane est la valeur qui sépare l’échantillon ordonné en deux moitiés égales. Si l’on note \(x_{(1)} \leq x_{(2)} \leq \cdots \leq x_{(n)}\) les statistiques d’ordre :
Définition 18 (Mode)
Le mode est la valeur (ou les valeurs) la plus fréquente dans l’échantillon. Pour des données continues, on parle du mode de la distribution estimée (le sommet de la densité).
Remarque 23
La moyenne est sensible aux valeurs extrêmes ; la médiane est robuste. Si la distribution est symétrique, moyenne et médiane coïncident. Si la distribution est asymétrique à droite (right-skewed), on a typiquement \(\text{mode} < \text{médiane} < \text{moyenne}\).
Moyenne : 2.0686
Médiane : 1.7970
Mode : 5.0000
Mesures de dispersion#
Définition 19 (Variance et écart-type)
La variance empirique (non biaisée) et l”écart-type d’un échantillon sont
La division par \(n - 1\) (correction de Bessel) assure que \(\mathbb{E}[s^2] = \sigma^2\).
Définition 20 (Quantiles)
Le quantile d’ordre \(p\) (avec \(0 < p < 1\)) est la valeur \(q_p\) telle que
Les quantiles d’ordre \(1/4\), \(1/2\) et \(3/4\) sont les quartiles \(Q_1\), \(Q_2\) (médiane) et \(Q_3\). L”écart interquartile est \(\text{IQR} = Q_3 - Q_1\).
Remarque 24
L’écart interquartile est une mesure de dispersion robuste : il n’est pas affecté par les valeurs extrêmes. C’est la mesure utilisée par les boxplots pour définir les « moustaches » et détecter les outliers.
Variance : 1.3316
Écart-type : 1.1540
Q1 (25%) : 1.1960
Q2 (50%) : 1.7970
Q3 (75%) : 2.6472
IQR : 1.4512
Mesures de forme#
Définition 21 (Coefficient d’asymétrie (skewness))
Le coefficient d’asymétrie (ou skewness) mesure le degré d’asymétrie d’une distribution :
\(\gamma_1 = 0\) : distribution symétrique
\(\gamma_1 > 0\) : queue à droite plus longue (right-skewed)
\(\gamma_1 < 0\) : queue à gauche plus longue (left-skewed)
Définition 22 (Coefficient d’aplatissement (kurtosis))
Le coefficient d’aplatissement (ou kurtosis) mesure l’épaisseur des queues :
La soustraction de \(3\) (excess kurtosis) normalise par rapport à la loi normale (\(\gamma_2 = 0\)).
\(\gamma_2 > 0\) : queues plus épaisses que la normale (leptokurtique)
\(\gamma_2 < 0\) : queues plus fines que la normale (platykurtique)
Skewness et kurtosis des variables numériques (California Housing) :
MedInc skewness = +1.647 kurtosis = +4.953
HouseAge skewness = +0.060 kurtosis = -0.801
AveRooms skewness = +20.698 kurtosis = +879.353
AveBedrms skewness = +31.317 kurtosis = +1636.712
Population skewness = +4.936 kurtosis = +73.553
AveOccup skewness = +97.640 kurtosis = +10651.011
Latitude skewness = +0.466 kurtosis = -1.118
Longitude skewness = -0.298 kurtosis = -1.330
MedHouseVal skewness = +0.978 kurtosis = +0.328
Résumé avec pandas#
La méthode describe() de pandas fournit un résumé complet en une seule ligne.
| MedInc | HouseAge | AveRooms | AveBedrms | Population | AveOccup | Latitude | Longitude | MedHouseVal | |
|---|---|---|---|---|---|---|---|---|---|
| count | 20640.000 | 20640.000 | 20640.000 | 20640.000 | 20640.000 | 20640.000 | 20640.000 | 20640.000 | 20640.000 |
| mean | 3.871 | 28.639 | 5.429 | 1.097 | 1425.477 | 3.071 | 35.632 | -119.570 | 2.069 |
| std | 1.900 | 12.586 | 2.474 | 0.474 | 1132.462 | 10.386 | 2.136 | 2.004 | 1.154 |
| min | 0.500 | 1.000 | 0.846 | 0.333 | 3.000 | 0.692 | 32.540 | -124.350 | 0.150 |
| 25% | 2.563 | 18.000 | 4.441 | 1.006 | 787.000 | 2.430 | 33.930 | -121.800 | 1.196 |
| 50% | 3.535 | 29.000 | 5.229 | 1.049 | 1166.000 | 2.818 | 34.260 | -118.490 | 1.797 |
| 75% | 4.743 | 37.000 | 6.052 | 1.100 | 1725.000 | 3.282 | 37.710 | -118.010 | 2.647 |
| max | 15.000 | 52.000 | 141.909 | 34.067 | 35682.000 | 1243.333 | 41.950 | -114.310 | 5.000 |
Distributions#
L’étude de la distribution de chaque variable est la première étape de l’EDA. On cherche à répondre aux questions : la variable est-elle symétrique ? unimodale ? la loi normale est-elle une approximation raisonnable ?
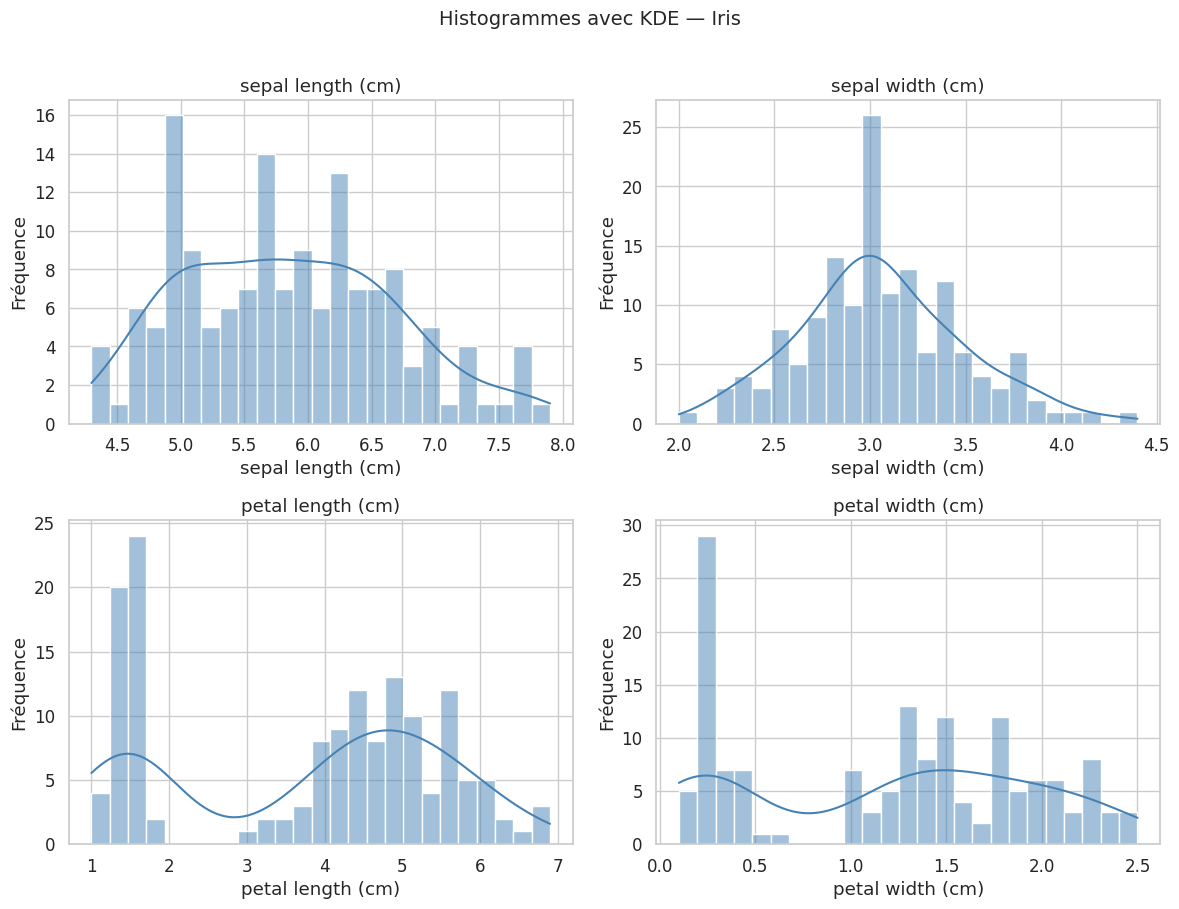
Histogrammes#
L’histogramme est la visualisation la plus élémentaire d’une distribution. Il discrétise l’axe en bins et compte le nombre d’observations dans chaque intervalle.
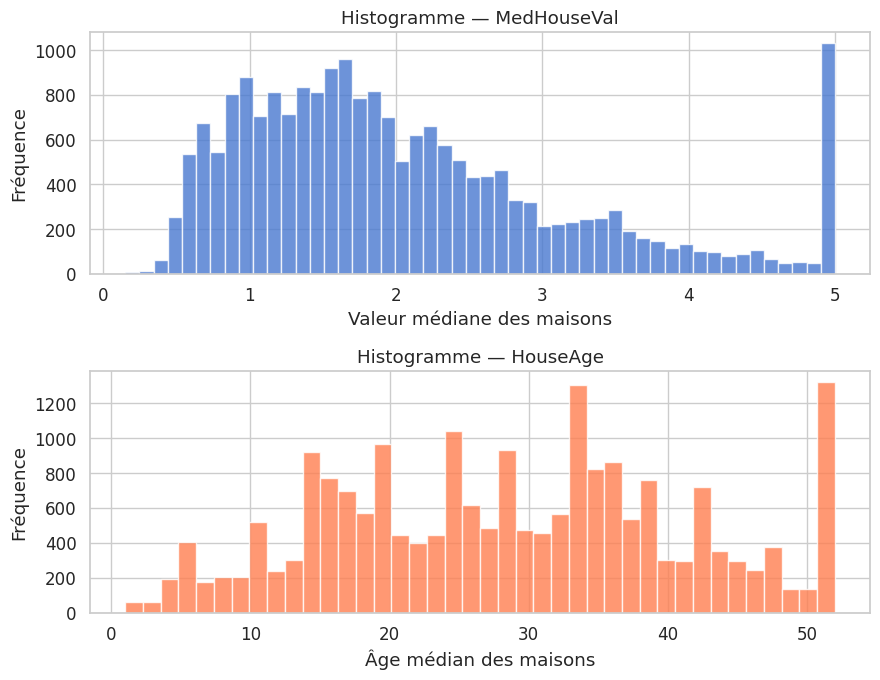
Remarque 25
Le choix du nombre de bins est déterminant. Trop peu de bins lissent la distribution et masquent les détails ; trop de bins produisent un graphique bruité. Des règles comme celle de Sturges (\(k = 1 + \log_2 n\)) ou de Freedman-Diaconis (\(h = 2 \cdot \text{IQR} \cdot n^{-1/3}\)) fournissent des heuristiques utiles.
Estimation par noyau (KDE)#
Définition 23 (Estimation par noyau (KDE))
L”estimation par noyau (Kernel Density Estimation) estime la densité de probabilité \(f\) à partir d’un échantillon \((x_1, \ldots, x_n)\) :
où \(K\) est un noyau (typiquement gaussien : \(K(u) = \frac{1}{\sqrt{2\pi}} e^{-u^2/2}\)) et \(h > 0\) est la largeur de bande (bandwidth).
Remarque 26
La largeur de bande \(h\) joue un rôle analogue au nombre de bins : trop petit, le KDE est bruité (surapprentissage) ; trop grand, il est trop lissé (sous-apprentissage). La règle de Silverman (\(h = 1.06 \cdot s \cdot n^{-1/5}\)) donne une bonne valeur par défaut pour des distributions unimodales.
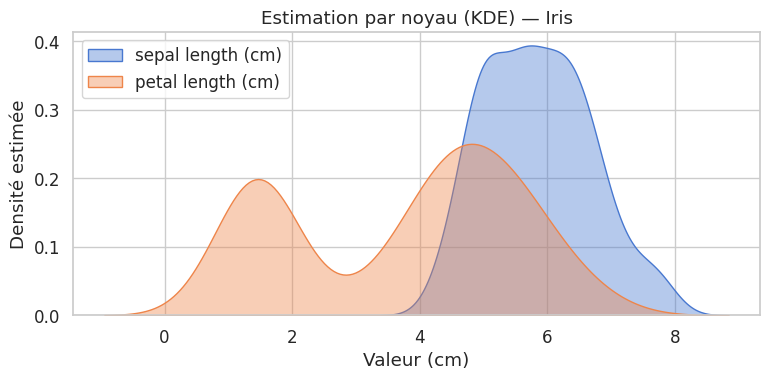
QQ-plots#
Définition 24 (QQ-plot)
Un QQ-plot (Quantile-Quantile plot) compare les quantiles empiriques d’un échantillon aux quantiles théoriques d’une distribution de référence (souvent la loi normale). Si les données suivent la distribution de référence, les points s’alignent sur la diagonale \(y = x\).
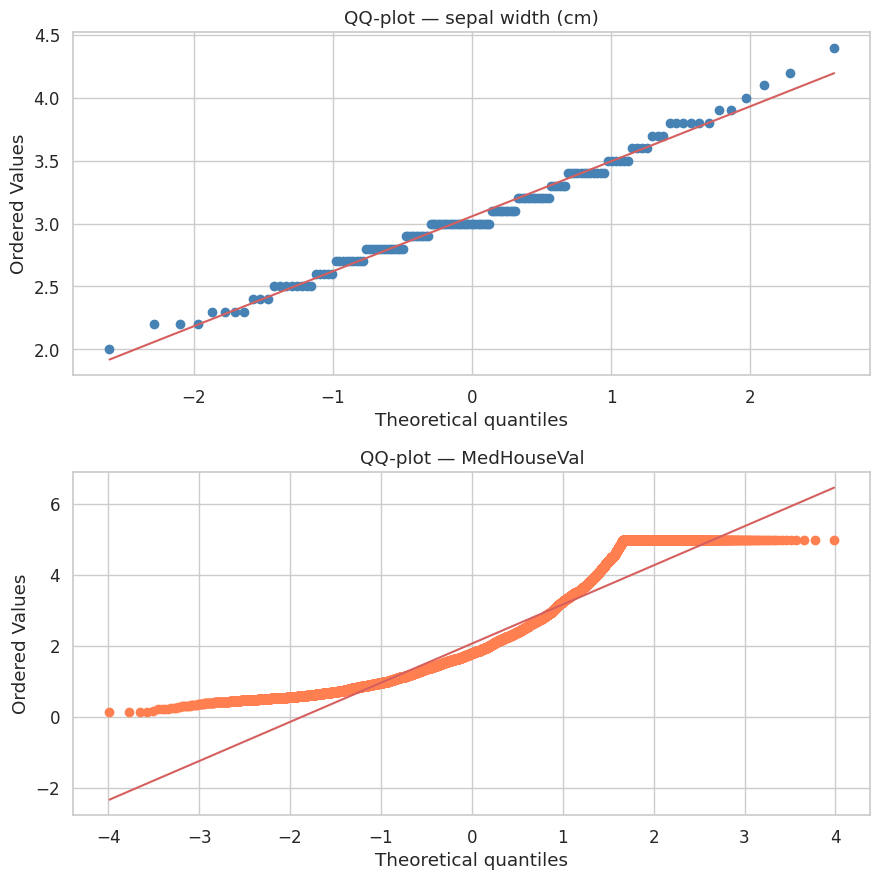
Tests de normalité#
Proposition 4 (Test de Shapiro-Wilk)
Le test de Shapiro-Wilk teste l’hypothèse nulle \(H_0\) : « l’échantillon provient d’une population normalement distribuée ». La statistique de test est
où les coefficients \(a_i\) dépendent des moments attendus des statistiques d’ordre de la loi normale. On rejette \(H_0\) si la \(p\)-valeur est inférieure au seuil \(\alpha\) (typiquement \(0.05\)).
Remarque 27
Le test de Shapiro-Wilk est l’un des plus puissants pour détecter la non-normalité, mais il est limité aux échantillons de taille \(n \leq 5000\). Pour de grands échantillons, on peut utiliser le test de D’Agostino-Pearson ou le test de Kolmogorov-Smirnov.
sepal width (cm)
Shapiro-Wilk : W = 0.9849, p = 0.1012
D'Agostino-Pearson: S = 3.1238, p = 0.2097
→ Normal (Shapiro-Wilk, α = 0.05)
petal length (cm)
Shapiro-Wilk : W = 0.8763, p = 0.0000
D'Agostino-Pearson: S = 221.6873, p = 0.0000
→ Non normal (Shapiro-Wilk, α = 0.05)
Corrélations#
Les corrélations mesurent la force et la direction de la relation linéaire (ou monotone) entre deux variables.
Coefficient de Pearson#
Définition 25 (Coefficient de corrélation de Pearson)
Le coefficient de corrélation linéaire de Pearson entre deux variables \(X\) et \(Y\) est
avec \(r \in [-1, 1]\).
\(r = +1\) : corrélation linéaire positive parfaite
\(r = -1\) : corrélation linéaire négative parfaite
\(r = 0\) : absence de corrélation linéaire (mais il peut exister une relation non linéaire)
Coefficient de Spearman#
Définition 26 (Coefficient de corrélation de Spearman)
Le coefficient de Spearman est le coefficient de Pearson appliqué aux rangs des observations. Si \(\text{rg}(x_i)\) et \(\text{rg}(y_i)\) sont les rangs :
où \(d_i = \text{rg}(x_i) - \text{rg}(y_i)\), en l’absence d’ex aequo.
Remarque 28
Pearson mesure la linéarité de la relation ; Spearman mesure la monotonie. Si la relation est monotone mais non linéaire (par exemple exponentielle), \(|\rho_s|\) peut être proche de \(1\) alors que \(|r|\) est sensiblement plus faible. Spearman est également plus robuste aux valeurs aberrantes.
Matrice de corrélation et heatmaps#
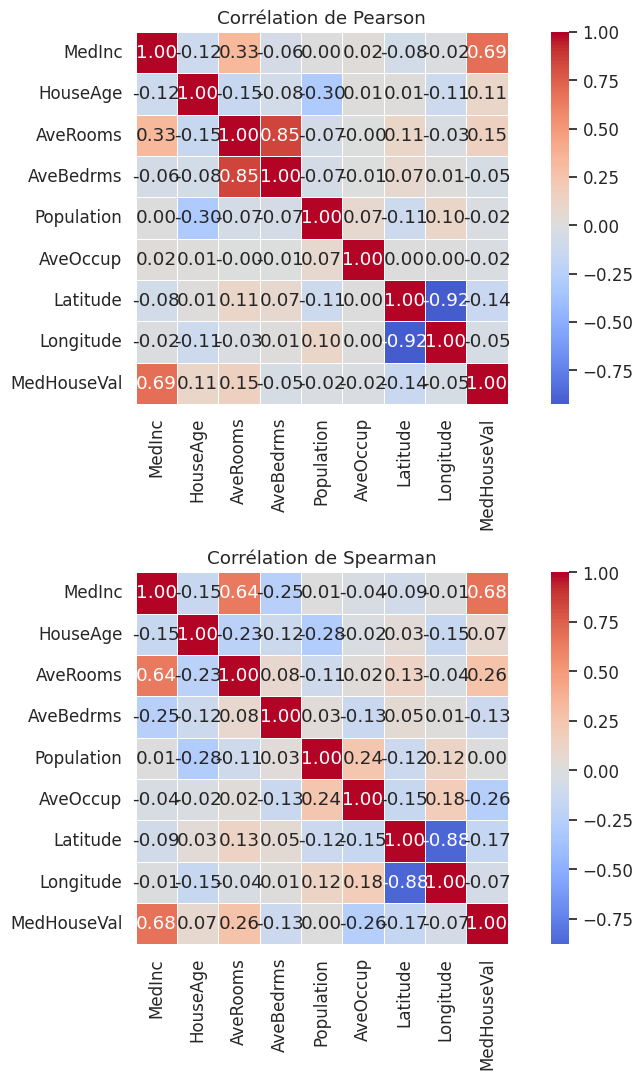
Exemple 3
Sur le jeu California Housing, on observe que MedInc (revenu médian) est fortement corrélé à MedHouseVal (valeur médiane des maisons) avec \(r \approx 0.69\). C’est l’information la plus importante pour un modèle de régression du prix. En revanche, AveBedrms et AveRooms sont très corrélés entre eux (\(r \approx 0.85\)) : c’est un signal de multicolinéarité qu’il faudra traiter lors du prétraitement.
Visualisations univariées#
Les visualisations univariées décrivent la distribution d’une seule variable à la fois.
Histogrammes et KDE combinés#
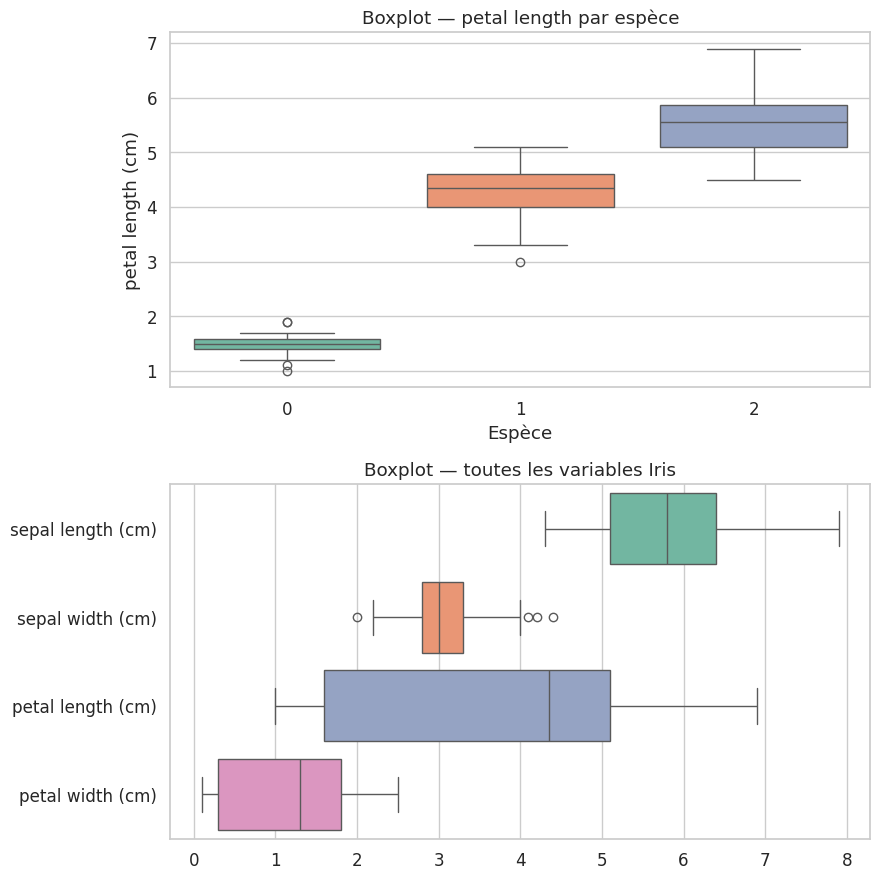
Boxplots (diagrammes en boîte)#
Définition 27 (Boxplot)
Un boxplot (diagramme en boîte) représente la distribution d’une variable par :
la boîte : de \(Q_1\) à \(Q_3\) (contient 50 % des données)
la ligne centrale : la médiane \(Q_2\)
les moustaches : s’étendent jusqu’aux valeurs les plus extrêmes dans l’intervalle \([Q_1 - 1.5 \cdot \text{IQR},\ Q_3 + 1.5 \cdot \text{IQR}]\)
les points au-delà des moustaches : les valeurs aberrantes (outliers)
Violin plots#
Définition 28 (Violin plot)
Un violin plot combine un boxplot et un KDE symétrique. La largeur du « violon » à chaque ordonnée représente la densité estimée de la distribution, offrant une vision plus riche qu’un simple boxplot.
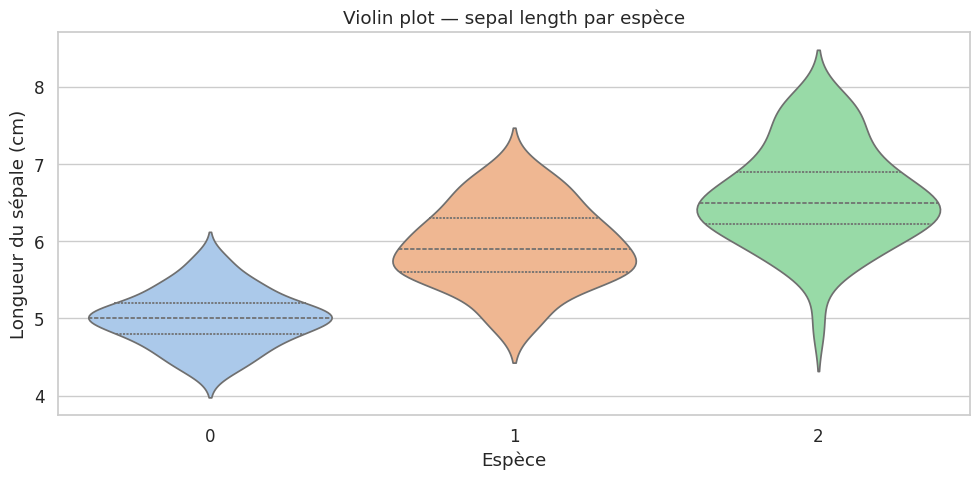
Remarque 29
Les violin plots sont particulièrement utiles lorsque la distribution est bimodale ou multimodale : le KDE révèle la forme complète, là où le boxplot ne montre que les quartiles.
Visualisations bivariées#
Les visualisations bivariées examinent la relation entre deux variables.
Scatter plots (nuages de points)#
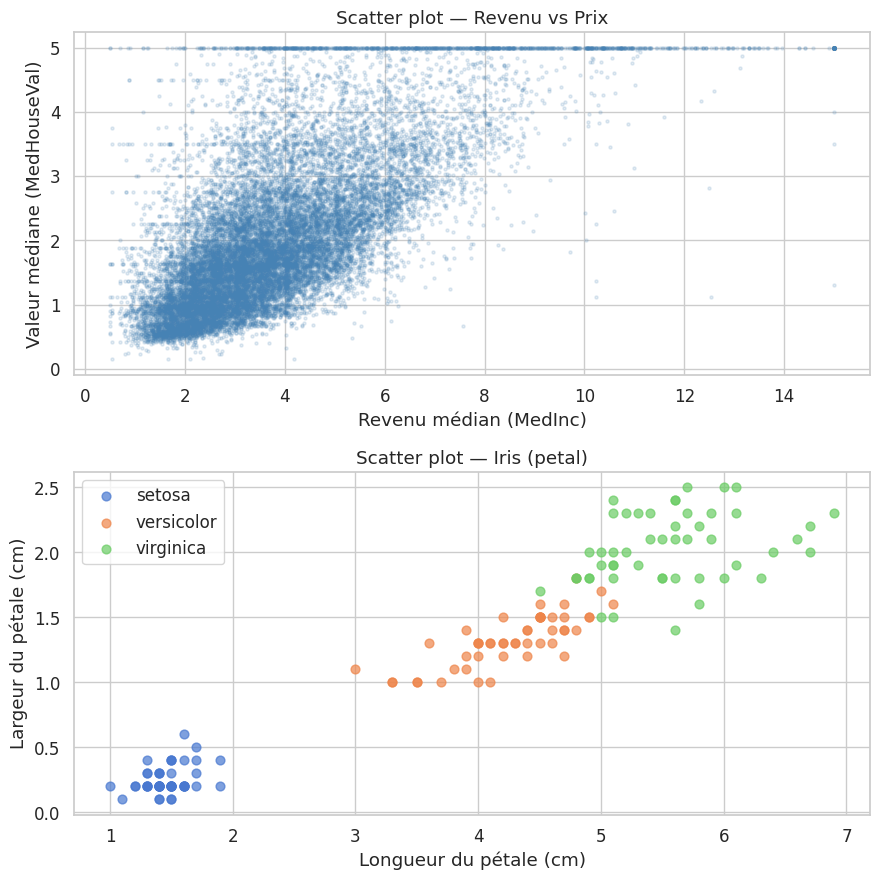
Pair plots#
Définition 29 (Pair plot)
Un pair plot (ou matrice de nuages de points) affiche les scatter plots de toutes les paires de variables, avec les distributions univariées sur la diagonale. C’est un outil puissant pour obtenir une vue d’ensemble rapide des relations entre variables.
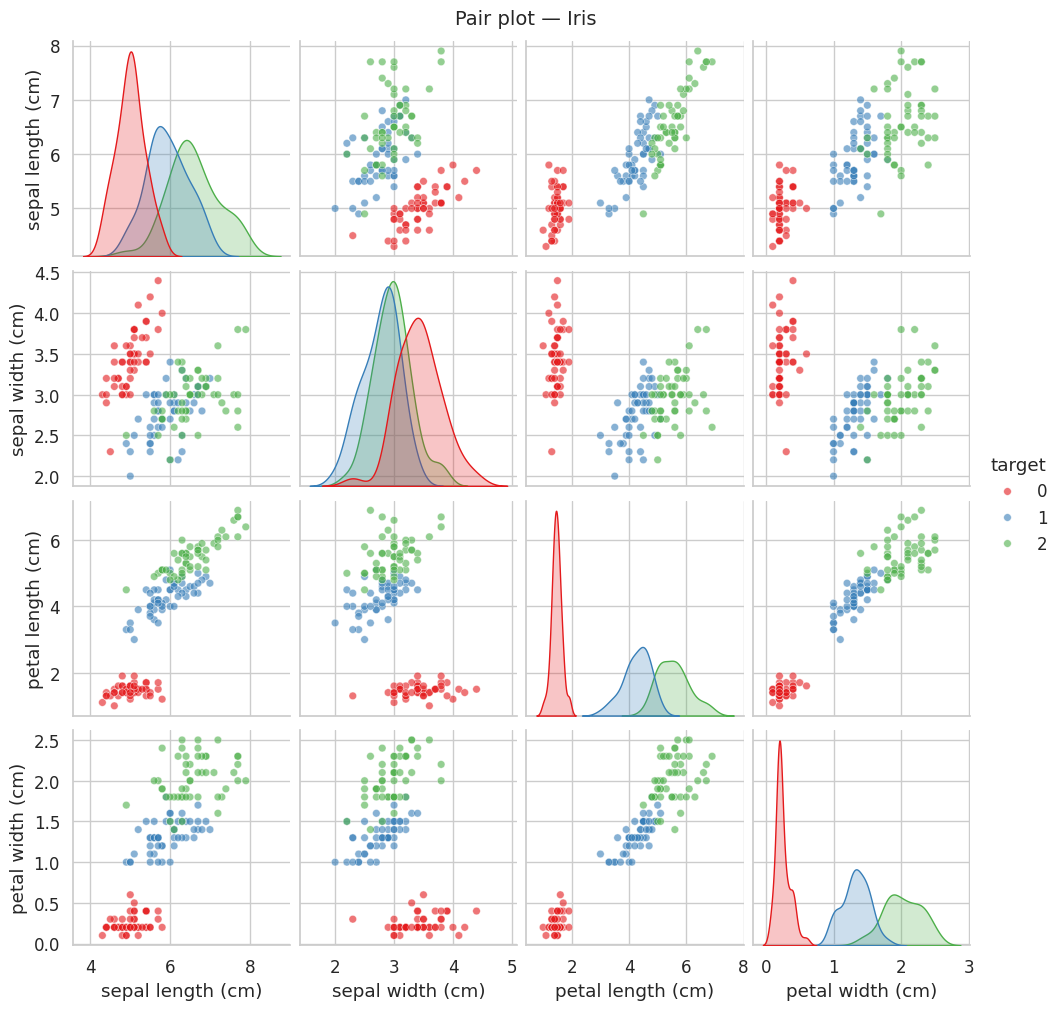
Remarque 30
Le pair plot du jeu Iris est un classique de la visualisation en apprentissage automatique. On observe que la longueur et la largeur du pétale séparent nettement les trois espèces, ce qui indique que ces deux variables seront les plus discriminantes pour un classifieur.
Bar plots#
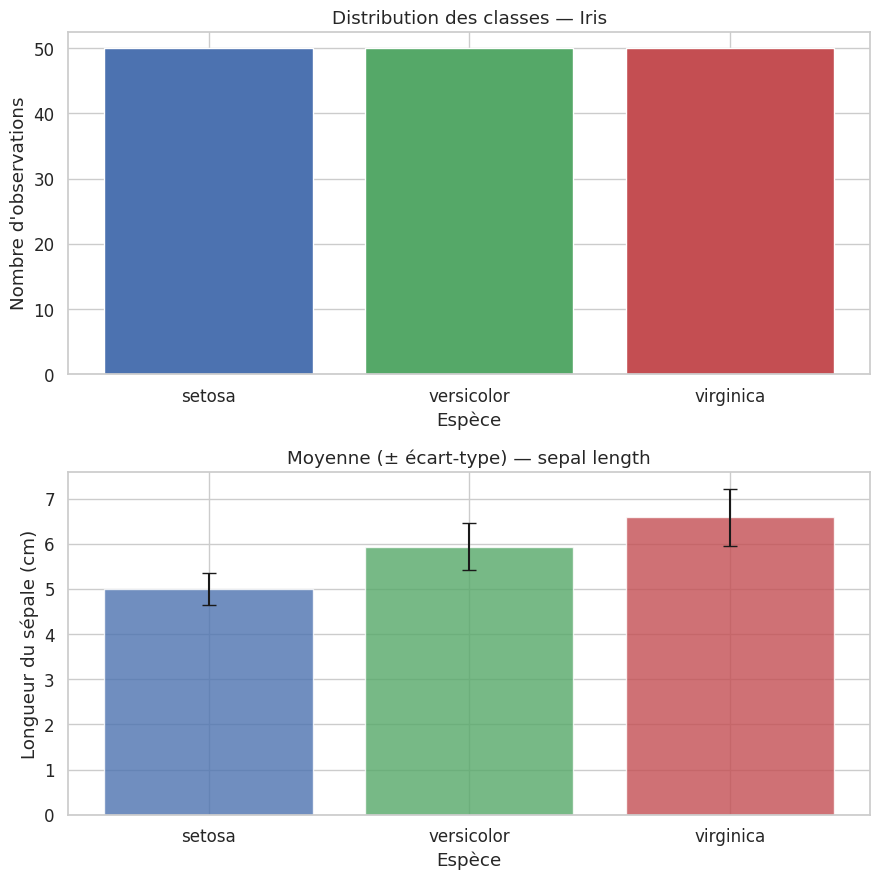
Visualisations multivariées#
Lorsque le nombre de variables dépasse deux, il faut recourir à des techniques de visualisation plus élaborées.
Heatmaps#
Les heatmaps ne servent pas uniquement pour les matrices de corrélation. Elles peuvent représenter toute matrice numérique.
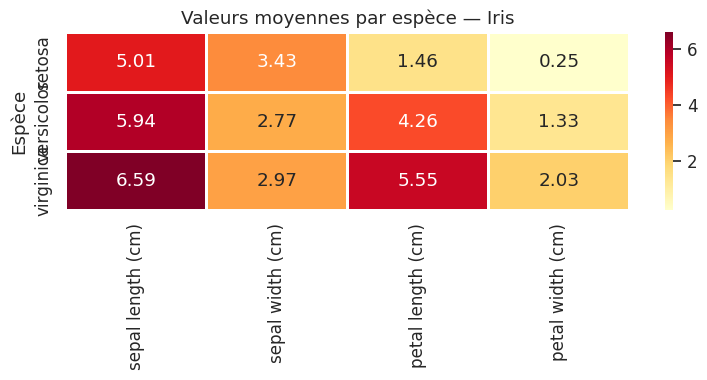
Coordonnées parallèles#
Définition 30 (Coordonnées parallèles)
Un graphique en coordonnées parallèles représente chaque observation comme une ligne brisée traversant des axes verticaux parallèles (un axe par variable). C’est une technique efficace pour visualiser des données à plusieurs dimensions et identifier des groupes ou des tendances.
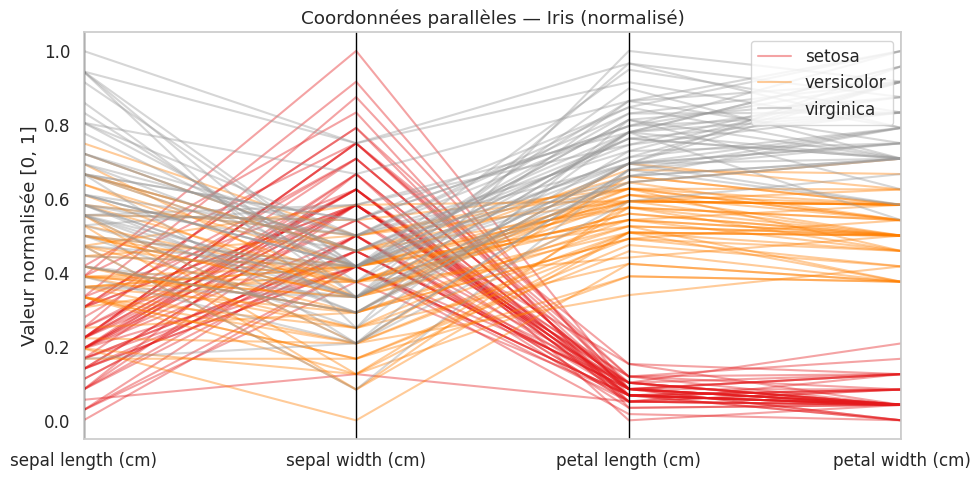
Radar charts (diagrammes en radar)#
Définition 31 (Radar chart)
Un radar chart (ou diagramme en toile d’araignée) représente les valeurs de plusieurs variables sur des axes partant d’un centre commun, les extrémités étant reliées pour former un polygone. Il est utile pour comparer des profils multivariés.
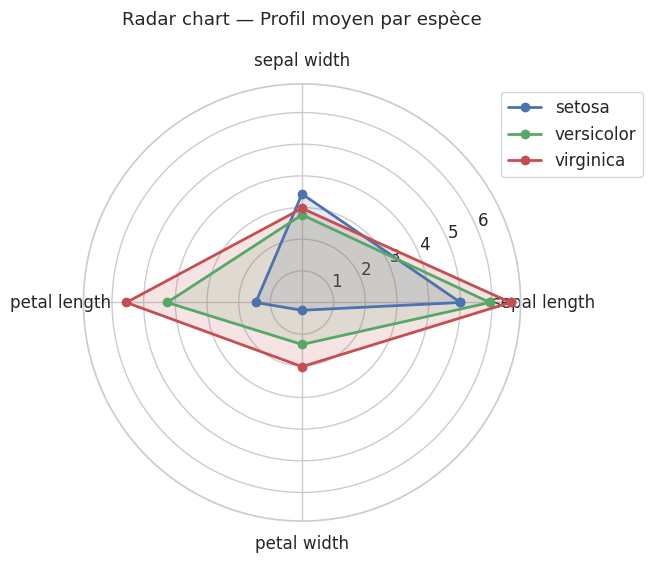
Remarque 31
Les radar charts sont visuellement attractifs mais doivent être utilisés avec prudence : la surface du polygone dépend de l’ordre des variables, et la comparaison des aires peut être trompeuse. Ils conviennent bien pour comparer un petit nombre de profils (2 à 5) sur un petit nombre de variables (4 à 8).
Détection visuelle d’anomalies#
Les valeurs aberrantes (outliers) sont des observations qui s’écartent fortement du reste des données. Leur détection est cruciale car elles peuvent :
résulter d’erreurs de mesure ou de saisie (à corriger ou supprimer)
représenter des phénomènes rares mais réels (à conserver et étudier)
dégrader les performances de certains modèles sensibles aux valeurs extrêmes
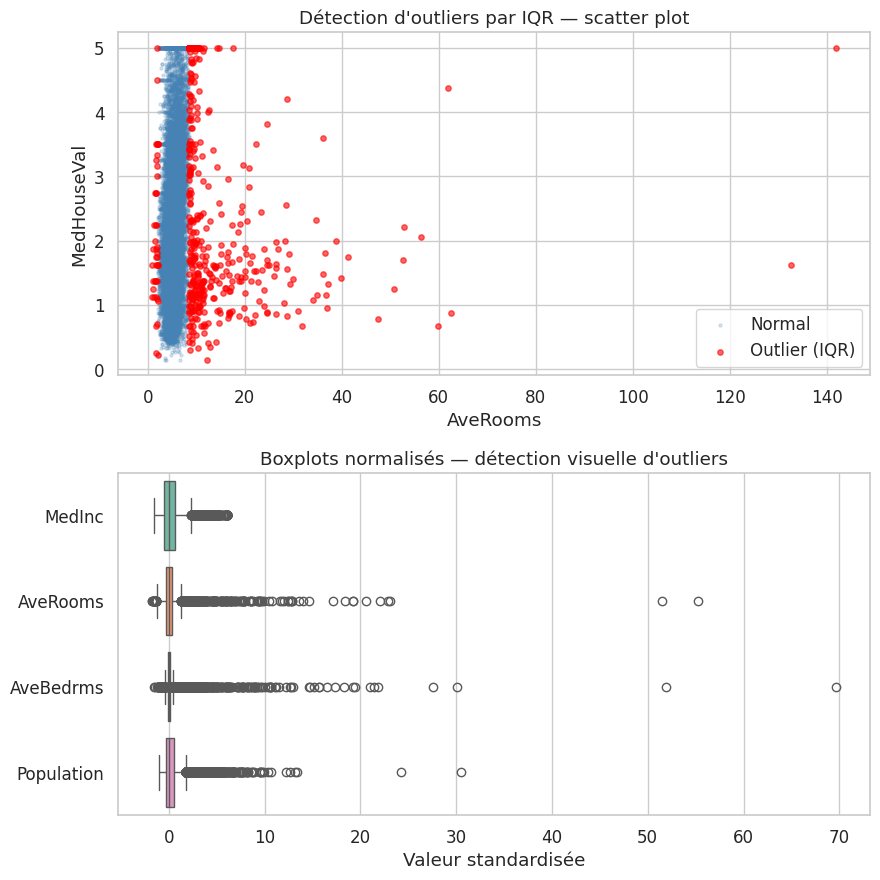
Détection par boxplot et IQR#
Proposition 5 (Règle de l’IQR)
Une observation \(x_i\) est considérée comme un outlier si
Elle est considérée comme un outlier extrême si le facteur \(1.5\) est remplacé par \(3\).
Nombre d'outliers (IQR) par variable — California Housing :
MedInc : 681 outliers (3.3 %)
HouseAge : 0 outliers (0.0 %)
AveRooms : 511 outliers (2.5 %)
AveBedrms : 1424 outliers (6.9 %)
Population : 1196 outliers (5.8 %)
AveOccup : 711 outliers (3.4 %)
Latitude : 0 outliers (0.0 %)
Longitude : 0 outliers (0.0 %)
MedHouseVal : 1071 outliers (5.2 %)
Détection par scatter plot#
Détection par Z-score#
Définition 32 (Z-score)
Le Z-score d’une observation est le nombre d’écarts-types qui la séparent de la moyenne :
Une règle empirique classique considère comme aberrante toute observation avec \(|z_i| > 3\).
Outliers (|z| > 3) dans Population : 342 (1.7 %)
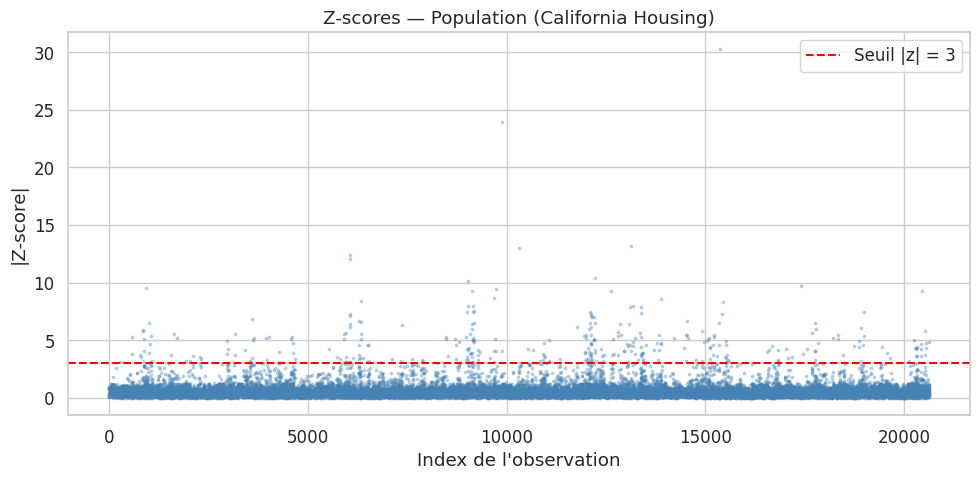
Remarque 32
Le Z-score suppose implicitement que les données suivent une distribution approximativement normale. Pour des distributions fortement asymétriques, on préfère le Z-score modifié basé sur la médiane et le MAD (Median Absolute Deviation) :
Le facteur \(0.6745\) normalise le MAD pour qu’il coïncide avec l’écart-type dans le cas gaussien.
Résumé visuelle#
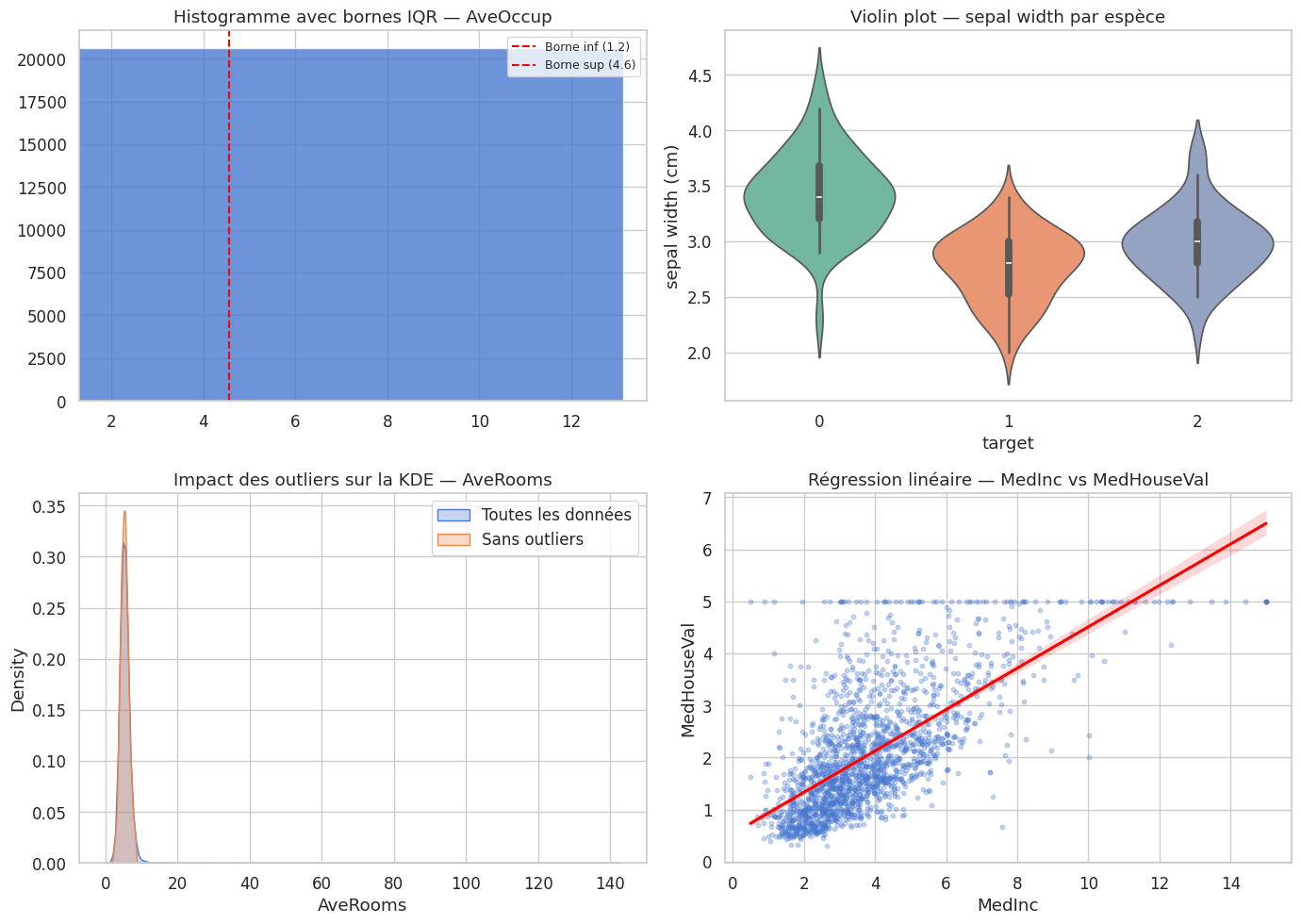
Résumé#
Remarque 33
L’analyse exploratoire des données est une discipline à part entière. Ce chapitre a présenté les outils fondamentaux, mais la pratique de l’EDA s’enrichit avec l’expérience. Voici quelques principes directeurs :
Toujours commencer par
describe()etinfo()pour avoir une vue d’ensemble rapide.Visualiser chaque variable individuellement (histogramme, KDE, boxplot) avant d’étudier les relations.
Examiner les corrélations pour identifier les variables redondantes et les prédicteurs potentiels.
Chercher les outliers et décider de leur traitement au cas par cas.
Adapter la visualisation au message : un bon graphique raconte une histoire claire.
Itérer : chaque observation soulève de nouvelles questions.
Les outils présentés ici — statistiques descriptives, tests de normalité, corrélations, et la gamme complète des visualisations univariées, bivariées et multivariées — constituent le socle sur lequel reposent toutes les étapes suivantes du pipeline d’apprentissage automatique : le prétraitement, la sélection de variables et la modélisation.