
Le perceptron et les bases des réseaux de neurones#
L’ordinateur est né pour résoudre des problèmes qui n’existaient pas avant lui ; mais le neurone artificiel est né d’un rêve plus ancien — comprendre comment l’esprit apprend.
— Adaptation libre d’une réflexion sur les origines de l’intelligence artificielle
Nous entrons dans la Partie IV de cet ouvrage, consacrée aux réseaux de neurones. Ce premier chapitre retrace la naissance du neurone artificiel, formalise le perceptron de Rosenblatt, explore ses capacités et ses limites, puis ouvre la voie au perceptron multicouche (MLP) et, au-delà, à l’apprentissage profond. Le perceptron est un modèle historiquement fondateur : c’est le point de départ de toute l’architecture moderne des réseaux de neurones. Le comprendre en profondeur — son algorithme d’apprentissage, son théorème de convergence, ses échecs sur des problèmes non linéairement séparables — est indispensable pour apprécier les motivations qui ont conduit aux réseaux profonds.
Introduction historique#
L’histoire des réseaux de neurones est indissociable de celle de l’intelligence artificielle. Elle est ponctuée d’enthousiasmes, de désillusions et de renaissances.
Le neurone biologique. Le système nerveux est constitué de milliards de neurones interconnectés. Chaque neurone reçoit des signaux électriques par ses dendrites, les intègre dans le corps cellulaire (soma), et, si la somme des signaux dépasse un certain seuil, propage un potentiel d’action le long de son axone vers d’autres neurones via les synapses. Cette architecture massivement parallèle et adaptative a inspiré les pionniers de l’IA.
McCulloch et Pitts (1943). Warren McCulloch (neurophysiologiste) et Walter Pitts (logicien) proposent le premier modèle mathématique du neurone : une unité logique binaire qui calcule une fonction à seuil de ses entrées. Ce modèle montre qu’un réseau de tels neurones peut, en principe, calculer n’importe quelle fonction logique.
Le perceptron de Rosenblatt (1958). Frank Rosenblatt introduit le perceptron, le premier modèle doté d’un algorithme d’apprentissage automatique. Contrairement au modèle de McCulloch-Pitts dont les poids sont fixés à la main, le perceptron ajuste ses poids à partir des données. Rosenblatt démontre un théorème de convergence : si les données sont linéairement séparables, l’algorithme trouve une solution en un nombre fini d’itérations. L’enthousiasme est immense.
L’hiver de l’IA (1969–1980s). Marvin Minsky et Seymour Papert publient Perceptrons (1969), une analyse mathématique rigoureuse des limites du perceptron simple. Ils montrent qu’il ne peut pas apprendre la fonction XOR, ni aucune fonction non linéairement séparable. Cette démonstration, combinée à l’absence d’algorithme d’apprentissage efficace pour les réseaux multicouches, contribue à un tarissement des financements et de l’intérêt pour les réseaux de neurones.
La résurgence (1986–présent). La découverte de la rétropropagation du gradient (Rumelhart, Hinton et Williams, 1986) permet d’entraîner des perceptrons multicouches. Les progrès du calcul GPU, l’explosion des données disponibles et des architectures innovantes (réseaux convolutifs, récurrents, Transformers) ont conduit à la révolution actuelle de l”apprentissage profond. Nous y reviendrons dans les chapitres suivants.
Le neurone artificiel#
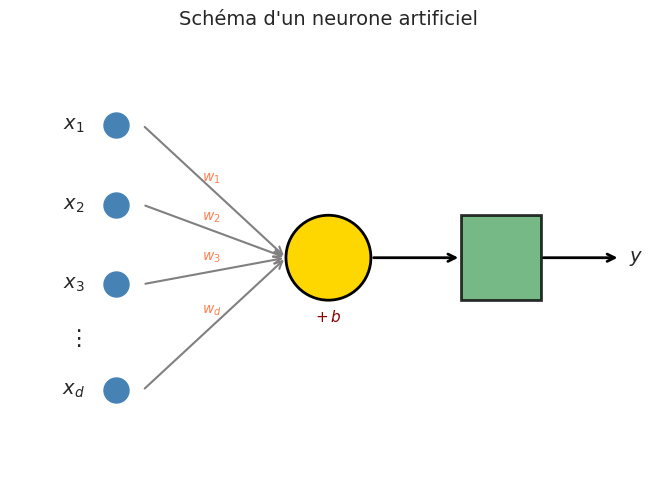
Le neurone artificiel est l’unité de base de tout réseau de neurones. Son fonctionnement s’inspire — de manière simplifiée — du neurone biologique.
Définition 194 (Neurone artificiel)
Un neurone artificiel est une fonction \(f : \mathbb{R}^d \to \mathbb{R}\) définie par :
où :
\(\mathbf{x} = (x_1, \ldots, x_d)^\top \in \mathbb{R}^d\) est le vecteur d’entrée,
\(\mathbf{w} = (w_1, \ldots, w_d)^\top \in \mathbb{R}^d\) est le vecteur de poids (analogues de l’efficacité synaptique),
\(b \in \mathbb{R}\) est le biais (analogue du seuil d’activation),
\(\varphi : \mathbb{R} \to \mathbb{R}\) est la fonction d’activation.
Remarque 167
L’analogie biologique est la suivante : les entrées \(x_j\) correspondent aux signaux reçus par les dendrites ; les poids \(w_j\) à la force des connexions synaptiques ; la somme pondérée \(\mathbf{w}^\top \mathbf{x} + b\) à l’intégration dans le soma ; la fonction d’activation \(\varphi\) au mécanisme de déclenchement du potentiel d’action. Cette analogie est utile pour l’intuition, mais il faut garder à l’esprit que le neurone artificiel est une simplification drastique du neurone biologique.
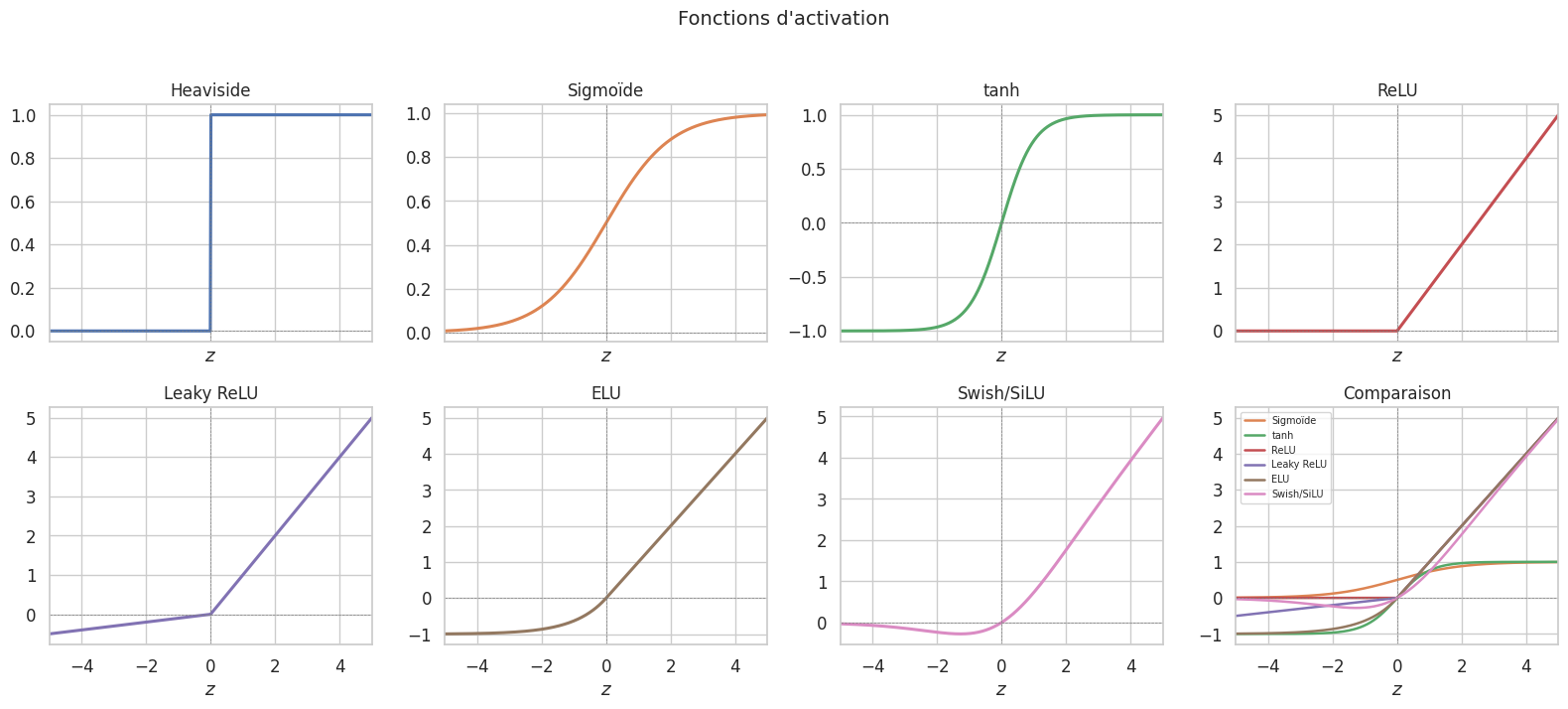
Fonctions d’activation#
Le choix de la fonction d’activation \(\varphi\) détermine le comportement du neurone et du réseau. Nous présentons les fonctions classiques, de la plus simple à la plus moderne.
Définition 195 (Fonction de Heaviside (seuil))
La fonction de Heaviside est définie par :
C’est la fonction d’activation originelle du perceptron. Elle produit une sortie binaire. Son principal défaut est de ne pas être dérivable (en \(z = 0\)), ce qui empêche l’utilisation de méthodes d’optimisation par gradient.
Définition 196 (Fonction sigmoïde)
La fonction sigmoïde (ou logistique) est définie par :
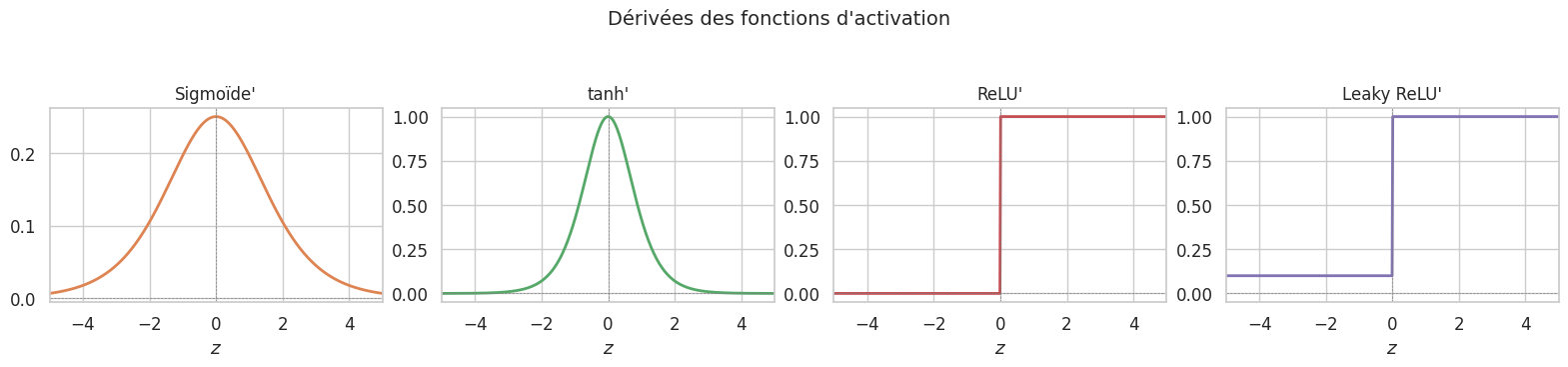
Elle est lisse, dérivable partout, bornée dans \((0, 1)\) et sa dérivée vaut \(\sigma'(z) = \sigma(z)(1 - \sigma(z))\). Elle souffre du problème de saturation : pour \(|z|\) grand, \(\sigma'(z) \approx 0\), ce qui ralentit l’apprentissage par gradient (vanishing gradient).
Définition 197 (Fonction tangente hyperbolique)
Elle est centrée en zéro (image dans \((-1, 1)\)), ce qui est un avantage par rapport à la sigmoïde. Cependant, elle souffre aussi de saturation aux extrêmes.
Définition 198 (Fonction ReLU et variantes)
La Rectified Linear Unit (ReLU) est définie par :
Leaky ReLU : \(\text{LeakyReLU}(z) = \max(\alpha z, z)\) avec \(\alpha \approx 0.01\), évitant les neurones « morts ».
ELU (Exponential Linear Unit) : \(\text{ELU}(z) = z\) si \(z > 0\), et \(\alpha(e^z - 1)\) sinon.
Swish/SiLU : \(\text{Swish}(z) = z \cdot \sigma(z)\), une activation lisse et non monotone qui a montré des performances supérieures dans certaines architectures profondes.
Définition 199 (Fonction softmax)
Pour un vecteur \(\mathbf{z} = (z_1, \ldots, z_K)^\top \in \mathbb{R}^K\), la softmax est définie par :
Elle transforme un vecteur de scores en une distribution de probabilités (\(\sum_k \text{softmax}(\mathbf{z})_k = 1\)). Elle est utilisée en couche de sortie pour la classification multiclasse.
Remarque 168
Propriétés comparées des fonctions d’activation :
Monotonie : toutes sont monotones sauf Swish.
Dérivabilité : Heaviside n’est pas dérivable en 0 ; ReLU n’est pas dérivable en 0 (mais sous-dérivable) ; les autres sont \(C^\infty\).
Saturation : sigmoïde et tanh saturent ; ReLU ne sature pas pour \(z > 0\) mais produit des neurones morts pour \(z < 0\) ; Leaky ReLU et ELU corrigent ce défaut.
En pratique, ReLU est le choix par défaut pour les couches cachées, et softmax pour la couche de sortie en classification.
Le perceptron simple#
Le perceptron simple est un classifieur binaire linéaire. Son algorithme d’apprentissage est l’un des premiers algorithmes d’apprentissage automatique.
Définition 200 (Perceptron simple)
Le perceptron simple est un classifieur binaire défini par :
où \(\text{signe}(z) = +1\) si \(z \geq 0\) et \(-1\) sinon. La frontière de décision est l’hyperplan \(\{\mathbf{x} \in \mathbb{R}^d : \mathbf{w}^\top \mathbf{x} + b = 0\}\).
Algorithme d’apprentissage#
Définition 201 (Algorithme d’apprentissage du perceptron)
Étant donné un jeu d’entraînement \(\{(\mathbf{x}_i, y_i)\}_{i=1}^n\) avec \(y_i \in \{-1, +1\}\) et un taux d’apprentissage \(\eta > 0\) :
Initialiser \(\mathbf{w} \leftarrow \mathbf{0}\), \(b \leftarrow 0\).
Répéter jusqu’à convergence :
Pour chaque \((\mathbf{x}_i, y_i)\) :
Calculer \(\hat{y}_i = \text{signe}(\mathbf{w}^\top \mathbf{x}_i + b)\).
Si \(\hat{y}_i \neq y_i\) (mauvaise classification) :
\(\mathbf{w} \leftarrow \mathbf{w} + \eta \, y_i \, \mathbf{x}_i\)
\(b \leftarrow b + \eta \, y_i\)
La règle de mise à jour pousse l’hyperplan dans la direction de l’observation mal classée.
Remarque 169
L’intuition de la règle de mise à jour est géométrique. Lorsqu’un point \(\mathbf{x}_i\) de classe \(y_i = +1\) est mal classé (c’est-à-dire \(\mathbf{w}^\top \mathbf{x}_i + b < 0\)), on ajoute \(\eta \mathbf{x}_i\) au vecteur de poids, ce qui « tourne » l’hyperplan vers \(\mathbf{x}_i\). Symétriquement, si \(y_i = -1\) et que le point est du mauvais côté, on soustrait \(\eta \mathbf{x}_i\).
Théorème de convergence du perceptron#
Proposition 52 (Théorème de convergence du perceptron)
Soit \(\{(\mathbf{x}_i, y_i)\}_{i=1}^n\) un jeu de données linéairement séparable, c’est-à-dire qu’il existe \(\mathbf{w}^* \in \mathbb{R}^d\) avec \(\|\mathbf{w}^*\| = 1\) et une marge \(\gamma > 0\) tels que \(y_i (\mathbf{w}^{*\top} \mathbf{x}_i) \geq \gamma\) pour tout \(i\). Soit \(R = \max_i \|\mathbf{x}_i\|\). Alors l’algorithme du perceptron (avec \(\eta = 1\) et biais absorbé) fait au plus
erreurs avant de converger.
Proof. Absorbons le biais en ajoutant une coordonnée constante 1 aux entrées : \(\tilde{\mathbf{x}}_i = (\mathbf{x}_i^\top, 1)^\top\) et \(\tilde{\mathbf{w}} = (\mathbf{w}^\top, b)^\top\). Notons \(\tilde{\mathbf{w}}^{(t)}\) le vecteur de poids après \(t\) mises à jour, avec \(\tilde{\mathbf{w}}^{(0)} = \mathbf{0}\). Soit \((\mathbf{x}_{i_t}, y_{i_t})\) le point mal classé à l’étape \(t\), de sorte que \(\tilde{\mathbf{w}}^{(t)} = \tilde{\mathbf{w}}^{(t-1)} + y_{i_t} \tilde{\mathbf{x}}_{i_t}\).
Borne inférieure (le vecteur de poids s’aligne avec la solution) :
Par récurrence : \(\tilde{\mathbf{w}}^{*\top} \tilde{\mathbf{w}}^{(t)} \geq t\gamma\). Par Cauchy-Schwarz : \(\|\tilde{\mathbf{w}}^{(t)}\| \geq t\gamma\).
Borne supérieure (la norme du vecteur de poids croît lentement) :
Comme le point est mal classé, \(y_{i_t} \tilde{\mathbf{w}}^{(t-1)\top} \tilde{\mathbf{x}}_{i_t} \leq 0\), donc \(\|\tilde{\mathbf{w}}^{(t)}\|^2 \leq \|\tilde{\mathbf{w}}^{(t-1)}\|^2 + R^2\). Par récurrence : \(\|\tilde{\mathbf{w}}^{(t)}\|^2 \leq t R^2\).
Conclusion. En combinant : \(t^2 \gamma^2 \leq \|\tilde{\mathbf{w}}^{(t)}\|^2 \leq t R^2\), d’où \(t \leq R^2 / \gamma^2\).
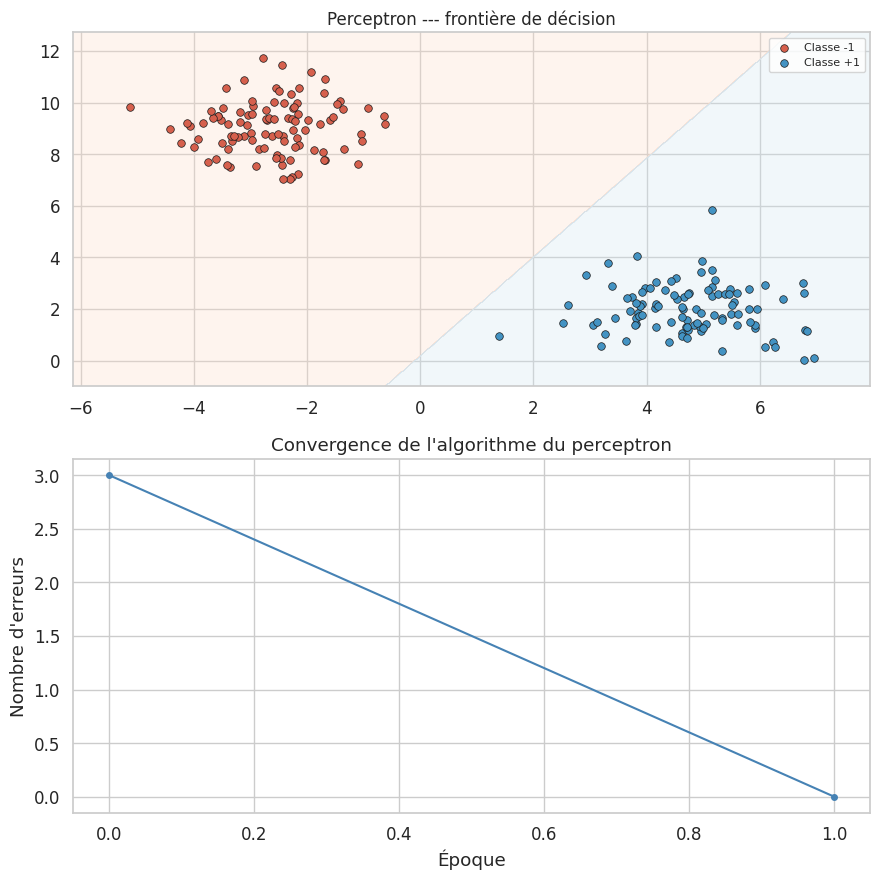
Implémentation from scratch#
Convergence en 2 époques
Précision sur l'entraînement : 100.00%
Limitations du perceptron simple#
Le perceptron simple ne peut apprendre que des frontières de décision linéaires. Cette limitation a été formalisée de manière célèbre par Minsky et Papert.
Le problème XOR#
Proposition 53 (Impossibilité du XOR par un perceptron simple)
La fonction XOR, définie sur \(\{0, 1\}^2\) par :
\(x_1\) |
\(x_2\) |
\(x_1 \oplus x_2\) |
|---|---|---|
0 |
0 |
0 |
0 |
1 |
1 |
1 |
0 |
1 |
1 |
1 |
0 |
n’est pas linéairement séparable et ne peut donc pas être apprise par un perceptron simple.
Proof. Supposons par l’absurde qu’il existe \(w_1, w_2, b \in \mathbb{R}\) tels que le perceptron \(\hat{y} = \text{signe}(w_1 x_1 + w_2 x_2 + b)\) calcule le XOR. Alors :
\((0,0) \to -1\) : \(b < 0\)
\((0,1) \to +1\) : \(w_2 + b \geq 0\), soit \(w_2 \geq -b > 0\)
\((1,0) \to +1\) : \(w_1 + b \geq 0\), soit \(w_1 \geq -b > 0\)
\((1,1) \to -1\) : \(w_1 + w_2 + b < 0\)
De (2) et (3) : \(w_1 + w_2 \geq -2b > 0\). Mais (4) exige \(w_1 + w_2 < -b\), donc \(-2b \leq w_1 + w_2 < -b\), ce qui donne \(-2b < -b\), soit \(b > 0\). Contradiction avec (1). Aucun hyperplan ne sépare les quatre points. \(\square\)
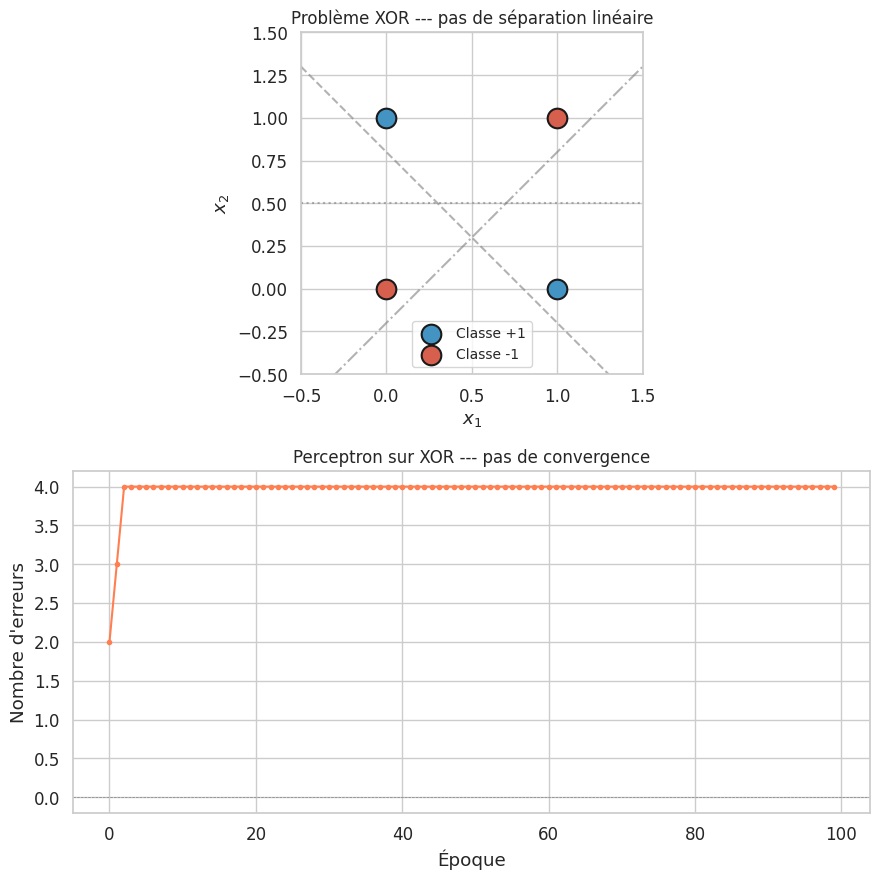
Remarque 170
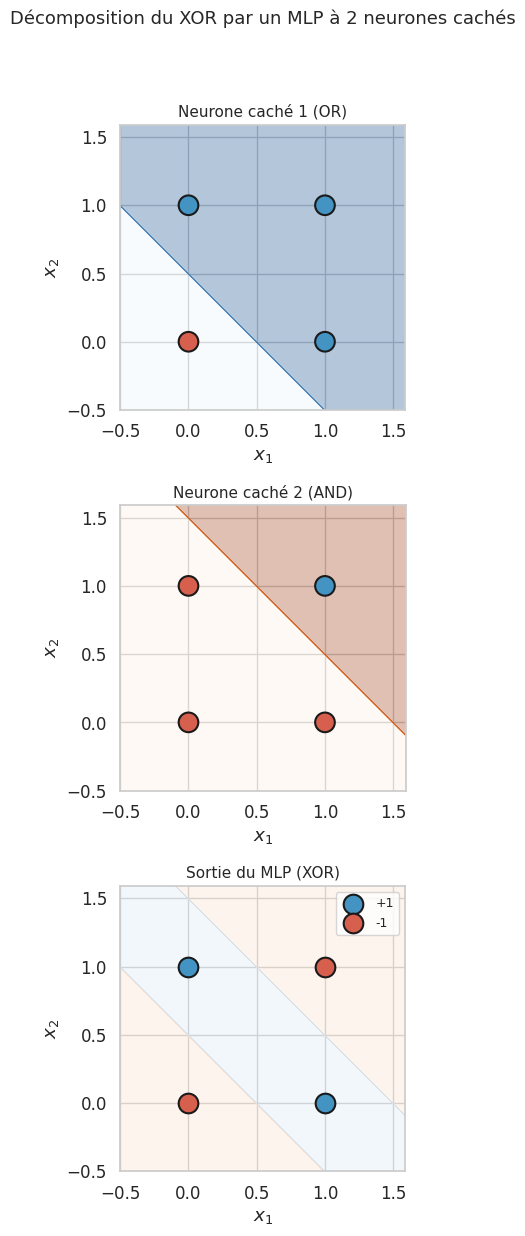
Le résultat de Minsky et Papert ne concerne que le perceptron simple (sans couche cachée). Un réseau avec une seule couche cachée de deux neurones suffit à résoudre le XOR. Cette observation est la motivation centrale du perceptron multicouche.
Perceptron multicouche (MLP)#
Pour dépasser les limitations du perceptron simple, on empile plusieurs couches de neurones. Le modèle résultant — le perceptron multicouche — est capable d’apprendre des frontières de décision arbitrairement complexes.
Architecture#
Définition 202 (Perceptron multicouche)
Un perceptron multicouche (MLP, Multi-Layer Perceptron) est un réseau de neurones organisé en couches :
Une couche d’entrée de \(d\) neurones (les features).
Une ou plusieurs couches cachées de \(h_1, h_2, \ldots, h_L\) neurones.
Une couche de sortie de \(K\) neurones (\(K = 1\) pour la classification binaire, \(K\) classes pour la multiclasse).
Chaque neurone d’une couche est connecté à tous les neurones de la couche suivante (réseau entièrement connecté ou fully connected). L’information se propage de la couche d’entrée vers la sortie : on parle de réseau feedforward.
Notation matricielle#
Définition 203 (Propagation avant (forward pass))
Notons \(\mathbf{a}^{(0)} = \mathbf{x}\) l’entrée. Pour la couche \(\ell = 1, \ldots, L+1\) :
où \(\mathbf{W}^{(\ell)} \in \mathbb{R}^{h_\ell \times h_{\ell-1}}\) est la matrice de poids, \(\mathbf{b}^{(\ell)} \in \mathbb{R}^{h_\ell}\) le vecteur de biais, et \(\varphi^{(\ell)}\) la fonction d’activation de la couche \(\ell\). La sortie du réseau est \(\hat{\mathbf{y}} = \mathbf{a}^{(L+1)}\).
Remarque 171
Le nombre total de paramètres d’un MLP à couches \(d, h_1, h_2, \ldots, h_L, K\) est :
Par exemple, un réseau \(784 \to 256 \to 128 \to 10\) possède \(784 \times 256 + 256 + 256 \times 128 + 128 + 128 \times 10 + 10 = 235\,146\) paramètres.
Théorème d’approximation universelle#
Proposition 54 (Théorème d’approximation universelle (Cybenko, 1989 ; Hornik, 1991))
Soit \(\varphi\) une fonction d’activation continue, bornée et non constante (par exemple, la sigmoïde). Alors, pour toute fonction continue \(f : [0, 1]^d \to \mathbb{R}\) et pour tout \(\varepsilon > 0\), il existe un réseau à une seule couche cachée avec un nombre fini de neurones tel que
Autrement dit, un MLP à une couche cachée est un approximateur universel : il peut approximer toute fonction continue à une précision arbitraire, pourvu que la couche cachée soit suffisamment large.
Remarque 172
Ce théorème est un résultat d”existence : il garantit qu’une solution existe, mais ne dit rien sur la manière de la trouver (algorithme d’apprentissage) ni sur le nombre de neurones nécessaires (qui peut être exponentiellement grand). En pratique, les réseaux profonds (plusieurs couches) atteignent de meilleures performances avec moins de paramètres que les réseaux larges et peu profonds, grâce à la composition hiérarchique de représentations.
Vérification du MLP sur XOR :
x = [0 0] -> y_pred = -1 (attendu : -1) ok
x = [0 1] -> y_pred = +1 (attendu : +1) ok
x = [1 0] -> y_pred = +1 (attendu : +1) ok
x = [1 1] -> y_pred = -1 (attendu : -1) ok
Exemple pratique : MLPClassifier de Scikit-learn#
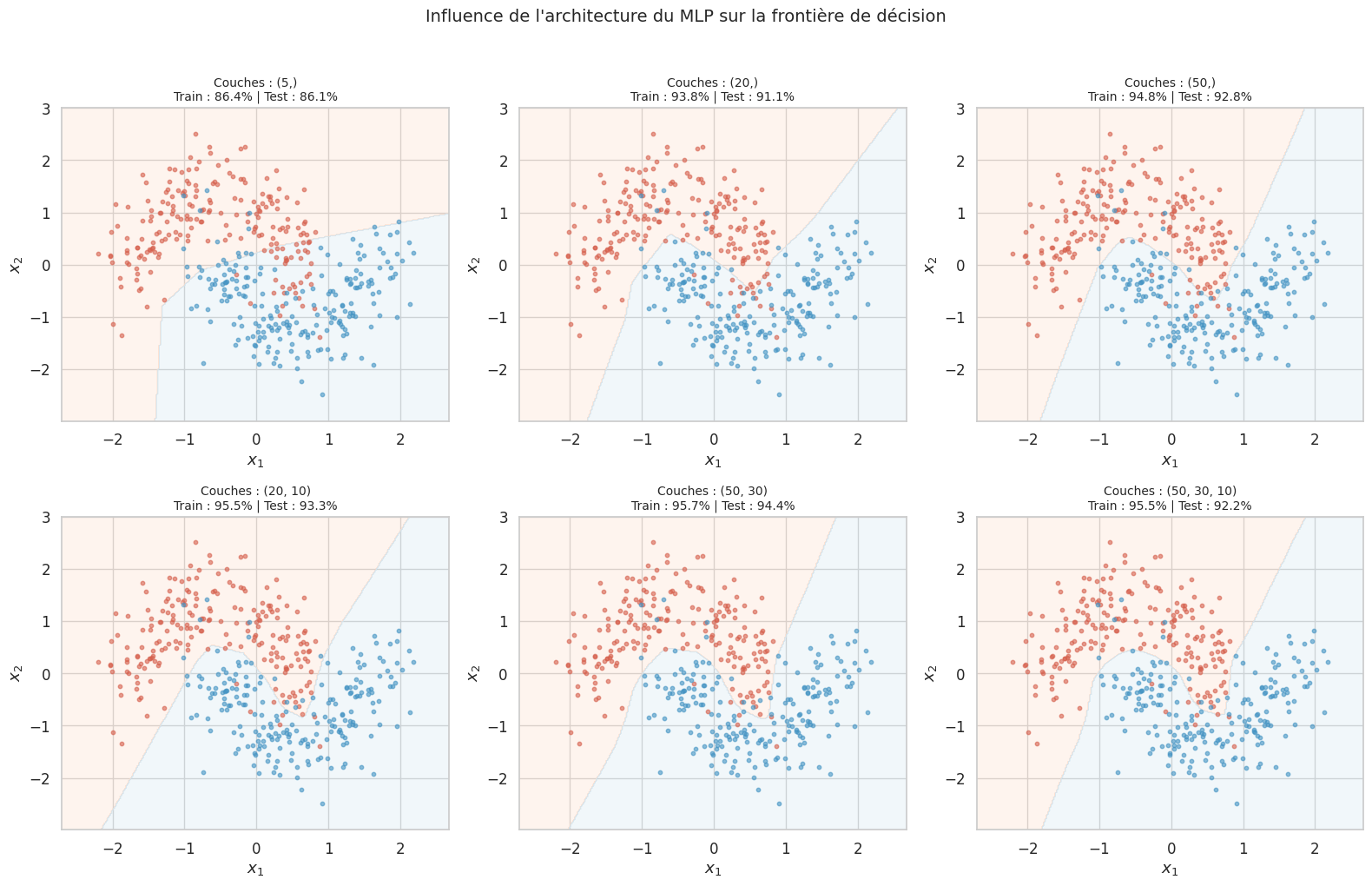
Passons à une mise en oeuvre avec MLPClassifier de Scikit-learn sur un jeu de données non linéairement séparable, pour montrer la puissance du perceptron multicouche.
Entraînement : 420 échantillons
Test : 180 échantillons
Remarque 173
On observe que même un MLP avec une seule couche cachée de 5 neurones capture déjà la forme non linéaire des données. En augmentant le nombre de neurones et de couches, la frontière de décision devient plus flexible, mais le risque de surapprentissage augmente. En pratique, on contrôle ce risque par la régularisation (paramètre alpha dans Scikit-learn), le early stopping ou le dropout (abordé dans les chapitres suivants).
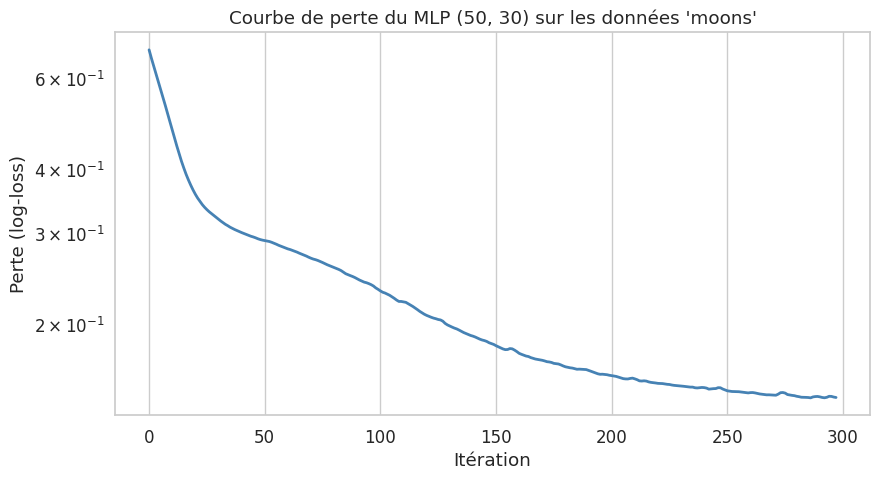
Précision finale --- Train : 95.71% | Test : 94.44%
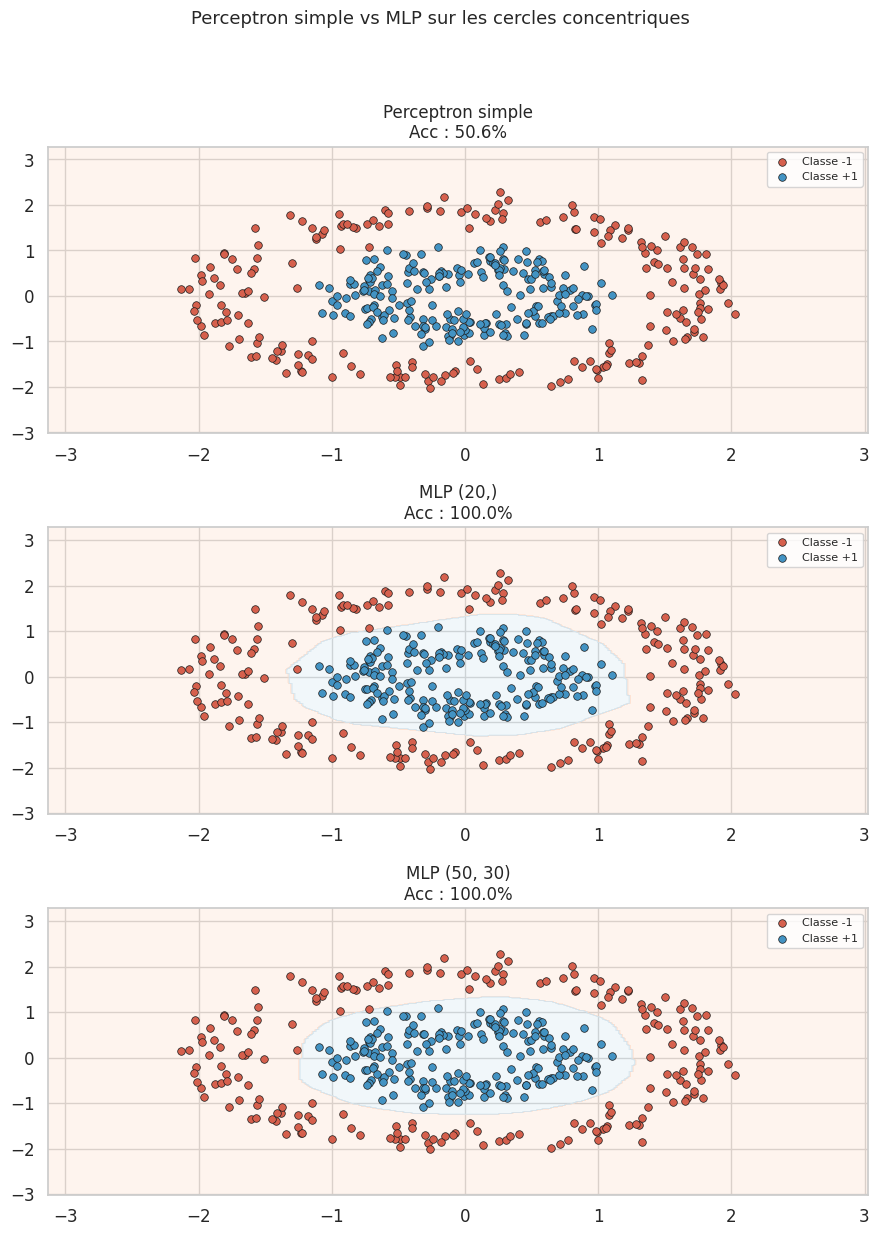
Exemple 17 (Interprétation des résultats)
Sur les cercles concentriques, le perceptron simple est incapable de séparer les deux classes (frontière linéaire dans un problème circulaire). Le MLP avec une couche de 20 neurones capture déjà la structure circulaire, et le MLP à deux couches (50, 30) produit une frontière de décision très propre. Cela illustre concrètement la puissance de la non-linéarité introduite par les couches cachées.
Du perceptron au deep learning#
Ce chapitre a posé les fondations de l’architecture neuronale : du neurone artificiel unique au perceptron multicouche. Le chemin vers le deep learning passe par plusieurs étapes que nous aborderons dans les chapitres suivants :
Rétropropagation et optimisation (chapitre 17) : l’algorithme de rétropropagation du gradient permet d’entraîner efficacement un MLP en calculant les gradients de la fonction de perte par rapport à chaque poids, couche par couche. Nous y étudierons aussi les optimiseurs modernes (SGD avec momentum, Adam, etc.) et les techniques de régularisation (dropout, batch normalization).
Frameworks : PyTorch (chapitre 18) : les bibliothèques de deep learning (PyTorch, TensorFlow) automatisent la différentiation, gèrent le calcul sur GPU et fournissent des abstractions de haut niveau pour construire, entraîner et déployer des réseaux.
Au-delà du MLP : les réseaux convolutifs (chapitre 19) exploitent la structure spatiale des images ; les réseaux récurrents (chapitre 20) traitent les séquences ; les Transformers (chapitre 23) révolutionnent le traitement du langage naturel.
Remarque 174
Le perceptron multicouche, malgré sa simplicité relative, reste un composant fondamental des architectures modernes. Les couches entièrement connectées (fully connected ou dense) sont présentes dans presque tous les réseaux profonds, au moins en couche de sortie. Comprendre le MLP est donc un prérequis essentiel pour aborder le deep learning.
Résumé#
Ce chapitre a couvert les fondations des réseaux de neurones :
Le neurone artificiel modélise une unité de calcul simple : somme pondérée, biais et fonction d’activation.
Les fonctions d’activation (Heaviside, sigmoïde, tanh, ReLU, Leaky ReLU, ELU, Swish, softmax) déterminent le comportement non linéaire du réseau. Le choix de ReLU pour les couches cachées et de softmax pour la sortie en classification est devenu standard.
Le perceptron simple apprend une frontière linéaire. Le théorème de convergence garantit qu’il trouve une solution si les données sont linéairement séparables, en au plus \(R^2/\gamma^2\) mises à jour.
Les limitations du perceptron simple (impossibilité du XOR) motivent le passage au perceptron multicouche.
Le perceptron multicouche (MLP), grâce aux couches cachées et aux fonctions d’activation non linéaires, est un approximateur universel capable d’apprendre des frontières de décision arbitrairement complexes.
L’entraînement du MLP par rétropropagation du gradient sera l’objet du chapitre suivant.